改进Faster R-CNN的道路目标检测*
2022-05-10朱宗晓徐征宇
周 康 朱宗晓 徐征宇 田 微
(中南民族大学计算机科学学院 武汉 430074)
1 引言
目标检测作为计算机视觉领域的核心问题之一,其目的是检测目标在图像中的位置并确定其类型。道路目标指对车辆行驶行为有重大指示意义的目标,对其进行识别定位是实现自动驾驶的基础环节。随着计算机硬件性能的快速提升,研究人员开始将深度学习应用于目标检测任务。卷积神经网络对图像数据进行若干层的组合操作(卷积、池化和激活函数)提取出语义特征,弥补了手工提取特征低效、泛化能力弱的缺点[1]。以YOLO[2]、SSD[3]为代表的一阶段目标检测算法直接预测图片中包围框的类别和偏移量。两阶段目标检测算法如Fast R-CNN[4]首先做初步检测,生成候选区域(包含物体大致位置)后对预测框进行详细分类和位置微调。以Faster R-CNN为代表的两阶段算法包含生成候选区域的过程,有利于提高检测精度,尽管相对一阶段算法耗时多,但是其网络框架更灵活,适用于复杂的车辆行驶环境。
车辆行驶时视野开阔,道路小目标数量繁多成为自动驾驶场景下的关键问题。针对通用目标检测框架对弱小目标检测效果不佳的问题,国内外学者做了大量研究。Bai等[5]提出基于GAN的目标检测算法,使用超分重构将提取出的RoI高清化再做检测。由于对图片做了两次检测,模型检测实时性较差,不适用于自动驾驶场景。Takeki[6]等将语义分割与目标检测方法相结合,使用支持向量机(SVM)整合深层CNN网络、全卷积网络(FCN)及其变体的训练结果以提高检测性能。该方法在背景单一的图像中检测鸟类效果良好,但对于复杂背景下的多目标识别则表现不佳。Zhu等[7]提出设置anchor的新思路:采用上采样扩大特征图尺寸并减小anchor步长、增加小尺度anchor数量等方法使anchor与小目标的匹配度更高。Xin等[8]融合卷积神经网络的多层特征,针对小目标本身信息量弱的特点,借助周边像素点信息辅助模型进行判断,但相邻目标的漏检率较高。Kong等[9]对浅层特征作最大池化、深层特征作反卷积,经过LRN归一化得到图像超特征以提升小物体检测效果。
本文以Faster R-CNN为研究对象,针对自动驾驶场景下的目标类别复杂、弱小目标多等问题引入特征金字塔结构,融合图像不同特征层的语义信息,提高对道路小目标的检测精度。对数据集标签进行分析,选择更适合的先验框尺寸,并且替换VGG16特征提取网络,采用更深层的卷积神经网络ResNet50以获取更丰富的语义信息,改善模型检测道路目标的各类别精度。
2 改进算法模型
2.1 Faster R-CNN基本原理
Faster R-CNN检测流程如图1所示,首先将输入图像缩放处理为统一大小,经过特征提取网络(VGG16[10])获得区域建议网络(RPN)所需的全图特征。随后RPN利用特征图生成若干候选区域和相应的概率得分,对所有候选区域做非极大值抑制后将得分最优的候选框送入感兴趣区域池化层(ROI pooling)。候选框的特征图经过ROI pooling缩放到7×7大小,最后经过全连接层(FC)输出候选框的类别预测及位置回归结果[11]。
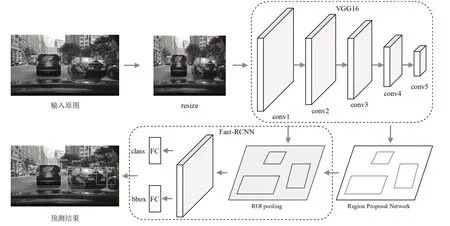
图1 Faster R-CNN检测框架
2.2 改进特征金字塔结构
Faster R-CNN的骨干网络使用多层卷积逐步提取图像的语义信息,生成不同大小的特征图。VGG16是Faster R-CNN常用的骨干网络,其包含5个卷积和1个分类模块。VGG16的网络较浅,提取出的特征信息不全。ResNet50包含深层的特征网络能提取出更丰富的语义信息,残差结构的引入也有效解决了网络层数增加导致的退化问题[12]。本文后续的实验主要采用ResNet50作为Faster R-CNN的特征提取网络。
原始Faster R-CNN网络中,候选区域的特征仅由最深层的卷积层提供,经过多层卷积后的深层特征中几乎不包含弱小目标的语义信息[13]。参考FPN[14]的思想引入多尺度特征融合,对网络中多种尺度的特征图分别做上、下采样,融合后针对不同尺度的目标物在对应层的融合特征图上生成候选区域[15]。浅层卷积神经网络输出的特征包含图片中的细节信息,能帮助模型更好地识别弱小目标,特征融合的具体结构如图2所示。
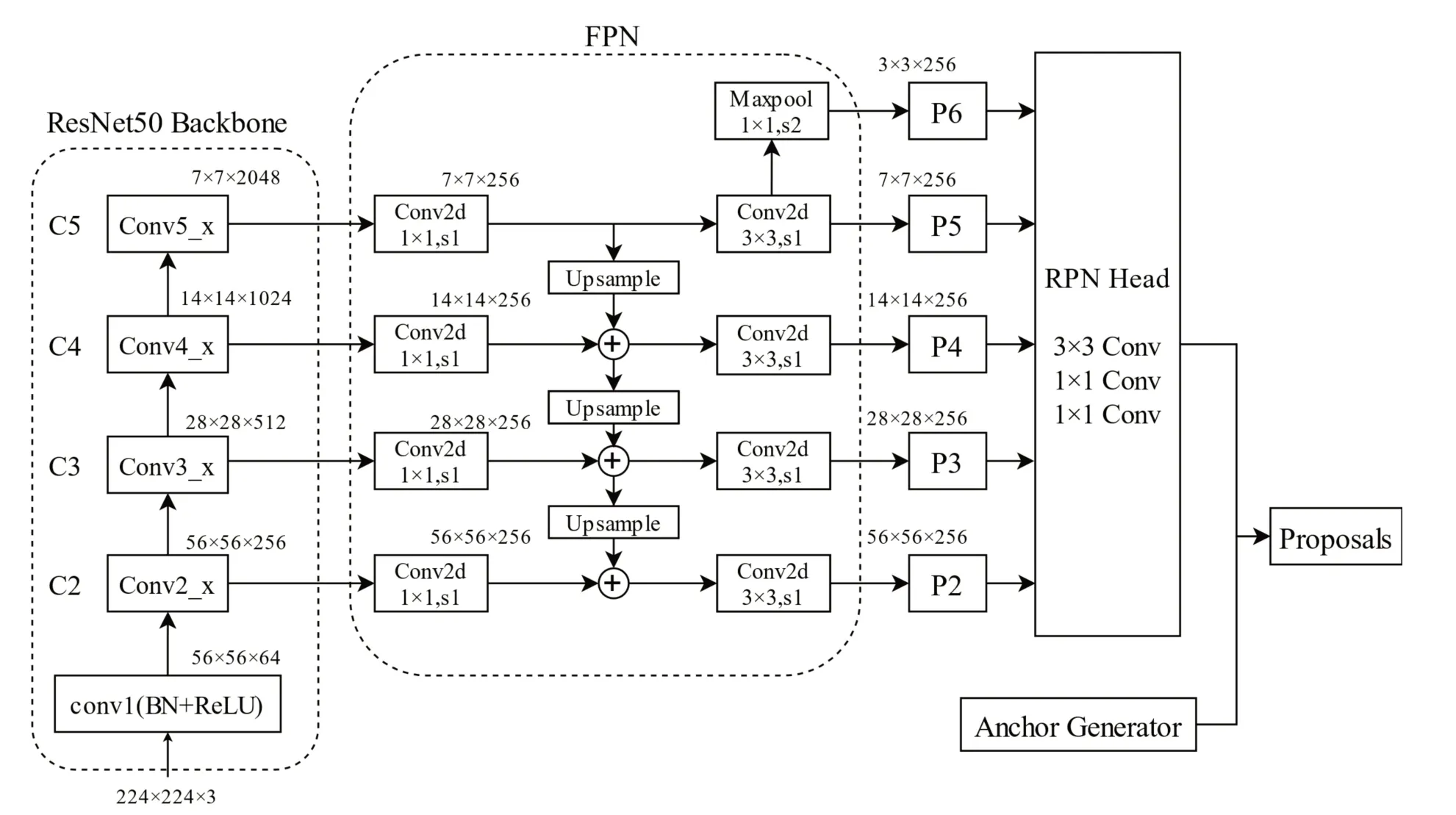
图2 加入FPN的特征提取模块
举例说明,输入224×224大小的图片,经过卷积模块Conv1后,特征图尺寸变为56×56。随后每经过一个残差模块输出一种尺寸的特征图,不同层之间按照2的整数倍进行缩放,C2~C5输出的特征图尺度分别为56×56,28×28,14×14以及7×7。将不同尺寸的特征图进行融合,每个残差模块提取出的特征图先经过1×1的卷积核使得各层的通道数相同(侧向连接),再使用邻近插值算法对深层的特征图做两倍上采样保证两个卷积模块之间特征图H、W相等。相邻模块输出的特征图经上述处理后融合(逐个元素相加)。对上采样得到的特征图进行3×3的卷积以消除混叠效应对后续预测结果的影响。由上至下实现特征图的融合,C4输出的特征图调整通道数后与C5上采样后的特征图逐元素相加,经3×3卷积后得到融合后的特征图P5。以此类推,可得到融合特征图P4、P3、P2。C5输出的特征图经多次卷积后作步长(stride)为2的下采样生成P6,进一步扩大该层感受野,以生成大尺寸锚框用来预测大尺寸的物体。
原Faster R-CNN中区域建议网络的Anchor生成器在单尺度特征图每个位置上生成9种不同长宽比和面积的目标框(anchor),其尺寸包含三种长宽 比(1∶1,1∶2,2∶1)和 三 种 面 积(1282,2562,5122)。加入FPN后将多种尺度的特征图送入RPN,由于特征图本身具有不同的尺度,anchor生成器只需生成三种不同长宽比的锚框,在不同尺度的特征图上生成锚框就能达到生成不同面积锚框的效果。
2.3 候选区域映射
原始的候选区域映射到特征图中进行切图的操作在单张特征图上进行,引入FPN结构后得到若干不同尺度的特征图。根据候选区域面积相对原图的比例与特征图对应原图的缩放比例对两者进行匹配,以确定候选区域应在何种尺度的特征图上切图。具体匹配规则见式(1):

k表示使用哪一层特征图进行切图;backbone为ResNet的Faster R-CNN网络中将C4作为单尺度特征图,故k0为4;w、h分别为单个候选区域对于原图尺寸的宽和高;s代表输入图片的面积。由式(1)可知,候选区域面积越小时,使用越浅层的特征图;反之候选区域面积越大,使用越深层的特征图。符合特征融合的核心思想,即浅层特征图(分辨率高、感受野小)关注图像细节信息,更适用于弱小目标的检测;深层特征图(分辨率低、感受野大)关注图像整体语义信息,适用于大目标的检测。
3 实验结果与分析
3.1 实验环境
为验证网络有效性,本文实验运行及训练基于Ubuntu20.04操作系统,实验硬件环境包括:CPU为AMD®Ryzen 5 4600h,运行内存为16GB,GPU为NVIDIA RTX 2060,显存为6GB。编译环境为pytorch1.6.0、torchvision-0.7.0,CUDA10.0、cudnn 7.6.5。本文采用BDD100K数据集进行训练并验证模型效果。BDD100K[16]是伯克利大学于2018年发布的公开驾驶数据集,其中包含道路目标标注的图片共十万张,训练、测试和验证集的比例为7∶2∶1。标注信息包括物体类别、大小(标注框的左上及右下角坐标、宽度和高度)等信息。数据集中物体的标签类别包括person,rider,car,bus等十类目标。
3.2 数据分析及预处理
由于BDD100K官方未给出测试集两万张图片的标注文件,本文对训练集7万、验证集1万张图片做数据清洗后得到训练样本69856张、测试样本1万张。Faster R-CNN作为两阶段目标检测算法,先将特征图送入区域建议网络生成前后景分类以及边框回归值,结合anchor生成器生成检测框(先验框)。而后将先验框传入后续网络进行分类及回归并输出结果。一般认为,增加先验框的数量,丰富框的长宽比及尺寸,使其与真实标签相匹配才能达到更好的检测效果。尝试对数据集标签的面积、长宽比数据进行分析,选取出合适的anchor使得其与小目标的匹配度更高,从而提升Faster R-CNN的检测精度[17]。如图3所示,对训练集标注框的面积与长宽比进行分析。经计算长宽比在0.5~2之间的标注框占比75.9%,而面积在82与1282之间的标注框占比89.7%。故标注框的长宽比大多集中在0.5~2之间,面积集中在82~1282之间。

图3 训练集标签长宽比及面积分布
3.3 不同anchor参数下的性能对比
默认anchor参数:Faster R-CNN中anchor基础尺寸为16×16,经过默认的缩放倍数[8,16,32]后anchor面积为[1282,2562,5122],默认长宽比为[0.5,1,2]。根据3.2节对数据集标签的分析,修改设置anchor的缩放倍数为[2,4,8,16,32];长宽比不变,仍为[0.5,1,2]。Faster R-CNN特征提取网络分别采用VGG16和ResNet50时在不同anchor参数下在测试集上进行实验,采用平均精准度mAP[18]量化模型的综合性能。如表1所示,其中VGG16+尺度[1282,2562,5122]、VGG16+尺度[322,642,1282,2562,5122]、Res50+尺度[1282,2562,5122]、Res50+尺度[322,642,1282,2562,5122]分别对应表1中①、②、③、④,IoU阈值均设为0.5。
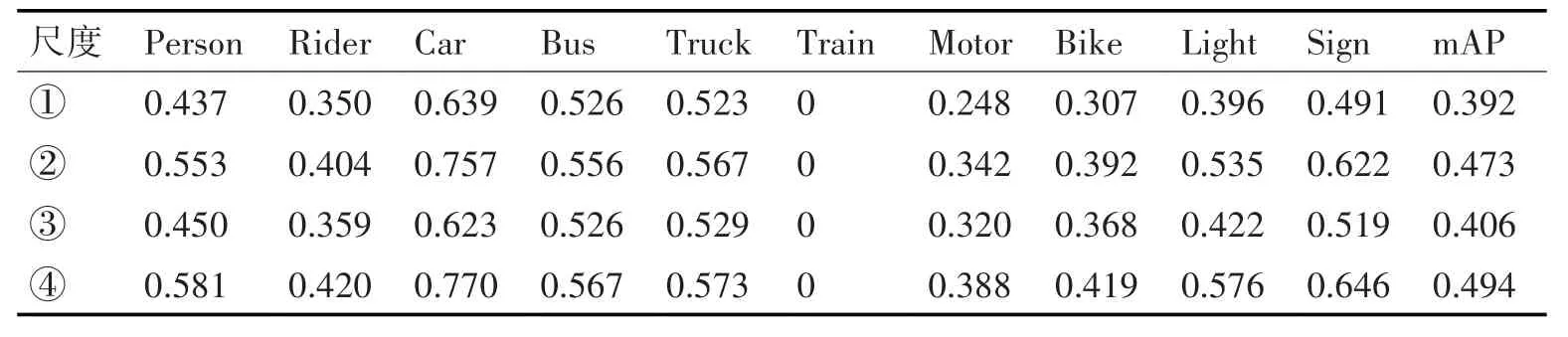
表1 不同Anchor尺度下各类别目标AP及mAP
默认anchor参数下backbone设置为VGG16和ResNet50的mAP分别为0.392、0.406。而采用anchor缩放倍数为[2,4,8,16,32]时mAP分别提升了8%和8.8%,这说明提升anchor与数据集标签尺寸的匹配度能有效增强检测效果。修改anchor参数后表中各类别AP得分均有提升,对比VGG16与ResNet50,汽车分别提高11.8%和13.1%、交通灯提高13.9%和15.4%,交通标志提高13.1%和12.7%。说明添加小尺寸anchor使得模型更加匹配数据集标签并有效地提升检测精度,在后续的实验改进中依旧采用[2,4,8,16,32]的anchor缩放倍数进行实验。
3.4 不同网络结构的性能对比
分别采用VGG16、ResNet50、ResNet50+FPN作为Faster R-CNN的特征提取模块,测试其在BDD100K验证集下的检测精度。具体实验结果见表2。

表2 不同网络结构下各类别目标AP及mAP
由图4可知,相对于VGG16网络,ResNet50网络的mAP提高了2.1%,说明更深层的特征提取网络能有效提升模型检测精度;而在ResNet50网络基础上添加特征融合结构后,融合特征层既包含浅层特征丰富的图像纹理、边缘等细节信息,又包含深层特征的语义信息;mAP提高了4.9%,各类别的AP得分均有不同程度的提升,说明特征融合能有效提升网络整体性能。

图4 不同网络结构的mAP
查看表2中具体类别的得分变化,加深特征提取网络层后AP提升0.6%~4.1%,其中大型目标(卡车)提升幅度较小,小目标(交通灯)提升幅度较大。加入特征融合后各类别AP值提高了1.9%~8.8%,弱小目标的检测精度有明显提高。在多项测试中train类别物体检测结果AP得分为0,数据集中目标类“train”样本数极少(87张),说明样本数量过少导致模型难以学习该类别特征,故检测效果差。观察表2,模型对于图片中出现频率最高的car检测精确率最高,而对于出现频次较少的类别(如Bike、Motor等)检测精确率偏低。
3.5 检测速度对比
表3对比了特征提取模块分别为VGG16、ResNet50时采用不同anchor与ResNet50+FPN模型的检测速度。检测指标为FPS(Frames Per Second),即每秒检测帧率,数值越大说明模型实时性越好。查看具体数值,添加小尺寸anchor后检测帧率稍有下降(0.3FPS~0.8FPS)。因为RPN阶段生成的anchor会经过阈值检测后过滤,训练时anchor数并不会大幅增加,说明增加anchor数量几乎不会影响检测速度。加入FPN结构后检测速度相比原基于ResNet50的Faster R-CNN模型有所下降(0.9FPS),这是因为在多个特征层进行特征提取增加了计算量,随之提高了模型运行时间。检测速度略有下降,处在可接受的范围内,anchor尺寸的修改和FPN模块的加入使得模型检测精度得到明显提升。

表3 不同网络结构下检测速度
3.6 结果展示
分别使用VGG16、ResNet50和ResNet50+FPN算法对行驶道路图片进行识别,各算法检测结果对应图5第1、2、3列。如图所示(图片均放大400%),第一张图片中目标物很远,大多为弱小目标;第二张图片中目标物的背景复杂、遮挡严重;第三张图片光线复杂,小目标较多。第一列VGG16算法对弱小目标漏检严重,对于被遮挡物体,只能识别出物体的部分区域,且会误检背景复杂的目标,检测准确度最低。第二列ResNet50算法对于小目标仍有漏检(第1、2、3行图中的汽车、行人和交通标志),但数量较少,误检的情况也得到改善,检测精度有一定的提升。第三列Res50Net+FPN算法,图片中几乎没有漏检、误检,检测精度提升明显。

图5 不同网络结构的检测结果
4 结语
本文提出了一种多尺度Faster R-CNN算法,用于道路场景多类别目标的检测。在原Faster R-CNN的基础上,引入特征金字塔结构融合不同特征层以提高小目标检测精度;根据道路目标的尺度分布特点重新设计锚框尺度以提升锚框与目标的匹配度,使用更深层的特征提取网络ResNet50代替VGG16,加深网络深度以提高网络整体性能。在BDD100K公开驾驶数据集上进行实验,结果表明加深网络深度检测性能有一定的提升,重新设计anchor尺寸后平均准确度提升8.8%,引入特征金字塔后平均精确度再提升4.9%。模型仅对特征提取和锚框匹配方面做了优化,后续工作是缓解数据集中类别间样本数量不均衡问题,提升小样本类别的检测精度。
