常规组网通信中的自适应滤波降噪技术研究
2022-05-15张颖花白云天
张颖花,李 增,崔 璨,白云天
中国人民警察大学a.警务装备技术学院; b.研究生院,河北 廊坊 065000
在警务及消防救援人员正常出警处理案件期间,外界环境是动态变化的,现场的环境噪声种类多,且噪声音量大,不利于警务及消防救援人员有序处理案件。在现场环境中,夹杂着各类噪声音源,比如汽车警报声、汽车鸣笛声、车辆发动机声、群众呼喊声等,这些声音混杂在一起干扰正常通信。在警务及消防救援人员通信过程中,人员之间的通信基本依赖于对讲机,而受众多噪音源影响,对讲机可能无法正常通信,或者对讲机通信期间杂音过多,影响正常指令的传输,通信质量大为降低。基于上述现实情况,有效提升通信质量是目前警务和消防救援通信研究中重点关注的一个课题。由此衍生了基于警务和消防救援现场噪声的自适应滤波降噪方案,使现场噪声处理系统化。
1 自适应滤波降噪系统
自适应滤波降噪系统在音频降噪方面有着一定的应用效果,也是一个值得研究的方向。自适应滤波降噪主要是通过识别噪声频率,分析音频信号中噪声与注册噪声的区别,根据噪声的重合性作出合适的判断[1]。通过构建自适应滤波降噪系统,能够对音频系数进行分化,从中提取一个完整的模块,与噪声抑制模块相贴合,完整的噪声自适应滤波降噪系统组成板块包括以下几个部分:音频信号采集模块、音频信号预处理模块、相似度计算模块、系统决策模块,整体框架流程如图1所示。
1.1 音频信号预处理
对于音频信号的预处理,主要是对音频特征参数进行提取,在正式提取之前,需要对音频信号进行分化处理,这个处理过程也被称为音频信号预处理。音频信号预处理对于降噪系统的降噪性能有直接的影响,所以应重视音频信号预处理[2],做好细节方面的处理工作,确保各个环节有序衔接,其具体的处理流程框架如图2所示。

图2 音频信号预处理框图
1.2 音频特征
在音频信号采集过程中,收集到的声音种类比较多,相对来说声音收集的数据量比较庞大,对于原始音频信号数据的提取,是一个复杂的过程,数据提取量非常大,而且容易导致数据出现不稳定的情况。而音频信号本身具有一定的动态性,通过音频特征对噪声音频进行提取,可以有效减少数据运行量,有效提升系统效率,而且对噪声的抵御指标也会有所提升。抗噪性能的提升能够更好地让系统抵御噪声的影响[3],要从多个角度规划好音频特征,借助于音频特征完成噪声提取,使之能适合自适应滤波降噪处理。在降噪系统中,音频特征参数的选择对于自适应滤波的影响比较大。
在警务和消防救援现场中,应对系统运行过程所选择的频谱分析进行调控,以伽玛通频率倒谱系数(GFCC)特征对噪声进行降噪,其特征向量表达式如公式(1)所示:

(1)
式中,M代表通道数量;n代表通道编号,其值范围为0~31。在v>13情况下,GFCC的大部分值近似为0,其压缩数学表达式为:

(2)
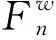
1.3 音频特征识别模型
科学技术水平的提升进一步推动了自适应滤波降噪系统的发展进程,在降噪系统中对音频特征识别模型的应用频率也越来越高,音频特征识别模型具有一定的分化性,模型种类较为多样化。不同的模型适用范围不同,针对线性情况和非线性情况,主要有向量机模型、身份模型、隐马尔可夫模型、高斯混合模型等[4],不同的模型侧重点不同,随着降噪系统的深入发展,很多模型在自适应滤波降噪系统中都有较好的应用效果。
2 自适应滤波降噪系统方案设计
近几年,滤波降噪技术在各类环境下的应用频率逐渐增多,但是由于噪声环境的多样化,使得该技术的应用效果无法充分发挥,针对这种问题,设计了详细的规划方案,具体内容指标如图3所示。

图3 自适应滤波降噪系统设计方案
2.1 声音预处理模块
该模块是对声音信息进行归类处理,将收集的声音数据一一拆分,根据识别标准将这些声音分类,将其中冗余声音数据一一去除掉,也可以针对性地消除某一个节点的声音,达到一定的降噪效果。在声音预处理过程中,应使用专门的算法进行计算,其中维纳波降噪需要结合声音特征,有一定的降噪要求,谱减算法在噪声环境中容易失调,在有色的噪声环境中失调会加重,使用中值滤波法降噪效果相对来说比较好,对于跳变噪声去除效果也较为明显,能够完成对声音信号的平滑降噪处理。
2.2 特征提取模块
特征提取模块涉及多种特征参数,如伽玛通频率倒谱系数(GFCC)。在不同噪声环境下,不同特征参数变化情况是不同的,噪声环境下GFCC特征参数的辨识度最高,有着良好的抗噪性。对GFCC特征参数进行深入分析,发现其在噪声辨识方面存在一定的局限性,为了提高对噪声的精准辨识,需要对GFCC特征参数进行优化和完善,改进自适应压缩ACGFCC特征参数,形成全新的特征参数指标。
2.3 噪声辨识模块
这个模块包含了多个节点,以多个模块为基础框架,对噪声辨识进行系统化的环境训练,实现对噪声辨识模型参数的有效优化。
3 音频特征识别模型设计
高斯分布(Gaussian Distribution)具有一定的广义性,单纯从概念上理解也被称为正态分布(Normal Distribution),它是一个连续概率分布的函数,以单值为中心,呈聚集分散的状态。从现实情况来看,很多心理测试分数与高斯分布都有极高的贴合性。而高斯混合模型(Gaussian Mixture Model,GMM)是基于高斯密度函数演化而来,高斯混合模型包含的内容比较多,具有一定的机构化特点,从某种程度上来说,它满足任意形式的概率密度分布要求,所以在各个行业领域都有一定的应用价值,直观体现在图像识别、音频识别、噪声辨识等方面[5]。
3.1 高斯混合模型
在音频特征识别过程中,可通过识别指标构建高斯混合模型。从本质上来看,音频特征识别采用的识别模型,就是通过识别的方式对噪声源构建一个专门的GMM模型,其框架结构如图4所示。

图4 高斯混合模型图
从概率学的角度来看,单一化的高斯分布存在一个最大值,用一维的高斯概率分布无法有效描述其分布情况,需要导入高斯混合模型,通过高斯分布叠加的方式进行辨识[6],一个多维高斯分布的联合正态分布表达式见式(3)。

(3)
式中,ui是高斯分布的均值向量;∑i是它的协方差矩阵,ωi表示其权重,其约束条件为∑i=1,根据高斯混合模型的定义,M阶高斯混合模型的概率密度函数数学表达式见式(4)。
一个音频特征识别GMM模型由其均值向量、协方差矩阵、混合权重来表示,如图5所示。
3.2 高斯混合模型改进
在模型训练过程中,受多方面因素影响,训练音频信号的样品数量存在一定不足,使得GMM模型并不具备全面性特点。针对这个问题,在本次模型训练中,引入了通用背景模型,这种模型对训练要求比较低,只要通过很少的语音训练集就可以有效提高对噪声的辨识度。

图5 音频特征识别GMM模型的表示
通用背景模型(UBM)具有一定的综合性特点,这种模型就是提前将各种警务和消防救援现场噪声的音频数据进行整合,然后训练成一个完整性的GMM模型,这种模型能够辨识音源和噪声的分布情况。在现场的噪声可以通过GMM模型参数调整辨识出来,这得益于现场噪声背景的提前收录。目标模型主要通过目标声音最大化后验算概率得到。UBM模型本身就比较大型化,训练时与GMM模型的训练方式大同小异,其结构如图6所示。这种噪声辨识模型不仅节省时间,而且对于噪声辨识的准确性也比较高。

图6 GMM—UBM模型
4 结语
本文从常规组网通信中噪声自适应滤波降噪技术的角度出发,研究了警务及消防救援现场噪声环境下如何有效提高降噪指标,并对音频信号进行预处理,从而完成音频特征的识别。在噪声干扰的情况下,自适应滤波降噪系统的识别功能会极大程度上降低。针对这一问题,需要从降噪模型角度出发,提高模型性能指标,融入先进的科学技术,将高斯混合模型融入其中,作为系统的基础优化模板,有效提高系统噪声的辨识性,更好地满足现场噪声滤波降噪处理要求。
