基于多智能体强化学习的无人机群室内辅助救援①
2022-05-10郭天昊岳文渊郭大波
郭天昊,张 钢,岳文渊,王 倩,郭大波
(山西大学 物理电子工程学院,太原 030006)
无人机具有易于部署,灵活性高以及制造成本低等优势,常被用来部署在各种民用场景中,其中包括精准农业,清理海洋废弃物,包裹投递,自然灾害后恢复网络服务以及搜索与搜救[1–5].基于无人机的灾后搜救也由之前的单机式搜救逐渐发展到小型的多机群式搜救[6],大幅度提高了搜救效率.
在早期,无人机辅助搜救的目标多是针对目标位置已知的情况[7–9],无人机只需要规划飞行路线抵达目标所在位置即可.实际搜救过程中在搜索目标之前对于任务区域的信息知之甚少,复杂的室内环境对于无人机的避障能力提出了巨大的挑战.如何使无人机群对环境无任何先验知识的前提下进行自主决策是个值得研究的问题.为此,文献[10]将基于模型的强化学习算法应用到无人机的自主导航领域,极大提高了无人机自主决策能力.在无人机最佳路径规划方向,文献[11]考虑了奖励与惩罚机制,使得无人机在不断地尝试飞行中选择最佳路径从而到达目标位置.考虑到无人机在复杂环境中状态值爆炸式的增多,为解决大容量的状态值问题,文献[12]提出了基于神经网络的分布式DQN算法,以控制无人机在未知环境中进行目标搜索与目标跟踪.针对大规模的搜索环境,需要多台无人机设备进行协作完成搜索任务,文献[13]提出一种异构多智能体算法,以控制多台无人机在复杂的环境中以协作的方式最大程度上完成搜索任务.
为组织合作的、智能的、适应复杂环境下的无人机群,本文提出了一种基于多智能体强化学习的控制策略.首先将多无人机搜救任务进行建模处理,将其转化为具有完全回报函数的分散的部分可观的马尔可夫决策过程;其次提出了基于集中学习分散执行的多智能体强化学习方法,利用了Double-DQN 算法对Dec-POMDP 进行了求解;最后利用蒙特卡洛方法对本方案进行通用性测试.结果表明本文方案在搜救成功率方面所具备的优势,能够在大型的救援环境中出色的完成搜救任务.
1 问题概述与系统模型
1.1 问题概述
本文考虑了这样一个场景,某大型图书馆发生火灾,无人机群进入图书馆以协作的方式迅速对馆内受害人员进行搜索.具体地,无人机群的搜索任务环境如图1所示.该图模拟了复杂的室内环境,为简化训练模型,假设无人机飞行过程中高度恒定为h(不包括起飞与降落操作),飞行速度恒定为V.受害者的手机可作为其位置信息传感器随时发出其位置信息,其通信模式为:无人机通过发射一种激活信号,受害者持有的终端设备接受此信号后通过反向散射(back scatter)方式向无人机发送位置数据[14],由于每个手机设备反射功率的不同会导致无人机只有在一定范围内才能采集位置信息.
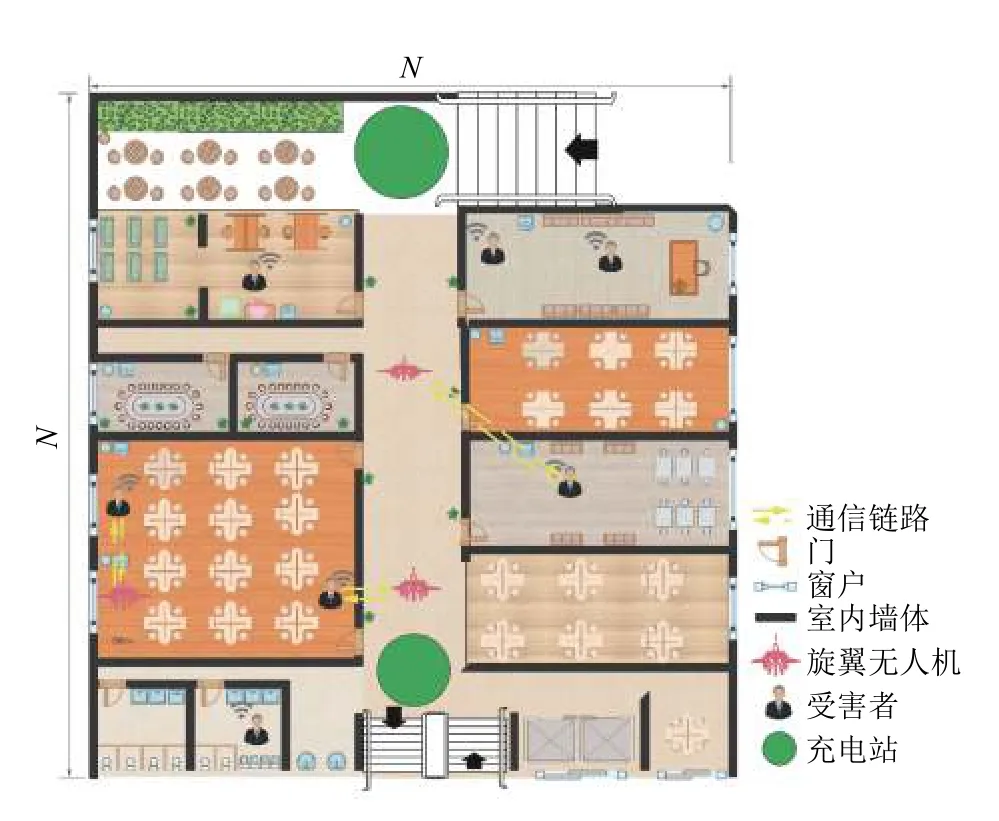
图1 无人机室内搜救模型
任务区域内随机布置了3 台无人机与7 名位置随机的受害者.无人机从停机坪(充电站位置)出发后,分别对受害者位置信息进行采集,受限于电池容量的影响,无人机群须在电量耗尽之前返航到充电站位置进行充电操作,对于没能在电量耗尽之前安全返航进行充电操作的所提方案将其作为惩罚加入奖励函数中.
为将地图进行合理的建模,本方案将地图分割为N×N的网格模型,定义整个室内区域为M:M×M∈N2,将M区域分割为尺寸大小为n的32×32 网格.定义无人充电位置区域Z ∈{[xZi,yZi]T,i=1,···,N},将所有窗户位置定义为禁飞区域 C ∈{[xCi,yCi],i=1,···,N},避免由于窗户处于打开状态而导致无人机从窗户飞到室外无形中将搜索区域扩展为无限大.将墙体与门所在位置定义为障碍物区域 N={[xNi,yNi],i=1,···,N},无人机在飞行过程中要绝对避免的区域.
1.2 信道模型
在本文中,所提方案考虑到现实场景,将无人机与受害者之间的通信链路建模为视距(line of sight,LOS)与非视距(none-line of sight,NLOS)的点对点信道模型[15],在该信道模型下本文定义在时间为n,第j位受害者能够达到的信息速率为:
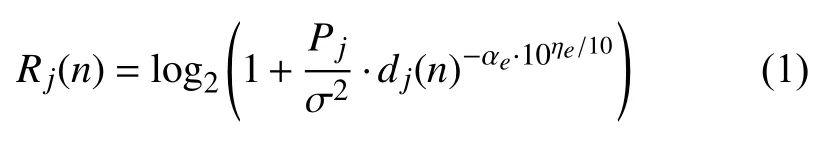
其中,Pj为发射功率,σ2为接受机处的高斯白噪声的功率,αe与 ηe为信号在无人机与受害者之间的传播路径损耗指数,其中e∈{LOS,NLOS},具体与环境有关,主要来自视距损耗或者非视距损耗.dj(n)为无人机距离受害者的直线距离.
1.3 系统模型
本系统模型的主要研究目标是使得无人机团队在一定约束条件下能够最大化的从搜救区域中搜集受害者的位置信息.这些约束条件主要分为两部分,一部分来自无人机设备自身的条件约束,例如电池容量.另一部分来自环境对无人机设备的约束.例如室内门墙等障碍物、无人机与无人机之间避免碰撞以及无人机的起落位置(充电位置).
对无人机群进行建模,定义第i台无人机的位置为pi(t)=[xi(t),yi(t),zi(t)]T,为简化模型假设无人机的飞行高度为zi(t)∈{0,h}即无人机的高度位置只能为地面0 或者以h的高度恒定飞行.在本模型中无人机的动作空间受限于其所处环境的位置,无人机只有在充电区域时才能执行着陆充电动作.动作空间定义为:
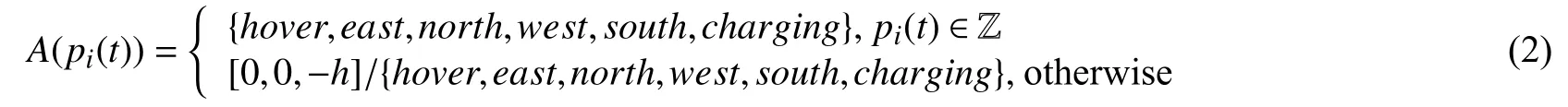
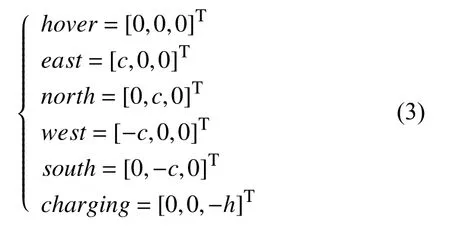
第i台无人机在t时刻的动作为ai(t),其中,ai(t)∈A(pi(t)).
无人机t时刻的飞行状态为λi(t)∈{0,1},0 表示无人机处于静止状态,1 表示无人机处于运动状态.值得注意的是当无人机处于充电状态时,运动状态变为非运动状态.定义无人机的下一状态为:
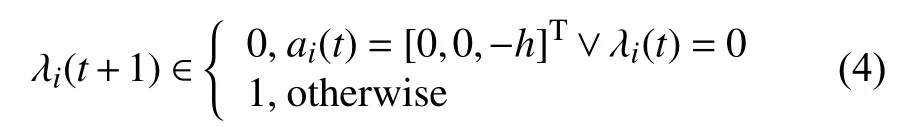
对于本模型中的无人机剩余电量,第i台无人机在t时刻剩余电量为Ei(t).假设无人机运动时消耗的电量始终恒定,此时可以直接将剩余电量等价于此无人机的剩余飞行时间.由于耗电量主要由运行状态决定,为此无人机的下一时刻的剩余电量可离散化为:
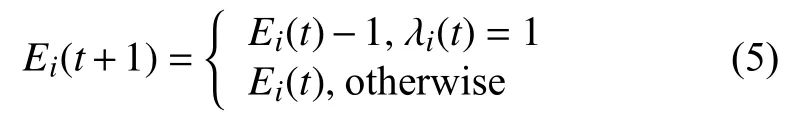
对于无人机的动作策略的优化本质上是对无人机的接收信息的吞吐量最大化,无人机群与受害者持有的设备之间通信时遵循标准的时分多址模型(TDMA),在任务时间T内,整个团队I台无人机设备在联合策略xiai(t)下的最大化吞吐量模型为:
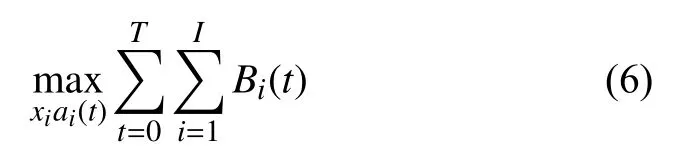

其中,n∈[βt,β(t+1)−1]表示在任务时间T内的通信时间,β为通信时隙,λi(t)为无人机的在t时刻的运行状态,qi,j(n)∈{0,1}为TDMA 模式下的调度变量.
2 多智能体强化学习
强化学习作为机器学习的一个重要分支,其核心是智能体与特定环境的重复交互,学习如何在未知环境中执行最优策略[16].在当前状态S下,智能体执行动作A,环境接收到此动作后反馈于智能体下一状态St+1和回报值R,智能体依据环境反馈的回报值来优化策略并且进行再学习,就这样通过不断地迭代最后生成最优策略.
本文针对多无人机协作问题定义了同质的、非通信的、简单合作的无人机群.同质性是指每台无人机设备具有相同的构造结构,相同的动作空间以及任务领域;非通信是指无人机之间没有直接的通信,即无人机不能协调它们的动作以及进行有关的通信,但都能感知与其他无人机之间位置信息,并可利用这种感知到的位置信息对无人机进行监管维护;简单合作是指无人机团队共同收集的位置数据可添加到每一台无人机的回报函数中,这就使得他们有一个共同的目标.在多智能体训练阶段,每台无人机与环境不断地交互进行自身的策略优化,之后将它们的经验数据集中起来,通过组建神经网络数据库来训练控制系统,最后将训练好的控制系统部署到每台无人机设备上.
2.1 部分可观的马尔可夫决策过程
本节将无人机团队与环境交互的问题转换为部分可观的马尔可夫决策过程.一个Dec-MDP 通常是由一个七元组组成(S,Ax,P,R,Ωx,O,γ),其中S代表一组空间状态值,Ax表示智能体的动作空间,P:S×A→∆(S)为状态转移概率矩阵,R:S×A×S→R为即时的奖励函数,Ωx=ΩI为一组观测结果,即无人机传感器获得的环境数据.O为条件观测概率.γ ∈[0,1]为贴现因子,表示长期回报与短期回报的重要程度.
状态(S):本模型状态空间由3 部分组成.分别为环境信息、无人机状态、受害者状态.定义状态空间为S(t)=(M,{pi(t)},{Ei(t)},λi(t),{Lj},{Dj(t)}),其中,M表示环境中的一系列位置信息集合,包括室内门窗以及墙体等障碍物的位置、无人机的起落位置以及危险区域的位置信息.{pi(t)} 表示第i台无人机的位置信息,{Ei(t)}表示第i台 无人机的剩余电量,λi(t)表示第i台无人机的运行状态,{Lj} 表示第j位受害者的位置信息,{Dj(t)} 表示第j位受害者的位置信息量.
动作(Ax):考虑到模型的复杂性,为避免无人机发生碰撞,引入符合本模型的动作状态空间,在之前的无人机动作空间模型中引入一种安全控制机制,无人机通过判断所处的环境位置来执行相应的动作,当无人机位于区域 R时,该区域包括无人机的下个位置位于障碍物区域以及两台无人机同时出现在同一种位置且处于运动状态,此时安全机制执行悬停动作.本方案定义安全动作空间如下:
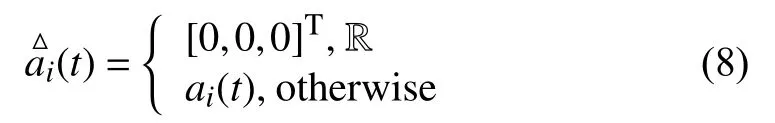
在区域 R,有:

即时奖励(R):本模型总即时奖励Ri(t)由所有无人机任务时间内搜救受害者数量的奖励、路径规划奖励、即时充电奖励3 部分组成,其中搜集所有受害者位置信息量奖励是每台无人机共享奖励的唯一部分.
t时间内收集的所有受害者的位置信息量作为集体奖励,τ为收集乘数将数据收集参数化,方法如下:
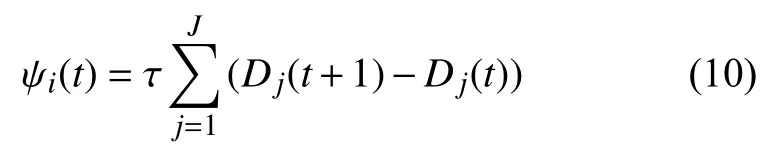
路径规划奖励主要用于惩罚无人机在飞行过程中不执行安全动作空间,为诱导无人机优化最短飞行路径来搜集受害者的位置信息,定义方法如下:
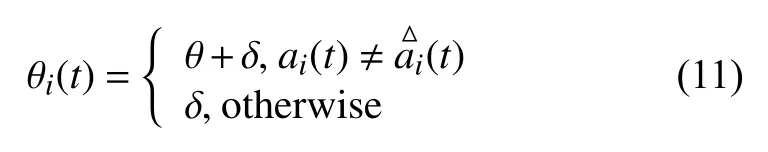
其中,当无人机的动作空间不符合安全动作空间时,给出惩罚θ,δ为持续飞行的路径惩罚,使无人机减少飞行时间优化其搜救路径.
即时充电奖励强迫无人机在电量耗尽之前返航进行充电,对于没有即时返航的无人机给予值为ω的处罚,为此定义即时充电的奖励计算如下:
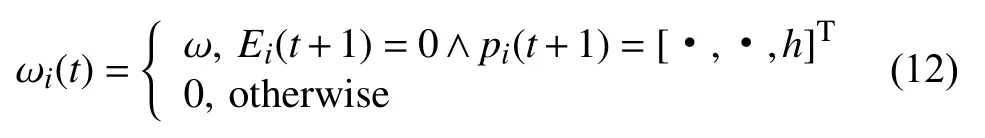
综上3 部分,总即时奖励为以上3 部分奖励之和,即:

观测结果(Ωx):本模型无人机的观测空间由室内环境M、无人机的飞行状态Oλi(t)、无人机的剩余电量OEi(t)、受害者位置信息量ODj(t)四部分组成.为简化模型,将无人机的位置与受害者位置进行2D 投影,投影函数定义如下:
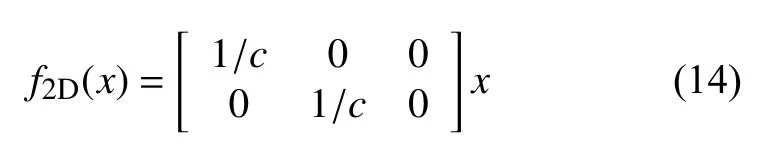
式(15)与式(16)分别将受害者与无人机的位置经过投影函数f2D(x)后所得2D 位置信息为:
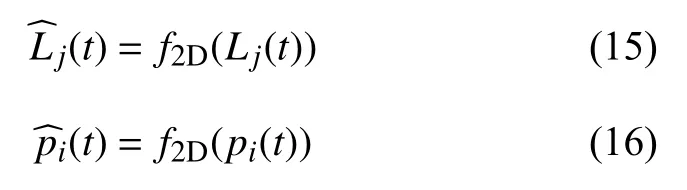
带有位置信息Plocation与该位置所对应的某一类值Qinformation映射到相对应的图层O,定义如下映射:

式(18),式(19),式(20)分别将无人机的位置信息与该位置对应的运动状态和剩余电量在映射函数fobservation下,得到其对应得图层O.
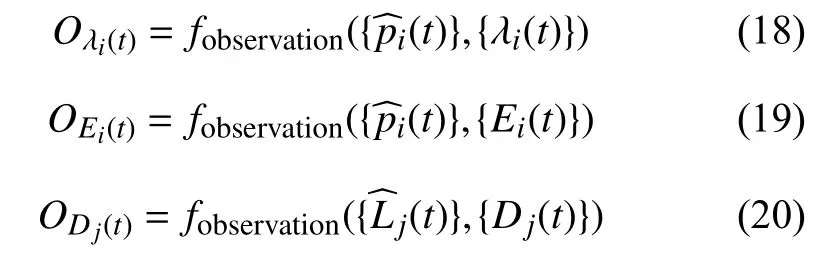
将上述所有的图层作为无人机的观测结果输入到本文神经网络架构中,式(21)为无人机的观测结果:
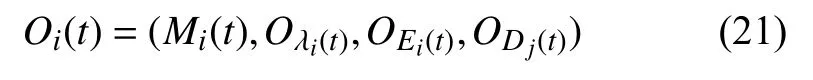
2.2 DQN 算法:
本文的无人机群在大型室内空间中执行任务,如将Q值表示为数值表格是不可取的,文献[17]应用了经验回放等方面的技术,将Q-Learning 与神经网络结合起来,完美的解决了大状态空间问题.经验池的主要功能是解决相关性与非静态分布问题,具体方法是通过将每个时刻智能体与环境交互的样本 (st,at,rt,st+1)存储于回放记忆单元,训练时在经验池中随机抽取一批数据进行训练.
DQN 算法的主要目标是保证估计值网络输出的值Q(s,a;θ)无 限接近于目标值网络输出的目标值TargetQ,其中,θ为网络参数,目标值计算方法为:
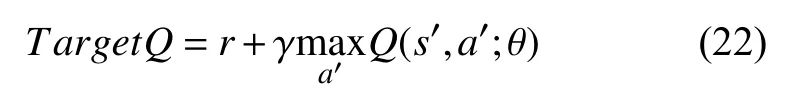
基于上述的目标值,定义DQN的损失函数公式,求L(θ) 关于θ的梯度,使用随机梯度下降算法更新网络参数θ:
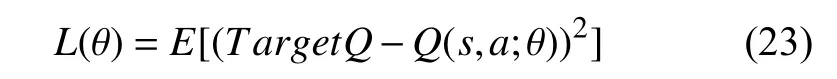
具体地,DQN 算法的流程如图2所示.
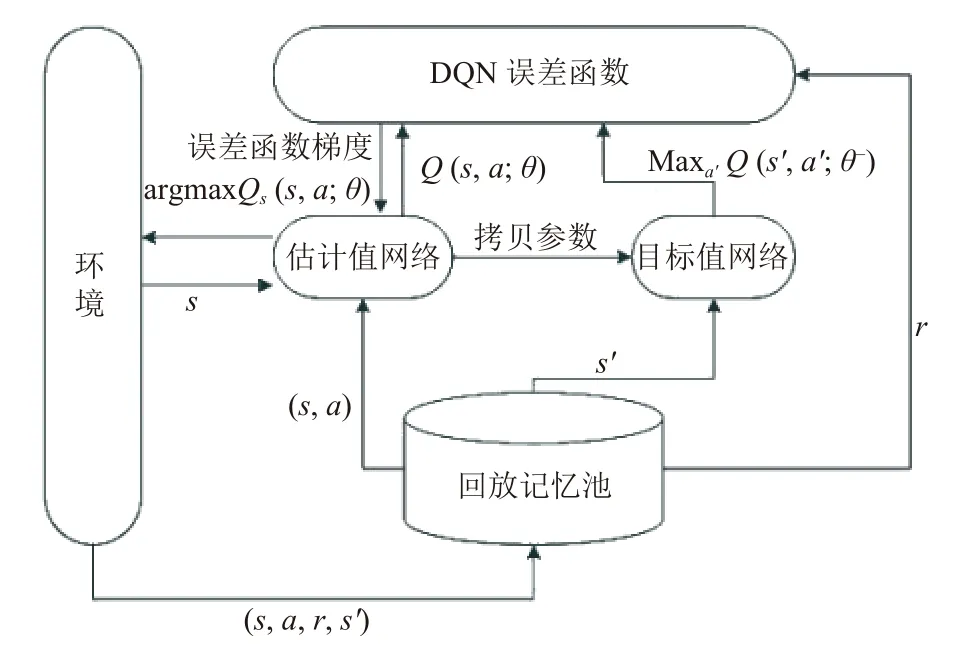
图2 DQN 算法流程图
3 无人机团队路径规划算法
3.1 Double DQN (DDQN)算法
本文利用DDQN 算法对无人机团队路径规划进行训练,不同于DQN 算法,DDQN 算法克服了QLearning 算法固有的缺陷即过估计问题,而在DQN 算法中此问题也没有得到有效解决,为解决过估计问题Double DQN 算法将动作的选择和动作的评估分别用不同的值函数来实现如图3所示,具体如下:
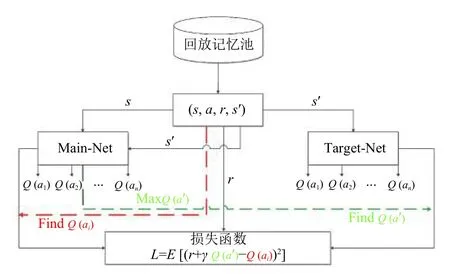
图3 DDQN 损失函数构造流程
通过网络(main-net)获得最大值函数的动作a,然后通过目标网络(target-net)获得上述动作a所对应的TargetQ值:
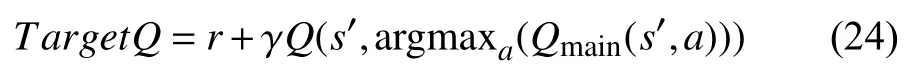
基于目标网络TargetQ值,定义DDQN的损失函数为:
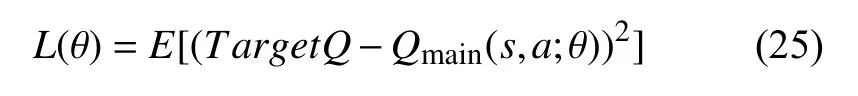
3.2 Double DQN 神经网络
如图4所示,本文构建了该神经网络架构.将上述处理的4 幅信息图层堆叠起来组成状态信息图作为观测值传入卷积核为5×5的卷积层1和2,然后通过激活函数R eLU (线性整流函数)将输出传入展平层,该层的目的是将多维的数据一维化.最后将平坦后的数据与无人机剩余飞行时间的标量连接起来经过3 个隐藏层后通过激活函数 ReLU将数据传入到一个动作空间大小为6的全连接层,最后得到在给定观测空间状态下的每个动作所对应的Q值.
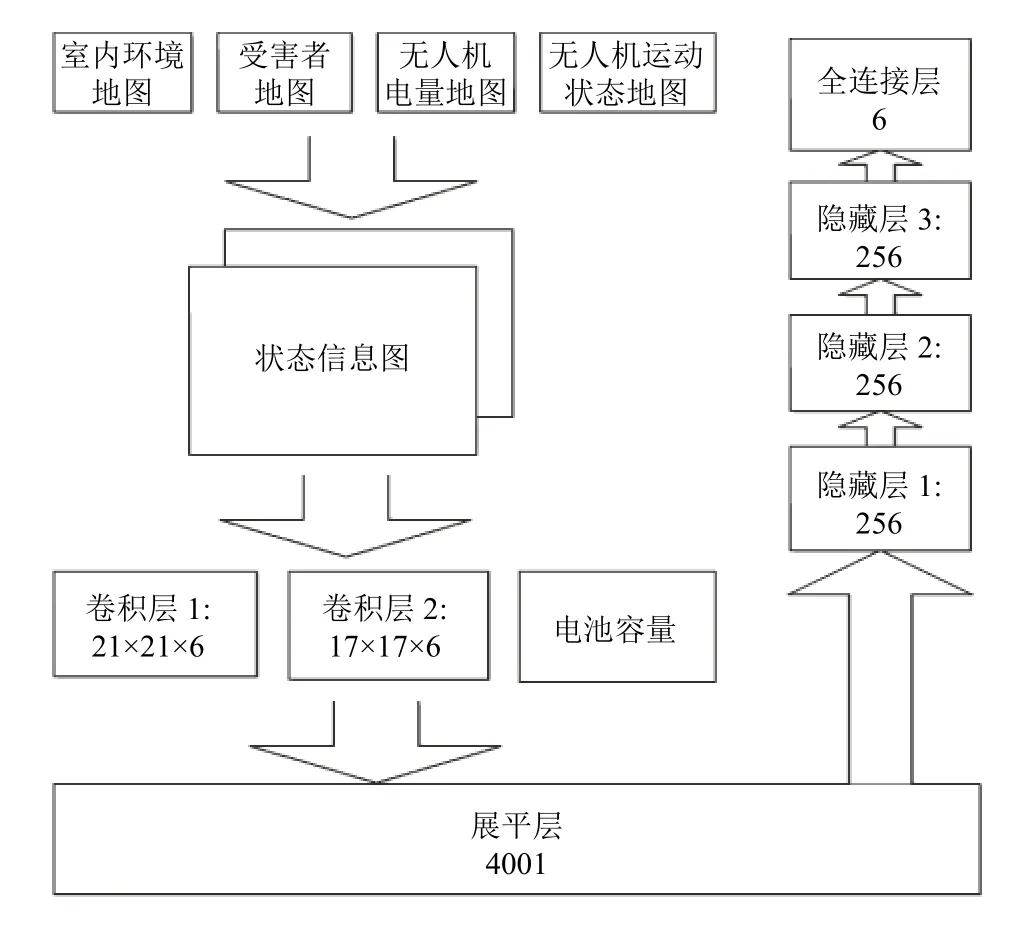
图4 神经网络架构
利用 Softmax激活函数对每个动作的Q值处理转换为相对概率P(ai|s),其中通过调节参数 β来平衡无人机的探索与利用.
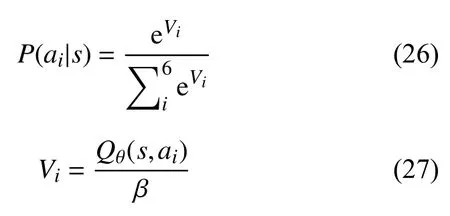
通过贪婪策略得到P(ai|s)中最大值的索引,其中,a∈A.
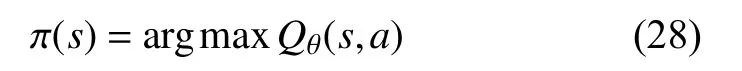
4 仿真分析
本节对所提方案进行仿真与分析,且与传统算进行对照,最后验证了本文所提方案所具备的优势.本文考虑了320 m×320 m的无人机搜索区域,无人机团队在所提方案的训练后在室内搜救路径规划如图5所示.
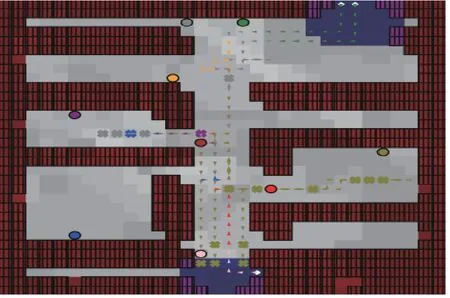
图5 无人机团队搜救路径
在该室内区域随机分布了9 位受害者,为达到较好搜救效果,本方案为其配备由3 台无人机设备组成的搜救机群.无人机的起落位置,充电站都在图5中蓝色区域.将不同的受害者用不同颜色的小圆圈表示.所飞行的路径轨迹由图5中带箭头的线段表示,不同路径颜色则代表此时的无人机正在搜集与本颜色所对应受害者的位置信息.固定其飞行高度为10 m,飞行速度为1 m/s,考虑到飞行区域为室内区域,设定路径损耗参数αLOS=2.27,αNLOS=3.64.训练仿真参数由表1给出.

表1 仿真参数设置
相比于传统方案,所提方案优势在于加入充电操作、引入多智能体、适用大状态搜救场景3 方面,为验证3 方面所具备的优势,分别使用所提方案与传统的算法对本文场景进行了无人机群的路径规划训练.经过3 000 000 次的训练迭代,所提方案使得累计回报值得到显著提升.
本文方案加入充电模块,相比于未加入此模块的传统方案训练所得的累计回报对比如图6所示.
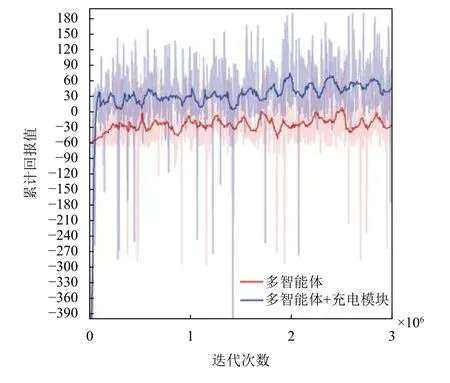
图6 两种方案的训练回报对比
在图6中,所提方案累计回报值增长较快,最终达到收敛.可以明显看出加入充电模块的回报值明显高于传统方案.这种比较说明了本文方案能够快速的适应搜救场景,且能高效的进行辅助搜救,因此本文方案更加有效.
为说明所提方案在大状态环境的适用性,将本文室内搜救场景下的受害者的数量以及部署的无人机集群规模进行逐步增大,观测其对于搜救率的影响.如图7所示,随着受害者人数的增加对同一规模集群其搜救率并没有出现明显的骤降,之所以出现下降趋势是由于在整个搜救场景中受害者的位置被随机的放置,受害者人数的增加导致无人机的碰撞概率增大最终导致无人机集群更加复杂的路径规划,因此使得搜救成功率有所下降.
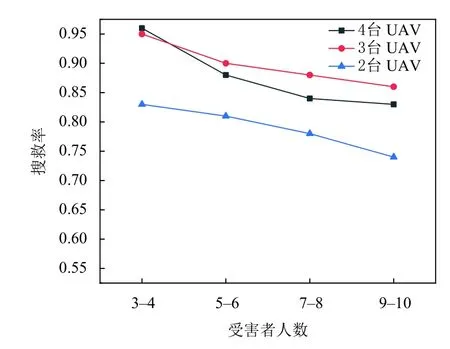
图7 所提方案对于大状态环境下的搜救率
在图7中,由2 台无人机组成的集群搜救成功率明显低于其他集群,主要原因是在大范围与复杂的搜救场景中,2 台无人集群缺乏搜索覆盖能力,存在搜索盲区导致搜救率下降.如果采取由4 台无人机组成的集群进行搜救任务,当环境中存在4 位以下受害者时能达到最佳搜救效果,然而随着受害者人数增加到5 位以上时,搜救成功率明显低于由3 台无人机组成的搜救集群.这是因为环境中存在4 位以下受害者时,由4 台无人机组成的搜救集群具有较强的搜救覆盖能力且不需要执行复杂的路径规划,受害者人数增加到5 人以上时,4 台无人机集群虽具有较强的覆盖能力,但在一定范围的搜索环境下,无人机设备数量的增多以及受害者人数的上升势必会导致复杂的路径规划,对于无人机之间的避免碰撞以及单程电池容量提出了巨大挑战.考虑到本文实际的模拟场景以及设备成本,最终选择3 台无人机作为搜救集群,并达到了最优的搜救效果.
本文对随机场景进行了1 000 次蒙特卡洛迭代,所得性能指标用于评估多智能体在搜救任务中的优势,图8可以明显看出,在搜救场景中部署多台无人机设备使得搜救成功率得到了显著提高,传统的单智能体方案在搜救区域增大时缺乏搜救覆盖能力,如其经常在某一个固定区域搜救然后直接返回着陆位置,造成其他区域位置的受害者无法得到救援,最终导致搜救能力下降.
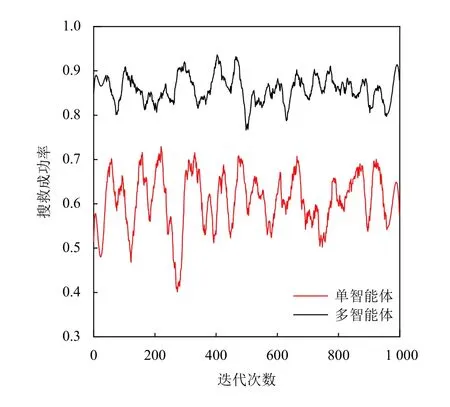
图8 多智能体与单智能体搜救率对比
5 总结
本文研究了无人机群协作进行辅助搜救的问题,搜救的区域是发生火灾的大型室内场景.为提高无人机群的搜救能力本文引入了一种多智能体强化学习方案,该方案基于DDQN 算法来优化无人机团队的飞行路径,解决了无人机群在不确定环境下的搜救问题,在搜救过程中无人机群受限于电池容量,所提方案又引入了充电模块,从而最大程度的完成对受害者位置信息的搜集.除此之外,本文还详细描述了将搜救的模型转化为部分可观的马尔可夫决策的过程.对于未来的工作,无人机速度控制以及飞行高度的扩展是重要的探索方向,这种扩展可以使无人机团队适应更为复杂的搜救场景.
