基于点群聚类的网络涉密信息安全传输仿真
2022-05-14陈孝如邢萧飞
陈孝如,邢萧飞
(1. 广州大学华软软件学院,广东 广州 510990;2. 广州大学计算机科学与网络工程学院,广东 广州 528225)
1 引言
目前的涉密信息都是从物理上分离,为防止信息泄密导致互联网禁止互通[1],这种情况会出现诸多矛盾,特别是基础信息和重要业务系统出现分离,因此无法实现资源共享,存在工作效率低的问题[2],所以如何保证进行资源共享的同时还能保证涉密信息被更加严格的安全控制是目前亟待解决的一大问题[3]。
刘倍雄等人[4]提出大数据资源调度下网络信息安全传输方法,该传输方法在合并多进程网络信息及将要传输信息的基础上,将网络通讯地址映射机制进行改善,改变网络数据传输中的信息包装形式,完善了网络信息的传输协议,实现信息安全传输,该方法在传输信息前未利用点群聚类的方法细致分类数据,因此无法精确选取出传输路径,降低了信息传输的成功率。欧静兰等人[5]提出基于携能通信的非信任双向中继网络信息安全传输方法,该方法利用非信任中继功率分割策略进行信息保密,以最大性能保密目标,并优化中继的PS因子,以此推导出保密和速率的解析式,同时针对非理想信道状态信息的情况,分析信道误差对系统保密性能的影响,最终实现信息安全传输,该方法没有采用广义距离的定义将数据转化成属性和点群聚类,因此只能粗略地分类涉密数据,增加信息传输的复杂度,降低了信息传输速率。才岩峰等人[6]提出基于加密机制的SDN网络信息安全传输方法,该方法利用AES加密算法对网络数据的映射进行加密,并结合SDN传输特征优化传统传输协议,更新流表匹配域,实现信息安全传输,该方法在实现信息安全传输前,没有将分类问题转化求解权重的点群聚类问题以此进行数据分类,导致分类后的涉密数据中含有许多无用数据,大大增加通道缓存数据,导致CPU使用率过高。为了解决上述方法中存在的问题,提出基于点群聚类的网络涉密信息安全传输方法。
2 基于SOFM的点群网络信息聚类
2.1 SOFM的输入和输出
将涉密信息中的离散点群Pn(n=1,2,…,N)通过SOFM点群网络信息聚类的方法进行聚类[7],即结合信息点位置的坐标和属性生成SOFM的输入向量特征,遗传获取出一组带有点群位置的信息数据和专属点群特征的属性数据。点群中的每个点都是SOFM聚类时可输入的样本,将所有信息点组成一个输入样本集合,则输入样本集合的表达式为
x={xn|n=1,2,…,N}
(1)
式中:N代表输入样本的总数。
且xn的表达式为
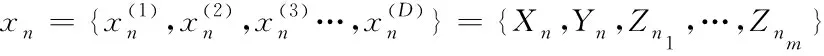
(2)
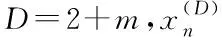
SOFM聚类的输出层又叫竞争层[8],竞争层其中含有神经元,且神经元数量相当于预测出的样本分类数。因此在进行点群聚类前应确认样本分类的数量,根据此数量任意设置输出层神经元,并将此处当作原始聚类中心。在进行数据聚类时,将相同或相似范围内的数据点群特征值当成样本进行运算,可减少训练时间的同时还可保证训练样本分类精度,所以在输入样本数据前需要标准化处理原始数据,处理公式为:
xi=(x′i-xmin)/(xmax-xmin)
(3)
式中,xi代表经过标准化处理后的数据特征分量,x′代表数据未经标准化处理的特征分量,xmax代表特征分量的最大值,xmin代表特征分量的最小值。
2.2 基于点群和属性的聚类距离
将信息中的某组点群通过不一样的分类规则分成很多个子群,以此确定出子群中的聚集特性[9],点群聚类最广泛使用的两种准则分别是方差准则及距离准则,它们的定义分别是子群内的方差保持最小和相同子群中的两点之间的距离最小,不同子群中的两点保持最大。
在进行聚类统计时,最重要的一步就是计算距离,且此距离必须含有点群位置和语义的特性[10],虽然点群聚类中的距离是指一种广义距离,但此距离中具有判别属性间的相近、相似和相关大小的特征,由于距离聚类分析无法详细分析高维点群,所以输入时加入点群的坐标和属性特征再进行SOFM,根据此情况定义出的聚类统计量表达式为
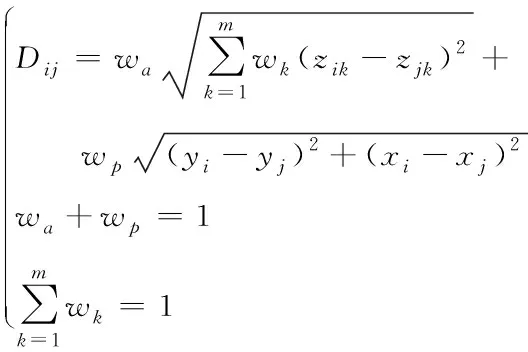
(4)
式中,Dij代表点j及点i间的广义距离,m代表点群的属性特征个数,(xj,yj)代表点j的平面坐标,(xi,yi)代表点i的平面坐标,zjk代表点j的第k个属性值,zik代表点i的第k个属性值,wa代表广义距离中属性距离的对应权重,wp代表空间距离的对应权重,wk代表属性距离计算中每个属性的对应权重。
根据以上总结出的学习算法过程步骤为:
第一步,在区间[0,1]中任意选取并设置SOFM聚类算法中的原始连接权。
第二步,输入点群样本集中的任意一个数据样本xn。
第三步,利用广义距离衡量出最优匹配结果,将最终结点记为c,且结点c的条件为
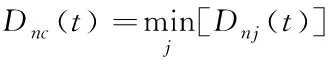
(5)
式中,Dnc(t)代表结点c和第t次聚类计算中第n个输入向量的广义距离,Dnj(t)代表结点j和第t次聚类计算中第n个输入向量的广义距离。
经过多次实验后,学习步长及邻域都有所减少,此学习算法最终是在提取出最终结点和调整权重的基础上,将全部输入矢量投影至参考矢量,实现各个样本都得到最好的分类结果,聚类训练结束后,每个输出结点相应的参考矢量就是所要求的聚类中心,且每一个聚类中心都对应一个训练样本点群。以此实现了涉密信息的点群聚类。
3 加密涉密信息及传输
为进一步加强信息安全,在精确划分涉密信息类别后,将所有涉密信息利用SM2椭圆曲线公钥加密算法进行信息安全加密。
3.1 SM2椭圆曲线公钥加密算法
此算法经大量试验及分析,证明出此算法是目前最有保证且安全的算法,也是最适合网络涉密信息加密的算法[11]。
3.1.1 确定网络系统参数
在SM2椭圆曲线公钥加密算法中,SM2的系统参数就是有限域内的椭圆曲线,因此求解其参数就是求解椭圆曲线,椭圆曲线包括。
1)有限域Fq的规模q。
2)规定椭圆曲线E(Fq)方程的两个成分b∈Fq和a∈Fq。
3)E(Fq)上的基点为
G=(xG,yG)
(6)
式中,G≠0,xG代表Fq上的一个成分,yG代表Fq上的一个成分。
4)G的阶n和其它可选择的项目。
3.1.2 密钥派生函数
假设KDF(Z,Klen)是密钥派生函数,则Z就是所需要加密的信息数据,Klen就是最终密钥的长度。最终获取到密钥长度是Klen的密钥信息数据
k=(Ha1+Ha2)×Klen
(7)
当Klen不是整数时,将Klen设置成1。
3.1.3 涉密信息的SM2加密算法
1)涉密信息的加密过程
第一步,将原始涉密信息数据(椭圆曲线系统参数)和公钥等数据输入算法系统中随机生成参数k,且k∈[1,n-1]。
第二步,求解出椭圆曲线c1点,其表达式为
c1=[k]G=(x1,y1)
(8)
第三步,并求解出椭圆曲线S点,其表达式为
S=[h]PB
(9)
第四步,判断获取到的椭圆曲线点S是否为0,若等于0,则需要退出系统并上报错误,若不等于0,则完成涉密信息的加密操作。
2)涉密信息的解密过程
第一步,当用户在网络系统中获取到密文数据,在密文数据只能够提取出C1密文。
第二步,判断C1是否符合椭圆曲线要求,若不符合则直接报错并退出运算,若符合曲线要求则进行下一步。
第三步,求解出椭圆曲线点S=[h]C1。
第四步,判断椭圆曲线点是否为0,若是,则直接报错并退出,若不为0,则进行下一步运算。
第五步,计算出[dB]C1=(x2,y2)。
第七步,判断私钥t是否为0,若为0,则进行下一步操作,若不等于0,则直接报错并退出运算。
第八步,计算明文M′=t⊕C2。
以上就是涉密信息的安全加密,最后将信息传输给用户,即实现涉密信息安全传输。
3.2 基于路由算法的涉密信息传输
3.2.1 传输路径训练阶段
最终进行安全传输前需将所有传感器节点设置在M×M的区域内,此时的节点都有属于自己的专属位置和ID[12]。且网络中传感器的全部类别都和初始配置相同,已知各个节点的区域位置信息,因此发射节点都可根据距离选择传输功率。
节点收到的数据是损失的能量表达式为
ERx(k)=kEelec
(10)
节点接收到数据后将数据进行一系列处理的能耗表达式为
Eda-fus=kEda
(11)
式中,Eda代表接收数据后的处理单位比特数据的能耗。
利用LEACH算法选取出成簇后,令路由表S代表最短边权值的节点集合,针对所有簇都有任意一个节点M在TDMA时隙中,将采集到的信息传输并标记该簇的簇头Ci,则此簇头将涉密数据全部传输到各个基站的最优路径为:
第一步,簇头Ci按照路由表训练全部邻近簇头,可获取到邻近簇头的边权值。
第二步,将M和Ci间的边权值与Ci对应的簇头的边权值之间生成的边权值和邻近簇头与M产生的边权值进行比较。
第三步,若两个边权值相同,就可在路由表S中构建出最多数量的带有初始状态子路由表,标记Ci对应邻近的簇头。簇头Ci的邻近节点根据上述过程进行训练直到路由表S含有基站后停止训练。
3.2.2 涉密信息稳定传输阶段
在传输阶段,排除掉死亡节点的子路由表,通过结合M和其它子路由以此保存路径,进而评价涉密数据传输性能,并基于余下能量R得出子路由表a的路径代价函数,其函数表达式为:
Djf=EAvg-Re(a)+Re(a,b)+Hop(a)+α
(12)
式中,EAvg-Re(a)代表表a保存路径中余下能量的平均能量,Re(a,b)代表表a保存路径上所产生的b节点的余下能量,Hop(a)代表子路由表a所能保存的路径的跳数值,α代表传输路径中的权重因子。
将每个子路由表保存路径的代价函数值大小进行对比,同时选择出函数值为最小的路径当成最优路径,源节点将采集到的涉密数据根据最优路径响应的子路由表的引导输送给基站,最终实现涉密数据的安全传输。
4 实验结果与分析
为了验证所提方法的整体有效性,在WindowsXP操作系统下对基于点群聚类的网络涉密信息安全传输方法、文献[4]方法、文献[5]方法进行传输成功率、传输速率和CPU使用率进行测试。
4.1 传输成功率对比结果
分析图1可知,在多次迭代中所提方法的传输成功率始终保持百分百,而其它两种方法中总有不明因素干扰传输,导致传输失败,因此降低传输成功率,所提方法保证每次传输都成功是因为它在传输前将涉密数据通过点群聚类的方法进行细致的分类,因此可精确选取传输路径,保证传输的成功率。
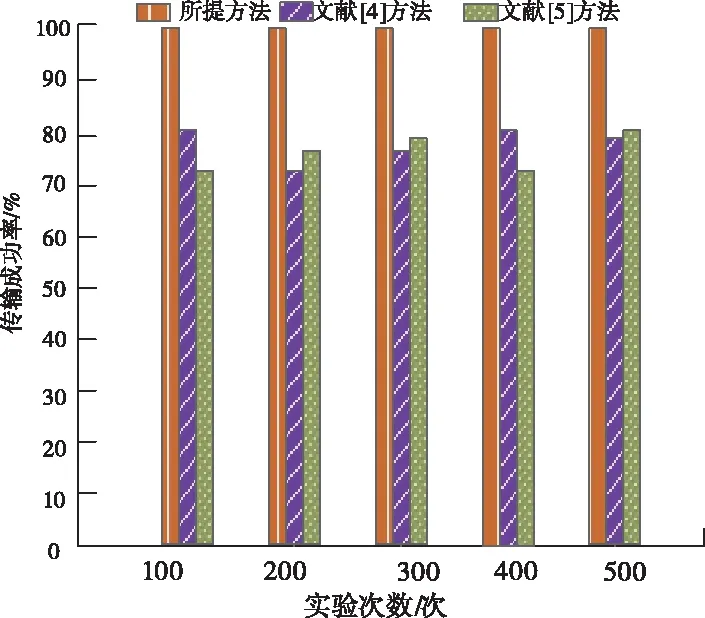
图1 不同方法的传输成功率
4.2 传输速率对比结果
对比三种方法在不同信息量环境下的传输速率,分析图2可知,传输信息量越多会一定程度上导致数据传输速率下降,但所提方法的传输速率始终远远高于其它两种方法,这是因为所提方法利用广义距离的定义将数据转化成属性和点群聚类,以此更加清晰且简便地分类涉密数据,进而简化传输,加快信息传输速率。
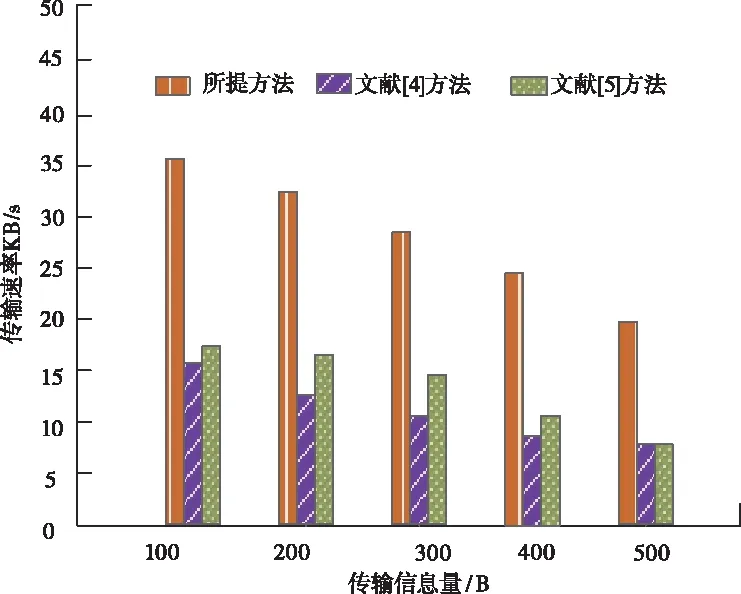
图2 三种方法的传输速率
4.3 CPU使用率对比结果
在传输过程中可能缓存一些无用数据导致CPU使用率过高,正常情况下的CPU使用率不能超过35%,但不小于15%,由图3可知,所提方法的CPU使用率始终保持在20%左右,文献[5]方法的使用率过高,且接近最高值,文献[4]方法CPU使用率次之,这是因为所提方法在实现信息安全传输前,利用可将分类问题转化为求解权重的点群聚类方法进行数据分类,使得所有数据都精确分类并准确传输,降低无用数据被丢弃的概率,保证CPU使用率的稳定性。
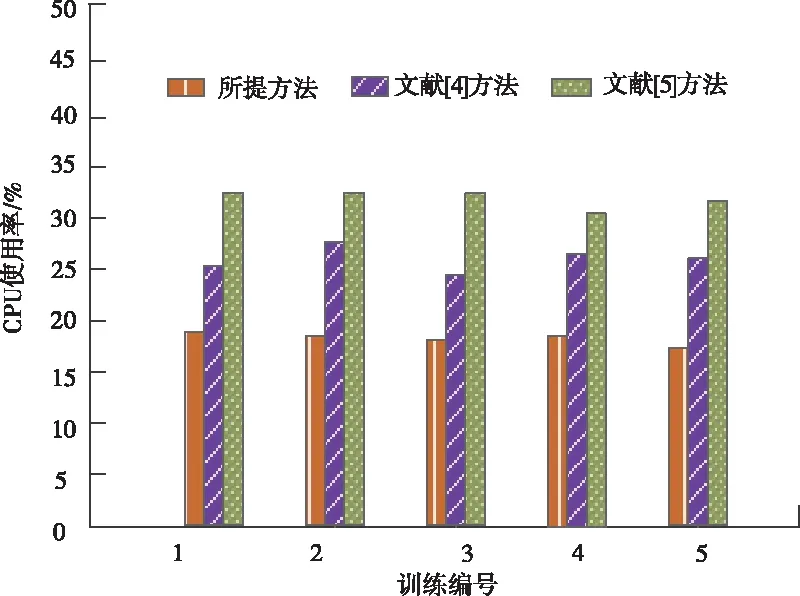
图3 不同方法的CPU使用率
5 结束语
针对当前算法的不足,提出基于点群聚类的网络涉密信息安全传输方法。该方法利用基于SOFM的点群聚类方法将涉密信息详细分类,同时利用SM2加密算法在传输前将数据加密,最终通过路由算法找出最优路径实现信息安全传输。经实验表明,所提算法传输成功率高、传输速率快和CPU使用率稳定。为今后的信息安全传输奠定了基础。
