基于GBDT的城轨塞拉门早期机械故障诊断
2022-05-10张子豪王云霞王祖进陈健飞
张子豪,王云霞,王祖进,陈健飞
(1. 南京工程学院机械工程学院, 江苏 南京 211167;2. 南京康尼机电股份有限公司研究生工作站, 江苏 南京 210038;3. 南京康尼机电股份有限公司, 江苏 南京 210038)
近年来,随着国家经济水平大幅度提高,轨道交通行业也得到了大力发展,城轨列车因其舒适、便捷、安全的优点成为人们出行的重要工具[1].城市轨道车辆门的种类大致可以分为外挂移门、内藏移门、塞拉门等.其中塞拉门应用最为广泛,其优势包括密封性能良好、运行过程阻力小、节约空间[2].赵风启等[3]设计了一种针对城轨塞拉门机构不同频段振动信号的检测装置,利用计算机对振动信号处理分析,提取开门、关门过程中门机构的运行特征,通过对比实际门机构与正常状态下的各项振动信号特征的差异为机械故障的诊断提供辅助参考依据.但研究中对细化城轨塞拉门故障类型方面有所欠缺,也未对故障诊断可采取的切实方法进行具体展开.
由于城轨列车运行频率高、车门频繁开关,使得各零部件摩擦增大,导致门系统性能下降,引起门系统故障.在门系统健康与故障间存在着一种早期故障,这种状态存在于故障发生之前,若不及时处理,随着门扇的运行,可能会产生故障,影响列车正常工作,威胁乘客的安全.因此,需要做到对门扇故障的提前预知,并及时排查.目前,塞拉门早期故障问题主要表现为位置难以确定、故障难以排除,导致故障概率高、地铁检修排查量大、成本高[4]、人为排查工作时间长且效率不高.
1 建立故障诊断模型
信号采集试验通过改变塞拉门运行状态模拟试验数据.在严重故障发生之前,车门通常会因为性能退化出现一些微弱的早期故障征兆,如一些部件的退化和磨损.早期故障状态是指车门处于健康与故障之间的一种状态,主要表现为车门参数的异常变化,车门处于早期故障状态时仍然可以完成开关门功能,但如果不及时发现系统的早期故障并诊断出其早期故障状态,可能会导致严重故障的发生[5].因此,发现系统常见故障的早期征兆,准确识别故障类型,为工作人员提供维修指导,提前进行系统维护,可极大程度降低或避免灾难性故障的发生,这对提高车门系统的安全性、可靠性,降低故障率具有重要意义[6].采集相应城轨塞拉门各状态下运行数据.
诊断模型建立的总体流程如图1所示.
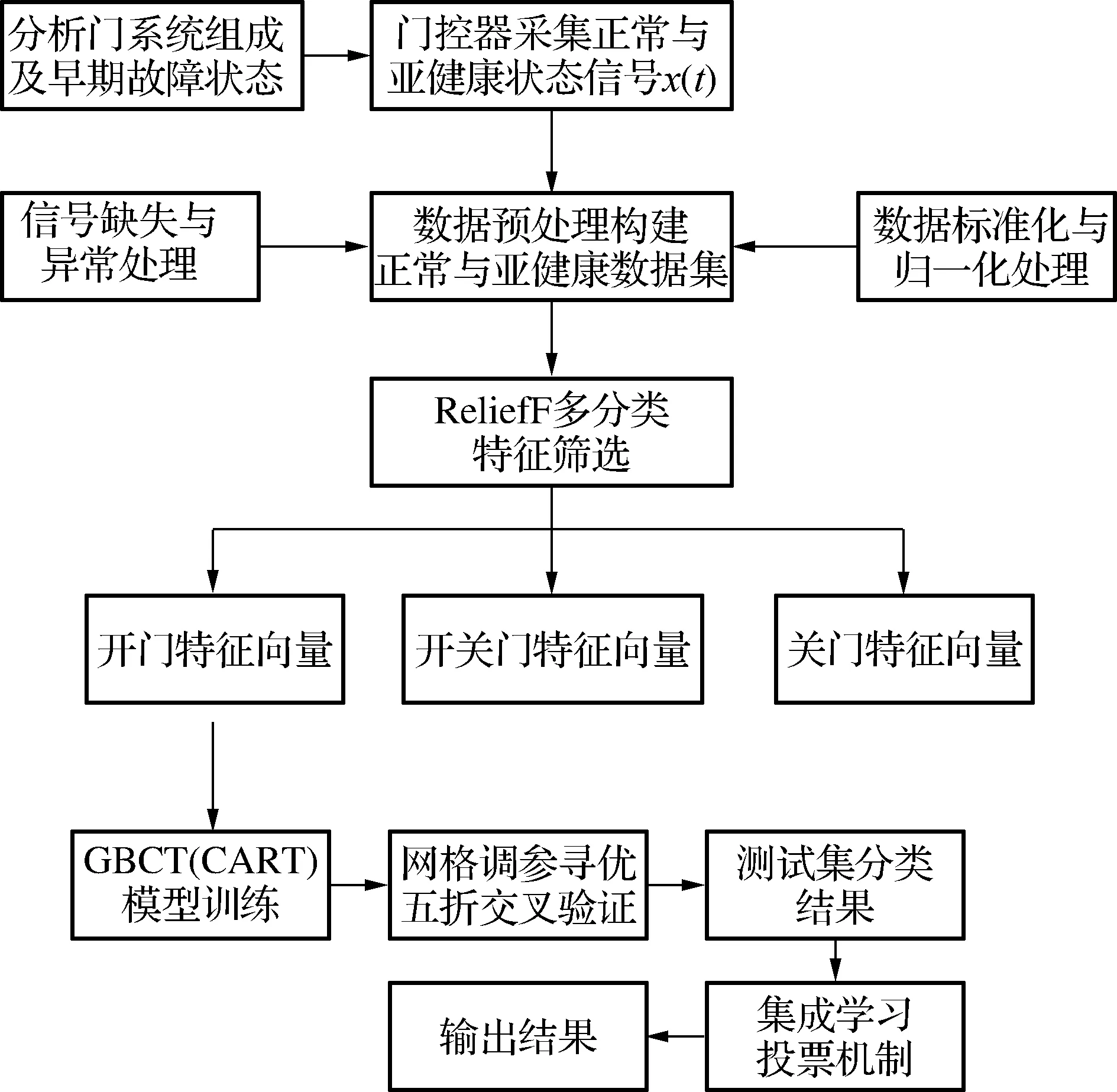
图1 诊断模型建立流程图
1.1 数据预处理
原始数据可能出现数据缺失、异常、位置偏移等问题,无法直接使用.通过设定异常阈值、删除不正常数据、以平均数补全遗失数据、调整原始数据位置,保证数据的合理性.采集电机转角、转速和电流3个过程变量.根据城轨塞拉门运动特性,将塞拉门开门状态分为启动段、升速段、高速段、减速段、缓行段和到位后段,关门状态分为启动段、升速段、高速段、减速段和缓行段.对开门、关门状态各过程进行时域特征提取,提取特征为行程、最大值、最小值、均值、标准差、偏度和峰度.分别计算开门状态六段的行程、最大值、最小值、均值、标准差、偏度和峰度的特征再加上总行程和总时间.通过时域分析将开关门特征分类为开门152个特征,关门127个特征.对状态识别作用较大的特征称之为相关特征,对状态识别基本上没有作用的特征称之为无关特征,在特征筛选中需要选取相关性较大的特征构建诊断模型[5].
方差极小判定条件为:
(1)
式中:freqcutx=xf/x1,xf为变量x频次最大的样本值,x1为变量频次大的样本值;Tf为对应阈值;uniquecutx=mx/nx,mx为样本值去重后的样本数量,nx为样本值数量;Tu为uniquecutx的检验阈值[6].
通过筛选去除开门第12个升速度转角标准差、第78个特征到位后段速度最小值、关门第10个特征高速段转角行程、第65个特征到位后段速度最小值.将原始数据中各数据从不同数量级处理成同一尺度的数据,一般的无量纲化方法有标准化和归一化[7].数据符合正态分布,通过计算平均值和标准差,将数据转化为符合标准正态分布.
标准化的计算公式为:
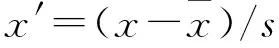
(2)
划分数据集D,将正常和亚健康状态数据集分为{D0,D1,D2,D3,D4}五个部分,其中:D0为正常状态,其他为不同情况亚健康状态数据集,从每组数据集中随机抽取相同组数据组成测试集,测试集不参与训练,防止对测试精度产生影响.
1.2 ReliefF多分类特征筛选
ReliefF算法根据不同特征的相关性来筛选特征,其中同类别与不同类别的相关性通过特征对近邻样本分类能力来判定[8].从训练集D中随机选择一个特征数据R,分别计算R与同类样本H最小距离、R与不同类样本M最小距离,如果前者距离小于后者距离,说明这个特征对分类效果起正作用,则加大该特征的权重;如果前者距离大于后者的距离,说明这个特征对分类效果起反作用,则减小该特征的权重.随机重复n次,计算权重的平均值.分类能力与特征权重呈正相关[9]、权重为负则影响分类效果,必须删去.ReliefF算法运行效率与数据集抽样次数n和特征个数N呈线性正相关,运算速度较快[10].ReliefF算法具体流程如图2所示.
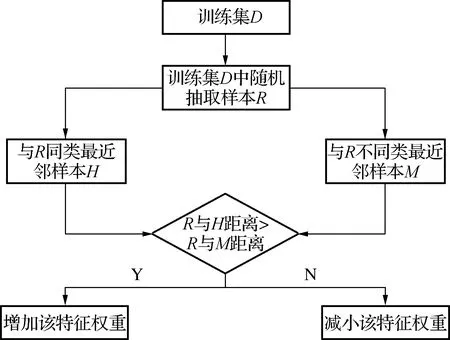
图2 ReliefF多分类特征筛选流程图
调取Matlab提供的ReliefF模块处理训练集,计算特征相应的权重,计算结果如图3所示.
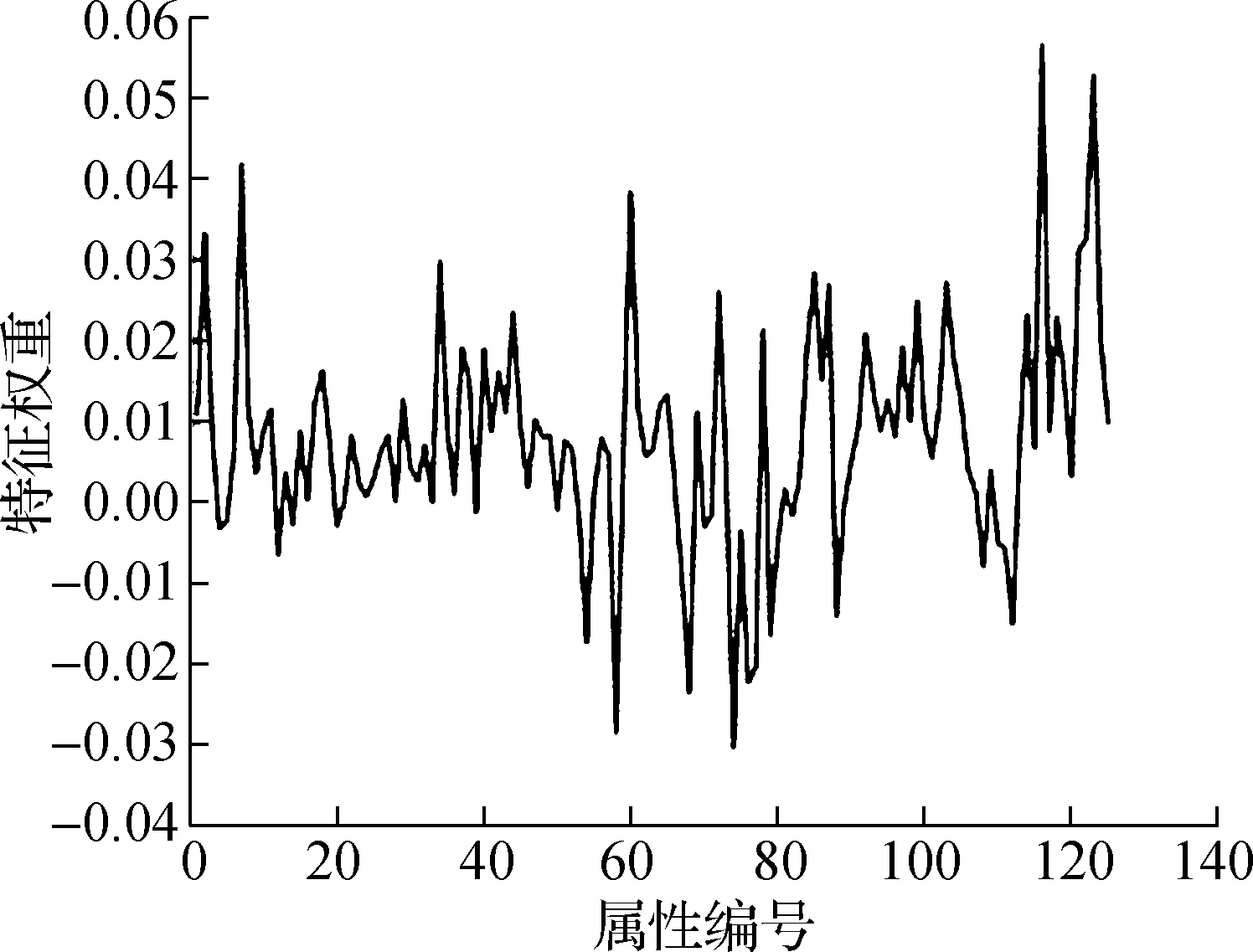
(a) 关门
按照特征权重大小设定开、关门特征权重阈值,权重阈值设置为0.95.将特征权重大的保留,特征权重小的舍去,开门特征选择权重前9项,关门特征选择权重前10项.
1.3 GBDT分类模型建立
集成学习策略分为Bagging策略和Boosting策略,本次搭建模型采用Boosting策略组合CART决策树[11].GBDT利用最速下降的近似方法组合多个决策树有效降低模型的方差和偏差.梯度提升树以决策树算法为基分类器,利用Boosting思想对弱分类器进行迭代,下一个弱分类器学习上一个弱分类器损失函数的负梯度.加权组合这些弱分类器,构成强学习器.地铁门系统开关过程存在[x1,x2,…,xi]和[y1,y2,…,yj]两组数据,两组数据叠加形成[x1,x2,…,xi,y1,y2,…,yj],通过三组数据描述当前城轨塞拉门系统运行状态.运用ReliefF算法计算相应权重,按照各自权重大小进行排序,建立三组诊断模型.以关门状态为例,本次选择5种类别.本模型训练集中有20%的健康类关门数据.GBDT多分类针对每个类别都训练一棵决策树.对5个类别分别进行训练,针对类别1的训练样本是以第一特征的第一特征值为例,第一棵决策树右边节点为样本中第一特征大于等于第一特征第一特征值的样本集合,左边为样本中第一特征小于第一特征第一特征值的样本集合,y1为左边所有样本的label均值,y2为右边所有样本的label均值.以此类推,遍历所有特征的所有特征值.
初始化弱学习器:
(3)
式中:f0(x)为初始函数;N为样本序号;c为初始预测值.
对函数的超参数进行设定,假设迭代次数为M,当前迭代次数为m=1,2,…,M,样本序号为n=1,2,…,N,当前模型损失函数的梯度值为:
(4)
当前模型的损失函数负梯度值为γmj,对γmj进行决策树计算,得到第m棵树的叶子节点区域Rmj,j=1,2,…,J.根据不同的学习率对模型进行更新:
(5)
式中:Fm(x)为m轮迭代后的值;lr为学习率;cmj为第j个第m轮迭代的叶子节点值;I为损失函数.
承接上一轮的拟合结果拟合下一轮模型,多次迭代后残差值越来越小,本案例最终迭代26次,模型建立公式为:
(6)
以开门模型为例,初始参数选择:学习率为0.1(学习率过大会导致过拟合);迭代次数为5;树的深度为2.
为适用于多分类情况,本案例以logloss为损失函数,使用的对数似然损失函数为deviance.
1.4 GBDT参数寻优
将训练集随机划分为5份,其中1份作为测试集,结合内部五折交叉验证法(5-Fold CV),使模型在建立过程中不必使用大量数据,5次轮流使用内部训练集训练分类诊断模型,找到使模型具有更好泛化能力的超参数.
由于本案例模型存在大量参数,设置的初始参数值不能得到最优性能.使用网格调参进行超参数寻优.为提高计算效率,针对性地选择对模型影响较大的几个参数划分最小样本数,包括迭代次数、学习率、最大深度和节点.采用顺序网格调参,但由于按顺序调参容易形成局部最优解,选择将重要参数进行并列调参,避免形成局部最优.通过超参数寻优,减少迭代次数和模型决策树的数量,提高了运算效率和分类精度,降低了运算时间.参数寻优结果如表1所示.

表1 梯度提升树模型参数
1.5 集成学习投票
由于存在开门、关门和开关门三分类器,分类结果存在一定的差异性,即可能出现三者相同的情况、其中两者相同的情况以及三者完全不相同的情况,无法判断哪个分类器为真.本案例采用集成学习投票机制(VMAEL),VMAEL是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,提高模型的鲁棒性.采用硬投票法,诊断结果是所有投票结果中出现最多的类别.
2 试验结果与分析
为了验证模型性能,利用C4.5、CART算法分别进行亚健康诊断,并将测试结果与本文提出的评估模型进行对比,不同模型的性能诊断结果如表2所示.
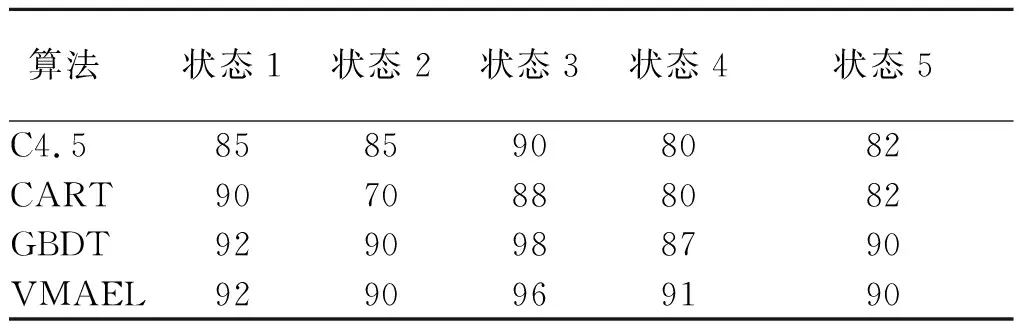
表2 基于不同诊断算法的诊断结果 %
由表2可见,应用VMAEL融合GBDT三个分类结果得到的各类型分类结果准确率达到90%以上,具有较高的鲁棒性.即本文提出的诊断模型具有较高的精度与计算效率.
为了验证ReliefF算法在降低本模型特征维数的效果,采用主成分分析法(PCA)、线性判别分析法(LDA)、ReliefF算法分别进行降维.为保证对比试验的一致性,三个模型的建立均采用网格调参与内部5-Fold CV对算法参数进行调整.不同特征降维算法诊断结果如表3所示.
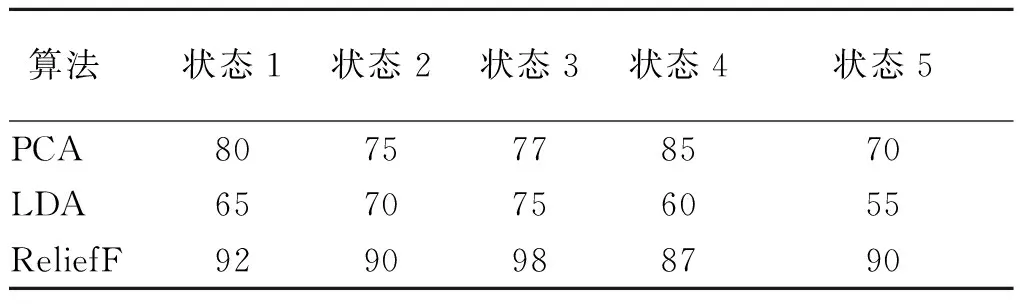
表3 基于不同特征降维算法诊断结果 %
由表3可见,在特征融合上,ReliefF算法相较于其他两种算法对特征信息的保留度更高,特征筛选更为精确.
3 结语
本文基于GBDT的城轨塞拉门早期机械故障诊断方法构建塞拉门早期机械故障状态;通过门控器对开关门电流、速度、转角、加速度等信号进行采集;按照门扇开关门特性将整个过程分为开门6个阶段、关门5个阶段;通过无量纲化与方差极小判定对数据进行预处理;通过ReliefF算法计算特征数据在同类别与不同类别之间的最小距离并比较,计算特征权重并进行特征筛选,降低特征维度,提高了运算速度和精度.试验结果表明,与PCA和LDA方法相比,ReliefF特征筛选表现最优;针对城轨塞拉门信号频率低、干扰小、模型可复制性的特点,采用GBDT算法中的Boosting集成学习策略建立相应的开关门诊断模型;通过5-Fold CV与网格调参,选择部分重要的超参数进行并列寻优,防止局部最优,提高了运算效率和模型的泛化能力;采用VMAEL对开门、关门、开关门多组模型进行对比诊断,通过多个模型的集成降低方差,得到的模型诊断精度在90%以上,表明模型具有较高的鲁棒性.
