基于注意力机制的Siamese目标跟踪算法研究
2022-05-07刘先禄张宇山
张 军,刘先禄,张宇山
(1.安徽理工大学人工智能学院,安徽省淮南市泰丰大街168号 232001;2.安徽理工大学机械工程学院,安徽省淮南市泰丰大街168号 232001)
纵观Siamese目标跟踪,其主流网络经历了SiamFC[1-4]、SiamRPN、SiamRPN++、SiamMask的发展;其中,SiamFC[5]实现了首次将Siamese应用于目标跟踪领域,更新了单目标跟踪算法的记录;SiamRPN[6]网络则在SiamFC的基础之上,引入了RPN[7]结构,实现了对目标锚框的位置回归优化,进一步提升了锚框的定位精度[8];SiamRPN++则在SiamRPN框架基础上引入了深层的ResNet50网络用于backbone的设计,以及采用了多通道的特征融合,将网络的跟踪精度进一步提升[9];SiamMask则引入了分割的思想,增加了Mask预测分支,实现了跟踪的IOU值的提升[10]。
文中将对SiamMask算法进行再设计,分别对其backbone以及IOU评价标准进行了改进;算法的原理如图1所示,由Se-Net对模板与搜索域进行特征提取,经过下采样实现对深度的快速标准化,接着由depth-conv模块在深度卷积的模型下实现算法的3个各自分支,实现对Score map,regression以及mask的预测。下面将详细介绍追踪算法各个模块的结构。

图1 注意力机制网络的架构Fig.1 Framework of net based on attention mechanism
1 Backbone设计
基于Res-Net50的SiamMask算法的backbone采用如表1参数设计;算法对Res-Net50基于最大stride为8标准进行局部的卷积步长调整,采用block3输出特征,进行对图像的特征提取。
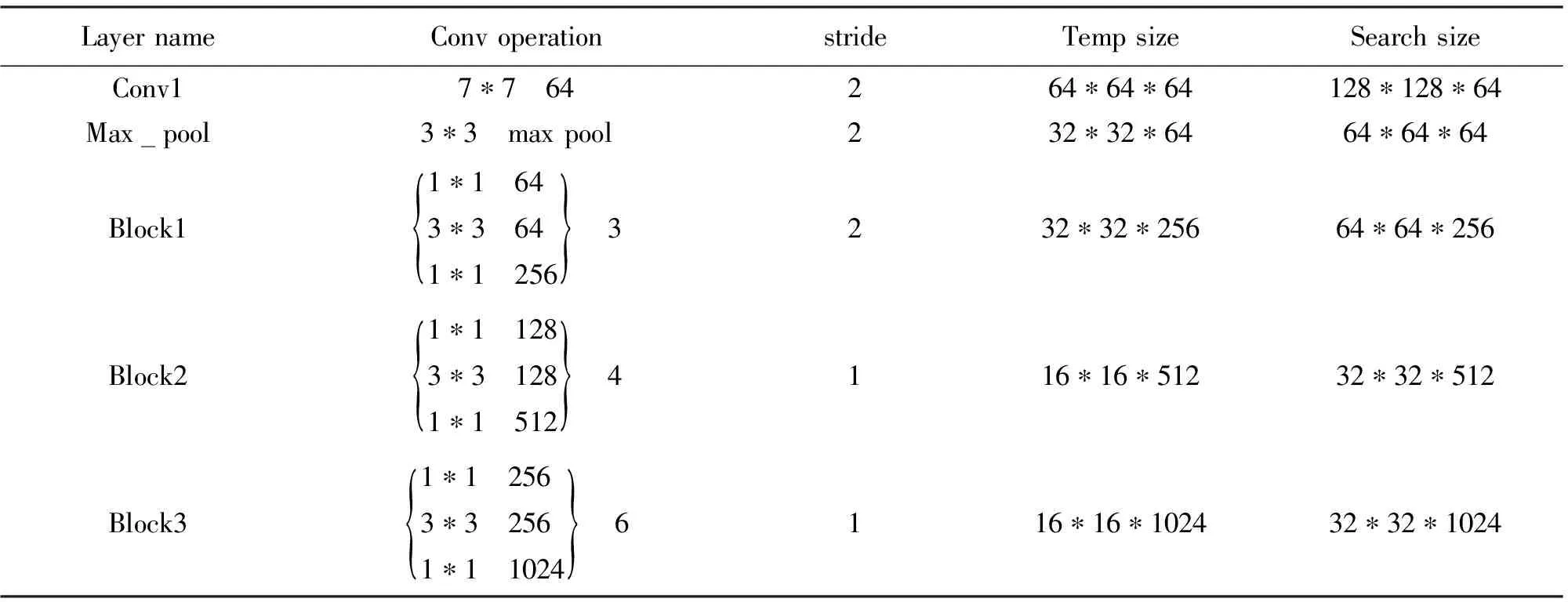
表1 Res-Net50网络配置
对于文中的孪生卷积神经网络的backbone网络,将以Se-Net思想为基础,对网络进行局部的修改,重新设计追踪网络的backbone。算法backbone采用了注意力机制框架可以提升网络的表达能力,其框架结构如图2所示:

x——输入特征,X——经过了扩展和压缩之后结合权重的输出,c1,c2——特征通道数,h——输入图像的高,w——输入图像的宽,H——输出特征图的高,W——输出特征图的宽,Ftr(.,θ)——将输入x的通道数变为c2,Fsq( )——对特征图进行压缩,Fex(.,w)——对压缩后的特征图进行excitation操作;Fscale(·)——特征图乘法操作。图2 注意力机制架构Fig.2 The frame of attention mechanism
该结构在Res-Net的网络内部进行了局部改进,对网络的输出特征进行了加权输出。通过图2,该结构首先对网络层进行了squeeze特征提取,形成一维特征向量,接着采用全连接网络进行excitation,提取出网络的基本权重特征。Squeeze主要用于编码网络层特征的全局信息,采用全局池化来感应特征在通道上的全局响应分布特点,接着由excitation连接各个通道响应,形成对各个通道的权重,建立了通道间的相关性;这样,通过在线学习的方式获得权重,根据权重去选择有用的特征通道,抑制无关紧要的特征,在深度上对该层网络实现权重抑制,提升了网络的语义提取能力。该结构的具体卷积流程如图3所示:

图3 注意力机制卷积架构Fig.3 The frame of the convolution of attention mechanism
权重主要是经过对该层的全局池化,以及两次的全连接激活形成,通过权重与原始特征图的相乘完成了在通道维度上对原始特征的重标定,形成了在Res-Net block深度方向上再选择,使得在付出不高的计算与参数量的代价上,加强了网络的特征提取能力,获得更高性能的网络。文中的backbone结构采用如表2参数进行设计。
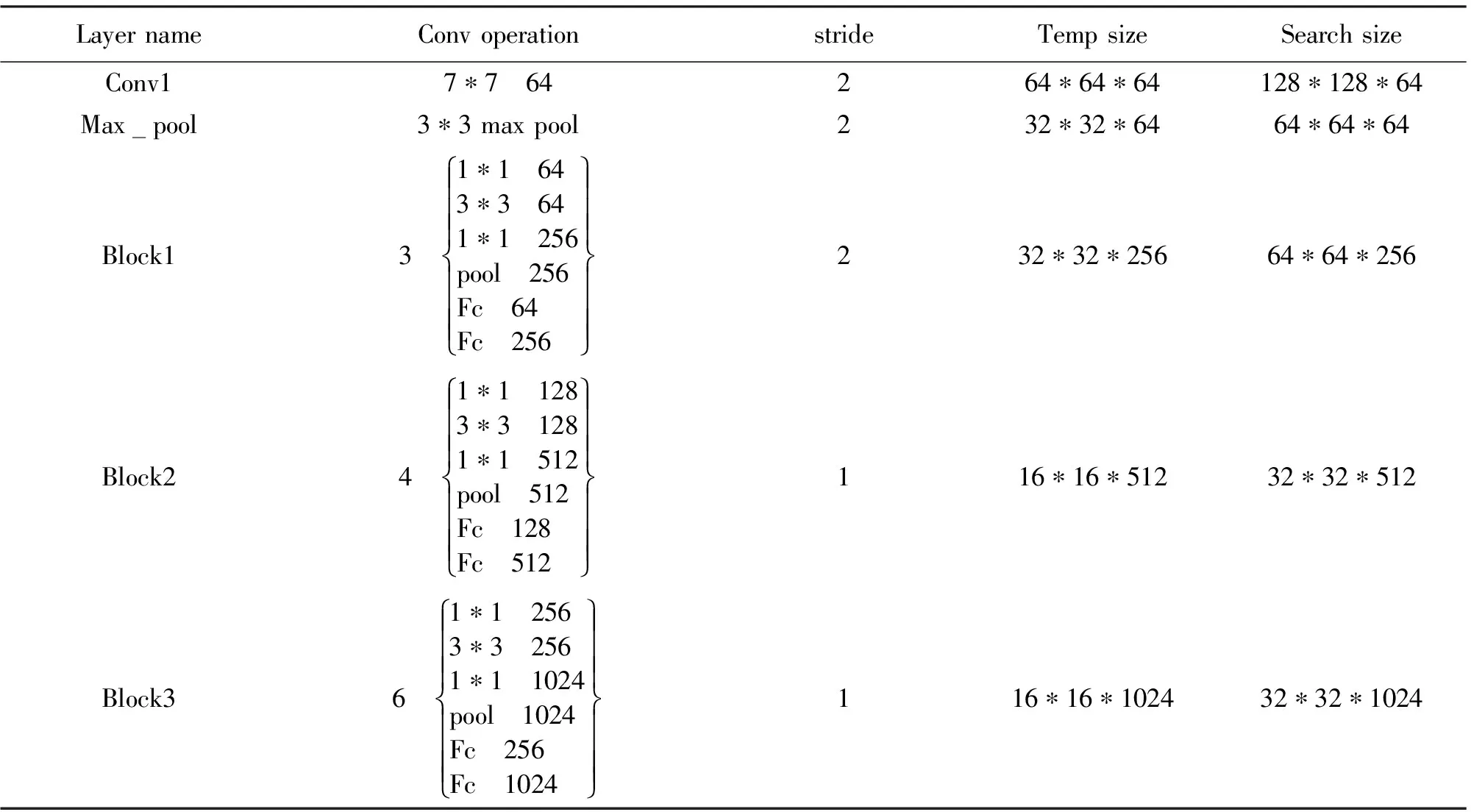
表2 backbone网络配置
卷积网络架构分别对temp image以及search image进行特征提取,如图4与图5网络反映了2个分支在各个层对图像提取的特征尺寸,通过backbone的前向特征提取网络将模板图像提取出深度为1024,大小为16*16的特征;同时将搜索图像提取出深度为1024,大小为32*32的特征。

图4 模板图像特征提取架构Fig.4 The feature extraction frame of the temp image
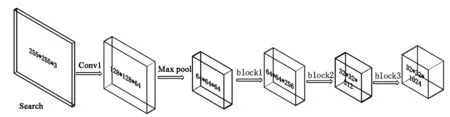
图5 搜索图像特征提取架构Fig.5 The feature extraction frame of the search image
由于网络提取出的特征深度信息过于庞大,在backbone网络特征提取后采用卷积核为1*1的降采样运算,以此来实现对特征深度的减少,形成了256深度的图像特征,同时减轻网络庞大的模型参数量,提高网络的运算速度。
2 深度卷积模块设计
为了提高网络的预测能力,Siamese追踪网络架构采用如图6模块对模板与搜索域进行深度卷积操作,可以在减少网络模型参数的情况下,提高网络的预测能力。其中各个模块的卷积操作参数配置见表3。
算法最后两层的卷积操作全部采用1*1的卷积核,实现对特征保持二维尺寸的同时,实现对特征深度的灵活匹配,这样可以保证对模型参数量的控制。经过层层卷积操作,最终提取出了17*17大小的map特征,深度为10的score map,深度为20的回归特征,以及深度为63*63的mask分支特征。各个分支的前向网络框架采用了独立的上图深度卷积模块设计,图7反映了网络的预测分支框架结构。
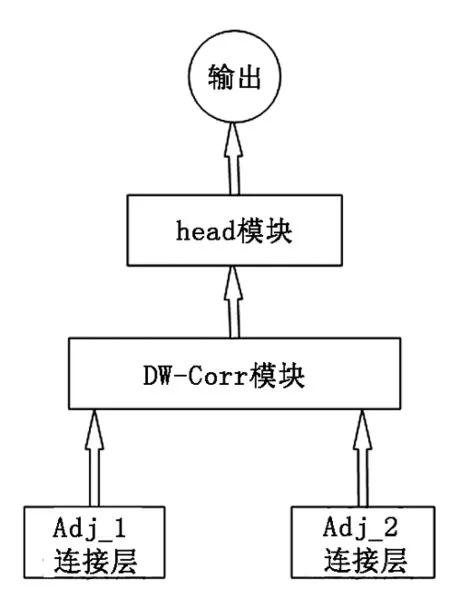
图6 深度卷积模块架构Fig.6 The frame of the DW-Corr

表3 深度卷积模块网络配置
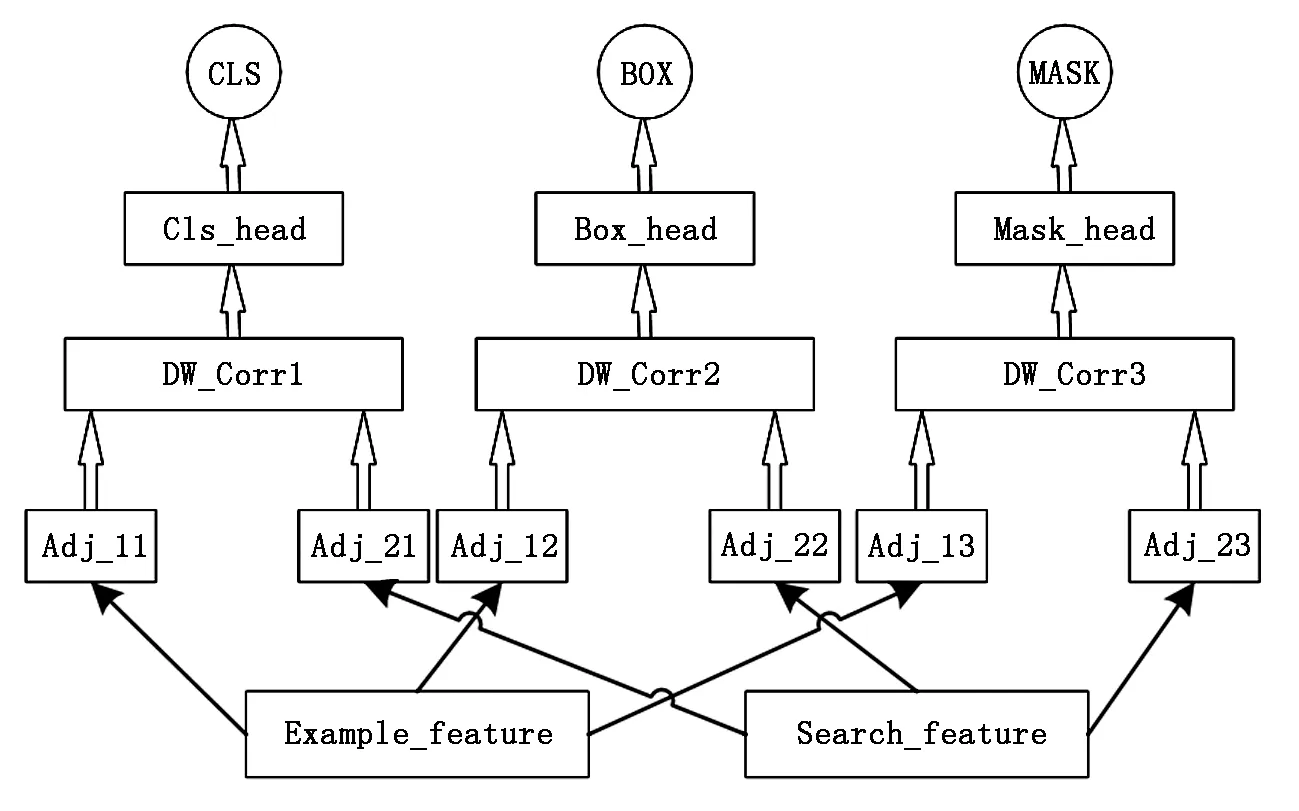
图7 预测分支架构Fig.7 The frame of the branch of prediction
独立的分支采用对了的预测模块对来自backbone经过下采样的特征进行图像特征信息提取,实现了对搜索域像素的目标得分预测,目标位置回归预测,以及目标分割生成。
3 损失函数与优化策略设计
算法优化目标由三个部分构成,分别代表score map损失、回归损失,以及分割蒙版损失。对于score map损失,算法采用交叉熵损失,见式(1)。
(1)
损失函数主要与训练数据目标位置的得分标签(0/1)、网络的特征图像素以及anchor尺寸相关。
Mask特征损失的设计采用对训练集的蒙版标签进行分割处理,对255*255的二值蒙版图像进行滑窗分割出17*17个127*127大小的标签,步长采用8个像素值如下图所示:

图8 Mask标签设计Fig.8 The layout of the label of Mask
Mask分支损失目标函数采用对数函数,数学解析式如式(2):
(2)
回归损失采用L1损失设计,如式(3):
Lloc=∑|yi-f(xi)|
(3)
算法采用共64样本像素点,正负样本按照16∶48的分配比例进行训练,正样本标签赋值为1,负样本的标签赋值为0,对网络的17*17大小的回归特征进行有监督训练。
总损失函数采用各个分支加权求和的方式计算,如式(4):
Ltotal=λclsLcls+λlocLloc+λmaskLmask
(4)
算法优化器采用随机梯度下降算法SGD,主要是该算法本身兼具了快速性与鲁棒性,通过小批量数据的梯度下降实现了在计算上复杂度下降,同时在批量样本的采样上,引入了随机数,增强了算法的鲁棒性,两者的结合可以实现对目标函数的快速收敛。学习率更新采用周期的cosine函数来调整大小,动态变化过程如图9所示。
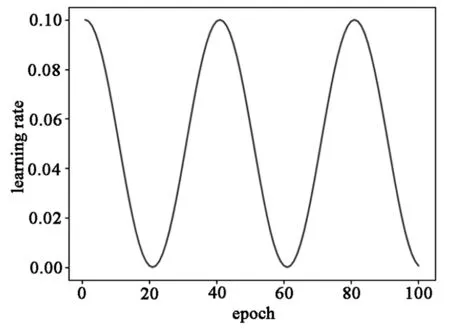
图9 训练学习率Fig.9 The learning rate of the training
4 训练图像数据准备
为提高训练好的网络的泛化能力,需要考虑图像的色彩、大小、模糊噪音、亮度等因素对网络性能的影响。因此,训练集对原始图像引入了随机的缩放,灰度化,模糊化处理,以使算法能够表现出强的预测能力,如图10所示。

图10 图像预处理Fig.10 The pretreatment of the image data
其中对于训练集的模板以及搜索图像参数配置如表4。

表4 数据集参数配置
模板图采用了缩放、8像素随机偏移、灰度化以及尺寸标准化处理,搜索图采用了缩放、64像素随机偏移、灰度化、模糊化以及尺寸标准化图像处理,使得对具有一定噪音的搜索图像,算法还能够准确追踪到目标,可以增强算法在验证集上的泛化能力。对于验证集上的图像处理参数见表5。
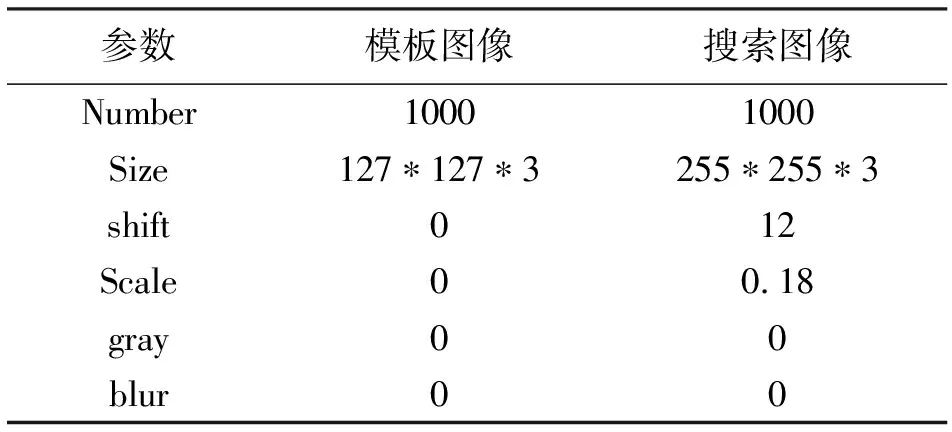
表5 验证集参数配置
主要关注搜索图像的尺寸以及偏移变化对追踪性能IOU值的变化,以此来验证与评价算法在训练集上的泛化能力。
5 实验数据分析
算法的数据包括训练数据、验证数据,以及算法部署的效果数据。训练数据主要通过IOU值的变化来反映算法在训练集上的效果,通过大数据来更新算法的模型参数、设置合适的超参数学习率,可以使得算法在训练集上达到完美的效果的同时,提升在验证集上的性能值。文中采用训练集与验证集数据的分配比例为1∶8,训练集图像数量为8000张,验证集采用1000张图像,并且2个数据集相互独立,没有交叉。以此来较为准确的反映算法的实际泛化能力,可以评估算法的实际效果。
图11反映了IOU值与总损失函数在训练集上随训练迭代次数的变化曲线:

(a)Mean IOU
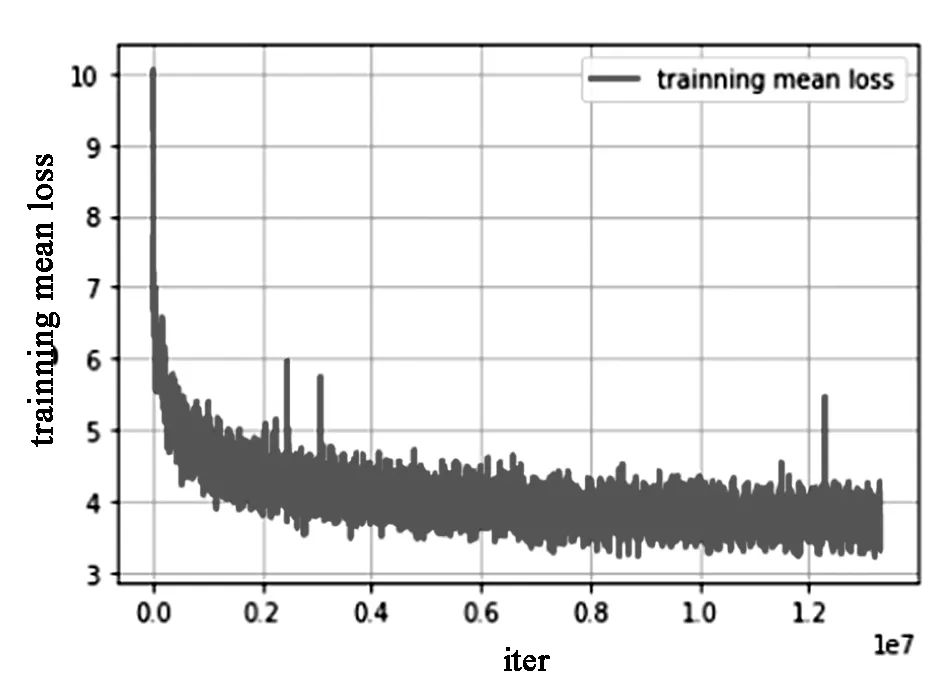
(b)Mean loss图11 训练数据曲线Fig.11 The curve for the training data
在神经网络的反向传输下,目标函数随着迭代的增加变化率逐渐减小,表现在曲线上是损失值在初始时急速下降,然后逐渐趋于平稳。同时,IOU值则由起初的陡增,逐渐趋于恒定。在模型的参数上,主要表现为参数出现陡变的锯齿形状,如图12。

图12 训练模型参数变化Fig.12 The parameter variation in training
通过模型参数的急剧变化,可以使得算法跳出局部最优解,以此来进一步提升算法的性能。之所以参数的变化如此剧烈,需要对算法的超参数作出一定的约束。本文采用周期的余弦变化曲线来设计学习率,使得算法的学习率在训练的过程中动态的调整,以使得算法训练时在快速学习与平稳保持间变换,可以使得算法在训练过程中得到快速调优。
通过梯度下降算法对算法进行优化后,主要通过预先准备的验证集进行对算法泛化能力的评价。文中采用在迭代过程中,时隔一定训练轮数进行一次验证,以此来反映训练对算法实际性能的影响,总损失在验证集上的表现如图13所示。
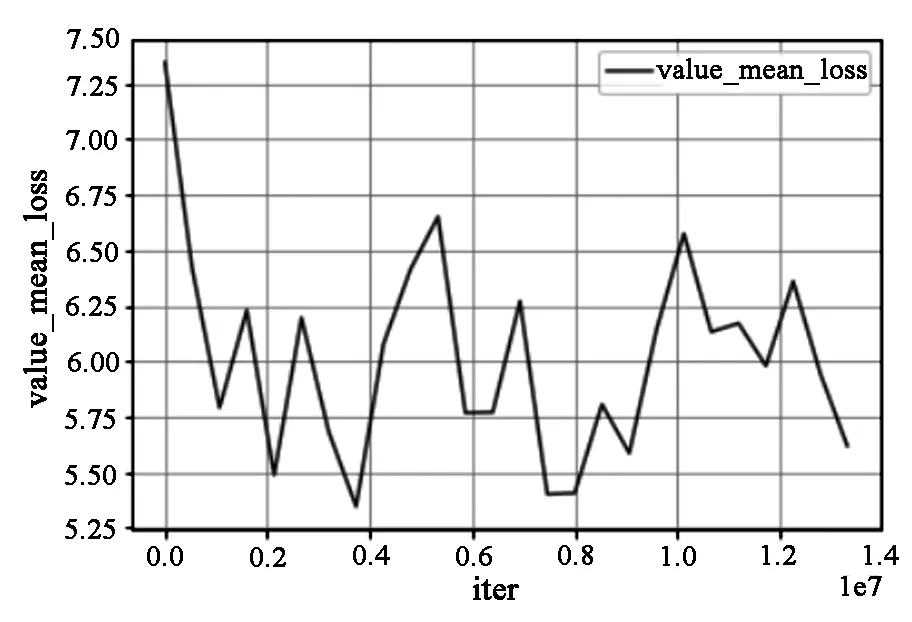
图13 验证损失Fig.13 The loss in validation
图13反映了随着训练的逐步迭代,总损失表现出波浪式下降的趋势,性能在训练中逐步提升。对于验证集上的性能评估,本文采用采样的方式进行IOU值计算,基于目标锚框重叠区域最大的周围64个像素点,来计算验证集标签的IOU值。在训练过程中,验证集上的TOP5与TOP7的IOU值变化曲线如图14所示。
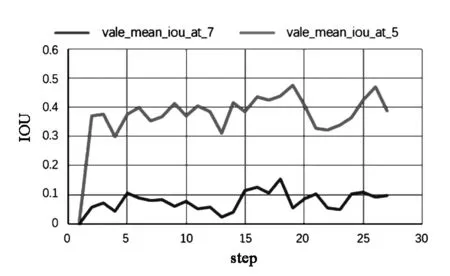
图14 验证IOUFig.14 The IOU in validation
通过随机采样计算,虽然在数值上比全像素的值有较大的误差,但引入随机采样可以更加准确的反映算法的性能变化趋势,以此更为准确的评估算法的泛化性能。上图曲线的呈现出波浪式上升的趋势,反映了算法的性能在逐渐的优化。同时,本文将基于SE-Net的Siamese算法与基于ResNet50的SiamMask算法的验证集平均IOU性能值绘制于同一曲线图中,如图15。经过对比发现,文中的算法在性能指标IOU上略高于SiamMask算法2个百分点左右。
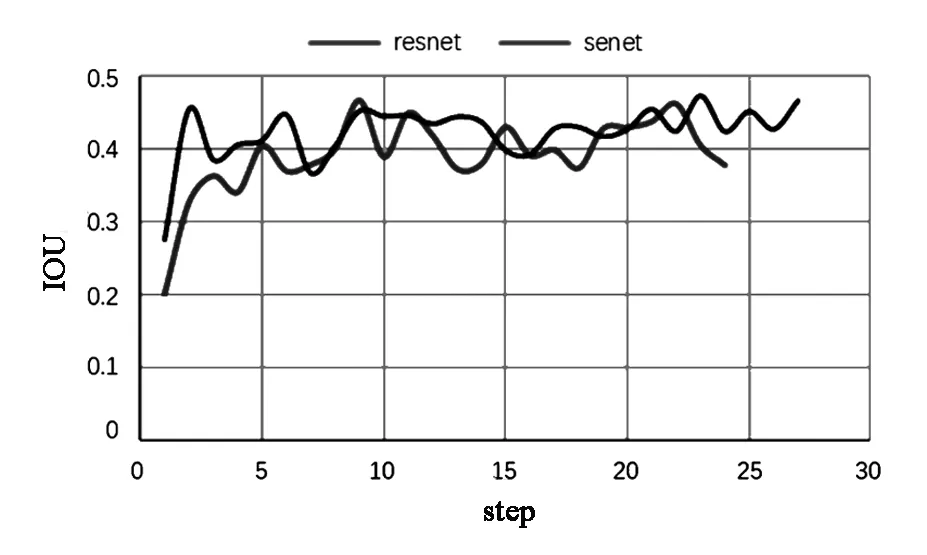
图15 Resnet 和SE-Net IOU对比Fig.15 The comparison of IOU between ResNet and SE-Net
算法的部署,主要将训练好的网络算法用于跟踪相机采集的人脸目标,以此来评估算法的预测精度;图16反映了算法在ROS中的人脸跟踪实验效果。
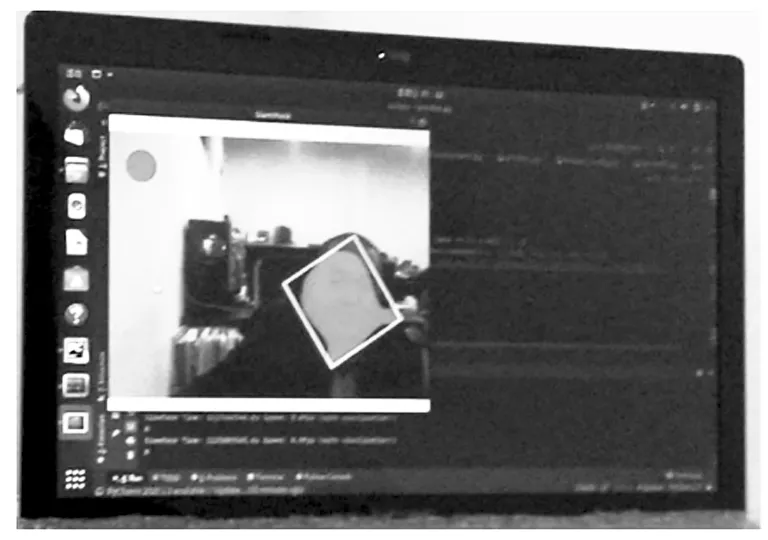
图16 算法部署跟踪结果Fig.16 The result of the algorithm in tracking
图16的mask预测以红色反映,anchor以绿色方框画出,上图的方框可以准确的框住人脸目标,同时mask可以较为精确的生成人脸的目标域,使得算法表追踪人脸的应用场景中表现良好,可以准确迅速的追踪图像中人脸目标。
6 结论
首先基于注意力机制改进了SiamMask的backbone架构,在原有的SiamMask的主干网络中增加了SE-Net,增强主干网络的特征提取能力。其次设计了深度卷积模块并对模板与搜索域进行深度卷积操作,减少了参数量并提高了网络的预测能力。设计了各个卷积模块的结构与程序;并且对改进的算法进行了训练与验证,分析了在各个阶段的算法性能;以及将算法部署到了人脸追踪系统中,来验证算法的人脸追踪效果。同时在验证集上与原算法进行了性能的比对了,以此来分析算法改进的性能提升量,本文的具体研究成果总结如下:
(1)基于Siamese改进了SiamMask,设计了基于注意力机制的backbone,结果显示增加了注意力机制之后网络的表达效果更好,提升了最终的追踪效果。
(2)在Microsoft COCO2017数据集上对算法进行了训练与验证;基于此,分析了算法的跟踪性能,结果表明,改进后的网络在同等算力条件下优于改进之前,文中的算法在性能指标IOU上高于SiamMask算法2个百分点左右。
(3)将文中的算法部署到ROS系统中,实验结果表明,本文的算法能够实现对人脸目标的实时追踪。
