Winograd 快速卷积相关研究综述
2022-05-17黄立波
童 敢,黄立波
国防科技大学 计算机学院,长沙410073
卷积神经网络(convolutional neural network,CNN)在计算机视觉、自然语言处理等任务上应用广泛。越来越多的研究尝试加速CNN 的训练和推理,使用快速卷积算子就是其中的重要方法。快速卷积算子包括快速傅里叶变换(fast Fourier transformation,FFT)卷积和Winograd 卷积,这类卷积通过把输入特征映射和卷积核线性变换到相应的空间,将原来的运算转换为对应位相乘,运算结果再经过逆线性变换即可得到原特征映射空间的输出。
在“变换-运算-逆变换”的过程中,乘法运算的次数比直接卷积有可观的减少,而代价则是加法运算次数的增加。在绝大多数现代处理器上,加法的执行效率远高于乘法,因此可以使用快速卷积算子来提高模型执行效率。由于FFT 变换是映射到复数空间,Winograd 卷积运算过程中对内存的占用只需FFT卷积的一半,使其迅速成为最流行的快速卷积算子。
但是直接应用Winograd 卷积存在很多挑战。首先,基本的Winograd 卷积适用范围有限,仅可在单位步长、小卷积核的二维卷积上应用,在大卷积核上应用则会有数值不稳定的情况。其次,由于线性变换和逆线性变换的复杂性,快速卷积算子在特定平台上的优化难以实现,比如利用并行性和数据局部性。此外,Winograd 卷积与以剪枝和量化为代表的网络压缩技术难以直接结合,因此不易在算力不足和有能耗限制的平台上部署实现。针对这些问题,研究者做了大量的工作,但至今还未有公开的文章对相关工作进行系统性的总结。为给后续研究者提供参考,本文从算法拓展、算法优化、实现与应用三方面综述Winograd 的发展,并对未来可能的研究方向做出展望。
1 Winograd 卷积原理
Winograd 于1980 年提出了有限脉冲响应(finite impulse response,FIR)滤波的最小滤波算法。最小滤波算法指出,由拍的FIR滤波器生成个输出,即(,),需要的最少乘法数量((,))为+-1。以(2,3)为例,涉及到的乘法数量为((2,3))=2+3-1=4,从6 次降低到了4 次。
2015 年,Winograd 最小滤波算法初次被应用在CNN 中,利用减少的乘法次数提升卷积算子性能。如果用矩阵的形式表示Winograd 最小滤波算法,则可以得到:

其中,为滤波器向量,为输入数据向量,为输出数据向量,表示滤波器变换矩阵,表示数据变换矩阵,⊙表示矩阵的对应位相乘(Hadamard积),表示输出变换矩阵。通过嵌套一维最小滤波算法(,),可以得到二维的最小滤波算法(×,×):
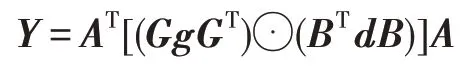
二维最小滤波算法所需乘法数为(+-1),而原始卷积算法需要乘法数为×××。对于(2×2,3×3)而言,乘法次数从36降低到了16,减少了55.6%。
根据二维矩阵形式,可以自然地将Winograd卷积分为四个分离的阶段:输入变换(input transformation,ITrans)、卷积核变换(kernel transformation,KTrans)、对应位相乘(element-wise matrix multiplication,EWMM)和输出变换(output transformation,OTrans),如图1所示。
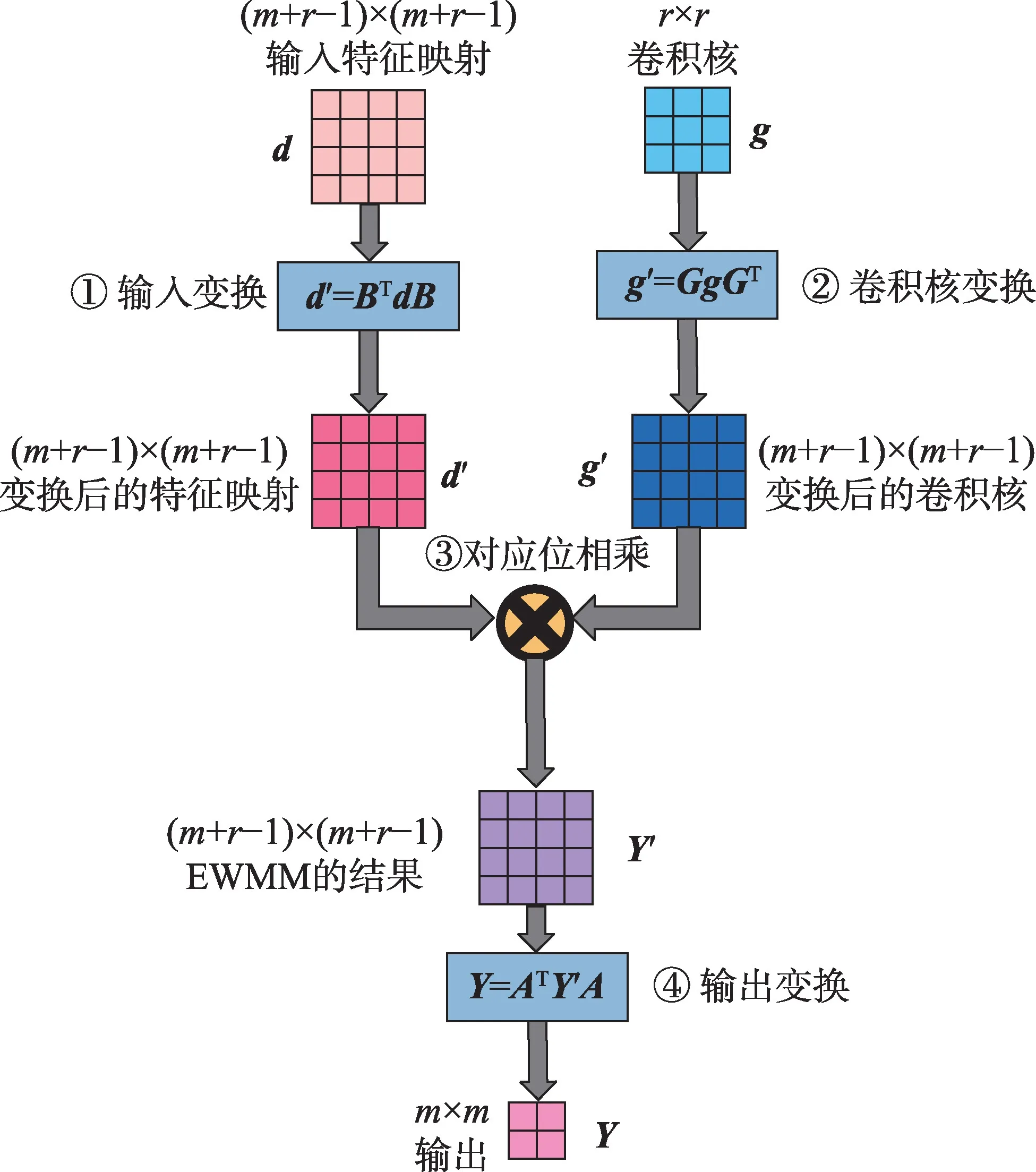
图1 Winograd 卷积的四个阶段Fig.1 Four stages of Winograd convolution
对于二维卷积算子,需要先将卷积输入划分为相互重叠的(+-1)×(+-1)的切片,切片之间有-1 的重叠部分。实验表明,(2×2,3×3)在多个卷积上的实现性能超过了NVIDIAcuDNN,而且使用的内存大小远低于FFT 卷积。
2 Winograd 卷积的一般化和拓展
2.1 Winograd 卷积的一般化
基本的Winograd 卷积仅支持=3 和=2 的二维卷积算子,且切片大小不超过6,无法满足现代CNN 中丰富的卷积算子类型,需要对其进行一般化。Winograd 卷积的一般化主要分为四个方向,分别是支持任意维度、支持任意切片大小、支持任意常规卷积、支持特殊卷积。
三维卷积是三维CNN 的主要组件,常用于处理空间相关的信息。通过对一维Winograd 卷积进行嵌套,可以得到其二维形式,重复进行嵌套则可以得到任意维度的Winograd 卷积。Budden 等给出了维Winograd 卷积的一般形式,并将二维Winograd 卷积视为特殊情况在CPU 上实现,但并未实现三维的情况。其他研究者使用了同样的嵌套方法,并针对特定平台完成了三维Winograd 卷积的实现。由于不同维度上算法的实现有统一性,Shen 等提出了二维、三维统一的现场可编程逻辑门阵列(field programmable gate array,FPGA)模板实现。Deng 等提出了可变分解方法,支持三维卷积的同时也支持了非单位步长的卷积。
更大的切片大小会减少切片之间的重叠部分,但同时也会带来更大的数值误差,因此在对精度要求不太严格的场合会直接使用更大的切片尺寸以提升性能。大尺寸的卷积核也在卷积网络模型中经常出现,通常为了保持Winograd 卷积的精度,这里卷积也会被替换为小尺寸的卷积。Lu 等在FPGA 上评估了大尺寸切片分别在=3 和=5 下的精度情况,实验表明小的切片尺寸在=3 时可以保持模型的高精度。Huang 等也完成了类似的工作。Mazaheri等则基于符号编程构建了支持不同硬件后端的实现,同时也支持不同尺寸的切片。
此类直接实现的方法会在大尺寸切片和大尺寸卷积核上显著损失精度,因此将这类卷积分解为更小的卷积成为了研究者常用的方法。Yang 等使用分解方法统一了常规卷积、depth-wise 卷积以及分组卷积,而大切片尺寸、大卷积核卷积和非单位步长卷积也都可以通过分解方法转换为基本的Winograd 卷积。常用的分解单元实现包括(2×2,3×3)、(2×3,3×3)、(3×2,3×3)、(3×3,3×3)等。Liu 等同样基于分解方法,在FPGA 上实现了使用相同资源支持任意卷积核大小的Winograd 卷积。利用大卷积核上计算的对称性,Sabir 等使用近似计算技术支持了=5 大小的卷积核。
包括空洞卷积和转置卷积在内的特殊卷积常用于图像分割、超分辨率等领域。空洞卷积的Winograd形式被提出用于支持扩张为2 和4 的情况,原理是扩张输入变换矩阵的规模。Shi 等通过预定义的分解和交织操作将转置卷积转换为多个基本卷积,从而实现了对转置卷积的支持。
总结Winograd 卷积一般化研究工作相关文献如表1 所示。通过结合嵌套方法和分解方法,理论上可以实现CNN 中所有卷积的Winograd 卷积形式。

表1 Winograd 卷积的一般化Table 1 Generalization of Winograd convolution
2.2 Winograd 卷积的拓展
除了一般化到各类卷积,还有一些研究尝试拓展Winograd 卷积本身的线性变换。Winograd 算法族首先将输入的切片和卷积核线性变换到Winograd域,执行Hadamard 积之后再逆变换回特征映射域。对于指定的卷积核和切片尺寸,线性变换矩阵、、是给定的。卷积可以表示为多项式乘法,将卷积核和输入向量的元素分别映射到多项式()和()的系数,则输出向量(和的卷积)的元素等于多项式()=()()的系数。Winograd 卷积算法族基于多项式上的中国剩余定理(Chinese remainder theorem,CRT)对不可约且互质的多项式同余系统内的多项式取余即可得到卷积输出,对同余方程组进行求解即根据多项式的系数得到线性变换矩阵的具体解。因此,对Winograd 卷积的拓展可以从两个角度入手:一是使用不同的变换,将运算映射到不同的域;二是采用不同的变换矩阵生成多项式。
Barabasz 等将Winograd卷积算法中使用的卷积多项式拓展为高阶多项式,实验表明使用二阶多项式会显著降低误差,但同时也会增加乘法次数,因此需要在乘法次数和浮点数精度之间做权衡。Ju等提出的双线性多项式与此方法原理相同,保持了大卷积核上的数值稳定性。而Meng 等将多项式乘法拓展到复数域,利用共轭复数乘法的对称性可以进一步减少乘法数量。Liu等提出将余数系统(residual number system,RNS)引入到Winograd 卷积,通过取余的操作实现Winograd 卷积的量化操作,进一步支持更大的输入切片尺寸而不会引入显著误差。Xu等创新地引入了费马数变换(Fermat number transformation,FNT),使用这种变换一方面可以确保中间运算结果均为无符号数,另一方面还将所有的计算都简化为移位和加法操作,有利于在FPGA等设备上实现。
根据最小滤波算法的描述,Winograd 卷积已经达到了最少的乘法运算次数。FFT 卷积由于使用了傅里叶变换,在乘法次数和内存占用上远高于Winograd 卷积,但保持了很好的精度。探索不同的变换可能会引入更多的乘法次数,但若能保持模型精度也是可选的实现技术。而生成多项式的选择则是在不增加乘法次数的前提下减少了精度损失,且无需修改算法,因此在应用上更具有现实意义。
2.3 其他
Winograd 卷积还被用于和Strassen 算法结合。Strassen 算法是一种减少矩阵运算次数的算法。虽然有研究指出Strassen 算法减少的运算远小于Winograd 算法,但该工作将在Strassen 算法中使用的卷积替换为Winograd 卷积,结合了两者带来的运算减少实现了更进一步的优化。Winograd 卷积也被应用在加法神经网络上,用加法代替乘法,保持了相当的性能且降低了功耗。
3 Winograd 卷积的优化
3.1 剪枝和利用稀疏性
剪枝是CNN 优化中常用的有效技术。剪枝主要用于对CNN 中卷积算子的权值进行修剪,对输出影响很小的权值会被置零。剪枝后的卷积核成为稀疏张量,这带来了两点好处:一是按照特定的压缩格式存储稀疏的卷积核张量权值可以减少内存使用;二是稀疏张量中大量元素为0,因此可以减少卷积的计算量。对于卷积层和全连接层的卷积可以将参数减少90%以上。但在Winograd 卷积上直接应用剪枝是有困难的,因为稀疏的卷积核在变换到Winograd 域后又会变回稠密矩阵,这违背了剪枝的初衷。
Liu 等首 先提出 在Winograd 卷积和FFT 卷积上应用剪枝,在卷积核变换之后引入剪枝以得到稀疏的Winograd 域卷积核。他们在后续的研究中又将线性整流单元(rectified linear unit,ReLU)置于输入变换之后,结合稀疏的卷积核进一步提升了稀疏性,如图2 所示,Wang 等也使用了相同的剪枝方法。Li等提出在本地学习剪枝系数,减少了剪枝带来的精度损失。Lu 等和Shi 等也分别在卷积核变换后引入了剪枝。Yu 等指出,添加ReLU 的方法改变了网络结构,重训练的代价也大,因此他们提出在输入变换前进行结构化剪枝传递稀疏性,同时对卷积核进行剪枝。为了兼顾速度和准确性,Zheng 等在Liu等工作的基础上,提出了动态学习批量的大小。

图2 在Winograd 卷积中应用ReLU 以实现剪枝Fig.2 Pruning by applying ReLU in Winograd convolution
在对稀疏性的利用上,包括计算优化和模型压缩两方面。Park 等提出Zero-Skip 技术,软硬件上分别实现在EWMM 阶段计算时跳过零权值,是经典的计算优化方法。Choi 等首次提出了利用Winograd 卷积剪枝的模型压缩方法,区别于Liu 等工作,他们使用池化代替了ReLU。Yang 等提出了一种规则的剪枝模式,以优化模型的压缩,Wang 等则是提出了一种新的编码方式来确保压缩与解压缩。
Winograd 卷积的剪枝技术主要相关工作的总结与分析如表2 所示。

表2 Winograd 卷积中的剪枝Table 2 Pruning in Winograd convolution
3.2 低精度与量化
Winograd 卷积也可以与量化结合,牺牲精度以换取更小的模型和更快的运算速度。Zhuge 等首先使用了8 位定点数的Winograd 卷积,但与16 位定点数相比误差显著。Zhang 等使用的精度与他们一致,但引入了细粒度调度,因此在性能上有显著提升。Meng 等在变换后的卷积核上应用量化,使用精度缩放技术量化到INT8 精度上。Liu 等在把Winograd 卷积拓展到余数系统的同时也使得可以将卷积量化到INT8 精度。Ye 等实现了12 位的混合卷积FPGA 实现,还有一些研究也使用了8 位的量化精度。Han 等还进一步探索了ARMCPU 上的2~8位量化精度。Li等直接在Winograd域插入线性量化,对2~8 位的量化精度进行了全面评估。他们的实验表明,8 位以下的量化精度会带来不可忽视的模型精度下降。
对于低精度和量化带来的精度损失,Fernandez等提出通过学习训练减少INT8 精度Winograd 卷积的误差,与剪枝技术中的重训练原理相同。而Ahmad 等提出对精度损失建模,为特征映射和卷积核使用不同的量化级别。Barabasz用勒让德基多项式取代Winograd 变换中的规范基多项式,提出基于基变技术的9 位量化精度Winograd 卷积,维持了数值稳定性。Sabir 等在特征映射切片上应用量化,应用粒子群优化技术找到量化的阈值以保持精度。可以根据他们的工作,总结缓解量化带来的精度损失的方法如表3 所示。

表3 缓解量化Winograd 卷积精度损失的方法Table 3 Methods to alleviate accuracy loss of quantization in Winograd convolution
3.3 数值稳定性
Winograd 卷积在初期只应用在3×3 的卷积核和小的输入切片上,原因在于Winograd 卷积计算中内在的数值不稳定性。在更大的卷积核或输入切片上,Winograd 变换的多项式系数呈指数增长,这种不平衡会反映在变换矩阵的元素上,造成很大的相对误差。Vincent 等指出这种数值不稳定性的来源是变换中大尺寸的范德蒙德矩阵,提出精心挑选出最小指数增长的值相应的多项式,同时对变换矩阵进行缩放以缓解数值不稳定性。
Barabasz 团队从数学的角度在Winograd 卷积数值稳定性的维持上做了大量工作。他们首先提出使用超线性多项式来构造Winograd 变换矩阵,在运算次数和计算精度之间进行平衡,Ju 等提出的双线性方法与他们的想法一致;之后他们又提出基变技术,通过额外引入一个正则化变换矩阵,在实现了量化的同时保持了数值稳定性;他们进一步的研究表明,线性变换过程中浮点数乘加的运算顺序会影响到结果的准确性,这同样是由于变换矩阵中元素的指数级不平衡导致的,通过霍夫曼编码运算顺序就可以减少这种误差,从而允许更大的切片尺寸和卷积核尺寸。
在前文提到的工作中,也有很多研究尝试优化Winograd 卷积的数值稳定性,总结相关工作的主要思路有四点:
(1)将卷积拆分为小切片或小卷积核的Winograd 卷积,如分解方法;
(2)对Winograd 变换作出修改映射到精度更高的空间,如使用超线性多项式;
(3)选择变换矩阵生成多项式中相对误差更小的,如使用变换矩阵最大最小元素比值最小的;
(4)更改计算中乘累加的顺序,优先累加乘积更小的结果。
其中分解方法已经大量使用于研究中,而选择变换矩阵的方法由于无需修改Winograd 卷积算法本身也具备直接应用的可行性。而超线性变换会突破现有Winograd 卷积实现的架构,在数学上论证该方法优越性之前距离实际应用还有一定的距离。
4 Winograd 卷积的实现、优化与应用
4.1 实现
Winograd 卷积带来的高性能使得研究者们迅速将其部署到各类平台,除了CPU、GPU 等,还包括对效率和功耗有严格要求的FPGA 平台、移动端和边缘计算设备。对实现了Winograd 卷积的实现进行统计,得到特定平台上的研究占比如图3 所示。

图3 Winograd 卷积实现的平台分布情况Fig.3 Platform distribution of Winograd convolution implementation
从图中可以看到,在FPGA 上的Winograd 卷积实现几乎达到了总数的一半。这个具有统治地位的比值一方面说明Winograd 卷积在硬编码的FPGA 平台上更容易实现并发挥优势,另一方面也说明越来越多的人工智能应用在向低功耗的平台上部署。与之类似的是移动端和边缘计算上的实现,在这类平台上计算资源十分有限,对功耗的要求也更高,因此Winograd 卷积带来的乘法数量减少是有重大收益的。CPU 端和GPU 端具备很强的算力,通常用于神经网络的训练,因此相关工作也集中在对训练速度的优化上。而也有部分供应商仍在使用云服务器上的CPU 和GPU 为用户提供人工智能服务,因此相关研究也具备一定的市场。GPGPU-Sim 作为模拟GPU 的软件平台,可以模拟对GPU 硬件的修改,在GPGPU-Sim 上的研究可以为SIMT 体系结构的设计提供方向。
对于上述传统平台,部分研究实现了相应的深度学习框架,在其中集成了Winograd 卷积以提升模型执行效率。Perkins实现的Cltorch 是基于OpenCL实现的硬件无关的后端平台。Xiao 等实现了一个Caffe 模型到FPGA 映射的工具,基于动态规划选择是否应用Winograd 卷积。Dicecco 等设计了CPUFPGA 异构平台上的开源后端框架,但仅支持单位步长的Winograd 卷积。Demidovskij 等还实现了面向Intel 硬件的、支持Winograd 卷积的软件栈,面向包括CPU、集显、神经计算棒等生成高效负载。
值得注意的是,除了上述传统平台,还有一些研究尝试将Winograd 卷积部署在其他非传统平台上。比如基于内存的计算平台,Lin 等在ReRAM 上实现了Winograd卷积,基于切片提高了数据重用,而Ghaffar等则基于DRAM 架构实现了8-bit 的量化卷积。随机计算和近似计算也用于实现Winograd 卷积。Chen 等实现了向量DSP(domain specific processor)上的三维Winograd 卷积。而第五代精简指令集计算机(reduced instruction set computer-V,RISC-V)指令集作为新流行的开源指令集,同样吸引了部分研究者在相关平台上部署人工智能应用。Wang 等通过拓展一条(2×2,3×3)的卷积指令并新增计算模块,在一个开源RISC-V框架上实现了Winograd 卷积。
4.2 优化
性能是部署在特定平台上必须要考虑的事情,对于不同的平台,研究者们采用的优化方法也大相径庭,现分平台总结相关优化技术如下。
Heinecke 等将即时(just-in-time,JIT)编译优化技术用于加速x86 CPU 架构上直接卷积和Winograd卷积在小卷积核上的实现,在编译过程中提前计算卷积核调用时的地址偏移量。Ragate依赖编译器的自动向量化,可将计算阶段转换为批量矩阵乘法(batched general matrix multiplication,BGEMM),利用CPU 的高级向量扩展(advanced vector extensions,AVX)指令集实现性能提升。Jia 等提出了CPU 上的自定义数据布局,同样利用CPU 上的向量化指令实现高效访存。在数据重用方面,Gelashvili 等利用CPU 的L3 Cache 驻留卷积核实现了对卷积核的重用,但无法支持通道数过大的卷积,而Wu 等利用Winograd 卷积中的相似性也可以实现CPU 上的深度数据重用。
在GPU 上同样可以将Winograd 卷积的计算阶段转换为批量矩阵乘法,然后调用高效的矩阵乘法实现。Lan 等和Wang 等分别在GPU 上实现了三维Winograd 卷积,但前者的计算阶段直接调用了cuBLAS 中的矩阵乘法实现,后者则是手动编写了特定的实现。Hong 等在大规模GPU 集群上利用Winograd 卷积的数据并行性和切片内并行性实现了多维并行训练。Jia 等利用MegaKernel 技术将Winograd 卷积的四个阶段融合,同时利用精心设计的任务映射算法可在GPU 上达成显著的性能提升。另外,Yan 等将源代码和汇编(source and assembly,SASS)级别的汇编器优化用于优化Winograd 卷积,通过合并全局访存并使共享访存无冲突,利用缓存设计流水线,提高计算强度,还利用常规寄存器填补了谓词寄存器不足的缺陷。
与CPU和GPU不同的是,FPGA上没有高效的神经网络计算库可供直接调用,但可定制的特性给予了FPGA 上进行优化更多可能性。Cariow 等首先研究了Winograd 卷积硬件实现的最小需求,并在FPGA 上实现了Winograd 卷积的基本模块。在数据重用方面,Aydonat 等利用流缓冲区暂存所有的中间特征映射实现了高能耗比的FPGA 实现,而Lu等设计了线缓存结构来暂存特征映射并重用不同切片的数据,并在后续工作中针对稀疏的情况进行了优化。
由于FPGA 可定制化的特性,对计算资源的充分利用是优化的重点。一些研究统一了二维和三维的Winograd,构建了FPGA 上的统一模板。另一些研究聚焦于统一Winograd 卷积和矩阵乘的实现,以最大化模块的可重用性。对硬件实现方案进行系统评估才能最大化资源利用率并提升计算效率。Ahmad 等和Liu 等还对FPGA 上实现Winograd 卷积进行了全面的设计空间探索。此外,还有其他工作也在FPGA 上实现了Winograd 卷积并对设计空间进行了探索,他们还在设计高效数据布局等方面进行了大量研究。
各个平台上的优化虽然方法各异,但相互有共同之处。例如,CPU 和GPU 均为多级内存层级体系结构,因此均可利用各级缓存驻留数据实现数据重用。三个平台上的优化方法总结比较如表4 所示。
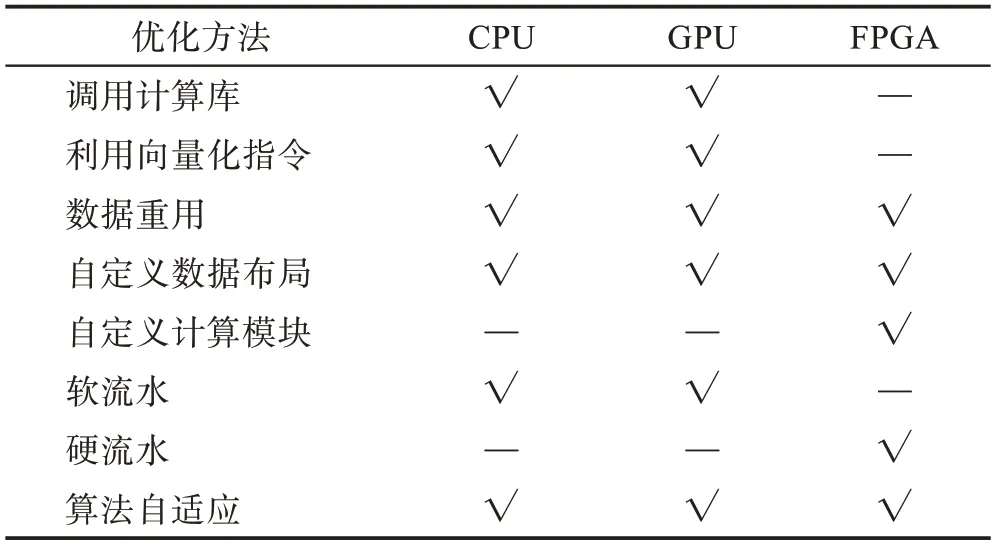
表4 不同平台上的性能优化方法Table 4 Performance optimization methods on different platforms
4.3 应用
Winograd 卷积提出的初衷是为了实现高性能卷积,但由于其内在的数值不稳定性,初期仅有小卷积核 上应 用Winograd 卷积。CPU 上和GPU 上均有对FFT 和Winograd 的性能进行的比较,他们的结论是一致的,即FFT 在大尺寸卷积核的卷积上性能更好,而Winograd 卷积适用于小尺寸卷积。而Zlateski等指出,随着CPU 的内存带宽越来越大,Winograd 卷积的性能优势也会减少。不过随着拓展和优化的进一步深入,Winograd 卷积也成为了最适合小尺寸卷积核的快速卷积实现,在各神经网络计算库和深度学习编译框架上均有实现。
Winograd 卷积旨在加速卷积以提高CNN 模型的执行效率,对实时性有要求的场景都可以尝试使用。Zhuge 等利用混合卷积实现了人脸识别系统。Lou 等基于三维Winograd 卷积实现了用于动作识别的加速器。Shi 等和Yen 等分别将其用于实时超分辨率,但在上采样上有区别,前者使用的是转置卷积的Winograd 实现,而后者使用shuffle 层代替了转置卷积。Yao 等还实现了穿戴设备上的语音识别加速器,应用了一维的8 bit 整数Winograd 卷积网络。Winograd 卷积的应用不止于此,未来还可以有更多对实时性有要求的人工智能应用Winograd卷积实现,尤其是在移动端、物联网和边缘计算设备上。
5 总结与展望
Winograd 卷积是当前应用最广泛的快速卷积算子。从引入到CNN 至今,其使用范围随着研究的深入逐渐覆盖了现代CNN 中的各类卷积,与剪枝、量化等技术的结合也走向成熟。在各种平台深度学习框架和神经网络库中均已集成Winograd 卷积,可以为各类硬件平台生成高效的工作负载。
这里对未来的研究方向给出几点展望。在算法本身的优化方面,数学方法仍然是突破Winograd 卷积局限性的根本方法,由于其内在的最小乘法次数属性,有望在未来的研究中基本取代现有的基于一般矩阵乘的卷积。现已有从数学角度解决数值稳定性的方法,但由于引入了新的计算机制或额外的步骤,在各平台上还没有高效的实现,对硬件友好优化方法的研究可能会是后续研究的重点方向。在实现与应用方面,FPGA 平台上可以轻松为Winograd 卷积定制软硬件协同的实现,但现有FPGA 实现对数值稳定性的关注太少。FPGA 实现具备很高的灵活性,可参照相关优化方法率先部署更快更精确的Winograd卷积。由于Winograd 卷积数据流的内在复杂性,在CPU、GPU 这类通用计算平台上,如何利用好算力和内存层级还有待进一步研究。比如Winograd 四个阶段现大多实现为四个分离的计算核,CPU 上已经有研究尝试利用L3Cache 进行融合。但GPU 上尝试的融合属于任务调度层面的融合,利用高速缓存的融合还未有相关研究。GPU 等设备近年都引入了类似TensorCore的高性能运算单元,但Winograd 卷积相关研究均未利用这类部件,因此对新硬件特性的利用也可以成为另一个突破口。此外,在非常规平台的实现明显滞后于理论,比如基于内存的计算平台、开源RISC-V框架上的实现还局限于小卷积核,下一步可以尝试在这类平台上实现更一般化的Winograd卷积。
