基于改进的XGBoost模型预测南太平洋长鳍金枪鱼资源丰度
2022-05-08袁红春高子玥张天蛟
袁红春,高子玥,张天蛟
(上海海洋大学 信息学院,上海 201306)
引 言
近年来,我国在南太平洋捕捞渔船大量增加,南太平洋长鳍金枪鱼(Thunnus alalunga)已成为我国远洋延绳钓渔业的重要捕捞对象之一。渔场预报是渔情预报的重要内容[1],渔场预报准确性的提高有助于渔业生产企业合理安排渔业生产,缩短寻找渔场的时间,达到降低成本、提高渔获产量的目的。
目前,预测效果较好的资源丰度回归预测模型主要有线性回归[2-3]、决策树[4-5]、神经网络[6-7]等。陈芃[2]等建立了多元线性回归模型(Multiple Linear Regression),以资源量为指标对东南太平洋秘鲁鳀进行资源丰度预测,线性回归也是目前用的最多的资源丰度预测方法;魏广恩[5]等采用随机森林(Random Forest, RF)对资源丰度进行预测。谢斌[6]等利用BP神经网络方法预测秋刀鱼资源丰度,BP神经网络已广泛应用于其他海域的资源丰度预测且效果较好。但资源丰度预测仍然存在难以有效拟合高维海洋数据、易受渔业生产数据缺失值影响的缺陷。
最优分布式决策梯度提升树(Extreme gradient boosting, XGBoost)[8]的结构能够很好地减少缺失值较多的样本对模型的影响。同时,面对高维时空数据难以有效提取特征的问题,王青松[9]等建立了CNN-XGBoost混合模型对短时交通流进行预测,使用CNN对交通流数据进行时空特征提取,预测效果良好。但XGBoost存在参数过多,难以找到较好的超参数组合的问题。模拟退火算法[10-11](Simulate Anneal,SA)具有良好的全局搜索能力和局部寻优能力,能够有效弥补XGBoost模型的缺陷。
本文利用改进的XGBoost模型对南太平洋长鳍金枪鱼资源丰度进行预测,通过CNN进行高维海洋数据特征提取,再将输出的特征向量输入到XGBoost模型进行训练。同时,使用模拟退火算法寻找CNN-XGBoost模型最优超参数组合。以降低资源丰度预测误差为目标,以期为南太平洋长鳍金枪鱼延绳钓渔业科学生产提供依据,为远洋渔场预报提供新方法。
1 材料与方法
1.1 实验数据来源
大量研究表明,长鳍金枪鱼受包括海表温度、叶绿素a浓度、垂直和表层温度及海面高度异常等多种因素的影响[12-14]。

表1 原始数据尺度
本文所用数据分为渔业生产统计数据和海洋环境数据,时间跨度为2005—2015年。长鳍金枪鱼渔业生产数据来源于中西太平洋金枪鱼渔业委员会(WCPFC,Western Central Pacific Fisheries Commission),生产数据包括作业日期、经度、纬度、放钩数和渔获尾数等,时间分辨率为月,空间分辨率为5°×5°。海洋环境数据包括海表面温度(SST)、叶绿素浓度(Chl-a)、采用Nino3.4区海表温度距平值(SSTA)来表示的ENSO 指数(厄尔尼诺-南方涛动)均来源于OCEANWATCH网站(https://oceanwatch.pifsc.noaa.gov/),时间分辨率为周,海表面盐度(SSS)、海水密度(SSD)、海面高度(SSH)、海表面高度异常(SSHA)均来源于哥白尼海洋环境监测网站(http://marine.copernicus.eu/),各个垂直水层结构[15](100,125,150,200,250,300)的温度(TEMP)和盐度(SAT)来源Argo实时数据中心(http://www.argo.org.cn)。
1.2 数据预处理
1.2.1 CPUE计算
本文以长鳍金枪鱼资源丰度指标[16]为单位捕捞努力量渔获量 (Catch per unit effort, CPUE),是指渔场在一定时期内,平均每一个捕捞努力量所能捕获的渔获量。本研究定义5°×5°为一个渔区[17],计算每个渔区的CPUE(尾/千钩,ind/khooks),计算公式如下:
CPUEymij=Catchymij/Effortymij
(1)
其中,CPUEymij表示i经度j纬度渔区m月平均 CPUE,单位为尾/千钩;Catchymij表示i经度j纬度渔区m月渔获量,单位为尾数;Effortymij表示i经度j纬度渔区m月捕捞努力量,单位为千钩。
1.2.2 海洋环境因子预处理
由于模型预测时间尺度为月,所以对各个环境因子分别按每年每月求平均值,并用平均值补充各环境因子同年月的缺失值。同时,由于渔业数据的空间分辨率为5°×5°,时间分辨率为月,而各环境因子的时间和空间分辨率与渔业数据不同,为了使环境数据与生产数据匹配,需要分别对环境数据进行空间和时间尺度上的重采样,因此,通过python编程进行数据处理,转换到与渔业数据相同的时空分辨率。
1.2.3 归一化
对环境因子和CPUE值分别进行归一化到[0,1]区间内,以此消除由于数据各因子量级不同对训练模型产生的影响。计算公式如下:
xi'=(xi-xmin)/(xmax-xmin)
(2)
其中,xi'为环境因子或CPUE归一化后的值;xi为初始值;xmin、xmax分别代表每个参数的最小值与最大值。
1.3 CNN-SA-XGBoost预测模型的构建
1.3.1 基本XGBoost模型
XGBoost模型是对梯度提升决策树模型[8](Gradient Boosting Decision Tree,GBDT)的改进,由多棵决策树迭代组成。XGBoost算法能够在生成树的过程中通过自动学习得出最优分裂方向,减少渔业生产数据中缺失值对模型的影响,主要步骤如下:
1) 构造目标函数
obj(φ)=L(θ)+Ω(θ)
(3)
其中,L(θ)为损失函数,用于衡量模型的好坏;Ω(θ)为正则化项,用于控制模型复杂度。
2) 将上一棵数的预测值与真实值的残差作为下一棵树的输入
(4)

(5)

3) 正则化项为决策树的复杂度,可以控制模型的过拟合。其公式为:
(6)
其中,γ为正则项参数;T为叶子节点个数;λ为学习率;ω表示叶节点的数值。
4) 令集合Ij={i|q(xi)=j}为叶子j的集合,将目标函数进行二阶泰勒展开,得:
(7)
其中,ωj为第j个叶子节点的权重;γ为正则项参数;T为叶子节点个数;gi、hi分别为第i个样本预测误差的一阶导数和二阶导数:
(8)
(9)
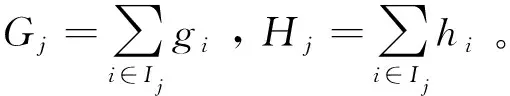
(10)
(11)
1.3.2 CNN-XGBoost模型
卷积神经网络(Convolutional Neutral Network,CNN)是一种以神经网络为架构的算法,其网络模型包含卷积层、池化层、全连接层等结构[18]。
如图1所示,卷积层一般用于数据的特征值提取,卷积核的个数由CNN的层数决定。池化层通过对特征进行降采样操作从而达到降低参数量和防止过拟合的目的。全连接层是一个普通的神经网络层,该层将数据特征进行线性空间转换,得到期望的输出。其计算过程为:
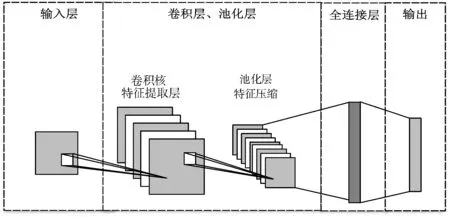
图1 卷积神经网络结构图
xi+1=f(ωxi+b)
(12)
其中,f为激活函数;ω为权重矩阵;b为偏置矩阵。
在预测模型中,构造特征的好坏直接决定了模型性能。对于海洋数据高维、样本数量少、变量多的特点,CNN模型可以实现端到端的学习,中间的特征可通过模型自动学习得到。并且XGBoost模型是由多棵回归树迭代而成,优势在于不容易过拟合且训练速度快。因此,结合两者的优点,构建CNN-XGBoost模型,CNN-XGBoost模型在使用CNN自动提取不同层次的特征后,将得到的特征向量作为输入给XGBoost模型进行资源丰度预测,能够有效降低预测模型的误差,但XGBoost模型中难以找到最优超参数组合的问题并没有解决。
1.3.3 CNN-SA-XGBoost预测模型
在XGBoost模型中,booster参数决定了XGBoost中回归树的形成,是决定XGBoost模型预测效果的关键部分,但booster参数数量过多,导致XGBoost在训练过程中难以找到最优参数组合。因此,本文将CNN-XGBoost模型与模拟退火算法相结合,构建CNN-SA-XGBoost资源丰度预测模型。
由图2可知,模拟退火算法在每次迭代中都会选择一种booster参数的超参数组合训练XGBoost模型,并通过以均方根误差为评估函数的K折交叉验证得出对应的均方根误差,即模拟退火算法中的分数(score)。在模拟退火算法过程中,首先计算下降幅度ΔE=pre_score-score,其中,pre_score是前一次迭代的分数,score为这次迭代的分数。若ΔE≤0,即存在“局部”改进(可进行局部寻优),将该超参数组合接受为当前组合,并根据当前组合来扰动并产生下一次迭代的相邻组合。若ΔE>0,则新解xj按Metropolis准则[11]中的接收函数exp(-ΔE/kTi)接受这个效果更差(分数更低)的组合作为当前组合,以跳出局部最优,其中,k为Boltzmann常数,Ti为当前温度(实验中会设置一个初始温度T0,随着迭代次数的增加,温度T不断降低,T的衰减函数为Tk+1=αTk,k=0,1,2,…,α为衰减系数)。然后从“冷却时间表”中找到分数最高即最优的超参数组合,最后,用最优超参数组合训练XGBoost模型,并用测试集验证分数最高的模型预测性能。

图2 CNN-SA-XGBoost模型
1.3.4 模型预测结果评估
均方根误差(Root Mean Square Error,RMSE)、均方误差(Mean Squared Error,MSE)、平均绝对误差(Mean Absolute Error,MAE)是机器学习回归模型预测结果的衡量标准[8]。本文使用RMSE、MSE和MAE来评估实验中回归模型预测的结果。
(13)
(14)
(15)

1.4 模型验证
本文以每个渔场的年份、月份、经度、纬度、海面温度、叶绿素浓度、ENSO 指数、海面高度以及垂直水层结构的温度、盐度等变量作为输入数据,输出数据为CPUE。将 2005—2015年总共25 344个样本,进行归一化处理,随机化分配75%作为训练样本,25%作为测试样本评估模型。
首先利用CNN卷积神经网络自动特征提取和特征选择等特点,自动提取多维数据特征,再将其输入到XGBoost中进行训练。由于XGBoost参数过多,难以找到最优超参数组合,因此同时利用模拟退火算法不断寻找最优超参数组合,降低预测误差。并且用均方根误差RMSE、均方误差MSE和平均绝对误差MAE来评估预测结果。
其中,CNN模型采用两层卷积层和一层全连接层堆叠来自动提取特征,卷积层采用1x1的卷积核。其中,第一层卷积层滤波器数目设置为64,第二层设置为32。全连接层的个数为32,采用relu激活函数。同时,为了防止模型过拟合,引入Dropout层并设置参数为0.2。
在XGBoost模型中,增强迭代的次数num_rounds设置为50,这样能够缩短处理时间。同时为之后的启发式搜索选择了几个常用的重要Booster参数:树的深度max_depth、训练实例的子样本比率subsample、列二次采样colsample_bytree、步长eta、节点分裂所需最小损失函数下降值gamma、正负权重scale_pos_weight、最小叶子结点样本权重和min_child_weight,超参数可能的组合总数为648个。
根据问题规模,本文将模拟退火算法设置100次迭代进行寻优,经过多次模拟退火试验后,将初始温度T0设置为0.4,衰减函数的α设置为0.85时,算法寻优效果最佳。
为了验证改进的XGBoost资源丰度预测模型的有效性,本文设计了两组对比实验,主要包括:
(1)通过CNN-SA-XGBoost模型自身构建过程对比,来验证对XGBoost模型的改进有效降低了模型预测误差。
(2)由于缺少前人对南太平洋长鳍金枪鱼的资源丰度预测的研究,因此,本文用其他海域应用效果较好的资源丰度预测模型[2-7](多元线性回归、随机森林和BP神经网络)分别对南太平洋长鳍金枪鱼资源丰度进行资源丰度预测,旨在验证CNN-SA-XGBoost模型对南太平洋长鳍金枪鱼资源丰度预测效果。
2 结果与分析
本文实验的CPU为Intel(R) Core(TM)i5-9400F CPU@ 2.90GHz,采用NVIDIA GeForce GTX 1660的GPU,RAM为16GB。并借助CUDA8.0调用基于keras 2.2.4搭建的深度卷积神经网络。
2.1 CNN-SA-XGBoost模型预测结果分析
表2展示了在CNN-SA-XGBoost模型的训练结果。其中最优超参数组合是:max_depth为15,colsample_bytree 为0.7,subsample为0.9,scale_pos_weight为1, eta为0.2,gamma为0.05,min_child_weight为6,分数为-0.074 432。
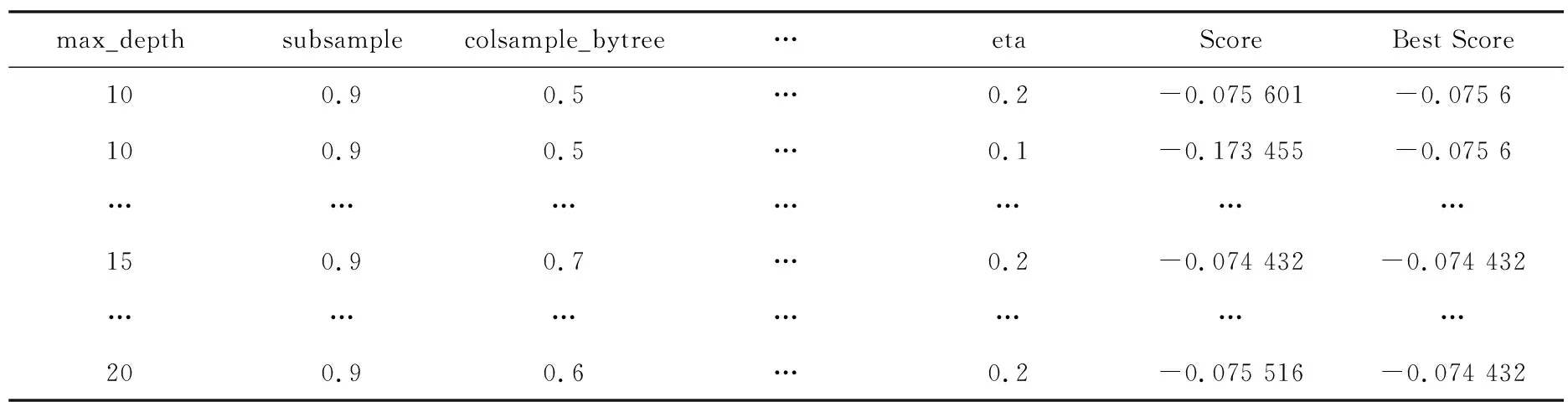
表2 CNN-SA-XGBoost模型训练结果
图3展示了模拟退火算法寻优过程中交叉验证所得分数的变化。由图3(a)为迭代过程中模拟退火算法的分数变化,可以看出模拟退火算法在寻优过程中不断跳出局部最优,仅100次迭代就寻找到分数较高的超参数组合,图3(b)为随着迭代次数的增加,寻优过程中最佳分数的更新,展示出最优解不断更新为分数更高的解的过程。图3寻找最佳分数的过程体现了模拟退火算法易于跳出局部最优、快速搜索最优解的特点。
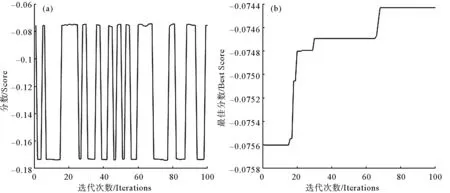
图3 模拟退火算法寻优过程
最后用测试集对训练好的最优模型预测评估,测试集占总样本25%,共6 336个样本。如图4的回归分析可知,实际值CPUE与预测值CPUE的相关系数为0.669 6,呈正相关性。均方根误差为0.486,拟合曲线为y=0.941x+0.0042,具有很好拟合效果,模型的预测能力良好。由实验结果可以看出,除少量极端数据的值预测效果较差外,CNN-SA-XGBoost模型的预测值与真实值基本吻合。

图4 模型预测CPUE值与CPUE真实值相关性
2.2 模型对比
2.2.1 CNN-SA-XGBoost模型构建对比
由表3可知,在XGBoost模型的构建过程中,CNN-XGBoost模型比XGBoost基本模型均方根误差RMSE降低3.24%、MSE降低6.49%、MAE降低7.74%,CNN有效提取了高维海洋环境数据的时空特征和复杂关联,使XGBoost模型预测误差降低。
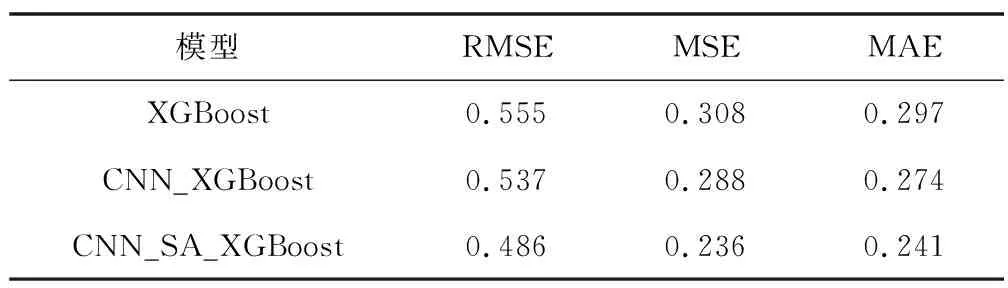
表3 CNN-SA-XGBoost模型构建结果对比(测试集)
CNN-SA-XGBoost比CNN-XGBoost模型的RMSE降低9.50%、MSE降低18.06%、MAE降低12.04%。实验表明,模拟退火寻优算法明显降低了模型的预测误差。
最终实验结果表明,CNN-SA-XGBoost模型的均方根误差(RMSE)较XGBoost基本模型减少12.4%,预测效果明显优于XGBoost基本模型,本文提出的改进方法有效降低了XGBoost预测误差。
2.2.2 改进的XGBoost模型和其他资源丰度预测模型对比
表4为改进的XGBoost模型和多个有代表性的资源丰度预测模型结果对比。本实验中多元线性回归(Multiple Linear Regression)模型的回归方程(最佳拟合线)为Y=-218.24+0.01X1+(-0.01)X2+…+1.32X23,其中,X1,X2,…,X23分别为23个输入变量。模型的均方根误差为0.679,预测效果较差。相比其他模型,线性模型的结构对高维数据的拟合能力较弱,高维度海洋数据的资源丰度预测效果不佳。
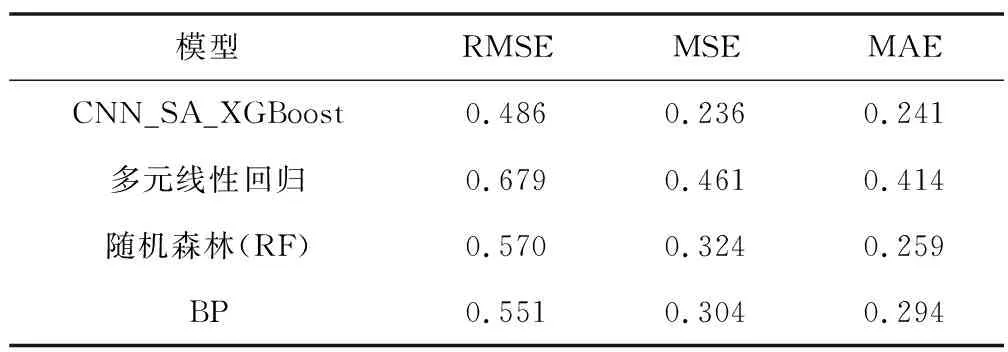
表4 CNN-SA-XGBoost模型与其他模型结果对比(测试集)
随机森林模型(Random Forest, RF)与XGBoost结构类似,随机森林模型也是由多颗回归树组合而成。本实验中RF模型的内部结点再划分样本数min_samples_split设为2,最小样本数min_samples_split为2,决策树深度max_depth为10。经过模型预测结果评估,均方根误差为0.570,预测误差高于CNN-SA-XGBoost模型。
目前,BP神经网络模型已在其他海域的资源丰度预测取得较好的应用效果,具有很好的自主学习能力和很强的泛化和容错能力,但较容易出现局部最优、收敛慢和振荡等问题。由于隐含层结点数一般设为输入层结点数的75%[17],且有23个输入变量,因此,本实验采用结构为23-17-1的BP神经网络,即输出层为23个结点,隐含层为17个结点,输出层为1个结点。模型的均方根误差为0.551,高于CNN-SA-XGBoost模型。此对比实验表明,CNN-SA-XGBoost模型预测效果良好,在南太平洋长鳍金枪鱼资源丰度预测中,误差低于其他应用效果较好的预测模型。
3 讨论
近年来,有关南太平洋长鳍金枪鱼的研究多集中于分析环境因子与渔场的相关性和渔场的时空分布变化,鲜有对其资源丰度预测的研究,而在其他海域早已有学者建立相应物种资源丰度回归预测模型。
目前,资源丰度预测都是基于一种或多种海洋环境因子来构建预测模型,多选用叶绿素浓度、海面温度以及海面高度等海表面数据进行预测[12,19]。根据长鳍金枪鱼延绳钓的捕获特性[13]和长鳍金枪鱼适宜的垂直活动水层深度[14],长鳍金枪鱼在18~30 ℃水层均有分布,但由于季节变化和地理位置不同等因素的影响,适温水层深度不断变化,且本实验的地理覆盖范围较广,时间尺度较大,因此添加100~300 m范围的垂直水层的温度和盐度作为输入变量。其次,考虑到南太平洋会受到厄尔尼诺或拉尼娜现象的影响,导致部分异常年份的海水温度异常升高或降低,造成长鳍金枪鱼的产卵、洄游路线、渔场分布等鱼类行为变化,因此,以Nino3.4区的海表温距平值(SSTA)表征 ENSO 现象,作为输入变量加入到预报模型中。众多研究表明[2-7],海表面温度(SST)是影响大洋性鱼类渔场分布的最为重要的环境因子之一。由于食物链原理[21],叶绿素浓度(Chl-a)也可以影响渔场的分布。再结合其他传统预测模型[12,19]认为关键的海洋环境因子,共选取了19个海洋环境因子以及4个时空变量作为CNN模型的输入变量。
对于海洋数据多源化和异构性的特点,CNN可以更好的拟合复杂的数据形式,自动获取高维海洋环境数据中存在的复杂关联,有效提取出高维数据特征,且CNN是“黑盒”模型,不需要考虑各输入变量间的相互影响,使用方便。但由于CNN提取出的特征向量已转换形式,相当于根据原有的数据特征创造了新的变量,模型可解释性较差,无法获取原有的各个变量对预测模型的重要性大小,因此实验中对各个环境因子重要性分析有待进一步研究。实验表明,CNN提取的特征向量作为XGBoost的输入向量,有效提高了XGBoost的预测效果。
XGBoost是机器学习中一种新兴的集成模型,它将多颗回归树组合起来形成一个性能更加强大的学习器,不仅对数据的拟合能力强于传统的线性回归,而且在模型构建过程中,将目标函数引入正则项,有效避免变量较多,样本较少的资源丰度预测模型过拟合。由于渔业生产数据难以获取,收集过程易受到当地气候、政策等影响,导致渔业生产数据中含有缺失值的样本较多,相比传统的决策树资源丰度预测模型,XGBoost在生成树的过程中通过自动学习得出最优分裂方向,减少渔业生产数据中缺失值对模型的影响。同时,模拟退火算法良好的局部寻优和全局搜索能力有效弥补了XGBoost参数过多,难以找到最优超参数组合的缺陷,有效提高了XGBoost的预测效果。因此,CNN-SA-XGBoost模型相比传统的资源丰度预测模型,更适合高维海洋环境数据和含有缺失数据的渔业生产数据,有效降低了渔场资源丰度预测误差,为渔情预报提供了一种新的方法。
4 结论
本文针对资源丰度预测模型中难以有效拟合高维海洋数据、易受渔业生产数据缺失值影响的问题,以降低预测南太平洋长鳍金枪鱼资源丰度的误差为目标,利用2005—2015年南太平洋长鳍金枪鱼生产数据和获得的海洋遥感环境数据,提出了一种结合模拟退火算法和卷积神经网络的CNN-SA-XGBoost模型。实验结果表明,CNN-SA-XGBoost模型有效的提取出高维海洋环境数据特征,且拟合效果良好,预测误差明显低于其他传统的资源丰度预测模型对南太平洋长鳍金枪鱼的资源丰度预测误差,为渔场资源丰度预测提供了新的方法和思路,有助于企业合理安排渔业生产。但由于CNN模型是一种“黑盒”模型,导致无法分析实验结果中渔场与各环境因子的关系。因此,下一步将研究更有效的特征提取方法,在进一步降低渔场资源丰度预测模型误差的同时,有效分析渔场与环境因子之间的关系,为渔场预报提供理论指导。
