基于镜面对称引导的单幅图像三维重建
2022-05-12路志青付燕平
路志青,付燕平
(安徽大学计算机科学与技术学院,合肥 230601)
0 引言
人类能够有效利用自身的视觉系统从单幅图像中推断出对应场景或物体的空间结构或几何形状。即使图像中物体或者对象存在严重的遮挡或自遮挡的情况,人类视觉系统也能够估计出物体的大致形状。这种从有限的2D 信息中直接感知3D 结构的能力来源于对我们熟悉的形状和几何的强烈先验。近年来,一些研究者对这种从单幅图像推断三维结构的能力进行了大量的研究,并应用到三维重建、物体识别、机器人抓取、物体位姿估计等领域。然而从含有明显遮挡的图像中推断出对应的物体或场景的三维信息仍然是一个巨大的挑战,尤其是存在物体自遮挡的情况。
为了处理重建中的图像中对象的遮挡问题,Xie 等提出将先验的三维形状知识整合到网络中作为额外的约束,来对输入单视图三维重建进行完整的估计,并获取三维结构。Li等通过对遮挡物体进行概率估计生成多个似是而非的三维结构,从而解决遮挡物体可能存在的三维结构。然而,上述的工作往往忽略了大多数自然界以及人造物体自身的几何特性,即自身镜面对称性(图1),无法有效地解决物体遮挡导致的遮挡部分重建结果准确率下降以及二义性问题。在本工作中,我们提出了利用物体的自身几何镜面对称特性来对三维重建网络进行约束,从而提高单幅图像三维重建的质量。我们提出一个基于镜面对称的端到端的网络结构,首先通过包含概率采样的图编码器将特征映射到一个基于深度学习的隐空间,然后计算出三维空间中对应点坐标的镜面对重建进行约束,最终输出一个三维点云模型。通过ShapeNet和Pix3D数据集上大量的实验和测试中验证了我们想法的正确性,通过定性和定量分析证明了我们提出的基于对称引导的三维重建网络能够重建处高质量的三维点云,并估计处遮挡部分准确的三维结构。

图1 人造物体自身对称性结构
1 相关工作
1.1 多视图三维重建
目前,海量图像数据驱动下的深度学习给三维重建带来了新的机遇。基于深度学习的图像处理能够给三维重建带来更多更有价值的信息,并提高重建的准确性。而三维重建方法大多数是需要多个视角的图像作为输入,这种被称为多视图三维重建工作能够利用重建对象的多个视角采样推断出准确的物体三维空间信息。Choy 等提出了3D-R2N2多个视角的三维重建网络,该网络通过深度卷积主动学习从图像到3D 形状的映射,并以3D 占用网格的形式输出三维表示。当输入多张图像到该网络时,三维重建表示会逐渐细化。然而,该网络在输入图像少的时候,重建的精度就会降低。类似于3D-R2N2等主流的网络采用循环神经网络(RNNs)来融合从输入图像中连续提取的多个特征映射。然而,当输入图像存在不同阶次时,基于RNN 的方法就无法产生一致的重建结果。基于此,Xie 等提出Pix2Vox 网络,该网络首先通过输入多视角图像生成一个粗略的3D 模型,然后利用上下文感知融合模块自适应地从不同三维体中选择部分高质量重建部件(比如桌腿),通过融合得到融合后的三维模型。最后通过求精模块进一步细化整合在一起三维模型,并得到最终的三维重建结果。类似于Xie 等的三维重建算法一般称作增量式的三维重建。然而,增量式多视图三维重建的几何结构的获取非常依赖于重建的初始视图,或者说最初生成的粗略的3D 模型好坏往往取决于输入的视图的好坏,并在不断的调整中受到输入视图的约束。然而,该类算法会存在明显的相机位姿累积误差,并最终影响三维重建的结果。因此Liang等采用非增量式进行多视图三维重建,非增量式三维重建对初始视图重建的精度要求不高,他们首先求出所有摄像机的参数,通过全局方式一次性计算目标三维点,并在重建的精度和效率上优于增量式三维重建。然而,该方法在输入数据较大的时候,参数的增多往往会使得重建效率下降。
1.2 单视图三维重建
由于在多视图重建中,数据获取不方便以及数据计算量大的原因,致使很多研究者们把目光投向了单视图三维重建,并提出了很多基于单视图的端到端的三维重建框架。然而,单张视图在三维重建中仍然存在很多的问题,其中最重要的就是重建对象存在自遮挡现象,由于单张图像没有更多的视角给重建提供足够的信息,这直接导致最终重建的结果不准确和二义性。针对这个现象,Mandikal 等提出了两个思考问题:①给定一个物体的二维图像,推断其精确的三维点云表示的有效方法是什么?②当输入图像存在高度遮挡时,我们如何设计网络来生成一组与输入图像一致的可信的3D 形状?基 于此,他们提 出了3D-LMNet 网络。3D-LMNet首先利用倒角距离损失训练点云自编码器,然后使用多样化损失和潜在空间匹配损失将自编码向量映射到高斯概率分布来解决图像遮挡导致重建的不确定问题。Li等提出了针对自遮挡问题的端到端的单视图三维点云重建网络3D-ReConstnet。针对物体自遮挡部分的不确定性,该网络同样利用特征向量学习到的高斯概率分布来预测点云。为了提高单视图3D重建的准确性,Xu 等提出了DISN 网络,该网络采用一种隐式三维表面表示法SDF(signed distance function)在全局和局部特征信息上对给定一张图像预测符号距离域,以此来重建三维模型。然而,数据驱动的网络在估计点云重建方面往往不够准确,因为它们缺乏几何约束,无法利用物体自身的几何特性来对重建结构进行引导从而消除物体遮挡和自遮挡的影响。
1.3 镜面对称性约束
对称性尤其是自身对称性已经应用到了计算机视觉领域的很多方面,比如无监督形状恢复和图像处理。在三维重建中,利用单张RGB 图像中对象的自身对称性来重建物体的三维形状通过传统的方法是可以实现的。正如Zhou 等所叙述的一样,从图像中检测对称性以及重建相应的点云是一项挑战的任务。首先,由于大多数基于几何的对称性检测方法仅适用于二维平面以及摆放适宜的物体,而对于三维对称平面是处理是不足的;再者,虽然通过神经网络能够检测出三维物体的镜面,但是由于缺乏几何先验的约束,准确性不高。为了提升三维的准确性以及满足上述的不足之处,我们的网络在训练中添加了综合上述二者优势的三维几何对称来约束三维重建,以期达到更好的结果。我们的对称性通过高斯概率获取对称性信息,并通过神经网络的训练下获取的参数来约束对称信息,使得提升重建的准确性。
2 研究方法
本文所提出的基于镜面引导端到端的三维重建网络框架如图2 所示,输入单张RGB 图像,经过网络特征提取网络、概率采样、镜面对称约束等处理能够生成较为准确的三维点云模型。我们的网络框架是在3D-LMNet的模式下进行设计并改进的,在特征提取部分我们引入DenseNet网络,并采用DenseNet121 网络对图像进行编码,以便获取更加充足的图像特征。在点云生成部分我们引入了镜面对称对模型的三维结构进行自相似约束。最后利用输出网络来获取最终的三维模型。
2.1 网络架构
我们提出基于单幅图像镜面约束的三维重建网络的目的就是输入单张RGB 图,通过网络处理输出对应物体的三维点云结构。首先,我们对输入图像进行特征提取,并将图像的二维空间信息映射到三维空间。近些年基于学习的图像特征提取方法多种多样,其中最为常见的就是ResNet和DenseNet。ResNet利用 残差块对图像进行处理,并在增加网络深度的情况下引入跳跃连接的方式来避免层数的增加带来的不足,这很可能会丢失部分的参数;而DenseNet 在保证增加网络层的基础上对每一层的参数都进行跳跃连接,能够大大减少了参数的丢失。由于我们采用的是单幅图像的三维重建,信息量的减少会影响重建的质量,因此我们队3D-LMNet 进行改进, 我们采用了DenseNet121 网络为特征提取层来充分利用图像信息,从而减少有用信息的大量丢失。通过DenseNet121对特征提取,获取图像特征张量。接着我们把引入到一个高斯概率潜在空间,在网络中进行大量输入数据的训练并更新潜在空间网络的权值,然后利用最终的模型对输入特征进行解码获取输入图像中物体对应的三维空间信息:

其中,均值=(), 标准差=(),是和有相同的尺寸的随机参数,对标准差进行约束。然后,我们通过解码器对三维信息进行解码,输出维度为1024×3的三维张量。
在多次实验中我们发现利用输出的三维张量直接重建点云准确率不高,为了解决这个问题我们引入了三维镜面对称来对网络进行约束,如图2 中部分就是我们的镜面对称结构约束。此时,我们首先要考虑的就是三维平面的位置问题,即如何确定我们需要的三维空间平面。在实验中,我们将二维图像信息映射到三维空间中采用的是高斯概率采样,在设计上我们利用了标准正态分布对二维图像信息进行的处理,标准正态分布密度函数如下:
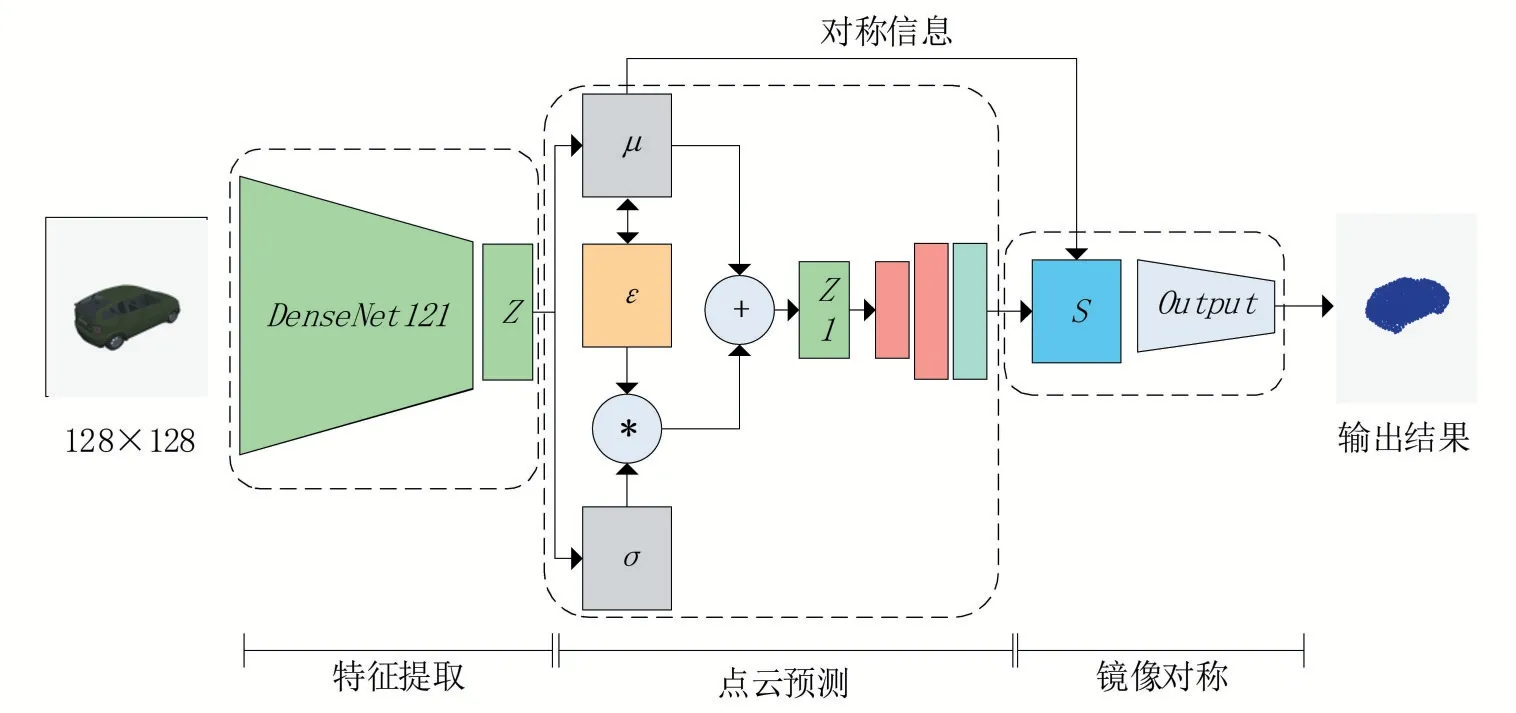
图2 网络总体结构
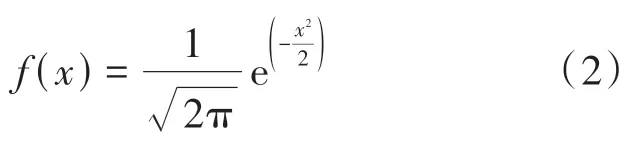
此时的均值= 0,也就是所有三维空间的信息全部聚集到了均值两侧,并对称分布。根据这个理论,我们能够推测出生成的三维数据是处于某一个维度的分布中的。之后,我们将解码后的维度为1024 × 3 的三维张量进行平面估计,最终确定其镜面结构。
2.2 损失函数
点云的结构无序性要求我们需要选择一种与输入点序列不相关的损失来训练点云生成网络。目前广泛应用的方法就是采用倒角距离(chamfer distance, CD)和 地 移 距 离(earth mover’s distance,EMD)去训练点云生成网络。倒角距离CD 测量的是生成点与GT(ground truth)中对应位置的点的距离的平方。EMD 处理的是GT 与生成点云之间点与点之间的映射。为了有效地利用物体自相似的特性,我们利用估计的镜面对称平面,在损失函数中加入镜面对称约束,整个损失函数定义为:
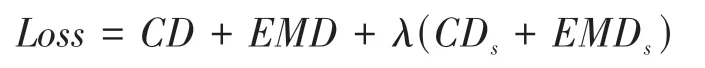
其中CD和EMD是对称性点云生成的损失函数,是约束对称性生成强度的超参数,这里我们定义为= 0.1,我们的CD 函数和EMD 分别定义为:
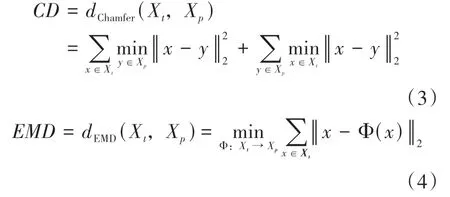
其中我们令X∈R表示GT,X∈R表示生成的点云集合。表示生成的点云中点的数量。∈X表示GT 中的点,∈X表示生成点云中的点。
3 实验与结果分析
3.1 实验
数据集。为了让我们的实验在结果上更加具有公信度,我们采用公共数据集ShapeNet和Pix3D来训练和测试我们的三维重建网络模型,其中ShapeNet 数据集包含来自13个不同类别的共43809 CAD 模型,以及其对应不同角度的渲染图像,Pix3D 数据集包含7595 中真实拍摄的图像以及其对应的物体遮罩掩码和CAD 模型等。我们采用和相关工作相同的4∶1训练集和测试集的比例进行实验。
实验详情。为了使得和以往工作进行更公平的对比,我们采用与相关工作相同的学习率5×10和优化器Adam 分别对实验进行约束和优化。由于数据量较大,我们采用小批量(尺寸为32)将需要训练的数据输入到训练网络中,并在50 轮的迭代,输出最终的网络模型。为了满足网络对输入数据尺寸的要求。首先,我们将输入的图像进行预处理,使其长宽尺寸都为128像素,然后在特征提取网络DenseNet-121的处理下,将图像的特征映射到不同的隐空间,之后为了减少额外的参数我们引入平均池化层对输出进行下采样,最后,将包含三维空间信息的输出通过镜像平面约束并输出包含自身镜像的三维点云结构。
评价方法。点云重建最常用的评价方法有两种:倒角距离和地移距离,我们利用这两种方法来评估我们的生成1024 随机镜像采样点的点云重建网络模型。我们在ShapeNet数据集上对每一类别随机选取图像进行测试,并展示其生成模型(图3)和评价结果(表1)。
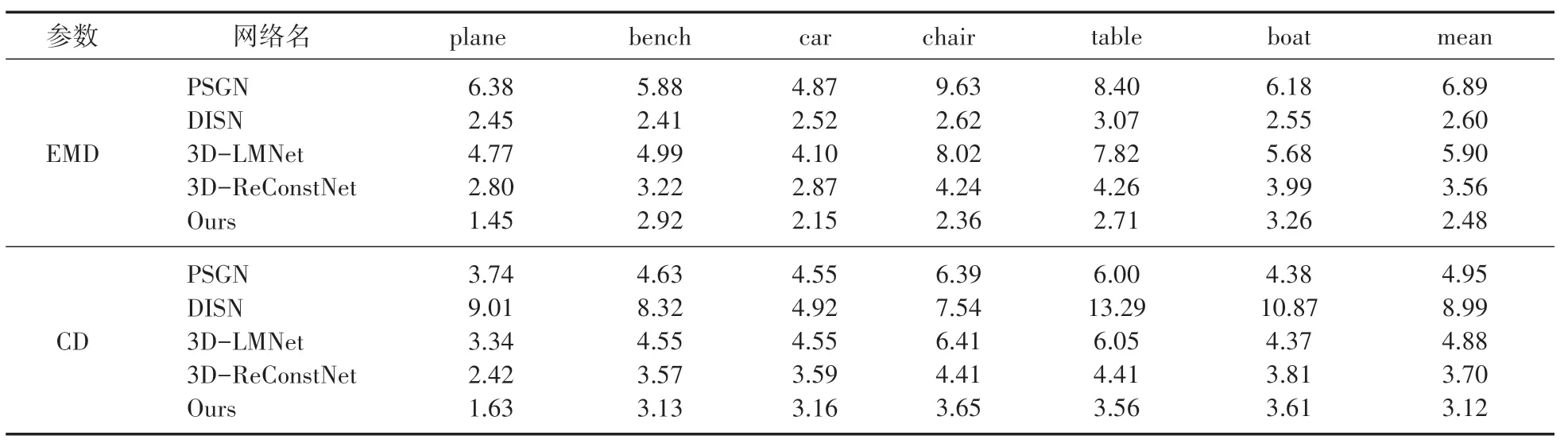
表1 部分物体的重建结果在CD(10-2)和EMD(10-2)指标上的比较
3.2 实验结果与分析
图3 展示了在ShapeNet数据集上的部分类别物体三维重建结果,最左侧为输入图像(包括飞机、汽车、桌子等),中间是我们的网络生成的点云重建结果,右侧为GT(ground truth)。为了使得输出尺寸能够适应我们的网络输出,我们设计的重建模型点的数量=1024。从结果中我们能够看出我们的重建在视觉效果上与GT 的重建结果接近,而且在结构上与输入图像是近似的。
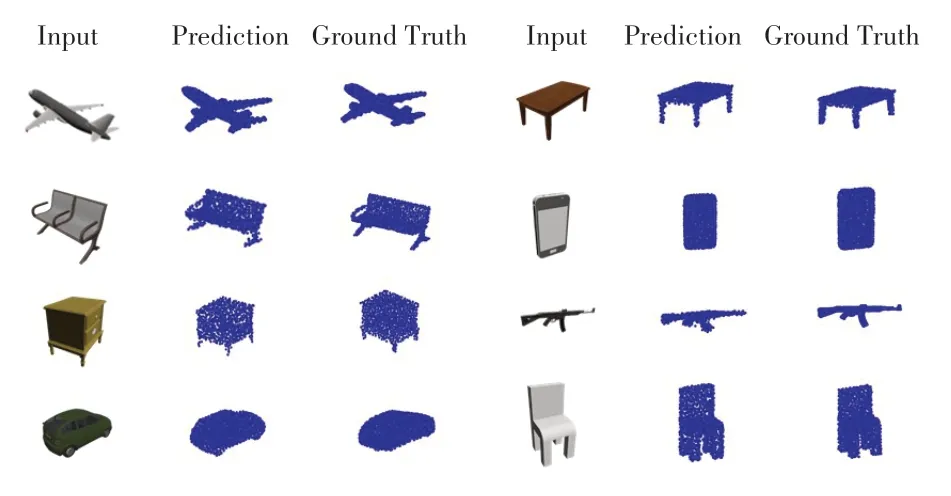
图3 在ShapeNet数据集上的不同类别的重建点云结果
用于重建的点云模型比较稀疏,在可视化效果上并不能直观的看出重建模型的优缺点,因此我们对每一个类别的对象进行定量的评估,我们采用CD和EMD 度量来对现有的三维重建算法进行定量评价(其中CD和EMD 都是以10为单位),如表1所示。我们选取了6类不同的对象来进行测试,并对与近些年最好的三维重建网络结果进行比较(包括如PSGN,DISN,3DLMNet, 3D-ReConstNet),其中数值越小代表重建结果越好,表中的加粗体部分代表在某一类别中某个网络架构重建结果最优。从表1中可以看出我们的方法采用镜面对称约束只有,能够恢复出更加精细的三维点云结构。
为了验证我们引入对称性平面是否对我们的训练发挥作用,我们对我们的网络结构畸形了消融实验,分别比较了使用和不使用镜面对称约束三维重建的结果。表2展示了我们的网络的使用和不适用镜面对称重建结果的定量分析对比结果,其中U_ours 代表未加镜面对称约束的结果,Ours 是添加镜面对称约束的重建结果。通过表2的结果展示,我们能够直观的看到对称性对三维重建可以有效地提高三维重建的质量。图4展示了我们镜面对称平面的可视化结果。

表2 未加对称性约束和添加对称性约束的结果在CD(10-2)和EMD(10-2)指标上的比较

图4 引入对称平面的结果
图5是在Pix3D数据集上随机选取的3类6个对象进行三维重建的结果,图中左侧为输入图像,中间是通过本文提出的网络重建的结果,右侧为GT。数据集Pix3D上的图像来源于真实拍摄的物体,为了满足我们的模型对输入的要求,在重建中我们为其添加了mask处理,因此在重建的结果的视觉上没有在ShapeNet数据集上的好,这也说明了单视图三维重建在真实场景中重建三维模型还是存在不足之处的。通过图5中的重建结果与GT 进行对比我们还能发现,我们的重建结果在精细的几何细节上处理的并不好,这也是目前基于单幅图像三维重建面临的一个重要的挑战也是我们后期工作的一个研究方向。

图5 在Pix3D数据集上的重建结果
虽然添加对称性能够给基于学习的三维重建网络带来质量和结果的提升,但是单视图重建中所存在的病态问题依然没有完全解决。图6展示了本文重建结果的不足之处,这同样也是单视图重建中的所面临的共同问题。那就是对于细节部分无法很好地重建,如图中圆圈所圈的部分比如长椅的把手和分叉的椅腿部分,都不能更加清晰的重构出来,图中音响的音桶部分是无法重构出来的,这些都是我们需要仔细思考的问题。

图6 重建结果中的问题
4 结语
在本文中,我们提出了一个端到端的基于镜面对称引导的单视图三维重建网络。我们的网络首先将2D 图像特征映射到一个潜在空间并进行采样获取图像的三维空间结构,然后利用镜面约束来处理三维重建中物体的自遮挡问题。我们在ShapeNet和Pix3D两个公共数据集对训练并测试我们的网络,并输入非对称对象的图像进行验证我们算法的有效性。实验的结果展示我们的网络在定性和定量上都有一定程度的提升。然而,我们的工作仍然存在一些不足之处,比如严重遮挡的以及其他遮挡的问题我们没有进行处理,我们将在未来的工作尝试解决。
