基于多维神经网络深度特征融合的鸟鸣识别算法
2022-05-13吉训生
吉训生 江 昆 谢 捷,2,3
(1.江南大学物联网工程学院,江苏无锡 214122;2.轻工业先进过程控制重点实验室(教育部),江南大学,江苏无锡 214122;3.江苏省先进食品制造装备与技术重点实验室,江南大学,江苏无锡 214122)
1 引言
近年来,随着生态环境的不断恶化,全球鸟类数量正不断减少,越来越多的学者开始关注鸟类生物多样性的保护。然而,这项工作的首要任务,就是对鸟类的活动进行监测[1]。目前,鸟类活动的监测主要由专家进行,他们一般通过听觉来识别鸟的种类[2]。然而,这个过程是昂贵且耗时的。
随着无线声传感器网络的发展,人们可以自主部署无线声传感器网络进行连续录音[3-4],通过远程分析录音数据来获得物种的组成。然而,每一个声传感器每天会产生大量的声学数据。因此,开发一个自动化的鸟鸣识别系统变得非常重要[5]。目前,鸟类识别主要包括基于视觉的方法、基于声音的方法以及二者混合的方法。其中,声学传感器可以帮助收集更大时空尺度的音频数据,无需考虑角度与遮挡问题,成本低廉。
现今,已有很多学者对鸟鸣识别开展了研究,LUCIO 等人[6]使用三种纹理特征算子:局部二值模式、局部相位量化与Gabor滤波器,联合支持向量机在46 种鸟类中获得了77.65% 的准确率。FRITZLER 等人[7]以音频信号的声谱图为特征,使用预先训练的Inception-v3 卷积神经网络在1500 种鸟类,36492 个样本中获得了0.567 的平均精度均值。XIE 等人[8]首先分别使用声学特征、视觉特征与深度学习等三种方法对鸟鸣分类,其中,深度学习最高获得了94.36%的F1 得分,优于声学特征(88.97%)与视觉特征(88.87%),最后,将三种方法融合在14种鸟类中获得了95.95%的F1得分。
飞行叫声指的是鸟类在持续飞行中所发出的特有声音,如候鸟迁徙,其研究如下:SCHRAMA 等人[9]提出使用持续时间、最高频率、最低频率、最大频率幅值、平均带宽、最大带宽和平均频率斜率作为特征集,使用欧氏距离算法匹配最优类别。MARCARINI 等人[10]使用梅尔频率倒谱系数联合高斯混合模型用于鸟鸣分类。SALAMON 等人[2]提出使用球形k-means 无监督学习算法,从对数尺度的梅尔谱图中生成字典特征,使用支持向量机在含有43 种鸟类,5428 个样本的CLO-43SD 数据集中获得了93.96%的准确率。之后,为了进一步提高模型的表现,SALAMON 等人[11]将球形k-means算法与卷积神经网络进行基于类的后期融合,获得了96.00%的分类准确率。然而,CLO-43SD 是一个不平衡的数据集,不同类别的样本数量存在显著差异。因此,通过准确率难以衡量模型对每一种鸟类的分类性能。为了解决这一问题,文献[1]使用平衡准确率作为衡量指标,将VGG Style 网络与Sub-SpectralNet 进行后期融合,获得86.31%的平衡准确率。
为了进一步优化鸟鸣识别,本文以CLO-43SD数据集为研究对象,包含43种北美林莺(鹦鹉科)的鸟鸣[2],提出一种基于多维神经网络的深度特征融合系统用于鸟鸣分类,包括1D CNN-LSTM、2D VGG Style 与3D DenseNet121,使用两种浅层分类器:最近邻与支持向量机,在含有43 种鸟类的CLO-43SD数据集中最高获得了93.89%的平衡准确率,显著优于先前的工作。
论文的主要贡献:(1)对已有的Mel-VGG模型进行改进,提取鸟鸣对数尺度的梅尔谱图作为时频特征,增强时频谱图的能量分布,并使用Mix up数据混合以减少过拟合。(2)将CNN-LSTM 与DenseNet121的全连接层优化,减少模型参数,提高实时性。(3)提出一种基于多维神经网络深度特征融合的鸟鸣识别系统,有效提高了鸟鸣识别准确性,相对于最新的Mel-VGG 与Subnet-CNN 融合模型[1],平衡准确率提高了7.58%。
2 基于多维神经网络的深度特征融合过程
本文以CLO-43SD 数据集为研究对象,包含43类北美林莺的迁徙鸣声,具有持续时间短、频率高等特点,一般不超过200 ms,不同北美林莺鸣声的发声时长与峰值频率如图1 与图2 所示。可以看出,不同种类鸟鸣的持续时间与峰值频率各不相同,对应的时频谱图也存在差异,如BTYW 的峰值频率为22 Hz,LOWA 的峰值频率为7963 Hz,其对应的梅尔谱图如图3 所示。BTYW 的能量主要集中在低频,LOWA 的能量主要集中在高频,二者的梅尔谱图存在显著差异。
针对深度学习优异的学习能力以及不同维度模型表现的互补性,本文提出一种基于多维神经网络的深度特征融合过程用于鸟鸣分类,包括1D CNN-LSTM、2D VGG Style 与3D DenseNet121,如图4所示。可以看出,该过程主要包括5个阶段:预处理、特征提取、深度特征生成、最小最大归一化与分类,详细描述如下。
2.1 预处理
在CLO-43SD 数据集中,每一段鸟鸣的持续时间不同,其对应的时频谱图大小不一致。本文将每一段鸟鸣多次复制连接,通过截取前2 s 使每个样本持续时间相同[12]。由于录音条件的不同,同一类鸟鸣样本幅值差异较大,本文将每一段鸟鸣去均值归一化,如式(1)所示:
其中,s(n)为输入信号,mean(·)、max(·)与abs(·)分别为均值、最大值与绝对值。
2.2 特征提取
一般来说,鸟鸣具有频率高,短促等特点,使用纹理描述子可以将鸟声划分为长度很小的时间片段,通过整合短时间内的纹理特征来描述鸟鸣。为了提取鸟鸣的深层特征,本文使用多层局部二值模式[13](Multi-level local binary pattern,Multi-level LBP)作为纹理描述子,以一维二值模式[14-15](one dimensional binary pattern,1D BP)与一维三值模式[16-17](one dimensional ternary pattern,1D TP)为基础,以“sym4”为基小波对鸟鸣信号进行9 层小波分解,最后,分别对9层低频小波系数与输入鸟鸣提取1D BP与1D TP并连接得到Multi-level LBP-T特征。
为了描述鸟鸣的频域信息,对预处理后的鸟声进行离散余弦变换[18](discrete cosine transform,DCT)和傅里叶变换(fast Fourier transform,FFT),并对FFT 结果的幅值提取多层LBP 特征,得到Multilevel LBP-F[19]。最后,将Multi-level LBP-T 与Multilevel LBP-F 特征连接,得到Multi-level LBP-T-F,作为1D CNN-LSTM的训练特征,如图5所示。
对于2D VGG Style,针对不同种类鸟鸣梅尔谱图的差异性,如图3 所示。本文选用预处理后鸟声对数尺度的梅尔谱图作为VGG Style 的训练特征。其中,梅尔谱图的行数为40,帧移为1.45 ms。同时,将对数尺度的梅尔谱图复制三份形成三通道作为3D DenseNet121 的训练特征,与彩色图像类似。
2.3 深度特征生成
2.3.1 VGG Style模型
VGG 模型[20]是2014 年ILSVRC 竞赛的第二名,性能优异,然而其参数量有140M 之多,需要更大的存储空间。VGG Style 作为轻量级的VGG 模型在声音识别中得到了广泛应用,如声音场景分类[21]与鸟鸣识别[1]。本文使用VGG Style 作为鸟鸣时频谱图的特征提取器,如表1所示。
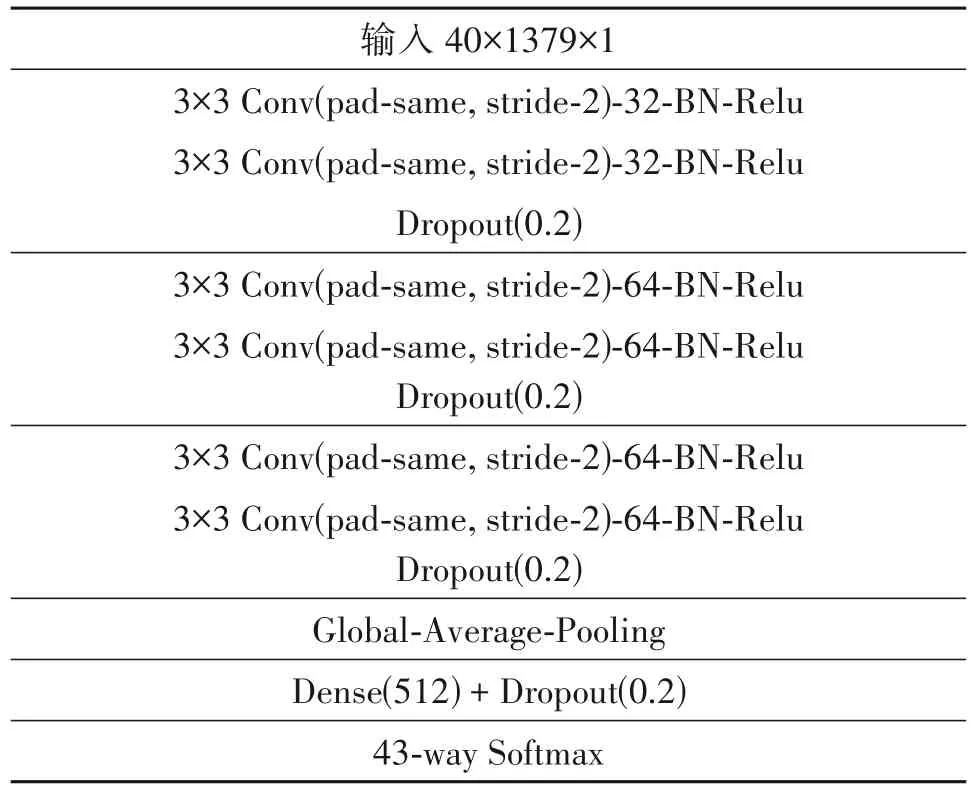
表1 VGG Style的网络结构Tab.1 The Network Structure of VGG Style
可以看出,VGG Style 主要有9 层,包含三个卷积块、一个全局平均池化层与全连接层。其中,每个卷积块包含两次卷积和一次dropout。在CLO-43SD 数据集中,含有43 种鸟鸣,因此输出层神经元个数为43,通过Softmax函数,输出43种鸟鸣的预测概率,如式(2)所示:
最后,使用argmax 函数将概率最大的鸟类作为最后的预测标签。其中,优化器为Adam,学习率为10-4,损失函数为交叉熵,批大小为32,训练批次为200。同时,使用Mix up数据增广[22]以线性插值方式生成虚拟数据加入模型训练,如式(3)和(4)所示:
其中,λ∈[0,1]。α∈(0,∞)时,λ~Beta(α,α)。xi,yi为数据集中随机抽取的原始的特征与标签,x′i,y′i为生成的特征与标签,yi,y′i为one-hot编码形式。模型训练完成后,计算每一段鸟鸣Dense(512)层的输出作为深度特征。
2.3.2 CNN-LSTM 模型
以往的研究表明,不同维度的模型可以分别学习信号中的时间与空间动态信息,通过将不同维度的模型融合,往往可以有效提升性能[23]。据我们所知,这是第一次将多维度网络融合应用于持续飞行中的鸟鸣识别。对于1D CNN-LSTM[24],通过堆叠三个局部特征学习块和长短时记忆网络以提取鸟鸣特征,其中,局部特征学习块由一层卷积和一层最大池化组成。鸟鸣信号是时变信号,需要特殊处理以反映时变特性,因此,引入LSTM 层来提取长期的上下文依赖。这里,我们使用Multi-level LBP-T-F作为网络的训练特征,然而过多的参数将影响模型的训练效率。通过VGG Style 的初步实验表明,512 个神经元将足够用于该鸟鸣分类任务。因此,本文将CNNLSTM的全连接层简化为512个神经元,此时,模型参数从30505019减少到15679579,如表2所示。

表2 CNN-LSTM的网络结构Tab.2 The Network Structure of CNN-LSTM
可以看出,CNN-LSTM 主要由三个卷积块、一个LSTM 层与全连接层组成。其中,每个卷积块包含一个卷积层和一个池化层。对于LSTM 层,将其输出转换为一维后使用全连接层分类。其中,优化器为Adam,学习率为10-4,损失函数为交叉熵,批大小为32,训练批次为200。模型训练完成后,将每一段鸟鸣Dense(512)层的输出作为深度特征。
2.3.3 DenseNet121模型
在三维模型中,我们选用DenseNet121[25]提取鸟鸣的空间动态信息。在DenseNet121 模型中,对于每一层,前面所有层的特征图都被用作输入,每一层的特征图都被用作后续层的输入。它有效缓解了梯度消失问题,加强了特征传播,并大大减少了参数数量与训练模型所需的时间。同CNNLSTM,本文将CNN-LSTM 的全连接层简化为512 个神经元,如表3 所示。此时,模型参数从51113547减少到29604459。
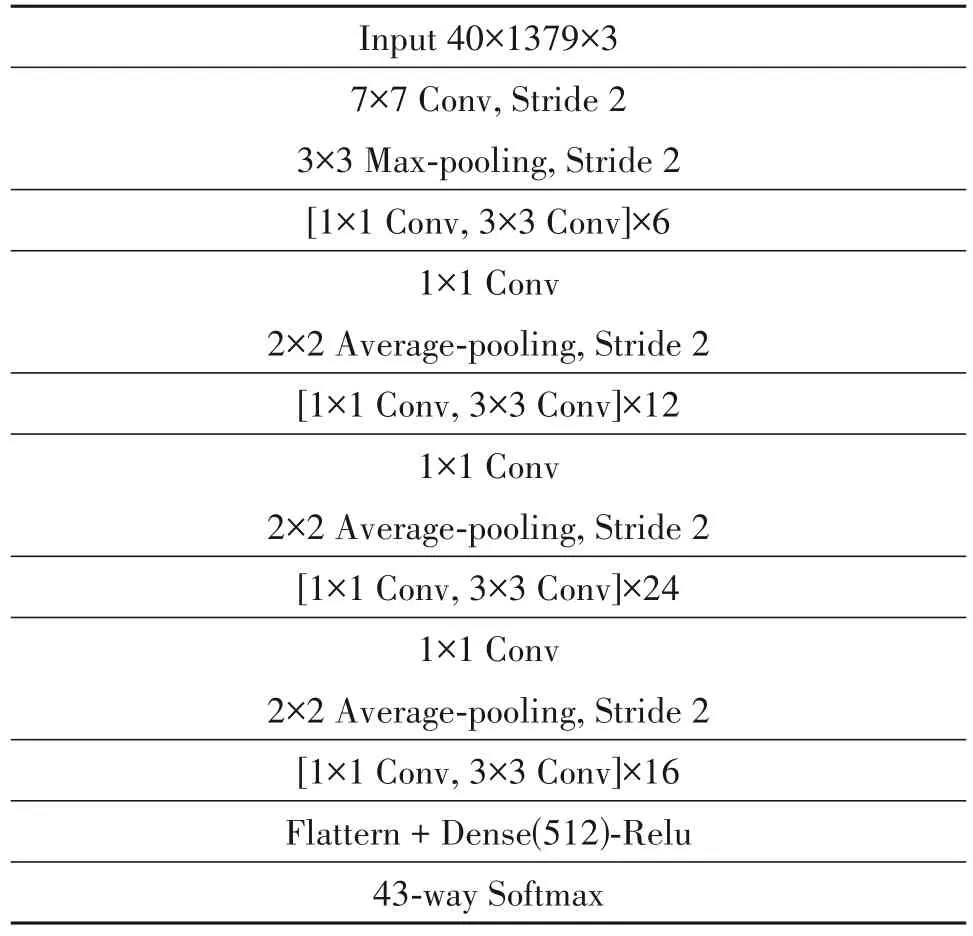
表3 DenseNet121的网络结构Tab.3 The Network Structure of DenseNet121
其中,优化器为Adam,学习率为10-4,损失函数为交叉熵,批大小为8,训练批次为200。同VGGStyle 相同,使用Mix up 生成虚拟数据加入模型训练以减少过拟合。训练完成后,计算每一段鸟鸣Dense(512)层的输出作为深度特征。最后,将1D CNN-LSTM、2D VGG Style 与3D DenseNet121 生成的深度特征连接,得到了1536个特征。
2.4 最小最大归一化
深度特征生成后,使用最小最大归一化[26]将每个特征缩放到[0,1]区间,如式(5)所示。
其中,feat 表示输入特征,featmin表示特征的最小值,featmax表示特征的最大值,featN表示归一化的特征。
3 实验结果与分析
3.1 数据集
本文使用CLO-43SD[2]的数据集,包含43 种北美林莺(鹦鹉科)的飞行叫声,共5428 个音频片段。这些音频片段来自于不同的录音条件,包括使用高定向猎枪麦克风获得的干净录音,使用全向麦克风获得的嘈杂现场录音以及从圈养鸟类获得的声音。每一个音频片段包含一种鸟类的一次发声,采样率为22.05 kHz,量化位数为8,通道数为1,以wav 格式保存。此外,CLO-43SD 数据集是不平衡的,不同鸟类的样本数有显著差异,其样本分布如图6 所示。其中,X轴为鸟类名称的缩写,Y轴为样本的数量。
3.2 实验设置
首先将数据集随机划分出15%测试集,剩余85%的数据被随机划分为60%的训练集和40%的验证集。其中,划分后的数据集中每种鸟类样本所占比重与原数据集相同。这个过程被重复五次,并将实验结果的均值展示。由于CLO-43SD 数据集是不平衡的,为了评估模型对每种鸟类的分类性能,我们使用平衡准确率作为性能指标,如式(6)所示:
其中,n为类别数,TP 为真正数,Si为类别i的样本数量。
3.3 基线
为了对本文方法进行基准测试,本文将每一段鸟鸣预处理,提取13 维梅尔倒谱系数及其一阶、二阶差分作为训练特征(39-MFCCs),使用KNN 与SVM作为分类器,如图7所示。
其中,滤波器的个数为40,帧长为11.6 ms,帧移为1.45 ms,实验结果如表4所示。

表4 基线的分类结果Tab.4 Classification results at baseline
3.4 深度学习模型
首先,针对已有的Mel-VGG 模型,本文替换其训练特征为对数尺度的梅尔谱图,并去掉z-score 归一化步骤,实验对比如图8所示。可以看出,改进后的Mel-VGG 平衡准确率提升了4.34%。之后,本文实验了Mix up 数据增强联合改进Mel-VGG 的分类性能,获得了89.66%的准确率,这表明了数据增强的有效性。因此,在后续的实验中,默认对VGG Style 与DenseNet121 进行数据增强。最后,本文分别测试了1D CNN-LSTM 与3D DenseNet121 的分类结果,可以看出,1D CNN-LSTM 表现最差,获得了84.84%的平衡准确率。
3.5 基于深度特征的模型
为了生成鸟鸣的高级特征,本文分别使用1D CNN-LSTM、2D VGG Style 与3D DenseNet121 提取深度特征,分别计算出全连接层512 个神经元的输出,将其最小最大归一化后送入KNN 与SVM 分类,实验结果如图9 所示。可以看出,KNN 分类器的表现要优于SVM,其中,2D VGG Style 联合KNN 表现最好,获得了91.20%的分类准确率。
3.6 基于深度特征融合的模型
针对不同维度模型可以分别提取信号时间与空间动态信息的特性,本文将1D CNN-LSTM、2D VGG Style 与3D DenseNet121 生成的深度特征连接(深度特征-1-2-3),将其最小最大归一化后送入KNN与SVM分类,实验结果如表5所示。
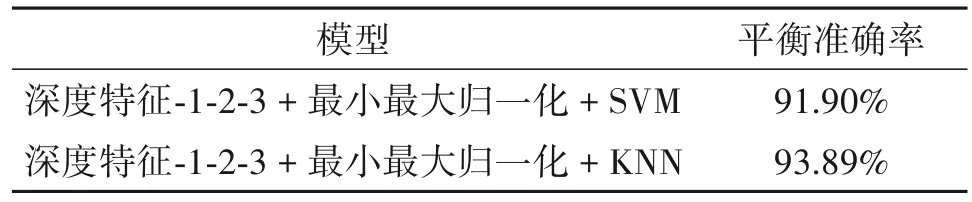
表5 深度特征融合的平衡准确率Tab.5 Balanced accuracy of deep feature fusion
可以看出,深度特征-1-2-3 联合KNN 最高获得93.89%的平衡准确率,这表明融合不同维度模型的深度特征对于鸟鸣识别的有效性。为了进一步分析深度特征融合模型的分类结果,本文绘制出深度特征-1-2-3联合KNN的混淆矩阵,如图10所示。
可以看出,该模型对13 种鸟类获得了100%的分类准确率。然而,13%的BLPW 与17%的BWWA被误分为MAWA,其梅尔谱图如图11所示。
可以看出,它们的谱图结构非常相似,这解释了模型难以区分这些鸟类的原因。在先前的工作中,文 献[1]将Mel-VGG 与Subnet-CNN 后期融合(Fusion1),获得了86.31%的平衡准确率。其中Mel-VGG 指的是梅尔谱图+Z-SCORE 归一化+VGG Style,Mel-Subnet 指的是梅尔谱图+Z-SCORE 归一化+SubSpectralNet[1]。整体实验结果如图12所示。
该项工作中,本文首先对Mel-VGG 的预处理进行改进,使用对数尺度的梅尔谱图作为训练特征,获得了87.61%的平衡准确率。之后,联合Mix up数据混合生成虚拟数据,减少过拟合,获得了89.66%的平衡准确率(Mixmel-VGG)。为了生成鸟鸣的高级特征,本文将Mixmel-VGG 作为特征提取器,计算每一段鸟鸣全连接层的输出作为深度特征,初步实验表明,KNN最高获得了91.20%的平衡准确率(Deep 1)。最后,为了融合利用不同维度模型的学习特性,提高鸟鸣识别的准确率,将1D CNNLSTM、2D VGG Style 与3D DenseNet121 提取的深度特征连接(深度特征-1-2-3),联合KNN 最高获得了93.89%的平衡准确率(Fusion 2),相对于先前的工作,平衡准确率提高了7.58%。
4 结论
本文提出一种基于多维神经网络的深度特征融合方法用于鸟鸣分类。针对不同维度模型描述鸟鸣的互补性,分别使用1D CNN-LSTM、2D VGG Style与3D DenseNet121作为特征提取器生成深度特征描述鸟鸣。对于CNN-LSTM,针对鸟鸣频率高、短促等特点,将鸟鸣划分为长度很小的时间片段,通过整合短时间片段内的纹理特征来描述鸟鸣的快速变化。为了提取鸟鸣的深层特征,获取更丰富的时频信息,以小波分解为池化方法,分别对鸟鸣时、频域提取多层LBP 特征作为网络输入。针对不同种类鸟鸣时频谱图的差异性(见图3),提取鸟鸣对数尺度的梅尔谱图作为VGG Style 的网络输入,并复制三份形成三通道作为3D DenseNet121 的训练特征。为了减少模型参数,提高训练效率,分别将CNN-LSTM与DenseNet121 的全连接层简化为512 个神经元。同时使用Mix up 数据增强减少过拟合。最后,为了融合不同维度模型的学习特性,将三个模型的深度特征连接,联合浅层分类器:KNN与SVM,在含有43种鸟类,5428 个样本的CLO-43SD 数据集中最高获得了93.89%的平衡准确率。然而,对于频谱相似的鸟类,如BLPW、MAWA 与BWWA,模型难以进行有效区分。同时,较高的算法复杂度使得模型需要指定的设备方可运行。在将来的工作中,我们将致力于解决频谱相似鸟类的识别,以及模型的轻量化。
