基于图注意力网络表示学习的协同过滤推荐算法①
2022-05-10刘锦涛谢颖华
刘锦涛,谢颖华
(东华大学 信息科学与技术学院,上海 201620)
推荐系统中用户已交互的项目相对于系统中的所有项目来说是冰山一角,这导致用户-项目交互矩阵的元素极度稀疏,而协同过滤推荐算法是根据交互数据分析用户潜在的兴趣和需求来为用户提供个性化的资源推荐服务[1].由于传统的协同过滤算法没有充分利用辅助信息,当数据稀疏时,对用户和项目的信息提取能力有限,相似度的计算不够准确,无法准确地建立用户的偏好模型.因此缓解数据稀疏问题一直以来都是推荐算法研究的重点.
随着深度学习的发展,使用深度学习方法缓解推荐系统的数据稀疏问题得到了广泛研究[2-4].基于深度学习的推荐模型主要是利用矩阵分解思想或网络表示学习方法来得到用户和项目的嵌入特征向量,然后将学习到的用户和项目的嵌入特征向量通过深度学习方法获得推荐结果[5-8].如何向南等人考虑到内积运算对传统矩阵分解模型表达能力的限制,将广义矩阵分解模型和多层感知机模型进行融合,提出了神经协同过滤模型[9].李同欢等人考虑到在不同维度空间中用户和项目的潜向量表示的意义不同,在隐藏层设计了一种多交互的网络结构,即利用塔式结构的神经传播网络学习不同维度空间中用户和项目的潜向量表示,并通过内积操作表示每一层用户潜向量和项目潜向量的交互结果,最后综合所有的交互结果作为最终的预测结果[10].
随着图神经网络研究的发展,将网络表示学习方法运用到推荐系统中成为推荐领域研究的热点.如Alibaba 的商品推荐系统根据用户的行为历史构建项目图,然后通过带权重边信息的图嵌入模型学习图中所有项目的嵌入表示,项目嵌入表示用于计算项目之间的成对相似性,并将其用于推荐过程[11].刘峰等人提出的基于网络表示学习与深度学习的推荐算法使用无监督的GraphSAGE 算法在用户图和项目图上学习节点的网络嵌入表示,并通过外积建模嵌入向量间的交互关系以作为后续卷积网络推荐模型的输入[12].Shi 等人提出的基于异构网络嵌入的推荐模型通过设计一种基于元路径的随机游走策略,为网络嵌入生成元路径相关的节点序列,然后根据由节点序列确定的邻域来学习节点的相关元路径嵌入,并通过融合函数对学习到的元路径嵌入进行聚合,最后将聚合后的节点嵌入集成到扩展的矩阵分解模型中[13].
本文考虑到不同邻居节点的属性信息不同,对学习目标节点的嵌入表示应该有不同的贡献.图注意力模型通过注意力机制获得邻居节点的注意力权重,并按权重聚合邻居节点的特征,从而可以更准确地学习目标节点的嵌入表示.因此,本文设计了一种基于图注意力网络表示学习的推荐模型,该模型通过图注意力网络学习用户和项目的网络嵌入表示,并用其改善传统的基于模型的协同过滤算法的推荐性能.
1 相关知识
1.1 神经网络矩阵分解模型
矩阵分解模型(matrix factorization,MF)是将用户-项目交互矩阵分解成用户潜特征矩阵与项目潜特征矩阵相乘的形式[14].用pu和qi分别表示用户u和项目i的潜特征向量,对pu和qi进行内积运算得到用户对项目预测得分.

K表示用户和项目潜向量的维度大小.从式(1)可以看出,矩阵分解使用潜向量内积作为用户和项目的交互结果,并假设维度之间特征彼此独立且权重相等.但在实际中,用户和项目的潜特征向量的各个维度之间可能不是彼此独立的,并且每个维度的特征权重也有所不同,简单的线性叠加限制了模型的表征能力.因此,在矩阵分解的基础上,有学者提出了其广义的神经网络实现.
从图1 中可以看到,神经网络实现的广义矩阵分解模型(generalized matrix factorization,GMF)将用户和项目的One-hot 编码作为模型的输入,通过嵌入层将用户和项目的稀疏输入向量映射为稠密的潜特征向量,接着在矩阵分解层对用户和项目的潜特征向量进行对应元素积操作,最后通过一层全连接操作得到模型最终的预测得分.
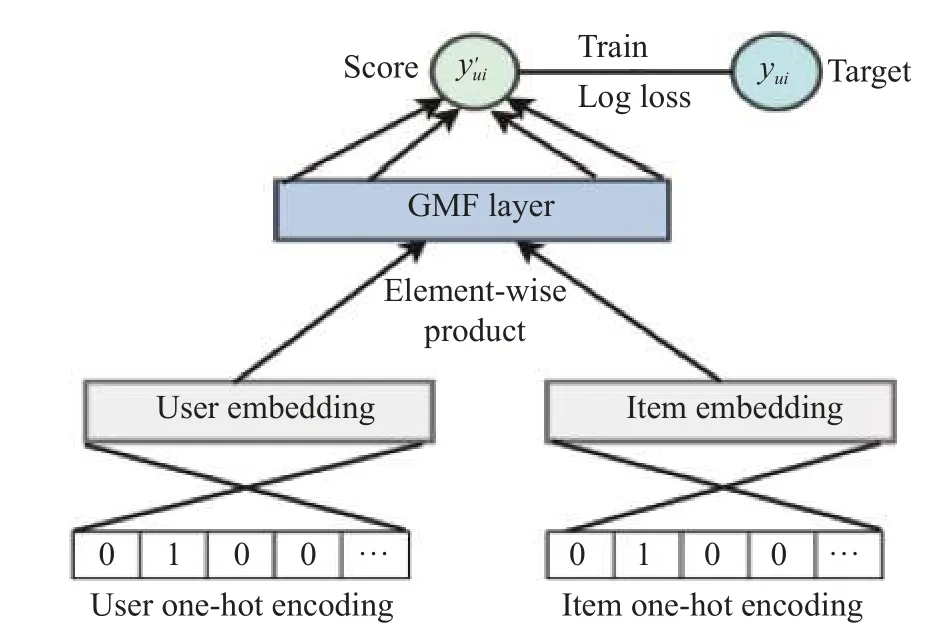
图1 广义矩阵分解模型
1.2 图注意力网络
图注意力网络(graph attention network,GAT)将注意力机制引入到基于空间域的图神经网络中[15],优化了基于频谱域的图卷积网络不能处理动态图和不能表示邻居节点重要性程度的缺陷.GAT 通过聚合邻居节点的特征来更新目标节点的特征表示,不需要使用依赖完整的图的结构的拉普拉斯矩阵,提高了模型的泛化能力,并且通过注意力机制,GAT 可以为每个邻居节点学习不同的注意力权重,实现对邻居节点特征的有效聚合以提高对目标节点的特征提取能力.
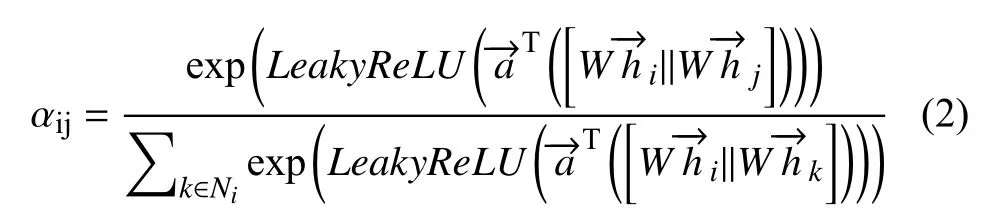
不同邻居节点的重要性不同,对目标节点特征表示的贡献也不同.GAT 通过计算注意力权重来区分邻居节点的重要程度,并聚合按不同注意力权重缩放后的邻居节点特征表示得到更新后的目标节点特征表示计算公式如下:
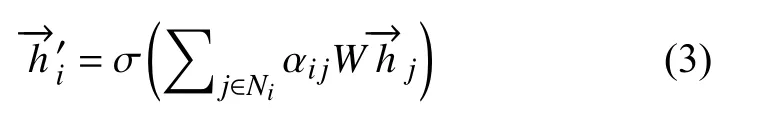
GAT 可以使用多头注意力机制从不同方面学习节点的特征表示,丰富模型的数据表达能力并稳定学习过程.多头注意力机制是指通过多个独立的注意力机制执行式(3)的转换,从而获得目标节点的多个不同特征表示.考虑到每个注意力机制的学习能力不同,学习到的特征表示的意义也不同,多头注意力机制的输出有两种组合方式,一是连接(Concatenation),二是均值(Average).
Concatenation:
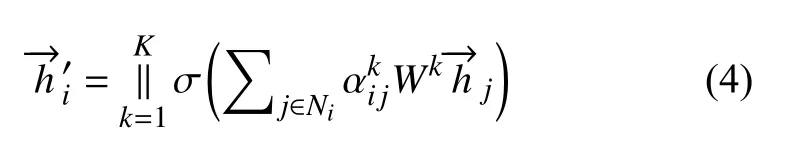
Average:
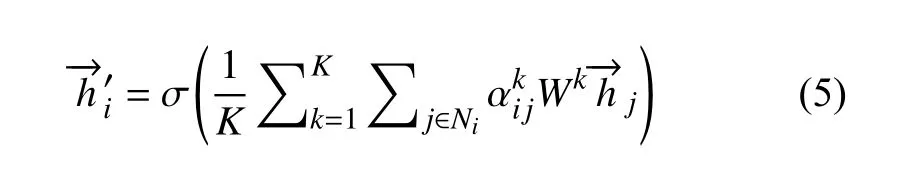
式(4)为连接组合方式,将多头注意力机制获得的多个特征表示直接连接起来,这种组合方式会增加特征的维度.式(5)为均值组合方式,对多头注意力机制获得的多个特征表示取平均值.
2 基于图注意力网络表示学习的协同过滤推荐算法
知识图谱可以通过结合辅助信息和交互数据来更加立体地展现用户和项目之间复杂的关系结构,而传统的基于模型的协同过滤推荐算法根据用户与项目之间的交互信息来优化模型参数,学习用户与项目的潜向量表示,对用户和项目的信息提取能力有限,没有考虑到用户与用户之间以及项目与项目之间的关系结构信息,这些信息可以在一定程度上对推荐提供有用的帮助.网络表示学习方法在处理图谱数据上有着很大优势,可以通过提取图中重要的网络结构特征和节点属性特征,学习图中节点的嵌入表示.因此,本文提出一种基于图注意力网络表示学习的协同过滤推荐算法.算法的流程示意图如图2所示.
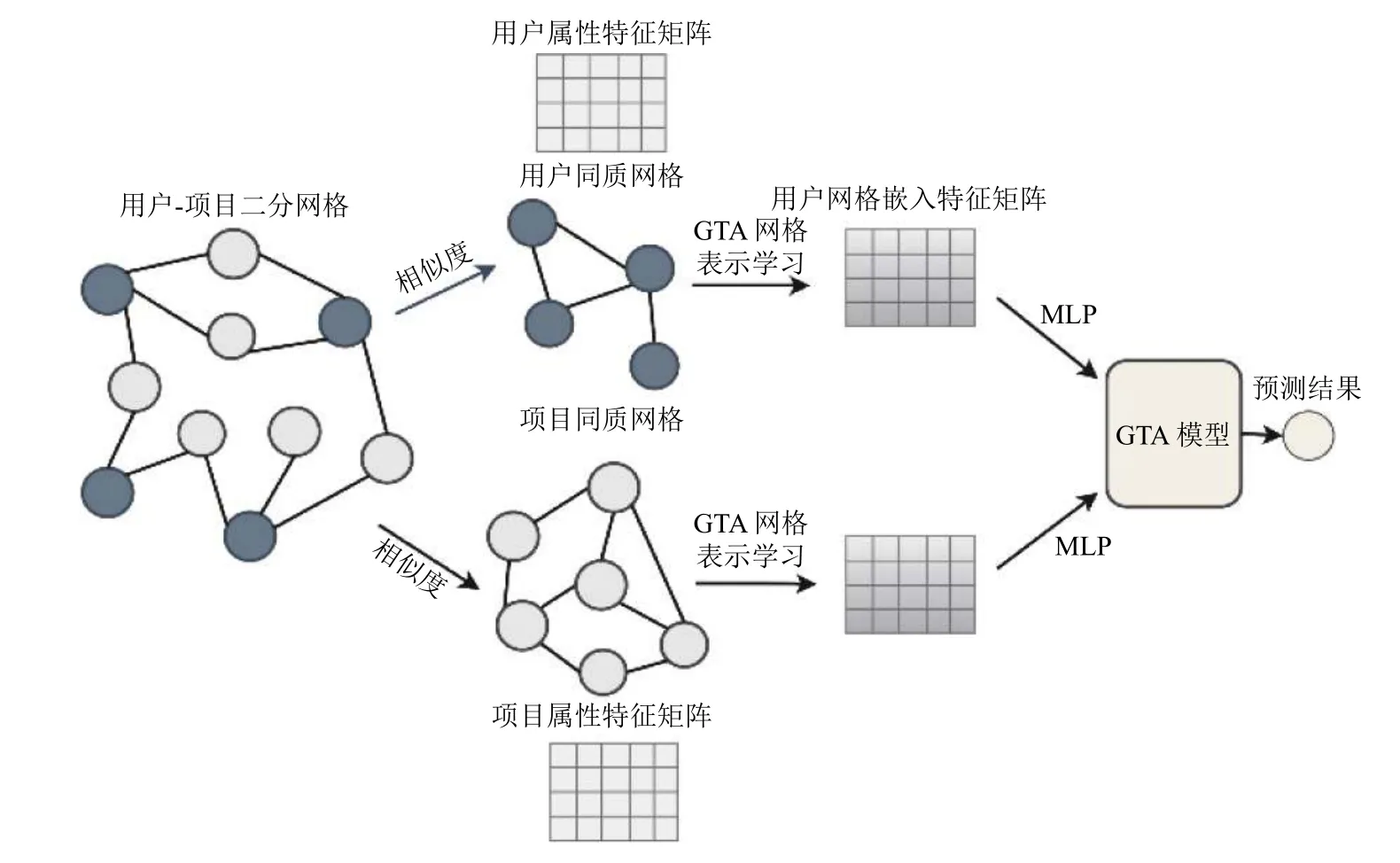
图2 算法流程示意图
本文算法的整体流程如下:首先根据用户的行为历史构建用户-项目二分网络,并由计算出的用户之间、项目之间的相似度将二分网络分解成用户与用户的同质网络以及项目与项目的同质网络.然后在同质网络上进行节点的网络表示学习,利用图注意力网络融合节点的属性信息和网络结构信息,学习用户与项目的网络嵌入特征表示.最后将用户与项目的网络嵌入信息通过多层感知机融入到广义矩阵分解模型中,综合两个部分的预测结果,构建出融合网络嵌入信息的神经矩阵分解模型.
2.1 图注意力网络信息嵌入
推荐系统收集有用户与项目之间的交互记录以及他们各自的属性信息,因此可以通过知识图谱来建模用户和项目之间的关联信息.图中有两类节点,分别表示用户和项目,节点特征为用户和项目的属性特征信息.图中有一类边,表示用户与项目的交互行为.根据这些映射构成用户-项目二分网络G=(U,V,E).用户节点集合用U={u1,u2,···,uN}表示,项目节点集合用V={v1,v2,···,vM}表示,边的集合用E表示,eij∈E表示用户和项目之间存在交互.
用户-项目二分网络是一个由用户和项目之间交互信息构建的异构网络,对于用户、项目的同质网络来说,用户-用户之间、项目-项目之间也有着各自的联系.以项目同质网络为例,不同的项目可能有着相似的受众群体,因此可以根据相似度将用户-项目二分网络分解为两个同质网络.定义用户节点之间和项目节点之间的相似度计算公式如下:
用户相似度:
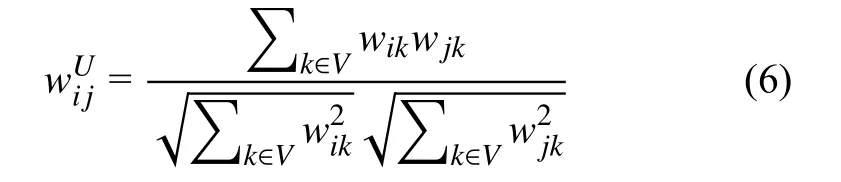
项目相似度:

其中,wij对应边eij的权重,不存在边则为0.计算获得项目相似度矩阵与用户相似度矩阵接着根据WV和WU对相似度大于阈(值的)节点之间添加边,从而建立项目同质网络和用户同质图.
在用户同质网络GU和项目同质网络GV上,我们分别进行用户和项目的网络表示学习.通过图注意力网络模型学习目标节点与邻居节点之间的注意力权重,并根据权重值聚合邻居节点的特征表示来更新目标节点的嵌入特征表示.为了提高模型的数据表达能力,本文使用双头注意力机制学习节点的特征表示,并通过均值组合方式综合这两种特征表示.
用户网络嵌入表示:
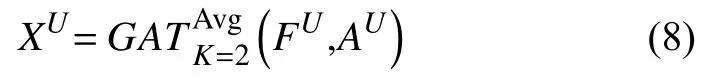
项目网络嵌入表示:
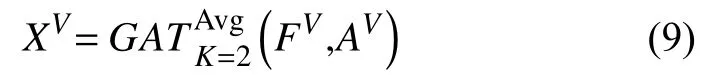
其中,FU为用户节点的属性特征矩阵,FV为项目节点的属性特征矩阵,AU为用户邻接矩阵,AV为项目邻接矩阵,为采用均值组合方式的双头图注意力网络模型,XU和XV分别为GAT网络学习的用户网络嵌入特征矩阵和项目网络嵌入特征矩阵.
网络表示学习分为无监督学习和有监督学习两种方式.无监督学习采用基于图的损失函数作为模型优化的目标函数,即希望相邻节点具有相似的嵌入特征表示,同时让相离节点的嵌入特征表示之间尽可能区分.有监督学习可以根据任务的不同来设置相应的目标函数.本文使用有监督的图注意力网络模型学习节点的嵌入表示,将节点之间的相似度作为模型训练的目标值,使用均方误差作为模型优化的目标函数.

其中,xi和xj为节点i和节点j的网络嵌入特征向量,wij表示节点之间相似度,模型学习的目标是使得节点的网络嵌入特征向量之间的夹角余弦尽可能接近计算出的相似度值.
2.2 融合网络嵌入信息的神经矩阵分解模型
MF 模型将用户和项目映射到相同的潜空间,使用潜向量间的内积作为用户和项目的交互结果,然后对用户-项目交互矩阵使用基于点的目标函数来优化模型参数,学习用户和项目的潜特征矩阵,用户或项目潜特征向量之间的夹角余弦反映出他们之间的相似性.在实际中,我们使用皮尔逊系数作为用户或项目之间的真实相似度,简单内积操作对用户和项目的信息提取能力有限,在恢复用户之间和项目之间的真实相似度上存在缺陷.因此本文通过图注意力网络模型来学习用户和项目的网络嵌入特征表示,拟合真实相似度,并将在网络表示学习中获得的用户和项目的网络嵌入信息通过多层感知机融入到广义矩阵分解模型中,构建一种融合网络嵌入信息的神经矩阵分解模型(GATNMF),缓解MF 模型存在的缺陷.GAT-NMF 网络模型如图3所示.
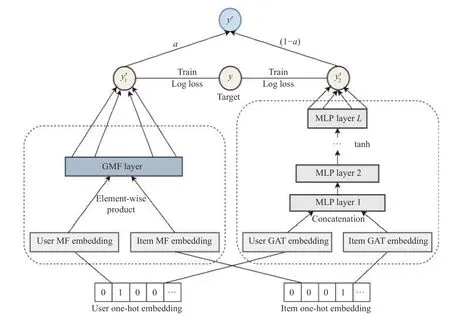
图3 融合网络嵌入信息的神经矩阵分解模型
GAT-NMF 由图注意力网络信息嵌入的多层感知机模型(GAT-MLP)和广义矩阵分解模型(GMF)这两部分组成.输入层为用户和项目的one-hot 向量.GMF的嵌入层通过单层神经网络映射得到用户和项目的潜特征矩阵.GAT-MLP 的嵌入层通过图注意力网络表示学习获得用户和项目的网络嵌入特征矩阵.
GMF 部分将用户和项目的潜特征向量进行对应元素积,最后通过权值向量映射得到预测得分.
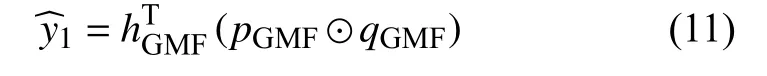
其中,pGMF表示GMF 模型的用户潜特征向量,qGMF表示GMF 模型的项目潜特征向量,⊙表示对应元素积,为全连接层的权值向量.
GAT-MLP 部分将GAT 网络学习的用户和项目的网络嵌入特征表示拼接后通过多层感知机得到预测得分,MLP 采用3 层的塔式网络结构.

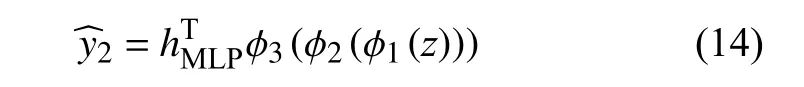
其中,pGAT表示用户的网络嵌入特征表示,qGAT表示项目的网络嵌入特征表示,Wl和bl分别表示网络层l的权重矩阵和偏差向量,为全连接层的权值向量,激活函数 σ选择tanh 函数.
使用逻辑回归中的对数似然函数作为GMF 模型和GAT-MLP 模型优化的损失函数.yui表示用户u与项目i之间的交互信息,存在交互关系为1,不存在为表示模型的预测值,表示用户与预测项目存在交互的可能性,Y表示与用户存在交互的项目集合,Y-表示在用户没有交互的项目集合中采样的负样本,在全连接层使用Sigmoid 函数将其取值范围限制在[0,1],损失函数定义如下:
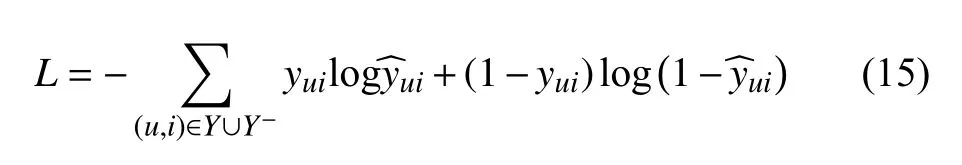
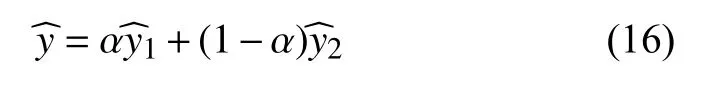
3 实验评估
3.1 实验数据集
Movielens 100 K 是提供电影推荐的数据集[16],它包含943 位用户对1 682 部电影的10 万条评分信息,以及用户的性别、年龄、职业,电影的类别、上映时间等属性信息.本文按9:1 的比例随机地将原数据集划分为训练集和测试集.
3.2 实验设置及评估指标
图注意力网络表示学习在训练时需要构建用户和项目的同质网络,因此需要根据相似度阈值确定节点的邻居节点.本文在实验中设置用户同质网络的相似度阈值为0.2,项目同质网络的相似度阈值为0.1,将相似度大于阈值的节点添加为邻居节点.在学习节点嵌入时,采样邻居节点中相似度最高的前5 个节点进行特征聚合.GAT 的其它参数设置如下:嵌入特征维度d1=32,聚合深度为1,注意力头数为2,batchSize 为512,学习率为0.000 1.
GAT-NMF 模型训练时需要扩展训练集,定义用户交互的项目构成其训练正样本,假设用户的训练正样本数为m,从其未交互的项目中随机抽取s×m个项目作为该用户的训练负样本.在测试时,对于用户的每一个正样本,同样随机抽取该用户t个负样本并与正样本一起构成一组测试样本.本文在实验中设置训练负采样系数s为4,测试负采样数t为99.GAT-NMF 的其它参数设置如下:GMF 的潜向量维度d2=32,权衡参数α=0.5,batchSize 为128,学习率为0.001.
在基于排序Top-N 的推荐系统中,推荐的质量与推荐列表中用户真正发生交互的项目数呈正相关.为验证本文算法的有效性,使用召回率与归一化折损累计增益作为评估指标.
(1)召回率
在推荐系统中,对于用户u,设R(u)为其推荐列表,T(u)为其真实交互列表.召回率为系统推荐且用户真正交互的项目在交互列表中的比值.公式如下:
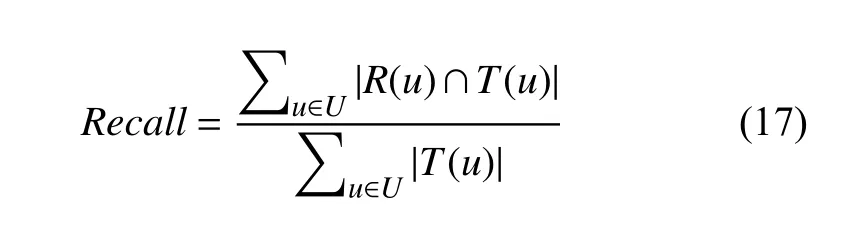
召回率值越大,推荐算法命中用户感兴趣项目的概率越大,推荐性能越优.此外召回率的大小与推荐列表的长度紧密相关,通常表示为HR@K 以表明推荐列表长度的条件设置.
(2)归一化折损累计增益(NDCG)
累计增益(CG)表示为推荐列表中的项目相关性程度的总和,缺乏对项目排序的位置因素的考量.而折损累计增益(DCG)对推荐结果在列表中的排名增加了惩罚,公式如下:
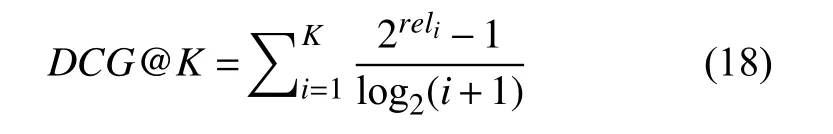
其中,reli表示位于位置i的推荐结果的相关性,若与用户存在交互关系则为1,否则为0.K为推荐列表的长度.由于评估指标衡量的是算法对整体用户的推荐效果,因此使用归一化折损累计增益(NDCG)作为推荐结果的评估指标,公式如下:

其中,IDCG为理想情况下最大DCG值,即推荐算法为某一用户返回的推荐结果为按照相关性从大到小的顺序排序的前K个结果组成的集合,也就是最优推荐列表.NDCG@K用作排序结果的评价指标,评价排序的准确性,与推荐列表的长度相关,取值范围在0~1 之间,且其值越接近于1,推荐效果越好.
3.3 实验结果与分析
3.3.1 推荐性能分析
为验证本文算法的有效性,实验选取了较为有代表性的ItemKNN[16]、GMF[9]、MLP[9]、和NeuMF[9]模型进行对比实验.
图4 显示了在Movielens 数据集中本文模型和其它几种模型在不同推荐列表长度K下召回率HR@K的对比情况.从图中可以看出,在相同的推荐列表长度下,对于无序评价指标,本文模型的召回率高于其它几种模型,其推荐的项目为用户所喜好的概率最大.且在推荐列表长度K=5 时,本文GAT-NMF 模型的召回率较NeuMF 模型提升了1.02%,较GMF 模型提升了2.21%,较MLP 模型提升了6.53%.
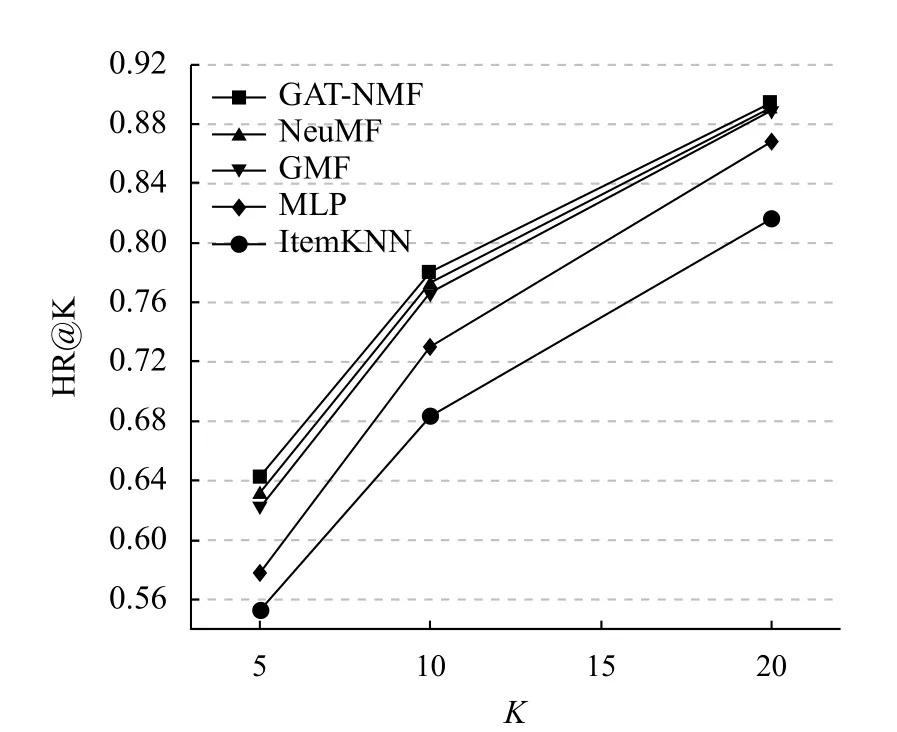
图4 HR 对比情况
图5 显示了在Movielens 数据集中本文模型和其它几种模型在不同推荐列表长度K下的归一化折损累计增益NDCG@K 的对比情况.从图中可以看出,在相同的推荐列表长度下,对于有序评价指标,本文模型的归一化折损累计增益高于其它几种模型,其推荐列表中真正为用户所喜好的项目在列表中的排序更靠前,即排序的准确性最高.且在推荐列表长度K=5 时,本文GAT-NMF 模型的归一化折损累计增益较NeuMF模型提升了1.26%,较GMF 模型提升了2.17%,较MLP 模型提升了6.11%.
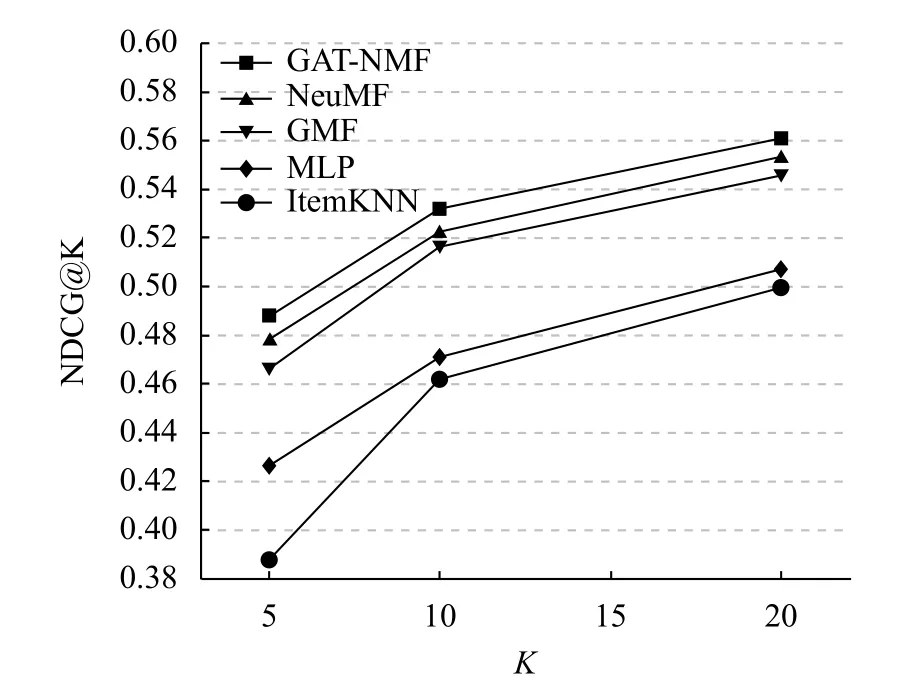
图5 NDCG 对比情况
此外,实验还将本文GAT-MLP 模型和MLP 模型的推荐性能随迭代次数的变化情况进行了对比,推荐列表长度设置为10,实验结果如图6、图7所示.

图7 NDCG 的迭代次数对比实验
图6 显示了本文GAT-MLP 模型和MLP 模型的召回率随迭代次数的变化情况.从图6 中可以看出,经过图注意力网络表示学习的GAT-MLP 模型的召回率高于MLP 模型,较MLP 模型提升了2.18%,并且GAT-MLP 模型的收敛速度也快于MLP 模型.

图6 HR 的迭代次数对比实验
图7 显示了本文GAT-MLP 模型和MLP 模型的归一化折损累计增益随迭代次数的变化情况.从图7中可以看出,经过图注意力网络表示学习的GAT-MLP模型的归一化折损累计增益优于MLP 模型,较MLP模型提升了2.03%.
表1 显示了本文算法GAT-NMF 和其它几种算法在不同推荐列表长度K下的HR@K 和NDCG@K 的具体得分情况.
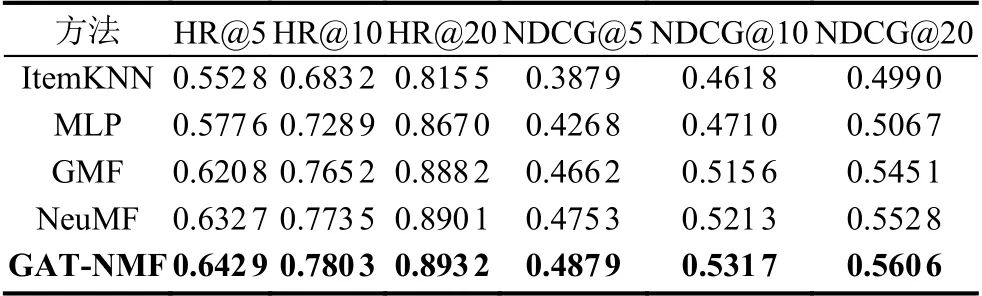
表1 Movielens 数据集对比实验结果
4 总结与展望
传统的基于模型的协同过滤推荐算法根据用户与项目之间的交互信息来学习用户与项目的潜特征矩阵,使用潜向量间的内积表示用户和项目的发生交互的可能性,没有考虑到用户与用户之间以及项目与项目之间的关系结构信息,对用户和项目的信息提取能力有限,在恢复用户之间和项目之间真实相似度上存在缺陷.因此本文使用知识图谱来表示用户与项目之间的复杂关系结构,根据用户-项目二分网络计算用户之间、项目之间的相似度来构建用户与项目的同质网络,并在各自的同质网络上进行节点的图注意力网络表示学习,最后构建融合网络嵌入信息的神经矩阵分解模型获得推荐结果.与相关算法进行对比实验,本文算法提高了推荐的HR@K 和NDCG@K.
