基于权重增强的方面级情感分析模型
2022-05-09齐嵩喆黄贤英朱小飞
齐嵩喆,黄贤英,朱小飞
(重庆理工大学 计算机科学与工程学院,重庆 400054)
1 引 言
方面级情感分析ABSA(Aspect-Based-Sentiment-Analysis)是细粒度情感分析的一个分支.例如:“Great food but the service was dreadful!” 这句话包含两个方面词“food”和“service”,对应的观点分别是“Great”和“dreadful”,表达的情感极性分别是积极和消极.ABSA的任务就是根据上下文的语义关系、方面词的特征信息、以及每个方面对应的观点词来判断出每个方面的情感极性.
方面级的情感分析对于各行各业都有着重要的意义.在电子商务领域,对用户购买商品的评价进行方面级情感分析,可以迅速了解用户的消费习惯和购买喜好;通过对社交评论进行方面级的情感分析可以准确地了解民众对于相关政策的态度.Wu等人[1]提出一种基于概率图模型的情感分析方法,结合SVM进行分类,通过理论证明了模型的可行性,且在实验中表明在含有潜在情感的文本中具有良好的表象.
目前,关于方面级情感分析的研究更多是基于深度学习的方法来展开研究的,并且都侧重于通过获取方面词的相关语义表示来判断情感极性.Bahdanau等人[5]首次将RNN(Recurrent Neural Network)和注意力机制结合并应用到在机器翻译任务中,取得了出色的结果.之后,Ma.等人[6]将注意力机制运用到了方面级情感分析任务中.通过注意力机制对原文本的词语赋予不同的权重,从而利用加权特征对于方面词的情感极性进行预测,并通过实验验证了注意力机制对于该项任务的有效性,但是没有考虑到注意力机制可能会增加噪声并对实验结果产生影响,例如:否定副词:hardly,never等,都可能被注意力机制忽略其重要性,从而导致分类错误.Wang等人[7]使用LSTM(Long Short Term Memory)来结合注意力机制建立分类模型,LSTM可以有效地避免RNN的梯度消失和梯度爆炸的问题;注意力机制可以用来捕捉方面词的相关语义.但是,相较于单层的注意力机制,Tang等人[8]通过多层注意力机制来获取更深层次的情感特征信息.He等人[9]提出在注意力机制的基础上添加句法约束来降低噪声对于模型的影响,但是对于句法结构的利用不够充分.Xue等人[10]提出将卷积神经网络CNN(Convolutional Neural Networks)应用到该类任务中,但是卷积神经网络只能融合连续词语的特征,不能有效的处理非连续词语所表达的情感.Zhang等人[3]提出一种基于有序神经元长短时记忆和自注意力机制的方面情感分析模型(ON-LSTM-SA),结合深层语境化词表征进行预训练,在多个数据集上效果有所提升.Chen等人[4]提出一种基于双向切片门控循环单元和注意力机制(Bi-SGRU-Attention)结合的情感分类模型,用以解决切片操作导致的低层网络的长期依赖性损失和单向SRNN无法充分提取文本语义特征的问题.Chen[11]等人则表示文档级的语义知识可以增强方面级情感分析的效果,通过构建方面级和句子级两个层次的语义胶囊提出了一种迁移胶囊网络(TransCap),但是忽略了句法信息.Zheng等人[12]提出了一种基于随机游走的RepWalk神经网络模型,发掘依存树中与情感极性相关的特定子树,有效地利用了树形结构.
Kipf等人[13]提出将图卷积GCN(Graph Convolutional Networks)应用于文本分类任务中.GCN是一种具有多层网络的结构,其中每一层在更新权重时都会融合节点的邻接信息,通过实验验证在文本分类方向上比CNN的性能更佳.根据前人的研究成果,Zhang等人[14]将完整的句法依存树(Syntactic dependency tree)和图卷积相结合来完成方面级的情感分析任务,取得了更好的效果.而Li等人[15]在Zhang的基础上加入掩码机制和位置编码并采用注意力机制来进行分类,相比之前的方法更加充分的利用了句法依存树的结构信息,而且掩码机制和注意力机制的结合能有效的提升模型的性能.Sun等人[16]提出一种更加朴素的图卷积模型,通过图卷积融合句法,词性和位置等特征信息来增强Bi-LSTM的上下文特征表示.但是没有考虑方面词和非方面词的句法关系对于注意力机制影响的差异性,为了弥补上述研究存在的空缺,本文提出了一种基于权重增强的改良型图卷积神经网络模型AW-IGCN(Aspect-weighted Improved-Graph Convolutional Networks).
AW-IGCN模型通过加载预训练词向量的方式将文本编码为词嵌入向量,然后利用双向GRU序列获取上下文的语义信息;与此同时,构造文本的句法依存树,并将其转化为邻接矩阵输入到模型中,考虑到方面词和非方面词的句法依存关系对于目标情感的重要性是不同的,通过权重增强的方法,将原有的无权依存树矩阵转化为带权矩阵以存储更多的信息,从而给予与方面词存在句法依存关系的节点更高的权重.在图卷积融合部分,使用squash函数[17]代替ReLU函数来改良图卷积网络,避免ReLU函数输入负值后神经元失活所导致的信息遗漏.后续实验验证了这两种方法均能在一定程度上提升模型的性能.
2 AW-IGCN模型
AW-IGCN模型如图1所示,整体可以分为词嵌入层、上下文语义抽取层、句法提取层、语义融合层、掩码机制层、注意力权重分配层以及最终的情感分类层.
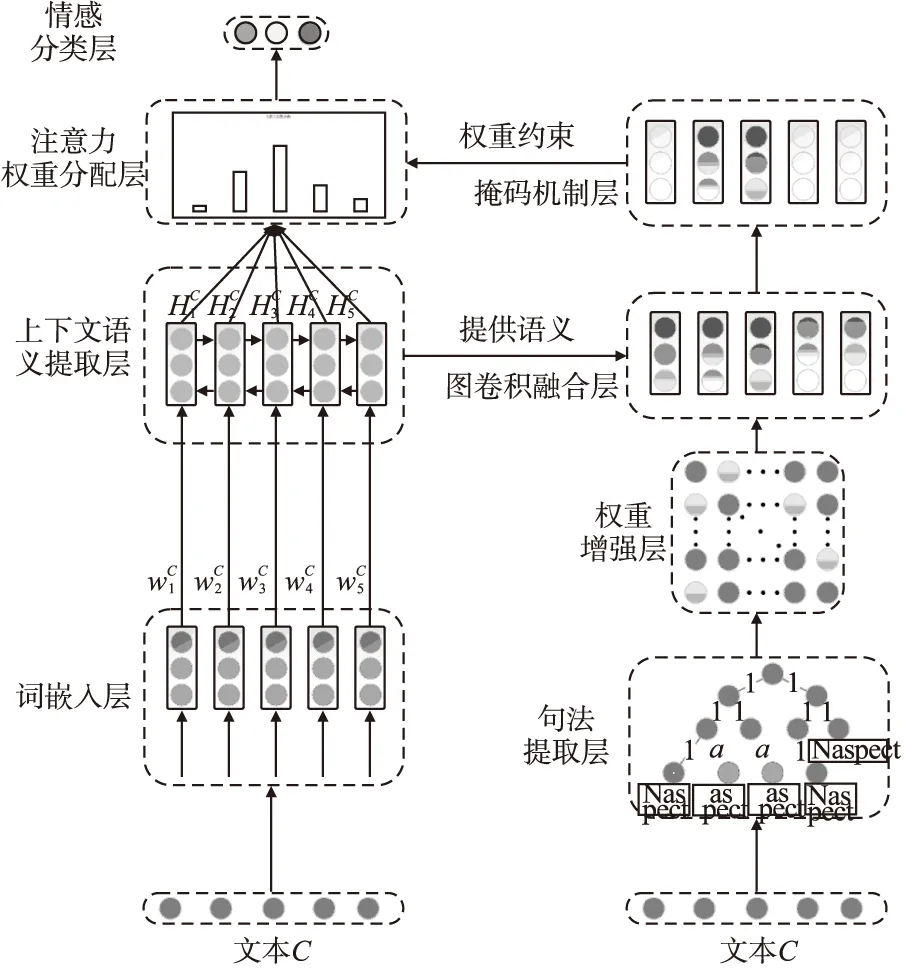
图1 AW-IGCN模型Fig.1 AW-IGCN model
2.1 词嵌入层

2.2 上下文语义提取层
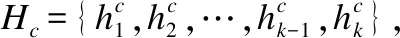
(1)
(2)
(3)
2.3 句法提取层和权重增强层
句法依存树是通过分析语句成分之间的依存关系来获取其句法结构.对于方面级的情感分析,通过提取每个词或短语的依存关系,能更准确地获得指定方面词的修饰成分.对于生成的句法依存树,节点表示词语,节点与节点的连接表示词与词之间的依存关系.
依存关系通常以无权图邻接矩阵的形式输入到模型中,本模型为了充分利用句法信息,通过转换函数将每一句文本的依存关系邻接矩阵转换为带权矩阵,这一步骤称为权重增强.转换函数取决于方面词的依存关系,具体的函数定义方式如下:对于一句由k个单词构成的文本,其中τ表示对应方面词或短语的长度,A∈Rk×k表示对应的依存关系矩阵,转换函数如下:
A′=C×A×C
(4)
其中C∈Rk×k对于主对角线元素cij∈C,cnn~cn+τn+τ=α,其余部分的cii均为1,非对角下元素为0.α为句法依存树矩阵的权重增强系数,其取值通过后续对比实验结果得出,当K=2时,模型能够取得最佳分类效果.
2.4 语义融合层

(5)

(6)
其中,s为待输入的向量.
通过在双向门控循环序列的上方使用上述的改良图卷积IGCN结构来融合结点信息,与此同时根据kipf等人[7]的方法,在实验时向IGCN中加入其自循环约束,即每个节点都设置一个指向自身的连接,最终实验对每个结点的更新方式如下:
(7)
(8)
2.5 掩码机制层与注意力权重分配层
在获得基于方面级的信息融合向量后,通过将向量输入到注意力机制,来获得与方面词更相关的词或短语的权重分配,但是在这之前,为了保持方面词的向量表示不受到影响,整句语料的向量表示需要经过掩码机制的处理.掩码机制是通过将非方面词对应的节点向量置位0,保持方面词节点对应的向量不变,操作方式如下:
(9)
随后,使用特殊的方面词注意力机制,来检索整句语料的向量表示中对于方面词的情感极性的判别有着重要作用的单词或短语,并根据重要程度予以权重分配.通过将掩码机制层的输出直接输入到特殊的方面词注意力网络层中,从而获得每一个词对应向量表示的权重分配,其权重计算方式如下:
(10)
(11)
其中αt是得出的待分配权重,最终的权重分配公式如下:
(12)
2.6 情感分类层
将获得的带权语义特征表示向量r,输入到一个全连接层后,接着使用softmax分类算法将语义向量映射到一个与预设情感极性空间维度相同的概率空间:
P=softmax(Wpr+bp)
(13)
其中P的维度与情感极性的标签种类数是相同的,权重矩阵wp和正则项bp是可被训练的参数.
3 实验设计及结果分析
3.1 实验数据
本研究的相关实验将在5组公开的数据集上进行,分别是Twitter短文本评论数据集,以及来自于SemEval 2014任务4 的Rest14和Lap14数据集,来自于SemEval 2015任务12 的Rest15数据集,来自于SemEval 2016任务5的Rest16数据集.在进行实验之前,我们将数据进行了一定的预处理:去掉了没有明确表明方面词的评论语料的语料,实验数据设置如表1、表2所示.

表1 实验数据设置Table 1 Experimental data settings

表2 实验数据样例Table 2 Experimental data example
3.2 实验流程
数据的预处理:对原始数据集首先进行格式上的处理,清除数据集中的HTML标签;为了适应模型文本方面词的同步输入,将方面词从每一句文本中抽取出来,然后在文本中使用统一的特殊符号来替换方面词.为了更好的学习文本结构特征,在使用预训练词典的同时分别附加30维的词性编码和相对位置编码,由于采用的数据集多为短文本评论,所以只采用补全的方法,在词嵌入完成后把文本向量的长度补全到与其当前所在batch的最长文本相同.
图结构的生成:为了提升实验效率,文本的图结构部分独立于模型训练来生成,使用spaCy框架来获取文本的句法依存树,对依存树进行权重增强后以矩阵的形式保存成序列文件以备输入.
模型的训练与调整:训练一共设置100个训练轮次,当连续5个轮次loss值不再发生改变时进行early stop.在每种数据集上进行不同的随机初始化训练3次,取3次的准确率和F1-score得平均值作为最终实验结果.
3.3 实验配置和超参数的设置
本模型进行的一系列实验统一选择GloVe预训练词向量作为初始化的词嵌入,BatchSize设置为16;为了避免过拟合,在实验中双向GRU的输入端应用了Dropout,整个模型的权值矩阵使用正态分布来进行初始化,使用Adam作为模型的优化器,具体的超参数以及实验环境配置明细如表3、表4所示.

表3 实验环境及配置Table 3 Experimental environment configuration
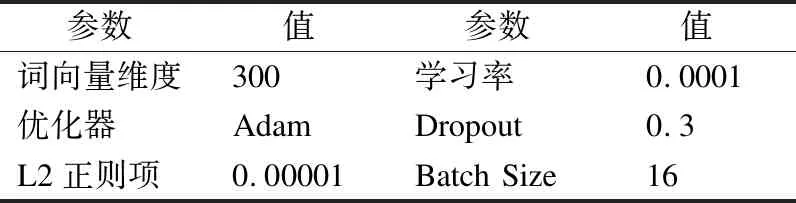
表4 实验超参数明细Table 4 Experimental parameter configuration
3.4 损失函数
本模型采用的损失函数是交叉熵损失函数,并使用L2正则化来增加模型的泛化性.其中,C代表数据集,t代表情感极性的输出集合,λ代表L2正则化的系数,评论文本和方面词是成对给出的,即一组数据可以表示为(c,t).
(14)
3.5 模型对比实验
本文的目的在于提升方面级情感分析的准确性和稳定性,因此结合其他相关研究文献提出的模型设立了以下多组对比实验,其中所有的模型的采用相同的数据集,实验参数配置严格遵照原文献,其中带有*标的对比模型实验结果直接引用自原文献,N/A代表未获得的实验结果.
SVM:Kiritchenko等人[20]建立的模型,通过采用经典的SVM分类模型和进行一些具有针对性的特征处理,在SemEval 14的任务4中获得出色的成绩.
LSTM:Tang等人[21]使用LSTM的最后一层输出向量作为整个句子的语义表示并结合方面词信息来预测情感极性.不过该方法虽然考虑了方面词信息的作用,但是没能充分利用方面词与它上下文之间的关联.
MemNet:Tang等人[8]利用一种加入注意力机制的深度记忆网络,并且在注意力机制中加入了位置特征,实现了对于方面级情感极性的分类,并在多个方面级情感分析的数据集上取得了比传统LSTM模型更好的效果.
AOA:Huang等人[22]将机器翻译领域的AOA(attention-over-attention)机制应用到方面级情感分析中,通过AOA模块,模型可以共同学习方面和句子的表示形式,并自动关注句子中的重要部分.
AEN-GloVe:Song等人[23]通过平滑标注来处理中性方面词情感模糊的问题,结合多种注意力机制对方面词和文本极性建模.
IAN:Ma等人[6]认为方面词和情感语料是具有交互性的,因此通过将方面词和整句语义相互融合,并结合注意力机制,从而达到方面级情感分类的目的.
ASCNN:Kim等人[24]提出采用CNN作为基础建立模型,通过预训练的词嵌入作为输入,使用CNN网络层来获得文本的情感特征,但是该模型只采用了最基础的CNN模型结构,在方面级的情感分析任务中效果一般,但是验证里CNN网络层确实具有优秀的语义抽取能力.因此,为了验证GCN和CNN的语义提取效果的差别,设置对比实验使用CNN网络结构来替代GCN网络结构部分,并结合注意力机制来进行方面级情感分析.
ASGCN:Zhang等人[15]提出一种基于图卷积和句法依存树的模型,对方面词和语义信息同时建立表达形式,用注意力机制进行二者的交互.
ATBL-MHMN:Lu等人[2]通过将LSTM获取序列信息和多跳记忆网络获取方面词的分类特征相结合,来着重考虑临近方面项的依赖关系对情感分析的影响,最终使用注意力结合和softmax来获得分类结果.
RepWalk:Zheng等人[12]通过在句法依存树上进行随机游走的方法来确定与情感极性相关的特定子树,建立神经网络模型获取更加准确的上下文信息,从而进行方面级的情感分析.
TranCaps:Chen等人[11]通过迁移学习来引入文档级情感信息来增强方面级的情感分类,建立双层语义胶囊网络(方面级胶囊和句子级胶囊)通过适当的扩展路由机制来完成情感分类任务.
CDT:Sun等人[16]融合了句法、词性、位置和语义特征信息,提出了一种结合图卷积和Bi-LSTM的轻量级模型,缩短模型训练代价的同时提升了分类效果.
实验的评估指标是分类准确率(Accuracy)和F1值(F1-score).准确率是相关研究中的常用指标,而F1值是综合考虑了模型准确率和召回率的计算结果,取值更偏向于二者中结果较小的那个指标,从而更能说明模型的整体性能.最终的结果为3次随机初始化实验结果的平均值.对比实验结果如表5所示,AW-IGCN模型在所有的数据集上都达到了最优的效果.

表5 模型测试结果Table 5 Test results of models
对比ASCNN和ASGCN可以发现:尽管加入了注意力机制,可以有效地避免CNN在方面级情感分析上的能力不足,但是通过对比试验结果可知,在这种以句法依存树邻接矩阵作为主要输入形式的模型中,GCN在语义抽取方面的表现更好.
通过对比模型在5种不同数据集的效果提升幅度,可以发现AW-IGCN在准确率这一指标上明显在LAP 14上取得了更好的改进效果,相比在其他3个餐厅评论以及Twitter评论数据集提升效果微弱,为了探究产生这种差异的原因,我们仔细观察LAP 14与REST各数据集发现:相对于前者,后者的3个数据集的正负样本比例更加不均衡,我们认为这是导致准确率提升效果不够显著的原因之一;本实验结果中F1值在除Twitter以外的四组数据集上均有一定提升,这足以说明,AW-IGCN相对于分类的准确性来说,对于分类的稳定性提升更大.但是在Twitter数据及上与RepWalk模型性能相比仍存在一定差距,经过对数据的统计和模型结构剖析,我们认为造成这种现象的原因主要是AW-IGCN对句法依存树的权重增强更注重规则,RepWalk对于特定子树的选择更加依赖于随机游走,在面对类似Twitter这种句法结构相对自由,且存在大量不规范语法的文本时(如:大量感叹词,颜文字等),这些噪声相比于RepWalk模型,对于AW-IGCN的影响更大,这也是后续研究我们需要解决的重要问题之一.
3.6 结果测试举例与分析
为了更加直观的了解模型对于方面级情感分析的性能,我们从对比实验数据集中抽取出实例文本来进行情感分析,从而展现本文模型的优势与不足,对比结果如表6所示.

表6 对比测试举例Table 6 Comparative test example
在第1句文本中:Great food but service was dreadful,含有两个方面词且极性相反,这是一句能够体现方面级情感分析任务特性的典型例子,Memnet对于两种情感均分类错误;IAN两者均能够分类正确;对于以CNN为基础的ASCNN模型只能分类正确一部分,在一定情况下也说明了CNN在处理双方面相反极性的问题时存在一定的欠缺.在第2句文本中,虽然出现了通常作为积极情感修饰语的friendly,但是因为a bit的修饰导致情感极性发生了翻转,这也是在情感分析中存在的一项任务难点,这可能是导致Memnet和IAN分类错误的原因;但是在AW-IGCN中,对于这两个例子都能够分类正确,也通过在关键问题上的对比,能够充分体现本模型在方面级情感分析问题上具有更好的泛化性.
3.7 消融实验设计及结果
为了更明确的研究影响模型效果的独立因素,本研究设置了多组消融实验:
3.7.1 权重增强系数α
首先,为了探究权重增强系数α的取值对于模型分类效果的影响,通过枚举不同的α值在各个数据集上进行对比实验,其中α∈{1,2,3,4,5,6}.实验结果对图2所示,通过可以看出在α=2时.模型在5种数据集上均取得最佳准确率.
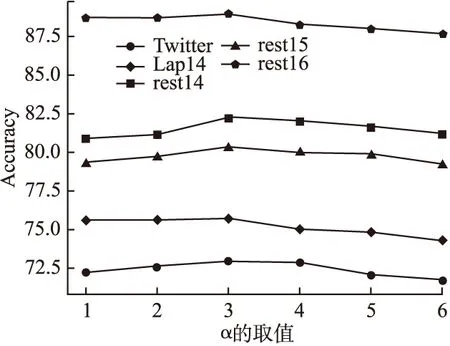
图2 α的取值对于模型的影响Fig.2 Effect of α on the model
3.7.2 squash与ReLU对比实验
除此之外,为验证squash函数相对于ReLU函数的优越性,设置对比实验,移除模型中权重增强这一步操作,依旧使用普通的无权矩阵表示句法依存树,从而将IGCN退化为GCN.
实验结果如图3所示,可以清楚地看出虽然squash函数对模型性能产生的影响大小不同,但是在多个数据集中都能够比ReLU函数有更好的分类效果.
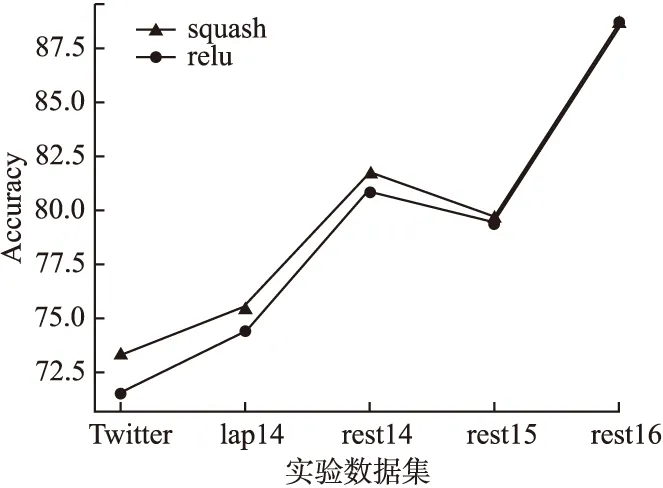
图3 squash和ReLU的模型效果比较Fig.3 Comparison of model effects between squash and ReLU
3.7.3 IGCN与GCN对比实验
为了验证改良的图卷积对于模型性能的提升,在保留模型的其他部分不更改的前提下,我们进行了IGCN和普通的GCN的对比实验,如图4所示.结果表明,单纯地使用IGCN确实比普通的GCN能获得更好的分类效果.
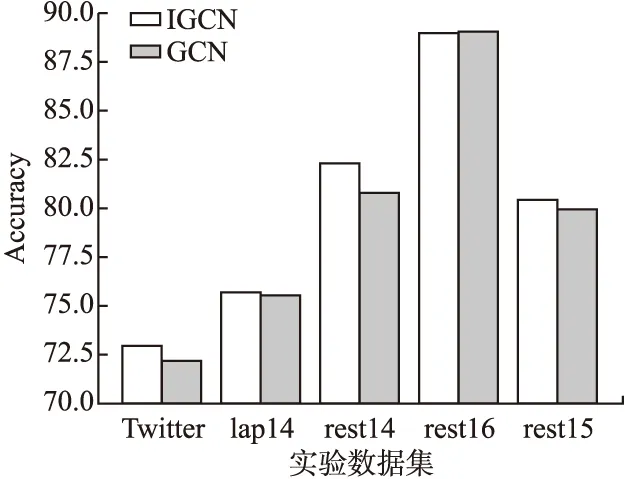
图4 IGCN和GCN的模型效果比较Fig.4 Comparison of model effects between IGCN and GCN
综上所述,无论是单纯的采用IGCN网络结构还是独立应用squash函数对于模型都是有一定的效果提升的,而且在上述5种数据集中二者相结合的时候能够获得相对更好的效果,这与我们的预期结果是相同的.
4 结束语
为了解决句法关系利用的单一性,本文提出了AW-IGCN模型来进行方面级情感分析任务:通过权重增强机制来增强语句的依存关系表示;利用squash函数的优势来克服ReLU函数的信息丢失问题,在不同的公共数据集上通过实验与其他模型进行比较,均取得了更加优秀且稳定的分类效果,也验证了附加权重增强的句法依存树能够提升图卷积机制表示的有效性.
虽然本文提出的模型在多个公共数据集上取得了实验效果上的提升,但是对于权重增强的过程还可以考虑将依存关系的种类作为判定依据,从而对于矩阵中每个向量的权重采用不同的增强方式,这可以作为未来继续提升模型效果的一个研究方向,并设计实验进行验证分析.
