近十年国内教育数据挖掘领域的应用技术分析
2022-05-11杨志禹吴士雨王增琦丁国勇
杨志禹 吴士雨 王增琦 丁国勇
(南京审计大学 信息工程学院,江苏 南京 211815)
数据挖掘(Data Mining,简称DM)被定义为从大量数据中发现有价值的、新颖的、潜在可利用信息的非平凡过程。[1]在教育方面,使用数据挖掘既有改进学习过程、引导学生学习等应用研究目标,又有非应用研究目标,如纯粹为了加深对教育现象的理解。
将数据挖掘技术应用于教学环境中,也称为教育数据挖掘(Education Data Mining,简称EDM)。教育数据挖掘是一个跨学科的研究领域,它将机器学习、统计、数据挖掘、教育心理学、信息检索、认知心理学和推荐系统的方法和技术应用于各种教育数据集,以解决教育问题。[1]信息化教育的发展为教育数据挖掘的研究提供相当可观的数据,研究人员通过对这些数据进行挖掘和分析得到有用的信息,再反馈到教育过程中。
教育数据挖掘在国外得到较好的应用,体现在电子学习与学习管理系统(Learning Management System,简称LMS)、自适应教育超媒体系统(Adaptive Educational Hypermedia Systems,简称AEHS)以及自我辅导(Intelligent Tutoring System,简称ITS)等方面。[1]相对于国外教育数据挖掘研究与应用,国内相对滞后。李宇帆、张会福等[2]将国内EDM 的发展历程分为三个阶段:第一阶段是2002 年至2012 年,称为萌芽阶段,这个阶段内国内教育信息化和在线教育开始发展起来,但主要局限于对国外文献进行研究;第二个阶段是2013 年至2014 年,称为起兴阶段,2012 年美国国家教育部发布的《通过教育数据挖掘和学习分析促进教与学》为在线教育领域大数据的研究提供思路;第三个阶段是2015 往后,称为快速发展阶段,北京师范大学“移动学习”教育部-中移动联合实验室等机构于2015 年联合发布了《中国基础教育大数据发展蓝皮书》,此后,关于教育数据挖掘的文献开始大量涌现。本研究从技术应用角度对近十年国内教育数据挖掘的相关文献进行分析,以期发现教育数据挖掘的发展规律。
一、教育数据挖掘常用技术
瑞安·贝克(Ryan Baker)等[3]将教育数据挖掘的工作主要分为以下几类:①预测,涉及分类、回归与密度交易;②聚类分析;③关系挖掘,包括关联规则挖掘、序列挖掘和因果挖掘;④模型发现。
本文通过总结与分析,认为国内教育数据挖掘的常用技术主要有分类技术、聚类技术和关联规则技术等。
(一)分类技术
分类是一种重要的数据分析形式,通过分类可提取刻画重要数据类的模型。分类算法是通过扫描数据,并根据每个数据不同的特征将其划分到不同的类。
一般认为,分类算法的实现分两步进行:第一步是学习,在该阶段基于预先定义的数据集或概念集建立合适的分类器;第二步是分类,先用已知的测试样本集评估分类规则的准确率,如果准确率是可以接受的,则使用该模型对未知类标号的待测类样本进行预测。常用的分类算法有分类回归树(Classification And Regression Tree,简称CART)、迭代二叉树3 代(Iterative Dichotomiser 3,简称ID3)、支持向量机(Support Vector Machine,简称SVM)、Bayes 算法、K 最近邻算法(K-Nearest Neighbors,简称KNN)、C4.5算法、C5.0 算法等。
(二)聚类技术
聚类分析简称聚类。也就是将数据对象划分成子集的过程。每一个子集是一个簇,簇中的对象彼此相似,与其他簇中的对象不相似。
聚类算法有许多分类,主要有层次方法、划分方法、基于密度的聚类方法、基于模型的聚类方法和基于网格的聚类方法五大类。帕夫洛·安东年科(Pavlo Antonenko)等[4]分别以层次聚类方法和非层次聚类方法讨论聚类分析在教育数据挖掘中的作用。该项研究提出,无论是层次聚类分析还是非层次聚类分析,都是有效的分析方法。常见的聚类算法有K 均值聚类算法(K-Means Clustering Algorithm,简称K-Means 算法)、具有噪声的基于密度的聚类方法(Density-Based Spatial Clustering of Application with Noise,简称DBSCAN算法)等。
(三)关联规则
关联分析又称关联挖掘,关联分析是从大量数据中发现项集之间有趣的关联和相关联系。
一般可以将该算法分为两个阶段:第一阶段先从数据集合中找到频繁项集,第二阶段则对这些频繁项集进行分析,得到其中的关联规则。常见的关联规则分析算法包括Apriori 算法、FP-growth 算法等。
(四)其他常见技术
人工神经网络(Artificial Neural Network,简称ANN),这种算法模型通过模拟学习动物神经网络的行为特征,将数据进行分布式并行处理。其于上个世纪80 年代开始发展,至今已在计算机方面取得不小成就,解决了不少现代计算机难以解决的问题。
Web 挖掘技术,即以网络资源信息为数据集,使用数据挖掘技术进行处理和分析,从中获取有意义的信息。它是一项综合性的技术,包括Web 技术、统计学、计算机语言学、数据挖掘技术等多个领域。
层次分析法(Analytic Hierarchy Process,简称AHP),由美国国家工程院院士托马斯·萨蒂(Thomas Saaty)于上个世纪70 年代初期提出,该算法适用于针对定性问题进行定量分析,是一种简便、灵活而又实用的多准则决策方法。
二、数据来源
本文以“教育数据挖掘”为关键词在CNKI进行检索,收取2010—2020 年125 篇教育数据挖掘领域技术类文献,包括62 篇期刊论文和63篇硕士论文。剔除和主题无关、重复的文章,只筛选出解决实际问题的论文,收集的125 篇文献均使用数据挖掘技术或其他相关算法,完成一定的数据处理,对教育环境和教育利益相关者有反馈作用。
本文研究了这125 篇文献应用技术的情况、不同技术的使用情况以及近十年使用技术变化的趋势。
三、国内近十年教育数据挖掘领域的应用技术基本分析
图1 展示出每年的文章篇数与每年技术类文章数量。表1 显示的是每年文献总数和技术类文献数量比例。可以发现,技术类文献处于一个总体增长的趋势。且在教育数据挖掘领域,技术类文献越来越占据文献主体。

表1 每年文献与技术类文献数量比
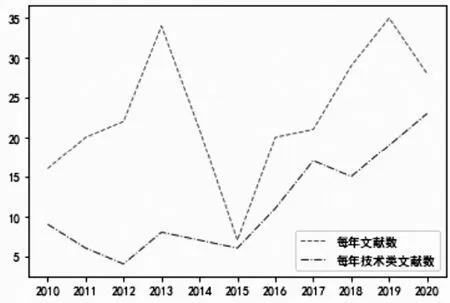
图1 每年文献数与技术类文献数
这些论文使用的技术包括分类技术、聚类技术、关联规则技术、Web 挖掘技术、遗传算法、神经网络算法等。图2 描述的是这些论文使用的技术,以及使用技术文章数量的统计情况。图3 为各类技术占比。其中涉及关联规则的有35 篇,涉及分类技术的有51 篇,涉及聚类技术的有28篇,涉及遗传算法、神经网络的各有3 篇,涉及Web 数据挖掘的有6 篇,涉及其他技术的有20篇。因存在一篇文献使用多种技术手段的情况,统计数量有部分重叠现象。
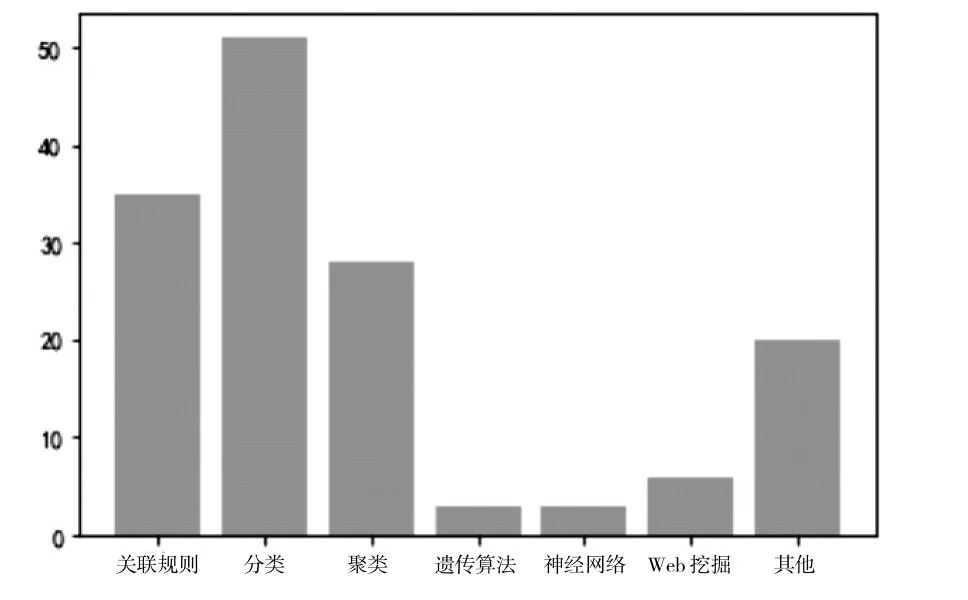
图2 技术及技术使用数量统计
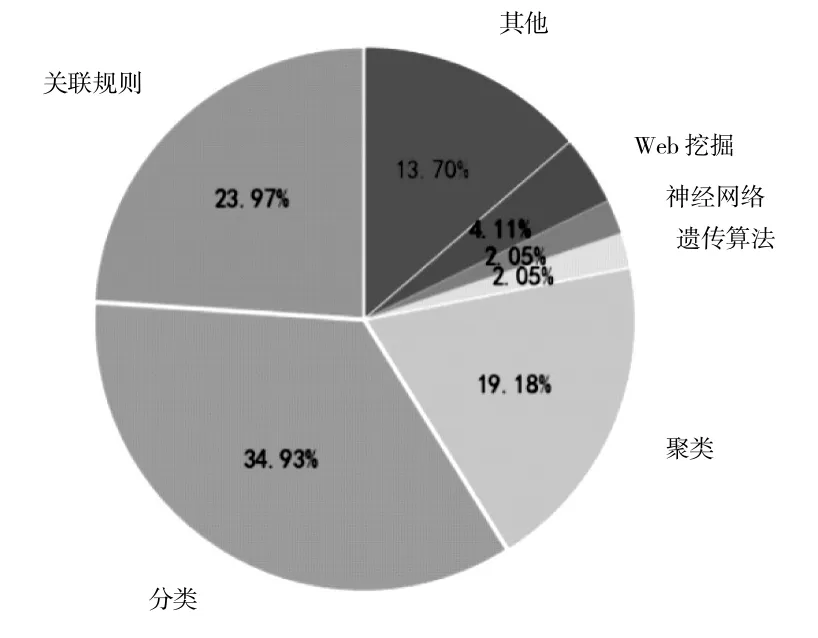
图3 各类技术使用占比
(一)关联规则技术的使用
关联规则技术主要是找到数据之间的联系——相关性或因果性。其目的是在找到相关性或因果性之后采取相应的措施改善情况。在选取的35 篇论文里,主要是对教育环境数据进行分析,找到目标变量的重要关联因素,分析影响方式,从而做出相应反馈。通过分析总结,将其分为应用于学生和应用于管理两类。
1.应用于学生
关联规则技术在学生层面的应用一般包括学生行为分析和学业表现情况分析。目的是找出重要影响因素,从而提出相应建议。张芬芬、许新华[5]使用Apriori 算法研究学生的课程安排与学业表现二者之间的关系,得出学生的课程安排情况对学生的成绩有一定的影响,且合理的安排课程能帮助学生更好地学习。喻越[6]考察学生英语四、六级的通过成绩与入学英语成绩、在校英语成绩之间的关系,得出在校英语成绩更能决定四、六级成绩的结论,因此需要重视大学期间的英语学习。易新河等[7]和程楠[8]也做了与喻越类似的研究,其研究结果均证明了该观点。罗晓丽[9]通过分析不同专业学生的借阅图书信息,认为可改变图书安排方式以引导学生更好地学习。王兆连[10]使用Apriori 算法分析高师类学生的教育能力,发现影响学生教学能力的主要因素及影响关系。
2.应用于管理
关联规则技术也可以为教育环境中的研究人员和管理人员提供帮助。数据挖掘技术在教育体系中的应用,涉及对(个性化)平台设计、教学预警系统、教学课程安排、教学质量评价,以及聚集性现象的分析等方面。陈霄、曾振东[11]希望通过使用关联规则方法来找到教师的信息是否与教学成果有关,从而提升教学效率和质量。章丽芳[12]、刘丰年[13]与陈霄等人做了类似研究。吴修国、孙涛[14]和叶福兰[15]分别用FP-Growth 算法和Apriori 算法对学生学业预警进行研究。
程楠[8]在教务管理系统中分析学生高考英语成绩、在校英语成绩以及四级考试成绩之间的关系,总结出学校在英语教学方面存在的问题。赵纪涛等[16]则使用Weka 分析学生答卷情况,找出教学薄弱点。李伟杰[17]使用数据挖掘技术实现一个集成性的教学质量跟踪平台,对学生多门课程成绩进行操作和分析,实现学生成绩统计分析和学生成绩预测,为提高教学质量提供参考。
图4 展示的是关联规则不同算法使用的统计数量。使用关联规则算法的35 篇论文里,涉及Apriori 算法的有23 篇,涉及FP-Growth 算法的有5 篇,另外还有7 篇使用的是分析软件内置的分析算法,例如,葛琦[18]对不同学科之间的成绩进行分析时,使用的是Microsoft 内置的关联规则算法。

图4 关联规则算法统计
(二)分类技术的使用
分类技术是对数据对象进行分析,将其划分到一个合适的类。2010—2020 年国内教育数据挖掘领域使用分类技术的文献有51 篇。通过总结分析,可以将其分为预测和重要性分析两类。
1.预测
在教育数据挖掘领域,预测是一个重要应用领域,而分类的绝大多数目的也是进行预测。在阿米拉·穆罕默德·沙希里(Amirah Mohamed Shahiri)等[19]整理的2005—2015 年关于预测学生学习表现进步的43 篇文献中,使用分类技术来进行预测的就有23 篇,占据总文献数的53.49%。
国内使用分类技术的目的也多数是进行预测,在51 篇分类文献中,涉及预测的有30 篇。庄党[20]对北京某Java 培训公司的学生进行学习行为的研究,分别以KNN、SVM、KNN-SVM 算法及其相结合的方式对这1342 名学生最后取得的成绩进行预测,找出重要影响因素,在必要时进行预警,以提高培训效果。孙力等[21]通过分析学生网络英语学习的信息,使用C5.0 算法对最终学习成果进行预测,并针对发现的问题提出相应对策。前面提到李伟杰设计的综合性平台,也使用C4.5 算法对学生的成绩进行预测,以期望提高教学质量。
2.重要性分析
分类技术还可以应用于重要性分析,找出目标因素的重要影响因素,从而反馈有效建议。吴梨梨[22]对某高职学校的学生专业选择和专业倾向使用C5.0 算法进行分类分析,找出对专业学习重要的影响因素,对学生进行专业选择的引导,也对学校的专业设置进行建议反馈。翁宇[23]对高校的教学评价进行研究,引进专家意见平均法和权重值的均值为三级评价指标,并使用ID3算法和C4.5 算法对教学质量的评价进行分析,以期望提高教学质量。
有关分类技术的论文有51 篇,使用的算法比较丰富,其中使用支持向量机的有6 篇,使用ID3 算法、C4.5 算法、KNN 算法、贝叶斯算法和C5.0 算法的各有7 篇,CART 算法的有5 篇,其他分类算法的有5 篇,如图5 所示。

图5 分类算法统计数量
(三)聚类技术的使用
聚类技术可以帮助研究人员管理和组织大型数据集,以及在后续分析中使用已建立的聚类。一般聚类算法可以用于学生行为分析、离群点检测等,也有少数研究使用聚类算法进行预测。
在选取的28 篇聚类技术的论文里,使用K-Means 算法进行聚类分析的文献有23 篇。另外,涉及DBSCAN 算法的有2 篇,以及其他算法的有3 篇,如图6 所示。

图6 聚类算法使用分布
典型聚类算法的使用涉及不同学者的研究。王改花、傅钢善[24]对某在线课程的学生数据进行分析,使用K-Means 算法进行聚类,将学生分为四类,得出学生若沉浸性高、学习效果也会随之更好的结论。洪雷[25]则对某院系的辅导员工作考察表进行聚类分析,能更加公正地对辅导员工作进行评价。葛琦[18]在对学生不同学科的成绩进行聚类分析时,对差分进化算法进行改进,分别使用差分进化聚类算法、改进后差分进化聚类算法与K-Means 算法进行聚类效果比较,发现两者的表现均优于K-Means 算法。
(四)其他技术的使用
除了上文提及的三种数据挖掘技术,还有其他技术应用于教育数据挖掘领域。叶勇[26]在对课堂教学的数据进行分析时,使用遗传算法对SVM进行参数优化,从而提高对课堂教学质量分析的精度。陈晓明、唐新宇[27]使用AHP 算法对教学质量评价指标进行分析,以提高教学质量评价的公平性。于繁华等[28]通过规则检测和离群检测建立对交互式学习的预警模型,能更高效地获取预警信息,从而提高教学质量。
四、国内近十年教育数据挖掘领域应用技术的变化分析
对2010—2020 年每年教育数据挖掘技术类文献所使用的技术数量进行梳理,结果如图7所示。

图7 每年文献使用技术数量变化
从图7 可以发现,2010—2020 年关联规则技术的使用在慢慢减少,而分类和聚类技术的使用逐渐占据多数,且其他领域技术的使用也呈增长趋势。其变化特点和规律可总结为以下几点。
(一)从单一技术到多种技术融合
国内早期教育数据挖掘领域对技术的使用多局限于使用数据挖掘方法对教育数据做一些简单分析,提出适当反馈,且通常也只使用一种技术。陈思慧等[29]将关联规则简单应用于个性化远程教育,并做简要调整。洪雷[25]仅使用聚类对“辅导员考核表”进行分析,且对聚类技术的介绍占据论文总体的42%。
单一技术的使用也在一定程度上会造成分析结果的不准确。因此,教育数据挖掘领域应用技术的变化趋势是,从单一技术发展到不同技术来对文献进行技术分析,并进行结果比较或结果融合。叶福兰[15]研究影响学生成绩的因素,分别使用Apriori 算法、ID3 算法、K-means 算法对学生成绩进行分析,得到“危险学生”的共同特性,为教学预警提供帮助。对于教学质量的评估,赵俊红[30]在进行研究的时候,先使用决策树对影响因素进行分析,再使用Apriori 算法分析影响因素,最后进行意见反馈。这在一定程度上体现出研究者对教育数据挖掘理解的不断提升。
(二)从简单应用到技术改进
早期对教育数据挖掘方法的理解并不透彻,因此,在技术使用方面呈现的是简单化。陈思慧等[29]对远程教育的分析、陈霄等[11]在对教育质量的评估中,仅是简单应用关联规则技术,找出对教学质量影响的重要因素。这些文献对技术的使用占比较小,论述性内容占比较大。这体现出当时的研究对教育数据挖掘的理解程度不深。
随着信息化教育的深入推广,产生大量的教育环境数据,简单分析数据已不能满足教育利益相关者的需求。教育数据挖掘的研究者不再局限于单纯地使用现成技术来完成研究,将经典算法根据具体情况进行改进,并运用于文献研究成为趋势。宗晓萍、陶泽泽[31]对传统的KNN 算法进行改进并应用于学生的学业预警,实验证明,改进后的算法明显优于传统KNN 算法。杨强[32]针对运用Apriori 算法扫描数据库时出现的问题,提出相对应的改进算法,以降低算法执行的匹配难度和时间消耗。庄巧蕙[33]结合模拟退火算法对传统的随机森林算法提出在特征选择、参数优化等方面的优化,并应用于学生学业情况预测,证明改进后的算法能有效识别出重要影响因素。吴修国等[34]在研究教育大数据时,融合AprioriTid 方法,对Apriori 算法进行改进,提出一种模糊关联规则算法,实验结果表明,该算法可以有效降低算法时间消耗。
(三)从单一领域技术到多领域技术融合
随着各领域的交融发展,教育数据挖掘领域使用的技术也变得多元化。另外,深度学习和人工智能潮在国内的爆发,也影响到教育数据挖掘领域的研究。不同领域的方法被应用于教育数据挖掘的研究。赵红宁[35]在高校的留级预测中,不仅使用决策树和朴素贝叶斯等传统的数据挖掘算法,还加入反向传播神经网络和遗传算法等技术,一定程度上提高了预测的精准度。秦立山[36]在设计教育资源平台时加入深度学习技术,以提高资源利用率、增强平台的普适性。王伟奇[37]对高中数学学习情况进行预测,综合12 种机器学习方法,并对其进行综合比较得出最佳适用模型。于雪萌[38]基于深度学习对学生行为序列建模,结合注意力机制,更加准确地捕捉学生的意图。吴元君[39]和李艳红等[40]在研究个性化学习时,加入情感分析和热点推荐算法。这都是技术发展与融合的体现。
五、总结
本文对过去十年国内教育数据挖掘领域技术的使用进行总结与分析。每个时间段使用的技术与政策颁布、潮流发展均有关系。其规律总结为以下几点:①早期使用较多的技术,如关联规则技术和Web 挖掘技术日渐式微,聚类和分类技术的使用逐渐成为主流。②各领域交融发展,教育数据挖掘领域使用的技术也变得多元化。③随着研究人员对技术的使用和理解深度化,改进传统方法和融入新兴技术逐渐成为教育数据挖掘的研究潮流。教育数据挖掘的研究处于上升趋势,跨领域与多元化也将成为未来教育数据挖掘领域研究的主流。
