基于大数据的铜板带成品率预测
2022-05-17张呈熙靖青秀彭建
张呈熙,靖青秀,彭建
(1.江西铜业股份有限公司 贵溪冶炼厂,江西贵溪 335424;2.江西理工大学 材料冶金化学学部,江西赣州 341000)
随着科技发展,各行业对铜板带质量要求越来越高,尽管目前我国是世界铜产品生产、需求、贸易大国[1],但除了几家铜产业巨头之外,我国呈现中小型企业众多、规模小的局面。从整体趋势上来看,我国中小型铜板带企业产能低下[2],难以满足社会对铜板带精密带材的要求[3],并且铜板带行业的自动化程度低下,因此对铜板带进行智能制造建设是我国铜板带企业转型的关键一步,也是必然的一步[4-5]。江西K公司也在进行智能制造建设。根据企业要求,需要对其产品质量进行控制管理,其中铜板带的成品率就是一个重要控制环节。为了实现产品成品率的检测,提前做出产量成品率预警,方便企业管理者及时调整轧制计划[6],提高生产效率,该项目使用大数据技术构建大数据集作为分析数据,采用Spark大批量数据计算引擎实现PCA主成分分析,并提出了BP_AdaBoost算法对其进行预测[7]。
1 铜板带产品质量缺陷
K公司主要以生产铜板带为主,涉及到八达、400、390、600等多种产品规格,生产流程从配料、熔炼、热轧、粗轧、铣面、中轧、精轧到包装入库涉及到多道工序。K公司铜板带生产流程如图1所示。
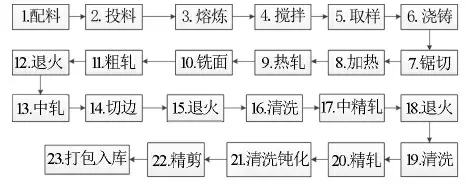
图1 江西K公司铜板带生产流程
由图1可知,其生产加工流程包含了23道工序,因此影响铜板带最终产品成品率的因素是各工序之间的一组参数组合。根据K公司2020年1—6月数据统计,该企业生产报废量最高达到234 906 kg,最低为37 586 kg。各大车间部门铜板带轧制报废量居高不下,不仅造成了大量的浪费,还降低了铜板带生产产能和成品率。
针对历史数据分析,从中挑选出几个产品质量控制关键点,总结得到该车间铜板带产品的主要报废缺陷:1)熔铸,缺陷表现有冷隔、起皮、夹灰;2)热轧,缺陷表现有过烧、起皮、共摊、双面铣打、磨印、毛刺、裂边;3)冷轧,缺陷表现为疤印、坑印、挫伤、公差不好、翻边、错位、共摊、板形、断带、黏结、乳液印、塌卷、折印、油印、退火印、亮印;4)成品,主要缺陷表现为挫伤、刷痕、错位、断带、疤印、包印、共摊、破边、停机印、撞伤、氧化、塌卷、折印、变形;5)设备,缺陷表现主要为故障、跳闸。
2 铜板带大数据数据平台构建
K公司生产车间各轧机操作侧、传动侧的工业参数多,影响铜板带成品率的因素很多。为了得到更好的数据集,为数据分析提供强有力支撑,提高铜板带成品率预测准确性,提高生产效率,需要构建一个数据量大,且数据真实的铜板带生产数据集。
2.1 数据采集
1)西门子PLC智能数据采集。现场轧机实地运行参数数据是利用PLC智能网关进行收集[8],PLC网关使用发布消息队列的方式,将采集之后现场数据以JSON格式数据的形式上传到中移动物联网O ne NET平台进行存储。
2)OneNET物联网数据接收平台。OneNET[9]是一种PaaS物联网平台,由中国移动自主研发,支持多种物联网协议类型,为各行业在跨物联网平台上的消息发布、云端储存、连接提供实质性的帮助。考虑到原始数据源来自各个不同车间的轧机,设备复杂、工艺参数多,存在数据异构性,不方便管理存储,为了实现接收存储PLC端推送过来的现场数据,采用了OneNet平台进行数据的储存。
2.2 数据清洗
数据的清洗采用了Spring Boot数据采集系统,OneNet端的JSON数据通过mqqt协议进行数据的清洗以及解析,结果存入mysql云服务器。为了数据的多样性,该项目搭建了4台运行内存为128 G、数据存储为40 T的高可用hadoop大数据集群用以研究K公司[10];使用hive数据仓库存储数据,采用继承扩写的Flume进行远程数据准实时抽取存储在hadoop大数据平台分布式文件HDFS上[11]。
2.3 Flume数据抽取
Flume[12-13]是Cloudera提供的一个适用性高、可靠性高的,分布式的海量日志采集、聚合和传输的系统。它由代理节点(Agent)和收集节点(Collector)组成,在Flume中最重要的抽象是数据流(data flow),数据流描述了数据从产生、传输、处理的过程。为实现铜板带车间数据及时对接,提高数据的准时性,及时对采集的数据进行ETL处理,研究搭建flume集群,并利用集群进行远程实时监控抽取收集数据。
2.4 数据预处理
由于采集到的数据具有噪音,并且数据维度较多,为方便更好地预测成品率,使用大数据分析Spark计算框架[14]编写PCA主成分分析代码对采集的数据进行降维[15],Spark实现对PCA的过程描述。
1)输入:训练dataset D=x(1),x(2),…x(m),低维空间维数d′;
Step1,去中心化均值操作:
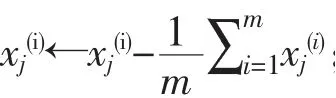
Step3,利用特征值分解/奇异值分解矩阵X XT;
Step4,取最大的d′个特征值所对应的特征向量w1,w2,...,wd′;
Step5,将原样本矩阵与投影矩阵相乘,得到降维后数据集X′。其中X为m×n维,W=[w1,w2,...,wd′]为n×d′维;
2)输出:降维后的数据集X′。
3 基于BP_AdaBoost神经网络的铜板带成品率预测
3.1 BP神经网络
BP神经网络(BP Neural Network,BPNN)是一种多层前馈神经网络[16-18],主要特点是信号正向反馈,误差反向传播。在正向传递中,输入信号从输入层经隐含层逐层处理,直至输出层。如果输出层中的实际值与预期输出值之间的误差太大或未达到学习时间,则将开始误差的反向传播。误差的反向传播以输出误差为基础来调整每个隐藏层的权重,然后再次开始向前传播,计算错误并重复循环直到满足指定要求。BP神经网络结构见图2。
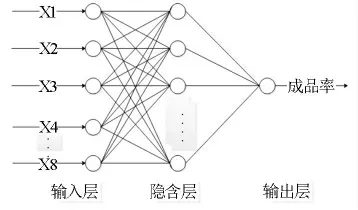
图2 BP神经网络结构
BPNN抽象为非线性函数,向量X(x1,x2,…,xn)是BPNN的输入自变量,向量Y(y1,y2,…,yn)是BPNN的因变量预测值,wij和wjk为网络的权值,BPNN有着很好的非线性映射关系;然而对于单独的BPNN在训练中容易产生过度拟合或拟合不足的现象,堕入局部最优解。为了解决这个问题,可以利用AdaBoost算法进行改进。
3.2 BP_AdaBoost神经网络建模
AdaBoost算法将多个“弱”分类器合并成为一个新的强分类器[19-20],提供更好的数据训练样本。针对单个BPNN过度拟合或拟合不足的问题,采用AdaBoost算法改进BP神经网络得到BP_AdaBoost模型[21-22],见图3。该模型将BPNN作为弱分类器,通过训练弱分类器学习者,AdaBoost算法增加了训练效果较差的样本和具有较强学习能力的弱样本的权重,减少了分类成功和学习能力差样本的权重,然后将这些弱学习者进行线性组合以提高模型的泛化性能,经过多次迭代后,最终强分类函数由弱分类函数加权得到,并且由多个弱学习者BPNN组成新的强分类器。
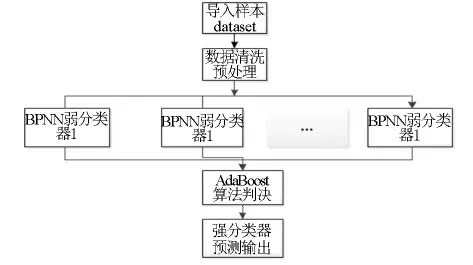
图3 BP_AdaBoost模型算法结构
BP_AdaBoost算法主要步骤如下:
2)输出,输出预测f(x)。
Step1,初始化训练数据的权重:D=(w11,w12,…,w1n)。
从样本空间中寻找m组训练数据,每组数据的权重均为:
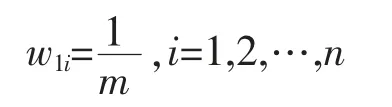
依据样本input/output维数确定BP结构,并初始化BP权值和阈值。
Step2,弱分类器BP预测。t=1且当t≦m时,训练第t个弱学习者,用dataset训练BPNN得到预测分类结果g(t)的预测误差和et,期望分类结果为y,其计算公式为:
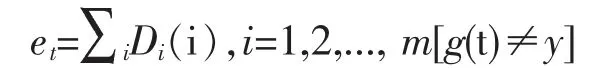
Step3,根据step2得到的计算预测分类结果权重。
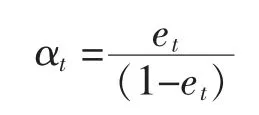
Step4,更新dataset的权重分布,其中是归一化因子。
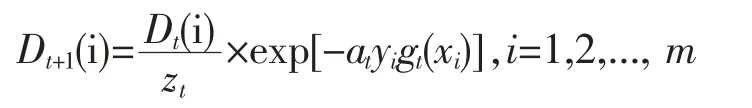
Step5,训练T轮后,获得T组弱分类函数Gj(x)。由T组Gj(x)构成强分类函数f(x),该强分类函数为:
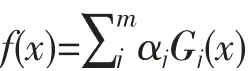
3.3 BP_AdaBoost神经网络预测铜板带成品率
1)试验样本挑选及模型参数设定。K公司的铜板带生产以精剪阶段的成品率衡量产品的生产效率,然而全厂精剪的实际成品率受到从来料到精剪前的22道工序产品成品率的影响。该公司的最终精剪成品率在实际生产中取决于铸锭重量、锯后重量、熔铸成品率、洗后重量、热轧成品率、成品重量、单卷成品率、酸洗重量等8个因素,因此实验挑选以上8个因素作为BP_AdaBoost的输入变量,用来预测精剪成品率。确定神经网络的结构为8-11-1,通过构建的铜板带生产数据集的清洗和挑选,从半年以来4 134组训练样本中随机抽取4 000组数据作为模型训练样本,134组数据作为预测样本。表1为试验样本的部分数据。试验利用mapminmax函数将数据归一化,使数据属于[0,1]之间,模型使用10个BPNN弱学习分类器,最大训练次数为100,学习速率值为0.1,训练目标值是0.000 1,把预测误差大于0.1的作为应该加强学习的样本。为了分析AdaBoost改进后的BP和单独BP的预测效果,采用对比两者预测误差的方式验证试验。
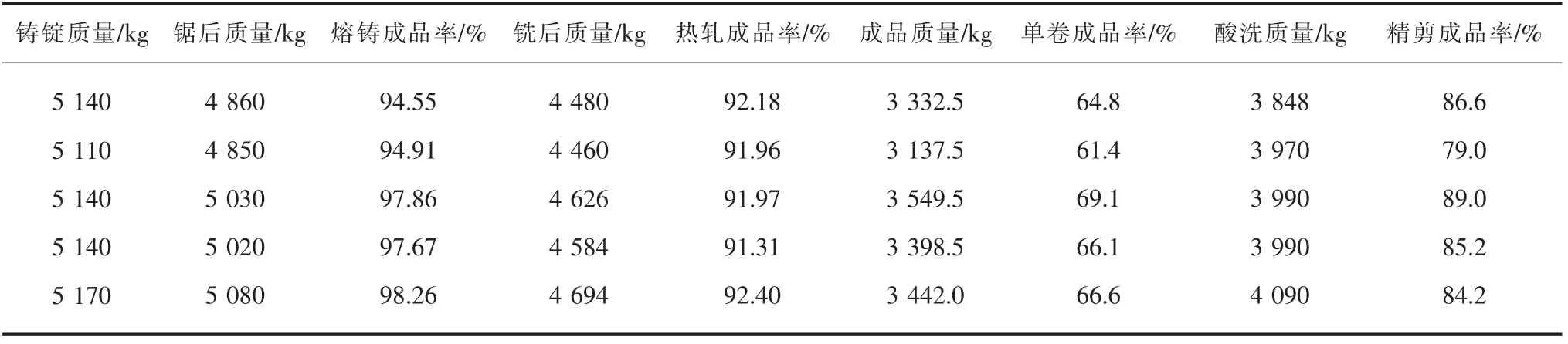
表1 2020年1—6月部分试验样本
2)铜板带成品率预测试验结果分析。模型训练到31次时,达到训练精度要求,最佳性能是0.000 887 17。图4为BP_AdaBoost模型预测拟合回归线。
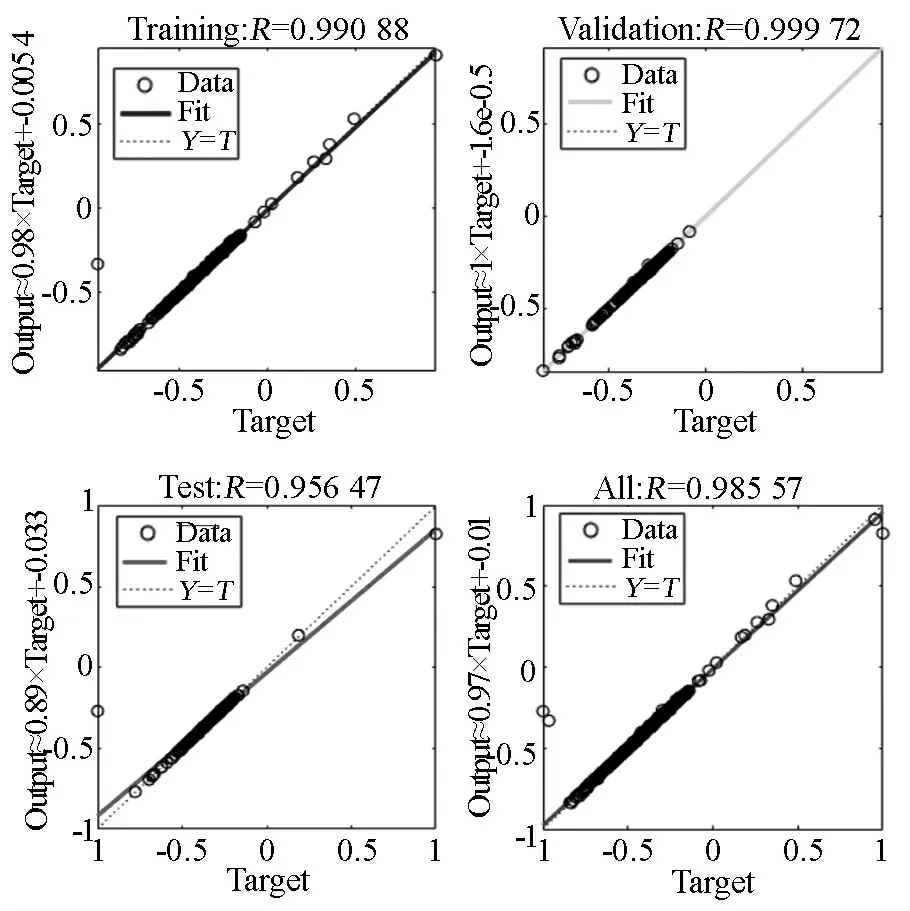
图4 BP_AdaBoost模型预测拟合回归线
由图4可知,模型训练拟合度为0.990 88,验证的拟合度为0.999 72,测试拟合度为0.956 47,综合拟合度为R=0.985 57,拟合度均大于0.95,接近于1,模型拟合效果好。成品率预测误差对比,见图5。
由图5可知,单独的BPNN模型预测的误差在[0,0.8]之内,而基于AdaBoost算法优化的BPNN模型预测误差绝对值在[0,0.3]之内。比较两者的铜板带成品率预测误差曲线,可以看出模型BP_AdaBoost的预测精确度更高,误差低,精剪成品率最大预测误差低于0.3,接近于实际值。结果表明,模型BP_Ada-Boost的铜板带精剪成品率预测性能优于未改进的BPNN模型,具有更好的精确度,能够更加准确地预测K公司精剪成品率。
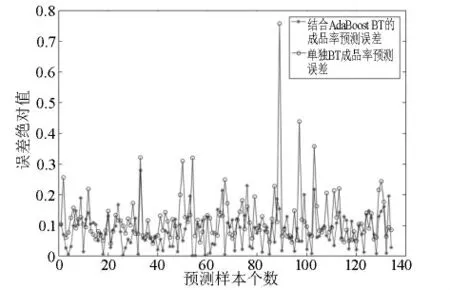
图5 成品率预测误差对比
4 结语
本研究统计了铜板带表面缺陷,为K企业构建了大数据存储平台,开发了Spark的主成分分析算法PCA代码,对具有噪音的数据进行降维预处理,建立了BP_AdaBoost模型,并且利用该模型对4 134组实验数据进行训练并预测,结果表明BP_AdaBoost模型具有很好的非线性映射关系,并且相比单独BPNN模型,拟合度高且性能更好,可以根据全厂轧制生产工序中关键环节的质量控制指标实现K企业铜板带产品最终成品率的预测,对于铜板带企业实现智能制造具有现实意义。
