基于机器学习的自适应预测式外呼算法研究
2022-05-14赵越超李睿哲汪达钦
赵越超,李睿哲,汪达钦
(1. 东华大学旭日工商管理学院,上海200051;2. 伦斯勒理工学院,美国 纽约 12180)
1 引言
电话外呼客户是当前诸多企业主动触达客户、服务客户的重要手段之一。然而由于存在空号、无人接听、电话占线等情况,并非所有电话都会接通,营销类的电话接通率一般只有5-20%[1]。传统的外呼模式是依靠人工手动拨号[2]进行外呼,当接通率较低时,大量人力浪费在拨打和等待的时间上,导致坐席的有效工作时长短,坐席利用率低下等问题。为了提升坐席利用率,企业引入了自动外呼的方式,即利用机器人代替人工拨号,在电话接通后再转给人工。这种方式可以大幅提高坐席利用率,但需要精确计算外呼速率:如果外呼速率过高,会出现客户接通但没有空闲坐席及时接电话的情况,那电话的性质就会变成骚扰电话,也称之为呼损;如果外呼速率过低,会出现大量坐席空闲的情况,无法体现自动外呼的优势。因此预测式外呼[3]的概念被引入了进来,即采用有效算法计算每周期内最合适的外呼速度[4],从而控制坐席利用率与呼损的平衡。
预测式外呼算法的难点主要体现在如下几方面:首先,系统自动外呼的速度与呼损率呈现出一种互相制约的关系,无法同时达到高水准的平衡。外呼速度过快会导致呼损升高,形成骚扰电话影响企业口碑[5];外呼速度过会慢导致坐席利用率低下,浪费人力成本。其次,手动调整算法速度存在流程繁琐、不准确等问题,且对员工的技术要求极高。一般情况下,员工只能利用过去实际测试得到的经验来设置不同的外呼速度,而且每当负责调试算法的员工更换时,经验也会随之改变,所以具有很大的不确定性。最后,现有的预测算法能够使用的范围十分有限,无法完全自动化,且难以适应不同业务的外呼环境。对于客户接通率高的名单,现有算法具有较好的拨打效果,而对于接通率低的名单拨打效果则不令人满意,这对于业务数量庞大且适用场景较多的大型企业来说,就只能退而求其次,在接通率低的名单中选择人工调整拨打速度或者直接选择手工拨打,这大大降低了预测试自动外呼的效率。
在此之前,已有很多位学者对预测式外呼算法展开过研究。Fourati等[6]采用连续时间马尔可夫链(CTMC)来控制外呼频率与速度,在外呼频率与坐席利用率之前进行权衡,减少客户等待时间,但是没有控制呼损;Dumas等[7]同时考虑了呼入与呼出,但设定总有k个坐席是空闲的,导致坐席利用率偏低;Bhulai等[8]对排队模型展开了深入研究,但仅当坐席数超过阈值才会分配接通的电话,没有考虑客户愿意等待的最大时间;Avramidis等[9]提出仿真模型和基于仿真的决策可能会在呼叫中心的管理中发挥核心作用;Pichitlamken等[10]也采用CTMC控制排队情况并采用了仿真模拟,但最终仅有70%坐席利用率和超过3%的呼损,结果并不理想;李刚[11]等人提出从预测式外呼算法和动态统计两方面同时优化,避免出现瓶颈问题,但仅使用了两组真实数据模拟,且规定坐席数偏少;马丽[1]等人提出从通话结束的概率入手及时更改外呼速度的,但使用的号码接通率偏高,没有考虑接通率很低的情况。
本文的主要目的是提出一种可以根据呼叫环境自适应调整的预测式外呼算法,该算法能够通过调节外呼速度使坐席利用率与呼损率在理想范围内。本文与其它论文的不同之处在于:①使用机器学习技术构建预测试外呼算法;②构建仿真平台模拟外呼流程,通过该平台获取机器学习训练数据以及实验验证,是一种数据驱动的预测试外呼算法;③该算法无需通过手动调整参数,能够自动适应不同接通率、通话时长的外呼环境。
2 自适应外呼改进算法构建
2.1 问题描述
本文旨在构造一个预测式外呼算法,目标是在不同的业务场景下,可以根据话务波动进行自适应调整,从而保持高水平的外呼效果。预测式外呼的效果是由两个指标来评价的:坐席利用率(即坐席通话时间占坐席工作时间的比率)和呼损率(呼损个数占接通个数的比率)来决定。由于坐席利用率和呼损率是正相关的,即坐席利用率的升高会导致呼损率的升高,所以算法需要在控制呼损率的前提下,尽可能地提升坐席利用率。
预测式外呼的流程如下,首先由算法根据当前反馈的上周期数据状态计算出需要拨打的电话量λ(每隔一定时间计算一次,间隔的时间称为决策周期),之后系统自动拨出λ个电话,每通电话的振铃时间β服从某个随机分布,振铃后有λρ(ρ为接通率)通电话被客户接通,λ(1-ρ)通被挂断,若此时有空闲坐席N个,则会由控制系统分配坐席给已接通电话,分配后若有剩余c通电话无坐席分配,则进入等待区。假设在等待区的电话的最大等待时间η服从某个随机分布,在此之前若有空闲坐席,则会自动接通电话,否则客户会挂断电话,形成呼损。每周期外呼流程具体如图1所示。
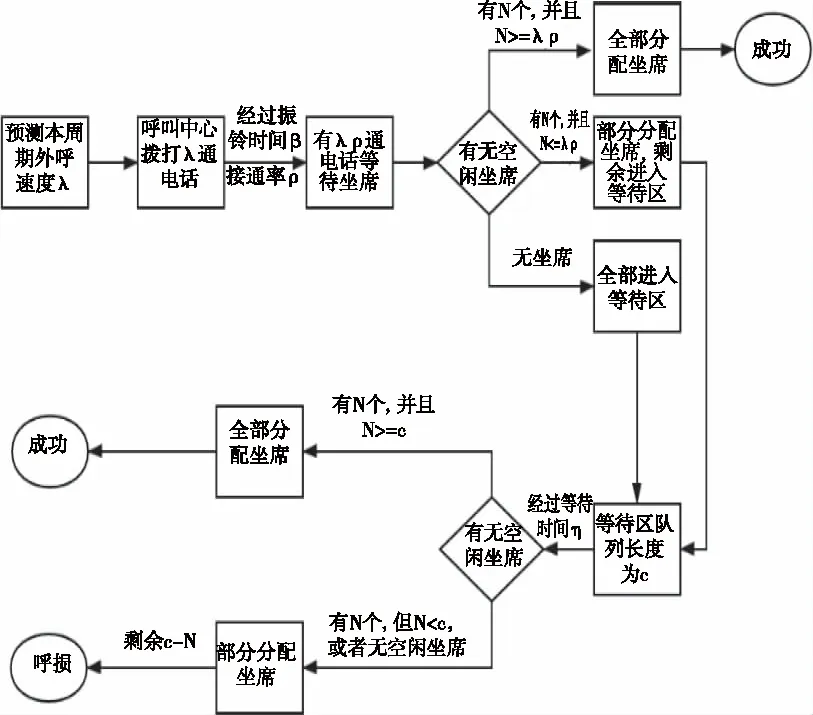
图1 每周期外呼流程图
并作如下假设:
1)坐席员工一个电话结束后,无缝衔接下一通电话;
2)坐席员工服务时间同质化,即每个员工单通电话的通话市场服从同一分布;
3)振铃时间和通话时间服从负指数分布[12]。
定义变量如表1所示:

表1 变量定义表
2.2 建立模型
预测式外呼的效果是由外呼速度与之前k个周期的坐席状态决定的。预测式外呼的效果评价指标包括坐席利用率与呼损率。外呼速度是该周期内需要拨打的外呼数量,该数量决定了拨打所需的坐席资源。坐席状态中的主要内容能够计算出下周期可利用的坐席资源,其内容包括空闲坐席数、繁忙坐席数、振铃数、接通率、等待队列长度,其中空闲坐席数是直接可利用的坐席数量,繁忙坐席数将在下一周期按照一定比例转化为空闲坐席数,振铃数通过接通率折算转化为下一周期将要占用的空闲坐席数量,等待队列长度中的一部分也将在下周期占用空闲坐席。因此,根据上文中预测试外呼效果、外呼速度、坐席状态之间的关系描述,可构建如下数学模型
Agent_ratiot+1=f(Call_speed,Xt,…,Xt-k)
Lost_ratiot+1=g(Call_speed,Xt,…,Xt-k)
Xt=(Freestaff_numt,Busystaff_numt,
Ringing_numt,Connect_ratiot,Queue_numt)
其中Xt为t周期的坐席状态,k是观察周期数量。
由于上述模型中的f和g函数无法得到显性的表达式,且实际运行过程中,话务的接通率会存在波动,使得事先预制的模型都无法适应变化,因此设计了一种自适应的算法,根据实际数据来动态拟合f和g函数。建模思路为:构建模拟自动化外呼的全流程仿真平台,利用仿真平台进行实验来获取训练数据集,然后利用机器学习方法来训练模型。具体步骤如下:
首先,构建自动化外呼的全流程仿真平台。该平台能够模拟每通电话的拨打、振铃、接通、等待、通话、挂断等流程,且能够模拟多通电话大规模并行拨打、按周期持续拨打,并同时模拟不同分布的振铃时长、通话时长。
其次,利用仿真平台生成机器学习训练数据。假设外呼速度起始量等于当前空闲人力:
Call_speed=Freestaff_num+n
其中n为调整量。按照固定周期,以Call_speed的速度进行外呼,每m个周期后,使n从0按照一定的步长自增,间隔m个周期的作用是使n的增长所产生的坐席利用率变化趋于稳定,记录n自增时周期的外呼速度、坐席状态、坐席利用率与呼损率作为一条训练样本。自增n直到某一个n满足Lost_ratio>Lost_ratiomax(给定可接受的最大呼损率),则停止实验。通过重复多组随机数据实验,可以得到样本数量充足的训练数据集。
最后,利用仿真平台生成的数据集训练机器学习模型。本文使用的机器学习算法是LSTM算法,LSTM算法能够较好地学习多个时间步的状态特征。
通过上述机器学习模型,能够通过外呼速度Call_speedt与坐席状态Xt,得到相应坐席利用率Agent_ratiot+1与呼损率Lost_ratiot+1。由于坐席状态是客观存在的,所以能够通过选取合适的Call_speedt,使t+1周期在满足呼损率的条件下Agent_ratiot+1最高。由于Call_speed与Agent_ratio是正相关的,所以可以在最小最大外呼速度之间使用二分法快速查找到最合适的Call_speed。
3 仿真数值分析
本节将利用数值实验来验证该算法的效果和稳定性。首先会构建一个简单的仿真平台,来模拟真实的预测式外呼的流程,并把不同的算法(自适应算法以及对比算法)嵌入,来验证算法效果。
首先参照图1中流程构建了一个仿真平台,模拟电话的拨打、等待、接通、挂断等流程,其中对每通已拨出的电话实时按秒更新其状态。仿真平台会在每次拨完一份名单后,自动统计总体的数据。该仿真平台能在最大的程度上模拟了实际预测式外呼的情况,且可以用极短的时间来模拟现实中很长的一段外呼时间,从而帮助评估算法的效果。
基于上述仿真平台,开展了一系列的数值实验来验证和分析自适应算法的效果,并分析了算法在不同场景中的鲁棒性。
选取了Pichitlamken等[11]的CTMC队列模型来作为对比模型,该模型通过经验值研究服务队列,对队列深入探究后改进经验算法。该论文中也采用了实验,通过十万天的仿真,得到的平均坐席利用率为73.3%,呼损率6%。用精确式算法[13]作为下限模型,该模型优点是可以控制呼损为0,但实验效果一般。
3.1 话务总量和坐席数量的影响效应分析
首先分析自适应算法在不同话务量和坐席数量下的表现。考虑了话务量为10000,50000,100000,以及坐席数量为10,50,100,500,1000,共15种情况。实验中,设定接通率为0.2,服务时间均值为30s,决策周期为10s。仿真结果如表2所示。
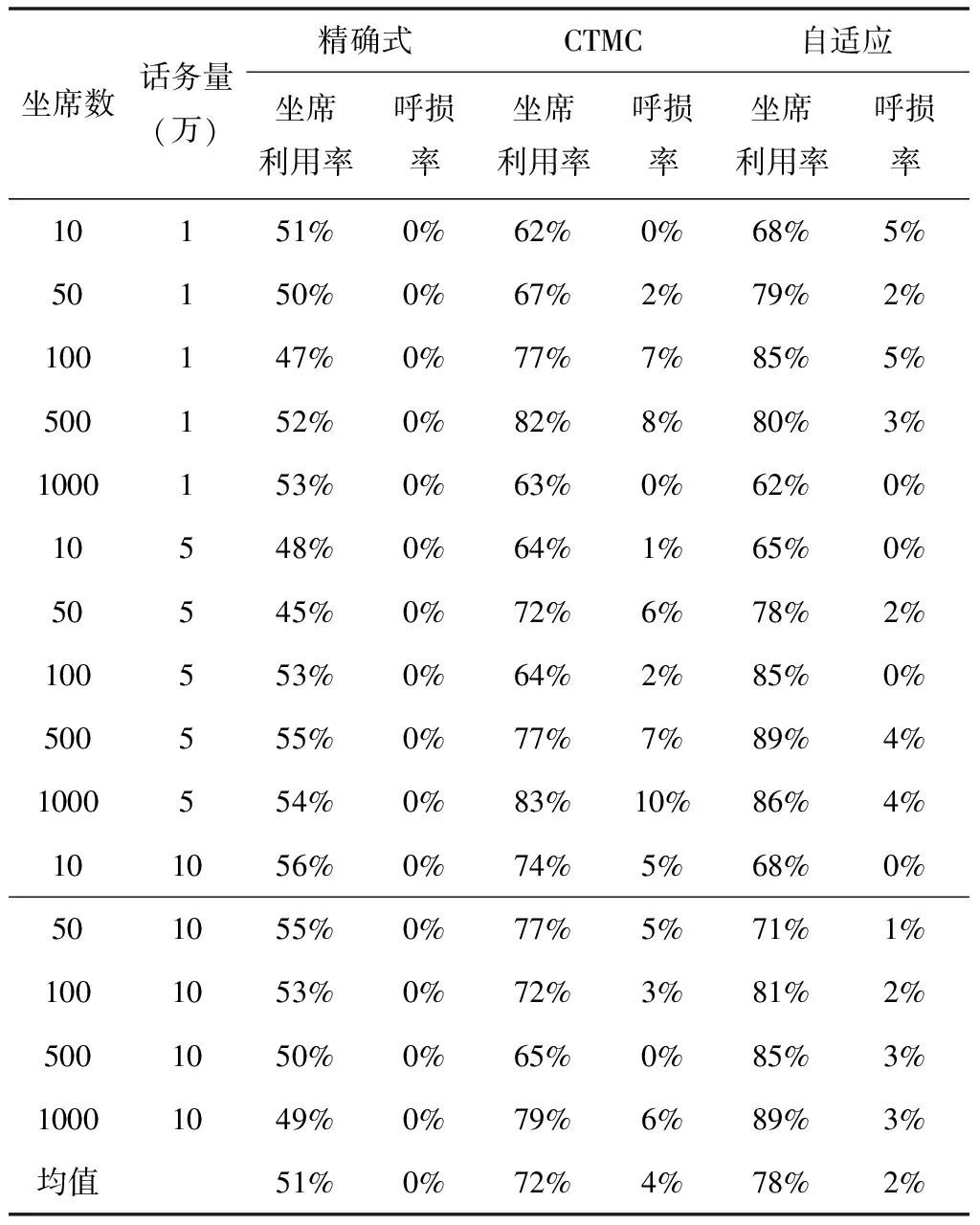
表2 坐席数与话务量对算法结果的影响表
通过表2可以得出,精确式算法虽然能够保障零呼损,但坐席利用率太低。对比自适应算法和CTMC算法,发现自适应算法总能在相同呼损的情况下获得更好的坐席利用率。说明自适应算法在不同的人员数量或者话务量情况下,都明显优于CTMC算法。
3.2 接通率的影响效应分析
为了验证不同话务波动下自适应算法的表现,选取了接通率为0.1~1,间隔为0.1的10组数据来测试算法。其中设置实验话务量10000,坐席数100,通话时间均值30s、标准差30s以及决策周期10s。仿真结果如表3所示。
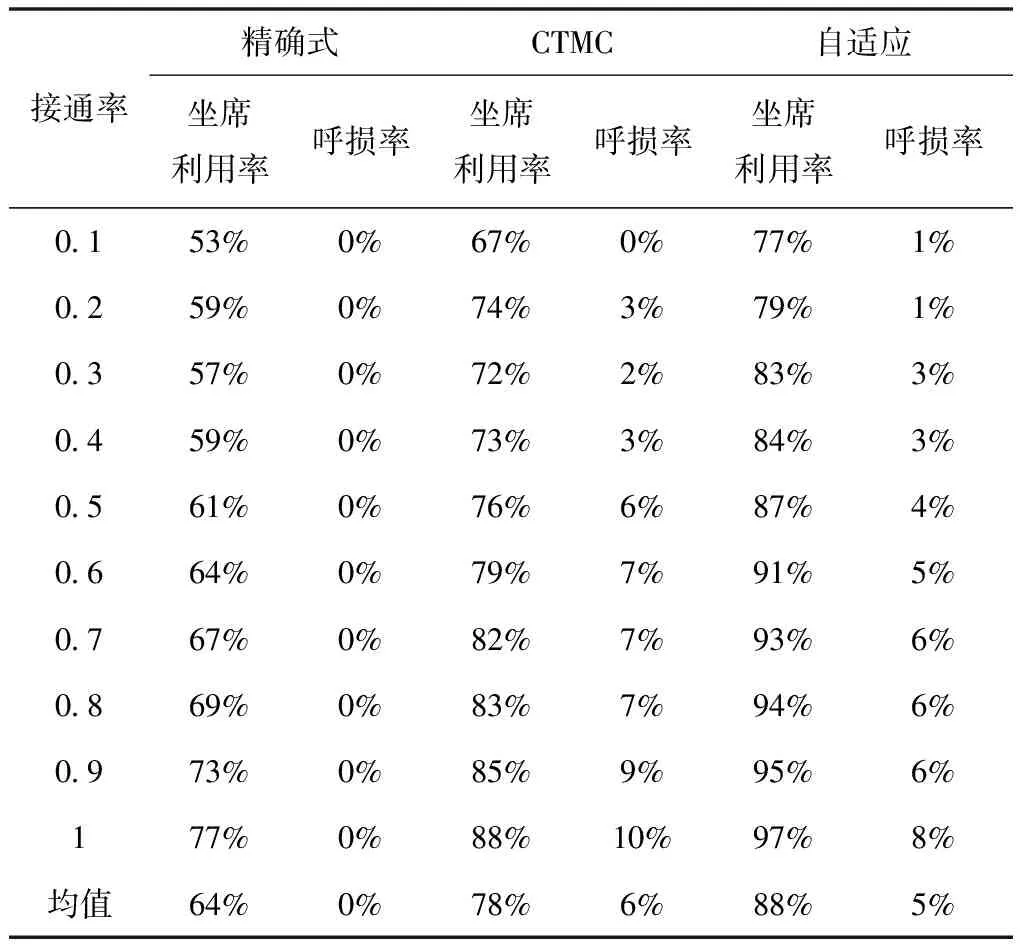
表3 接通率对算法结果的影响表
由表3可知,自适应算法的结果在总体上与对比算法相比明显较优,并大幅超过了下限算法,坐席利用率均值为88%,呼损率为5%。另外,可以发现图2中出现了坐席利用率与呼损率随着接通率升高的情况,这是因为接通率高时,接通的电话量也不断增加,相同人力下,坐席利用率更容易达到饱和,因而会触发更多的呼损。
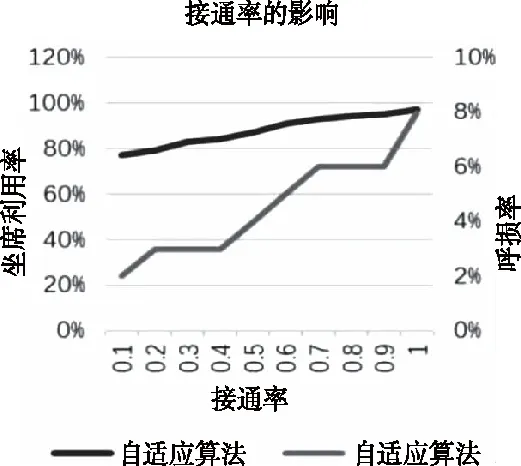
图2 接通率对自适应算法的影响折线图
3.3 通话时长的影响效应分析
根据企业现实话务数据分析得出,通话时间近似服从负指数分布,且均值在30s左右。本节选取了不同的通话时间分布(均值取30s和300s,标准差取1~5倍均值)的10组数据测试算法。实验数据设置为话务量10000,坐席数100,接通率0.3以及决策周期10s。仿真结果如表4所示。
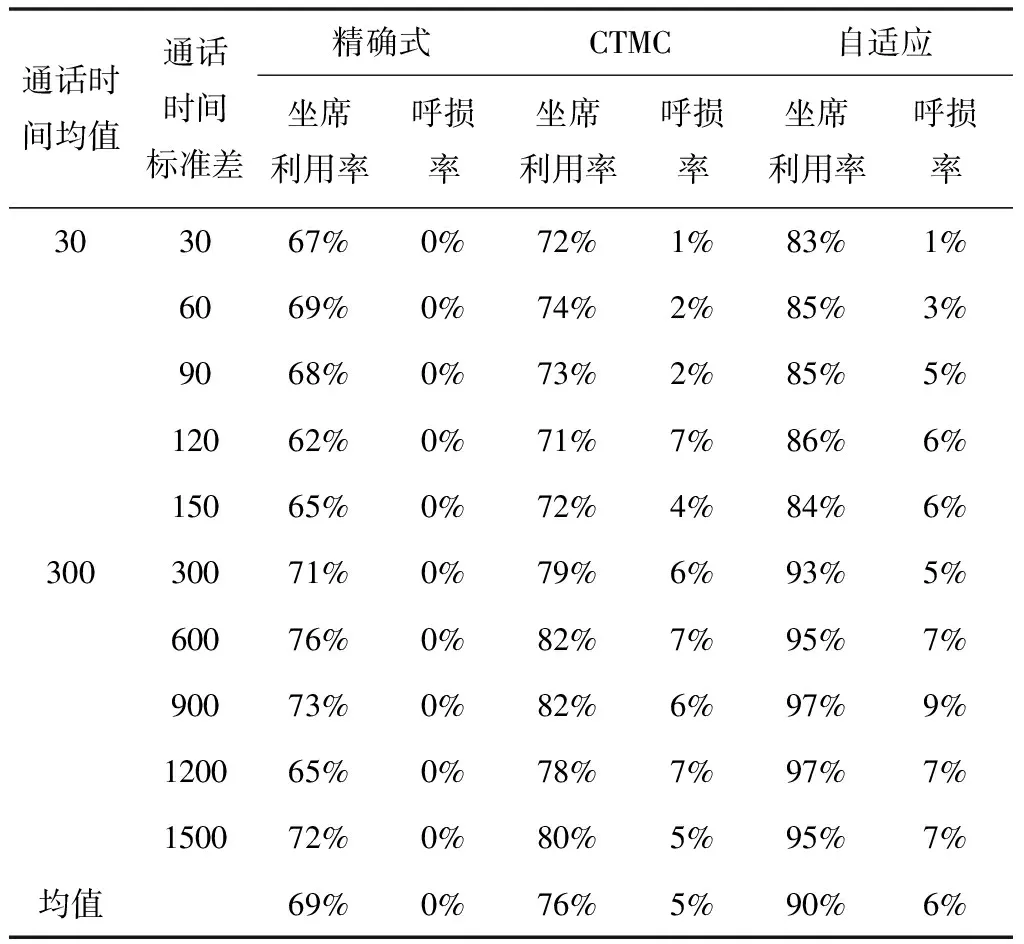
表4 通话时间波动情况对算法结果的影响表

图3 通话时间波动对自适应算法的影响折线图
由表4可知,自适应算法在每个实验中的结果均优于另外两种算法,坐席利用率均值90%,呼损率均值是6%,且通话时间越长,坐席利用率越高。同时随着通话时长波动性变大,呼损一般也会变多,这是因为波动性会带来更多的不确定性,使得评估函数的准确性降低。由图3可知通话时间分布的变异系数不同时,对自适应算法坐席利用率和呼损的影响并不大,说明算法具有很好的鲁棒性。
4 结论
本文设计了一种基于机器学习的自适应预测式外呼算法,目的是更好地解决预测式外呼问题,帮助企业提升效率,降低成本,同时尽可能避免客户抱怨。利用机器学习来构建关键变量的函数关系,并设计了自适应的算法机制。搭建了仿真平台来模拟实际的预测式外呼过程。通过数值分析结果发现,自适应算法在不同场景下(不同坐席数,不同接通率,不同通话时间分布)都明显优于两种对比算法,且具有很好的稳健性。
