单目视觉下基于逆投影空间的车辆细粒度识别①
2022-05-10唐心瑶田尚伟梅占涛
王 伟,唐心瑶,田尚伟,梅占涛
1(长安大学 信息工程学院,西安 710064)
2(安徽科力信息产业有限责任公司,合肥 230088)
3(内蒙古第一机械集团股份有限公司,包头 014030)
在无人驾驶领域及智能交通应用中,车辆三维信息的准确获取在车辆行驶路径规划,安全行驶及车辆违规判断上都有着重要的应用[1],同时,详细的车型信息对于精确检测与统计车流[2],车辆违规处罚[3–6]等应用上都提供了基础数据支撑.因此在交通应用中,十分关注车辆的三维尺寸及车型分类信息,本文所定义的车辆细粒度即为这两类信息.
目前主流的车辆识别方法主要包括:(1)基于目标二维局部特征的方法[7–11].这类方法利用车牌、车灯、车标或车脸等信息,对输入的车辆局部特征进行传统的模型识别,获取车辆的识别结果,由于检测精度低、特征设计复杂,这类方法在实际应用中逐渐淡出视线.(2) 基于深度学习的方法,随着数据集的增加及深度学习目标检测技术的成熟,出现了一批优秀的车辆检测及分类网络,尤其以YOLO 系列[12]为典型.但(1)和(2)类方法都属于二维目标检测方法,仅能检测识别出车辆目标的存在性及粗略的型号分类,并不能获取车辆物理尺寸等相关的其他辅助信息,做不到精细化描述.(3) 基于三维目标检测的方法.与二维目标检测相比,三维目标检测能够消除图像成像的透视形变,同时能够在三维目标检测能在物理尺度上描述车辆信息,因此更加适合车辆的细粒度描述.目前基于三维的方法主要基于深度相机(RGB-D camera)[13,14],激光相机(laser camera)[15]等,而这些设备价格昂贵且数据量冗余.相比之下,单目相机(monocular camera)价格便宜维护简单,同时具有视野范围大且数据量相对较小等优势,一直是视频监控系统中的主流应用,但是由于透视形变及投影造成的信息损失,直接通过单目相机获取车辆目标的三维信息有一定的难度.综上,基于单目视觉下三维目标检测的车辆识别研究具有重要意义.
近年来,基于单目视觉的车辆三维检测算法呈上升趋势.该类算法主要基于以下两种思路:(1)基于CAD/可变模型+局部特征设计[16–18],如Zhang 等[19]提出一种基于可变模型的车辆识别方法,主要使用Hog 特征生成初始三维车辆模型,能够识别轿车,掀背车,公交车等常见的8 种车辆.Corral-Soto 等[20]也提出一种基于三维可变模型的车辆识别方法,对于拥挤高速公路下的车辆遮挡有一定的鲁棒性,该方法对车辆前景根据蒙特卡洛方法和马尔科夫链方法(MCMC)沿着车道线方向滑动模型来获取最贴合的三维模型,从而解决解决道路中的车辆相互遮挡造成的识别失效.Prokaj等[21]采用三维CAD 模型结合DPM 分类检测器的思路,通过车辆的局部特征数据训练出一个能够将二维图像和三维模型在几何与视角上进行对齐的DPM 分类检测器.该类方法在CAD 模型库过大时,存在检索速度慢等缺点,同时手工设计目标特征在深度学习流行的今天,也远远达不到理想的准确率.(2)三维包络盒+机器学习.该类方法摒弃使用CAD 模型贴合车辆目标,而采用更灵活的三维包络盒的方式进行三维检测.Zapletal 等[22]提出将车辆三维包络盒在逆投影空间中展开,继而进行训练实现精细化识别的思路,具体方法为,对于展开的逆投影空间包络面,首先利用HOG特征对于逆投影空间进行描述,然后用SVM 算法进行训练识别,获取车型识别结果.由于采用的是传统的手工特征设计,在较复杂的数据集下,该算法的识别准确率并不高,仅能达到60%.Sochor 等[23]对车辆前面,侧面和顶面的二维平面图像进行标准化展开,然后进行标注,通过深度学习训练网络的方式学习车辆类型,在一般场景中精确度高达83.2%,但该方法采用3 个互相正交的消失点的方式对车辆进行三维包络,而消失点在某些方向存在不稳定现象,因此在一定视角下该类方法对于车辆的三维检测并不稳定.
基于上述对当前算法的综述分析,采用三维包络盒+深度学习的思路开展本文研究,与当前已有的方法相比,本文的创新与贡献有:
(1)前期工作中对于交通场景构建了自标定模型,本文将基于相机自标定参数,单灭点与车辆二维投影的几何约束构建车辆精细化的三维包络.
(2)对二维车辆目标进行逆投影空间标准化展开,构建联合物理尺寸标签的损失函数,训练出更具区分性的车辆细粒度识别网络.
1 前期工作
1.1 相机标定模型建立
相机标定是获得三维世界空间与二维图像空间映射关系的必要步骤,可为后续第1.2 节中的车辆3D 包络框的构建提供依据.
如图1所示,为道路场景相机空间模型示意图,前期工作对该场景下的相机自动标定和优化问题进行了相关的研究[24],是本文的基础.
如图1所示,在此空间模型中,世界坐标系包含xyz轴,相机坐标系包含xcyczc轴,相机焦距为f,相机距离地面的高度为h,相机俯仰角和偏转角分别为ϕ和θ.将世界坐标表示为齐次形式:x=[x,y,z,1]T,则在图像坐标中对应为:p=[αu,αv,α]T,α≠0表示尺度因子.由文献[24]推导可知,世界坐标到图像坐标的投影方程为:

图1 道路场景中相机空间模型示意图

将式 (1) 展开可得直观的世界坐标至图像坐标的表示形式:

由式 (2) 可知,当给定目标高度为z0时,即可计算得图像坐标在世界坐标的逆投影.标定参数(f,h,ϕ,θ)可通过道路标识[25](如道路虚线,道路宽度等)间接求取.在多标识的约束下,还可在参数空间对于标定参数进行迭代优化.在文献[24]中有详尽的描述,此处不再赘述.由此,通过建立的相机空间标定模型,可得道路场景下世界坐标与图像坐标的投影与逆投影变换,从而获得后续构建车辆3D 包络的基础.
1.2 车辆3D 包络框粗构建
基于第1.1 节中的相机标定,可进一步构建车辆的3D 包络框,为第2 节中的包络框展开及车辆细粒度识别奠定基础.
如图2所示,为本文车辆3D 包络框粗构建的示意图.设车辆3D 包络框8 个顶点的世界坐标为Pi=(xi,yi,zi),i=1,2,…,8,图像坐标为pi=(ui,vi),i=1,2,…,8,车辆的初始尺寸为(lv,wv,hv),分别表示车辆的长度、宽度和高度,单位为m.由图1的标定模型可推导出车辆在长度、宽度和高度的方向向量分别为dl=(−sinθ,cosθ,0),dw=(cosθ,sinθ,0),dh=(0,0,1).将P2作为车辆基准点,通过式(3)可得其余7 点坐标.

图2 车辆三维包络框的粗构建

在车辆3D 框粗包络的过程中,并不能保证所有参数均准确,因此需要进一步对粗包络进行调整,得到更准确的车辆3D 包络框.
参考前期工作对于车辆空间形态优化的思路[26],将调整过程看作包络框参数的优化过程,优化参数包括(lv,wv,hv),和车辆的偏转角θv构成的车辆空间形态向量V,V1为其初始值.构造车辆投影凸包与车辆轮廓的约束算法如下,其中车辆轮廓使用Mask-RCNN[27]进行提取.

算法1.车辆3D 包络框构建优化算法1) 通过式(3)构建车辆3D 粗包络,车辆初始尺寸(lv,wv,hv) 可通过Mask-RCNN 得到的车辆类型查阅车辆外廓尺寸获取.2) 将3D 包络的8 点物理坐标代入式(2)可反求出8 个投影点并求凸包,获得某组已知 V1 对应的3D 包络投影凸包,将式(3)得到的世界坐标点通过式(2)投影至图像坐标中,获得车辆投影凸包顶点,记为{si|1≤i≤m},m为投影凸包的顶点数量.3)为了更好地构建约束,在相邻的投影凸包顶点等间隔插入v 个新顶点,则稠密投影凸包可表示为{si|1≤i≤m(v+1)}.4) 求车辆轮廓C的重心O,连接Osi 获得与 C的交点qi,得到约束误差为.m(v+1)∑i=1 siqi
图3(a)为v=4时的一组初始参数向量对应的3D 包络,图3(b)为初始投影凸包与车辆轮廓的差值,使用红色线段表示,投影凸包顶点为P1,P2,P3,P5,P7,P8.约束函数可表示为:

其中,(l0,l1),(w0,w1),(h0,h1)为车辆长度、宽度和高度的约束范围.基准点(u2,v2)的取值范围为R,使用矩形区域表示.ε为θv的取值范围的阈值.限定参数的取值,可进一步缩小参数优化的空间,提升优化效率.如图3(c)为最优参数向量对应的3D 包络,图3(d)为最优投影凸包与车辆轮廓的差值.

图3 车辆三维包络精细化过程实例图
2 车辆目标展开标准化及深度网络训练
2.1 基于车辆三维包络框的标准化展开
由于透视投影可知,单目视觉下的目标会发生不同程度的透视畸变及尺度变化,事实上这对于目标的识别有一定的影响,传统的方法大多采用大量不同视角下及不同尺度下的目标数据进行训练,继而弥补透视畸变及尺度变化对于目标识别产生的影响,而本文可利用车辆三维包络框的标准化展开,在数据输入端即可做透视畸变及尺度变化的校正.通过这种方式,在达到相同精度的情况下,需要更少的数据集.如图4所示,通常视角下车辆的可视面有3 面,车辆目标正面(F),侧面(S),顶部(V) (当然还有其他一些可视面的组合方式,本文中暂时只考虑F-S-V的可视面组合方式),可利用透视变换的原理对3 个可视面进行矫正.

图4 车辆三维包络可视面示意图
透视变换的公式如下,其功能为投影图像至新的可视化平面.
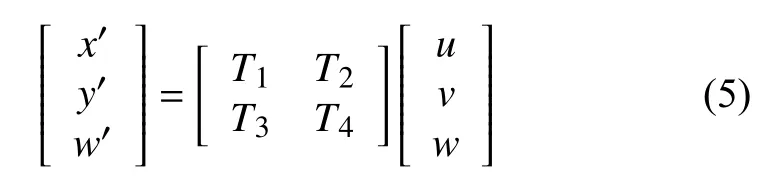
其中,图像像素坐标变换前表示为(u,v),变换后为(x′,y′),T1表示线性变换,为2×2的矩阵,T2表示透视变换,为2×1的矩阵,T3表示图像平移,为1×2的矩阵,T4为不为零的常数.本文对3D 包络框的每个可视面,利用其四边形的每个顶点与变换之后的标准矩形顶点建立映射等式关系,即可求取对应的透视变换矩阵,继而可将3 个可视面进行逆透视展开.其展开的顺序和规范如图5(a)所示,每个面的透视形变校正结果示例图如图5(b)所示.设规范化的展开图像宽为wsd,高为hsd,如图6所示,为一组车辆3D 包络及标准化展开的示例图.事实上除了展开的具有逆透视效果的规范化图像之外,车辆的物理尺寸也可作为后续分类识别的有效信息.

图5 车辆三维包络视变换示意图

图6 车辆三维包络及标准化展开示例图
2.2 基于标准化展开输入的深度网络训练分类模型
本文设计了一种可以同时预测车辆和车辆三维尺寸的细粒度识别网络,如图7所示,网络输入为由三维目标检测结果展开所得标准化展开图 (224×224),网络输出为车辆分类vtype(Hatch-back,Sedan,SUV,Bus,Truck 共5 类)和车辆三维尺寸(lv,wv,hv).

图7 深度网络结构图
为了提升网络整体泛化性能,防止过拟合,本文采用ResNet[28]作为backbone,网络共包含两个分支:主分支和辅助分支,这两个分支都可以完成车辆分类和车辆三维尺寸预测.其中,主分支用于训练和预测,辅助分支借鉴了GoogleNet 网络[29]中辅助分类器的结构,只在网络训练过程中使用,能够防止一定程度的梯度消失.
由于分类标签是一概率分布向量,其网络输出值比车辆实际三维尺寸标签小很多,因此,为了使得模型更稳定,本文对车辆三维尺寸标签做了归一化处理,具体为将标准化展开图中车辆尺寸像素与实际物理尺寸相比,作为最终的三维尺度因子,其值范围在0–1 之间.如图8所示,车辆像素尺寸标签大小为(lpix,wpix,hpix),物理尺寸标签为(lv,wv,hv),则新的标签设计为尺度因子:sl=lpix/lv,sw=wpix/wv,sh=hpix/hv.

图8 车辆三维物理尺寸标签尺度因子设计示例图
损失函数得设计共包含3 个部分,车辆分类损失,车辆三维尺寸回归损失和辅助训练损失,如式 (6) 所示,辅助训练损失也由分类和回归损失组成.具体形式如公式组 (7) 所示.
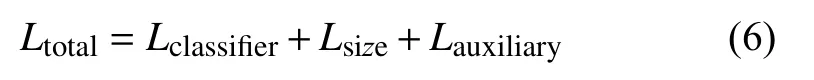

车辆分类损失Lclassifier形式为多分类交叉熵损失,如式 (7) 所示,N为网络训练时每批次输入的标准化展开图数量,K为分类数,本文中分别取32和5,表示第j类的车辆分类标签,如果车辆属于第j类,则=1,否则=0,表示经过全连接层及Softmax 处理后车辆属于第j类的概率.车辆三维尺寸回归损失Lsize为L1范数损失,如式(7)所示,lpvre,wpvre,hpvre分别表示网络预测所得车辆三维尺寸尺度因子,lgvt,wgvt,hgvt分别表示车辆三维尺寸尺度因子真实归一化标签值.辅助训练损失Lauxiliary如式 (7) 所示,Laux_classifier,Laux_size分别与Lclassifier,Lsize具有相同的形式,λc和λs分别表示分类和回归损失在辅助训练损失中的权重系数,本文中选取λc=λs=0.5.
3 实验结果
3.1 实验过程及实例
本文所应用的场景为道路交通视频监控,因此使用针对道路交通监控场景下的BrnoCompSpeed 数据集[30],该数据集包含6 个交通场景,如图9所示,其中,单车道宽度为3.5 m,道路虚线长度为3 m,虚线间隔为6 m.同时该数据集对于经过的每辆车都有明确的车辆记录.表1为本文对6 个交通场景自动标定的结果.
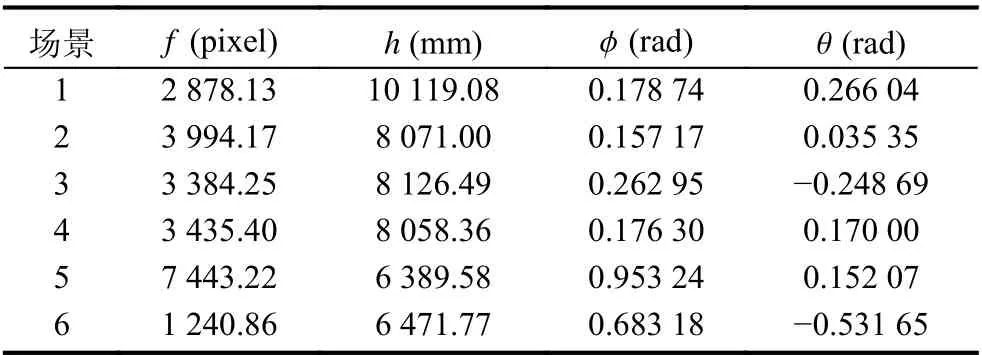
表1 交通场景相机自标定结果

图9 BrnoCompSpeed 数据集下的交通场景
对于数据集的处理,首先将视频数据集处理为图像数据集,由于交通场景中车流量较小,因此本文对数据集的处理方式为,每隔10 s 截取1 帧,去除车辆目标过小以及无车辆目标的图像帧,整理得到图像数据集.对图像数据集进行分类,本文的分类标准是对轿车类(Car) 中的两厢车 (Hatch-back)和三厢车(Sedan)进行再分类,总体车辆分为Hatch-back,Sedan,SUV,Bus,Truck 共5 类,同时根据数据集提供的详细车辆信息查取其对应的三维尺寸(lv,wv,hv).
Mask-RCNN 网络集目标检测分类与分割于一体,因此本文采用该网络对数据集中的车辆目标进行预处理,获取车辆的预分类及边界分割结果.该网络可以识别80 种不同类别目标,但对于车辆只能粗略分为Car,Bus,Truck 3 类.根据初始识别的车辆可根据统计给出物理尺寸取值范围,各车辆的外轮廓尺寸取值范围实例如表2所示.最后根据轮廓约束构建精细化的车辆3D 包络.实例图如图10所示.

图10 车辆精细化三维包络构建实例图

表2 各类型车辆外轮廓尺寸范围 (m)
对车辆三维包络3 个可视面进行透视变换,并对透视变换后的可视面进行标准化展开,更多展开实例如图11所示.

图11 车辆三维包络标准化展开实例
本次实验从BrnoCompSpeed 视频数据集中截取3 000 张图片,其中包含车辆6 000 辆,训练集 (4 000辆)和测试集 (2 000 辆),训练集和测试集均包含5 个类别的车辆,并对每辆车都标注了对应的车辆及三维尺寸信息,训练集中对较难区分的两厢车 (Hatch-back),三厢车 (Sedan)和SUV 各1 000 辆,公交车类 (Bus)和卡车类 (Truck) 各500 辆.为了便于网络的训练,将展开的标准化图像分辨率调整为224×224 大小.实验在配置有Intel i7-6800K CPU和GeForce GTX 1080Ti GPU的PC 机上运行.
3.2 实验结果分析
本文选取ResNet-101 作为主干特征提取网络,为了提高检测精度,采用其在ImageNet[31]上的预训练参数,在训练的过程中进行微调 (fine-tune).网络的输入的是展开的标准化图像,批次大小设置为32,分类输出5 类车辆,以及回归输出的是车辆物理尺寸长宽高.
由于本网络为多任务输出网络,包括车辆分类及车辆物理尺寸输出,因此,实验结果可以从分类的精度及物理尺寸回归的结果两方面进行分析.图12为细粒度识别结果在测试集上的车辆P-R 曲线 (Precision-Recall curves)图,可看出对于特征区分度较高的Bus和Truck,本文方法的分类精度均超过90%,Sedan和Hatch-back 车辆,识别率也超过80%,由于SUV的特征区分度和二厢车及三厢车不大,因此识别率稍低.

图12 车辆分类Precision-Recall 图
利用同样的网络结构及数据集,本文分别用标准化展开数据及原始图像数据做为输入进行训练,得到不同的识别结果,以此证明本文方法对于识别结果的有益性,如表3所示,为两类方法识别的结果对比,数值均为四舍五入的整数.

表3 车辆分类平均精确度对比 (%)
通过表3可以看出,对于Bus 及Truck 等本身特征区分度很大车辆,本文算法的准确率提高并不大,而对于SUV,Sedan 及Hatch-back 等特征区分度较小的车辆,本文方法的精确度有了明显的提高.可证明本文采用的车辆目标三维展开规范化的输入方法,可以有效的提高网络分类的性能.
对于车辆物理尺寸的回归输出,本文对于预测输出的物理尺寸Xpre=(lpre,wpre,hpre)与标签物理尺寸Xlabel=(llabel,wlabel,hlabel),利用式(8) 计算准确率Psize,其中,∥·∥2表示欧氏距离的二范数:

车辆三维尺寸的识别受视角影响比较大,如图13所示,为测试数据集上不同偏转视角下网络预测车辆物理尺寸的平均精度.
从图13中可以看出,当相机偏转角接近±45°左右时,由于图像中车辆的3 个可视面均可充分的展现,因此在做三维包络展开时,可以保留较多的特征信息,也有助于最终车辆三维尺寸的回归输出.而当相机偏转视角接近于0°附近时,图像中车辆目标纵向信息消失殆尽,因此尤其对于车辆纵向长度的识别影响很大,因此输出的车辆三维尺寸精确度较低.

图13 不同相机视角下车辆三维尺寸预测平均精度图
表4为车辆细粒度识别方法对比,其中精度由车辆单个识别精度和追踪过程中综合识别精度组成.

表4 不同车辆识别方法对比
表4中BoxCars 也是采用消除透视畸变及3D 展开输入的方法,从中可知,本文方法与BoxCars 方法在识别精度上均有较大的提高.本文方法相比于BoxCars还可回归输出车辆物理尺寸信息.
4 结论与展望
本文提出一种基于车辆三维包络展开的车辆识别方法,该方法采用三维包络展开的规范化数据作为输入进行训练,不仅可以提高车辆分类的精度,而且可输出获得车辆物理尺寸信息.通过在BrnoCompSpeed 视频数据集中的实验表明,相比于传统的原始图像数据直接输入训练,基于三维包络展开规范化图像数据方法,由于很大程度上消除了透视畸变及尺度因素的影响,使得目标的特征更加突出及规范,从而较大程度提升了细粒度识别的精度.同时,本文方法还可以回归输出车辆物理尺寸信息,更加丰富了分类车辆描述的维度.
然而,本文方法仍存在可优化的余地,譬如车辆三维包络展开数据的规范程度依赖于车辆的3D 包络准确程度,而相机接近0°视角下,车辆的3D 包络将会有较大误差.同时,与传统图像目标识别一样,本文对于小目标的识别也存在较大误差,主要原因就是小目标本身具有的图像特征较少,数据规范化之后有可能造成较大变形,影响分类识别结果.后续工作将会着重探索和研究车辆在不同视角下的精确包络难题,及小目标车辆的精确分类问题,以进一步提高车辆分类的准确率以及稳定性.
