基于混合编码的社交媒体英语文本情绪检测
2022-05-08黎家宁
黎家宁
(大连民族大学 外国语学院,辽宁 大连 116600)
世界各地的人们都在大量使用Twitter和Facebook等社交媒体平台来表达自己的观点。这些平台的广泛应用使得文本数据丰富,为自然语言处理领域的研究提出了各种挑战。在这些挑战中,检测文本中传达的情感在各个领域都具有重要意义。分析社交媒体文本内容中表达的情感,对于评估人们在产品评价、电影评价、对新出台政府政策的接受等应用中的理解力非常有用,这就增加了检测它的必要性。在社交媒体中,人们倾向于使用不遵循标准句法结构的非正式表达方式,使分类成为一项具有挑战性的任务。
首先,理解文本中表达的核心观点仅限于情感分析[1],其中基于句子中极性矛盾的分类,即是否表达任何积极、消极或中性的行为,也可以称为观点挖掘。在后期阶段,它已经进化到识别更精细的情绪水平。这种情绪检测和分类的目的是识别精炼的情绪,如快乐、悲伤、愤怒。由于大量的单语语料库的可用性,大多数有关情感检测的研究分析都是在单语数据上进行的。然而,公众属于多语言领域,当他们涉足社交媒体时,通常使用代码混合语言[2]。码混叠识别是将一种语言的形态成分嵌入另语言话语中的语义表达现象。这种用法在多语言社会中非常常见,人们在使用社交媒体平台时,将一种语言的单词翻译成另一种语言,而不遵循任何标准的语义结构。
印度是一个多元化的国家,在文化、语言和时尚方面,异质性在全国普遍存在。13亿人在印度使用大约1 600种语言。受至少2种语言的影响,印度公民往往在社交媒体上经常使用混合语言。印地语是这个国家使用最多的语言。超过45%的人口以印地语为母语,这使得印度英语(印地语+英语)混合的社交媒体文本内容过多。下面是一些直接从社交媒体上根据一些流行事件提取的印度-英语代码混合文本样本及其翻译。
文本1:Aaj ye government ek shaandar decision le liya Article 370 koscarp karke.
翻译:今天,本届政府做出了一个伟大的决定,废除了第三百七十条。
文本2:Indian team ke liye bura lag raha hai,they should have won.
翻译:真为印度队难过,他们本该赢的。
文 本3:Pulwama attack ki news dekh kar bahut gussa aa gaya.Hamare armed forces jaroor retaliate karna hein.
翻译:当我看到普瓦马袭击的新闻时,我非常生气。本文的武装部队一定要报复。
正如给的例子所描述的,在代码混合文本中,印地语单词被音译成罗马文字,并与英语单词一起书写。在文本1中,快乐的情绪是通过赞扬政府作为shandara决定所采取的步骤来表达的;在文本2中,短语bura lag raha haisigne表达的悲伤的情绪;在文本3中bahut gussa aa gayain表达愤怒情绪。这类句子的语义复杂性和句法结构的异常变化使得在代码混合的文本数据中进行情感检测非常困难。由于数据的缺乏,该情感检测任务在印地语-英语代码-混合语言领域的研究程度较低。
本文的目标是检测和分类这些代码,混合文本表达的情感。为了解决这一问题,将Vijay等[3]人的印地语-英语代码混合文本情绪检测任务作为工作的基线。作为初步的努力,本文主要集中在数据的收集。因此,在他们提供的数据集的基础上,还从各个平台上抓取了codemixed social media内容,共收集了12 000条文本。工作考虑的情绪类别是快乐、悲伤和愤怒,每个文本都手工注释与之相关的情绪。
1 数据收集及描述
Vijay等[3]人完成了印地语-英语代码混合数据中情感检测的基本工作。他们提供的数据集是这项工作的基础数据,基于此,开始了语料库的创建,收集更多的代码混合文本的数据,意图更好地统计意义的分类。Twitter API用于提取代码混合的tweet。本文使用了一个python库tweepy,并在程序生成文本数据。除了Twitter API外,Facebook和Instagram的评论也被汇集在一起以获取所需的数据。内容提取使用了很多关键词,一些热门的是三重塔拉克,巴拉克袭击,CWC2019,Chandrayaan2,Election2019,克什米尔问题,外科手术式打击,莫迪,Jio Fiber,PV Sindhu。由于这些活动吸引了如此多的公众关注,可以很容易地获得多种情感内容。通过对Vijay等人数据集的收集和分析,共收集了12 000个印地语-英语代码混合文本。数据类和每个数据类中出现句子数量的详细描述见表1。每堂课的课文数量保持统一,避免班级失衡问题。每一篇文章都有相应的情感注解。实验中考虑的情感类有快乐、悲伤和愤怒。注释是由2个拥有2种语言知识的人通过指定的指令手工完成的。
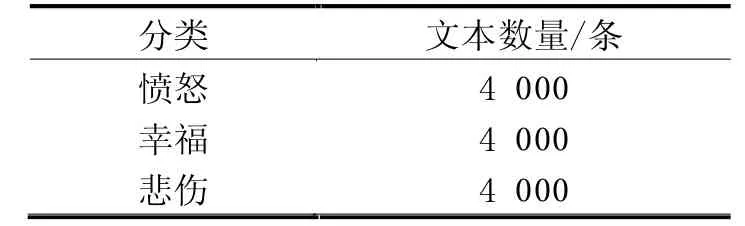
表1 数据集的详细描述
2 研究方法
在这一节中,将详细描述适用于实验的方法。方法的流程如图1所示。预处理:从社交媒体平台提取的数据中包含了大量不需要的信息,如url、用户名、标签、表情符号和其他特殊字符。为了删除它们并使文本干净,可以采用以下步骤:
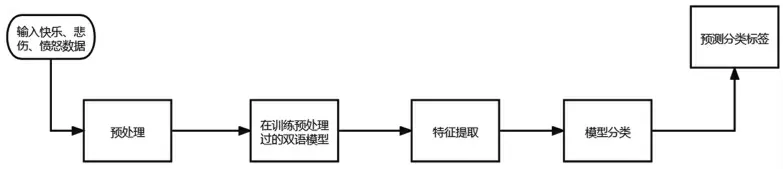
图1 方法流程图
(1)从文本中删除url。
(2)从文本中删除所有用户名和特殊字符。
(3)从整个文本中删除所有额外的空格。
(4)将每个文本转换为小写。
这些步骤以Jose等[4]人的工作为基础,在使用深度神经网络进行分类时,预处理技术的作用提供了明确的支持。
重新训练模型和特征提取:在特征提取工作中,使用预先训练的领域特定的词嵌入模型[5]。使用这个预训练模型的原因是,它是由250K码混合推文构建而成的,这样大的语料库生成的训练模型可以提供更好的特征向量。本文用Word2Vec重新训练了这个模型。Word2Vec的核心思想是通过分析所有被标记的词,了解它们之间的语义关系,根据词的相似度来实现向量相似度。
在Word2Vec中,有2种方法生成单词向量。这2种方法分别是连续词袋法和跳跃图法。CBOW在工作中的作用是用本文清理的数据对模型进行再培训。CBOW的主要功能是借助邻接词预测一个词的前景,即根据上下文预测单个词。Word2Vec是一个浅层神经网络,其中存在2组权值。当周围的单词作为输入时,它预测单个单词,如果在预测中有错误,它将通过反向传播进行修正,以调整权重。在更好的预测之后,CBOW给出隐藏层和输出层之间的权值作为单词的数值向量。综上所述,特征提取过程如下:
(1)对预处理获得的已清洗文本进行标记。
(2)使用标记化的单词对模型进行再训练。
(3)从重新训练的模型中为每个单词生成数值向量,从而获得每个句子的特征向量。
将从模型接收到的特征向量提供给各种深度学习算法进行文本分类。
单词向量一旦生成,所有的单词向量都被堆叠到一个嵌入矩阵中,并使用各自的行数作为索引。将令牌化句子中的每个词替换为词索引,并将其作为模型的输入,传递给嵌入层。由于每个句子的长度都是唯一的,所以使用零填充使它们的长度统一。在嵌入层中,每个输入整数作为索引访问包含所有可能特征向量的嵌入矩阵。在获取每个句子的特征向量后,将其传递给深度神经网络模型。从相关工作中可以明显看出,CNN和CNN为首的序列模型,如LSTM、BiLSTM已经证明在许多文本分类任务中提供了更好的结果。CNN层捕获的必要特征对于LSTM进行序列预测非常有用。它减少了LSTM上的负载,使计算速度更快。LSTM对顺序数据的处理效果非常好,因为它们可以选择性地记住所需的模式,这在分类任务中起着至关重要的作用。双向LSTM层也被使用,因为它们可以在2个LSTM上训练,而不是第1个LSTM对输入序列进行训练,第2个LSTM对其反向拷贝进行训练。简而言之即提出再训练一个双语预训练模型来生成单词嵌入特征向量和CNN头神经网络模型用于印式英语码混合文本分类。
3 实验和结果
收集的12 000条代码混合的社交媒体文本被考虑用于实验。每一个清理的文本被标记,并给予再训练的模型,以生成单词向量。语料库中的每个词都有索引并从嵌入层访问其各自的向量。调查结果表明,一维CNN在NLP分类任务中取得了一些显著的结果,因为词语的邻近性可能并不总是一个良好的指示可训练模式的指标。因此第1个实验是用1D-CNN做的。当仅使用CNN时,从模型中去掉LSTM层。LSTM和BiLSTM可以记忆在分析文本时具有重要意义的顺序模式,因此也通过省略CNN层来利用它们。最后,采用CNN-LSTM和CNNBiLSTM模型,因为CNN具有提取特征的能力,降低了LSTM或BiLSTM训练的复杂性。对CNN、LSTM、BiLSTM、CNN-LSTM、CNN-BiLSTM这5个模型进行分类实验。对每个模型进行了15代的训练,并利用10倍交叉验证进行模型评价。各分类模型的性能指标见表2。

表2 分类模型的性能指标
CNN-BiLSTM的分类准确率达到了83.21%,从所得结果可以看出,与其他模型相比,CNN-BiLSTM的分类性能更好,CNN-BiLSTM模型列于表3,以直观地展示其性能。从所提供的统计数据可以理解,CNN-BiLSTM在每一个类的分类中都有显著的表现,总体上的准确性都是最优的。
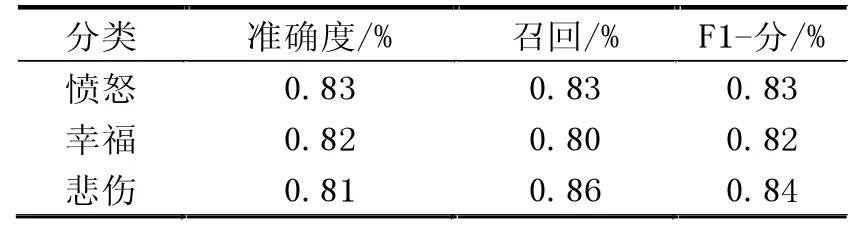
表3 CNN-BiLSTM分类性能
4 结论
社交媒体平台的普及为每个人通过文字或图片来表达自己对各种话题的情感铺平了道路。在印度,人们混合使用英语和当地语言(代码混合语言)来表达他们的情感。自动识别那些通过代码混合语言表达的情绪是一项乏味的任务,因为它包含2种(或更多)完全不同的语言的特征。本文提出了一种深度学习方法,用于识别各种社交媒体平台(如Twitter和Facebook)中通过印地语-英语代码混合语言表达的情绪。为了实现检测模型,本文从不同的来源收集并清理了12 000条包含快乐、悲伤、愤怒等情绪的印地语-英语代码混合句子。为了将句子转换成向量,使用了双语预训练模型,该模型再使用为该任务收集的语料库进行再训练。在检测情感的各种深度学习模型中,CNN-BiLSTM模型的检测准确率较高,达到83.21%。该模型在分类智能检测方面也有良好的性能。由于典型的单语预训练模型不包含其他语言的词汇,为了从代码混合数据中检测情感或其他信息,需要双语预训练模型。此外,应用CNN层可以从单词嵌入中生成更有意义的信息,这些信息可以作为输入传递给BiLSTM,BiLSTM捕获句子的语义。未来,通过在印度语言代码混合文本领域创建大型语料库,这项任务可以扩展到更精细的情感水平。
