应用主题爬虫的电力网络舆情数据采集
2022-05-11奚增辉王卫斌陆嘉铭瞿海妮
奚增辉,王卫斌,陆嘉铭,瞿海妮
(国网上海市电力公司,上海200122)
0 引 言
在电力网络系统快速发展的背景下,国内供电网的大多数业务均实现了网络化管理模式,网络通信成为电力发展和应用的重要数据基础[1-2]。然而电力网络应用中舆情频发,往往在很短时间内就快速传播,引起电力用户的广泛关注,从而形成舆论事件[3]。其网络舆情的发生原因既包括内部原因,也有外部原因,包括供电企业服务不佳、相关政策未能贯彻落实以及企业存在乱收费等情况,电力企业都需要对电网行业的舆情进行了解,居安思危,进而更好地推动行业发展。那么,如何快速准确获取电力网络舆情,了解用户最核心的意见,成为有效引导舆论热点的关键。在此背景下,电力网络舆情数据采集成为近来重要研究内容,通过采集此类数据能有效提高对电力网络的日常管理,提高工作效率。
常用的数据采集技术大可分为4类:ETL技术可在离线状态完成数据提取、转化及加载;Flume技术可实现实时采集,主要应用于考虑流水处理的业务场景中;网络爬虫技术可自动抓取网络中的信息程序或脚本,支持图片、视频、音频等文件格式的采集;对于企业生产经营相关的机密数据可通过特殊系统端口完成数据采集。
电力网络的舆论热点主要集中在微信、QQ、微博等社交网站之中,可利用网络爬虫技术进行数据获取[4]。网络爬虫技术是搜索引擎的重要组成部分,能够提供固定抓取规则,定向链接数据,辅助完成数据搜索并自动生成索引信息。网络爬虫技术面向底层互联网直接进行数据获取,因此对网络更新速度也具有一定影响[5-6]。
鉴于网络爬虫技术的优势和重要性,许多研究者针对网络爬虫技术以及电力网络舆情数据采集做出了相关研究。党佩等应用网络爬虫技术,采用XPath和正则表达式进行信息抽取,从电力网络中抓取事故信息相关内容,并进行信息数据匹配操作,获取电力事故相关信息,该方法能快速完成信息获取,但计算准确率不高[7];冯昊等主要利用网络爬虫TCP/IP协议栈,通过布局分配电力数据搭建了一种新的数据瓦解模型,解决网络占用资源合理分配问题,但该方法运行时间较长[8];谢文旺等提出了一种电力线通信数据处理算法,以实际用户用电采集数据为基础,采用改进神经网络进行数据处理,并对具体处理方式作出描述,通过仿真实验验证了该设计方法的可行性,但召回率较低[9];曾健荣等提出了一种新的网络爬虫数据采集技术,主要对象为多数据源,该文采用Servlet后台调度技术,融合处理了网络爬虫数据,对解析网页源码提取数据,将提取得到的信息存入数据库,提高了数据采集效率,但计算准确率还有待提高[10]。
为解决现有研究的不足,在电力网络舆情研究中采用主题爬虫技术,给模型添加链接和网页分析功能,滤除无关信息,达到降低资源存储和运算量的目的[11]。本文提出基于网络爬虫技术的电力网络舆情数据采集方法。
1 主题爬虫
网络爬虫技术也叫网络蜘蛛技术,是目前互联网研究中的典型技术,通过互联网中的统一资源定位系统(uniform resource locator,URL)进行数据定位符统一化处理,按照一定策略遍历网页,获取互联网网页数据并做出数据分析、舆情采集等,同时将数据迭代传递反馈[12-13]。网络爬虫技术的主要功能包括URL解析、互联网网页数据存储以及数据爬取队列维护等。本文采用网络爬虫技术的主要目的是爬取电力网络舆情相关数据,为电力网络舆情分析和控制提供数据基础[14]。
比较常见的网络爬虫技术为通用网络爬虫。该技术从URL开始,爬虫系统开始访问网页,采集网页所有超链接。为了防止获取重复的 URL,将爬取到的网页信息存储在原始数据库中,然后对网页进行解析,并根据网页搜索策略爬取新的URL。重复上述过程,直到爬取到的URL符合停止条件,则完成整个爬虫过程。这种面向全网的检索工具,需要非常大的存储空间和带宽,无法准确提供用户特定的需求[15]。因此,提出了面向特定主题需求的网络爬虫,即主题爬虫。
主题爬虫比通用网络爬虫复杂一些,需要定义目标、过滤无关链接、选取下一步爬取的URL地址。主题爬虫可以按照对应的主题有目的地进行爬取,将目标定位在互联网中与主题相关的页面中,初始URL的获取是通过对抓取目标的定义以及相关的描述。为了帮助爬虫更有效地发现与主题相关的URL,需要对主题准确描述,然后解析网页内 URL,判断网页与主题的相关度,根据网页搜索策略预测链接的主题相关度并确定 URL优先级。在聚焦网络爬虫中,不同的爬取顺序会导致爬虫的执行效率不同,需要依据搜索策略来确定下一步需要爬取的 URL 地址并存储。整个主题爬虫不断重复上述过程,直至符合爬虫系统中规定的停止条件[16]。
基于主题爬虫的电力网络舆情数据采集框架如图1所示。
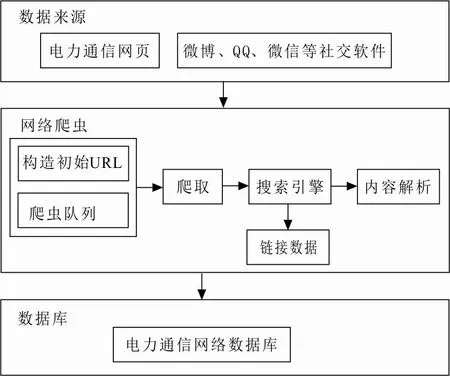
图 1 基于主题爬虫的数据采集框架Fig.1 Data collection framework based on topic crawler
2 电力网络舆情数据采集
网络舆情[17]具有明确的主题内容,在采集电力网络舆情之前需要首先构建该事件的主题向量,然后利用主题爬虫进行主题搜索、数据相似性分析等操作,最终实现网络舆情采集。
2.1 网络舆情的主题向量构建
主题向量构建是主题爬虫运行的首要步骤,使用主题向量表示网络舆情信息,能为后续舆情的主体相似度计算提供依据,帮助判断所获取信息是否与主题相关。
特征词是目前应用较多的主题向量构建方法。首先用户提供与电力网络舆情相关的网页,然后构建网页集合作为训练样本并提取网页特征,生成特征词,最终完成主题向量构建[18-20]。但该方法在运行初始阶段很难判断主题网页的质量,有很多用户的主观性在其中,网页权威性不高,导致样本的可信度不足,因此本文引入开放分类目录(open directory project,ODP),将ODP作为目标源对网页进行分类。ODP是目前人工编辑网站中内容最丰富的网站分类目录,引入ODP能有效提高网页权威性,很好地解决特征词样本可信度不足的问题,提高主题向量构建效果[21-22]。
电力网络舆情包含众多网页,每一个网页中的标题和所含内容均是对主题的表征,可使用主题来描述这些信息。因此本文从ODP中选取与电力网络舆情相关的目录文件,构建电力网络舆情的主题向量,如图2所示。

图 2 主题向量构建流程Fig.2 Topic vector construction process
2.2 基于相似性计算的最佳优先搜索策略
电力网络舆情的频发以及网络数据的指数级增长,使得网络舆情相关网页数量庞大,那么如何在众多网页获取匹配性较高的网页,避免消耗过量资源则非常重要,主题爬虫技术中的搜索策略则能很好地解决这一问题[23-24]。搜索策略是主题爬虫技术的核心,主要用于判断网页下载的优先顺序。先对主题相关度进行整体评估,计算主题向量与电力网络舆情的相关网页的相似性,对网页进行评分,相关性越高的网页评分越高,评分完成后按照分数高低依次下载电力网络舆情相关网页[25-26]。
依据主题爬虫技术特性,选取最佳优先搜索策略进行网页优先级判断,具体过程如下:
1) 初始化电力通信网的网页,选取与电力网络舆情相关的链接,根据链接获取网页;
2) 通过网页与网络舆情相似性计算确定优先级[27-28]。假设电力通信网络中关键字的权重为wi,表示主题向量维度,数量为n,网页中关键词的权重结合频率表示总权重,关键词的频率表示为αi,网页中关键词的总权重表示为αiwi。那么电力网络舆情的主题向量可表示为
T1=(w1,w2,…,wn)
(1)
电力网络舆情的主题网页可表示为
T2=(α1w1,α2w2,…,αnwn)
(2)
利用相似度模型,考虑数据的语义特征,综合分析式(1)、(2),可计算得到关键词主题向量与电力通信网页的相似度Sim:
Sim(T1,T2)=cos〈T1,T2〉=
(3)
设定相似性阈值γ,将主题向量与主题网页的相关性判断向量表示为C,取值范围为(0,1]。若Sim(T1,T2)<γ,则取值为0,两者不相关;若取值在[γ,1]范围内,则两者相关。在该范围内,取值越大表示相关性越高。
3)选取相似度最高的网页设定为第一优先级,并将该网页作为目标网页进行爬取。
2.3 网络舆情主题数据爬取
在上述完成相似性计算和优先级确定基础上,给出基于主题爬虫技术的网络舆情主题数据爬取实现流程,如图3所示。
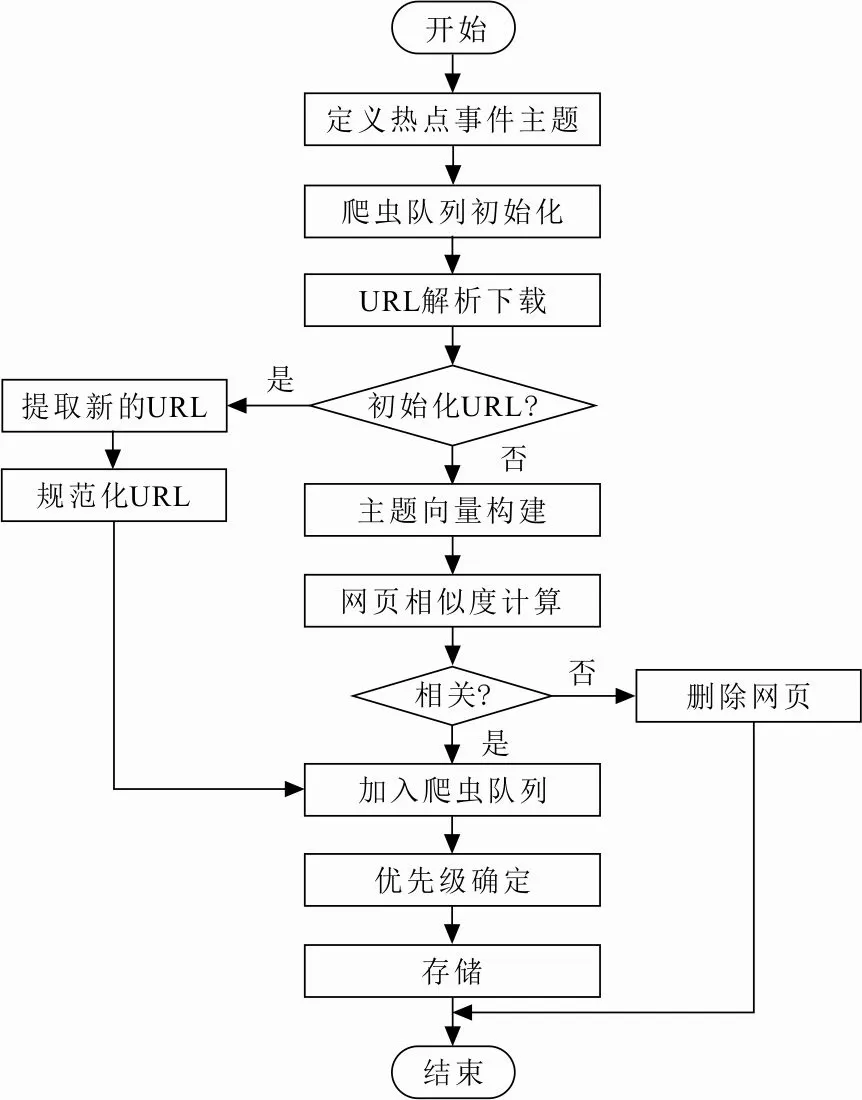
图 3 网络舆情主题数据爬取流程Fig.3 Crawling process of online public opinion topic data
从图3可以看出,通过主题爬虫技术进行电力网络舆情爬取时,首先定义网络舆情主题,初始化URL。然后构建主题向量,对主题向量和主题网页进行相似性计算,将与主题向量相关网页添加到网络爬虫队列中。使用最佳优先搜索策略选取最高相似性的网页作为第一优先级,依据优先级下载电力通信网的网页,并存储网络舆情,完成电力网络舆情采集。
3 结果与分析
为验证本文基于主题爬虫技术的电力网络舆情采集方法的有效性,设计如下对比实验。使用LoadRunner自动化测试工具,采用互联网服务端的性能测试软件开展实验。为保证实验测试结果的公平性,整个实验测试过程的环境和参数保持一致,分别测试本文数据采集方法与文献[7]、文献[8]、文献[9]方法的性能。
实验指标分别为:平均召回率、网页相似性计算准确率、数据采集耗时。
召回率即为查全率,是对数据采集方法获取结果全面性的一个描述指标,召回率越大,表示该方法的性能越好。为验证本文方法的有效性,以平均召回率为指标,在下载的网页数量分别为1 000、2 000、3 000的情况下,对比本文方法与文献[7]、文献[8]、文献[9]方法,结果见表1。

表 1 不同方法平均召回率对比Tab.1 Comparison of average recall rates ofdifferent methods 单位:%
从表1可以看出,随着网页数量的增加,4种不同方法的召回率均出现一定幅度的增长,但文献[7]、文献[8]、文献[9]方法在下载网页数量为3 000时,最大平均召回率均不超过80%,尤其是文献[8]方法,平均召回率仅为70%,而本文方法的最大平均召回率高达92%。通过数据对比可知,本文基于主题爬虫技术的网络舆情采集方法具有明显较高的召回率,展现出了较好的计算性能。这是因为本文引入ODP构建网络舆情的主题向量,有效提高了特征词样本可信度,从而提升了数据采集的召回率。
当应用主题爬虫技术时,网页向量与主题向量的相似性计算是非常重要的一步,因此本实验选取网页相似性计算准确率为指标验证本文方法,结果如图4所示。

图 4 网页相似性计算准确率对比Fig.4 Comparison of accuracy of web page similarity calculation
从图4可以看出,本文方法测试生成的准确度折线整体在90%以上,最高准确率达到95%,相比其他3种文献方法具有非常明显的优势。这是因为本文利用相似度模型计算网页向量与主题向量的相似性,考虑到了数据的语义特征,因此在计算性能上得到提高。
为进一步证明本文方法的优势,以数据采集耗时为指标对比本文方法与文献[7]、文献[8]、文献[9]方法,对比结果如表2所示。

表 2 不同方法数据采集耗时对比Tab.2 Comparison of data acquisition time ofdifferent methods 单位:min
从表2可以看出,网页数量越多,数据采集耗时越长。对不同数量的网页进行测试,本文方法的网络舆情采集耗时均值为36 min,文献[7]、文献[8]、文献[9]方法的数据采集耗时均值分别约为90 min、67 min、70 min。可见本文方法在采集时间上远优于传统文献方法,通过利用本文方法能有效提高电力网络舆情采集效率。
4 结 论
1) 引入ODP构建主题向量,并利用相似度模型计算关键字向量与网页向量的相似性,提高计算结果的准确率。
2) 本文方法具有非常优越的性能,相比文献[7]、文献[8]、文献[9]方法,其平均召回率为92%。
3) 相比文献[7]、文献[8]、文献[9]方法,本文方法的网页相似性高于90%,且数据采集耗时较短,均值为36 min。
