基于加权分组串行调度改进的MPA算法
2022-05-22朱立东
邓 旭,朱立东
(电子科技大学 通信抗干扰技术国家级重点实验室,四川 成都 611731)
0 引言
随着全球经济和信息交换的快速发展,如何对海量用户进行准确检测与识别、满足人们日益增长的海量接入需求,具有很高的研究价值[1]。由于分割的正交信道间没有交集,导致有限的信道容量中可容纳的用户数量相当受限,传统的正交多址接入技术已经无法满足日益增长的数据信息和海量用户连接要求了,因此非正交多址接入(Non-Orthogonal Multiple Access,NOMA)技术成为人们研究的焦点。
对于NOMA,高性能的多用户检测是必须考虑的问题。消息传递算法(MPA)是一种置信传播算法,通过因子矩阵的边缘迭代传递消息进行更新直到算法收敛或达到最大迭代次数。但是该算法当用户数增大时,其复杂度呈现指数增长,为此设计低复杂度的SCMA多用户检测算法变得尤为重要。近年来,低复杂度多用户检测算法已经成为热点研究方向之一,目前已有大量的研究成果。传统的MPA算法以并行方式更新消息,这会导致先更新的消息无法得到及时利用,需要中间变量将其存储等待下一次迭代才能被利用。为解决这一问题,文献[2]提出一种基于串行更新的消息传递算法(Shuffled MPA,S-MPA),该算法能够立即传播在当前迭代中已经更新的消息,无需等到下一次迭代,该方式能加快算法的收敛速度,降低迭代次数,从而降低算法复杂度。然而这种算法初始条件下对于用户的迭代更新顺序是随机的,无法保证最可靠的消息及时得到更新。在此基础上,文献[3]提出一种改进的基于串行调度的消息传递算法(Improved Serial Scheduling Based MPA,ISS-MPA),该算法首先对变量节点的更新顺序进行选择,根据变量节点的权值大小确定各个变量节点的更新优先级,在此基础上再根据S-MPA算法进行消息的迭代更新。由于增加了权值的计算,该算法增大了系统开销,因此该算法是通过牺牲算法复杂度为代价来进行BER更新的。
文献[4]提出了扩展的对数域Max-Log(Extended Max-Log,EML)MPA算法,该算法基于截短消息的思想避免了直接使用M维消息进行消息传递,这样的方式能较好地在BER性能和算法复杂度上获取平衡。为了进一步降低BER,文献[5]提出了另一种消息截取方式,即基于动态网格的消息传递算法(Dynamic Trellis Based MPA,DT-MPA)。在每次迭代过程中,首先将各个列对应的符号值进行排序,只需将前i个网格点的值保留下来参与消息的迭代即可,仿真结果表明该算法可以获得比EML算法更低的复杂度。
文献[6]提出了一种残差辅助的消息传递算法(Residual-aided MPA,R-aided MPA)。该算法利用变量节点消息更新前后的差异作为衡量标准,残差值越大表明其优先级越高,优先更新残差值最大的节点消息,从而加快译码的收敛速度,提高MPA迭代算法的收敛性。文献[7]提出了一种基于边缘选择的消息传递算法(Edge Selected MPA,ES-MPA),该算法只选取信道质量较好的部分边缘进行资源节点到用户节点的更新,质量较差的边缘将被视为干扰并利用高斯近似的方法进行计算,该算法可以在不降低BER性能的同时保证算法复杂度的降低。此外,文献[8]提出一种基于部分边缘化的消息传递算法(Partial Marginalization MPA,PM-MPA),该算法首先预设一个迭代次数阈值,当迭代次数小于阈值时按照并行的MPA算法进行消息的迭代更新,反之只有前面m个元素参与消息的更新迭代,从一定程度上降低算法的复杂度,但与此同时也带来了较大的BER性能损失。文献[9]提出一种基于球形译码的检测算法(Sphere Decoding MPA,SD-MPA),该算法首先通过高斯噪声的分布特性选定圆形半径 ,然后在进行资源节点更新过程中只有半径范围内的叠加星座点参与消息的迭代,从而可以在误码性能和复杂度上获取平衡。
根据前文介绍可知,降低MPA算法计算复杂度的算法主要分为基于串行调度和并行调度的MPA多用户检测算法。相比于并行调度的MPA算法,串行调度的MPA算法能在保证系统误码率的前提下加快系统的收敛速度,然而串行调度的MPA算法增加了处理时延。因此本文结合串行MPA算法和并行MPA算法的优势,提出一种改进的MPA算法,进一步降低计算复杂度。
1 SCMA系统模型
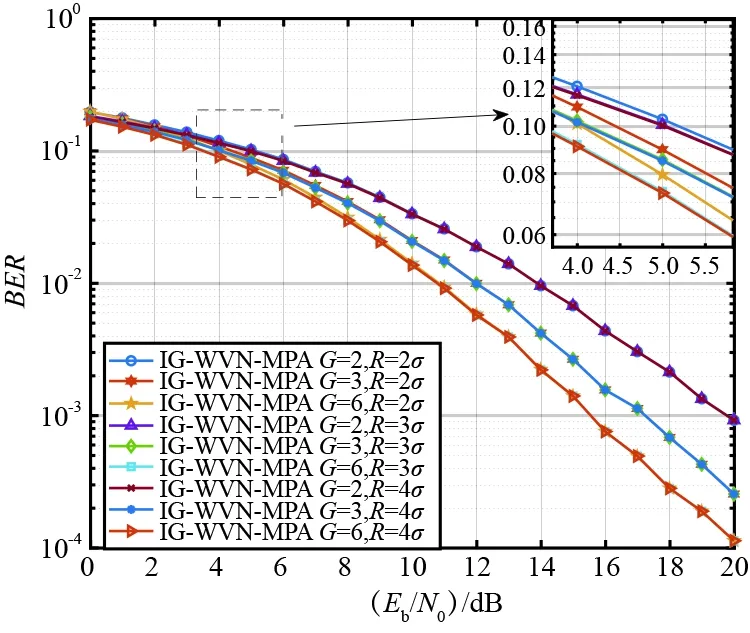
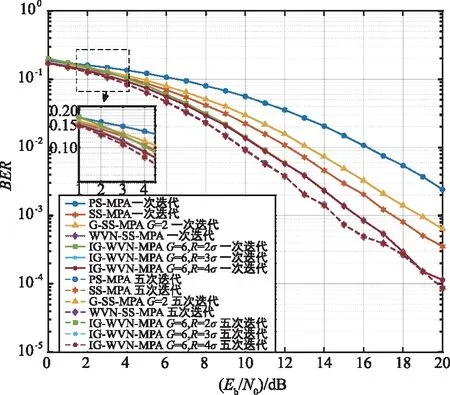
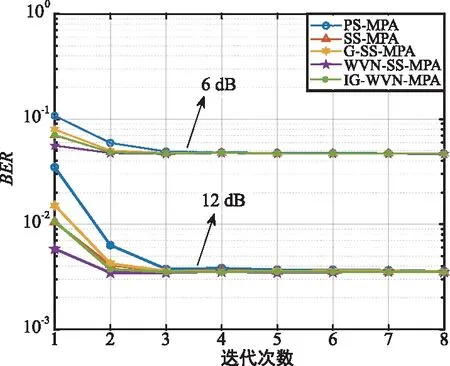
SCMA系统由J个用户和K个正交的资源块组成,其中SCMA系统的用户数大于资源块数,即K (1) 如果J个用户同步发送数据,则接收端收到的多路复用信号可表示为: (2) 式中,第j个用户的信道有效矩阵为hj,n表示信道噪声,服从高斯白噪声n~CN(0,N0I)。 当接收信号y和信道矩阵H=[h1,h2,…,hJ]T已知时,假设用X=(x1,x2,…,xJ)表示J个用户的码字,则MAP检测算法可表示为: (3) 由于各个用户发送的数据是相互独立的,所以SCMA系统中各个码字间也具有独立性,结合贝叶斯准则可以进一步将式(3)改写为: (4) 第k个资源块上非零码字组合可以用Xk,ξk=(Xξk,1,Xξk,2,…,Xξk,dr)来表示,则式(4)可以改写为: (5) 最终可以将式(5)改写为: (6) 由式(6)可以看出,MAP检测就是根据已知接收信号进行穷举从而得到最大的概率组合,该算法的计算复杂度为O(MJ)。随着用户数量的增长,该算法的计算复杂度将呈现指数型上升,这给SCMA接收机的设计带来了很大的挑战,要求对较低复杂度的SCMA多用户检测方案进行研究。 在众多算法中,MPA算法是一种次优的多用户检测算法。该算法在保证BER性能的前提下可以将计算复杂度降低至O(Mdr),其工作原理是根据因子图迭代地更新和传递边上的信息,直到最大迭代次数。假设Rrk→uj(xj)表示因子图中资源节点rk到用户节点uj的更新消息,Uuj→rk(xj)表示因子图中用户节点uj到资源节点rk的更新消息。 步骤1:对资源节点进行消息更新。鉴于第k个资源块,可得: (7) 式中,k=1,2,…,K,t=1,2,…,Nitmax。ξk为因子矩阵F第k行非零元素的集合。 步骤2:对用户节点进行消息更新。鉴于第j个用户,可得: (8) 其中,j=1,2,…,J,t=1,2,…,Nitmax。ζj为因子矩阵F第j列非零元素的集合。 当达到最大迭代次数Nitmax时,软判决输出结果可得: (9) 串行调度MPA算法(Serial Scheduling MPA,SS-MPA)和并行调度MPA算法(Parallel Scheduling MPA,PS-MPA)的最大区别是SS-MPA算法可以在同一次迭代中依次更新资源节点的消息和用户节点的消息,而PS-MPA算法则是在本轮迭代中无法使用已经更新的消息,必须等待下一轮才可以被使用。 虽然SS-MPA更新方式已经加快了MPA检测器的收敛速度,但是串行调度方式一次迭代过程所消耗的时间较长,即MPA检测时常将会增大,为了降低SS-MPA算法检测带来的较大时延问题,在此引入分组的概念,将J个用户分成N组,组与组之间并行执行,这样可以大大降低检测时间。这种检测方式也可以称为分组的SS-MPA(Group of SS-MPA,G-SS-MPA)。 G-SS-MPA算法的核心思想是将J个用户节点分成N组。组内的用户节点基于串行调度的方式更新节点消息,组与组之间基于并行调度的方式更新节点消息,G-SS-MPA算法一次迭代过程示意图如图1所示。从图中可以明显看到3个组之间并行化执行,组内的节点串行更新节点消息,由此进一步降低检测带来的时延问题。 图1 G-SS-MPA算法平均分为3组时的一次迭代过程Fig.1 An iterative process when the G-SS-MPA is evenly divided into 3 groups 一般情况下都是将所有用户节点进行平均分组,每组将会有Jn=J/N个用户节点。对于(n-1)·JN+1≤j≤nJN,n=1,2,…,N的用户节点,可以将式(7)改写为: (10) 式中,当G=1时,G-SS-MPA算法为标准的PS-MPA算法;当G=J时,G-SS-MPA算法为标准的SS-MPA算法。 本节介绍有关加权串行调度MPA算法(Weight Variable Node SS-MPA,WVN-SS-MPA),它是在SS-MPA的基础上,对用户节点的更新顺序进行调整,根据用户节点的权值大小优先选择权值大的节点进行更新。 定义用户节点的权值为βj(j=1,2,…J),其表示连接到用户节点uj处的资源节点权值之和;资源节点权值为αk(k=1,2,…,K),其表示资源节点rk的权值,由此可以得到: (11) 从式(11)可以看出,若βj权值越大,说明与用户节点uj连接的资源节点还没有达到收敛状态,此时应当优先选择这些对应的资源节点进行更新。如果存在多个用户节点的权值相同,则说明对应的资源节点的优先级一样,此时可以随机选择任意一个资源节点进行消息更新。 如图2所示,选择用户权值节点最大对应的用户节点,由于初始阶段所有用户节点权值都为0,则可以随机选取一个用户节点。假设选取用户节点u1及其相连的资源节点r2和r4,将资源节点r2和r4的权值α2和α4自增1,并且与r2和r4的变量节点权值都自增1,紧接着将β1从集合中去除,即Ω=Ω-β1。剩下的用户节点都按照该过程不断选取,最终可以得到用户节点权值更新的顺序为:1→3→5→2→4→6。从算法角度看,WVN-SS-MPA算法是在SS-MPA算法的基础上添加了权值计算来确定变量节点的更新顺序,所以WVN-SS-MPA算法的加法运算数目会变得更多,增加了系统计算复杂度。 图2 WVN-SS-MPA算法变量节点顺序选择更新示意图Fig.2 WVN-SS-MPA algorithm variable node sequence selection update diagram 目前有关降低PS-MPA算法计算复杂度主要从减少M或者dr着手,但是很少有人涉及从整体Mdr的角度降低该算法的计算复杂度。本节提出的SD-MPA算法通过减少SCPs的数量来降低MPA检测的复杂度,它首先对资源节点上的码字信息进行筛选,设置一个合理的半径,在半径范围内的星座点才参与迭代,大于半径范围的点全部去除。其中半径r的确定可以通过高斯噪声的分布特性,从而在误码性能和计算复杂度上保持平衡。 在PS-MPA译码过程中,由于一个资源块上一共有Mdr个SCPs,则rk资源块上的星座点集合可以表示为: Φ(k)=(φk(1),φk(2),…,φk(Mdr)), (12) 此时将第k个资源块的接收信号改写为: (13) 由于高斯噪声nk的随机性,所以接收信号星座点不会和任意一个SCP重叠,则二者之间的欧氏距离可以表示为: (14) 如果φk(ζ)为发送正确的SCP,则当前φk(ζ)的等价形式为: (15) 结合式(14)~(15)可以得到: (16) 在实际情况下nk服从AWGN分布,均值为0,方差为σ2。但是由于接收到的信号可能处于多个候选的SCPs中心,很难通过接收信号的星座点来判断正确发送的叠加码字组合。 从表1可以看出,置信区间(-2σ,2σ)在可以保证圆形区域内有95.4%的可信信息,当半径r→∞时,SD-MPA算法即为PS-MPA算法。在给定球形译码半径的前提下,置信度较高的SCPs和发送信号星座点之间的欧氏距离满足: (17) 表1 置信区间与概率间关系Tab.1 Relationship between confidence interval and probability 根据第2节介绍可知,降低MPA算法计算复杂度的方法主要有减少迭代次数Niter、降低码本大小M、降低行重因子df或是整体降低每次参与迭代点数Mdr[14]。但是通过减少迭代次数Niter和降低每次参与迭代点数Mdr二者结合考虑的方式来降低MPA算法复杂度却很少有人涉及,在此选出具有典型代表的G-SS-MPA和SD-MPA算法,发挥二者的优势从整体上来降低算法复杂度,为此设计了基于加权分组串行调度的改进MPA算法(Improved Group of WVN-MPA,IG-WVN-MPA)。 步骤1:根据2.1节的分析可知分组数越多G-SS-MPA算法的性能越好,因此考虑可以将G-SS-MPA代替SS-MPA来降低算法复杂度。然后又根据2.2节的分析可知对用户节点的更新顺序进行调整可以提高系统的BER性能。因此在初始阶段,在G-SS-MPA算法中加入权值大小排序,根据式(11)确定所有用户节点的待更新顺序。 步骤3:对用户节点进行更新。鉴于第j(n-1)·JN+1≤j≤nJN,n=1,2,…,N)个用户节点,可将式(10)改写为: (18) 步骤4:对用户节点进行更新。鉴于第j{j=(n-1)JN+1,(n-1)JN+2,3,…,nJN}个用户,根据式(10)进行更新。 当达到最大迭代次数Nitmax时,根据式(11)软判决输出结果。 具体有关IG-WVN-MPA算法如算法1所示。 算法1 IG-WVN-MPA多用户检测算法 输入: 1)接受信号y,噪声功率N0,信道H 2)各用户码本CB 3)最大迭代次数Nitmax 输出:Q(xj) 1:根据式(11)计算变量节点的权值,并按降序将变量节点进行排序 4: whilet≤Nitmaxdo 5: forn=1,2,…,Ndo 6: forj=(n-1)JN+1,(n-1)JN+2,3,…,nJNdo 7: fork∈ζjdo 8: 9: 10: end for 11: end for 12: forj=(n-1)JN+1,(n-1)JN+2,3,…,nJN 13: 14: end for 15:end for 16:t=t+1 17:end while 18:forj=1,2,…Jdo 19: 20:end for 表2展示了不同调度算法的复杂度对比。由表中可以看出SS-MPA、G-SS-MPA和WVN-SS-MPA算法的加法运算、乘法运算、指数运算复杂度一样。不难看出,WVN-SS-MPA算法是在SS-MPA算法的基础上得到的,相比于SS-MPA算法只多增加了权值的计算,但是这部分权值计算几乎可以忽略不计。因此该算法是以牺牲少量算法复杂度为代价,在VN-SMPA算法的基础上进行了BER性能的优化。而G-SS-MPA算法是SS-MPA算法的一个变形,当G=6时,G-SS-MPA算法等价为SS-MPA算法;而当G=1时,G-SS-MPA算法等价为PS-MPA算法。 表2 不同调度算法复杂度对比Tab.2 Comparison of complexity of different scheduling algorithms 此外通过前面分析可以明显看出串行调度算法的收敛速度要比并行调度算法快,即在相同条件下串行调度算法的复杂度要比并行调度算法低。但是可以将其中的SD-MPA算法融入至串行调度算法中,由提出的新算法可以看出相比于串行调度算法,其加法运算和乘法运算中每次参与迭代点数Mdr降低至|Φ*(k)|(一般情况下|Φ*(k)|=Mdr/3[15]),由此进一步降低算法复杂度。 本节将通过仿真对比PS-MPA、SS-MPA、G-SS-MPA、WVN-SS-MPA与本文所提出的IG-WVN-MPA算法,从BER性能和复杂度等方面进行分析比较,仿真中各参数的设置如表3所示。 表3 仿真参数Tab.3 Simulation parameters 本文的Rayleigh信道参数如表4所示[16]。 表4 Rayleigh信道参数Tab.4 Rayleigh channel parameters 图3展示了不同条件下IG-WVN-MPA算法的性能对比。由图中可以明显看出,随着G和R的增大,IG-WVN-MPA算法的性能在不断提升。这是因为G的增大意味着串行调度更新的频率就会越高,算法收敛速度也会变快,系统性能随之提高。而R的增大意味着置信区域在不断变大,迭代过程中丢失的信息逐渐变少,最终译码输出的结果精确度不断提高,则系统性能也跟着提升。此外还可以看到IG-WVN-MPA算法在G=6和R=4σ条件下性能最优,而在G=2和R=2σ条件下性能最差。与此同时随着Eb/N0的增大,G的变化对于所提算法的影响在逐渐增大,而R的变化对所提算法的影响在逐渐变小。 图3 不同G和R条件下的IG-WVN-MPA 算法BER性能对比Fig.3 BER performance comparison of IG-WVN-MPA algorithm under differentG andR conditions 图4展示了PS-MPA算法、串行调度MPA算法和所提算法在不同条件下的BER性能曲线对比,从图中可以明显看出WVN-SS-MPA算法的性能最好,IG-WVN-MPA算法在G=6,R=4σ条件下与WVN-SS-MPA的性能一样好,在G=6,R=3σ条件下的IG-WVN-MPA算法性能次之,PS-MPA算法的性能最差,可以明显看出串行调度MPA算法的性能比并行调度的MPA算法性能要好,与前面的分析中相一致。而IG-WVN-MPA性能要比WVN-SS-MPA略差一些是因为该算法中减少了每次参与迭代的码本数目,这将导致译码端无法正确判别出这些丢失的码本信息,最终导致性能上的缺失。IG-WVN-MPA算法通过牺牲一部分系统性能来加快算法的收敛速度,这样的算法思想与前文的分析一致。此外可以看出,当迭代次数达到5时,各算法的BER性能基本一样,且比迭代次数为1时提升了1 dB左右的增益。也就是说随着迭代次数的增大各算法的BER性能会越来越好,这是因为迭代次数的增大使得接收端的判决结果更加准确可靠,当各算法经过足够多的迭代次数后,都能充分利用所有更新的消息,最终性能上会保持基本一致。 图4 不同MPA算法BER性能对比Fig.4 Comparison of BER performance of different MPA algorithms 图5为不同MPA算法BER性能随迭代次数的变化关系,可以明显看出,迭代次数的增大对于各MPA算法来说性能会变得更好,并最终达到收敛状态。 图5 不同MPA算法BER性能与迭代次数的关系Fig.5 Relationship between BER performance and iteration times of different MPA algorithms 这是因为当迭代次数增大时接收端的判决结果更加准确可靠,从而整体性能会不断提高;而当迭代次数达到一定时,其消息都已经收敛,最终所有的算法在相同Eb/N0下拥有同等的BER性能。此外,也可以看到WVN-SS-MPA算法只需要2次迭代即可收敛,而IG-WVN-MPA算法、SS-MPA算法和G-SS-MPA算法分别需要3次迭代、3次迭代和4次迭代基本上可以收敛,然而性能最差的PS-MPA算法需要6次迭代才能够达到收敛。 图6显示了6次迭代的PS-MPA、4次迭代的G-SS-MPA、3次迭代的SS-MPA、2次迭代的WVN-SS-MPA算法和3次迭代的IG-WVN-MPA算法的复杂度比较。从图中可以明显看出,IG-WVN-MPA算法所需的乘法和加法运算次数最少,这进一步验证了IG-WVN-MPA算法的低复杂度算法特性。具体来说与6次迭代的PS-MPA、4次迭代的G-SS-MPA、3次迭代的SS-MPA和2次迭代的WVN-SS-MPA算法相比分别节省了76.9%、75%、66.7%和50.1%乘法运算,以及分别节省了90.9%、75.8%、67.7%和51.6%加法运算。因此IG-WVN-MPA算法在误码性能和复杂度上提供了更优的折中方案。 图6 不同MPA算法计算复杂度比较Fig.6 Comparison of computational complexity of different MPa algorithms 本文研究了SCMA低复杂度多用户检测方法,系统分析了SCMA多用户检测算法的研究现状,然后分别从串行调度MPA和并行调度MPA入手,重点介绍了G-SS-MPA、WVN-SS-MPA、RD-MPA和SD-MPA几种典型的算法,从算法原理、复杂度分析和性能对比分析的角度进行论述。从整体上看,算法的改进主要围绕降低迭代次数、码本大小、行重因子以及联合考虑码本大小和行重因子来进行。然而对于联合三者来考虑降低复杂度却很少有人涉及,本文结合G-SS-MPA、WVN-SS-MPA和SD-MPA的优势,设计了IG-WVN-MPA算法。该算法在误码性能和复杂度上可以实现比较好的平衡,通过牺牲少量误码性能来进一步降低算法的复杂度。
2 低复杂度检测算法
2.1 分组串行调度MPA算法

2.2 基于加权串行调度MPA 算法

2.3 基于球面解码的MPA算法
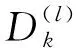
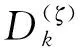

3 基于加权分组串行调度的改进MPA算法
3.1 算法描述



3.2 算法复杂度分析

3.3 仿真结果分析



4 结束语
