基于StarGANv2的多风格字体生成研究
2022-05-16李金金徐向紘龚心满
李金金,徐向紘,龚心满
(1.中国计量大学 机电工程学院,浙江 杭州 310018;2.中国计量大学 艺术与传播学院,浙江 杭州 310018)
在大数据环境的冲击下,我国中文字体设计面临着严峻的考验,人们对个性化的风格字体的需求越来越多,如何实现多风格的汉字生成是当前的重要研究方向。字体生成旨在自动生成特定字体的字符并创建字体库,大部分研究采用图像风格迁移的方法来实现。传统的汉字生成方法[1-2]大部分是对已有的汉字结构和笔画进行拆解并建模,然后根据想要生成的字符结构通过重组这些笔画来实现字体风格迁移。但是这种方法步骤复杂,容易受到先验知识的影响,并且只关注到汉字字符的局部笔画结构特征,而忽略了汉字的整体书写风格。随着人工神经网络深度的突破,目前深度学习算法在多个领域的应用都远远超过了传统机器学习算法,如目标检测、人脸识别、图像分类、图像超分辨率和机器翻译等。在汉字字体生成与风格迁移中,越来越多的研究者使用卷积神经网络(Convolutional Neural Networks, CNNs)或生成对抗网络(Generative Adversarial Networks, GANs)来实现。最典型的汉字风格迁移模型zi2zi[3]是基于pix2pix[4]的模型进行改进,该模型可以实现从源风格的字体转换成多种目标域风格的字体,但是需要大量一一配对的数据集,收集困难。伯克利的[5]BAIR实验室和Adobe研究院合作提出leave-one-out训练方法,只使用其中一小部分字母就能生成大部分未见过的字母,多内容的GAN模型由一个堆叠的CGAN架构组成,用于预测粗略的字形形状,以及一个OrnaNet预测最终字形的颜色和纹理。Lyu等[6]用生成对抗网络生成书法字体,提出使用自编码卷积神经网络作为监督网络,将笔画信息提供给生成器。Sun等[7]提出PEGAN的方法,使用具有级联连接和跳跃连接的生成器将多尺度特征融合,并结合生成对抗损失、感知损失等多个损失函数,交替训练生成器和判别器来合成字体图像。曾锦山等[8]受汉字田字格书写的启发,提出一种基于田字格变换的自监督方法来指导网络模型提取更高质量的特征,所设计的田字格几何变换无需改变现有模型网络且不增加任何人工成本。王江江等[9]提出汉字字体生成算法FontToFont,通过引入U-Net网络结构,可以使生成器保存更详细的信息,并有利于模型性能。
如上所述,现有的字体风格迁移与字体生成方法仍然需要大量的配对数据或者通过对字体属性人工标注标签进行训练,当存在多种风格的字体时,需要大量的人力以及时间上的消耗。并且当进行多种风格迁移时,模型的泛化能力差,生成图像质量降低。本文提出一种无监督的多风格汉字迁移,使用StarGANv2[10]作为基础模型,在生成器中,将上采样中归一化为IN的Resnet替换成由IBN的残差块组成的Resnet中,利用低层和高层的特征图使编码器更好的学习汉字全局的间架结构和局部的笔画特性;其余下采样为自适应的实例归一化(AdaIN)[11]的残差块不变,将内容图像特征的均值和方差对齐到风格图像的均值和方差中,引导模型灵活地控制形状和纹理的变化量,增强模型鲁棒性。陈欣等[12]提出将卷积神经网络和注意力机制相结合,针对类别不平衡问题,提升微博情绪分析任务的能力。所以本文将同时引入注意力机制,使用transformer[13]的思想改进风格编码网络,在处理不同风格域字体间的相互转换时,使得模型在局部和全局特征中有不同的侧重点。
1 生成对抗网络
生成对抗网络[14]是基于深度学习的一种强大生成模型,近年来被广泛用于图像翻译,比如:风格迁移、图像修复、图像超分辨、图像分割等。自生成式对抗网络被提出来以后,越来越受到学术界和工业界的重视,不同于以往的生成模型,GANs通过对抗训练来不断地拟合已有样本数据的分布,直至能够生成以假乱真的样本。这与汉字字体的生成过程相似,所以越来越多的研究者使用生成对抗网络来实现汉字字体生成并应用于数据增强。条件生成对抗网络(CGAN)[15]是在GAN的基础上添加条件标签信息来控制图像的生成,并且模型能够实现无监督的学习。DCGAN[16]将卷积神经网络来代替生成器和判别器中的多层感知器,同时为了增强模型的稳定性,移除网络的全连接层,替换为全局池化层,采用BN(BatchNorm)的归一化方式。WGAN[17]理论上给出了GAN训练不稳定的原因,即交叉熵(JS散度)不适合衡量具有不相交部分的分布之间的距离,提出使用Wasserstein距离去衡量生成数据分布和真实数据分布之间的距离,解决网络训练过程中难以判断收敛性的问题。CycleGAN[18]是一种无监督的模型,较好地解决了缺乏成对训练样本来做单一域的风格转换。StarGAN[19]提出一个多领域的无监督图像迁移框架,在输入图像和风格标签后采用多个域共享一个生成模型的方式来实现多个领域的图像转换。
2 基于StarGANv2的字体生成
2.1 StarGANv2的整体网络架构
StarGANv2[20]是在StarGAN的基础上进行改进,该模型不再需要人工标出图像的风格标签,而是输入随机噪声和潜在编码经映射网络生成目标域的随机风格编码或者输入目标域的字体图像经风格编码网络生成风格编码,实现由一个源域图像转换到目标域的多种图像,并且可支持多个目标域进行风格转换。StarGANv2用于多风格字体生成具体的工作流程如图1所示,可以看出StarGANv2主要由生成器、判别器、映射网络,及风格编码网络四部分组成。生成器生成目标域的风格编码的图像,输入为源域图像和映射网络或风格编码网络生成的风格编码Sα、Sβ,输出生成的目标域图片;多任务判别器同时对每种风格字体进行鉴别,输出属于各个域的概率。

图1 StarGANv2字体生成流程图Figure 1 Flow chart of StarGANv2 font generation
2.2 IBN-Net
由于多域之间风格转换往往通过训练大量的数据集来提高模型生成图像的质量,但生活中由于一些艺术字体数量的有限性,仅使用单个模型一次性完成多个域之间的映射,在数据集较少的情况下,模型的泛化能力增强了,但针对转换到某个特定字体风格上的效果就会有下降。因此尝试引入IBN-Net[21],将实例标准化IN和批标准化BN结合的特征归一化的方式。使用StarGANv2对字体进行风格迁移,通过对IN和BN的深入研究,IN嵌入到一个编解码网络中,学习到的是不随字体风格比如纹理、笔触、对比度等低频特征的变化而变化的特征,常位于CNN模型的的浅层网络中;BN学习到的是与字体内容相关的信息,涉及图像边缘这种高频特征。
给定一个输入张量xi∈RB×C×H×W中B为输入批次(batch)的大小,C为通道数,H和W分别为特征向量的高和宽。BN是对整个batch方向做归一化,计算流程公式如下:
(1)
(2)
(3)
IN是对单个图像做归一化,计算公式如下:
(4)
(5)
(6)

在生成器中,使用图2(a)中ResBlock残差块作为主干网络进行特征提取,对于添加IN的残差块进行改进,我们在第一次卷积后一半通道用IN,一半通道用BN。将上采样中归一化为IN的ResBlock替换成结构为图2(b)的残差块,利用低层和高层的特征图使编码器更好的学习汉字全局的间架结构和局部的笔画特性;其余下采样归一化为自适应的实例归一化(AdaIN)的残差块不变,将内容图像特征的均值和方差对齐到风格图像的均值和方差中,该方法能有效提高主干网络的容量和泛化能力。图3为生成器的网络结构。
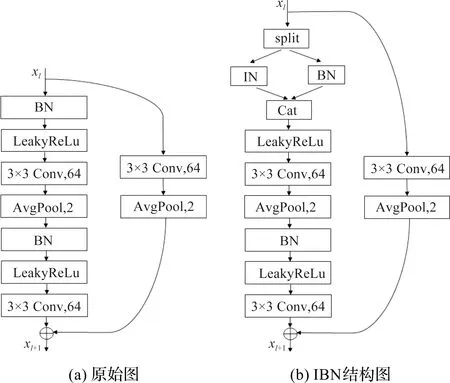
图2 ResBlock模块Figure 2 ResBlock module

图3 生成器网络图Figure 3 Generator block
2.3 融入注意力机制的风格编码网络
StarGANv2中风格编码网络有两个作用:一方面在应用阶段作为目标图像风格的指导器,此时目标域的图像y不能直接送入生成器随机采样而得到风格编码Sβ,而是输入到风格编码网络,输出s=Ey(y);另一方面优化映射网络,可以固定源域图像根据不同的字体风格表示Sα并且生成目标域下不同的字体图像。在多域之间的风格转换过程中,模型对不同风格域字体的区域关注程度是不同的。通常来说,在处理印刷字体或艺术字体时,模型更倾向于印刷字体线条粗细度等一些局部区域;而对于一些艺术字体,则更多的考虑字体的间架结构等全局特征。
本文利用transformer[22]中多头注意力机制的思想与上下文感知注意力[23]机制相结合,保持自注意力模型的并行性及简易性,从全局的角度在给定的上下文来适应选择的区域。基于StarGANv2的风格编码网络,如图4所示。

图4 风格编码网络图Figure 4 Style encoder block
在提取特征的主干网络ResBlock之后添加三个并行的上下文感知注意力模块,增强获得目标域的差异化特征表示。上下文感知注意力模块(Context-aware attention block)中把经过1×1卷积降维后的特征图作为输入,输入特征向量为{xi,i=1,2,3,…,H×W},该模型将上下文向量xu作为度量当前区域的重要性,并通过softmax函数得到一个归一化的注意力权重矩阵αi,公式如下:
(7)
αi=softmax(ei),
(8)
(9)
其中Wa是权重矩阵,ba是偏置矩阵,tanh函数将值域压缩到[-1,1]中。最后通过基于注意力机制的加权求和得到向量hi,此时三个平行的上下文感知注意力网络最后得到三个特征向量h1、h2、h3。上下文感知注意力模块得出的三个特征向量再进行softmax操作获得归一化的分数s1、s2、s3,然后加权求和得到最终的区域特征向量,之后再与最后一个卷积层得到的特征图ht进行点乘融合,得到最终的聚合特征f,公式如下:
s1,s2,s3=softmax(tanh(Wbhi+bb)),
(10)
(11)
这样就允许模型在不同的区域空间中学习相关的信息,主要目的是抽取更加丰富的特征信息。
2.4 损失函数
在损失函数方面,我们在保留了StarGANv2的对抗损失Ladv、风格重构损失Lsty、循环一致性损失Lcyc,同时为保证输入图像与输出图像的相似度,还加入了上下文损失(Contextual Loss)[24]。它的核心思想是通过特征间的相似度来衡量图像之间的相似度,而忽略特征的空间位置。本文使用VGG19来提取图像的特征值,用余弦距离计算xi的相似度,定义如下:
(12)

(13)
其中,ε=1e-5,通过幂运算转换为相似度运算为
(14)
此时h>0,特征之间的相似度定义成归一化相似度的尺度不变性为
(15)
最后,上下文损失函数的公式为
LCX(x,y,l)=-log(CX(Φl(x),Φl(y)))。
(16)
其中Φl(x)和Φl(y)是VGG19提取的特征图,l是网络层数。最终本文的优化损失为
LD=-Ladv,
(17)
LG=Ladv+λstyLsty+λcycLcyc+λcxLcx。
(18)
其中λsty,λcyc和λcx是训练时的超参数。
3 实 验
本文实验中使用的操作系统为Windows10操作系统,内存为128 GB,双核Inter CPU i7,GPU采用NVIDIA GeForce RTX3090。使用pytorch1.4.0框架并用python3.6编辑语言在pycharm编辑器实现。优化算法采用的是Adam[25],初始化步长因子为0.000 1,β1为0.5,β2为0.999,让其尽量接近1。训练迭代100 000次,batch的大小为12。
3.1 数据集
当下计算机字体以ttf的格式存储,而网络模型的训练数据是以图片格式作为输入,所以要把ttf格式的字体转换成图片格式。首先将收集好的国标常用汉字写入txt文件中然后编码为unicode格式的json文件,利用numpy来对其中的汉字进行筛选,再用PIL来提取所框选的汉字字体图像并在四周增加一个20像素大小的边框,使每个汉字都可以被置在所提取图像的中心。然后对输入的图像选择合适的尺寸,像素大小为64×64。图像的尺寸越大,在进行风格迁移时,需要进行的计算量就会越多,速度就会越慢;图像的尺寸也不宜过小,预防深层的卷积操作后没有特征映射输出或特征映射尺寸太小。获取图像后,将图像和对应的标签转换为二进制格式,得到训练数据集和验证数据集。
为了验证模型的泛化性,我们选择6种不同的字体风格进行字体风格迁移,分别为印刷体:汉仪中楷简体、黑体;艺术体:汉仪新蒂棉花糖黑板报、汉仪萝卜体简体、汉仪蜜糖体;手写体:汉仪尚巍小顽童。每种字体风格随机选取国标一级字库中500个汉字作为样本数据集,并按照7∶3的比例随机划分训练集和验证集。
3.2 实验结果及分析
为了验证本文改进算法的应用效果,分别使用StarGANv2原始模型和本文改进后的方法进行对比,图5为生成结果对比图。第一行和第一列分别为源域图像和目标域图像,它们都是真实的图像,而其余的是由模型生成的图像,保留原图像的内容与参考图像的风格。图像自左到右,自上而下分别为汉仪新蒂棉花糖黑板报、黑体、汉仪萝卜体简体、汉仪蜜糖体、汉仪尚巍小顽童、汉仪中楷简体。

图5 实验结果对比图Figure 5 Comparison chart of experimental results
多域之间的字体风格转换,往往通过大量数据集的学习,StarGANv2模型仅用单个模型完成多个域之间的映射,在数据集较少的情况下,不同风格域的学习程度是不同的,可以明显看出对于黑体的学习效果较差并且生成的字符容易有笔画的增添和缺失。我们推测当笔画密集或目标域字体与源域字体存在较大差异时,尤其是与标准字体笔画相似的部分对模型来说是很难学习的。而本文的方法生成的字体图像大部分可以保持完整结构,细节上的处理得到了进一步的优化,比如保留了点、撇等一些微小的笔画。模型不仅可以在无需重新训练的情况下生成多种字体风格,还可以生成与目标字体风格一致、笔画清晰、结构合理且更完整的字符图像。并且源域字体的改变并没有直接影响到生成结果的质量,已经达到了比较理想的效果。
将本文改进的方法与Zi2zi和CycleGAN方法对比,从图6、图7和图8中可以看出,Zi2zi在生成比较有挑战性的艺术字体时只能生成部分字符或有时结构不合理,CycleGAN和Zi2zi在一对一风格迁移中偏旁部首的损失问题似乎也很常见,生成的字符容易出现笔画模糊,难以识别字符的内容。而相比本文方法生成的效果图来看字形和轮廓上更加完整,比如笔画的开始、转折和结束区域,字体辨识度更高。

图6 汉仪新蒂棉花糖黑板报Figure 6 HY Senty marshmallow chalk

图7 黑体Figure 7 Sim Hei

图8 汉仪尚巍小顽童Figure 8 HY Shangwei xiao wan tong
3.3 评价指标
由于没有通用规则可以比较,当前主要使用定性评估和定量评估相结合的方法。定性评估通过人的视觉感知作为一项较为主观的评价指标,因此很难对生成模型进行客观评价。在定量评估中,分别从像素级、感知级等不同方面进行评估模型的准确性,使用Frechet Inception距离度量(FID)、结构相似性指标(SSIM)和学习感知图像块相似度(LPIPS)来衡量真实图像与生成图像之间的相似度。如表1所示,↑表示数字越大越好,↓表示数字越小越好。本文提出的算法生成的指标大部分优于其他算法,充分证明了本模型在字体风格迁移领域有广泛的适应性,并且模型的鲁棒性高于单域模型,在训练过程中不会发生模型坍塌。
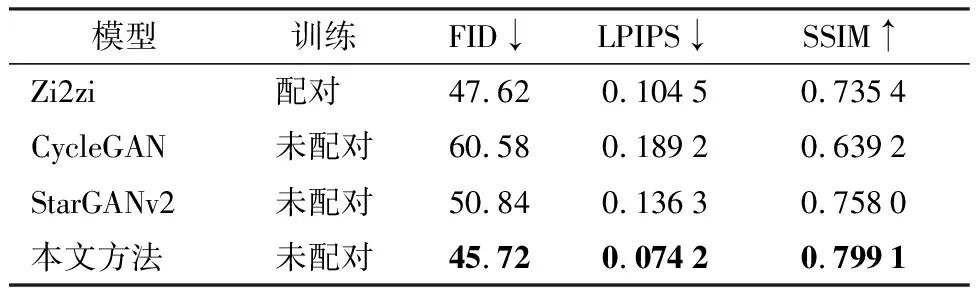
表1 评价指标测试结果Table 1 Result of evaluation index test
3.4 消融实验
为了有效评估基于StarGANv2改进的各个模块的作用,使用同样的训练方式,依次去掉各个组件进行消融实验。选择宋体作为源域字体,目标字体分别选取两种不同字体:一种是印刷体font1,与源域字体的汉字结构更加接近;一种是手写字体font2,汉字的笔画结构与源域字体差别较大。首先对实验结果进行定量比较,表2展示了消融实验研究的评价指标结果,w/o表示没有,IBN表示IN和BN结合的归一化方式,AT表示注意力机制模块。由表可知,提出的各个模块均对模型发挥着重要的作用。移除这些模块后,相对于本文模型而言,各项指标都会迅速下降。
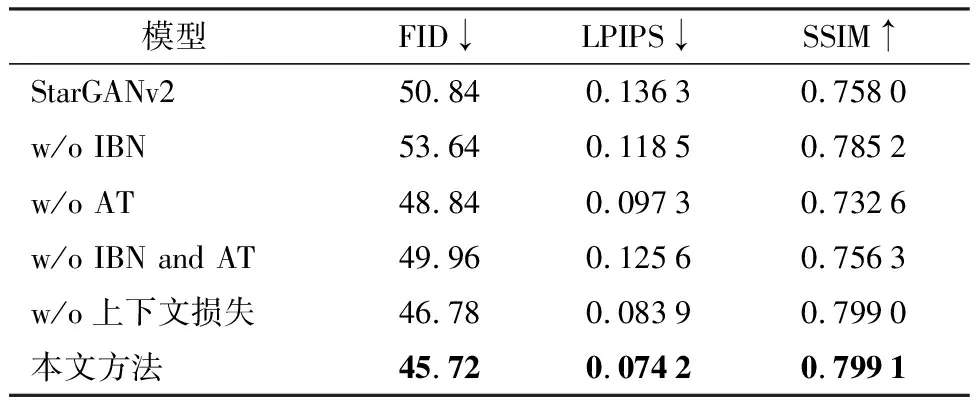
表2 消融实验评价指标测试Table 2 Evaluation index test of ablation experiment
从视觉效果上进行对比,如图9。把StarGANv2作为基准模型,可见模型对于两种字体的生成结果都比较差,生成字符的各个笔画增加或缺失严重。

图9 消融实验结果图Figure 9 Figure of ablation experiment results
在改进模型的基础上,将归一化IBN替换成BN之后,由于font1边缘清晰,字形和轮廓清晰并且笔画较粗,生成的字符相比改进的模型没有显著的差别,只是在汉字整体复杂或存在较多笔画的时候,效果明显比改进的模型差;而font2笔画较细并且字体结构不规则,对生成结果中每个笔画的要求更高,所以遇到笔画稍微多的情况整体汉字容易出现笔画错乱的现象。因此IBN的引入使得相同一个字在两种不同字体下的迁移不仅涉及到纹理、笔触、对比度等低频特征的变化,同时也涉及图像边缘这种高频特征,帮助解码器在隐层中学习到更多的表征,避免在风格迁移过程中有笔画错乱的汉字。
当去掉注意力机制后,font1大部分字符都能够很好的重建,但是对于风格的迁移效果较差,比如置的皿字头,渔的三点水偏旁;font2相比于font1,整体笔画细节和风格迁移效果较差。由此可见模型并没有赋予恰当的权重去关注局部特征或全局特征的分布偏差,从而无法学习不同字体的风格多样性和位置多样性。
当去掉上下文损失函数后,font1和font2生成的效果与改进模型没有显著的差别,只是出现了一些字迹斑点,边缘部分有模糊现象。这验证了加入上下文损失函数可以获取更细节的汉字笔画信息,取得更好的性能。
3.5 模型稳定性分析
在多风格的字体生成训练过程中,模型的损失值主要由生成器和判别器的损失函数构成。其中,判别器在训练过程中的损失函数变化如图10,可以看出,在训练初期发生了大幅度的波动,随后逐渐减小。当训练到40 000次之后,loss值在一定的范围内趋于稳定,且有小幅度的增加。这里需要解释的是,判别器的损失增大,并不代表越变越差,这是因为此时生成器越来越好。本身判别器和生成器是博弈关系,这就类似于对手越来越强大,尽管被对手打的越来越惨,但是自身能力也越来越强。

图10 判别器损失函数曲线图Figure 10 Figure of discriminator loss function
生成器的损失函数由对抗损失Ladv,风格重构损失Lsty、循环一致性损失Lcyc、上下文损失函数Lcx构成,从图11可以看出,一开始迭代时损失值取得全局最大值,随后逐渐减小,波动趋于平缓,说明判别器的拟合能力在不断地提高,此时判别器和生成器达到纳什平衡。
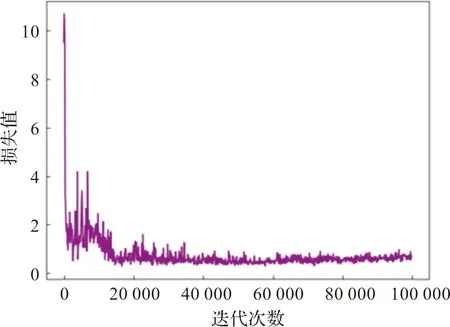
图11 生成器损失函数曲线图Figure 11 Figure of generation loss function
此外,生成器中的循环一致性损失函数是本模型的重要指标,因为它不仅是保证字体风格迁移任务的依据,而且也是生成字体图像质量的一个度量。图12所表示的生成器中循环一致性损失变化趋势图,损失值很快就达到稳定,这也说明本章所改进的模型使得字体重建效果很好,并且在迭代15 000次就已经达到收敛。随着迭代次数的增加,损失值基本上没有变化。

图12 循环一致性损失函数曲线图Figure 12 Figure of cycle consistency loss function
4 结 论
基于StarGANv2的网络结构,本文提出将生成器中上采样的归一化改为IBN-Net结构以及在风格编码网络嵌入上下文感知注意力机制的方法,通过无监督的域自适应,在训练时引入上下文损失,实现多风格字体的生成。实验结果表明,本文的改进算法模型提高了生成字体图像的质量并且优于现有的字体生成模型,对多种不同的目标字体有良好的扩展性和适应性。
