一种即时软件缺陷预测模型及其可解释性研究
2022-05-09陈丽琼宋士龙
陈丽琼,王 璨,宋士龙
(上海应用技术大学 计算机科学与信息工程学院,上海 201418)
1 引 言
传统的软件缺陷预测[1]是基于文件、软件包或代码库的分析,但是在实际情况下软件开发人员每次提交代码变更时都可能会引发缺陷.另一方面由于大量代码可能只带来极少量的缺陷,这导致代码审查人员需要花费大量时间.因此,研究人员提出了一种即时缺陷预测技术.在即时缺陷预测中,预测的软件实体是代码变更.即时性是即时软件缺陷预测技术的优点.该技术可以有效解决传统缺陷预测技术所面临的挑战.
然而,即时软件缺陷预测的准确性受数据集类别不平衡的影响[2].软件工程领域20%的缺陷可能存在于80%的模块中,在多数情况下不会引起缺陷的代码更改占比更大.因此数据集中存在不平衡率,即少数和多数类别之间的失衡,会影响模型的分类预测效果[3].大多数类,即不会产生缺陷的代码更改会使模型具有虚高的预测准确率,难以在实际应用中获得预期的结果.并且,数据集特征中含有许多无关特征和冗余特征,也会提高预测模型的复杂度[2].
近几年,可解释机器学习已成为了机器学习的重要研究方向.SHAP[4]是以一种统一的方法来解释任何机器学习模型的框架,将博弈论与局部解释联系起来,并根据预期表示唯一可能的一致且局部准确的加法特征归因方法.通过 SHAP 的3个特性,即局部精确性、 允许缺失和一致性以及模拟式的计算思想,从而考虑各个特征组合关键词对模型结果的影响,可满足即时缺陷预测模型这类高精度复杂集成模型的解释.
本文为提高预测模型分类性能并解释每个特征对模型的影响,使用SHAP分析原始数据集的特征关系,进行特征选择和数据预处理.SHAP-SEBoost与基线模型以及LocalJIT[5]、Kamei[6]、NeuralForest[7]相比极大地提升了预测的准确率,获得了较好的分类效果.
2 相关工作
近年来,即时缺陷预测技术由于其细粒度、即时可追溯的优势,成为了缺陷预测领域的研究热点.Khuat T T等[8]从经验上评估了在软件缺陷预测问题中针对不平衡数据上的各种分类器集合进行采样的重要性,结合采样技术和集成学习模型,对于具有类不平衡问题的数据预测具有积极的作用.Liu等人[9]使用信息增益特征选择算法对原始数据集进行特征优化,并结合多项式贝叶斯算法对优化数据集进行训练与测试.L Pascarella等[10]提出了一种新颖的细粒度模型,以预测提交中包含的有缺陷的文件,并根据分类性能和模型在多大程度上减少了判断缺陷所需的工作量.Hu等人[11]在类权值学习阶段,通过类权自适应学习得到不同类的最优权值;然后,在训练阶段,使用前一步得到的最优权值训练3个基分类器,并通过软集成的方法组合3个基分类器;最后,在决策阶段,根据阈值移动模型来做出决策.KK Bejjanki等提出class imbalance reduction (CIR)[12],通过考虑数据集的分布特性,提出了在不平衡数据集中建立缺陷记录与非缺陷记录对称的算法.特征选择和集成学习的结合也是分类预测的研究热点,Wang等人结合Relief特征选择算法和异质集成学习算法识别3类不同密码体制[13].
因为机器学习模型使用时通常难以解释,部分研究已经开始利用SHAP进行模型解释工作.AB Parsa等[14]使用SHAP和XGBoost解释即时交通事故发生的特征关联.Zhao[15]开发了CNN SHAP来计算基于CNN的文本分类模型的SHAP值与自然语言数据.充分利用了SHAP解释在计算局部特征重要性方面的优势,但避免了在解释NLP任务时特征维数高的诅咒.Fidel G[16]提出了一种新的检测方法,使用SHAP为DNN分类器的内部层计算的值,用于区分正常或异常输入.
在即时软件缺陷领域,对模型可解释性的研究较少.在本文中通过SHAP分析,本文进行启发性的特征组合和数据处理,最终目标是提升即时软件缺陷预测模型的准确率.最后使用SHAP分析模型中特征与最终预测结果之间的关系,从而解释复杂的即时软件缺陷预测模型.
3 模型设计
3.1 SHAP-SEBoost框架
本文使用SHAP+SMOTEENN+XGBoost(SHAP-SEBoost)建立即时软件缺陷预测模型.
如图1所示,SHAP-SEBoost模型的流程图包含如下4个步骤:
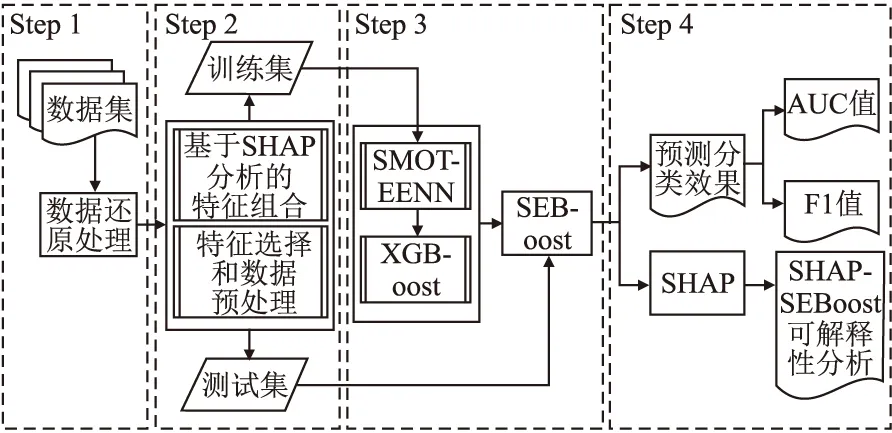
图1 模型流程图Fig.1 Model flow chart
Step1.收集数据集,并对进行数据还原的处理工作;
Step2.根据SHAP分析结果,进行相对应的数据预处理和特征工程;
Step3.本文在Step 3将使用SMOTEENN+XGBoost(SEBoost)作为预测模型;
Step4.选择合适的评价指标评估模型,使用SHAP分析SHAP-SEBoost.
3.2 数据收集和还原处理
为了SHAP分析掌握数据的原始特征分布,利于后续特征组合工作.本文将实验使用的数据集恢复成原始数据特征分布,表1是数据集基本信息.实验数据集其他细节在本文第4节实验设计部分进行概述.数据集信息如表1所示、数据集原始特征含义如表2所示.
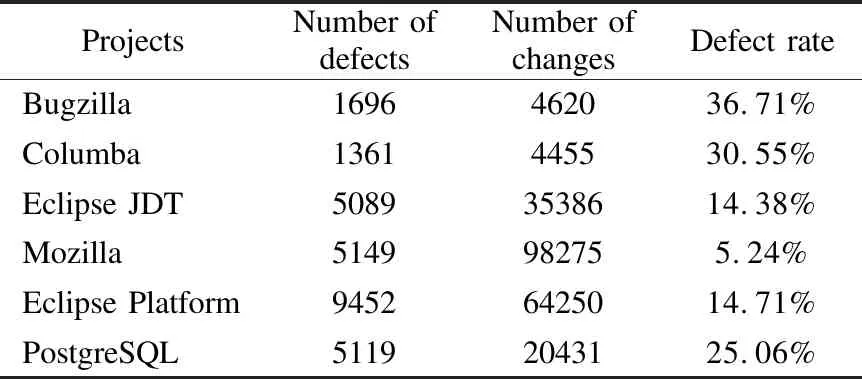
表1 数据集信息表Table 1 Datasets information table

表2 数据集原始特征表Table 2 Original features table of datasets
基于文献[5]的研究,本文对收集的软件缺陷数据进行了以下还原处理:1)将所有数据进行平方项处理;2)LT和NPT分别乘以NF;3)LA和LD分别乘以LT;4)Entropy乘以NF以2为底的对数.
3.3 基于SHAP分析的特征组合
在SHAP中所有特征都视为“贡献者”.对于每个缺陷预测样本,模型都产生一个预测值.SHAP value为该样本中每个特征所分配的数值.
本文在即时软件缺陷数据中,假设第i个代码变更样本为xi,第i个代码变更样本的第j个特征为xij,即时软件缺陷模型对该样本的预测值为yi,整个即时软件缺陷预测模型的基线(通常是所有样本的目标变量的均值)为ybase,那么即时软件缺陷数据的SHAP value服从公式(1):
yiy=ybase+f(xi1)+f(xi2)+…+f(xik)
(1)
其中f(xij)为xij的SHAP值.直观上看,f(xi,1)就是第i个样本中第1个缺陷特征对最终预测值yi的贡献值.当f(xi,1)>0,说明该特征提升了即时软件缺陷预测模型的预测值,对模型具有正向作用;反之,说明该特征使得预测值降低.本文基于SHAP分析对即时软件缺陷数据进行启发性的特征组合.
根据SHAP的summary_plot图片,能够更好的理解特征和模型的内部交互,以此做出创新性的数据预处理.summary_plot图片左侧是数据集的所有特征,右侧是特征值的大小.灰度颜色越深则此特征值越大,反之则越小.横轴表示特征影响模型预测结果的SHAP value.在软件缺陷预测中,SHAP value越大证明模型倾向于此特征会诱发缺陷.
由于篇幅限制,本节选取Columba和Mozilla两个数据集的分析图进行展示.因为这两个数据集比较有代表性,Columba总数据量最少类不平衡率较低;Mozilla数据量最多,且类不平衡率最高.两个原始数据集的summary_plot如图2和图3所示.

图2 Columba数据集分析Fig.2 Analysising of Columba dataset
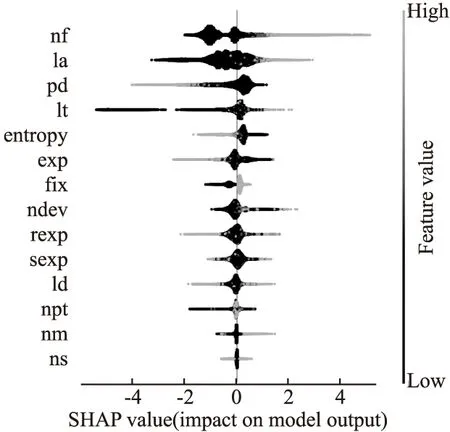
图3 Mozilla数据集分析Fig.3 Analysising of Mozilla dataset
根据两张图片总结出以下软件缺陷数据分布的规律:1)一个程序中定义的子系统、函数库、文件数量越多,越可能产生缺陷;2)对代码增加、删除或者修改的操作越多,越有可能引起缺陷;3)文件内代码行数越多,也有较大可能引起缺陷;4)修复缺陷的位置更有可能出现其他缺陷;5)越多开发人员接触过的代码块,越有可能产生缺陷;6)代码的变更,相隔时间越短越可能出现缺陷;7)代码最后一次更改的次数越多,出现缺陷的概率越大;8)相关程序员的经验越多,变更引起的bug概率会更小.
基于此,可进一步透视数据并构建具有启发性创造性的特征组合.本节基于SHAP分析进行特征组合,具体步骤如下:
1)平均增加代码行数(ALA),增加的代码行数除以文件更改的次数.如公式(2)所示:
ALA=LA/NPT
(2)
2)平均删除代码行数(ALD),删除的代码行数除以文件更改的次数.如公式(3)所示:
ALD=LD/NPT
(3)
3)开发人员经验差距(GEXP1、GEXP2),分别是前开发人员和现开发人员经验差距的绝对值,以及先开发人员和子系统开发人员经验差距的绝对值.如公式(4)、公式(5)所示:
GEXP1=|REXP-EXP|
(4)
GEXP2=|EXP-SEXP|
(5)
此外,还原后的部分特征高度相关,并且大多数数据倾斜严重,所以还需要进一步数据处理.为了应对特征之间多重共线性的风险,本文基于SHAP特征相关图,去除了一些具有高相关度的特征并逐步选择了变量.当某些特征具有强共线性时,模型可能无法可靠地工作.本节实验选择删除LA、LD特征.此外,实验发现NM、NS以及NPT高度相关,删除NM、NS特征.
根据实验,发现还原数据集并进行基于SHAP分析的特征组合效果较好.进一步通过对数据进行归一化能够使模型更方便快速地处理数据.经过上述步骤,基于SHAP分析的特征组合以及数据预处理已经完成.
3.4 SEBoost分类预测
本文使用SMOTEENN+XGBoost(SEBoost)作为核心的预测模型.因为软件缺陷数据存在类不平衡现象,本文使用SMOTEENN[17]算法对训练数据进行处理.首先对软件缺陷数据进行过采样,然后清理数据以进一步删除重复的样本.使得实验使用的软件缺陷数据分布较为平衡,提升即时软件缺陷预测模型的准确性.类不平衡处理只在训练集上使用,测试集等待模型训练完成后直接测试,以保证测试数据的真实性.
最后使用极端梯度提升XGBoost[18]对测试数据进行分类预测.XGBoost是一个CART回归树集成模型,其将K个树的结果进行求和,作为最终的预测值.算法1描述了SEBoost模型预测过程.
算法 1. SEBoost模型
输入:经过基于SHAP分析的特征组合和数据处理的数据集D1,D2,…,Di.
输出:对Di的预测结果Ri.
Step1.将Di分为Dtrain和Dtest.
Step2.将Dtrain中某个少数类样本,采用最邻近算法计算其K近邻,从K近邻中随机挑选N个样本进行随机线性插值,构造新样本(SMOTE).
Step3.Dtrain中某个多数类样本,如果其K个近邻点有超过一半都不属于多数类,则这个样本会被剔除(ENN).


Step6.将Dtest输入到M进行分类预测,得到Ri.
4 实验设计
4.1 数据集
本文使用的数据集由Kamei等人收集,是即时软件缺陷预测领域最为经典以及代表性的数据集.下面详细介绍这些开源数据集:
Bugzilla:开源的软件缺陷跟踪系统;
Columba:开源的CVS项目库,记录了大量的软件缺陷报告;
Eclipse JDT:Eclipse平台中一个功能齐全的Java集成开发插件;
Mozilla:网页浏览器;
Eclipse Platform:Java集成开发平台;
PostgreSQL:一种数据库管理系统.
表3描述了数据集经过特征组合和数据预处理的余下特征含义,新增的已经用黑体加粗.数据集余下特征如表3所示.
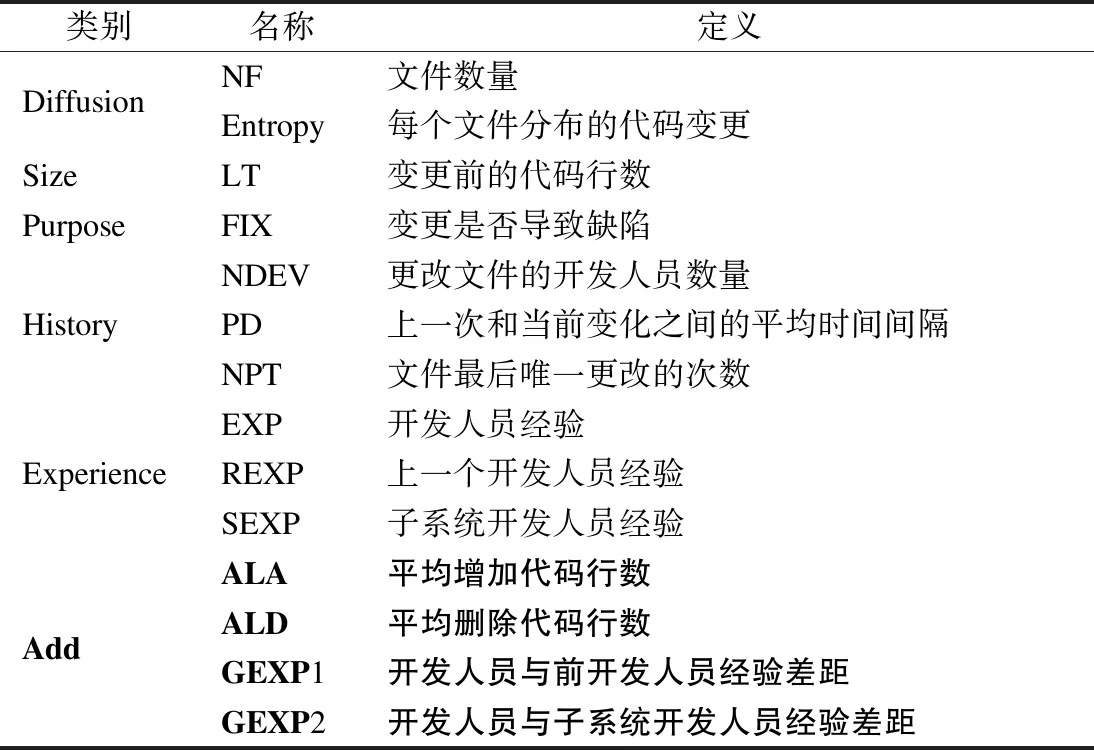
表3 数据集余下特征Table 3 Remaining features of the dataset
4.2 实验环境
本实验中,采用Pycharm专业版和Python3.8来构建即时缺陷预测模型.实验运行环境是windows10专业版,配有4.1GHz的因特尔i5-10600kf处理器和16G内存.
4.3 评价指标
评价指标一般是根据混淆矩阵的结果进行计算.即时软件缺陷预测是一个二分类问题,因此选用AUC和F1值作为模型评价指标.
本节将介绍评价指标相关的一些概念和定义,如混淆矩阵、精确率(Precision)、召回率(Recall)、F1值(F1-measure)、ROC曲线以及ROC曲线下方面积(AUC).如表4所示,混淆矩阵中每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别.其中,TP(True Positive)表示被正确预测的有缺陷数量,TN(True Negative)表示被正确预测的无缺陷数量,FP(False Positive)表示被错误分类为有缺陷实际无缺陷的数量,FN(False Negative)表示被错误分类为无缺陷实际有缺陷的数量.

表4 混淆矩阵Table 4 Confusion matrix
F1值:软件缺陷预测领域通常使用 F1值作为模型评价指标,它是精确率和召回率的调和平均值,其中F1值为1时达到其最佳值(最佳的精确率和召回率),在0处则为最差值.F1值公式如下:
(6)
其中Precision是精确率,用于评价模型正确标注为有缺陷的实例数量与真正有缺陷的实例数量的比例.精确率又称为查准率,其值越大越好.精确率公式如下:
(7)
Recall是召回率,用于评价模型正确标注缺陷实例的比例.召回率又称为查全率(True Positive Rate 或 PD),召回率越大越好.召回率公式如下:
(8)
ROC curve:根据模型分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve,横坐标为False Positive Rate(FPR假正率),纵坐标为True Positive Rate(TPR真正率).ROC曲线越接近左上角,该分类器的性能越好.ROC曲线如图4所示.

图4 ROC曲线Fig.4 ROC curve
Area Under Curve(AUC)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1.又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间.AUC越接近1,检测方法真实性越高;等于0.5时真实性最低,无应用价值.
5 实验结果与模型分析
5.1 同项目十折交叉验证
实验考虑了同项目十折交叉验证方案来评价SHAP-SEBoost的分类性能.使用AUC和F1两项评价指标,取每次实验结果的平均数.
十折交叉验证方法:首先需要随机打乱数据集,然后将数据集分为10份,即十折之后对每1折都作为测试集,另外9折作为训练集,训练预测模型并进行验证计算性能指标,一共运行10次实验,最后将每次得到的性能指标求平均值作为十折交叉验证的评价结果.实验将SHAP-SEBoost和其他模型进行比较,使用十折交叉验证对6个开源项目数据集进行分类预测.较好的AUC或者F1指标将会用黑体标注,实验结果如表5所示.

表5 模型实验结果对比Table 5 Comparison of model experimental results
在表5中,第2行-第7行分别给出了SHAP-SEBoost和其他4种模型在6个数据集上的AUC结果.第8行是每个模型的平均AUC值.第9行(W/D/L)展示了每个预测模型在6个数据集上预测结果的胜利次数.其他4种模型中拥有最高AUC预测值的是基线模型—0.80,最低的是NeuralForest—0.65.而SHAP-SEBoost的平均AUC为0.82,相较于传统算法模型平均提高了11.6%.其中值得注意的是,SHAP-SEBoost在Mozilla数据集的AUC预测结果为0.85,是所有模型中对单个项目进行预测得到的最高AUC指标.
第10行-第15行分别给出了SHAP-SEBoost和4个传统算法模型在6个数据集上的F1结果.第16行是每个模型的平均F1值.第17行(W/D/L)展示了每个预测模型在6个数据集上F1值预测结果的胜利次数.除了SHAP-SEBoost以外,F1指标最高的预测值是BaselineModel—0.78,最低的是Kamei—0.45.SHAP-SEBoost在Mozilla数据集的F1预测结果为0.93,是所有模型中对单个项目进行预测得到的最高F1指标.SHAP-SEBoost相较于这些模型平均提高了33.5%.
综上可得出结论,SHAP-SEBoost的分类性能上完全优于其他传统算法模型.基于同项目十折交叉验证的实验结果表明,SHAP-SEBoost对比其他传统算法构建的即时软件缺陷预测模型,在AUC上平均提升了11.6%,F1平均提升了33.5%.证明本文选取SMOTEENN和XGBoost作为核心模型的合理性.
从图5中可以看出,使用SHAP-SEBoost预测的 AUC值在0.80-0.85之间,平均值为0.82;使用基线模型预测的AUC值在0.80-0.81之间,平均值为0.80.除Columba以外基准模型AUC值普遍低于SHAP-SEBoost;LocalJIT的AUC指标0.70-0.76之间;Kamei模型的AUC指标0.74-0.79之间;NeuralForest的AUC指标在0.62-0.68之间.除了SHAP-SEBoost,其他4种模型平均AUC指标为0.73.

图5 AUC值对比图Fig.5 Comparison graph of AUC values
图6的F1指标可见,SHAP-SEBoost在类不平衡率越高的数据集(Mozilla--0.93)效果越好.在Postgres上F1指标最好的是基线模型,其他4种模型平均F1指标为0.6,Kamei作为即时软件缺陷预测的开山鼻祖,本文模型相较于提升81.5%.
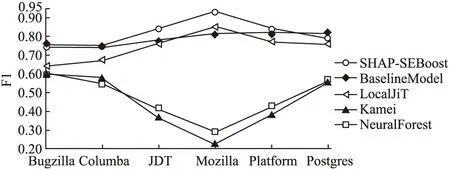
图6 F1值对比图Fig.6 Comparison graph of F1 values
综合表5、图5和图6,SHAP-SEBoost对比基线模型以及其他文献的预测模型,在AUC和F1指标上有明显提升,分别提升了11.6%、33.5%.与近年优秀模型相比的结果证明本文提出方法的可行性,更加证明了高准确率的即时软件缺陷预测模型不仅依靠强大的机器学习算法,更需要创新的特征工程和数据处理.
5.2 模型可解释性分析
在本文的最后,使用SHAP的summary_plot图片解释来自复杂算法SEBoost的结果.图7和图8将展示SHAP-SEBoost模型中各类特征对最终预测的影响.SHAP-SEBoost模型可解性分析如图7、图8所示(选取Columba和Mozilla进行展示).
由图7可知,基于SHAP分析的特征组合阶段增加的ALA、ALD、GEXP1、GEXP2 4个特征,ALA排在第8位、ALD排在第7、GEXP1排在第5、GEXP2排在第6.在图8中,ALA特征重要性排到了第2位、ALD排在第7位,对模型预测贡献大,GEXP1和GEXP2排名不理想,分别在12/13位.

图7 模型可解释性分析(Columba)Fig.7 Model interpretability analysis(Columba)
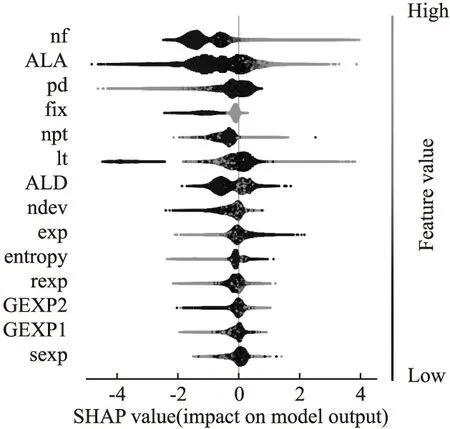
图8 模型可解释性分析(Mozilla)Fig.8 Model interpretability analysis(Mozilla)
图7清晰表明,ALA和ALD特征取值越大则模型预测缺陷的发生概率就越高.某个代码文件中增加或者删除的代码越多,发生BUG的概率就越大,这是符合软件工程实际的.开发人员的经验差距:GEPX1和GEXP2取值越大模型预测缺陷发生概率则会降低.
图8是Mozilla数据集在SHAP-SEBoost的可解释性分析.与Columba不同的是,极端类不平衡数据样本在模型内部的表现也出现特殊情况.ALA特征和其他数据集相同,取值越大模型越倾向于预测样本发生缺陷.然而,ALD特征取值越大,SHAP值接近于0,那么对模型预测贡献很小;取值变小时模型预测可能没发生缺陷也可能发生缺.在经验差距(GEXP2)特征方面,从图8还可以看出,经验差距越大,缺陷发生的概率也越高(有几处异常点,可能是由于SMOTEENN进行类不平衡处理后导致).可能源于这样一个事实:当开发人员和子系统开发人员的经验差距过大时,代码规范和代码能力会有很大差距,子系统开发人员提交代码后发生BUG的概率就会增加.GEXP1特征取值变大时,SHAP值降低,模型预测倾向数据样本没有发生缺陷.这里和GEXP2有所不同,GEXP1作为开发人员与前开发人员的经验差距拉大,则发生缺陷概率会降低.
实验最后为每个模型的每个特征绘制相应的SHAP值,不仅能评价特征对模型输出影响的重要性和方向,还能提取特征对模型输出的复杂非线性联合影响.这可以更好地理解整体模型并允许发现预测异常值,便于未来的挖掘研究.综上,证明本文提出的基于SHAP分析进行特征组合和数据处理工作的有效性,方法有效地提高了即时软件缺陷预测模型的性能.
5.3 有效性因素分析
本节从两个主要角度分析了所提出的即时软件缺陷预测模型的有效性:外部有效性和内部有效性.外部相关性反映了从实验研究得出的结论是否具有普遍性.本文使用六个开源项目数据集,均为可以从公共数据库中获取项目程序模块所有静态度量元的数据集,这些数据具有一定的代表性,从而确保研究结论的正确性.内部有效性影响实验结果的准确性.本文编写的代码主要基于Python的SHAP模型可解释包和Scikit-learn机器学习包,以确保模型构建的准确性.从模型的准确性和稳定性方面来看,确保度量标准的可靠性是使用AUC和F1值评价指标.
6 结束语
本文在即时软件缺陷预测中创新地使用了SHAP模型可解释性分析来进行相应的特征工程,并且将SMOTEENN类不平衡处理方法与集成学习XGBoost相结合,对6个开源项目的近22万条代码变更进行分类预测.实验结果表明,本文提出的SHAP-SEBoost与其他模型相比获得了更好的分类效果.最后再次使用SHAP解释复杂的SHAP-SEBoost模型,让算法黑盒变成易理解的图片,帮助开发人员理解即时软件缺陷缺陷预测模型.今后的研究将关注如何更深层次优化类不平衡数据分布、如何优化集成学习算法的处理过程,从而获得更快的模型运行时间、更高的预测准确率.
