基于Linux的多核并行可伸缩函数式编程研究
2022-05-14崔素丽孙曼曼
仇 宾,崔素丽,孙曼曼,田 亮
(1. 河北师范大学附属民族学院,河北 石家庄 050000;2. 河北师范大学计算机与网络空间安全学院,河北 石家庄 050024)
1 引言
在传统的Liunx平台编程中,采用较多的是冯诺依曼模型。随着人工智能技术在嵌入式Liunx平台上的普及,大量数据和复杂业务促使多核并行计算能力的提升,基于这种模型实现的编程语言,由于存在IO和指令的阻塞[1-2],造成了很多资源浪费。此外,在实现多线程编程时多采用互斥锁[3],造成了大量数据传输资源的消耗。由于计算规模的增加,多核并行是当前最有效的解决方式[4]。如何更好的实现多核并行计算成为关键,于是,很多专家针对多核并行编程展开优化研究。Leslie在BSP分析基础上提出了Multi-BSP编程模型;C-K Chui在LogP分析基础上提出了mLog编程模型。这些模型虽然能够完成多核并行计算,但是对不同的体系结构通用性较差。此外,也有以多级并行为重点,加上粒度因素的编程模型,如MPI和OpenMP[5]。MPI和OpenMP的粒子不同,MPI是一种相对粗粒度的模型[6];OpenMP是一种相对细粒度的模型[7-8]。
随着多核并行计算应用的越来越多,对多核并行编程模型也提出了越来越高的要求,而函数式编程具有高阶性与无状态性,能够增强编程的模块化与多态性,无需原语即可确保多核并行处理过程中的数据安全性。于是,本文设计了一种基于函数式的编程模型。该模型可以摆脱对互斥锁与状态信息的依赖。模型引入了乘法级数增长的任务窃取策略,能够有效改善任务的负载均衡。同时,模型设计了一种64bits定长哈希并行计算,用来保证数据和通信的完整安全。
2 编程模型构建
采用函数式编程,其最为关键的构件就是函数。利用函数的复合和嵌套,能够使编程过程摆脱状态信息。为了提高函数的描述性,将一些子函数做复合或者嵌套处理。一般可以采取顺序、分支和循环等手段来实现复杂关系的表达[9]。定义如下函数表达式
y(x)=f(u(x),v(x))
(1)
式中,x代表函数y、u、v的输入;同时u与v的输出又是函数f的输入。从该函数可以看出,函数f无需中间状态量就能够取出u(x)与v(x)。另外,函数y的求解涵盖了函数的复合嵌套关系。其中,复合有利于改善编程中的数据传递,主要用于优化内存。而嵌套有利于对复杂问题的拆分,主要用于优化并行处理。
为了更好的描述函数模型,根据函数间的复合关系构造树。如函数表达式(1)中,函数f映射为树y的根节点,函数u和v映射为树y的叶子节点。根据嵌套关系,可以在发生嵌套的时候构建嵌套子树,利用嵌套子树取代相应叶子节点。考虑到语法解析与编译过程对模型构建的约束,这里采用运行时构建的方式。每一个节点可以看成调度单元,从而把函数树模型的构建转换为调度优化问题。树中的任何一个节点对应一个子函数,每一个子函数对应一个独立的Task,由于函数的调用是通过栈的方式实现,因此映射为动态树模型后便可以实现并行处理。动态树模型描述如图1所示。函数能够对问题进行良好的抽象化处理,编程时不必考虑线程安全问题,只考虑树结构即可,有利于提高并行性。此外,所有节点的连接关系最终汇聚到一个根节点上,削弱了叶子节点间的耦合度,有利于提升编程模型的扩展性。
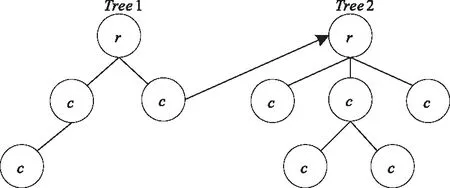
图1 动态树模型
采用动态树模型虽然可以实现并行计算,但是对于多核系统而言,其物理线程也是有限的。所以动态树的并行处理属于求解NP问题,应尽可能保证模型整体的效率。为了方便求解,将动态树模型描述如下
M={N,R}
(2)
集合N是动态树全部节点;集合R是动态树全部节点关系。对于任意节点ni∈N,可以表示为ni:{bi,di}。bi表示ni所属父节下的全部节点数;di表示ni的深度。如果ni是nj的父节点,则节点ni和nj的关系可以标记为ri,j。ri,j体现了父子节点间的约束条件,只有在全部子节点均完成后,父节点ni才会处于就绪态。根据bi和di的分布,该NP问题的优先级表示如下
μi=-(λ1di+λ2log2bi)
(3)
式中,λ1与λ2分别代表节点两种特征的权重。ui值的大小代表了节点ni优先级的高低,ui值越大,意味着ni优先级越高。整个动态树模型依据优先级顺序入队。基于模型分析,可以确定深度影响任务执行的层次和时间,对于深度较小节点,应该为其分配较高的优先级。
3 任务负载均衡策略
3.1 计算资源分析
基于Linux平台的多核系统是资源有限的,在节点任务调度时需要考虑资源约束。首先是处理器性能,它主要受CPU频率、Cache和指令等一些因素影响。因为影响因素过多,无法对单一指标进行量化评价,采用给定任务的方式来测试其计算性能,公式表示如下
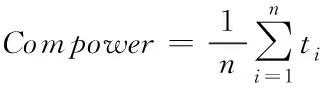
(4)
n是测试的任务数;ti是第i个任务所需的时间。ComPower即可用于描述处理器的计算性能。
然后是系统的存储空间,由于Linux平台在并行任务过程中,每一个任务都应该先检查存储条件。检查存储空间的方式为
Mu=Mall-Mhu
(5)
Mall是系统全部存储空间;Mhu是系统已消耗存储空间。Mu即为系统当前有效存储空间。内存也是Linux平台任务需要考虑的关键资源,其检查方式与存储类似,公式表示为
Ru=Rall-Rhu
(6)
Rall是系统全部内存;Rhu是当前已消耗内存。Ru即为系统当前有效内存。
3.2 任务窃取策略
由前述函数式编程模型可知,基于Linux平台的多核并行函数式编程可以转化为多任务并发调度。而这个过程又可看成是对资源的访问,为了提高整体的编程性能,就需要提高对资源的访问效率和合理性。在改善多核并行处理时,当前一些编程机制会采用回溯与分治操作。由于这些操作一般需要通过线程实现,因此可能会有线程中止导致操作失败的情况发生。可以说当前任何一种编程机制都存在资源问题,尤其是在多核并行处理时任务和资源的不确定场合。于是,本文采用任务窃取策略,核心思想是在监测到Linux平台多核系统的某个线程存在空闲,则会去窃取其余线程任务。
函数式编程时,对多核处理器的队列进行监控,如果发现队列内任务数量低于设定阈值,便将该队列标记为Filch。调度中心在发现Filch标记后,对该队列的窃取对象采取决策。包括窃取的目标Worker执行器和任务规模,其执行代码如图2所示。核心代码中参数performer指定了窃取目标,返回值filchNum为窃取规模。程序对窃取数量采用乘法级数增长,至第次窃取时,任务规模可以达到initFilchn,这样可以避免反复窃取。

图2 任务窃取核心代码
在窃取过程中,除了考虑窃取目标和规模外,因为涉及到迁移与通信操作,还需要充分考虑窃取的时机。根据处理器的实际处理能力来确定窃取阈值。通常情况下,阈值的选取与处理能力成正比。当某个Worker队列内任务规模降至阈值以下,或者Worker队列处于空闲状态,都将触发窃取策略的执行,从而有效权衡多核并行处理与窃取处理的开销问题。基于前述分析,负载均衡的核心代码如图3所示。

图3 负载均衡核心代码
4 哈希并行计算
由于Linux平台应用涉及的数据和通信对完整性、安全性要求日益增加,本文设计了一种哈希并行计算。保证原始消息(Message)可靠性的同时,也尽可能避免对并行处理效率的影响。Message是任意长度,且可能包含字母、数字和特殊字符。假定Message的字符长度是Lc,则中所有字符对应的ASCII二进制串可以表示为
C=Binary(c1,c2,…cn)
(7)
式中,ci是Message内第i个字符;n是Message内的字符总数。为了提高不规则消息的处理效率,这里将输出统一为64bits哈希值。根据消息中字符的数量,视情况采取补位操作,补位规则描述如下
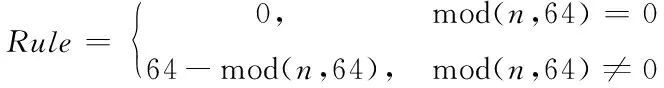
(8)
利用该公式对Message的字符数量进行检查,只有当n是64的整数倍时,无需采取补位操作。通过迭代对c4i…c4i+3进行序列拼接,其迭代处理过程描述如下
xt+i-1=xt+i-2XOR(c4i…c4i+3)
(9)
迭代过程直至所有的Message位执行结束,通过随机方式从中选出64bits哈希值。
为了验证Message字符拼接的混沌性,通过三维球形空间中的3000个点分布来进行模拟,迭代结束后的分布结果如图4所示。从分布结果可知,虽然混沌计算在单次会表现出一定的随机性,但是整个迭代过程是存在确定性的。所有点在球形空间中表现出良好的均匀分布,表明所设计的哈希生成方式不仅具有良好的随机性,而且具有良好的分布均匀性。
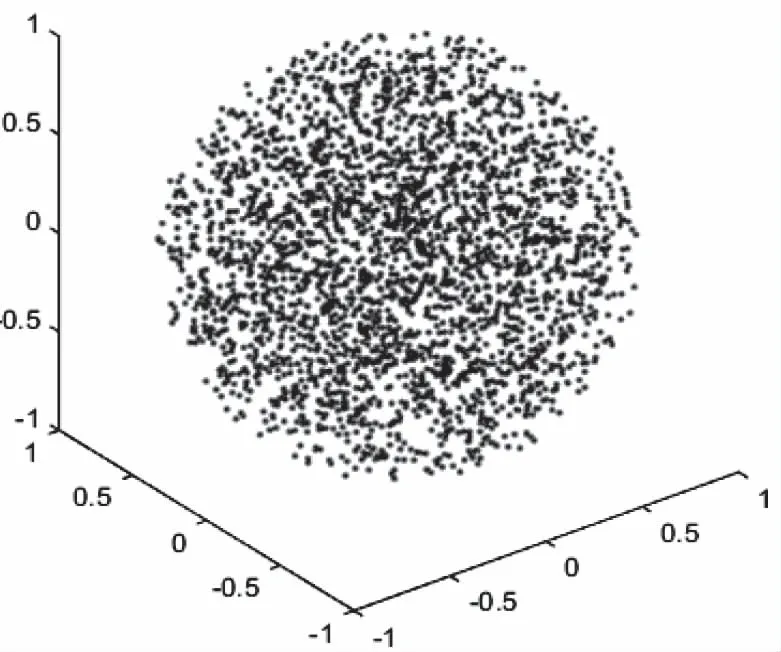
图4 混沌映射结果
5 仿真与结果分析
实验服务器选择Intel Xeon E7-4820型号处理器,该处理器为八核。此外,服务器内存是128B,操作系统是Ubuntu16.04。测试过程使用的应用程序包括histogram、linear regression和word count,它们所使用的数据集大小分别为2.0GB、3.5GB和3.0GB。为了测试多核并行编程的性能,分别从执行时间和可伸缩性进行验证。
5.1 执行时间分析
将本文所提的多核并行编程模型与MPI、OpenMP[8]进行性能比较,首先测试三种编程模型的执行时间。针对histogram、linear regression和word count应用程序,采用10次求平均的方式得到三种模型的最终时间,结果如图5所示。通过结果对比可得,三种编程模型在执行不同应用程序时的性能存在细微差别,这是由于不同的应用程序对任务、内存和存储等资源的分配存在差异导致的。但是综合来看,本文所提的函数式编程模型优势明显,在histogram、linear regression和word count应用程序的执行时间上仅为MPI模型的7.13%、11.51%和8.02%;为OpenMP模型的17.05%、25.13%和17.50%。
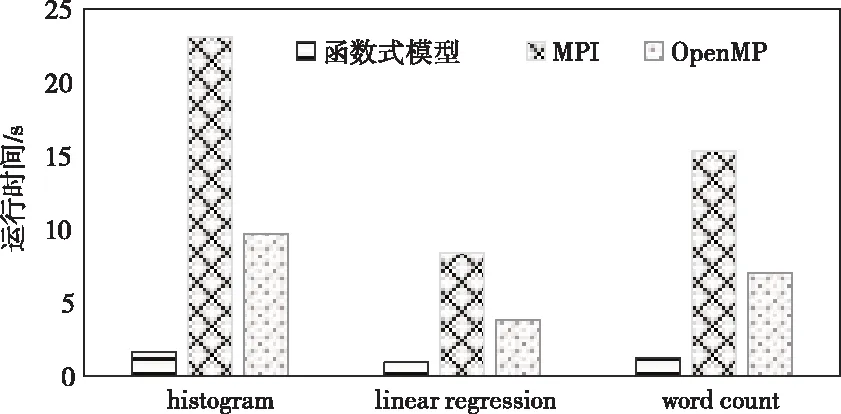
图5 不同编程模型的执行时间比较
5.2 可伸缩性分析
在大多数并行编程模型中都存在严重的锁竞争,测试得到不同编程模型在histogram、linear regression和word count三种情况下的锁竞争情况。图6为不同编程模型在Linux平台上的锁竞争开销。从结果分析可知,所提多核并行函数式编程能够将锁竞争开销稳定的控制在0.5%以下,显著降低了锁竞争现象的发生,避免由此导致的额外开销。
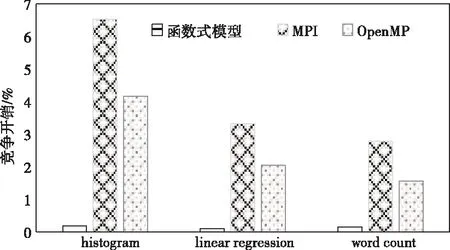
图6 不同编程模型的锁竞争开销比较
由于处理器的核数量直接影响并行计算能力,核数量越多,并行计算能力越高。为了描述多核并行计算能力,采用加速比作为评价指标。它是用于描述单核和多核情况下,某个应用的执行时间比,计算公式为
Sur=Tcore(1)/Tcore(n)
(10)
式中,Tcore(1)是单核情况下的执行时间;Tcore(n)是多核情况下的执行时间。
测试得到不同编程模型对histogram、linear regression和word count应用程序的平均加速比,结果如图7所示。从结果比较可知,所提函数式编程模型加速比近似于线性,能够更好的利用多核提高应用程序的执行速度。结合锁竞争测试结果,表明所提函数式编程模型在提高多核利用率的情况下,明显减少了线程访问公共资源时的开销,显著提升了多核并行编程的可伸缩性。
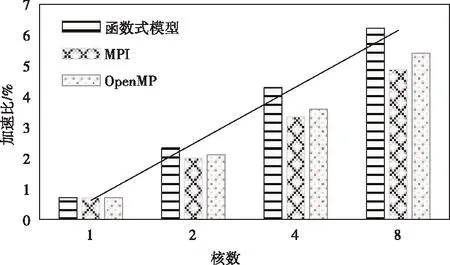
图7 不同编程模型的加速比
6 结束语
本文针对Liunx平台编程中存在的IO和指令阻塞,以及互斥锁等问题,提出了一种多核并行函数式编程模型。采用函数的复合和嵌套,能够使编程过程摆脱状态信息。同时,结合顺序、分支和循环等手段能够实现复杂关系的表达。函数模型转换成动态树后,可以看成是对资源访问的优化调度,于是设计了负载均衡策略和64bits定长哈希并行计算,确保资源访问和数据安全。通过仿真测试,得到在不同应用程序情况下,函数式编程模型的执行时间、锁竞争与加速比均明显优于MPI和OpenMP模型,表明函数式编程模型具有更高的执行效率,可伸缩性得到显著提高,具有更高的多核并行计算能力。
