基于LDA和加权Word2vec的科学知识图谱构建研究
2022-05-12杨云帆李坤琪杨秀璋罗子江
赵 凯,杨云帆,袁 杰,李坤琪,杨秀璋,罗子江
(贵州财经大学信息学院,贵阳 550025)
0 引言
随着科学研究环境逐步改善,大量研究成果问世,科学文献数量呈指数式增长,但是科研工作者阅读、分析、利用文献的速度远远低于文献发表的速度,科学知识图谱就是在此情况下出现的一种提升文献利用效率的科学方法,在趋势研究、热点发现、学科发展研究方面具有重要意义。有关科学知识图谱最早可追溯到20 世纪60年代,美国科学研究所名誉所长Eugene 等人在引文数据的基础上手绘完成DNA 领域发展图谱,此后,作为科学知识图谱发展史上具有里程碑意义的文献共被引分析和作者共被引分析方法也被逐步提出,为科学知识图谱的早期发展奠定了坚实基础。21 世纪以来,众多学者致力于科学知识图谱可视化的研究,2004年美国雷德赛尔大学的陈超美教授开发了CiteSpace,后由大连理工大学WISE 实验室引入国内,主要功能是对特定领域文献进行计量以探寻学科领域演化的关键路径及知识转折点;2008年瑞典于默奥大学的Perrson 教授开发了BibExcel,主要用于文献计量分析;2009年荷兰莱顿大学科技研究中心的Van和Waltman开发了VOSviewer,主要面向文献数据,侧重科学知识的可视化。近年来国内关于科学知识图谱的文献数量也逐年增多,据中国知网相关数据显示,2019年与科学知识图谱相关的中文文献量为714篇,相比2018年的553篇增长了29%。
1 相关研究概述
科学知识图谱作为一种直观展示科学知识间关联度的方法,受到众多学者青睐。国外相关研究中,Price作为科学知识图谱的早期开拓者,为科学知识图谱的发现与发展做出了重要贡献;德国著名科学计量学家Kretschmer有关三维空间模型的研究为科学知识图谱的进一步发展奠定了坚实的基础。我国学者对于科学知识图谱的研究相比于国外学者较晚,陈悦和刘则渊于2005年将科学知识图谱的概念引入国内,为我国科学知识图谱相关研究奠定基础;侯海燕以可视化方法对《科学计量学》1978年至2004年发表的1927 篇论文做作者共引分析,发现世界上最有影响力的50 位科学计量学家;刘荣在科学知识图谱的基础上,通过多维度分析、主成分分析等方法,研究分析了创新历史与其现状,并在此基础上针对我国的实际情况,提出保持较高增速与增强国力的几点建议;欧阳芬和张蕾选取1949—2019年CNKI数据库中收录的2248 篇有关语文教材的相关论文,运用CiteSpace 软件绘制语文教材的研究机构、研究作者、研究热点等知识图谱,深层挖掘新中国成立70周年以来语文教材的发展趋势;王露杨和杨国立收集CSSCI 中11284 篇与外国语言学研究有关的论文,运用知识图谱方法分析了外国语言学研究的研究热点和发展趋势;王山等运用关键词共现网络图谱分析、关键词引用突变分析、共词聚类分析等方法对中国知网数据库下载的2013—2017年政治经济学研究领域的相关文献进行了科学计量分析,发现了近年政治经济学的研究现状、研究热点,预测了政治经济学未来的发展趋势;陶于祥等采用时间演化分析、词频分析等方法,利用CiteSpace可视化软件作出学科共现图谱,综合梳理了国内外人工智能领域的发展脉络、演变过程和研究热点;许晓阳等通过结合专利与论文两类文献,以关键词共现为基础,识别学科研究热点。
综上所述,科学知识图谱中,关键词共现图谱与主题演化图谱是学者们常用的可视化分析方法,其中的常规算法通常采用向量空间模型(vector space model,VSM)表示文本。基于向量相似距离来计算文本相似度,主要缺陷是没有考虑词语之间的语法关系,忽略了词语之间的相似性,无法解决文本数据中存在同义词和多义词的情况。针对此问题,本文采用基于潜在狄利克雷分布(latent dirichlet allocation,LDA)和加权Word2vec 的科学知识图谱构建方法。该方法首先利用LDA 模型抽取主题及每个主题下的关键词,再用Word2vec 获取每个主题下关键词的词向量,通过加权计算词向量得到主题向量,进而计算主题相似度与重要度,最后以可视化方法构建主题共现图谱和主题演化图谱,从而达到从语义层面揭示领域发展变化的目标。
2 相关技术介绍
2.1 LDA模型
LDA是一种无监督学习的主题概率生成模型,也被称作三层贝叶斯概率模型,是在PLSA(probabilistic latent semantic analysis)模型的基础上增加贝叶斯架构模块所形成的,具体模型如图1所示。
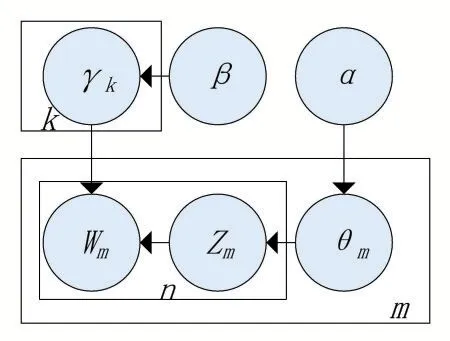
图1 LDA文档主题生成模型
2.2 Word2vec
Word2vec是2013年Google 公司开发的一款用于词向量计算的开源工具,它根据上下文信息将输入的特征词训练为词向量,用空间向量的相似度来表示语义相似度。其提供两种语言模型,分别是CBOW(continuous bag-ofwords)模型和Skip-gram 模型。CBOW 模型旨在通过上下文来预测当前词的概率,其结构如图2 所示;Skip-gram 模型则利用当前词的词向量来预测上下文,其结构如图3所示。两种模型输入输出的内容完全相反,但在模型的训练过程上是相同的。
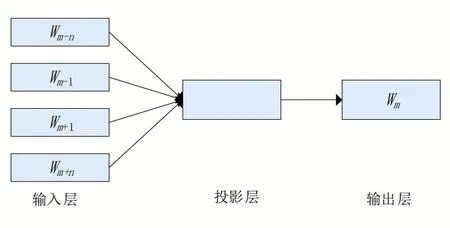
图2 CBOW模型
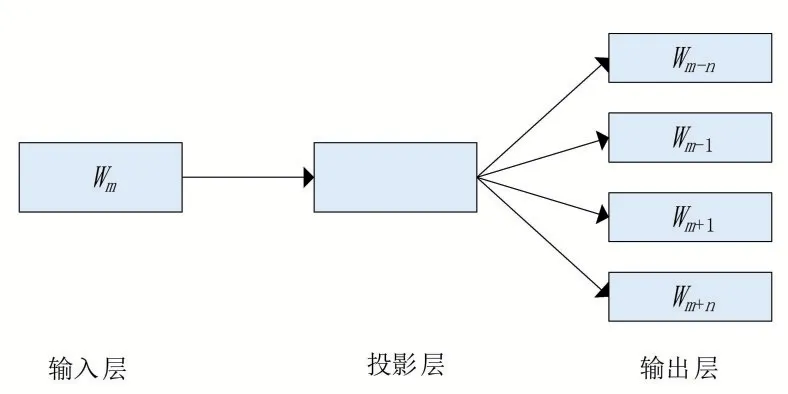
图3 Skip-gram 模型
3 基于LDA和加权Word2vec的科学知识图谱构建研究
本文旨在从语义层面揭示领域发展变化情况,采用基于LDA和加权Word2vec 的科学知识图谱构建方法,以中国知网某领域期刊题目、摘要及关键词作为分析对象,经过数据预处理后,利用LDA 模型抽取主题与关键词,再采用Word2vec 获取关键词的词向量,通过加权计算词向量得到主题向量,进而计算主题相似度与重要度,最后以可视化方法构建知识图谱。具体流程如图4所示。
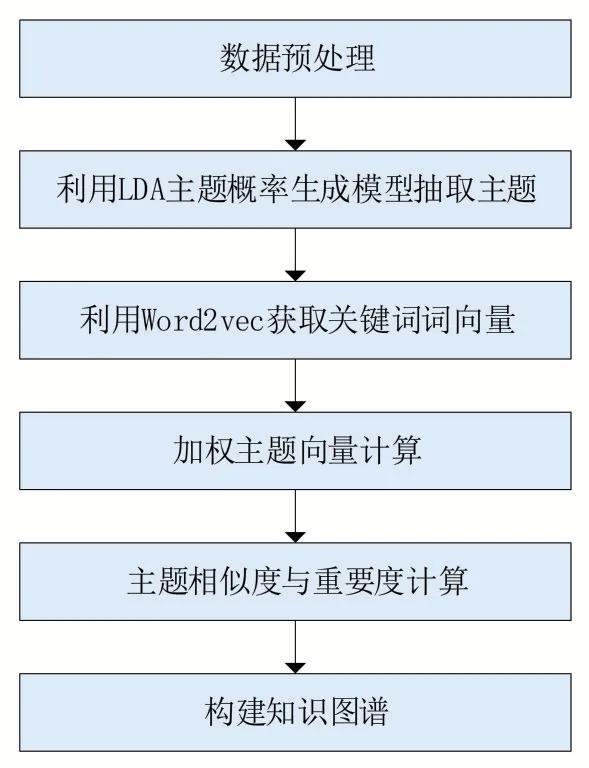
图4 基于LDA和加权Word2vec的科学知识图谱构建研究方法
3.1 数据来源与数据预处理
期刊论文的题目、摘要和关键词能够较好地反映研究领域的热点主题和发展过程,因此本文以中国知网某领域期刊题目、摘要及关键词为分析对象。数据预处理主要包括中文分词、去除停用词和关键词过滤。文中运用的分词工具为Python 语言环境下结巴(Jieba)分词工具;去停用词阶段使用的是哈工大公开的停用词表;关键词过滤采用TF-IDF 算法,通过计算每个词语的TF-IDF 值过滤小于指定阈值的词语,形成关键词集合。
3.2 利用LDA主题概率生成模型抽取主题
本文基于Python 第三方模块sklearn 中的LDA 模型实现主题分布研究,并调用可视化包pyLDAvis 来确定主题数量。对比传统的困惑度方法,视距图(Intertopic Distance Map)更加清晰直观地展现各主题之间的关系和对应主题下关键词词频,从而达到合理确定主题数量的目标,避免主题中关键词重叠或过于稀疏。
3.3 利用Word2vec获取关键词词向量
研究以预处理后的文档为基础数据,采用CBOW 模型,利用Python 语言下的Word2vec 第三方包将词训练为词向量,然后从中提取主题下各关键词的词向量,以便后续处理。
3.4 加权主题向量计算
主题为多个不同频次的关键词集合,以往研究通常采用主题内所有关键词词向量的均值来表示该主题向量,但这种方法没有考虑到词频问题。因此本文采用TF-IDF 加权平均法对主题内不同关键词赋予不同权重,计算公式如式(1)所示。
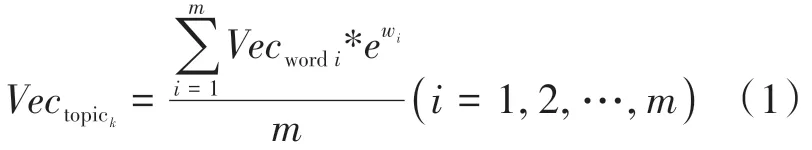
式(1)中:表示主题的主题向量;为关键词的词向量;w为关键词的TFIDF值;为主题中关键词数量。
3.5 主题相似度与重要度计算
主题相似度(resemblance,Res)反映主题之间的关联性和演化趋势,其值为不同主题之间的语义相似度,表示主题间的关联性,是以夹角余弦公式为基础改进的,具体计算公式如式(2)所示。
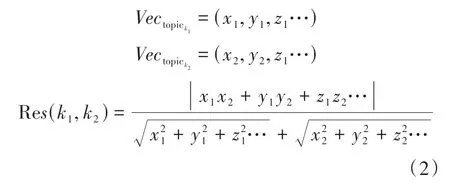
式(2)中:是根据式(1)计算得到的加权主题向量;(,,…)表示主题向量各个维度的数值;Re(,)表示主题与主题间的主题相似度。
主题重要度(imporantance,Imp)反映主题在研究领域内的重要程度,数值的大小与主题重要度成正比,其随时间的变化情况能够反映主题在领域中相对重要性的变化。本文采用主题内各关键词TF-IDF 的均值表示主题重要度,具体计算公式如式(3)所示
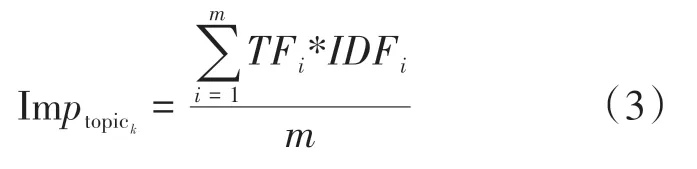
式(3)中:topic表示主题;为主题中关键词个数;TF与IDF分别表示关键词的文本频率与逆文档频率指数。
3.6 科学知识图谱构建
目前基于内容分析的科学知识图谱存在以下不足:①关键词共现图谱不具有主题概念、无法判断关键词归属。②主题演化图谱不包含时间信息,无法判断主题随时间的变化趋势。解决上述问题。本文参照传统的关键词共现图谱和文献主题演化图谱,构建包含关键词归属的主题共现图谱和增加时间横轴的主题演化图谱,结合两种图谱集中展示学科主题、主题重要度和主题相似度等三个方面的信息。
(1)主题。通过圆形表示每个主题,在主题演化图谱中结合了时间横轴展现不同时间段的主题信息。
(2)主题重要度。通过圆形的大小表现主题重要度,圆形半径越大,主题重要度越高。
(3)主题相似度。为展现各主题随着时间推移的演变趋势,将各主题用宽度不等的线连接,连线的宽度与主题间相似度成正比。
4 实证研究结果
为了验证本文提出的基于LDA和加权Word2vec 的科学知识图谱构建方法的可行性,本文采用信息服务领域的期刊论文做实证研究,数据来源于中国知网数据库,主要包含期刊题目、摘要和关键词三个方面,涉及58917篇期刊论文,时间节点跨越2000—2019 共20年。研究将整体数据分为两种形式,第一种是将20年数据依据每4年一个阶段划分为5 部分,在此基础上绘制主题演化图谱,以研究近20年信息服务领域的主题演化趋势;另外一种是将总数据进行整体分析,所得结果作为主题共现图谱绘制依据,借此探讨信息服务领域近20年来的研究热点。
4.1 主题提取结果
本文通过调用pyLDAvis 绘制视距图以确定合理的主题数量,因篇幅限制仅展示总数据主题1 的关键词,如图5 所示,五个圆圈表示五个主题,基本没有重叠,表示提取效果良好,右边为关键词词频。另外总年段数据的主题提取结果如表1所示,各年段数据的主题提取结果如表3所示。

表1 2000—2019年总数据各主题关键词
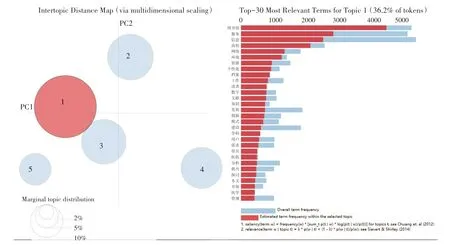
图5 总数据视距图
4.2 主题相似度与主题重要度计算
主题相似度计算:利用式(2)计算总数据不同主题间的相似度,举例来讲就是分别计算出主题1 与主题2、3、4、5,主题2 与主题3、4、5,主题3 与主题4、5,主题4 与主题5 之间的相似度。
主题重要度计算:主题重要度主要依据主题关键词的TF-IDF 值,按式(3)计算,基于以上两种条件,计算出总数据与各年段下每一个主题的主题重要度。总数据主题重要度与相似度如表2所示,由于篇幅原因,分年度数据不做赘述。

表2 总数据主题重要度与相似度
4.3 科学知识图谱构建
主题共现图谱结果如图6所示。
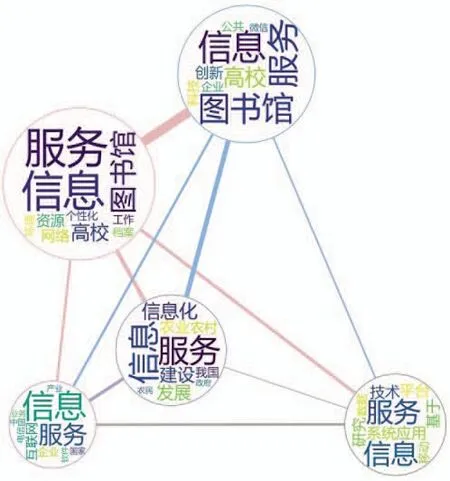
图6 主题共现图谱
从图中可见:
(1)近20年来,信息服务领域主要的研究方向为高校图书馆个性化建设和技术创新、基于信息服务平台的“三农”发展、基于计算机应用系统的技术研究、中国互联网企业研究等。以上研究对象具有一个共同的特点:均是以信息资源管理为基础,通过对数据的分析与处理,为主体的发展提供服务。
(2)从主题重要度来讲,近20年间信息服务在高校图书馆方向的研究是一大热点,与高校图书馆相关的主题重要度分别占据前两位,主要原因是信息服务是高校图书馆最基本的职能之一,高校图书馆也为信息服务的发展提供良好的条件,凭借5G、大数据和云计算等高新技术得到进一步发展,如5G 时代高校图书馆信息服务、大数据环境下高校图书馆研究和云计算环境下高校图书馆服务模式探索等均是一种体现。
(3)从主题关联度来讲,高校图书馆个性化建设和技术创新两个主题之间关联度最大。随着互联网技术的发展,网络资源对图书馆的冲击最大,而技术创新与个性化建设均是为了提升图书馆信息服务水平,两者互为补足,互相促进,是图书馆适应社会发展趋势的重要方法;高校图书馆个性化建设与中国互联网企业研究关联度最小,主要原因是二者研究对象具有明显差异,高校图书馆最主要的职能是为高校师生提供学习、研究的良好环境,属于服务为主的部门,而互联网企业是盈利性机构,是以计算机网络技术的发展为生存的根本,但是近年来高校图书馆与互联网企业的联系越发紧密,互联网企业为图书馆信息技术的建设提供了巨大帮助,相信这会是二者不断协调发展、互相促进的契机。
主题演化图谱结果如图7所示。
结合表3和图7可以看出:
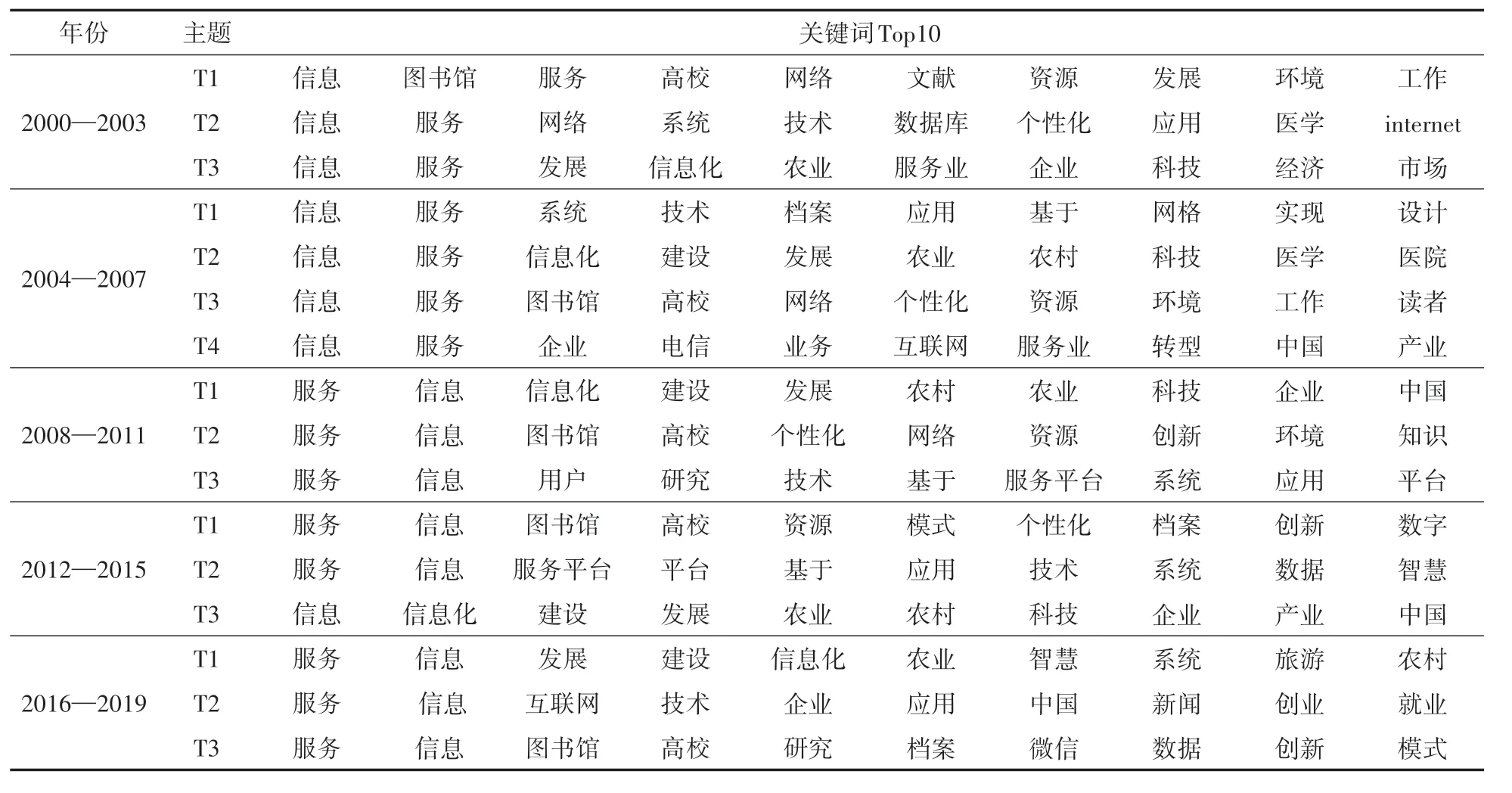
表3 2000—2019年各年段主题关键词
(1)各年段研究侧重点不同。2000—2003和2004—2007 两个年段,该领域主要侧重点是对信息技术的发展,而2008年至今三个年段主要侧重点是服务,基于这种现象,我们认为信息服务是基于信息技术才实现对社会的服务,坚实的信息技术是支撑服务的基础,但并非完全舍弃对信息技术的发展,而是在利用信息技术服务社会的同时也同样重视信息技术的发展。
(2)从主题关联度来看,20年间存在三条关键主题演化路径(图7 中三种颜色不同的路径),分别是高校图书馆、计算机技术应用和农业农村方向的研究。而且各路径在大的研究方向下不断出现新的研究内容,同时也伴随着旧研究内容的消失,以高校图书馆演化路径为例,2000—2003年以文献资源的研究为重点,随着时间的推移,结合社会发展,2004—2007年段出现读者个性化研究、2008—2011年段出现图书馆创新、2012—2015年段出现数字图书馆研究、2016—2019年段则以图书馆服务模式创新为主要研究方向。
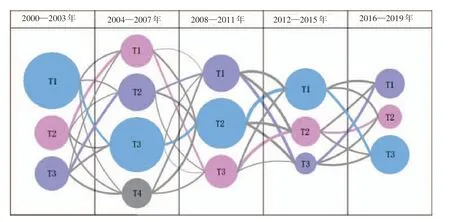
图7 主题演化图谱
(3)从主题重要度来看,高校图书馆演化路径中每个主题的重要度在其所在年段均为最大,并且研究内容均与高校图书馆有关,因此本文认为有关高校图书馆的研究是信息服务领域近20年间最大的研究热点,这种趋势也会继续延续下去。
5 结语
科学知识图谱作为一种直观展示科学知识间关联度的方法,可以大幅提升文献利用效率,在趋势研究、热点发现、学科发展研究方面具有重要意义。针对现有可视化分析算法中没有考虑词语间语法关系、忽略词语间相似性、无法解决同义词和多义词的问题,本文提出一种基于LDA 与加权Word2vec 的科学知识图谱构建方法,实现文本-词向量-知识图谱的一系列转化,达到从语义层面揭示领域发展变化情况的目标。首先,研究以中国知网信息服务领域期刊数据为分析对象,经过数据预处理后,利用LDA 模型抽取主题及每个主题下的关键词,再采用Word2vec获取每个主题下关键词的词向量,通过加权计算词向量得到主题向量,进而计算主题相似度与重要度,最后以可视化方法构建主题共现图谱,分析了现阶段信息服务领域各大研究方向、研究热点与其关联性,同时构建主题演化图谱,揭示了领域内各阶段研究侧重点,挖掘出关键主题演化路径与其发展趋势。
