融合3D注意力和Transformer的图像去雨网络
2022-05-23王美华柯凡晖梁云范衠廖磊
王美华,柯凡晖,梁云,范衠,廖磊
1.华南农业大学数学与信息学院, 广州 510642;2.汕头大学工学院, 汕头 515063
0 引 言
雨天会对摄影设备成像质量造成极大影响。单幅图像去雨算法的目标是:输入一幅有雨图像,得到对应图像的去雨结果,图像去雨任务能够有效提高图像质量并增加计算机视觉算法的适应性(Yang等,2019)。
早期图像去雨算法大多基于图像先验信息完成去雨任务,其将图像分为背景和雨层,把图像去雨任务转化为图层分解任务。使用字典学习、稀疏编码(Li等,2012;Luo等,2015)或高斯混合网络(Li等,2016)学习分解图像,以解决图像去雨任务这一复杂优化问题。然而,手工设计特征不足以获取足够的图像统计学信息,常常导致去雨效果不理想。
深度学习在一系列图像分类(Rawat和Wang,2017)、目标检测(Liu等,2020)和图像分割(Lateef和Ruichek,2019)等计算机视觉任务中大放异彩。许多基于深度学习的图像去雨工作取得了不错的效果。例如,基于先验信息引导的图像去雨网络(Fu等,2017a;Zhang等,2018;Yasarla和Patel,2019)、粗糙到精细的去雨网络(Ren等,2019)、多任务学习去雨网络(Yang等,2016)和基于注意力引导的去雨网络(Wang等,2020,2021)。
基于深度学习的图像去雨网络虽取得了不错的去雨效果,但仍在某些图像上存在着去雨不充分或过度去雨的问题。现有算法在某些去雨后的图像中依旧残留着雨纹;或在去雨过程中抹除了物体边缘信息。现有基于深度学习的去雨网络多是使用卷积操作进行图像去雨。然而,卷积操作不适合建模全局特征依赖,当图像全局信息对去雨过程十分重要时,网络将无法很好地完成去雨任务。图像中低频区域可能出现雨纹残留;或无法区分雨纹与高频信息,导致物体边缘存在涂抹痕迹或雨纹去除不成功。
Transformer注意力机制首次出现于机器翻译任务(Vaswani等,2017),其将一个序列作为输入,使用神经元计算序列中每一个元素与其余元素的特征依赖,这种设计赋予了它强大的特征长期依赖建模能力。基于卷积神经网络(convolutional neural networks,CNN)的去雨方法并不擅长建模特征长距离依赖,因此本文将Transformer与编码器—解码器结构应用于去雨任务中,以更好地减少去雨涂抹痕迹和恢复图像高频细节。
本文针对单幅图像去雨任务提出TDATDN(three-dimension attention and Transformer deraining network)网络,在一定网络空间内寻求更好的网络表达方式。将三维注意力和Transformer机制引入图像去雨领域,并将U型编码器—解码器网络与Transformer结合,以解决引入Transformer机制导致的特征分辨率损失问题。TDATDN具有以下特点:1)使用编码器提取图像特征;2)使用Transformer机制在高层语义空间内获取全局内容编码;3)使用解码器结构对Transformer获取的自注意力特征编码完成上采样操作;4)使用Skip-Connection融合编码器与解码器对应路径特征。
1 相关工作
1.1 单幅图像去雨
1.1.1 传统单幅图像去雨
传统的单幅图像去雨算法将有雨图像视为背景层与雨层的叠加图像。基于此假设,图像去雨工作可认为是背景层和雨层的分离任务。Kang等人(2012)使用滤波器提取图像高频信息,并使用字典学习和稀疏编码将图像高频成分中的雨分量和非雨分量分离,从而获得去雨图像。Luo等人(2015)通过学习强互斥性学习字典,使用高可辨性稀疏编码准确分离背景层和雨层。Li等人(2016)使用高斯混合网络分离背景层和雨层,以适应多方向和不同规模的雨纹。马龙等人(2018)使用最大后验估计建立能量模型,将其与高斯混合模型结合进行去雨。由于背景层和雨层存在复杂的结合关系,传统单幅图像去雨算法难以取得令人满意的结果。
1.1.2 基于深度学习的单幅图像去雨
Fu等人(2017a)将深度学习与图像去雨结合,在图像高频域内定义有雨图像到去雨图像的转换网络,相比传统去雨算法,显著提升了去雨性能。Fu等人(2017b)将卷积神经网络和传统图像处理技术结合去雨,以改进视觉效果。但这些粗糙的雨分离算法易导致部分图像高频成分被抹除。Yang等人(2017)提出去雨多任务学习网络,同时学习获取雨掩膜图、雨线图和去雨图像。针对雨线密度不均问题,Zhang等人(2018)提出预测雨密度标签引导图像去雨,但其需要额外训练标记数据,限制训练通用性。一些学者将有雨图像中雨线层定义为多个雨层的堆叠,提出对图像递归式去雨,或以多阶段方式图像去雨。Li等人(2018)将深度卷积和循环神经网络结合,使用通道注意力对雨线特征层分配不同的权重值。Ren等人(2019)提出一种递归式ResNet网络,引入循环层对有雨图像递归式去雨。王美华等人(2020)提出结合选择卷积网络和雨线修正系数的自适应卷积残差修正网络进行去雨。传统去雨算法和部分基于深度学习的去雨算法对图像的去雨操作仅使用浅层特征进行处理,而没有理解图像。
基于编码器—解码器的网络架构将图像内容逐级抽象至高层语义空间,可以更好地理解图像内容,而不仅使用图像浅层特征。一些学者将编码器—解码器架构用于图像去雨中。Guo等人(2019)提出深度自注意力金字塔网络,将自注意力和多尺度池化模块结合编码器—解码器学习不同雨线信息。Yasarla和Patel(2019)考虑雨位置信息,提出不确定性引导的多尺度残差学习网络,但其训练复杂,处理时间长。部分研究者将注意力机制引入图像去雨。Wang等人(2020)提出注意力机制引导的三阶段编码器—解码器去雨网络,并使用预测损失图辅助训练。Wang等人(2021)在编码器—解码器引入注意力精细化模块用于引导图像精细化去雨。但这些基于编码器—解码器的去雨网络大多设计复杂,显著增加了处理时间。
1.2 注意力机制
注意力机制在人类视觉感知系统中扮演了一个重要角色。人类视觉系统的一个重要特点是:不会一次性处理一幅图像的整个场景,而是简单快速浏览图像并选择性地关注某些显著区域以获取更好的视觉结构信息(Itti等,1998)。
1.2.1 传统注意力机制
Wang等人(2017)提出残差注意力网络,其提出的注意力网络由多层注意力模块堆叠而成,每个注意力模块包含主干分支和掩膜分支,两个分支特征使用点乘操作特征融合。Hu等人(2020)提出通道注意力(squeeze-and-excitation network,SE)模块,从通道角度计算特征的关联性,以自适应计算不同特征通道响应性。Woo等人(2018)提出卷积块注意力模块(convolutional block attention module,CBAM),CBAM模块将通道注意力和空间注意力级联,分别从通道维度和空间维度生成注意力图。
1.2.2 Transformer注意力机制
Transformer注意力机制首次提出于机器翻译领域(Vaswani等,2017),得益于强大的全局信息建模能力,其在许多自然语言处理任务中取得了最优结果。在计算机视觉领域,研究人员对Transformer变体进行研究。Parmar等人(2018)将其应用于图像生成领域,通过限制Transformer注意力机制关注图像局部领域,显著地增加了网络可处理的图像尺度。Child等人(2019)提出Sparse Transformer,其在注意力矩阵中使用稀疏分解技术,大大增强了Transformer注意力机制对深层网络和长序列数据的全局建模能力。Dosovitskiy等人(2021)使用纯Transformer网络对分块后的输入图像处理,极大加强网络对全局信息的提取能力。本文将Transformer注意力机制与编码器—解码器结构结合,以增强网络全局信息建模能力。
2 网络结构
提出基于编码器—解码器架构的TDATDN去雨网络,将3维注意力与残差密集块结合,构建编码器—解码器架构去雨网络,其将输入图像编码至高级语义特征空间,在高层语义特征空间内利用Transformer注意力机制计算特征全局关联性,然后解码器逐级恢复至原图分辨率,得到去雨图像。
2.1 整体网络架构
本文整体网络架构见图1,整体网络为基于U-Net的编码器—解码器架构(Ronneberger等,2015)。在编码器—解码器部分,使用卷积进行下采样操作,采用反卷积作为上采样操作。使用Skip-Connection融合编码器和解码器路径特征,对应层级特征图矩阵相加,并使用3×3卷积操作融合特征。激活函数为Leaky ReLU激活函数(其中,水平负半轴的斜率设置为0.1),输出层直接使用3×3卷积获取最终去雨结果,不额外使用激活函数。其中,编码器路径第1、2、3、4个全局残差密集块输入特征通道数分别为32、64、64、128;解码器路径第1、2、3个全局残差密集块和最后3×3卷积输入特征通道数分别为128、64、64、32。

图1 3维注意力和Transformer去雨网络架构
2.2 残差密集块
为了增强网络对于不同雨线位置、方向和差异的去雨能力,受到RDB(residual dense block)(Zhang等,2018)工作的启发,提出TARDB(three-dimension attention residual dense block)作为本文的网络基本单元。Residual(He等,2016)的加入可有效缓解梯度消失问题;Dense机制(Huang等,2017)对网络中不同层级特征融合;3维注意力机制(three-dimension attention module, 3DAM)(Yang等,2021)可通过优化能量函数获取每个神经元重要性,且计算过程中无需额外参数存储。
2.2.1 三维注意力局部残差密集块
传统视觉注意力模块通过输入特征图产生对应注意力权重。传统注意力模块一般可以分为两类:基于1维通道方向的通道注意力(Hu等,2020);基于2维空间的空间注意力(Woo等,2018)。相比1维通道注意力或2维空间注意力机制,3维注意力可获取精细的注意力权重图,更好地引导网络去雨任务。本文将3维注意力机制(3DAM)与残差密集块结合,提出3维注意力局部残差密集块,其包括密集连接层和3维注意力特征融合层。3维注意力局部残差密集块结构见图2。
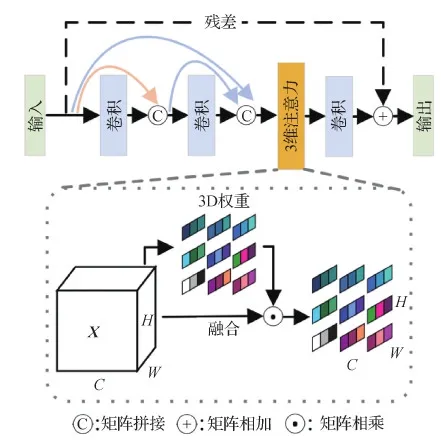
图2 3维注意力局部残差块图
1)密集连接层。为了增加信息在特征图之间的流动性,采用类似DenseNet网络(Huang等,2017)的策略,每一个卷积层将会与先前每一层进行通道方向拼接,然后使用卷积操作特征融合,后接激活函数。定义Xi为第i个卷积层产生的特征图,X0为当前局部残差密集块输入。则第i个卷积层产生的特征图输出为
Xi=σ(Wi[X0,X1,…,Xi-1])
(1)
式中,σ为Leaky ReLU激活函数,Wi为第i个卷积层权重,[·]为将特征图从通道方向拼接特征。
2)3维注意力特征融合层。将密集连接层获取的特征按照通道方向拼接,然后使用3DAM获取注意力图,并将注意力图与之相乘,后接1×1卷积完成特征融合和通道压缩。同时,增加残差连接进一步增强信息流动。3维注意力特征融合层最终输出为
Xout=W1×1(φ([X0,X1,…,Xi-1,Xi]))+X0
(2)
式中,Xout为最终输出的特征图,W1×1为特征融合的1×1卷积,φ(·)为3DAM注意力机制计算,其计算为
(3)
式中,[·]为特征拼接操作,X为输入特征图,φ(·)为3维注意力机制计算公式,ψ(·)为Sigmoid激活函数,ν(·)为按照各通道内计算特征图和,μ为输入特征图X按照各通道内计算的特征图平均值,w和h是输入特征图X的宽和高,λ为超参数,⊙为矩阵点乘操作。
2.2.2 全局残差密集块
全局残差密集块由3维注意力局部残差密集块作为基础卷积层,并使用密集连接和残差学习机制提升网络性能。其结构如图3。计算式为
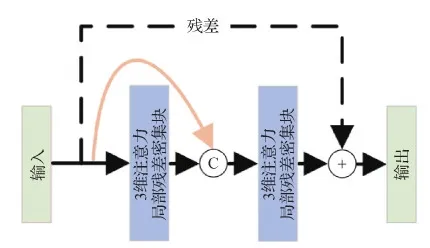
图3 全局残差块图
Yout=W1×1([Y0,…,Yi])+Y0
(4)
式中,Yout为最终输出特征图,W1×1为特征融合的1×1卷积,Yi为第i个3维注意力局部残差密集块产生的特征图,[·]为特征拼接操作。
2.3 Middle Layer层
参考Dosovitskiy等人(2021),将输入到Transformer层的特征矩阵进行令牌化,重新调整输入矩阵维度变为2D特征块{Xi∈RP2×C|i=1,…,N},每一个块的大小为P×P,C为特征图通道数。变换之后特征总块数为N=HW/P2,其中,H和W分别为特征图的高和宽。
2.3.1 Patch Embedding操作
使用神经网络将向量化的2D 特征块映射进线性空间。为了将2D 特征块进行空间位置信息编码,将额外学习位置嵌入信息矩阵,其将与2D 特征块相加,计算为
(5)
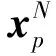
2.3.2 Transformer层
Transformer中间层由多层Transformer级联而成。单个Transformer层包括多头自注意力机制(Vaswani等,2017)和多层感知器前向神经网络。其结构见图4。第i层Transformer层输出为
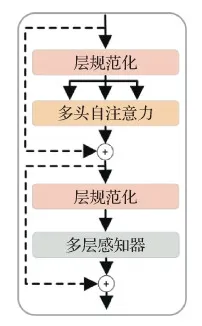
图4 Transformer结构图
z′i=τ(φ(zi-1))+zi-1
zi=ψ(φ(z′i))+z′i
(6)
式中,zi-1为Transformer层输入特征,τ(·)为多头自注意力(multi-head self-attention,MSA)机制计算,具体见式(7),ψ(·)为多层感知器(multi-layer perceptron,MLP)神经网络,具体见式(8),φ(·)为层规范化操作。
τ(Q,K,V)=WO[h1,…,hi]

(7)
式中,Q、K和V分别为自注意力的query矩阵、key矩阵和value矩阵,Qi、Ki和Vi分别为多头自注意力第i头自注意力的query矩阵、key矩阵和value矩阵,WO为神经网络权重,hi为第i头特征图,d为多头注意力中每头特征维度。
ψ(x)=ω(0,xW1+b1)W2+b2
(8)
式中,ω(·)为ReLU激活函数,W1和W2为感知器权重,b1和b2为感知器偏置。
2.4 损失函数
本文损失函数融合了多尺度重构损失、多尺度结构相似度损失和感知损失。网络训练过程更加稳定,可在训练过程中抑制梯度消失和梯度爆炸,加速网络收敛和提升网络去雨效果。
1)多尺度重构损失。为了准确恢复图像细节和捕获不同尺度特征上下文信息,使用L2范数建立多尺度重构损失(Wang等,2021),计算为
(9)

2)多尺度结构相似度损失。L2范数收敛速度快,但训练过程不稳定,训练过程中易受到数据离群值影响。即使训练去雨图像与清晰图像计算峰值信噪比可能较高,但是图像部分区域结构仍可能受到破坏。因此,引入结构相似度损失(Ren等,2019),提出多尺度结构相似度损失函数,以抑制数据离群值影响并加强去雨图像视觉效果。多尺度结构性相似度损失计算为
(10)
式中,ϖ(·)为结构相似度计算操作。
3)感知损失。参考Wang等人(2021)的去雨工作,添加感知损失以获取更好的去雨图像视觉质量。使用的感知损失计算为
(11)
式中,ρ(·)为VGG(Visual Geometry Group)16卷积特征提取器。
网络总损失函数计算为
LT=LL+LS+αLP
(12)
3 实验与结果分析
3.1 实验细节
本文提出的图像去雨网络使用合成雨线数据进行网络效果训练和测试,与CNN(convolutional neural network)(Fu等,2017a)、RESCAN(recurrent se context aggregation network)(Li等,2018)、PReNet(progressive recurrent network)(Ren等,2019)和AFR-Net(attentive feature refinement network)(Wang等,2021)等网络进行效果对比。
3.1.1 数据集和评估矩阵
图像去雨数据集为合成雨线数据集,首次在Zhang和Patel(2018)的工作中提出。包括低、中和高3种不同级别雨线密度合成有雨图像对,包含12 000对训练图像和1 200对测试图像。采用峰值信噪比(peak signal to noise ratio, PSNR)和结构相似性(structural similarity, SSIM)(Wang等,2004)作为矩阵评估方法。
3.1.2 实验相关设置
合成雨线数据集图像缩放至256×256像素。网络总训练周期数为100次,网络每迭代15次学习率将乘以0.5,不使用额外数据增强策略。网络参数采用Uniform初始化方法,Adam优化器训练网络,Adam参数设置为:β1=0.9,β2=0.999,ε=1×10-8,初始学习率为1×10-4。为了控制不同尺度对网络训练影响,参考Wang等人(2021)方法,式(9)和式(10)中λ0、λ1、λ2和λ3参数分别设置为1.0、0.8、0.6和0.4。式(12)中,感知损失权重α设置为0.1。
运行环境为:Windows 10,Python 3.7,Pytorch 1.6,CPU:Inter(R)Core(TM)I7-7820X,GPU:NVIDIA TITAN Xp,RAM:32 GB。
3.2 消融实验
3.2.1 损失函数与3维注意力
1)损失函数。绝对值(Fu等,2018)、均方差(Fu等,2017a)和结构相似性(Wang等,2004)等损失函数常用于去雨网络训练。结构相似性损失函数考虑了图像亮度、对比度和结构相似程度,更符合人类视觉特性。本文将结构性损失函数与其他常用去雨损失函数结合,并设计实验探究其有效性。首先使用多尺度均方差损失函数和感知损失函数作为baseline,并引入结构性损失函数。实验结果见表1。

表1 损失函数和3维注意力消融实验
2)3维注意力。3DAM(Yang等,2021)通过优化能量函数计算每个神经元重要性,直接产生3维注意力权重,且无需存储注意力权重。在验证损失函数有效性后,本文使用所提出的损失函数训练加入3DAM的去雨网络,以测试3DAM在去雨任务中的有效性。
不同损失函数和加入3DAM训练得到的网络去雨效果见图5。可以看出,使用多尺度均方差和感知损失函数具有一定的去雨效果,但图像中部分区域存在着去雨涂抹痕迹或部分雨线并未被成功去除(图5(c));加入单尺度结构相似性损失函数时,去雨效果得到加强,图像中大部分涂抹痕迹已被消除(图5(d)),例如图像中上层混凝土围栏和地面立柱顶部三角形区域附近的白色伪影;使用多尺度均方差、多尺度结构相似性损失函数和感知损失相结合方式网络训练时(图5(e)),相对单尺度结构相似性损失,公交车车窗区域获得了画面更纯净的去雨结果,地面立柱顶部三角形区域伪影进一步被消除;加入多尺度结构相似性损失函数和3维注意力训练得到的去雨结果见图5(f),图中更好地还原了上层混凝土围栏边缘细节,地面立柱三角形区域附近颜色过渡更自然。

图5 不同损失函数和模块消融实验去雨效果对比
实验表明,多尺度结构相似性损失在图像获得更好视觉观感的同时减少了局部区域伪影的出现。多尺度均方差、多尺度结构性损失和感知损失相结合的损失函数在网络结构相同情况下取得网络最优结果。本文最终选择此函数作为所提出TDATDN网络训练损失函数。
通过3DAM和密集块结构相结合,输入特征图计算3DAM权重,促使网络加强对去雨不完全区域处理,更好地恢复物体边缘纹理,本文将该机制加入TDATDN网络中进一步提升网络去雨性能。
3.2.2 Transformer层数的选择
Transformer主要应用于序列预测任务,其全局自注意力机制适合建模特征长期依赖,但其不擅长用于处理低层次特征位置信息。本文将Transformer模块和U-Net网络结合,加入3DAM组成TDATDN网络,用于单幅图像去雨任务。使用Transformer计算卷积编码器得到的高维图像特征块以提取全局语义信息,然后使用解码器逐步恢复图像到原始输入图像分辨率。使用Transformer的全局注意力机制计算特征内在关联,弥补了卷积只能对小范围特征依赖建模的缺点。
本文Transformer模块为可级联设计,为达到最佳去雨效果,本文提出设计不同数量的级联Transformer层以测试网络效果。不同Transformer层数训练得到的网络去雨效果见图5。加入Transformer模块使网络具有计算全局特征关联能力,弥补传统卷积操作只能计算小区域特征关联的缺点,减少网络过度去雨和去雨不足现象。当Transformer层数为1时(即T1),图像去雨效果见图5(g),相对于没有添加Transformer层的网络,公交车车窗玻璃去雨后颜色过渡更加自然,地面立柱顶端三角形区域附近的去雨伪影面积进一步减少。根据表2实验结果,级联多个Transformer模块可获得更好的去雨性能。当Transformer级联层数为3时,PSNR和SSIM评估指标有轻微的下降,在权衡运行速度和去雨效果之后,本文最终选择Transformer级联层数为2。多头注意力头数设置为16,中间层维度设置为256。

表2 不同数量Transformer层在TDATDN网络的去雨效果
3.3 与其他去雨算法对比
3.3.1 合成有雨图像实验结果
所有网络使用相似训练参数重新训练。从实验结果表3看出,CNN算法的PSNR值和SSIM值最低,其算法去雨性能有待提升;PReNet去雨网络对比RESCAN算法SSIM有所提升,但PSNR略有降低;本文提出的TDATDN去雨算法对比以往单幅图像去雨算法均有明显性能提升,其中PSNR和SSIM对比AFR-Net网络分别提升了0.67和0.010 3,取得了更好的去雨效果。

表3 不同去雨算法在Rain12000数据集的去雨效果
除了使用PSNR和SSIM评价指标对比,将现有主流单幅图像去雨算法和本文TDATDN算法进行去雨效果图像对比。对比展示见图6,从结果上看出,CNN算法去雨效果并不理想,整幅图像残留着大量雨线;RESCAN算法虽取得不错的去雨效果,但整体图像依然遗留了部分雨雾;PReNet和AFR-Net去雨算法取得较好效果,但原本蓝色的天空部分出现了白色去雨涂抹痕迹;本文算法对比PReNet和RESCAN去雨算法,极大降低了天空部分白色涂抹痕迹,对于图像高频信息取得较好的恢复效果。

图6 不同算法的去雨效果对比
从去雨效果细节图(图7)中看出,RESCAN和PReNet算法在砖墙处虽然去除了雨线,但红砖边缘已经被抹除;AFR-Net虽保留了边缘信息,但有部分雨纹没有成功去除;本文提出的TDATDN对比RESCAN、PReNet和AFR-Net在地面纹理处和广告牌字母边缘都获得更好的去雨效果,保留了边缘信息,并极大地减少了去雨算法造成的伪影和涂抹痕迹。

图7 不同算法的去雨效果细节对比
3.3.2 真实世界有雨图像实验结果
本文在真实世界有雨图像上进行去雨效果对比,以验证TDATDN网络去雨性能。因真实世界有雨图像无对应去雨标签图,本文将去雨图像进行视觉效果对比。对于部分真实世界场景,PReNet、AFR-Net和本文TDATDN算法都能取得不错的去雨效果(如图8第1行图像);但在某些复杂场景下,如图8第2行图像,对于汽车轮胎和行人衣服上的雨线,PReNet和AFR-Net去雨效果并不明显,但本文提出的TDATDN去雨算法仍可有效地完成去雨任务,在保留物体纹理信息的同时,较好地去除了复杂位置和物体边缘处雨线。

图8 不同算法的真实世界去雨效果细节对比
3.3.3 与其他算法运行时间对比
运行时间是评估去雨算法性能的重要指标,过长运行时间将使算法难以在实际计算机任务中应用。本文将不同去雨算法运行时间进行对比。具体做法为,将每个算法分别在尺寸为256×256像素和512×512像素的有雨图像上完成去雨时间计算,每个用于测试去雨时间的数据集包含200幅有雨图像,求每个数据集单幅图像的平均运行时间作为最终去雨运行时间对比。得到的不同去雨算法运行时间见表4。对比去雨时间相近的PReNet网络,本文可得到更好的去雨性能;对比现有去雨性能较优的AFR-Net网络,本文算法可在去雨性能提升的同时减少运行时间。TDATDN算法在去雨性能和运行效率之间取得良好均衡,具有一定实用性。
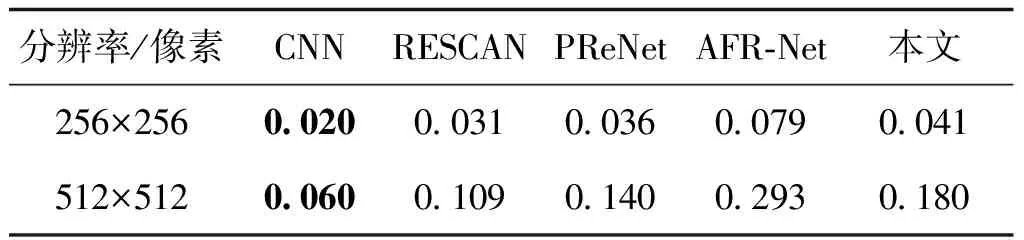
表4 不同去雨算法运行时间对比
4 结 论
针对现有单幅图像去雨网络去雨不完全或过度去雨问题,提出了TDATDN单幅图像去雨算法。将3维注意力与密集块结合解决高维度特征融合问题,使用残差密集块构建基于U-Net的图像去雨网络,并使用Transformer机制计算网络深层语义信息全局上下文关联性,同时将多尺度结构相似性与常用去雨损失函数结合参与网络训练。所提出的TDATDN单幅图像去雨网络结合了3维注意力机制、Transformer和编码器—解码器架构优点,实验结果证明了本文算法的有效性。提出的单幅图像去雨算法并未对Transformer内部结构进行精简化,这导致本文算法现在无法很好地应用在实时视频去雨领域。今后研究可以对Transformer结构进行精简,在保证去雨效果的同时更好地提升视频去雨效率。
参考文献(References)
Child R, Gray S, Radford A and Sutskever I.2019.Generating long sequences with sparse transformers[EB/OL].[2021-08-13].https://arxiv.org/pdf/1904.10509.pdf
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X H, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, Uszkoreit J and Houlsby N.2021.An image is worth 16×16 words: transformers for image recognition at scale[EB/OL].[2021-08-13].https://arxiv.org/pdf/2010.11929.pdf
Fu X Y, Huang J B, Ding X H, Liao Y H and Paisley J.2017a.Clearing the skies: a deep network architecture for single-image rain removal.IEEE Transactions on Image Processing, 26(6): 2944-2956[DOI: 10.1109/TIP.2017.2691802]
Fu X Y, Huang J B, Zeng D L, Huang Y, Ding X H and Paisley J.2017b.Removing rain from single images via a deep detail network//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu, USA: IEEE: 1715-1723[DOI: 10.1109/CVPR.2017.186]
Fu X Y, Liang B R, Huang Y, Ding X H and Paisley J.2018.Lightweight pyramid networks for image deraining[EB/OL].[2021-08-13].https://arxiv.org/pdf/1805.06173.pdf
Guo T A, Dai T, Li J W and Xia S T.2019.Self-attentive pyramid network for single image de-raining//Proceedings of the 26th International Conference on Neural Information Processing.Sydney, Australia: Springer: 390-401[DOI: 10.1007/978-3-030-36708-4_32]
He K M, Zhang X Y, Ren S Q and Sun J.2016.Deep residual learning for image recognition//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vega, USA: IEEE: 770-778[DOI: 10.1109/CVPR.2016.90]
Hu J, Shen L, Albanie S, Sun G and Wu E H.2020.Squeeze-and-excitation networks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(8): 2011-2023[DOI: 10.1109/TPAMI.2019.2913372]
Huang G, Liu Z, Van Der Maaten L and Weinberger K Q.2017.Densely connected convolutional networks//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu, USA: IEEE: 2261-2269[DOI: 10.1109/CVPR.2017.243]
Itti L, Koch C and Niebur E.1998.A model of saliency-based visual attention for rapid scene analysis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(11): 1254-1259[DOI: 10.1109/34.730558]
Kang L W, Lin C W and Fu Y H.2012.Automatic single-image-based rain streaks removal via image decomposition.IEEE Transactions on Image Processing, 21(4): 1742-1755[DOI: 10.1109/TIP.2011.2179057]
Lateef F and Ruichek Y.2019.Survey on semantic segmentation using deep learning techniques.Neurocomputing, 338: 321-348[DOI: 10.1016/j.neucom.2019.02.003]
Li X, Wu J L, Lin Z C, Liu H and Zha H B.2018.Recurrent squeeze-and-excitation context aggregation net for single image deraining//Proceedings of the 15th European Conference on Computer Vision.Munich, Germany: Springer: 262-277[DOI: 10.1007/978-3-030-01234-2_16]
Li Y, Tan R T, Guo X J, Lu J B and Brown M S.2016.Rain streak removal using layer priors//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas, USA: IEEE: 2736-2744[DOI: 10.1109/CVPR.2016.299]
Liu L, Ouyang W L, Wang X G, Fieguth P, Chen J, Liu X W and Pietikäinen M.2020.Deep learning for generic object detection: a survey.International Journal of Computer Vision, 128(2): 261-318[DOI: 10.1007/s11263-019-01247-4]
Li W K, Chia W L and Yu H F.2012.Automatic single-image-based rain streaks removal via image decomposition.IEEE Transactions on Image Processing, 21(4): 1742-1755[DOI: 10.1109/TIP.2011.2179057]
Luo Y, Xu Y and Ji H.2015.Removing rain from a single image via discriminative sparse coding//Proceedings of 2015 IEEE International Conference on Computer Vision.Santiago, Chile: IEEE: 3397-3405[DOI: 10.1109/ICCV.2015.388]
Ma L, Liu R S, Jiang Z Y, Wang Y Y, Fan X and Li H J.2018.Rain streak removal using learnable hybrid MAP network.Journal of Image and Graphics, 23(2): 277-285(马龙, 刘日升, 姜智颖, 王怡洋, 樊鑫, 李豪杰.2018.自然场景图像去雨的可学习混合MAP网络.中国图象图形学报, 23(2): 277-285)[DOI: 10.11834/jig.170390]
Parmar N, Vaswani A, Uszkoreit J, Kaiser, Shazeer N, Ku A and Tran D.2018.Image transformer[EB/OL].[2021-08-13].https://arxiv.org/pdf/1802.05751.pdf
Rawat W and Wang Z H.2017.Deep convolutional neural networks for image classification: a comprehensive review.Neural Computation, 29(9): 2352-2449[DOI: 10.1162/neco_a_00990]
Ren D W, Zuo W M, Hu Q H, Zhu P F and Meng D Y.2019.Progressive image deraining networks: a better and simpler baseline//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach, USA: IEEE: 3932-3941[DOI: 10.1109/CVPR.2019.00406]
Ronneberger O, Fischer P and Brox T.2015.U-Net: convolutional networks for biomedical image segmentation//Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention.Munich, Germany: Springer: 234-241[DOI: 10.1007/978-3-319-24574-4_28]
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, Kaiserand Polosukhin I.2017.Attention is all you need//Proceedings of the 31st International Conference on Neural Information Processing Systems.Long Beach, USA: Curran Associates Inc.: 6000-6010
Wang F, Jiang M Q, Qian C, Yang S, Li C, Zhang H G, Wang X G and Tang X O.2017.Residual attention network for image classification//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu, USA: IEEE: 6450-6458[DOI: 10.1109/CVPR.2017.683]
Wang G Q, Sun C M and Sowmya A.2020.Cascaded attention guidance network for single rainy image restoration.IEEE Transactions on Image Processing, 29: 9190-9203[DOI: 10.1109/TIP.2020.3023773]
Wang G Q, Sun C M and Sowmya A.2021.Attentive feature refinement network for single rainy image restoration.IEEE Transactions on Image Processing, 30: 3734-3747[DOI: 10.1109/TIP.2021.3064229]
Wang M H, He H J and Li C.2020.Single image rain removal based on selective kernel convolution using a residual refine factor.Journal of Image and Graphics, 25(12): 2484-2493(王美华, 何海君, 李超.2020.自适应卷积的残差修正单幅图像去雨.中国图象图形学报, 25(12): 2484-2493)[DOI: 10.11834/jig.190682]
Wang Z, Bovik A C, Sheikh H R and Simoncelli E P.2004.Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4): 600-612[DOI: 10.1109/TIP.2003.819861]
Woo S, Park J, Lee J Y and Kweon I S.2018.CBAM: convolutional block attention module//Proceedings of the 15th European Conference on Computer Vision.Munich, Germany: Springer: 3-19[DOI: 10.1007/978-3-030-01234-2_1]
Yang L X, Zhang R Y, Li L D and Xie X H.2021.SimAM: a simple, parameter-free attention module for convolutional neural networks//Proceedings of the 38th International Conference on Machine Learning.Virtual event: ICML: 11863-11874
Yang W H, Tan R T, Feng J S, Liu J Y, Guo Z M and Yan S C.2016.Joint rain detection and removal via iterative region dependent multi-task learning[EB/OL].[2021-08-13].https://arxiv.org/pdf/1609.07769.pdf
Yang W H, Tan R T, Feng J S, Liu J Y, Guo Z M and Yan S C.2017.Deep joint rain detection and removal from a single image//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu, USA: IEEE: 1685-1694[DOI: 10.1109/CVPR.2017.183]
Yang W H, Tan R T, Wang S Q, Fang Y M and Liu J Y.2019.Single image deraining: from model-based to data-driven and beyond[EB/OL].[2021-08-13].https://arxiv.org/pdf/1912.07150.pdf
Yasarla R and Patel V M.2019.Uncertainty guided multi-scale residual learning-using a cycle spinning CNN for single image de-raining//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Long Beach, USA: IEEE: 8397-8406[DOI: 10.1109/CVPR.2019.00860]
Zhang H and Patel V M.2018.Density-aware single image de-raining using a multi-stream dense network//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City, USA: IEEE: 695-704[DOI: 10.1109/CVPR.2018.00079]
Zhang Y L, Tian Y P, Kong Y, Zhong B N and Fu Y.2018.Residual dense network for image super-resolution//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City, USA: IEEE: 2472-2481[DOI: 10.1109/CVPR.2018.00262]
