基于深度学习下地磁干扰数据集的建立
2022-05-20车濛琪应允翔张明明
车濛琪,陈 俊,应允翔,朱 虹,张明明
(1.蒙城监测中心站,安徽 蒙城 233527;2.蒙城地球物理野外观测站,安徽 蒙城 233527)
0 引言
“十三五”建设后期,国内建设了越来越多地磁观测台站。面对大量产出的地磁数据,传统人工地磁数据处理方法存在工作效率低、主观性强等缺陷[1]。实现观测数据的自动化和智能化处理,已然成为了地震科技创新工作中的主流方向。随着人工智能相关理论与技术的发展,深度学习凭借其覆盖范围广、学习能力强、数据驱动上限高等优势成为各个领域中的应用热门[2]。当前,国内外研究人员对深度学习应用于地磁数据处理领域进行了深入研究,在地磁暴预测、大地电磁反演和地磁数据重构等方面取得了突破性进展。Amy M.[3]等利用OMNIWeb 数据构建数据集并在前馈人工神经网络(ANN)和长短时记忆(LSTM)下进行训练,最终得到的模型具有较好预测效果;而Adrian Tasistro-Hart 等[4]通过添加更多观测值作为特征以提高模型预测能力;Spichak 等[5]利用ANN 探索大地电磁三维反演问题的可能性;姚休义等[6]利用BP 神经网络完成对地磁观测数据重构工作。以上工作均为在深度学习框架下对地磁数据进行研究,并产出良好的产品。
在此情境下,将人工智能深度学习技术与地磁观测相结合,利用神经网络通过对不同干扰数据集的学习,实现干扰自动化分类,可为进行干扰判别的一线检测人员提供参考依据,并减少人工检查成本,进而提高工作效率和稳定性。因此,为更好推进地磁观测干扰自动化和智能化的识别研究,本文通过对原始数据的筛选及对干扰标签的整合,构建了地磁干扰数据集及标签样本。然后基于目前主流深度学习模型进行实验对比,敲定合理训练数据格式,构造合适训练样本,为后期搭建模型训练用地磁干扰数据库奠定了基础。
1 研究数据与方法
1.1 研究数据介绍
在日常地磁相对观测中得到了大量的原始数据,并及时进行了预处理。当数据受到干扰时,地震监测台站一线工作人员将会对其进行分类,并由学科组进行复核,经过几年的积累地磁观测台网数据库获得了具有一定可靠性的干扰标签。地磁干扰分类利用深度学习中的监督学习,本质上是一个对训练数据特征提取及参数优化的问题[7]。构造合适数据集和具有可靠性干扰标签是学习数据集特征及对应标签的必要步骤。
收集全国共25 个台站34 套仪器地磁观测数据及预处理标签,具体台站、测点仪器及数据时间见表1,干扰数据阈值设置为0.5 nT。数据收集地域具有广泛性,且连续率、完整率高,并拥有一定的干扰样本。根据近年来深度学习在mnist 手写体分类中良好的应用[8-9],参与训练的数据样本量需在60 000条以上。为保障后续数据集的准确性和科学性,通过对数据集数据进行随机采样加人工校验来评估其质量。整个样本集的错误率低于0.5%时,可以认定本文构建的数据集具有较高质量和可信度,并能够完成深度学习训练。
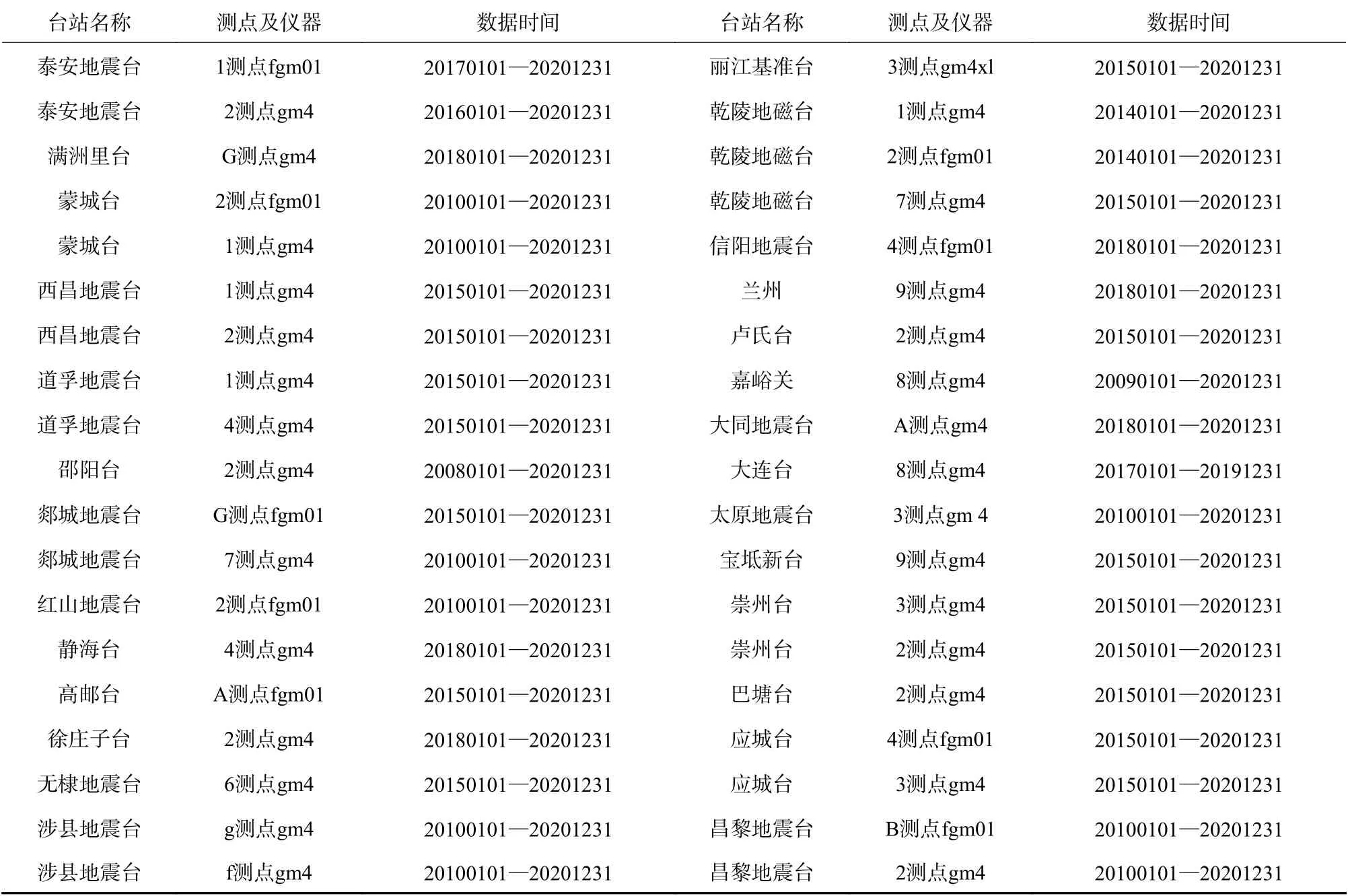
表1 数据采用详细信息
1.2 研究方法
为检验数据集质量,通过调用keras 的封装模块使用CNN 完成深度学习过程。CNN 模型已不断发展形成了适用于各个场景的架构模型,在地震与噪声分类[7]、微震与爆破事件辨识[10]、地震事件自动检测[11]、地震反演[12]等各实验中有良好的表现。Keras 基于Tensorflow 实现且模块化程度高,其中包含网络层、损失函数、优化器、激活函数等常用独立模块,能根据需求快速搭建并训练深度学习网络模型[13]。本文参考有众多成功经验的经典卷积神经网络“Le-Net5”[14],及在地震与噪声分类中CNN模型的变形,构建包含1 个输入层、6 个隐藏层以及1 个输出层的一维卷积模型,使神经网络能更好获得地磁干扰样本数据集的空间特性,以完成分类目标。将表1 中收集数据建立为实验组,将只含有昌黎台数据建立为对比组。
主要实验流程分3 步:确立样本数据的干扰类别、确定样本数据的数据格式、将样本数据与干扰类别标签对应。其技术路线(其中n为样本数量)见图1。

图1 技术路线
确立干扰类别:地磁观测中长时间段内的数据是正常、不存在干扰的,存在干扰的数据一般远少于正常数据,并且不同干扰类别数据的数量也是存在量级差异。统计实验组数据得到高压直流干扰和未分类干扰在日常观测中出现频次多,能够提供一定数量样本以保障训练正常进行。因此,本文尝试选择3 种干扰类型标签进行实验,分别为无干扰、高压直流干扰、未分类干扰类型。
数据格式的确定:选取30 分钟时长的数据为一个数据样本。根据观测数据特点、地磁要素计算及训练需要,并参照图像分类识别,将地磁D、H、Z 三分量波形看作一维三通道图像数据,选取实验组、对照组三测向数据,分割、重组、构建成为30分钟长度×3 通道的数据格式。有些时间段的数据由于缺数或入库问题并未采集到,重组时出现某半小时时段内缺少某分量数据的情况时,遵从“优胜劣汰”原则进行严格数据清理,删除该条样本数据。有些时段内数据由于仪器或观测环境影响存在部分缺数,“NULL”在深度学习过程会造成特征提取困难,将所有空值使用0 替换,筛选掉问题数据。最终构造数据集时,为保障分类质量评估结果的准确性和可靠性,3 个类别标签样本数量应不存在量级差距,所以对3 个类别需随机挑选固定且无量级差异的样本数量后进行训练。分割统计后,2 个组别内均为高压直流输电干扰样本数最少,以各自高压直流样本数作为其他2 个干扰类别样本数量。最终实验组数据集样本数约为15 000×3 条,对比组数据集样本数约为2 000×3 条,实验样本集达到训练样本量要求。各数据集的20%划分为测试集,剩下数据将在模型训练中将80%划分为训练集、20%划分为验证集。
进行标签对应处理时,需要在训练数据洗牌后,利用初始索引保证样本数据与干扰标签之间对应关系不变。将处理好的同类型训练样本分别存入“.npy”文件中方便日常管理和之后训练时提取。
2 基于CNN 模型的数据集训练与测试
分别用实验组和对比组进行三分类和二分类。其中二分类将三分类中的高压直流和未分类干扰归为一类作为有干扰类别,无干扰类别不进行操作。将实验组和对比组分别进行二分类三分类的训练。具体训练过程中准确率和损失变化见图2~5;模型训练精度与验证精度比较见表2。
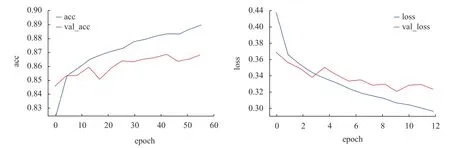
图2 实验中出现的早停

表2 模型训练精度与验证精度比较
在训练开始前,需对训练集内的样本进行标准化和归一化。在确定标准化对象后,发现对每个样本3 个通道分别进行标准化后的数据集将获得更高的准确率(accuracy)和更低的损失(loss)。可见为获得更好的分类效果,需在训练前对每个训练样本的每个通道进行标准化。
训练过程中,添加使用批标准化“batch_normalization”和激活函数“relu”。全连接层中使用“dropout”,神经元的丢弃概率为“0.3”,达到避免过拟合目的。训练和测试的批次大小都为“30”,使用 Adam 优化器,学习率初始值为“0.01”。当训练集数量不足时,迭代次数多后则避免不了出现过拟合现象。过拟合将导致最终模型泛化能力低,对测试集预测效果较差,需避免。例如图6 箭头过后出现过拟合现象,验证集的精度不再上升、损失不再下降而改为开始上升,利用“早停”停止训练。再利用“saveBestModel”功能保存最优模型完成训练,保存下来的模型在之后的训练直接加载即可继续学习。

图6 对比组小样本量三分类acc 和loss
为更好地了解模型在三分类过程中3 种干扰类型的训练情况,在上述实验后构建新测试集,利用实验组在三分类训练中得到的模型进行分类测试。在得到3 种干扰预测标签后与真实标签进行计算,利用“sklearn.metrics”模块导出其混淆矩阵和各干扰召回率、f1 等参数报告表格(表3~4)。

表3 各干扰召回率、f 1 等参数报告
在保障一定样本数量的前提下,经历数据清洗和样本格式重构后的数据集其实验分类准确率在80%左右,说明该数据集和模型具有一定识别干扰能力,但准确率和召回率都有待提升。通过训练曲线可以发现,验证集和训练集各参数在几次迭代后、未达到良好分类效果前迅速出现了差距,说明训练出现了过拟合现象。
根据实验组和对比组组间对比,即大样本量同小样本量精度对比,无论是在三分类(图4 与图5 对比)还是二分类任务(图2 与图3 对比)中,大样本量的数据集损失更小、准确率更大。实验结果符合深度学习规律:在分类模型能力内,数据集样本越多,特征学习越好,训练后分类效果越佳。

图3 实验组大样本量二分类acc 和loss
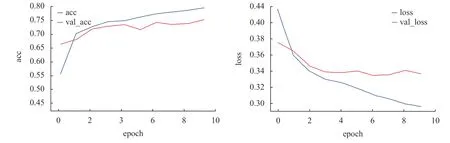
图4 对比组小样本量二分类acc 和loss

图5 实验组大样本量三分类acc 和loss
查看表2,比较三分类和二分类在不同数据集中的表现,可以发现在三分类实验中实验组训练效果相较于对比组训练效果的提升要大于在二分类中的提升,进行较少分类目标的实验将拥有更高的准确率和更低的损失。表明更进一步的分类依赖于充足的样本量,更多更细的分类需要更多数据样本支持。
查看表3 中各干扰类别的召回率情况,混淆矩阵可以清楚地表示模型对新测试集样本各干扰的分类判别情况(表4),发现-1(正常)和0(未分类干扰)判别成为313(高压直流输电干扰)较少,而313(高压直流输电干扰)易预测为-1(正常)。可能跟部分台站数据受高压直流输电影响但变化幅度不大有关,模型对样本集中的313 特征提取不够或泛化性不足。

表4 测试集混淆矩阵
3 结论与探讨
通过建立地磁干扰数据集、搭建CNN 网络模型,进行模型训练、验证与测试,证明了通过CNN 网络的分类能力可以应用于地磁干扰分类这一应用场景。基于深度学习构造的数据集经过严格数据清理过程,该数据集数据覆盖范围广、易收集与添加新样本,后期维护简单,能在训练后产出具有一定分类能力的模型,实现地磁干扰分类。
未来在进一步工作中可继续研究的方向有以下几个方面。
1)构造数据集工作量较大,尝试在同一个数据集下同时实现不同的任务,实现数据集价值最大化;并继续补充数据集样本数量,并尝试手动挖掘一些特征,尝试不同格式加入原始数据集,以期获得更好分类效果,在干扰类别更细、更多的任务下也可以较好完成分类。
2)实验中,在较大数据量上还是容易出现过拟合,考虑单个样本所含特征较少或模型构造及参数仍可改进,在未来模型调参时针对过拟合进行调节,并且可考虑适当扩大输入层节点。如秒数据中特征表现往往更为明显,则利用分数据标签套用到秒数据中,尝试增大每个样本的数据长度或对数据集采用传统的平移、滤波、使用插值等预处理手段,探索更高精度的分类效果。
3)将该数据集基于更深层或更多不同架构的模型、不同激活函数、不同损失函数计算方式(如加权交叉熵函数等)下进行训练,测试其特性并根据要求或结果优化数据集格式和预处理方法。
