区域注意力机制引导的双路虹膜补全
2022-05-23张志礼张慧王甲夏玉峰刘亮李佩佩何召锋
张志礼,张慧,王甲,夏玉峰,刘亮,李佩佩,何召锋*
1.北京邮电大学,北京 100876;2.北京中科虹霸科技有限公司,北京 100084
0 引 言
虹膜具有唯一性高、稳定性强、防伪性好和非接触等优势,被认为是最具有潜力的生物特征识别技术之一。然而,相较于人脸识别,虹膜识别系统对用户的配合度要求高,在图像采集过程中易受外界因素干扰(如眼镜框遮挡、光照、眨眼、距离和运动等)。如图1在虹膜图像采集过程中,受到眼镜框遮挡、红外光斑和眨眼等因素影响,会导致采集到的虹膜图像有效区域被遮挡。虹膜遮挡的存在,会导致虹膜识别系统的性能急剧下降。一方面,遮挡导致可见的虹膜区域变小,虹膜有效纹理信息减少,导致识别准确度下降;另一方面,遮挡的存在会影响虹膜预处理(如虹膜分割、质量判断等)的准确度,进而导致识别准确度下降。因此,提出有效的虹膜遮挡补全方法,对于提升虹膜识别、虹膜分割的性能有重要意义。

图1 遮挡图像
传统的图像补全方法(Bertalmio等,2000;Barnes等,2009;Darabi等,2012;Huang等,2014)主要根据已有像素来修复缺失区域,这类方法对于内容简单的图像修复效果较好,不适合纹理复杂的虹膜图像。随着深度学习技术的发展,以变分自编码器(variational autoencoder,VAE)(Kingma和Welling,2014)和生成对抗网络(generative adversarial networks,GAN)(Goodfellow等,2014)为代表的深度生成模型在理论上取得了重大突破,极大推进了图像生成与补全的发展。由于虹膜独特的“多自由度”的拓扑结构和“高熵率”的随机纹理,现有基于深度生成模型的虹膜补全方法无法充分利用全局信息,合成的虹膜图像与原图像缺乏一致性,且仍然可以观察到不切实际的扭曲和噪音等。近年来,Transformer(Vaswani等,2017)依靠其优秀的全局建模能力和自注意力机制,极大地推动了计算机视觉的发展,在图像分割(Zheng等,2021a)、图像检测(Carion等,2020)和图像分类(Dosovitskiy等,2021)3大经典图像处理任务上取得了不错的效果。本文首次尝试将Transformer应用到虹膜图像补全任务中,缓解卷积神经网络(convolutional neural network, CNN)全局建模能力较弱的问题。本文结合Transformer全局建模能力和CNN局部建模能力,提出了双路融合的虹膜补全网络,提高了修复图像的质量与整体一致性。此外,本文在现有注意力机制(Zhang等,2019;Guo等,2021)的基础上,针对虹膜补全任务,提出区域注意力机制进一步提升虹膜图像补全效果。
本文的贡献如下:
1)同时结合Transformer全局建模能力和CNN局部建模能力,提出双路融合的虹膜补全网络,尽可能保留图像的全局特征和局部特征,提高修复的虹膜图像质量,保持图像的全局局部一致性。
2)引入区域注意力机制,使得网络更加关注虹膜图像中遮挡区域的修复,生成高质量虹膜补全图像。
3)在CASIA(Institute of Automation, Chinese Academy of Sciences)虹膜数据集上进行大量的实验,证明了本文方法可以生成高质量的虹膜补全图像,并进一步提升虹膜分割与识别的性能。
1 相关工作
图像补全是对具有缺失区域的图像进行补全,或者对图像上的干扰物体进行消除。现有的图像补全方法可以分为传统方法和基于深度学习的方法。
1.1 基于传统方法的图像补全方法
传统的图像补全方法主要分为两类:基于扩散的方法和基于补丁的方法。基于扩散的方法(Bertalmio等,2000;Ballester等,2001;Esedoglu和Shen,2002)利用缺失区域周围的像素,沿着缺失区域的边缘向内扩散进行修复。这类方法在处理小区域遮挡或者无复杂结构的图像效果可观,对于具有较大缺失区域的图像,或者纹理信息比较复杂的情况,修复的结果往往会呈现模糊现象。基于补丁的方法(Barnes等,2009;Darabi等,2012;Huang等,2014)通过将相似或相关的图像块从非缺失图像区域转移到缺失区域来填充内容。虽然传统方法在缺失区域较小的情况下表现良好,但不能产生语义上有意义的内容,而且计算图像块之间的相似性,需要很高的计算成本。
1.2 基于深度学习的图像补全方法
深度学习在计算机视觉中得到了广泛的应用,GAN的出现更是促进了图像补全的发展。Pathak等人(2016)首次将CNN用于图像补全中,并提出了上下文编码器(context encoder,CE)结构,同时引入对抗训练来学习图像特征,补全较大的缺失区域。Iizuka等人(2017)和孙劲光等人(2020)同时使用全局和局部判别器,并借助空洞卷积增大输出神经元的感受野,保持补全结果的全局局部一致性。刘坤华等人(2021)将边界信息引入深度图像修复。Li等人(2017)、Song等人(2019)和Nazeri等人(2019)将人脸几何结构信息引入人脸补全中,以人脸几何信息为指导,预测缺失区域的内容,完成人脸补全和编辑任务。基于编码器—解码器的补全网络,单独对图像的结构或者纹理进行生成,而未将两者结合在一起,这降低了结构和纹理的生成效果,Liu等人(2020)提出相互编码器—解码器对图像结构和纹理进行联合恢复。Navasardyan和Ohanyan(2020)引入洋葱卷积来保持特征连续性和语义一致性。Li等人(2020)、Zheng等人(2021b)、Zhou等人(2021)和Zhao等人(2021)改进现有基于GAN的方法,解决大尺度图像的补全问题。
1.3 视觉Transformer
Transformer(Vaswani等,2017)是自然语言处理任务中的主流模型,并取得了优秀的成果。Dosovitskiy等人(2021)提出ViT(vision transformer)网络,验证了纯Transformer架构对计算机视觉任务的可行性。然而,Transformer中的自注意力机制容易忽略局部特征信息,为了解决这个问题,DETR(detection transformer)(Carion等,2020)将CNN提取的局部特征作为Transformer编码器的输入,以串行的方式建模特征之间的全局关系,实现目标检测任务。与CNN不同的是,Transformer不存在优先考虑局部信息的归纳偏置,Esser等人(2021)提出将CNN归纳偏置的有效性和Transformer的表达能力相结合,以合成高分辨率图像。与现有工作不同,本文提出的虹膜补全网络,是一个双路并行的交互融合网络,这种方式同时保留CNN局部建模和Transformer全局建模的优势。
2 区域注意力机制引导的双路虹膜补全
如图2所示,本文提出的虹膜补全网络,由两部分组成:1)区域注意力机制引导的双路生成器,由两个编码器、融合层、残差块、区域注意力机制和解码器组成,用于对残缺图像进行补全;2)全局局部判别器,用于促使生成的虹膜图像符合数据集的分布。

图2 区域注意力机制引导的双路虹膜补全结构图
2.1 虹膜补全网络
2.1.1 区域注意力机制引导的双路生成器
生成器基于编码器—解码器结构,如图2所示,本文使用基于Transformer的编码器(如图3所示)提取全局特征,使用基于CNN的编码器提取局部特征,利用融合模块结合网络提取全局特征和局部特征。本文Transformer编码器参考了ViT(Dosovitskiy等,2021),其由多头注意力和多层感知机组成。正则化应用在多头注意力和多层感知机之前,并在多头注意力和多层感知机部分增加残差连接。多头注意力负责捕捉长距离的依赖关系,而多层感知机则用于进一步转化合并的特征,正则化用于非线性投影。Transformer编码器的输入为1维的符号嵌入(token embeddings)序列,本文将2维图像转换为32×32像素大小的序列块,作为Transformer编码器的输入,Transformer编码器可以提炼出序列块之间的长距离关系。

图3 Transformer编码器(L×表示多个重复编码器)
为了融合全局和局部特征,并保留各自的特点,本文提出了双边引导聚合模块融合来自两个分支的互补信息,消除全局和局部特征之间的语义鸿沟。本文借助融合模块对特征图进行交互融合,同时保留CNN局部建模和Transformer全局建模的优势, 增强视觉表示的能力。
为了使得网络有针对性地处理特征图的不同区域,更加关注遮挡区域的补全,本文引入区域注意力机制,让网络自适应地关注遮挡和非遮挡区域的生成。本文参考短长期注意力SLTA(short long term attention)(Zheng等,2019)、外部注意力EA(external attention)(Guo等,2021),针对虹膜补全任务,设计了区域注意力机制,如图4所示,使用两个不同存储单元(Guo等,2021)Mk、Mv作为键和值。

图4 区域注意力机制
给定特征图f2,如图2所示,首先计算注意力分数A,并使用归一化(Norm)对注意力进行归一化,即
(1)
进而产生自注意力特征(Zhang等,2019)c2,以及输出y2,即
(2)
y2=γ2(1-m)c2+mf2
(3)
式中,本文和SAGAN(self-attention GAN)(Zhang等,2019)一样,使用参数γ2平衡c2和f2之间的权重,参数γ2初始值为0,m是降采样的二值遮挡图像。
此外,产生长期层间注意力特征c1(Zheng等,2019;Yi等,2020)和输出y1,关注来自编码器层的特征f1(如图2所示)
c1=Af1
(4)
y1=γ1mc1+(1-m)f1
(5)
式中,使用参数γ1平衡c1和f1之间的权重,参数γ1初始值为0。与f2中包含用于生成完整图像的特征信息不同,f1只代表输出图像的非遮挡部分,因此本文使用m来约束两个不同的注意力输出,分别关注不同的部分,对于f2,关注其中对应输入图像的遮挡部分,对于f1,关注其中对应输入图像的非遮挡部分。
2.1.2 全局局部判别器
本文使用判别器(Zheng等,2019),从而与生成器进行对抗学习(Goodfellow等,2014),辅助生成器提高生成质量。具体来说,判别器与生成器相互博弈,生成器是为了能够生成可以欺骗判别器的逼真图像,判别器是为了判断生成器生成的图像为假,真实图像为真,两者互相对抗,互相促进。本文的判别器结构是基于Patch-GAN(Isola等,2017),Patch-GAN判别器的特点在于最后一层为卷积层,Patch-GAN判别器的输出为N×N的矩阵,N×N的矩阵中每个输出对应原图中的一个Patch。因此Patch-GAN判别器可以根据N×N的矩阵来评价整幅图像,所以本文选择Patch-GAN作为判别器,更好地利用局部图像的特征来评判整体图像的真假,使得网络更能关注图像细节。同时为了稳固训练过程,引入光谱归一化机制(Miyato等,2018),加入注意力(Zhang等,2019),获取特征图全局依赖,更好地判别结果的真实性。
2.2 损失函数
本文采用感知损失、风格损失、总变差损失、重构损失、对抗损失和身份损失来约束生成器生成图像的质量。
重构损失用于衡量图像之间像素级差异,最小化生成图像和原始图像之间的误差
(6)
式中,Io是网络补全之后的结果,Igt是原始图像。
感知损失是为了捕捉高层次的语义并模拟人类对图像的感知,使生成的图像更加符合人类的认知且更加逼真。本文提出使用感知损失(Johnson等,2016),通过使用在ImageNet数据集上(Russakovsky等,2015)预训练的网络提取虹膜特征图,以计算不同特征之间的差异,其计算为
(7)
式中,Φi是VGG-19(Visual Geometry Group)(Simonyan和Zisserman,2015)骨干网络第i层的激活图,Ni为第i层激活图的总数,在本文工作中,Φi对应于ReLU1_1、ReLU2_1、ReLU3_1、ReLU4_1和ReLU5_1的激活图。
风格损失是计算图像之间的风格差异,保持生成图像和原始图像之间的风格一致,风格损失计算为
(8)
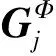
总变差损失(Johnson等,2016)用于抑制棋盘伪影的产生,使生成的图像具有空间连续性,定义为
(9)

全局局部对抗损失用于提高生成图像的真实性,分别对生成图像整体和修复遮挡区域计算对抗损失,对抗损失约束生成结果符合目标图片的分布,整体图像的全局对抗损失为
(10)
式中,N是批量大小,Dg是全局判别器,Gi是虹膜生成器,Im是输入的带遮挡的图像。同理,修复遮挡区域的局部对抗损失,crop为裁剪函数,Dl是局部判别器
(11)
身份损失指虹膜补全要求修复之后的虹膜图像和输入图像身份信息保持一致。本文基于虹膜识别网络,提出身份损失,用于约束补全网络修复之后的图像,在身份信息上与原图一致
(12)
式中,DI是DeepirisNet(Gangwar和Joshi,2016)虹膜识别网络,l代表识别网络的第l层,本文使用FC11(第11层全连接层)层。
整个网络的总损失函数为
Ltotal=λ1Lr+λ2Lp+λ3Ls+
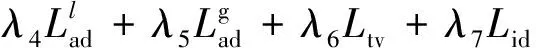
(13)
式中,λ1、λ2、λ3、λ4、λ5、λ6、λ7分别为重构损失、感知损失、风格损失、局部对抗损失、全局对抗损失、总变差损失和身份损失的权衡参数。
3 实 验
首先对数据集和实验细节进行介绍,随后在虹膜识别常用数据库CASIA上进行实验,证明本文方法的有效性。
3.1 数据集
本文使用中国科学院虹膜数据集第4版本中的灯光数据集(CASIA Iris Image Database V4 Lamp,CA4L)和千人数据集(CASIA Iris Image Database V4 Thousand,CA4T),如图5和图6所示,CA4L包括822个类别,由411个人的左右眼组成,同一个人的左右眼为不同类,一共16 212幅图像。CA4T包括2 000个类别,由1 000个人的左右眼组成,每个类有10幅虹膜图像,一共20 000幅图像,将CA4L、CA4T两个数据集进行合并,经过筛选之后,一共有2 738个类别,28 089幅虹膜图像用于本次实验。原始图像分辨率为640×480 像素,经过虹膜检测定位并裁剪为224×224像素,如图7所示,输入网络中的图像大小为160×160像素。

图5 CASIA虹膜数据集V4 Lamp
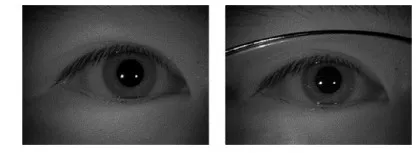
图6 CASIA虹膜数据集V4 Thousand

图7 裁剪之后虹膜图像
3.2 实验设置
实验使用的深度学习框架为Pytorch(Paszke等,2019),GPU为NVIDIA GeForce RTX3090。本文使用3通道图像,虽然实验使用的数据为灰度单通道图像,本文将其转换为3通道RGB图像,图像尺寸为160×160×3,进行网络训练时,本文使用宽、高为64×64像素矩形白块,进行随机遮挡。学习率为0.000 2,使用Adam(Kingma和Ba,2015)优化方法,用于生成器和判别器。


图8 不同损失函数权重实验结果
3.3 实验结果及分析
本文使用OSIRIS(open source iris recognition software)进行虹膜分割和虹膜识别的实验,测试不同遮挡大小图像补全结果的识别性能,证明所提方法的有效性。并以峰值信噪比(peak signl-to-nise ratio,PSNR)和结构相似度(structural similarity,SSIM)(Wang等,2004)作为评价指标,将本文方法与其他方法进行比较,例如,自注意力SA(self attention)(Zhang等,2019)、短长期注意力SLTA(Zheng等,2019)、外部注意力EA(Guo等,2021)。此外,进行不同模块的消融实验,验证Transformer编码器和区域注意力模块的有效性。
3.3.1 虹膜识别性能分析
为了验证本文方法在提高虹膜分割准确度方面的有效性,本文使用白色遮挡模拟光斑遮挡,如图9所示,通过对比图9(a)(b)和图9(a)(c),可以发现补全之后的图像分割结果相比于遮挡图像的分割结果更加准确,如图9(b)(c)所示,说明本文方法很好地缓解了光斑遮挡造成虹膜分割不准确的问题,有利于提高虹膜识别的性能。

图9 虹膜分割结果
为了验证本文方法对于提高遮挡图像补全结果识别性能的有效性,本文使用OSIRIS识别算法,对遮挡图像及遮挡图像补全之后的结果进行测试,ROC(receiver operating characteristic)曲线如图10所示,其中补全图像为遮挡大小为64×64像素的残缺图像修复之后的识别结果,遮挡图像为遮挡大小为64×64像素的残缺图像的识别结果,通过图10的ROC曲线,可以看出补全之后的虹膜图像的曲线始终高于遮挡虹膜图像的曲线,补全之后的虹膜图像的识别性能优于遮挡图像。匹配精度如表1所示,遮挡之后的是19.2%,补全之后的为63%,显著提高了43.8%,证明本文所提出的通过虹膜补全提升虹膜识别结果的可行性与有效性。

表1 识别性能对比

图10 识别性能ROC曲线
为了测试虹膜补全网络对于不同遮挡大小的修复情况,本文采用32×32像素、48×48像素、64×64像素大小的遮挡进行测试。图11展示了3种不同遮挡大小修复之后的图像,使用OSIRIS识别算法得出的ROC曲线,可以看出遮挡大小为64×64像素的ROC曲线一直低于32×32像素、48×48像素的ROC曲线。为了进一步对比实验结果,本文列出等错误率(equal error rate,EER)和匹配精度正确接受率(true accept rate,TAR),如表2所示,遮挡大小为64×64像素的匹配精度TAR低于32×32像素、48×48像素,说明遮挡大小为64×64像素时修复图像的识别效果低于32×32像素、48×48像素修复图像的识别效果,因为当遮挡块较小时,虹膜缺失的纹理信息较少,因此网络需要预测的纹理信息也较少,修复效果较好,识别性能得以提升,缺失信息过多时,补全难度较大,性能提升相对较小。证明本文所提出的双路虹膜补全网络对于遮挡越小的虹膜图像,补全效果越好,识别效果提升越高。
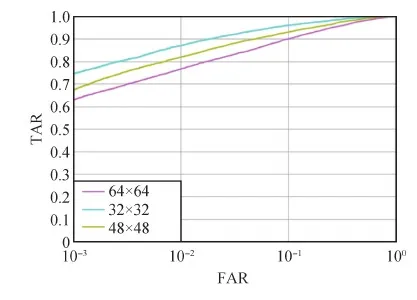
图11 不同遮挡尺寸识别ROC曲线
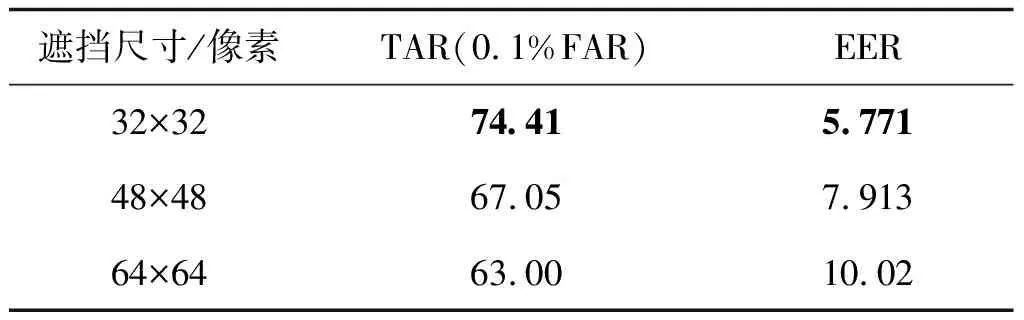
表2 不同遮挡大小识别性能
为了验证本文方法对遮挡位置的鲁棒性,本文以48×48像素大小的遮挡块为例,不同的遮挡位置如图12所示,本文使用OSIRIS识别算法对遮挡图像及其补全之后的图像进行测试,得出的ROC曲线如图13所示,从图13中可以看出不同位置的补全图像有相近的ROC曲线,且蓝色曲线和红色曲线几乎重合。EER和匹配精度TAR如表3所示,不同位置的补全图像的EER和匹配精度TAR相差不大,而且遮挡的虹膜区域(除瞳孔区域之外的遮挡区域)大小越相近,EER和匹配精度TAR的差异越小,可以看出本文方法对不同位置遮挡的虹膜图像有较好的修复效果。

图12 不同位置相同遮挡尺寸的虹膜图像
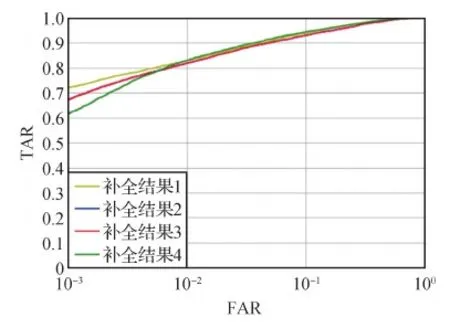
图13 相同大小遮挡在不同位置的识别ROC曲线
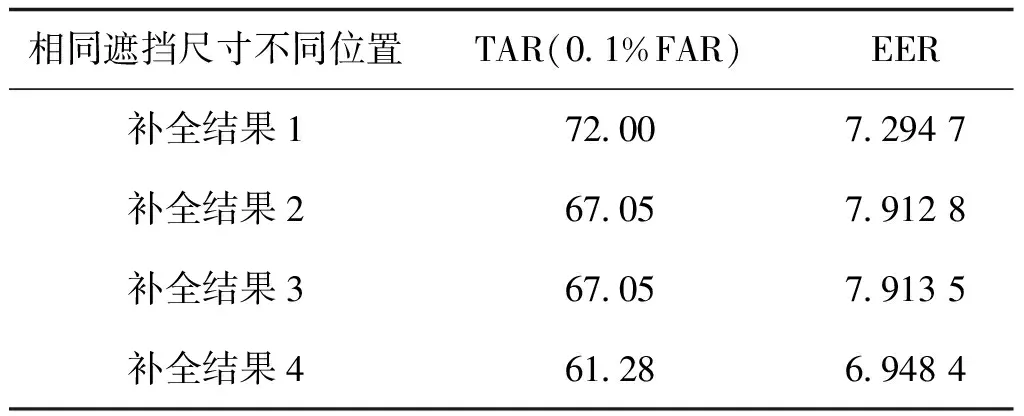
表3 不同遮挡位置虹膜图像
3.3.2 不同方法对比分析
1)定性分析。将本文方法与SA(Zhang等,2019)、SLTA(Zheng等,2019)、EA(Guo等,2021)3种方法进行定性比较,结果如图14所示,可以看出几种不同方法只有细微的差异,但本文方法取得了最优效果。与其他方法相比,本文方法的修复结果在区域保持性和整体一致性方面表现良好,这是因为本文方法针对图像补全任务的特点,并根据浅层特征和深层特征的差异,关注不同部位的特征,让网络有针对性地根据不同的特征图去生成遮挡图像的不同部分,比如非遮挡部分和遮挡部分,有利于网络针对性的生成不同区域,提高生成图像质量。

图14 在CASIA上视觉质量比较结果(64×64像素的随机遮挡)
2)定量分析。定量分析了本文方法的优越性,在PSNR和SSIM两个指标上进行定量比较,结果如表4所示,其中固定遮挡为使用64×64像素的白块固定遮挡图像的同一位置,32×32像素、48×48像素、64×64像素为对应大小的正方块对图像进行随机遮挡,如图15所示。与其他方法相比,对于不同遮挡类型的修复结果,本文方法的PSNR和SSIM均为最优,表明本文方法可以更好地修复遮挡的虹膜图像,保持修复结果与原图内容的一致性。
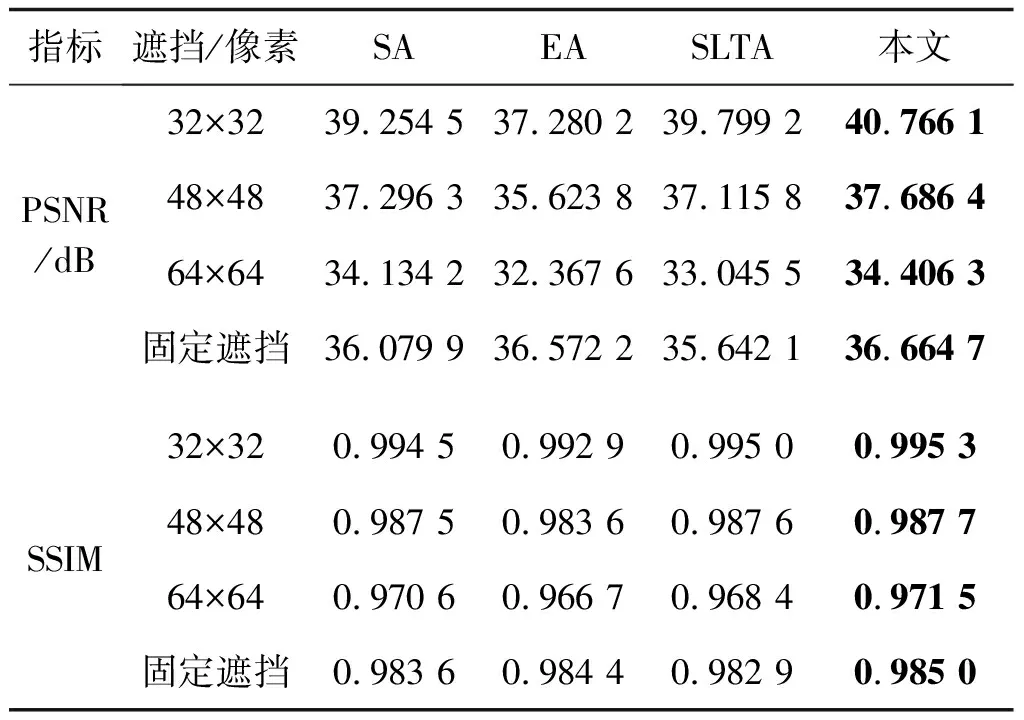
表4 不同注意力对比结果
图15 遮挡虹膜图像
3.3.3 消融实验
为了验证Transformer编码器和区域注意力模块的有效性,本文进行了消融实验,结果如表5所示,分析网络中各个部分对补全网络性能的影响,woT为不加Transformer编码器,woA为不加区域注意力。在网络中同时增加Transformer编码器和区域注意力,补全网络性能提升很明显,这种情况是因为Transformer编码器填补了CNN编码器全局建模能力不足的问题,证明了本文方法能有效结合Transformer全局建模能力和CNN局部建模能力,最大程度地保留了图像的局部特征和全局表示。区域注意力有针对性的作用,使得网络自适应地关注不同区域的生成。不同实验设置下测试结果的视觉质量如图16所示。
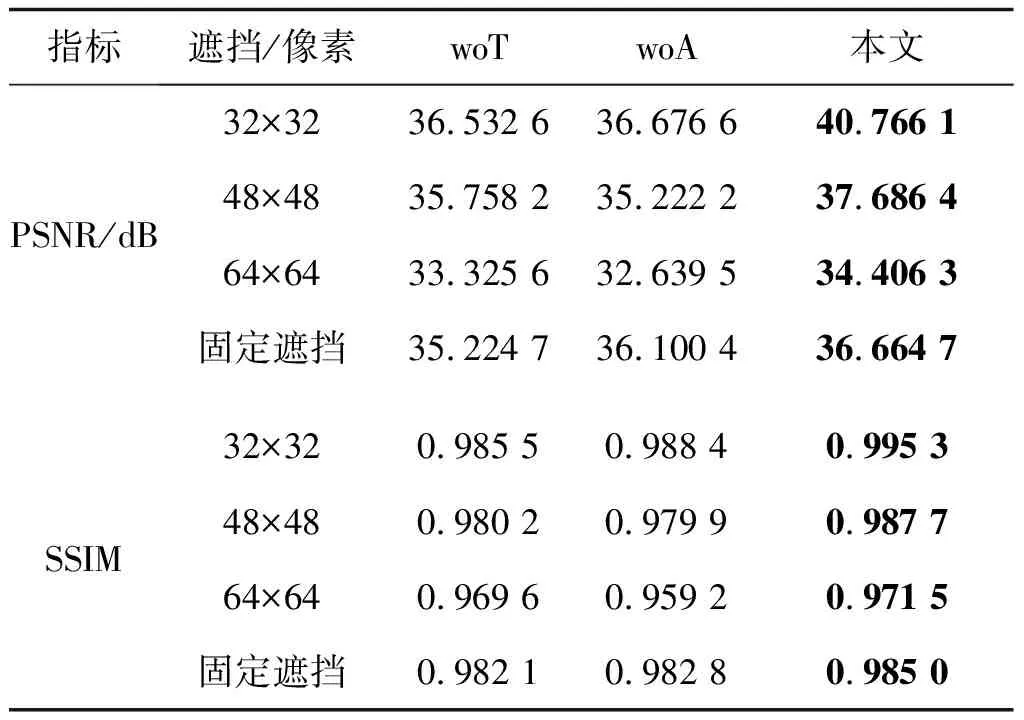
表5 不同实验配置对比结果
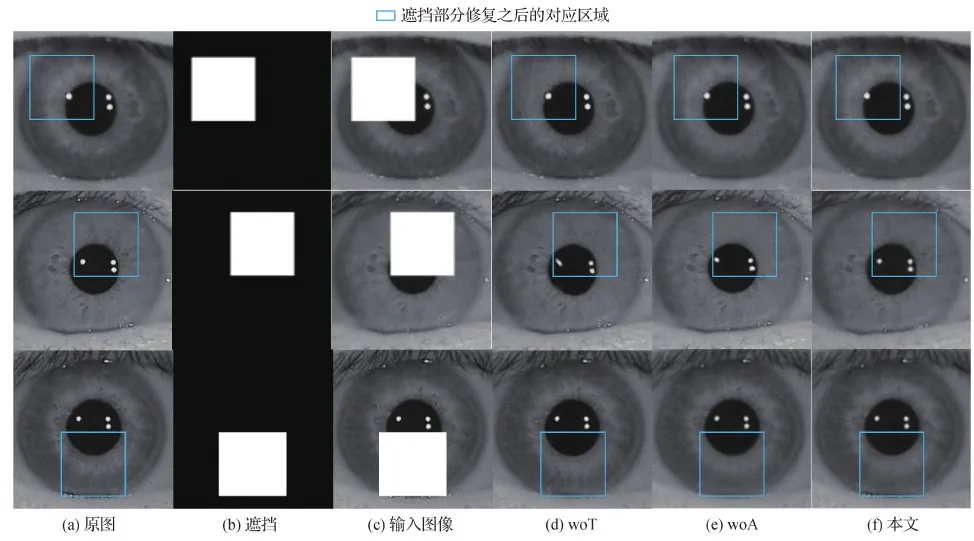
图16 消融实验结果(64×64像素的随机遮挡)
4 结 论
本文旨在解决虹膜遮挡导致虹膜信息缺失,影响虹膜分割准确性和虹膜识别准确性的问题,通过结合CNN和Transformer的互补特性,利用CNN编码器来提取局部特征,利用Transformer编码器来捕捉全局表示,并借助融合模块,对局部特征和全局表示进行交互融合,增强视觉表示的能力。并且针对虹膜补全的目的,提出区域注意力机制引导的双路虹膜补全网络,修复遮挡虹膜图像,并加入身份损失,保持补全结果的身份信息,提高虹膜分割、虹膜识别性能。从多个方面与其他方法进行了比较实验,验证了本文方法的可行性、有效性和真实性。
本文方法对于虹膜识别性能有显著提高,但是补全结果的识别性能和完整虹膜图像的识别性相比还有一定差距,这是因为本文方法较难重建虹膜纹理细节,因此解决虹膜纹理预测的问题,将是提高虹膜补全网络性能,生成视觉上真实、保持身份信息的虹膜图像的关键。在未来将进一步研究如何利用未遮挡的虹膜区域,尝试预测缺失区域的虹膜纹理信息,进而提高虹膜补全网络的性能。
参考文献(References)
Ballester C, Bertalmio M, Caselles V, Sapiro G and Verdera J.2001.Filling-in by joint interpolation of vector fields and gray levels.IEEE Transactions on Image Processing, 10(8): 1200-1211[DOI: 10.1109/83.935036]
Barnes C, Shechtman E, Finkelstein A and Goldman D B.2009.PatchMatch: a randomized correspondence algorithm for structural image editing.ACM Transactions on Graphics, 28(3): #24[DOI: 10.1145/1531326.1531330]
Bertalmio M, Sapiro G, Caselles V and Ballester C.2000.Image inpainting//Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques.New Orleans,USA: ACM: 417-424[DOI: 10.1145/344779.344972]
Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A and Zagoruyko S.2020.End-to-end object detection with transformers//Proceedings of the 16th European Conference on Computer Vision.Glasgow, UK: Springer: 213-229[DOI: 10.1007/978-3-030-58452-8_13]
Darabi S, Shechtman E, Barnes C, Goldman D B and Sen P.2012.Image melding: combining inconsistent images using patch-based synthesis.ACM Transactions on Graphics, 31(4): 1-10[DOI: 10.1145/2185520.2185578]
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X H, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, Uszkoreit J and Houlsby N.2021.An image is worth 16×16 words: transformers for image recognition at scale//Proceedings of the 9th International Conference on Learning Representations.virtual: OpenReview.net
Esedoglu S and Shen J H.2002.Digital inpainting based on the Mumford-Shah-Euler image model.European Journal of Applied Mathematics, 13(4): 353-370[DOI: 10.1017/s0956792502004904]
Esser P, Rombach R and Ommer B.2021.Taming transformers for high-resolution image synthesis//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Nashville, USA: IEEE: 12868-12878
Gangwar A and Joshi A.2016.DeepIrisNet: deep iris representation with applications in iris recognition and cross-sensor iris recognition//Proceedings of 2016 IEEE International Conference on Image Processing.Phoenix, USA: IEEE: 2301-2305[DOI: 10.1109/icip.2016.7532769]
Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A and Bengio Y.2014.Generative adversarial nets//Proceeding of the 27th International Conference on Neural Information Processing Systems.Montreal Canada: ACM: 2672-2680[DOI: 10.5555/2969033.2969125]
Guo M H, Liu Z N, Mu T J and Hu S M.2021.Beyond self-attention: external attention using two linear layers for visual tasks[EB/OL].[2021-05-31].https://arxiv.org/pdf/2105.02358.pdf
Huang J B, Kang S B, Ahuja N and Kopf J.2014.Image completion using planar structure guidance.ACM Transactions on Graphics, 33(4): #129[DOI: 10.1145/2601097.2601205]
Iizuka S, Simo-Serra E and Ishikawa H.2017.Globally and locally consistent image completion.ACM Transactions on Graphics, 36(4): #107[DOI: 10.1145/3072959.3073659]
Isola P, Zhu J Y, Zhou T H and Efros A A.2017.Image-to-image translation with conditional adversarial networks//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu, USA: IEEE: 5967-5976[DOI: 10.1109/cvpr.2017.632]
Johnson J, Alahi A and Li F F.2016.Perceptual losses for real-time style transfer and super-resolution//Proceedings of the 14th European Conference on Computer Vision.Amsterdam, the Netherlands: Springer: 694-711[DOI: 10.1007/978-3-319-46475-6_43]
Kingma D P and Ba J.2015.Adam: a method for stochastic optimization//Proceedings of the 3rd International Conference on Learning Representations.San Diego, USA: ICLR
Kingma D P and Welling M.2014.Auto-encoding variational Bayes//Proceedings of the 2nd International Conference on Learning Representations.Banff, Canada: ICLR
Li J Y, Wang N, Zhang L F, Du B and Tao D C.2020.Recurrent feature reasoning for image inpainting//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle, USA: IEEE: 7757-7765[DOI: 10.1109/cvpr42600.2020.00778]
Li Y J, Liu S F, Yang J M and Yang M H.2017.Generative face completion//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu, USA: IEEE: 5892-5900[DOI: 10.1109/CVPR.2017.624]
Liu H Y, Jiang B, Song Y B, Huang W and Yang C.2020.Rethinking image inpainting via a mutual encoder-decoder with feature equalizations//Proceedings of the 16th European Conference on Computer Vision.Glasgow, UK: Springer: 725-741[DOI: 10.1007/978-3-030-58536-5_43]
Liu K H, Wang X H, Xie Y T and Hu J Y.2021.Edge-guided GAN: a depth image inpainting approach guided by edge information.Journal of Image and Graphics, 26(1): 186-197(刘坤华, 王雪辉, 谢玉婷, 胡坚耀.2021.Edge-guided GAN: 边界信息引导的深度图像修复.中国图象图形学报, 26(1): 186-197)[DOI: 10.11834/jig.200509]
Miyato T, Kataoka T, Koyama M and Yoshida Y.2018.Spectral normalization for generative adversarial networks[EB/OL].[2021-11-22].https://arxiv.org/pdf/1802.05957.pdf
Navasardyan S and Ohanyan M.2020.Image inpainting with onion convolutions//Proceedings of the 15th Asian Conference on Computer Vision.Kyoto, Japan: Springer: 3-19[DOI: 10.1007/978-3-030-69532-3_1]
Nazeri K, Ng E, Joseph T, Qureshi F Z and Ebrahimi M.2019.EdgeConnect: structure guided image inpainting using edge prediction//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision Workshop.Seoul, Korea(South): IEEE: 3265-3274[DOI: 10.1109/ICCVW.2019.00408]
Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan C, Killeen T, Lin Z M, Gimelshein N, Antiga L, Desmaison A, Köpf A, Yang E Z, DeVito Z, Raison M, Tejani A, Chilamkurthy S, Steiner B, Fang L, Bai J J and Chintala S.2019.Pytorch: an imperative style, high-performance deep learning library//Proceedings of the 33rd International Conference on Neural Information Processing Systems.Vancouver, Canada: NeurIPS: 8026-8037[DOI: 10.5555/3454287.3455008]
Pathak D, Krähenbühl P, Donahue J, Darrell T and Efros A A.2016.Context encoders: feature learning by inpainting//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas, USA: IEEE: 2536-2544[DOI: 10.1109/cvpr.2016.278]
Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S A, Huang Z H, Karpathy A, Khosla A, Bernstein M, Berg A C and Li F F.2015.ImageNet large scale visual recognition challenge.International Journal of Computer Vision, 115(3): 211-252[DOI: 10.1007/s11263-015-0816-y]
Simonyan K and Zisserman A.2015.Very deep convolutional networks for large-scale image recognition//Proceedings of the 3rd International Conference on Learning Representations.San Diego, USA: ICLR
Song L S, Cao J, Song L X, Hu Y B and He R.2019.Geometry-aware face completion and editing//Proceedings of the 33rd AAAI Conference on Artificial Intelligence.Honolulu, USA: AAAI: 2506-2513[DOI: 10.1609/aaai.v33i01.33012506]
Sun J G, Yang Z W and Huang S.2020.Image inpainting model with consistent global and local attributes.Journal of Image and Graphics, 25(12): 2505-2516(孙劲光, 杨忠伟, 黄胜.2020.全局与局部属性一致的图像修复模型.中国图象图形学报, 25(12): 2505-2516)[DOI: 10.11834/jig.190681]
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, Kaiser L and Polosukhin I.2017.Attention is all you need//Proceedings of the 31st Conference on Neural Information Processing Systems.Long Beach, USA: NIPS: 6000-6010
Wang Z, Bovik A C, Sheikh H R and Simoncelli E P.2004.Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4): 600-612[DOI: 10.1109/tip.2003.819861]
Yi Z L, Tang Q, Azizi S, Jang D and Xu Z.2020.Contextual residual aggregation for ultra high-resolution image inpainting//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle, USA: IEEE: 7505-7514[DOI: 10.1109/cvpr42600.2020.00753]
Zhang H, Goodfellow I, Metaxas D and Odena A.2019.Self-attention generative adversarial networks//Proceedings of the 36th International Conference on Machine Learning.Long Beach, USA: ICML: 7354-7363
Zhao S Y, Cui J, Sheng Y L, Dong Y, Liang X, Chang E I C and Xu Y.2021.Large scale image completion via co-modulated generative adversarial networks[EB/OL].[2021-11-22].https://arxiv.org/pdf/2103.10428.pdf
Zheng C X, Cham T J and Cai J F.2019.Pluralistic image completion//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach, USA: IEEE: 1438-1447[DOI: 10.1109/cvpr.2019.00153]
Zheng S X, Lu J C, Zhao H S, Zhu X T, Luo Z K, Wang Y B, Fu Y W, Feng J F, Xiang T, Torr P H S and Zhang L.2021a.Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Virtual: IEEE: 6881-6890
Zheng C X, Cham T J, Cai J F and Phung D.2021b.Bridging global context interactions for high-fidelity image completion[EB/OL].[2021-11-22].https://arxiv.org/pdf/2104.00845.pdf
Zhou Y Q, Barnes C, Shechtman E and Amirghodsi S.2021.TransFill: reference-guided image inpainting by merging multiple color and spatial transformations//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Virtual: IEEE: 2266-2276[DOI: 10.1109/CVPR46437.2021.00230]
