基于文本信息的上市中小企业财务困境预测研究
2022-05-14陈艺云
陈艺云
(华南理工大学 经济与金融学院,广东 广州 510006)
0 引言
融资难一直是困扰中小企业发展的焦点问题,究其根源还是在于信息不对称,资金提供方难以获得充分有效的信息来准确评价中小企业的信用风险。在我国经济步入新常态、增长速度放缓的背景下,企业经营业绩开始下滑,违约事件频发,而实力弱、风险高、信息透明度低的中小企业更是首当其冲,信用风险对我国金融市场的稳定和宏观经济的可持续发展提出了严峻挑战。以往对企业信用风险评价的量化分析大多是以财务数据、市场交易数据等定量信息为基础的,往往会导致违约概率与信用价差的低估而产生“信用价差之谜”,这可能是公开信息不完全导致的[1],但实际上这些基于定量数据的研究对公开信息的分析并不充分,只注重对财务数据、市场交易数据等定量信息的分析,而没有考虑公开的各种定性信息,如企业的信息披露、新闻媒体报道、论坛和微博的在线评论等,标准普尔早在2003年就指出为传统研究忽视的定性信息中包含着区分信用风险的重要信息[2]。大数据时代的到来为准确评价和管理信用风险带来了海量信息和更先进的技术和方法,通过对互联网海量文本内容的分析来发掘更多有价值的信息以准确预测中小企业的财务困境,对于有效防范信用危机和债务危机具有重要的理论和现实意义。
1 财务困境预测的信息基础
1.1 基于会计信息的研究及其不足
由于财务报表直接反映了企业的经营情况和财务状况,因而可以财务比率等会计信息为基础,采用单变量与多元判别分析、定性响应模型、聚类分析和K近邻判别分析等非参数统计方法、神经网络和支持向量机等人工智能方法等方法寻找对财务困境有重要解释力的变量,评估这些变量的显著性,构建评价模型来确定分类规则[3,4]。会计信息已成为财务困境预测和信用风险评价的重要基础,但许多研究都表明基于会计信息的信用风险量化分析会受诸多因素的影响[5],如会计信息作为历史信息不足以用来判断企业未来的经营状况和财务状况,稳健性和历史成本原则会导致对企业资产价值的低估,会受到企业盈余管理行为的影响,以及难以考虑企业资产价值波动性的影响等,特别是对于信息不对称问题严重、信息透明度差的中小企业而言,会计信息的可靠性不足。
1.2 基于市场信息的研究及其不足
以会计信息来分析企业的信用风险缺乏理论基础,难以解释企业的违约原因,而证券市场的交易价格可以用来衡量企业资产的价值及波动性,由此就可以分析其违约的内在原因[6]。与会计信息相比,市场信息不仅反映了会计信息,还反映了其他来源的信息,市场变量也不会受到企业会计政策的影响,弱化了经理人盈余管理行为的影响,而市场交易价格是投资者对企业未来预期现金流价值的预期,由此对企业信用风险的评价将更为准确。
不过基于市场信息的研究是建立在一系列严格假设基础上的,如假设收益率服从正态分布,不区分各种类型的债务,资产价值和波动性需要根据市场价格计算而不能直接获取从而导致潜在很大的误差,财务困境企业更容易出现市场价格偏离公允价值等问题[7],一些实证研究发现在控制一系列其他变量后,市场信息模型的预测能力非常低[8]。对于中小企业而言,基于市场信息来评价信用风险也不可行,绝大多数中小企业并没有上市交易,无法获取相关的市场信息来进行评价和分析。
1.3 文本信息对财务困境预测的价值
从公开信息的角度来看,除了定量的会计信息和市场信息以外,还存在着大量与企业经营状况和未来前景相关的定性文本信息。
首先,从信息披露的角度来看,除了定量财务数据直观反映了企业经营和财务状况以外,企业在发布的定期和不定期报告、业绩说明会等各种信息披露报告中包含了大量描述性文本内容,这是对经营情况和财务状况的具体说明和分析。企业可能会通过提高负面信息的分析成本来弱化市场对负面信息的反应,倾向于以更直接、更清晰的方式来陈述正面消息,以更为复杂、更多中性或含义模糊而不是悲观和负面的词语来描述负面消息或表达对未来前景的担忧,这样就可以通过对企业信息披露文本内容的分析来判断其违约倾向。为此,一些学者在财务困境或破产预测的研究中加入了信息披露文本的量化指标,如不少基于年报文本的研究都表明企业信息披露文本是对定量财务数据的有效补充,在财务困境预测和信用风险评价模型中加入这些文本的量化指标可以提高模型的效力[9~11]。不过信息披露的频率相对较低,与财务数据一样会存在时滞性问题。
其次,传统新闻媒体与新兴互联网媒体上存在着大量对企业的报道和评论,大量关于媒体报道对资本市场影响的研究都表明媒体有助于促进信息的分散和传播,缓解信息不对称问题,媒体报道的内容通常具有明显的倾向性,还会传递对企业经营现状、未来发展、盈余预期等乐观或悲观的观点[12]。由于新闻媒体,特别是互联网和社交媒体会对企业存在的问题予以迅速报道和反馈,这样就可以为财务困境预测和信用风险评价提供时效性更强的信息,而且媒体报道的倾向会对投资者和消费者的心理与行为产生重要影响,媒体的负面报道一方面会使市场交易价格会偏离内在价值,导致对企业信用状况的错误评价,另一方面还会影响资金提供者对企业还本付息的信心,债券投资者可能会因此出售企业发行的债券,贷款者可能会提前收回资金,商业授信方会要求提前付款、不再提供商业信用等,这些都会增加企业的资金压力,使企业陷入财务困境或进一步加重财务危机。近年来,一些学者将新闻报道、互联网文本内容的分析引入到财务困境预测和信用风险评价中,结果表明对新闻报道文本内容的分析可以预测企业财务困境或信用评级变动[13~16],还有些学者则从债务成本的角度发现媒体关注与报道倾向隐含着关于债务人信用风险的有用信息[17,18]。
这些研究表明文本信息对于企业的财务困境预测和信用风险评价都会带来一定的增量信息,但选取的文本信息往往局限于某一类文本信息,没有考虑多种文本信息的影响。为此,本文以我国上市中小企业为研究对象,利用网络爬虫获取企业信息披露和互联网媒体新闻报道的文本内容,采用情感分析方法对文本内容进行量化分析,再与定量财务数据相结合对不同文本内容的量化指标在财务困境预测中的信息价值以及预测能力进行实证检验。本文的研究贡献在于:一是在财务困境预测的研究中考虑了不同来源文本信息的影响,拓展了信用风险评价的信息基础;二是对于互联网媒体新闻在财务困境预测中信息价值的分析有助于丰富对新闻媒体信息中介、监督功能等治理效应的研究;三是在以词袋方法为基础进行自动文本分析时,考虑不同来源文本信息的特点采用不同词表为基础来进行分析,对于金融领域文本分析方法的选择有一定的参考价值。
2 研究设计
2.1 样本选取
考虑到中小企业财务数据难以获取,本文选取了在深圳中小企业板块上市的中小企业为研究对象,参照国内研究的一般做法,将因财务状况异常而被特别处理作为企业出现财务困境的标志。由于我国上市企业在t年是否被特别处理与t-1年的年报公布发生在同一年度,因而参照石晓军等的做法[19],采用了上市企业t-2年的数据建立模型来预测其是否会在t年会出现财务困境。由于中小企业板块在2003年上市初期很少出现特别处理问题,并考虑到2008年金融危机的影响,本文选取了2012年到2018年被特别处理的上市中小企业为样本,对应的数据区间为2010年~2016年,并剔除了金融类企业以及跨市场在B股和H股上市的企业。在对样本进行处理时,不考虑2010年之前已被特别处理的企业,以及被特别处理后进一步降级或撤销特别处理的问题,最后样本中包括761家企业,其中48家企业被特别处理,共4500个企业-年度观测值。
2.2 实证方法
为了避免配对抽样导致的样本量受限问题,并考虑财务困境发生概率会随时间变化的特点,本文选取Shumway的离散时间风险模型[20]作为建模基础。企业i在t+1时刻出现信用风险的离散概率满足:
(1)
其中Xi,t表示企业i在t时刻的协变量,αt表示时变的基准风险率,这样就可以利用所有可观测的企业-年度样本,消除静态模型中的选择性偏误问题。在实证分析中,本文首先以单变量分析为基础对各种文本信息量化指标在财务困境预测中的作用进行比较分析,然后以财务比率模型为基础对不同文本信息量化指标的作用进行比较分析,然后再对文本量化指标对财务困境预测的信息含量进行检验,最后利用十分位检验的方法对文本量化指标预测财务困境的能力进行分析。
2.3 定量数据的选择
以往财务困境预测的研究中选取的财务变量与市场变量非常多,考虑到本文以上市中小企业为样本,并考虑到研究结论可进一步推广到众多非上市中小企业,因而在定量数据方面,没有考虑市场变量,仅以财务变量为基础。本文重点在于检验文本量化指标在财务困境预测中的作用,因而参照Shumway等的研究从规模、盈利能力、负债比率和利息偿付能力等方面选取了四个财务变量:总资产规模(ASSET,总资产的对数)、总资产收益率(ROA)、资产负债率(LEV)和利息保障倍数(INTCOV)。
2.4 文本信息的来源与分析方法
本文利用网络爬虫从以下两个方面获取文本信息:一是企业的信息披露,来自巨潮资讯的年度报告,并从中提取管理层讨论与分析(MD&A)部分的内容,分别以年报全文和MD&A部分为基础对文本内容传递的管理层语调进行分析;二是互联网新闻媒体报道,利用企业名称及简称作为关键词从百度新闻搜索引擎中爬取相关的文本内容,并进行预处理和清洗,如去除企业主动发布的各种报告等,再对媒体报道的倾向进行分析。
对金融文本的自动分析主要有两种方法,一是词袋方法,利用特定词典或词表对特征词的划分来对文本进行分类,Loughran和McDonald指出从其他领域引入的成熟词典或词表对金融文本的特殊性考虑不足,应以特定金融文本为基础来构建专门用于金融文本情感或语调分析的词表[21];二是机器学习方法,通过特定算法对训练集文本进行训练,确定文本分类规则再应用于全部文本。Loughran和McDonald指出机器学习方法需要选择训练集,这会受研究者主观性的影响[22],而词袋方法在确定词典和词表后可以很好的规避这一问题,为此本文采用了词袋方法来进行分析。由于年报与媒体报道来自于不同主体,文本内容的撰写上存在着一定的差异,为此采用了不同的处理方式:对年报文本,借鉴谢德仁和林乐的方法[23],以Loughran和McDonald构建的词表为基础,参照中文年报内容翻译后构建对信息披露文本分析的词表;对互联网新闻媒体报道的分析则以You等构建的新闻报道倾向词表为基础[24]。
在利用词袋方法计算文本的情感倾向时的另一个关键问题在于特征词的权重问题,常用方法是假设各个词语的权重相同,但Loughran和McDonald指出特征词的权重应考虑词语在全部文档中的重要性,因此本文以词频-逆向文档频率(TFIDF)为基础来设置特征词权重,计算文本内容的情感倾向。
在中文分词的工具方面,现有中文文本分词技术较多,为确保结果的稳健性,本文以R语言为基础同时采用两种方法:一是结巴中文分词工具JiebaR;二是基于中科院ICTCLAS中文分词算法的Rwordseg工具。通过自动分词,利用R语言的文本挖掘工具TM创建文档词语矩阵,再利用上述词表来统计正面和负面的情感词语词频POS和NEG(分别表示正面和负面情感词语数量占全部词语总数的比例),直接以NEG来衡量管理层的负面语调以及媒体报道的负面倾向,同时以POS和NEG来构建管理层的净语调以及媒体报道的整体倾向TONE:
(2)
对于信息披露文本传递的管理层语调,分别以年报全文和管理层讨论与分析部分为基础来进行衡量,结合分词工具的不同,构建了八个管理层语调变量:JTNEG_AR、JTTONE_AR、RTNEG_AR、RTTONE_AR、JTNEG_MDA、TTONE_MDA、RTNEG_MDA、RTTONE_MDA。由于一段时期内对单个企业会存在大量新闻媒体报道,本文从两个方面来构建媒体报道倾向的衡量指标:一是对一段时期内的负面倾向和整体倾向进行加权平均,由此构建JTNEG_NE、JTTONE_ NE、RTNEG_ NE、RTTONE_ NE四个报道倾向指标;二是采用You等(2018)的方法,根据一篇报道中负面词与正面词的数量来衡量整体报道倾向,负面词更多的为负面报道,计算负面报道篇数占该时期内全部报道篇数的比例,由此构建JTNEGB_NE和RTNEGB_ NE两个负面报道比例变量。
3 实证结果与分析
3.1 基于单变量模型的比较分析
本文首先对选取的财务变量、计算的年报管理层语调变量、新闻报道倾向和负面报道比例变量是否具有预测中小上市企业财务困境的能力进行检验,检验中都加入了常数项,结果如表1所示。
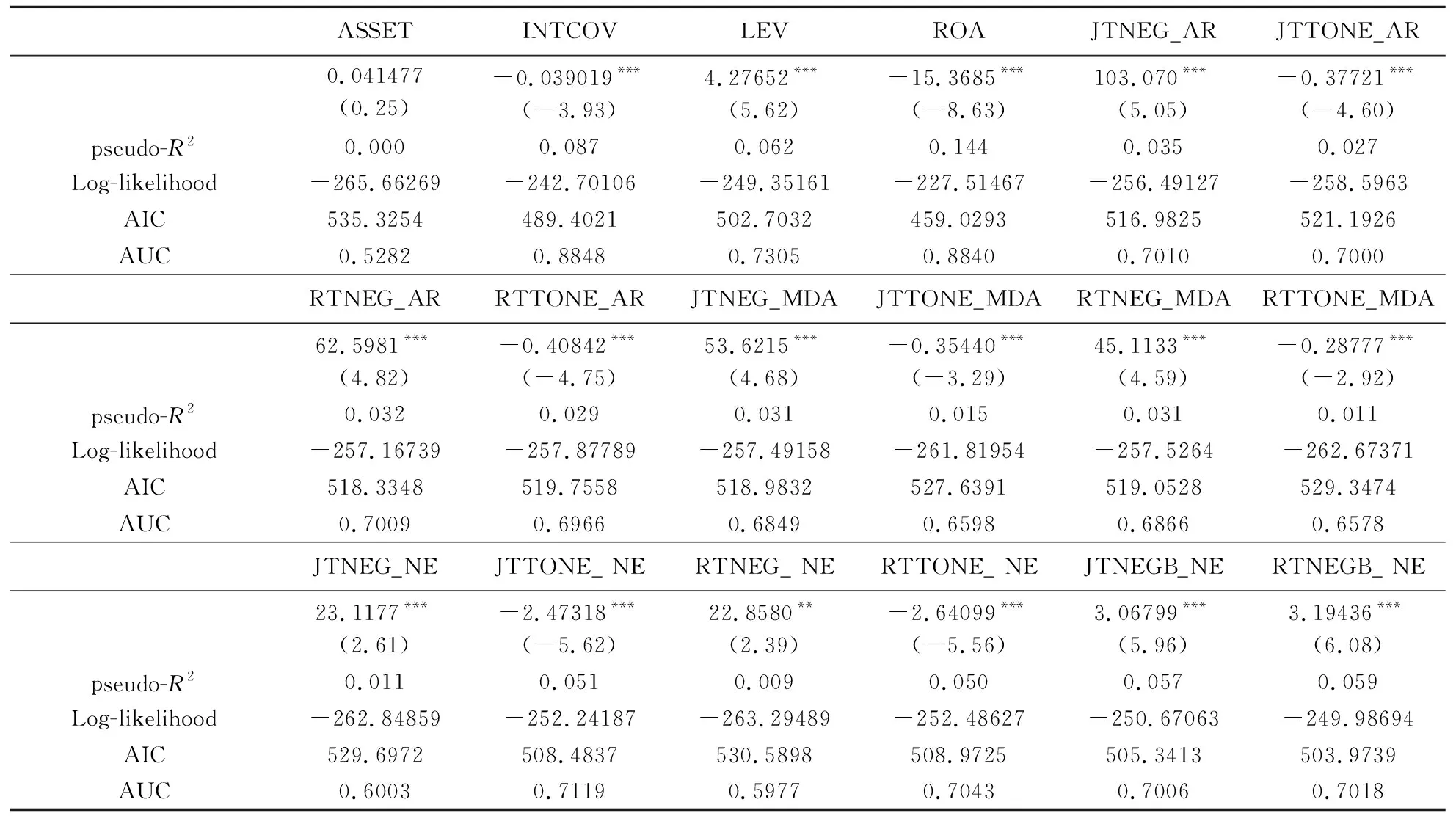
表1 文本信息预测财务困境的能力:基于单变量的比较分析
在财务变量中,资产规模ASSET的预测能力最差,其原因在于选取的上市中小企业规模相差不大,因而企业规模因素的影响较小;资产收益率ROA的预测能力最强,其原因在于上市企业特别处理的主要依据在于盈利能力,连续亏损的企业被特别处理的概率自然会更高,因而资产收益率会有较强的预测能力。
在年报文本指标中,分词工具的影响很小,基本可以忽略;由年报全文以及由管理层讨论与分析部分计算的管理层语调在预测财务困境时的效果差异较小,同样可以忽略;在负面语调和净语调中,负面语调的信息价值高于净语调。
在媒体报道倾向变量中,与管理层语调变量相似,分词工具的选择不会带来太大差异;整体倾向变量的效果要远好于负面报道倾向,而负面报道比例的效果同样较好,接近于整体倾向,这主要是由于负面报道的判断与整体倾向变量的计算相似,都依赖于报道中负面词语与正面词语的对比情况。
3.2 基于多变量模型的比较分析
为了进一步检验管理层语调、媒体报道倾向等文本信息变量在财务困境预测中的作用,本文以财务变量模型为基础,在控制年度和行业效应的情况下,分别加入文本信息变量对模型进行重新估计。
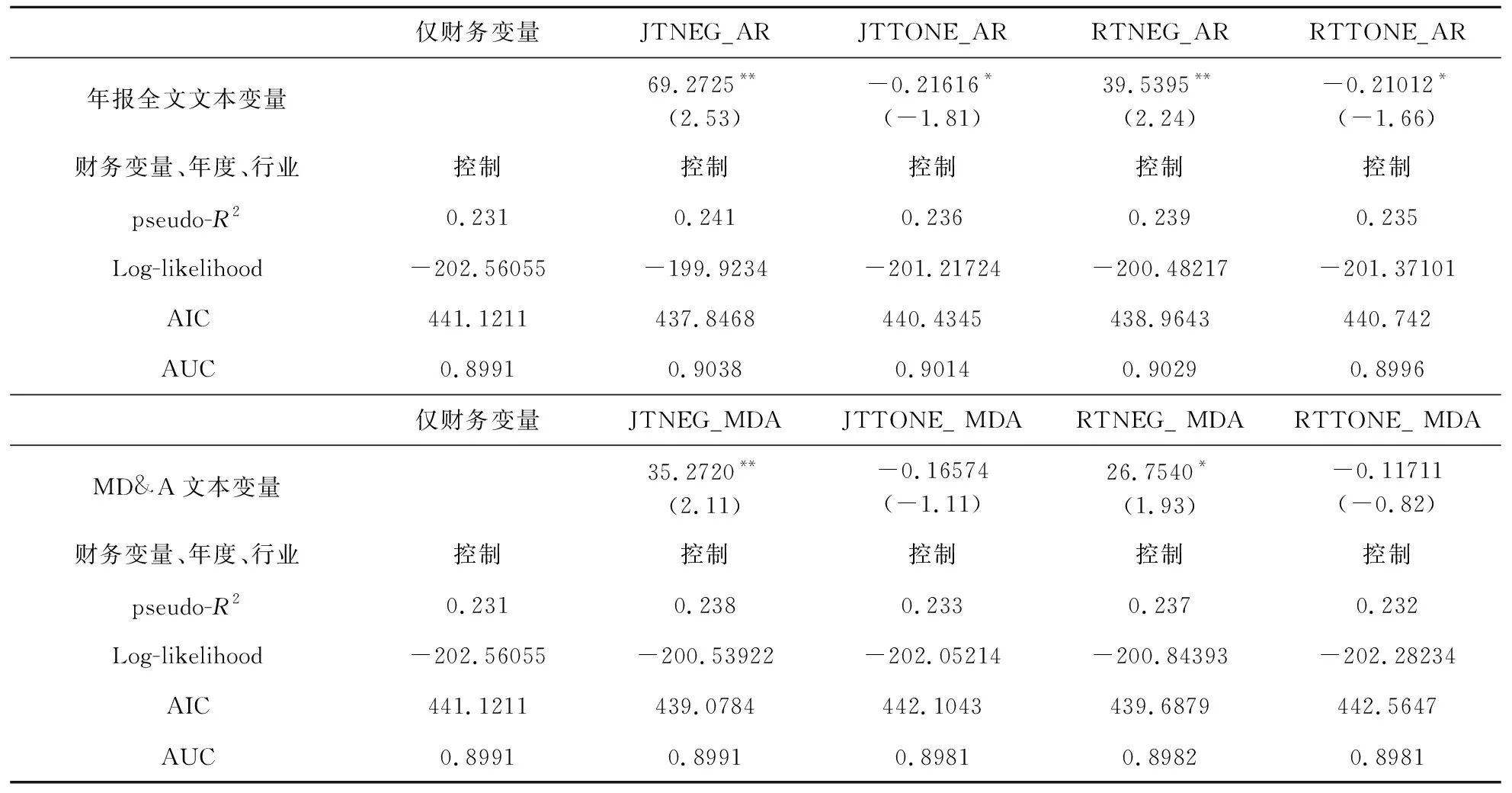
表2 管理层语调的对比分析
3.2.1 管理层语调变量的对比分析
表2报告了在财务变量模型中加入管理层语调变量的估计结果。在以年报全文为基础的分析中:首先,负面语调的估计系数显著为正,表明信息披露文本传递的管理层语调越负面,企业出现财务困境的可能性越大,而净语调的估计系数显著为负,但仅在10%水平下显著,表明净语调越正面,出现财务困境的可能性越小;其次,两种分词工具得到的结果在财务困境预测中效果基本相同;最后,从模型的拟合情况来看,加入负面语调后模型拟合效果相对更好,表明负面语调在财务困境预测中的信息价值相对更高。
在以年报管理层讨论与分析部分内容为基础的分析中:首先,负面语调依然显著为负,而净语调变量则不再显著;其次,两种分词工具同样没有太大差别;最后,从模型的拟合情况来看,加入负面语调后模型拟合效果相对更好。实证结果与基于年报全文的分析基本相似,这些结果都表明负面语调具有更高的信息价值。
3.2.2 媒体报道倾向变量的比较分析
表3报告了媒体报道倾向变量的实证结果。在控制财务变量、年度和行业效应的基础上,两个负面倾向变量都不显著,且加入后模型的拟合程度没有提高,而两个整体倾向变量都显著,加入后都可以提高预测模型的拟合程度,即整体倾向的信息价值要高于负面倾向,从这点来说,对媒体报道倾向的分析与管理层语调不同,对媒体报道应更注重对整体倾向的分析。此外,同样可以看到不同分词工具得到的结果并没有显著的差异。在两个负面报道比例变量中,估计结果都显著为正,表明负面报道的比例越多,企业出现财务困境的可能性就越大,之所以与前面对整体倾向的分析相似,原因在于负面报道的确定与整体倾向的计算方法类似;同样两种分词工具带来的影响非常小。

表3 媒体报道倾向的对比分析

表3 结合不同文本信息的实证结果
3.2.3 不同文本信息相结合的分析
为进一步对管理层语调、媒体报道倾向和负面报道比例在财务困境预测中的作用进行检验,本文以基于年报全文的负面语调JTNEG_AR和RTNEG_AR分别与对应分词工具得到的媒体报道整体倾向JTTONE_ NE和RTTONE_ NE、负面报道比例JTNEGB_NE和RTNEGB_ NE两两结合来进行估计,结果如表3所示。由表3可见,管理层负面语调和媒体负面报道比例变量都显著为正,而媒体报道整体倾向都显著为负,模型的拟合效果也相对比较接近,进一步验证了管理层负面语调、媒体报道整体倾向、媒体负面报道比例在财务困境预测中的信息价值。
3.3 基于信息量检验的分析
为进一步确认文本信息量化指标对财务困境预测的信息增量价值,本文基于离散时间风险模型对文本信息变量的信息含量进行了检验。前面的分析显示分词工具的影响很小,因而只选取了结巴分词的三个变量JTNEG_AR、JTTONE_ NE和JTNEGB_NE进行检验,首先以财务变量模型的估计结果来预测各观测样本出现财务困境的逻辑分值SFINANCIAL,然后将其与三个文本信息变量单变量估计结果预测的逻辑分值SJTNEG_AR、SJTTONE_ NE和SJTNEGB_NE相结合,结果如表4所示。模型1只加入了财务变量模型预测的逻辑分值SFINANCIAL,模型2~4分别在SFINANCIAL的基础上加入了三个文本信息变量预测的逻辑分值,模型5和6以SFINANCIAL为基础,将文本信息变量两两结合进一步检验其信息增量。SFINANCIAL在所有模型中都显著为正且在1%水平下显著,表明财务信息在财务困境预测中有着非常重要的作用;三个文本信息变量预测的逻辑分值都显著为正,模型拟合程度也都有一定的改进,表明文本信息中确实包含了预测企业财务困境的重要信息。

表4 信息量检验与信息增量的估计结果
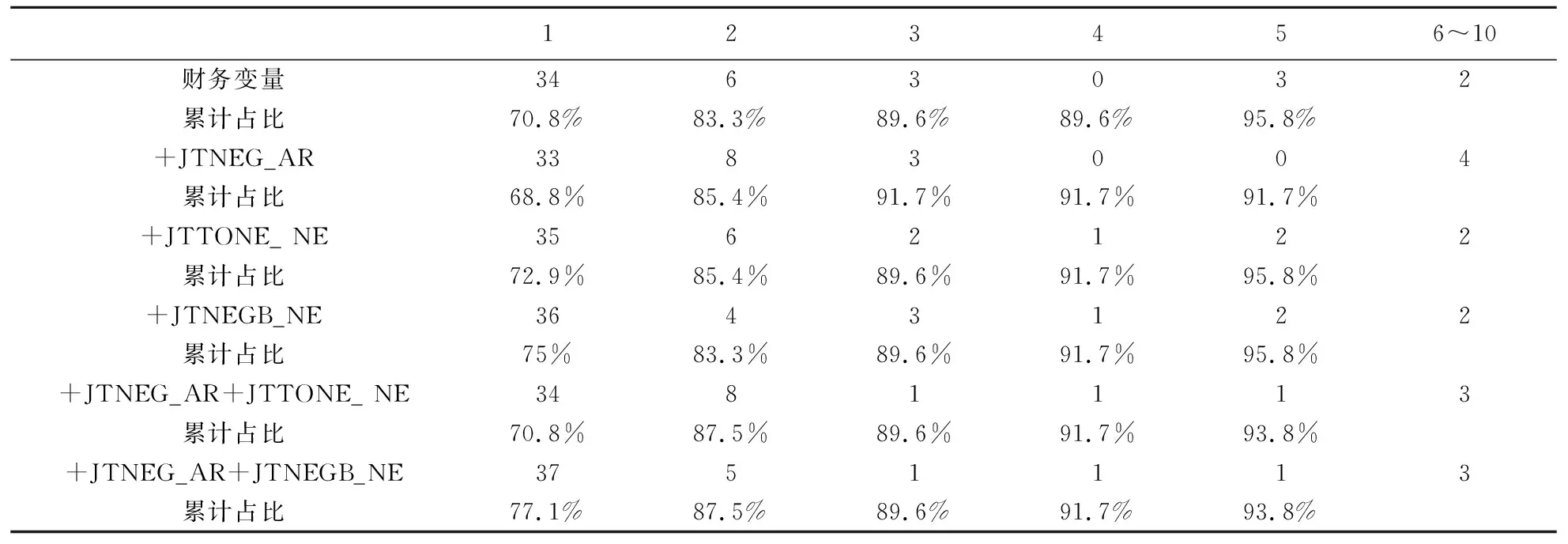
表5 十分位数检验的结果
3.4 基于预测能力的分析
本文采用Shumway的十分位数检验方法,将前述模型预测的违约概率按照十分位数分成十等分,计算十分位数中财务困境企业的比例,结果如表5所示。由表5可见,以财务变量模型预测的结果为基准,加入年报负面语调JTNEG_AR后尽管第一个十分位预测的准确率略有降低,但第二个十分位有显著提高;加入媒体报道整体倾向变量JTTONE_ NE后前两个十分位的预测准确率都有所提高;而加入媒体负面报道比例JTNEGB_NE后在第一个十分位预测的准确率就有明显提高;在同时加入年报负面语调和媒体报道整体倾向后,尽管第一个十分位的预测准确率不变,但第二个十分位预测的准确率有显著提升;同时加入年报负面语调变量和媒体负面报道比例变量后第一个十分位预测的准确率有大幅提升,第二个十分位预测的准确率也有所提高。由此可见,尽管年报负面语调变量对财务困境模型预测能力的改善相对有限,但媒体报道整体倾向与负面报道比例都有较强的预测能力,因而在财务困境预测和信用风险评价的研究中加入文本信息的量化指标确实可以提高模型的效力和预测能力。
4 结论
本文针对绝大多数中小企业缺少市场信息,而财务数据披露不规范的问题,以上市中小企业为样本,通过对企业信息披露和互联网新闻媒体报道文本内容的量化分析构建管理层语调与媒体报道倾向变量,对这些文本量化指标在财务困境预测中的信息价值进行了实证检验,主要结论如下:
首先,企业的信息披露与互联网新闻媒体报道的文本内容都可以提高财务困境模型的预测能力。单变量分析以及在财务变量模型中加入文本信息变量后的结果都显示文本信息变量可以提高模型的拟合程度,且不会因为分词工具而出现变化。信息量检验的结果进一步确认了这一结论,而十分位检验的结果表明文本信息变量对财务困境确实具有一定的预测能力。
其次,采用词袋方法对不同类文本进行情感分析时应有不同的侧重点,采用不同的方法。在年报文本内容的分析中,负面语调在财务困境预测中的效果更好,净语调变量的效果较差,且在离散时间风险模型的估计中不显著;在对互联网新闻媒体报道的分析中,整体倾向的效果更好,而负面倾向的效果较差,但负面报道数量的比例变量则具有较好的效果。
再次,从财务困境预测的角度来看,以年报全文和管理层讨论与分析部分文本内容构建的管理层负面语调和净语调在离散时间风险模型中的估计结果基本相似,表明年报全文与管理层讨论与分析部分文本内容的信息价值不存在显著的差别。
尽管本文对文本信息在中小企业财务困境预测中作用的研究针对的是中小上市企业,但在实证研究中仅考虑了主要的财务变量,因而基于文本分析来构建财务困境预测模型的方法可以推广到非上市中小企业,如以中小企业的信息披露、主要股东的相关信息来代替上市企业的年报,并获取对中小企业及外部环境的新闻媒体报道,就可以构建基于文本信息的中小企业财务困境预测和信用风险管理模型,强化对其信用风险的评价与管理。
