基于非对称特征差异网络的图像超分辨率重建
2022-05-20王彩玲
王彩玲,沈 齐
(南京邮电大学自动化学院、人工智能学院,江苏南京 210023)
单幅图像超分辨率(SISR)是一项常见的计算机视觉任务,主要的工作过程是将低分辨率(LR)图像重建成符合客观事实的高分辨率(HR)图像,结合一些最新的图像去噪算法[1-2]、图像复原算法[3],可以广泛应用在小物体检测、卫星成像和医学成像等多个高精度领域。然而,将一张基于特定的LR图像映射成HR图像会出现很多种结果,而这种结果不确定性并不能适用到这些高精确度的任务中。随着特征表示学习的发展,卷积神经网络(CNNs)在各种计算机视觉任务中取得了优秀的成果,这也极大地推动了SISR的发展。在SRCNN中,Dong等[4]首次将神经网络应用到图像超分辨率领域。为了进一步提高网络的性能,图像超分辨率网络被设计成更深更复杂的结构。Lim等[5]通过堆叠残差块的EDSR算法,显著地提高了生成的超分辨率图像的重建质量,这种深化网络模型的方式被进一步证明有效。
然而,本文认为单纯增加网络模型的深度,堆叠各种神经网络层不能真正提高图像超分辨率的生成质量,相反,在以RDN为代表的深度图像超分辨率模型的结果中,重建的图像趋于过度平滑,丢失了很多局部的细节特征。为了解决上述问题,一些利用关注局部特征的注意力机制的方法被提出,这些方法的研究重点是关注SISR的局部细节特征和图像独有的特征。例如,Liu等[6]利用非局部注意块进行图像恢复。 Zhang 等[7]利用通道注意力块[8]来提高SR的效果。后来,文献[9-10]中提出的方法充分利用空间注意力和通道注意力来提高SR性能。
也有一些工作使用生成对抗网络(GAN)来完成图像重建任务。近期的SinGAN[11]是一种特定于单张图像的GAN方法,采用多尺度渐进结构搭建生成器和鉴别器网络,将纯高斯噪声映射成图像样本,训练过程中仅使用低分辨率图像作输入。同样特定于单张图像的 GAN方法还有 KernelGAN[12]。KernelGAN网络接受给定的单张图像,生成与真实图像接近的SR卷积核,最大程度上保留了LR图像跨尺度图像块的数据分布。
这些使用注意力机制的方法在一定程度上增强了超分辨率图像的局部细节,然而大多方法只是处理单一网络结构下特征图之间的相关性,关注的图像细节层次单一,在生成效果上仍有提升空间。
1 相关工作
1.1 单幅图像超分辨率
一直以来,图像超分辨率问题都被定义为一种病态问题。当低分辨率LR图像与高分辨率SR图像之间的退化关系未知时,一张输入的LR图像xLR可以对应多张输出的SR图像。可以描述为
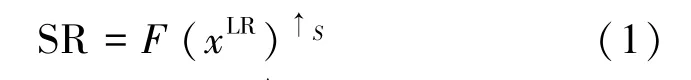
式中:s代表尺度因子,F(·)↑S代表将低分辨率图像放大s倍的超分辨率网络。单幅图像超分辨率算法首次搭建神经网络模型时,其性能优于传统的图像超分辨率算法。为了进一步提高准确性,Kim等提出了两个深度的超分辨网络,即 VDSR[13]和DRCN[14],它们分别将全局残差学习和递归层应用于SR问题。Tai等[15]提出了一个深度递归残差网络(DRRN),通过使用参数共享机制来减少非常深网络的模型大小。
为了加快图像超分辨率算法的执行时间,Shi等[16]提出了一种高效的亚像素卷积神经网络(ESPCN),它在LR空间中提取特征,并通过进行高效的亚像素卷积层来放大网络末端的空间分辨率。Tong等[17]提出了一个采用密集跳跃连接的SR网络,将不同层次的特征进行组合,显著提高了最终生成的SR质量。最近,Zhang等[18]扩展了这个想法并提出了一个残差密集网络(RDN),通过密集连接的卷积层提取丰富的局部特征,验证了非常深的网络可以有效地提高SR性能。
1.2 对比学习和孪生网络
对比学习是自监督学习的一种方法,通过将正负样本映射到高维度空间,拉近正样本的距离并拉开负样本的距离,计算正负样本之间的对比损失来进行分类,其精髓在于以孪生网络(Siamese network)为基础。 孪生神经网络[19]是由Yann Lecun提出来,网络接收两个输入样本,输出其嵌入高维度空间的特征,以比较两个输入样本的相似程度,具有天然的建模不变性。近年来大量的工作结果表明[20-21],孪生网络模型可以最大限度地提高同一图像的两个放大部分之间的相似性,但是两个网络分支的所有输出容易崩溃成一个常量,而解决这种问题的一个方法就是融入对比学习思想。例如基于动量更新的对比学习Moco[20]设置了一个负样本序列,将孪生结构的一个分支转换成动量编码器来提高序列的一致性。最新的 SimSiam方法[21]通过大量消融实验,验证了简单的stop-gradient思想可以有效地避免网络在训练过程中生成崩溃解。
1.3 通道注意力和空间注意力
通道注意力机制是对输入特征的每一个通道做处理,得到各个通道中有意义的特征信息。具体的操作是压缩输入特征的空间维度,聚合特征的空间信息,常用的方法是将最大池化和平均池化相结合。具体的通道注意力公式为
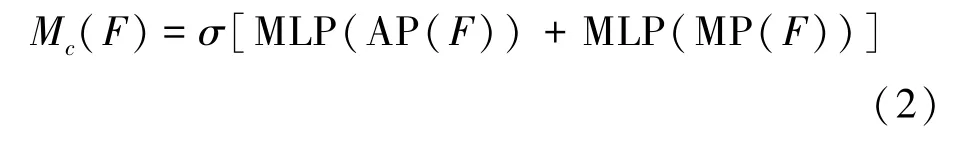
式中:F代表输入的中间特征图;σ代表Sigmoid函数;AP和MP分别代表平均池化层和最大池化层;中间特征图经过平均池化层和最大池化层计算后,生成两个特征描述符,之后被送入一个由多层感知器组成的全连接网络(MLP)生成两个特征向量,并使用点和的方式进行合并,最后经过Sigmoid函数生成具有通道注意力的特征图Mc(F)。
空间注意力是对通道注意力的补充,用来聚焦经过通道注意力处理过后的特征图中具有信息量的部分。空间注意力具体公式为
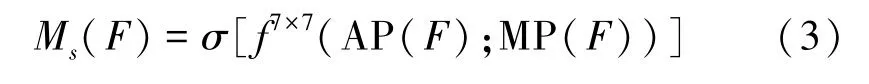
与通道注意力的处理方式类似,首先使用平均池化和最大池化分别生成两个特征描述符,再使用卷积核为7×7的卷积层f7×7处理这两个特征描述符,最后通过Sigmoid函数生成具有空间注意力的特征图Ms(F)。
2 本文方法
本文提出一种基于非对称特征差异网络(ATFDN)的图像超分辨率重建算法,网络模型可以分为两部分:用于训练学习输入图像全局分布的非对称特征提取网络和用于处理两个分支输出结果的特征增强模块。其中,非对称特征提取网络的两个分支网络分别命名为在线分支网络和对比分支网络。网络模型的整体结构设计如图1所示。
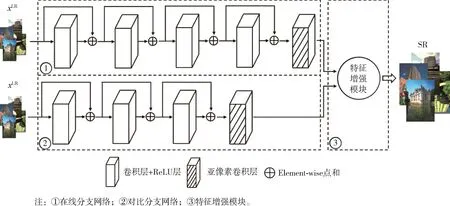
图 1 ATFDNet网络结构
2.1 非对称特征提取网络
借鉴SimSiam[21]的网络模型,设计了双通道的非对称特征提取网络来学习输入图像xLR的特征分布。具体公式表示为

式中:ySR表示最终生成的高分辨率结果;FEM(·)表示特征增强模块;Sub[·]表示亚像素卷积层;R(·)表示 ReLU激活函数;fc(·)表示卷积核为3*3,步长为1的卷积层。网络中每个卷积层使用3*3的卷积核来提取特征,并使用跳跃连接的方式,融合浅层信息,在经过最后亚像素卷积层进行放大之前,所有的卷积都会对图像特征图进行边界值相同填充处理,以保证训练过程中特征图的大小不变,充分利用图像自身涵盖的信息。
在线分支的网络层数要更深于对比分支网络,且根据损失函数的反向更新而更新自身权重值。对比分支的网络在训练过程中停止反向梯度流的更新,网络的权重参数由在线分支进行共享。这样设计的出发点是:在神经网络中,不同网络通道的卷积层提取到的特征也是不同的,这些不同的特征包含不同的高频细节信息分布。而对比分支网络提取的特征信息与在线分支网络既不同步也不是同一层次,通过损失函数计算两个网络的特征并反向更新在线分支网络的权重,可以强化网络的特征提取能力。
2.2 特征增强模块
图2为特征增强模块的具体组成,特征增强模块作用是输入上文所述的非对称特征提取网络生成的中间特征图,通过注意力机制的计算,增强特征图中重要的高频细节特征,使用非线性点乘的方式增强在线分支网络生成的结果,得到最终强化细节之后的生成结果图。
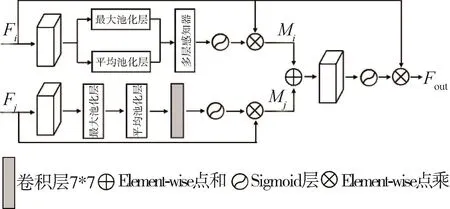
图2 特征增强模块结构
特征增强模块具体公式为
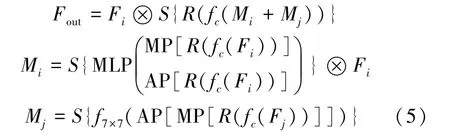
式中:Fi和Fj分别表示在线分支网络和对比分支网络的中间特征图;S(·)表示 Sigmoid层;f7×7(·)表示卷积核为 7*7的卷积层;AP和 MP分别代表平均池化层和最大池化层;Mi,Mj分别表示经过通道注意力和空间注意力的强化中间特征图。这里将在线分支的中间特征进行强化并输出为最终的结果,是因为在线分支网络的权重根据损失函数进行更新,生成的中间特征图具有更真实的全局分布。
2.3 损失函数
在本文中,使用两种损失函数,分别用来计算在线分支网络与对比分支网络之间的特征图的差异和最终生成的SR图像与输入的真实图像GT之间的误差值,下面将介绍两种损失函数。
2.3.1 Smooth L1损失
本文使用Smooth L1损失来计算两个分支网络在训练过程中生成的n个特征图。Smooth L1损失由L1范数损失和L2范数损失组成。L2范数损失是将目标值Y与估计值f(x)的差值的平方和最小化的损失函数。当估计值f(x)与目标值Y相差很大时,容易产生梯度爆炸,而L1范数损失的梯度为常数,具有鲁棒性。通过使用Smooth L1损失,当预测值与目标值相差较大时,由L2范数损失转为L1范数损失可以防止梯度爆炸。
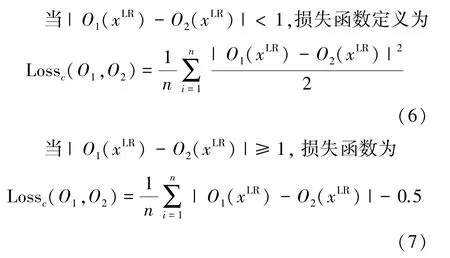
式中:O1(xLR)和O2(xLR)分别为在线分支网络和对比分支网络生成的中间特征图,xLR表示输入的低分辨率图像。
2.3.2 均方误差损失
本文使用均方误差作为整个网络最终生成的结果图与真实图像之间计算的损失函数,其计算过程是将真实值与预测值的差值的平方进行求和取平均得到均方误差值。在图像超分辨率重建中,使用均方误差可以得到更高的峰值信噪比(PSNR)指标。具体公式为
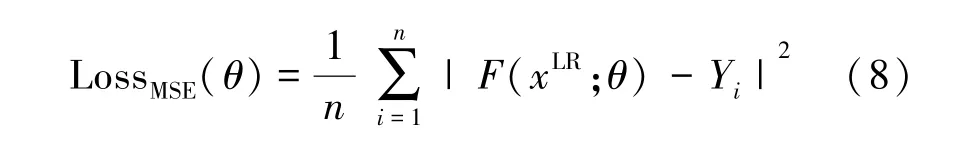
式中:xLR表示输入的LR图像,F(·)表示超分辨率网络模型,Yi表示与LR对应的真实图像GT。在训练过程中,每完成一张输入图像的训练,使用MSE损失函数计算重建图像与真实图像之间的差值,并反向对在线分支网络中各层的参数θ进行更新,θ=(W1,W2,W3,…,Wi;B1,B2,B3,…,Bi)。
3 结果与分析
为了验证本文提出的网络有效性,在图像超分辨率的4个常用数据集上进行实验,分别为Set5,Set14,BSD100和Urban100,并选取比较有代表性的图片进行效果对比。所有的实验均是在NVIDIA GTX1080Ti,Intel(R) Core(TM) i7-4790 CPU@3.60 GHz和8 GB内存,操作系统为Unbuntu18.04上进行。在深度学习框架上使用了pytorch-1.1.0并且使用Adam作为优化器,Adam优化器中参数β1设置为 0.5,β2设置为 0.999。
本文的可视化实验如图3所示。SinGAN方法和KernelGAN方法的结果具有很多不符合真实图像的噪声点,RDN方法的结果趋于平滑,未达到预期的超分辨率任务目标。从图中的效果可以看出,本文提出的方法在最后的生成效果上,比其他方法具有更丰富、更真实的细节特征,图像超分辨率重建的效果较好。

图3 图像超分辨率算法结果对比
另外,为了进一步验证本文提出方法的有效性,采用图像超分辨率领域最常用的两个全参考的图像评价指标进行客观分析:PSNR也称为峰值信噪比,其得分越高,表明图像的生成效果越好;SSIM也称为结构相似性,其指标的范围是[0,1],其得分越高表明图像的失真度越小。表1中的数据均在同一台设备下计算得出,由表1可知,本文提出的方法在PSNR和SSIM指标上均取到较好的结果。
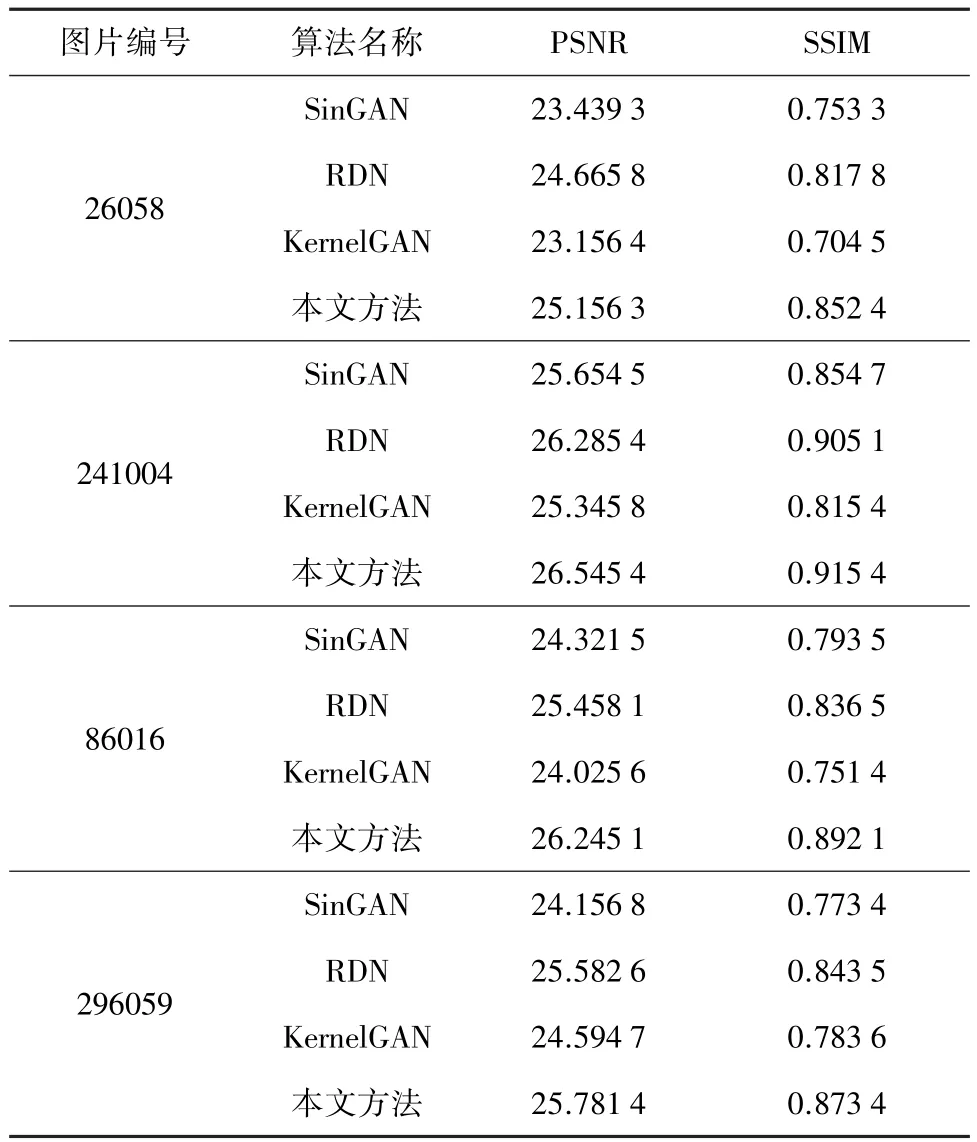
表1 图像超分辨率算法对比
4 结束语
本文提出了一种基于非对称特征差异网络模型用于图像超分辨率重建。首先,设计了一种具有简单结构的非对称特征提取网络,通过使用在线分支网络和对比分支网络处理输入图像,对生成的中间特征图进行误差计算,然后通过设计的特征增强模块,对在线分支网络生成的结果做进一步的增强,提升最后输出图像的质量。在几个数据集和图像的实验结果表明,本文提出的方法在性能上均优于相对比的方法,证明了本文方法的有效性。
在今后的工作中,将进一步探讨对比学习在图像超分辨率领域的作用和优势,利用对比学习的思想,进一步提升非深度网络的特征提取能力和生成泛化能力。
