融合注意力机制的模糊图像多尺度复原
2022-05-23陈紫柠张宏怡曾念寅李寒
陈紫柠,张宏怡,曾念寅,李寒
1.厦门理工学院光电与通信工程学院,厦门 361024;2.厦门大学航天航空学院,厦门 361102
0 引 言
模糊图像复原是现代数字图像处理研究中的重点和难点,其实质是从一幅模糊的图像中复原出与真实图像接近的清晰图像。去模糊方法可以分为模糊核已知的非盲图像去模糊和模糊核未知的盲图像去模糊。在现实生活中,图像系统的模糊核往往是未知的,因此在先验知识不足的情况下盲图像去模糊的研究具有更大的意义。传统的去模糊方法需要对潜在模糊核进行估计,针对不同模糊(均匀、非均匀)进行建模(Xu等,2013),同时需要依靠大量的自然图像先验来约束解空间,拟合模糊特征。然而真实世界的模糊比建模情况要复杂的多,预测模糊模型需要大量的参数调整以及花费高昂的时间成本(Kim和Lee,2014)。
深度学习的兴起,为模糊图像处理提供了一些新思路。Sun等人(2015)利用卷积神经网络(convolutional neural network, CNN)提取模糊图像特征并预测其模糊核概率分布,使用图像旋转扩展CNN预测的运动模糊核候选集,解决了单幅图像中估计和消除非均匀运动模糊的问题,但耗时过长。Noroozi等人(2017)和Nah等人(2017)采用多尺度卷积神经网络直接对图像进行去模糊,但在图像进行卷积操作的过程中会使图像过于平滑导致图像的高频信息和图像纹理细节丢失。Tao等人(2018)基于多尺度策略,提出一种参数共享的尺度循环网络(scale-recurrent network, SRN)用于去模糊。相比于Nah等人(2017)的多尺度结构,SRN能够显著减少可训练参数的数量,使网络架构变得更加简单,极大地提升了训练效率。吴迪等人(2020)将残差密集网络应用到图像去模糊领域,该网络能够充分利用中间层的有用信息,既能显著提升复原图像的质量,又不需要大量的时间消耗,但是对大尺寸模糊核的模糊图像复原效果还有所欠缺。
生成对抗网络(generative adversarial network, GAN)由于其能保留图像中丰富的细节、创造出与真实图像十分接近的图像等特点而广泛应用于图像处理任务中。Kupyn等人(2018)提出基于条件生成对抗网络(conditional generative adversarial networks, CGAN)的去模糊方法,将图像去模糊视为一种特殊的图像迁移任务,该方法视觉效果方面取得不错的结果,但去模糊后的图像存在边缘轮廓不清晰的问题,复原图像存在伪影。随后,作者又提出了新的端到端的生成对抗网络DeblurGAN-v2(Kupyn等, 2019),首次将特征金字塔网络引入去模糊处理中,将特征金字塔网络与各种骨干网络相结合,在性能和效率之间取得平衡,但是整体网络框架较大,较为复杂。
为解决现有方法中存在的不足,本文提出一种基于多尺度对抗学习去模糊的方法,主要的创新点包括:1)采用多尺度生成对抗网络,基于由粗到细的策略对模糊图像进行复原;2)改进残差结构,加入空洞卷积模块,以此来获取不同感受野大小的特征图并进行拼接,使得卷积层能够获取更大范围的特征信息;3)在残差块中引入瓶颈结构,通过使用1×1卷积来巧妙地缩减或扩张特征图的维度,简化网络结构;4)加入通道注意力模块,通过学习各通道间的相互依赖关系自适应地调整各通道的特征权重,以此来提高网络的表示能力,加强有用特征的权重并抑制无用特征。
1 基于GAN的图像去模糊
图像盲去模糊是指在模糊核未知情况下从退化图像中复原出清晰图像的过程。清晰图像在模糊核和噪声的影响下,得到模糊图像的过程为
IB=K(M)*IS+N
(1)
式中:IS表示清晰图像,N为加性噪声,*表示卷积操作,K(M)表示由运动场M产生的模糊核,IB为模糊图像,由清晰图像与模糊核卷积并加上噪声得到。传统的图像去模糊方法主要对模糊核已知的图像进行处理,但现实中模糊核未知的系统更为常见,确定图像模糊核函数并复原出清晰图像的过程复杂烦琐,需要大量时耗。
1.1 GAN网络
Goodfellow等人(2014)提出GAN结构,其应用极其广泛。GAN网络结构由生成器和判别器组成。生成器通过学习真实样本的数据分布来生成新的数据。判别器将真实数据和生成的样本数据作为判别器的输入数据,并输出置信度得分。判别器的作用是接收真实样本和生成样本,并试图区分它们。而生成器的目标是通过生成无法与真实样本区分的感知上令人信服的样本来愚弄判别器。生成器G和判别器D之间的动态博弈过程可以转化为求解以下极小极大目标函数的过程,即
(2)
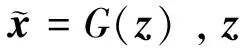
1.2 条件GAN网络
条件生成对抗网络(CGAN)是在GAN的基础上增加条件扩展的条件模型, 使得生成器和判别器都适用于某些额外条件c,并以条件c指导数据生成。在本文方法中对于模糊图像均有与之相对的清晰图像,因此采用模糊图像作为额外条件来训练网络模型,指导样本生成。基于CGAN模型能够学习到模糊图像和清晰图像之间的映射关系,如图1所示,生成器G通过学习真实数据的分布规律得到生成图像G(I),判别器D是用来判断清晰图像P和生成图像G(I)的数据分布的相似度,并且输出一个关于生成图像与真实清晰图像的评分,来表示置信度,以此来衡量生成器G的性能。当判别器D无法区分生成图像和真实清晰图像时,认为此时生成器达到最优。在整个过程中生成器与判别器进行对抗生成。

图1 条件生成对抗网络CGAN的基本模型
2 多尺度模糊图像复原网络
2.1 多尺度网络结构
为了避免传统方法中对模糊核和图像交替估计的冗长过程,提出一个基于CGAN的多尺度网络结构,网络改进了残差模块,采用端到端的训练方式,并采用多种损失函数对不同尺度下的生成图像加以约束,确保不同阶段下的图像复原都能达到最优。
如图2所示,生成器输入模糊图像IB,下采样得到多尺度图像,利用残差块进行特征提取,然后利用反卷积网络生成对应的去模糊图像ID。判别网络对生成图像ID和真实清晰图像IS进行对抗学习,来引导生成网络生成更加真实的图像。算法总体可分为训练阶段和测试阶段。

图2 多尺度网络结构
训练阶段:1)将训练数据集进行预处理,主要进行尺度变换、随机旋转以及随机垂直水平翻转等数据增强操作;2)将预处理后的数据输入多尺度网络,进行训练。
测试阶段:使用测试数据集对训练好的模型进行测试,并与测试数据中的清晰图像进行比较,评估模型性能。
2.1.1 生成器总体网络
生成器网络结构如图3所示,其中Bi,Ri分别代表3个尺度下(256×256像素、128×128像素、64×64像素)的模糊图像和生成图像,实验中i的最大值为3。提出的多尺度网络结构,粗网络的输入图像是小的分辨率图像,更精细的网络基本上与最粗规模网络结构相同。第1个卷积层采用串联的方式将前一阶段获得的去模糊图像上采样并与下一尺度的模糊图像一起作为下一个网络的输入,即在金字塔中的不同分辨率上逐渐恢复清晰图像,最粗糙的网络(网络的输入图像尺度为64×64像素)位于网络前端。因此,最粗糙的网络具有足够大的接收域去感知整个图像块,关注图像的轮廓等大特征。而更精细的网络,可以学习到更精细的特征(纹理细节)。该多尺度策略类似传统的模糊核估计中由粗到细的策略,将复杂的问题进行分解,逐步复原,先在低分辨率下复原大尺度的信息,然后在高分辨率下复原细节信息。生成器采用多尺度的网络结构,使得每个尺度的输出图像都经过训练。在测试时,选择原始比例的图像进行测试。
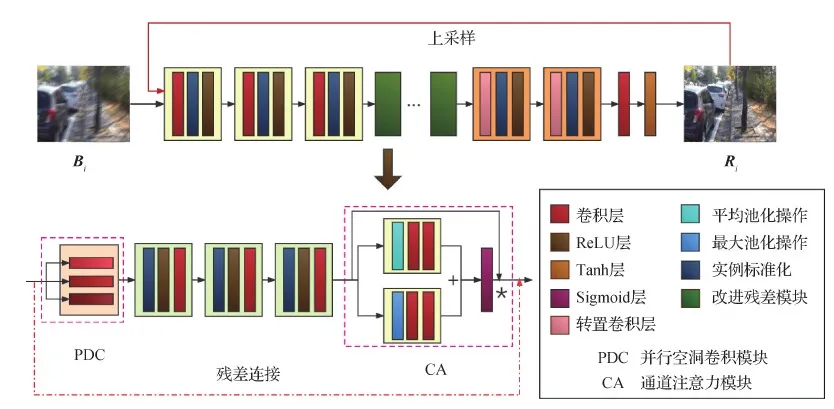
图3 生成器网络结构
生成网络由3个卷积—残差—转置卷积网络块组成。每个网络块又由1个7×7卷积层、2个5×5卷积层、12个改进残差块(最后第3层网络将残差块个数设置为15个)、2个转置卷积层级联组成,每一个小的卷积单元,均包含实例标准化层(instance normalization, IN)和ReLU激活函数层,以此来限制系数的范围,稳定生成器的训练。网络参数如表1所示。
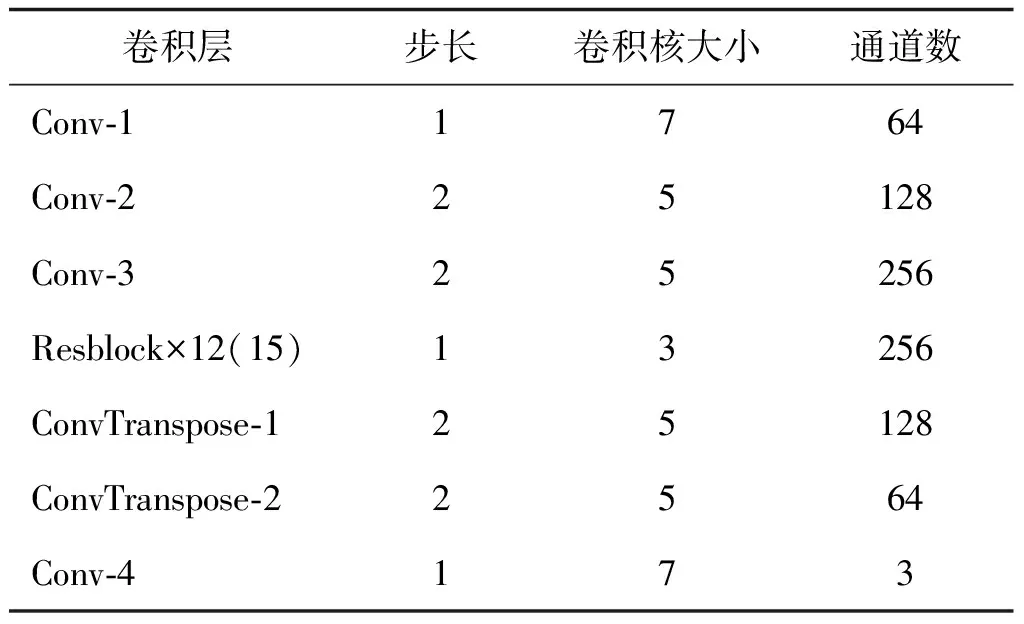
表1 生成器网络结构
2.1.2 改进残差块结构
原始残差块结构如图4(a)所示,由2个步长为1的3×3卷积以及残差连接组成。本文将瓶颈结构(Szegedy等,2015)与残差模块相结合,通过使用1×1卷积来巧妙地缩减特征图的维度,其结构如图4(b)所示。在最终实验中,去掉了实例归一化层,网络结构如图4(c)所示。
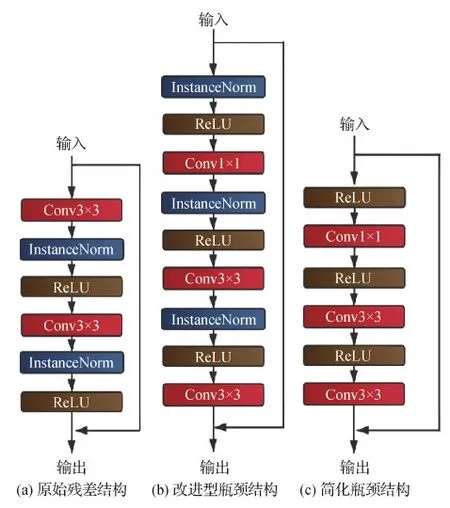
图4 简化残差结构
为了进一步提升网络的性能,在残差块结构后加入通道注意力机制(Hu等,2020),通过对各通道间的相互依赖关系进行建模自适应地对特征进行逐通道调整,利用全局信息有选择地增强有用特征的权重并抑制无用特征。原始残差块结构如图5(a)所示,加入通道注意力机制后的残差块如图5(b)所示,首先进行全局平均池化操作,将每个2维的特征通道变成一个实数,将全局信息压缩到通道描述符中,然后通过全连接层进行降维,再由ReLU函数激活;接着通过全连接层恢复维度,最后经过Sigmoid输出网络学习到的归一化通道权重系数,通过Scale层将原始特征图与通道权重逐通道相乘,得到加权特征图,最后将加权特征图与输入特征图逐点相加(⊕),得到最后的特征为通道注意力模块的输出。

图5 通道注意力模块
实验中发现,结合平均池化和最大池化更有助于特征的选择,本文将残差输入分为两个通道分别进行平均池化和最大池化操作,再将得到的结果并行输入Sigmoid层。最终采用的改进通道注意力模块,其结构如图6所示。
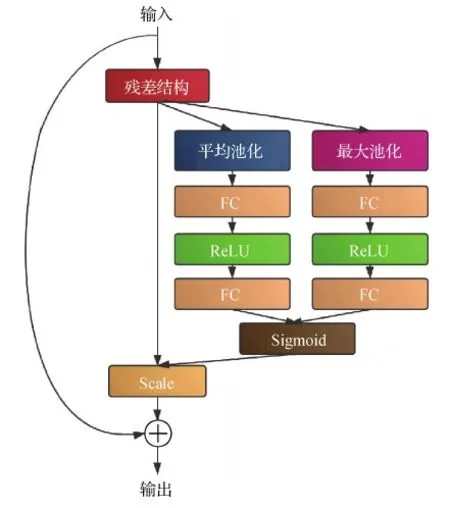
图6 改进通道注意力模块
为了在不增加计算量的同时增大感受野,提出一个新的模块,在残差结构中加入空洞卷积(dilated convolutions)。空洞卷积的字面意义就是在标准的卷积上注入空洞,以此来增加感受野,相比于原来的普通卷积,空洞卷积多了一个超参数空洞卷积率(dilation rate),简写为d,d指的是卷积核的间隔数量,而(d-1)的值则表示其中塞入的空格数,假定原来的卷积核大小为k,那么当塞入了(d-1)个空格后,在特征图上的实际感受野大小N变为
N=k+(k-1)×(d-1)
(3)
增加空洞卷积之后的感受野变化如表2所示。对于去模糊任务而言,感受野应当足够大,以保证捕获严重的大尺度模糊。使用空洞卷积可以在不做池化操作损失信息的情况下,增大感受野,同时获得不同感受野大小的特征图,构成并行空洞卷积模块,使得卷积输出层获取更大范围的信息。

表2 不同d值下的卷积核感受野大小
改进的残差结构虽然使用1×1卷积核降维来减少参数量,但是压缩特征通道的过程中,会造成一定的信息丢失,通过不同尺度特征图融合,可以获取更多的特征信息。将图7(a)中的并行空洞卷积模块加入通道注意力残差模块中,结构如图7(b)所示。

图7 改进残差模块
将改进残差模块加入本文多尺度网络结构中得到本文的最终网络结构。
2.1.3 判别器网络
判别网络D借鉴了PatchGAN(Isola等,2017)的方法,使用全卷积网络结构,如图8所示,网络包含实例标准化、LeakyReLU激活函数,其中LeakyReLU的负值斜率设置为α= 0.2。判别器网络结构参数如表3所示。
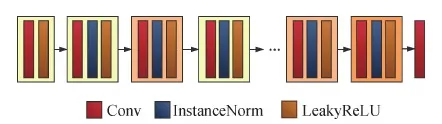
图8 判别器网络结构

表3 判别器网络结构
2.2 损失函数
2.2.1 对抗训练损失
对于由JS(Jensen-Shannon)散度近似引起的GAN训练不稳定而造成模式崩溃等问题,Arjovsky等人(2017)提出了 Wasserstein距离,计算为
(4)
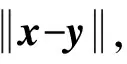
(5)
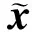
采用加入梯度惩罚项的WGAN-GP(Wasserstein generative adversarial network with gradient penalty)作为对抗损失函数(Gulrajani等,2017),GAN网络在训练后期,容易生成大量的重复样本,造成模式崩溃问题,在网络中加入梯度惩罚可以很好地解决这一问题,WGAN-GP计算为
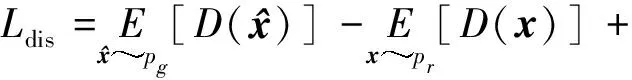

(6)
(7)

2.2.2 内容损失
在内容损失函数上选择感知损失,对清晰图像和生成图像进行约束,维持图像的内容一致性。同时使用像素点之间的最小均方误差(mean squared error, MSE)损失使得生成的去模糊图像具有更加光滑的边缘轮廓,MSE的计算为
(8)
感知损失是由神经网络提取的深层的特征图,由于网络层数越深越能够获取到更深层次的语义信息,所以采用较为深层的卷积层作为计算感知损失的特征层。选择在ImageNet(Deng等,2009)上的VGG19(Visual Geometry Group layer 19)(Simonyan和Zisserman,2015)预训练模型的深卷积层作为特征层,计算感知损失,即


(9)
Lcon=α1LMSE+α2Lper
(10)
式中,α1、α2的取值分别为0.999和0.01。实验最终采用的损失函数为对抗损失和内容损失的加权和,即
L=Lcon+λLgen
(11)
式中,λ的实验值为0.000 1。
3 实验步骤
3.1 训练数据集
GoPro数据集(Nah等,2017)通过累加拍摄高速视频中的视频帧来模仿真实模糊图像的生成过程,模拟复杂的物体的运动和相机的抖动。并通过叠加不同数量连续的短曝光帧求平均来生成不同强度的模糊图像,得到更加真实的模糊图像。
DVD(deep video deblurring)数据集(Su等,2017)收集了由iPhone 6 s、GoPro Hero 4等各种设备以240 帧/s捕获的真实世界视频,也是通过平均连续的短曝光帧来生成模糊图像。
3.2 数据预处理
本文将训练数据集随机裁剪成256×256像素分辨率图像,同时将图像水平翻转、随机按照一定角度旋转增加数据量,增强网络泛化能力。最后将训练的模糊—清晰图像对的像素值作归一化处理,数值范围为[-1,1],使得网络更易于训练。同时将裁剪后的图像下采样为64×64像素、128×128像素分辨率以提供多尺度输入。
3.3 训练细节
使用GoPro数据集、DVD数据集进行训练与测试,训练集的原始分辨率均为1 280×720像素,其中GoPro使用其中2 103对模糊—清晰图像对训练,剩余的1 111组测试。DVD数据集将其中59组图像作为训练集,剩余10组进行测试。实验采用Pytorch作为网络模型训练框架,在GTX1080Ti GPU上进行训练,Batchsize设置为2。使用Adam算法进行网络的训练优化,初始学习率设为10-4,当训练epoch大于500时,学习率开始递减,网络模型逐渐收敛,训练到1 000个epoch时,模型收敛,学习率趋于0,停止训练。
4 实验结果
4.1 不同尺度网络测试结果对比
为衡量不同尺度网络模型的优劣性,从左到右分别为1个尺度(256×256像素),两个尺度(128×128像素、256×256像素),以及3个尺度(64×64像素、128×128像素、256×256像素)模型,对模糊图像的处理结果分别对应图9(a)—(c)。3个模型均训练300个epoch进行对比,从图9(a)(b)可以看出,模型所复原的图像均存在边缘不清晰、细节纹理信息不够丰富等问题。而图9(c)模型所还原的模糊图像有着更加清晰的边缘,细节纹理信息也更加丰富。3个尺度输入模型由于其小尺度更关注图像轮廓等大特征、大尺度更关注图像的细节特征,由粗到细,分阶段提取模糊图像特征,因此取得最好的模型效果。

图9 不同尺度去模糊效果对比图
如表4所示,1个尺度输入与两个尺度输入的结果相近,3个尺度输入模型获得最高的峰值信噪比(peak signal to noise ratio, PSNR)和结构相似度(structural similarity, SSIM)。PSNR指标较1个尺度输入模型提升1.3%,较两个尺度输入模型提升2.5%。SSIM指标均提高2.3%。

表4 多尺度下的全参考图像质量评价对比
4.2 不同残差模块测试结果对比
从表5可以看出,增加并行空洞卷积模块的网络结构,由于其感受野的增加,使卷积输出层能够获得更大范围的特征信息,去模糊后的图像获得了视觉提升。而加入通道注意力模块的结构,由于对网络各通道特征进行加权选择,在一定程度上忽略掉一些信息,在训练数据集上表现优异,但是对测试集数据产生过拟合现象,反而使测试结果的指标降低。将两者结合,既能扩大感受野,又能针对不同的特征通道进行选择,在所有方法中达到最优的性能指标,较原来的3个尺度结构PSNR至少提升1%,SSIM提升0.77%。
从图10中可以看出增加通道注意力和并行空洞卷积模块后所得到的去模糊图像有着更加清晰的人脸边缘轮廓,对于地板的复原纹理信息也更加丰富。通过表5的定量和图10的定性分析,加入并行卷积模块和通道注意力模块的网络结构,对于图像的复原效果,均有一定程度的提升,但是将两者结合起来的模型获得最好的人眼视觉效果和最高的性能指标。

图10 本文方法的实验结果对比
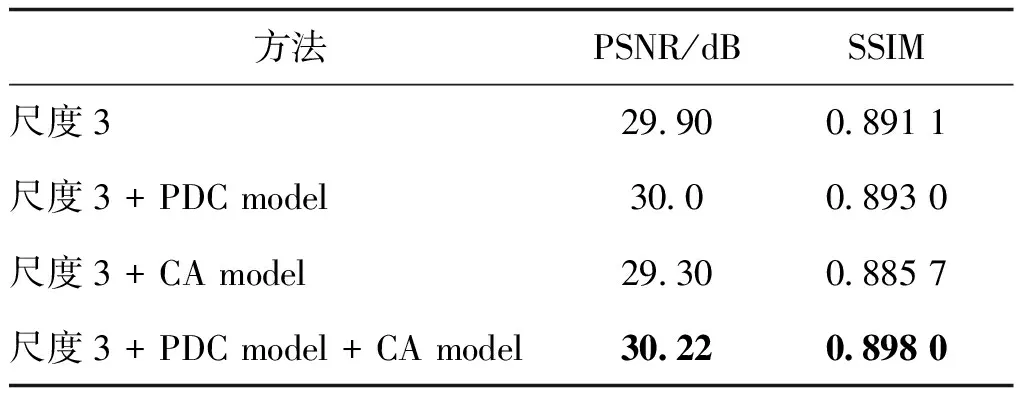
表5 本文方法的消融实验结果
4.3 几种主流方法与本文的去模糊效果对比
为验证提出网络的有效性,分别使用本文方法、Xu等人(2013)、Sun等人(2015)、Kim和Lee(2014)、Nah等人(2017)、Kupyn等人(2018)方法对模糊数据集进行处理,并通过PSNR、SSIM和处理时间来评价算法的优劣。
4.3.1 GoPro 数据集测试结果分析
表6为不同方法在GoPro测试集进行去模糊处理后获得的性能指标,将在GoPro测试集上的所有测试结果的PSNR、SSIM以及处理时间的平均值作为实验最后的评价指标。由表6可知,本文方法的各项指标都明显优于Xu等人(2013)、Kim和Lee(2014)、Sun等人(2015)的方法。本文方法的PSNR值较Xu等人(2013)方法提升约20.4%,较Sun等人(2015)方法提升约22.6%,较Kim和Lee(2014)方法提升约27.8%。Nah等人(2017)方法的结果与本文方法接近,虽然本文SSIM指标低于Nah等人(2017)方法,但是PSNR指标较Nah等人(2017)提升3.9%,较Kupyn等人(2018)方法提升5.3%。这归功于改进的残差结构,它引入空洞卷积获得更大范围的特征信息;并加入通道选择,有选择地加强有效特征并抑制无效特征,因此获得更好的视觉效果。同时,本文的复原时间较Kupyn等人(2018)方法减少一半,本文方法的处理速度约为Nah等人(2017)方法处理速度的7倍,Xu等人(2013)方法的32倍,Sun等人(2015)方法的2 860倍,Kim和Lee(2014)方法的8 570倍。这是因为Kim和Lee(2014)、Xu等人(2013)采用传统盲去图像复原技术,过程冗长烦琐。而本文采用端到端的复原方法,无需对模糊核进行额外的估计,并且参数量减少,大大提升了复原速率。

表6 不同方法在GoPro 测试集上的全参考图像质量评价及运行时间
用不同方法对GoPro测试集进行测试, 并将处理结果进行局部放大来对比主观视觉效果。由图11可知,Sun等人(2015)、Xu等人(2013)的方法更适用于小尺度模糊的模糊图像,对大尺度的模糊图像复原效果不佳,复原后的图像存在一定的失真现象且没有清晰的边缘轮廓线。总体来说,Sun等人(2015)、Xu等人(2013)方法对于模糊程度较大的模糊图像,有着一定的局部复原效果,但是整体效果不理想。Kupyn等人(2018)、Nah等人(2017)的复原效果较Sun等人(2015)、Xu等人(2013)有着明显的提升,无论是车牌号码还是人脸图像都有着更好的人眼视觉效果,色彩信息更加丰富。相较于Kupyn等人(2018)、Nah等人(2017)的方法,本文方法有着更加清晰的轮廓边缘,对于地面的纹理细节信息也更加丰富,存在的伪影现象也更少。

图11 在GoPro测试集上的去模糊效果对比
4.3.2 DVD数据集结果分析
图12为在DVD验证集上的去模糊结果,从图中可以看出对于模糊核尺寸较小的图12(a)左图,Sun等人(2015)、Xu等人(2013)对模糊字母的复原取得一定的效果,但是字母的边缘存在一些伪影现象,影响视觉观看效果,Kupyn等人(2018)方法存在伪影现象,边缘不够清晰,图像的亮度对比度也较清晰图像有一定的差距,本文方法有着更清晰的边缘轮廓以及更丰富的细节信息,获得更好的人眼视觉效果。对比模糊核尺寸较大的图12(a)右图,用Sun 等人(2015)以及Xu等人(2013)的方法效果较差,复原效果不是很理想,图中窗户的边缘轮廓不够清晰,纹理细节方面有一定的缺失,车的边缘轮廓纹理细节较为缺失,伪影现象较为严重,Nah等人(2017)的方法对比Sun等人(2015)复原效果有明显的提升,窗户的边缘较为清晰,墙壁的纹理信息也更加丰富。而使用本文方法可获取最清晰的边缘轮廓,复原出的车与树木的纹理信息更加接近原始清晰图像,复原程度最高。

图12 不同方法在DVD数据集的去模糊效果对比
综上,Sun等人(2015)、Xu等人(2013)方法对于模糊核尺寸较小的模糊图像能够达到较好的复原效果,但是对于大尺寸模糊核的复原效果较差。而本文方法与Nah等人(2017)、Kupyn等人(2018)方法对于大小尺度模糊核均有一定程度的复原,但是相较于Nah等人(2017)、Kupyn等人(2018)方法,本文方法的复原结果具有更清晰的轮廓、更丰富的纹理细节信息,以及更接近清晰图像的色彩信息。
4.3.3 Köhler数据集测试结果
Köhler(2012)是一个基准数据集,用来评价去模糊算法,它由4幅清晰图像分别用12种不同的模糊核处理产生。该数据集较小,仅用来测试。图13为针对3种不同模糊核尺寸大小的模糊图像的处理情况。从图中可以看出相对于模糊图像,所复原旗子中的星星的边缘更加清晰,人脸的边缘轮廓线也更加清楚,整体复原效果良好。针对不同模糊核的模糊图像,本文方法均有一定程度上的复原。

图13 Köhler数据集上的处理结果
4.3.4 去模糊图像在目标检测中的结果
对GoPro数据集以及去模糊后的结果进行目标检测,使用基于COCO(common objects in context)2017数据集训练的YOLO-v4(you only look once)网络模型(Bochkovskiy等,2020)。如图14所示,在模糊图像上没有清晰的边界,也不能检测出较小的物体,而本文方法产生的去模糊图像有着更加清晰的边界,能够检测到更多的物体,并且能够识别小物体,置信度得分也有一定的提升。与表6中的PSNR和SSIM相比,通过目标检测结果可直观看出本文方法的去模糊效果,检测不同物体的置信度得分更加说明了经过本文方法处理后,目标检测算法能够更加准确地检测出物体。

图14 去模糊后的目标检测结果
5 结 论
提出了一种多尺度生成对抗网络的图像去模糊方法,采用由粗到细的策略,对模糊图像进行复原,改进残差块的结构,减少通道数量,降低网络参数量。同时,在不增加网络参数的情况下,加入并行空洞卷积模块,增大感受野,使得卷积输出层获取更大范围的信息,在图像需要全局信息或者需要捕获多尺度上下文信息的问题中能够很好地应用。最后,加入通道注意力模块,对通道之间的相关性进行建模,增强有用特征通道的权重,抑制无用特征,确定每层特征图上需要重点关注的内容,重新校准特征以此来提高网络的性能。实验结果表明,本文方法对于由不同尺寸模糊核产生的模糊图像均有一定程度的复原。同时,对比其他方法,本文方法具有运行速度快,复原边缘更清晰,纹理特征更加丰富等优点。此外,采用类似编码解码结构的网络结构,这种网络结构能在较大感受野的前提下学习多尺度的高级上下文信息,但是在捕捉精细的空间细节上还是有所欠缺。因此,今后的工作将围绕以下两点展开:
1)改进结构,追求有效学习高级上下文信息和生成精确的空间输出,达到两者之间的性能平衡;
2)GAN网络具有强大的图像迁移功能,与其他网络模块相结合具有强大的生成效果,未来也将在网络结构的改进、生成图像质量的提高、视频模糊消除等方面继续展开研究。
参考文献(References)
Arjovsky M, Chintala S and Bottou L.2017.Wasserstein GAN[EB/OL].[2021-03-22].https://arxiv.org/pdf/1701.07875.pdf
Bochkovskiy A, Wang C Y and Liao H Y M.2020.YOLOv4: optimal speed and accuracy of object detection[EB/OL].[2021-03-22].https://arxiv.org/pdf/2004.10934.pdf
Deng J, Dong W, Socher R, Li L, Li K and Li F F.2009.ImageNet: a large-scale hierarchical image database//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Miami, USA: IEEE: 248-255[DOI: 10.1109/CVPR.2009.5206848]
Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A and Bengio Y.2014.Generative adversarial networks[EB/OL].[2021-03-22].https://arxiv.org/pdf/1406.2661.pdf
Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V and Courville A.2017.Improved training of Wasserstein GANs//Proceedings of the 31st International Conference on Neural Information Processing Systems.Long Beach, USA: ACM: 5769-5779
Hu J, Shen L, Albanie S, Sun G and Wu E H.2020.Squeeze-and-excitation networks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(8): 2011-2023[DOI: 10.1109/TPAMI.2019.2913372]
Isola P, Zhu J Y, Zhou T H and Efros A A.2017.Image-to-image translation with conditional adversarial networks//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu, USA: IEEE: 5967-5976[DOI: 10.1109/CVPR.2017.632]
Kim T H and Lee K M.2014.Segmentation-free dynamic scene deblurring//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus, USA: IEEE: 2766-2773[DOI: 10.1109/CVPR.2014.348]
Köhler R, Hirsch M, Mohler B, Schölkopf B and Harmeling S.2012.Recording and playback of camera shake: benchmarking blind deconvolution with a real-world database//Proceedings of the 12th European Conference on Computer Vision Computer Vision.Florence, Italy: Springer: 27-40[DOI: 10.1007/978-3-642-33786-4_3]
Kupyn O, Budzan V, Mykhailych M, Mishkin D and Matas J.2018.DeblurGAN: blind motion deblurring using conditional adversarial networks//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City, USA: IEEE: 8183-8192[DOI: 10.1109/CVPR.2018.00854]
Kupyn O, Martyniuk T, Wu J R and Wang Z Y.2019.DeblurGAN-v2: deblurring(orders-of-magnitude)faster and better//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul, Korea(South): IEEE: 8877-8886[DOI: 10.1109/ICCV.2019.00897]
Nah S, Kim T H and Lee K M.2017.Deep multi-scale convolutional neural network for dynamic scene deblurring//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu, USA: IEEE: 257-265[DOI: 10.1109/CVPR.2017.35]
Noroozi M, Chandramouli P and Favaro P.2017.Motion deblurring in the wild//Proceedings of the 39th German Conference on Pattern Recognition.Basel, Switzerland: Springer: 65-77[DOI: 10.1007/978-3-319-66709-6_6]
Simonyan K and Zisserman A.2015.Very deep convolutional networks for large-scale image recognition//Proceedings of the 3rd International Conference on Learning Representations.San Diego, USA:[s.n.]
Su S C, Delbracio M, Wang J, Sapiro G, Heidrich W and Wang O.2017.Deep video deblurring for hand-held cameras//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu, USA: IEEE: 237-246[DOI: 10.1109/CVPR.2017.33]
Sun J, Cao W F, Xu Z B and Ponce J.2015.Learning a convolutional neural network for non-uniform motion blur removal//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition.Boston, USA: IEEE: 769-777[DOI: 10.1109/CVPR.2015.7298677]
Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V and Rabinovich A.2015.Going deeper with convolutions//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition.Boston, USA: IEEE: 1-9[DOI: 10.1109/CVPR.2015.7298594]
Tao X, Gao H Y, Shen X Y, Wang J and Jia J Y.2018.Scale-recurrent network for deep image deblurring//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City, USA: IEEE: 8174-8182[DOI: 10.1109/CVPR.2018.00853]
Wu D, Zhao H T and Zheng S B.2020.Densely connected convolutional network image deblurring.Journal of Image and Graphics, 25(5): 890-899(吴迪, 赵洪田, 郑世宝.2020.密集连接卷积网络图像去模糊.中国图象图形学报, 25(5): 890-899)
Xu L, Zheng S C and Jia J Y.2013.Unnatural L0 sparse representation for natural image deblurring//Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition.Portland, USA: IEEE: 1107-1114[DOI: 10.1109/CVPR.2013.147]
