一种优化YOLO模型的交通警察目标检测方法
2022-05-09李妮妮王夏黎付阳阳郑凤仙何丹丹袁绍欣
李妮妮,王夏黎,付阳阳,郑凤仙,何丹丹,袁绍欣
一种优化YOLO模型的交通警察目标检测方法
李妮妮,王夏黎,付阳阳,郑凤仙,何丹丹,袁绍欣
(长安大学信息工程学院,陕西 西安 710064)
针对复杂交通场景中交通警察目标检测与定位准确率低的问题,提出一种优化YOLOv4模型的交通警察目标检测方法。首先,采用4种随机转换方式对自建的交通警察数据集进行扩充,解决了模型过拟合问题并提高模型的泛化能力;其次,将YOLOv4主干网络替换为MobileNet并引入Inception-Resnet-v1结构,有效地减少了参数总量并加深了网络层数;然后,使用K-means++聚类算法对自建数据集进行聚类分析以重新定义网络的初始候选框,提高了交通警察目标深度特征的学习效率;最后,引入焦点损失函数以优化分类损失函数,解决了训练中正负样本数量不平衡问题。研究结果表明,优化后的YOLOv4模型大小仅50 M,AP值达98.01%,与Faster R-CNN,YOLOv3和原始YOLOv4模型相比均有提升。有效解决了目前复杂交通场景中交通警察目标的漏检、误检及检测精度低等问题。
交通警察目标检测;YOLOv4模型;K-means++聚类算法;深度特征学习;焦点损失函数
近年来,随着人工智能技术不断地革新突破,无人驾驶技术因具有缓解交通压力、降低环境污染、降低交通事故发生率等优点,将成为智能交通领域未来发展的主流趋势[1]。成熟的无人驾驶系统除需对交通信号灯[2]、交通标志牌[3]等固定信号做出响应外,还需对复杂交通场景中进行灵活判断和疏导的交通警察做相应地回应[4]。因为交通警察是复杂交通网络中的重要一员,能够有效地协调在无交通信号灯的路口、拥堵路段、事故现场等复杂交通状况下的交通秩序问题,对城市交通网络更好、更快地发展起着积极地促进作用[5-6]。因此,对交通警察检测算法的研究有助于保护交通警察人身安全及保障城市交通网络持久健康的发展。
交通警察检测属于计算机视觉领域中目标检测的范畴。传统的目标检测是通过特征提取和特征分类2个相互独立的步骤完成,特征提取有方向梯度直方图(histogram of oriented gradient,HOG)[7]、局部二值模式(local binary pattern,LBP)[8]等;特征分类包括AdaBoost (AdaptiveBoosting)[9]、支持向量机(support vector machine,SVM)[10]等,该方法由于受到光线、遮挡和复杂背景等问题影响易导致提取的特征单一且鲁棒性不强。随着卷积神经网络(convolutionalneuralnetwork,CNN)在图像分类任务上应用后,其目标检测算法成了当前主流算法[11-12]。如GIRSHICK等[13]提出的R-CNN (regions with CNN features)和Fast R-CNN[14];REN等[15]提出的Faster R-CNN;HE等[16]提出的Mask R-CNN均是基于目标候选框思想的Two-stage方法,拥有较高的准确率。LIU等[17]提出的SSD (single shot multibox detector);REDMON等[18]提出的YOLO (you only look once),YOLO9000[19]和YOLOv3[20];BOCHKOVSKIY等[21]提出的YOLOv4均是基于回归思想的One-stage方法,其相较于R-CNN系列网络因无目标候选框提取操作而拥有更高地检测速度。虽然采用CNN的方法在目前主流的数据集中取得了较大进展和突破,但该方法不能完全适合复杂交通场景中交通警察图像的检测工作,因此要在复杂的交通场景下快速且准确地检测出交通警察仍面临着一定的局限性。
针对以上问题,本文将Faster R-CNN,YOLOv3和YOLOv4等3种方法分别应用于交通警察的检测中,以寻求最适合交通警察检测的算法,发现基于YOLOv4在检测准确率和检测速度上均优于其他检测方法。为此,本文又通过K-means++聚类算法重新计算交通警察的anchor值、将主干网络替换为MobileNet并引入Inception-Resnet-v1模块及焦点损失函数来优化YOLOv4网络模型,使其更优地实现复杂交通场景中不同服饰交通警察的检测工作。实验结果表明,基于YOLOv4优化模型的大小仅50 M,其在交通警察测试集上的精确率、召回率、类别平均精度、每秒帧数(frame per second,FPS)分别为99.60%,95.42%,98.01%和39.5,均优于其他3种网络模型。
1 YOLOv4算法原理及检测流程
1.1 YOLOv4目标检测算法原理
YOLOv4是YOLO系列中最新的目标检测算法,其具体的网络结构由主干特征提取网络、特征金字塔结构和预测网络组成,如图1所示。
1.1.1 主干特征提取网络
YOLOv4学习目标特征的主干特征提取网络为CSPDarknet53,该结构是在YOLOv3主干特征提取网络Darknet53的基础上引入跨阶段局部网络结构的思想[22]。首先对416×416×3大小的输入图像经CBM进行卷积操作使之变为416×416×32大小,又经5个CSPX模块,然而对于YOLOv4中的CSPX模块与一般的由初始输入和经卷积后输出而组成的残差模块不同,其是在保留原有残差块的基础上,将前一层的输出经过少量处理和小的残差结构做大的残差连接,在CSPDarknet中可以绕过很多残差结构的大残差边,通过这种拼接方式可以在减少计算量和降低内存成本的同时保证准确率,从而提取更多有用的特征信息。对于图1中的CSP1,CSP2,CSP4和CSP8中的1,2,4,8表示残差单元模块的重复次数。另外,由于网络中每个CSP模块相对应的2个卷积核大小分别为3×3和1×1,能使经过残差块处理的特征图通道数翻倍,且尺寸缩小一半。由于在第3和第4个CSP8中的第54和85层分别有一个分支用于后续上采样的特征,因此输出维度分别为13×13×1024,26×26×512和52×52×256的3个残差模块的特征图。

图1 YOLOv4网络结构
1.1.2 特征金字塔结构
特征金字塔由空间金字塔池化层(spatial pyramid pooling,SPP)[23]和路径聚合网络(path aggregation network,PANet)[24]组成,且位于主干特征提取网络与预测网络之间,主要负责深层融合特征的提取。如图1所示的SPP模块主要解决输入图像可能不符合输入大小而对其进行裁剪和拉伸操作时导致图像失真的问题。SPP模块仅处理输出维度为13×13×1024的特征图,为了增加网络的感受野从而分离出显著的上下文特征,使该特征经过(1×1,5×5,9×9,13×13)不同大小的池化核进行最大池化处理,再将每个池化后的结果进行通道拼接输出。YOLOv4主要通过深浅层特征融合实现增强特征信息的目的PANet网络(图2),其主要对输出维度为13×13×1024,26×26×512和52×52×256的特征图上采用PANet结构,然而PANet网络对于高层和低层特征处理方式不同,为了与上一层同维度特征进行拼接,采取对高层特征进行上采样的方式使特征图的维度翻倍,为了与下一层同维度特征进行拼接,采用对低层特征进行下采样的方式使特征图的维度减半,从而实现特征信息的融合。
1.1.3 预测网络
YOLOv4的预测网络同YOLOv3,均是完成3种尺度的预测工作,其预测的本质是在特征金字塔结构输出的特征维度信息上进行解码的过程。经过特征金字塔结构输出的特征维度的大小为××75,将图片划分为×的网格,对于存在物体的网格将构成先验框,根据特征信息对应调整先验框可得特征层的预测结果。其中每个特征层输出的特征均需要进行一次解码,并取各特征层预测结果中置信度最大的先验框作为最终的预测结果。

图2 PANet结构图
1.2 YOLOv4交通警察目标检测流程
YOLOv4算法先对输入的复杂交通场景下含交通警察的图片进行预处理,使之重置为416×416大小,使用CSPDarknet53主干特征提取网络提取交通警察的深度特征,将特征向量发送至SPP和PANet进行预测输出特征,3个尺度预测输出的特征可以检测复杂交通场景中不同大小的交通警察,从而提高模型的精确度。


最后利用非极大值抑制的方法对每一个尺度的预测结果进行处理,将预测相同目标的重复选框进行消除,最终得到复杂交通场景图片中交通警察的位置信息。
2 优化YOLOv4的交通警察检测分析
2.1 聚类先验框优化
YOLOv4借鉴Fast-RCNN思想引入先验框,先验框的引入使交通警察检测问题转为固定格子内是否含有交通警察的问题,其是一组因摒弃多尺度滑动窗口遍历而提高检测精度和速度的固定尺寸大小的初始候选框。但与Fast-RCNN不同,先验框是在PASCALL_VOC和COCO数据集中采用的K-means算法[25]聚类而来,因2个数据集包含的物种种类繁多,在对复杂交通场景下的交通警察检测时先验框不适合。为了能够让YOLOv4网络更好地进行交通警察的深度特征学习,选用K-means++对自建的交通警察数据集重新聚类分析,得到适合交通警察检测的初始候选框。
传统K-means++聚类算法[26]因采用欧几里得距离函数聚类,可能导致结果发生一定程度的偏离,因此交通警察检测的初始候选框采用交通警察先验目标框与交通警察实际预测框的交并比IOU (intersection over union)作为距离公式,即
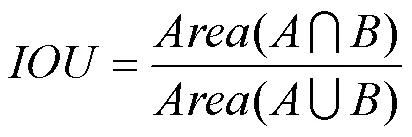
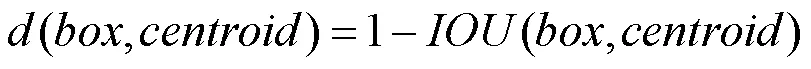
其中,为交通警察真实标记目标框;为交通警察实际预测框;为与交集和并集面积的比值,与框的尺度无关。
图3是不同初始候选框的数量对应的平均IOU,可看出平均IOU随候选框数量的增多而不断增大,但因候选框数量和待检测目标区域成正比,若待检测目标区域越多其计算时间就越长,因此在兼顾精度和计算速度的情况下,选择采用表1的9个先验框。
2.2 网络结构优化
YOLOv4原始的主干特征提取网络为CSPDarknet53,该网络虽然能提取有效的交通警察深度特征信息,但由于网络模型较复杂可能导致实时性较差,因此将其主干网络替换为轻量级的MobileNet[27]。其采用深度可分离卷积模块(depthwise separable convolution,DSC)[28],而建立的网络结构是普通卷积建立的网络结构的参数量的1/9,因此精简了网络参数减少了计算量从而提高了检测速度。另外,为了避免普通卷积层中任意卷积核都需要对所有通道进行操作,DSC采用将传统的卷积操作分为深度卷积(depthwise convolution)和点卷积(pointwise convolution)2步进行,其中深度卷积对不同输入通道采用不同的卷积核,而点卷积主要融合来自深度卷积的特征。
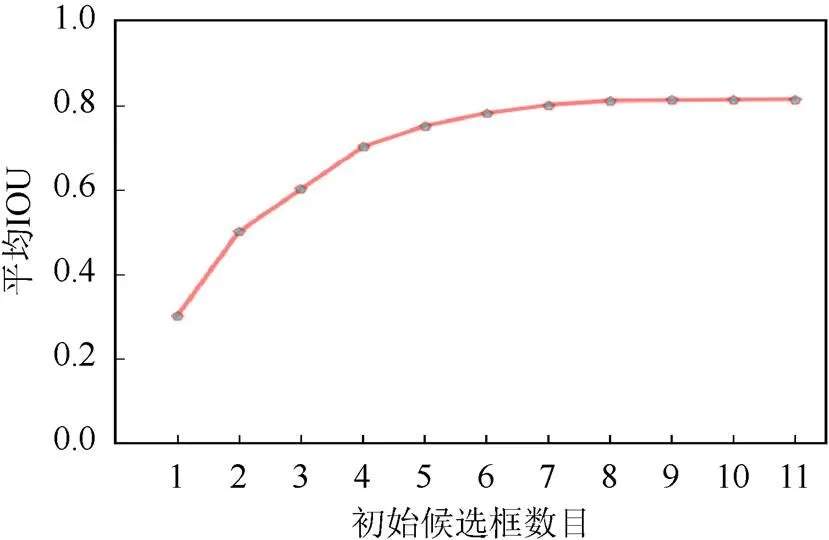
图3 不同候选边框数量的平均IOU

表1 聚类优化后先验框尺寸
虽然MobileNet网络结构相较于CSPDarknet53参数量大大减少,但对于复杂交通场景下远处的交通警察和被遮挡的交通警察的特征图上信息将受到一定程度的影响。要想提高复杂交通场景下交通警察检测的精确率,需要保证复杂交通场景下交通警察的深度特征信息足够丰富。
2014年Google公司SZEGEDY等[29]提出的Inception-Resnet-v1网络加入残差模块,使参数能够跳层进行传播,解决深层次网络结构中存在的梯度消失现象。为增加网络模型的宽度提升网络的性能和对多尺度交通警察目标检测的适应性,借鉴Inception-Resnet网络的思想,在原始CBL位置引入如图4所示的2个Inception-Resnet-v1模块,在增加少量网络参数的前提下实现增加网络宽度和拓展网络的深度,从而更好地提取交通警察的深度特性信息。优化后的交通警察检测网络结构图如图4所示(https://www.sohu.com/picture/417071894)。
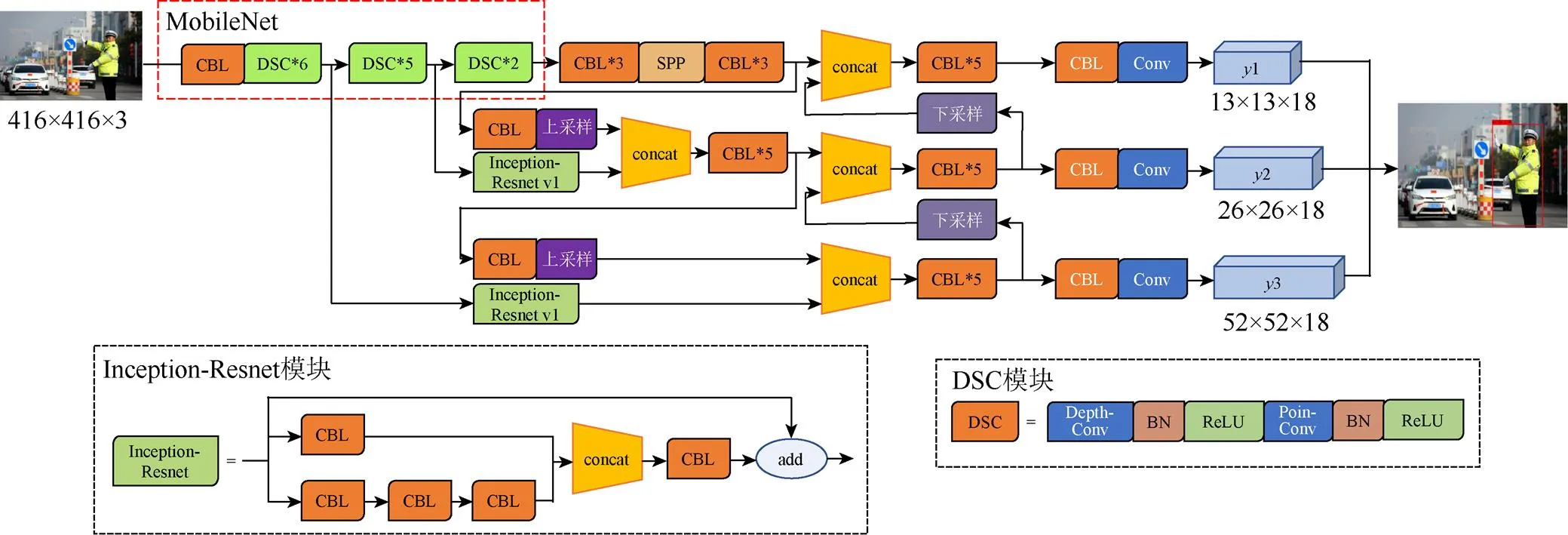
图4 优化的交通警察检测网络结构图
2.3 损失函数优化
在复杂交通场景图片中,交通警察仅占图像的小部分,其背景占据大部分区域。若将图片中含交通警察的区域为正样本,不含区域为负样本,可知,不含交通警察区域的负样本数量远多于正样本数量。其数量严重失衡可能导致训练过程中给模型提供的交通警察的特征信息较少而影响模型的收敛。而焦点损失函数(focal loss,FL)[30]能通过降低内部加权解决正、负样本不平衡的问题,即使负样本的数量很大,但其对总损失的影响却很小,可认为是一种困难样本挖掘。将其应用于分类损失函数中,使网络学到更多更有用的交通警察特征信息从而提高对交通警察检测的准确率。
原始YOLOv4模型使用二元交叉熵计算分类损失函数的置信度损失为
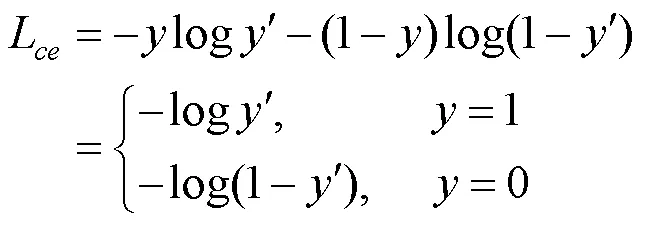
其中,,分别为真值和检测值,1和0分别为正、负样本。二元交叉熵函数对于正样本检测概率和损失成反比,而对于负样本则成正比。因此,在大量的负样本进行迭代训练的过程中模型无法达到理想状态。
焦点损失函数本质上是交叉熵损失函数的一种改进,首先为了使易分类样本的损失减少能够更多地关注困难样本,故在标准的二元交叉熵损失函数上引入一个大于零的因子,即
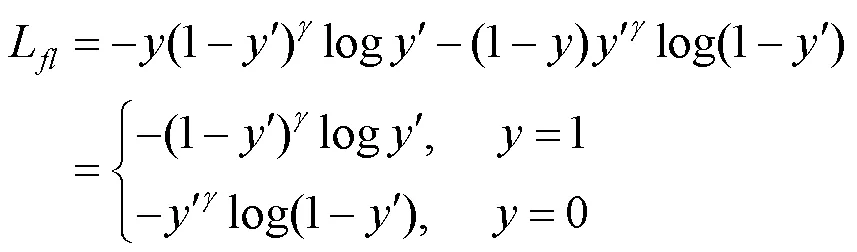
此外,为了解决正、负样本不平衡问题,引入一个平衡因子,则总的焦点损失函数为
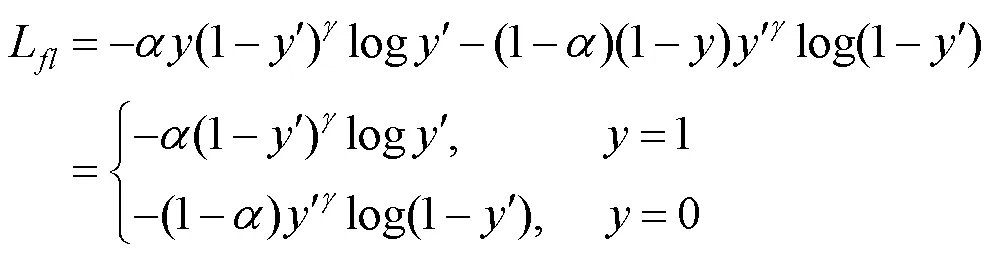
YOLOv4网络的损失函数由边界框回归、置信度和分类损失组成[21],即
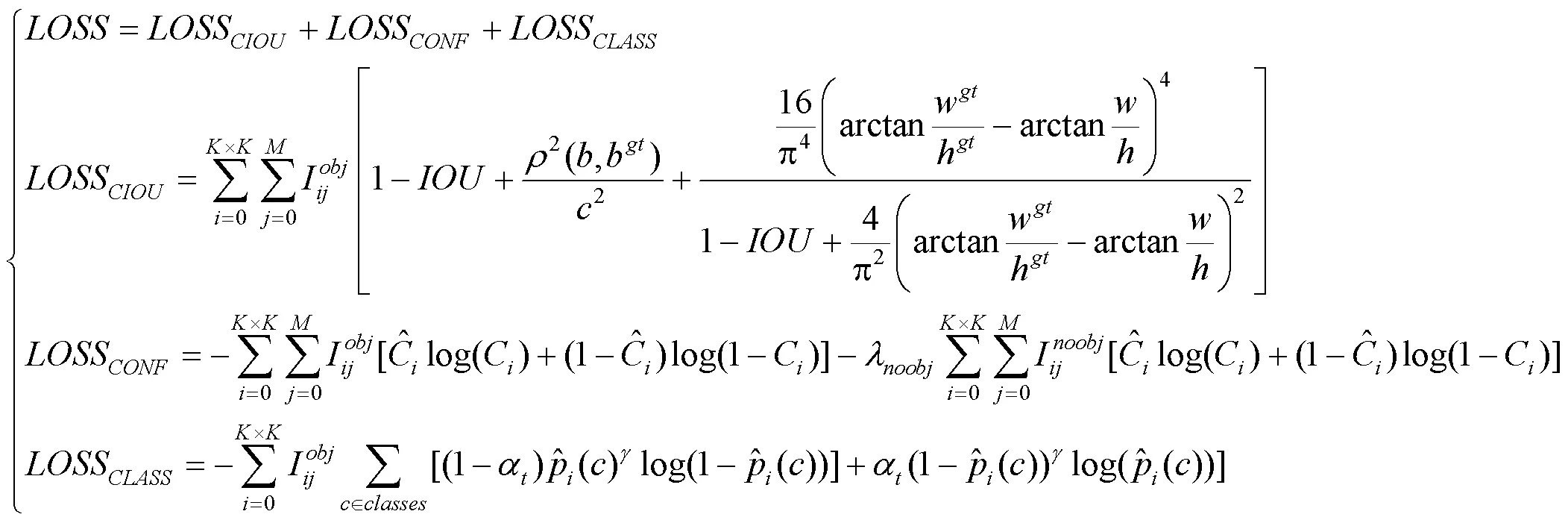
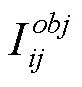
3 实验与分析
3.1 数据集准备
3.1.1 数据集获取
目前并没有公开的交通警察检测数据集,因此交通警察网络检测模型训练和测试所用数据集是一个自建数据集,其主要通过网络爬虫爬取一些交通警察图片,另外,为了获取更加丰富的复杂交通场景下的交通警察训练和测试图片,又在实验室周边进行了交通警察图片的拍摄工作,最终择优挑选1 000张复杂交通场景下的交通警察图片作为本文所需的数据集样本,其部分交通警察数据集样本如图5所示(https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gb18030&word=%BD%BB%CD%A8%BE%AF%B2%EC%CD%BC%C6%AC&fr=ala&ala=1&alatpl=normal&pos=0&dyTabStr=MCwzLDIsMSw2LDUsNCw3LDgsOQ%3D%3D)。
该数据集中,每张图片的背景、光线、交通警察年龄、性别、着装及所处的位置均有所不同。例如,包含众多行人车辆和建筑物的复杂交通场景,也包含阴雨天、傍晚等光线较弱的交通场景,以及不同着装、不同年龄、不同性别的交通警察同时出现的交通场景。同时,一方面为进一步提高网络模型的鲁棒性,防止模型在训练的过程中因收集的交通警察图像数据量较少导致过拟合现象,从而停止交通警察深度特征的学习;另一方面为了提高该网络模型的泛化能力,本文将采用随机转换的方式对采集的交通警察数据集进行图像处理扩充操作。
3.1.2 数据集扩充
为了使训练后的网络模型能够满足复杂交通场景下交通警察的检测需求,本文针对2种方式采集的每张交通警察数据集样本,分别使用表2中的水平翻转、添加高斯噪声、标准模糊、亮度增强等4种图像处理随机转换方式进行交通警察数据集样本的扩充,得到一组新的数据样本,其中对于每一种扩充操作彼此之间是相互独立的,原始图像每经过一种扩充操作所得到的新数据集样本均为1 000张,因此原始图像分别通过4种数据扩充后的交通警察图片共计4 000张,加上原始图像共计5 000张。其部分经4种图像处理扩充处理后的数据集样本示例图6所示(网址同图5)。

表2 交通警察数据集扩充操作

图6 数据扩充后的部分交通警察数据集示例
3.1.3 数据集标注
交通警察样本数据集使用基于python语言编写的labelImg进行交通警察训练集和测试集的标注。其为一款用于深度学习的数据集制作的标注工具,可用于记录复杂交通场景中交通警察的类别名和具体的位置信息,并将这些信息储存在voc标准数据集格式的文件中。从自建的交通警察数据集中随机划分80%为训练集,20%为测试集。
3.2 实验环境
实验平台的软件环境为Windows 10。64位操作系统,选用Python3.6语言进行编程,采用的深度学习框架为Tensorflow1.14;搭载Intel(R) Core(TM) i5-10400F CPU @ 2.90 GHz处理器,GPU是NVIDIA GeForce GTX1660 SUPER,加速库是CUDA10.0+CUDNN7.4.1。
3.3 评价指标
为客观分析实验结果,选用模型识别的精确率(Precision)、查全的召回率(Recall)、F1值、类别平均精度(average precision,AP)和FPS等5种评价标准衡量网络的性能,即

其中,T,F,F分别为被正确、错误和未检测的交通警察目标数。
3.4 消融实验
为了进一步分析各优化部分在复杂交通场景下对交通警察检测工作的影响,在自建交通警察数据集上分别从聚类先验框、MobileNet、Inception- Resnet-v1和分类损失函数做消融实验,对比了采用不同策略和组合对复杂交通场景下交通警察检测模型的性能影响。由表3可见,优化后的网络模型AP值提高1.17%,且模型大小仅50 M。
3.5 对比实验
为客观评价本文算法的有效性,在自建交通警察数据集上采用YOLOv4优化网络、Faster- RCNN网络、YOLOv3网络、原始YOLOv4网络,并分别进行实验,客观分析4种网络模型的综合性能。
表4是当Score_threhold=0.5时交通警察数据集上性能比较结果,可见YOLOv4优化模型的大小仅50 M,在Precision,Recall,F1,FPS上均优于其他3种网络模型。PR是以Recall和Precision分别为横、纵轴绘制的曲线,根据其PR曲线可计算其所对应的AP值,如图7所示,可见YOLOv4优化网络模型相比于其他3种深度学习模型也略胜一筹。
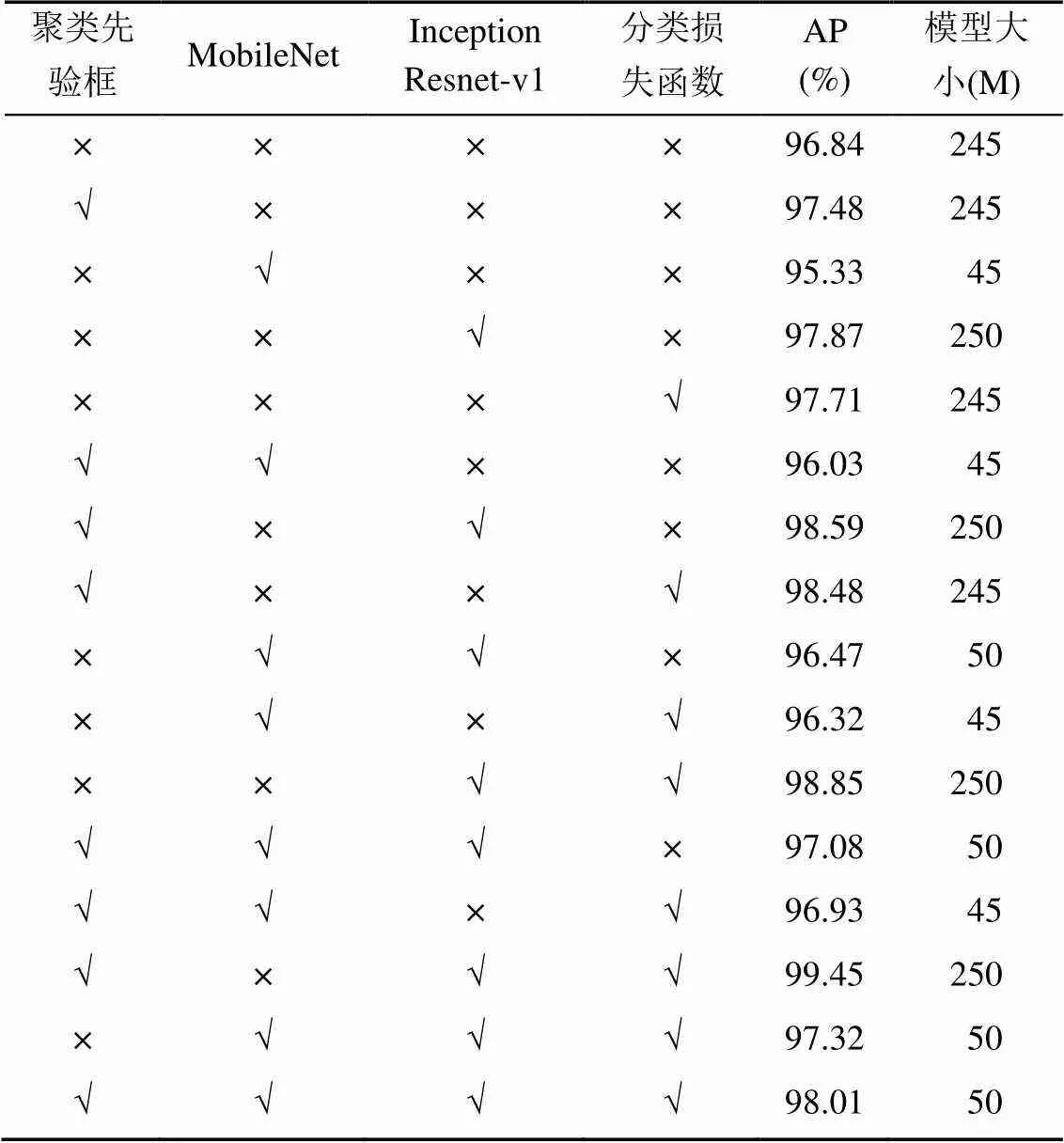
表3 不同策略YOLOv4网络的性能影响
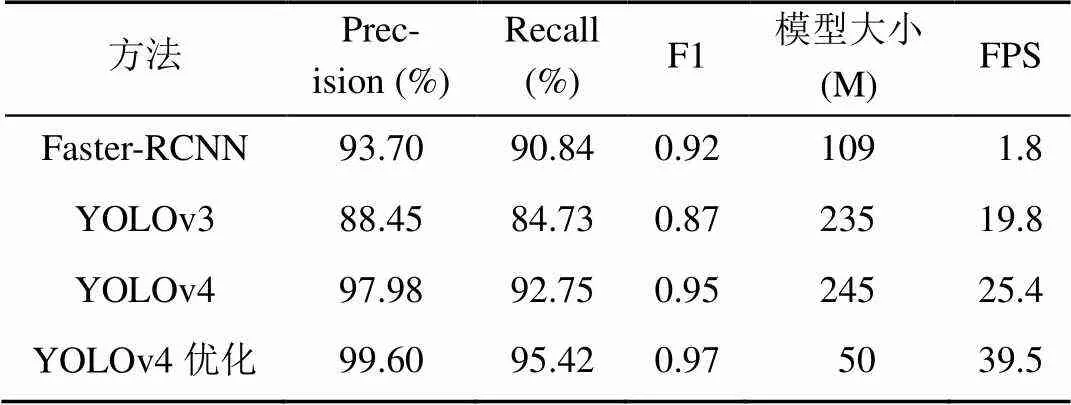
表4 4种算法的性能对比
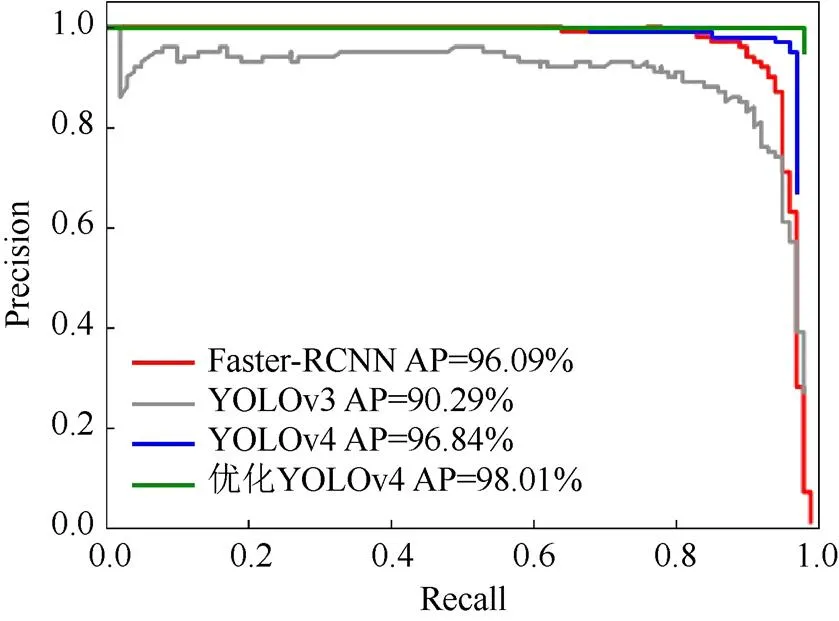
图7 不同网络的PR图
3.6 检测结果分析
为了进一步比较Faster-RCNN网络、YOLOv3网络、YOLOv4网络、YOLOv4优化网络对交通警察的检测效果,分别选取不同交通场景下的3张图片进行测试,结果如图8~10所示。
图8是在交通警察位置较隐蔽的情况下,图9是在夜间交通场景下,图10是在模糊且遮挡的交通场景中,其每幅图中的(a)~(d)分别代表Faster R-CNN网络、YOLOv3网络、YOLOv4网络、YOLOv4优化网络检测的效果图。通过对比发现,在图8中Faster R-CNN网络、YOLOv3网络、YOLOv4网络均未检测到图片中的第三位交通警察,且Faster R-CNN网络还将路人错检为交通警察,而YOLOv4优化网络中在保证其他警察准确率的前提下成功检测出第三位交通警察。在图9中Faster R-CNN网络、YOLOv3网络、YOLOv4网络均检测出一位交通警察,而YOLOv4优化网络检测出位于该警察对面的第二位交通警察。在图10中,YOLOv3网络只检测出一位交通警察,而Faster R-CNN网络和YOLOv4网络能检测出两位交通警察,对于图片中严重遮挡的第三位交通警察均未检测出,但YOLOv4优化网络以99%的准确率检测出被严重遮挡的第三位交通警察。可见YOLOv4优化网络模型在不同的交通场景下的检测效果均优于其他3种深度学习模型。

图8 交通警察位置较隐蔽的交通场景

图9 夜间交通场景

图10 交通警察模糊且被严重遮挡的交通场景
4 结束语
本文在单阶段检测模型YOLOv4的基础上,根据复杂交通场景中交通警察数据的特点,提出了一种主干网络为轻量级目标检测网络的YOLOv4交警察检测模型。该模型的优势:①通过多种图像处理扩充策略对自建数据集样本进行扩充处理,弥补了数据集不足的缺陷;②使用轻量级MobileNet网络代替YOLOv4中CSPDarknet主干网络并引入Inception-Resnet-v1结构,精简了网络结构,从而提高了模型检测的实时性;③使用K-means++算法对自建数据集进行聚类分析,有利于特征深度信息的提取;④通过焦点损失函数平衡数据集正、负样本数量从而降低了漏检率。优化后的模型相对于原模型在自建的交通警察测试集上的精确率、召回率、类别平均精度和FPS分别提升了1.62%,2.67%,1.17%和14.1。并通过实验验证了该模型在弱光线、复杂背景、图像模糊和被遮挡环境下的适应性良好。但是,使用单一的图像处理扩充策略得到的样本在亮度和色彩饱和度等方面与真实交通场景下的样本存在一定差异性,后续将配合使用迁移学习和自监督学习方式解决样本失真的问题,并进一步提高模型对极少量样本情况检测的准确率,以便更好地服务于智能交通事业的发展。
[1] 李超军. 面向自动驾驶的交警手势识别算法研究[D]. 北京: 北京工业大学, 2019.
LI C J. Traffic police gesture recognition for autonomous driving[D]. Beijing: Beijing University of Technology, 2019 (in Chinese).
[2] 董晓玉, 孔斌, 杨静, 等. 小尺度交通信号灯的检测与状态识别[J]. 测控技术, 2020, 39(11): 45-51.
DONG X Y, KONG B, YANG J, et al. Detection and state recognition of traffic light with small scale[J]. Measurement & Control Technology, 2020, 39(11): 45-51 (in Chinese).
[3] 薛搏, 李威, 宋海玉, 等. 交通标志识别特征提取研究综述[J]. 图学学报, 2019, 40(6): 1024-1031.
XUE B, LI W, SONG H Y, et al. Review on feature extraction of traffic sign recognition[J]. Journal of Graphics, 2019, 40(6): 1024-1031 (in Chinese).
[4] 王科俊, 赵彦东, 邢向磊. 深度学习在无人驾驶汽车领域应用的研究进展[J]. 智能系统学报, 2018, 13(1): 55-69.
WANG K J, ZHAO Y D, XING X L. Deep learning in driverless vehicles[J]. CAAI Transactions on Intelligent Systems, 2018, 13(1): 55-69 (in Chinese).
[5] 陈泽新, 徐彧. 道路交通事故处理的规范性问题探讨: 基于L市交通警察支队行政复议案卷的分析[J]. 四川警察学院学报, 2020, 32(3): 133-139.
CHEN Z X, XU Y. Exploration on standardization of traffic accident treatment based on analysis of administrative review files from traffic police division in L city[J]. Journal of Sichuan Police College, 2020, 32(3): 133-139 (in Chinese).
[6] 石臣鹏. 我国交警手势指挥现状及改善对策[J]. 四川警察学院学报, 2016, 28(1): 72-75.
SHI C P. The current situation and countermeasures of gesture command of traffic police in China [J]. Journal of Sichuan Police College, 2016, 28(1): 72-75 (in Chinese).
[7] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2005: 886-893.
[8] WANG X Y, HAN T X, YAN S C. An HOG-LBP human detector with partial occlusion handling[C]//2009 IEEE 12th International Conference on Computer Vision. New York: IEEE Press, 2009: 32-39.
[9] FREUND Y, SCHAPIRE R E. A decision-theoretic generalization of on-line learning and an application to boosting[J]. Journal of Computer and System Sciences, 1997, 55(1): 119-139.
[10] PLATT J. Sequential minimal optimization: a fast algorithm for training support vector machines[J]. Advances in Kernel Methods-Support Vector Learning, 1998, 208: 1-21.
[11] 李哲, 张慧慧, 邓军勇. 基于改进Faster R-CNN的交通标志检测算法[J]. 液晶与显示, 2021, 36(3): 484-492.
LI Z, ZHANG H H, DENG J Y. Traffic sign detection algorithm based on improved Faster R-CNN[J]. Chinese Journal of Liquid Crystals and Displays, 2021, 36(3): 484-492 (in Chinese).
[12] 刘胜, 马社祥, 孟鑫, 等. 基于多尺度特征融合网络的交通标志检测[J]. 计算机应用与软件, 2021, 38(2): 158-164, 249.
LIU S, MA S X, MENG X, et al. Traffic sign detection based on multi-scale feature fusion network[J]. Computer Applications and Software, 2021, 38(2): 158-164, 249 (in Chinese).
[13] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 580-587.
[14] GIRSHICK R. Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 1440-1448.
[15] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[16] HE K M, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[C]//2017 IEEE International Conference on Computer Vision. New York: IEEE Press, 2017: 2961-2969.
[17] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[M]//Computer Vision – ECCV 2016. Cham: Springer International Publishing, 2016: 21-37.
[18] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 779-788.
[19] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 6517-6525.
[20] REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. (2018-04-08) [2021-06-04].https:// arxiv.org/abs/1804.02 767.
[21] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: Optimal speed and accuracy of object detection[EB/OL]. (2020-04-23) [2021-06-04]. https://arxiv.org/abs/2004.10934.
[22] WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. New York: IEEE Press, 2020: 1571-1580.
[23] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[24] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 8759-8768.
[25] HARTIGAN J A, WONG M A. Algorithm as 136: a K-means clustering algorithm[J]. Applied Statistics, 1979, 28(1): 100.
[26] LATTANZI S, LAVASTIDA T, MOSELEY B, et al. Online scheduling via learned weights[C]//The 14th Annual ACM-SIAM Symposium on Discrete Algorithms. Philadelphia: Society for Industrial and Applied Mathematics. 2020: 1859-1877.
[27] HOWARD A G, ZHU M L, CHEN B, et al. Mobilenets: efficient convolutional neural networks for mobile vision applications[EB/OL]. (2017-04-17) [2021-06-04]. https://arxiv. org/abs/1704.04861.
[28] CHOLLET F. Xception: Deep Learning with Depthwise Separable Convolutions[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition, New York: IEEE Press, 2017: 1800-1807.
[29] SZEGEDY C, IOFFE S, VANHOUCKE V, et al. Inception-v4, inception-ResNet and the impact of residual connections on learning[EB/OL]. (2016-08-23) [2021-06-04]. https://arxiv.org/ abs/1 602.07261.
[30] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//IEEE Transactions on Pattern Analysis and Machine Intelligence. New York: IEEE Press, 2020: 318-327.
A traffic police object detection method based on optimized YOLO model
LI Ni-ni, WANG Xia-li, FU Yang-yang, ZHENG Feng-xian, HE Dan-dan, YUAN Shao-xin
(School of Information Engineering, Chang’an University, Xi’an Shaanxi 710064, China)
To tackle the problems of low accuracy of detection and localization for traffic police object in complex traffic scenes, a method to detect traffic police object based on the optimized YOLOv4 model was proposed in this study. Firstly, four random transformation methods were employed to expand the self-built traffic police data set, so as to solve the problem of model over-fitting and improve the generalization ability of the network model. Secondly, the YOLOv4 backbone network was replaced with the lightweight MobileNet. The Inception-Resnet-v1 structure was introduced to reduce the parameter numbers and deepen the network layers of the model effectively. Then, the K-means++ clustering algorithm was adopted to perform clustering analysis on the self-built data set. In doing so, the initial candidate frame of the network was redefined, and the learning efficiency was improved for traffic police object depth features. Finally, to address the problem of the imbalance of positive and negative samples in the process of network training, the focus loss function was introduced to optimize the classification loss function. Experimental results demonstrate that the size of the optimized YOLOv4 model is only 50 M and the AP value reaches up to 98.01%. compared with Faster R-CNN, YOLOv3, and the original YOLOv4 model, the optimized network has been significantly improved. The proposed method can effectively solve the problems of missed detection, false detection, and low accuracy for traffic police object in current complex traffic scenes.
traffic police object detection; YOLOv4 model; K-means++clustering algorithm; deep feature learning; focus loss function
TP 391
10.11996/JG.j.2095-302X.2022020296
A
2095-302X(2022)02-0296-10
2021-06-09;
2021-09-27
国家重点研发计划项目(2020YFB1600400)
李妮妮(1996–),女,硕士研究生。主要研究方向为图形图像处理与智能交通系统。E-mail:ninili0128@163.com
王夏黎(1965–),男,副教授,博士。主要研究方向为图形图像处理与智能交通系统。E-mail:2453277077@qq.com
9 June,2021;
27 September,2021
National Key R&D Program of China (2020YFB1600400)
LI Ni-ni (1996–), master student. Her main research interests cover graphic image processing and intelligent transportation systems. E-mail:ninili0128@163.com
WANG Xia-li (1965–), associate professor, Ph.D. His main research interests cover graphic image processing and intelligent transportation systems. E-mail:2453277077@qq.com
