基于Citespace的物种分布预测研究进展的可视化分析
2022-05-07昌秋霞钟云芳宋希强
昌秋霞,钟云芳,张 哲,赵 莹,宋希强
(海南省热带特色花木资源生物学重点实验室,海南大学林学院,海南 海口 570228)
自19世纪工业革命以来,由于经济的快速发展以及人类无限制地开发自然资源等活动,大气中的CO2、CH4和N2O等温室气体含量正在迅速增长,全球气候呈现变暖趋势。全球气候变暖是21世纪生物多样性保护的重大挑战之一[1]。前人研究发现,气候变暖可能会带来物种的分布格局[2-3]与物候期[4]发生改变、物种丰富度减少[5]、增加外来植物入侵风险[6]、引起物种灭绝或加速灭绝[7]等一系列不利影响。研究气候变化背景下物种的潜在地理分布,对揭示物种分布格局的形成、迁移特征以及制定生物多样性保护策略具有非常重要的意义。
物种的分布区是物种的空间特征,是物种与环境长期相互作用的结果,而物种的分布规律是由生态因素、历史演化因素(包括地质演化历史,群体演化历史)等共同影响下形成的[8]。物种分布模型(Species Distribution Models, SDMs)是利用物种的地理分布存在/不存在数据、气候数据、地形数据等,根据分类、回归、机器学习等多种算法[9-12]对物种的生态位进行度量,再将模型投影到现在或未来的环境情景中,以分布概率的形式反映特定气候生境对物种的适宜程度,其结果可以解读为物种出现的概率或生境对于物种适宜度等[13]。物种分布模型最早起源于物种—环境相互关系的研究[14],随着物种分布模型的不断发展,SDMs在生物多样性保护[15-17]、入侵生物风险评估[18]、探究环境变化对生物的影响[19-20]、珍稀濒危物种动态预测[21]、物种起源、散布及演替分化规律研究[22]等诸多方面具有重要的应用价值。
科学知识图谱(Mapping Knowledge Domains)是利用可视化知识图谱显示学科的发展历程与结构关系的一种图形,同时兼备“图”与“谱”的双重性质特征:既是可视化的知识图形,又是序列化的知识谱系,可对知识单元或知识群体之间形成的网络结构及其互动、交叉、衍化等诸多复杂关系进行表达和描述[23]。CiteSpace 是由陈超美教授基于Java 语言开发的一个可视化分析软件,其原理是利用共引分析理论及寻径网络算法,对某一领域的文献进行计量,形成一系列可视化的科学知识图谱,由此挖掘出学科发展的演化路径及研究热点与趋势[24]。CiteSpace软件自2004年被推出以来,已成为学术界科研工作者使用最广泛的分析软件之一[25]。
目前,前人对物种分布预测领域研究更侧重于应用方向,而基于信息可视化与计量化分析的相关综述性研究较少,因此,本文运用 CiteSpace软件对“物种分布预测”领域的相关文献进行归纳分析,通过构建知识图谱梳理该领域的发展历程,总结其未来发展趋势及研究热点,以期为后续研究与发展提供参考依据。
1 研究方法与数据来源
1.1 研究方法
本研究基于CiteSpace5.8.R1(64-bit)、Excel等软件对相关文献的发表时间、国家、科研机构、作者、关键词进行可视化分析,在绘制可视化图谱中,其固定参数“Slice Length=1,Pruning=Pathfinder”;词频节点的大小和深浅代表其学术影响力;连线的粗细代表词频之间的联系强度;Density(网络密度)代表提示词频间的相互关系;Modularity代表网络聚类情况,数值越大,聚类效果越明显,当Q>0.3时,即网络结构显著;Silhouette代表网络同质性情况,数值越大,聚类结果越可行,当S>0.7时,即聚类结果具有高信度,同时剔除S值为1的不合理聚类。节点数量与大小代表核心作者群体共现频次,线条数量与粗细反映作者合作关系与合作强度。
1.2 数据来源
数据源于中国知网(CNKI)及Web of Science(WOS)数据库的核心合集中相关的中英文文献。其中,CNKI数据库拟定检索条件为:“主题:(适生区)OR主题:(生境)AND主题:(预测)”,共检索到相关中文文献1 486篇,将相关度较低的文献剔除,得到有效文献1 433篇;WOS选用核心合集数据库,拟定检索条件为:“主题:(specie*)AND主题:(potential distribution model*)AND文献类型: (Article OR Review)AND语种:(English)”,共检索到相关英文文献6 777篇,并通过CiteSpace“除重筛选”功能得到有效文献6 687篇。
2 结果分析
2.1 发文时间分析
国内外物种分布预测研究领域年度发表论文情况如图1所示。
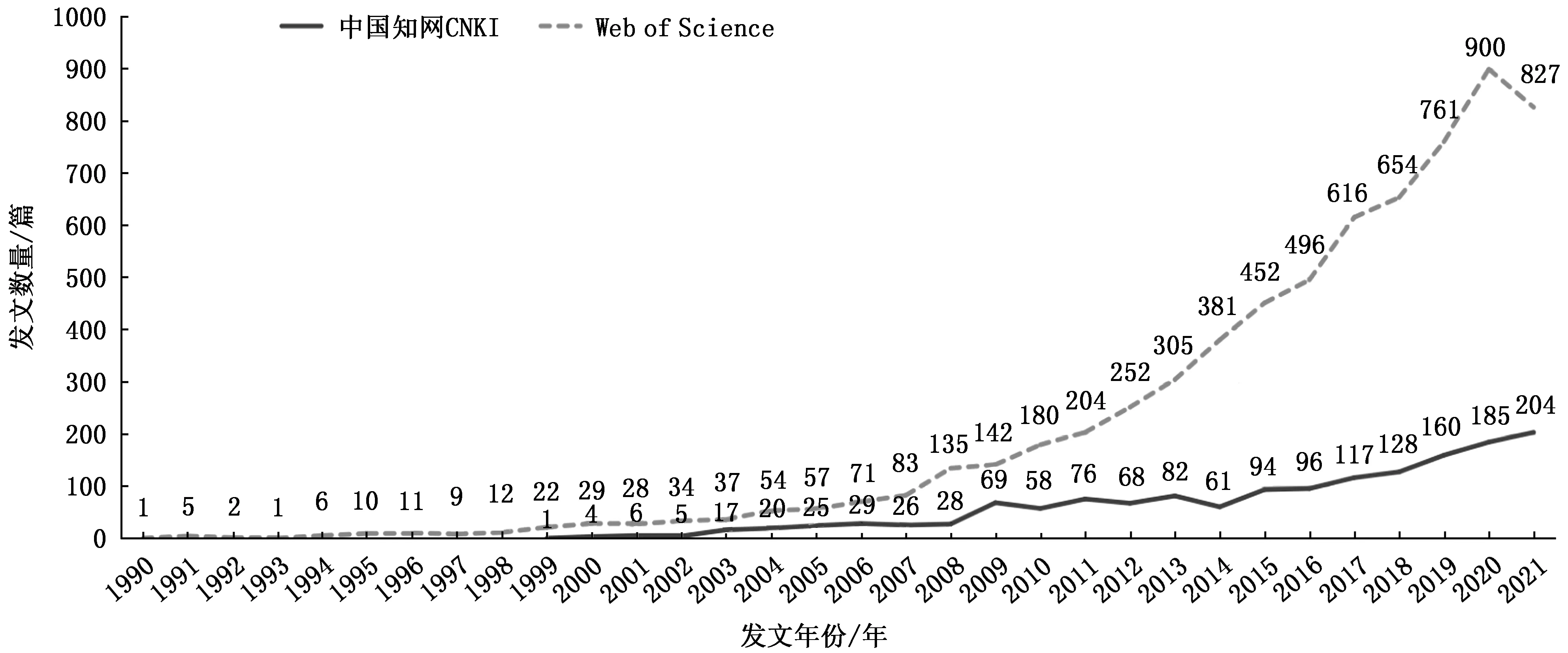
图1 国内外年度累计发文量趋势Fig.1 Broken line chart of research documents quantity at home and abroad
从文献总量来看,国内外相关研究年发文量均呈现逐年增加状态,特别是2007年后,年发文量有较为显著的增长,说明物种分布预测研究逐渐引起国内外学者的关注与重视。从发展阶段来看,国外的物种分布预测研究可大致分为两个阶段:第一阶段为初级探索阶段(1990—2007年)。国外相关研究萌芽于20世纪90年代初,BIOCLIM 模型为首个物种分布模型,由 Busby于1991年提出,Busby基于生态位理论利用生物气候分析害虫物种的分布及气候变化下其潜在分布区范围[26]。由于计算机与编程技术的限制,经历了十几年的探索,此阶段的年发文量仍较少且增长缓慢,此时学者的探索重心主要集中于物种生境适宜性研究及物种生境评价模型开发,这为后续的快速发展奠定了理论基础。第二阶段为高速发展阶段(2008—2021年)。此阶段年发文量多且增长快速,仅2016年的年发文量就超过了第一阶段的发文量总和。随着卫星遥感与地理信息系统(Geographic Information System,GIS)的快速发展,部分学者尝试将GIS技术与物种多样性空间分布格局研究相结合,研究发现,GIS不仅能够准确地绘制出物种分布图,体现物种分布的动态变化,获取物种丰富度信息,而且GIS结合物种与生境关系模型能够较为准确地预测动物的空间分布格局[27]。此后,物种分布预测研究迅速成为学术研究的热点课题。
国内相关研究的发展历程与国外大致相同,亦可分为两个阶段:第一阶段为初级探索阶段(1999—2008年)。我国相关研究起步于1999年,当时有学者利用Climex模型预测了植物害虫麦双尾蚜Diuraphisnoxia(Mordvilko)在中国的适生区[28],可视为我国物种分布预测研究的开端。第二阶段为高速发展阶段(2009—2021年)。此阶段年发文量呈稳步增长状态,研究重点除上一阶段的模型基础理论研究[27,29-30]、外来物种入侵范围预测[28,31-32]、害虫种群动态预测[33-36]等研究方向外,还增加了野生珍稀濒危物种适生区预测[37-40]、物种起源与演替[41]、外来生物入侵风险评估[42-43]、传染病病原体的传播及扩散路径预测[44]、多模型结合优化应用[45-48]、植物病菌传播预测[49-50]等多个研究方向,与古生物学、疾病传播学等多个学科交叉融合,应用层面更广、层次更深。
2.2 发文国家与机构分析
合作图谱是体现该领域研究机构或作者间学术合作与交流强度的重要依据。从发文量国家统计与合作图谱来看(表1,图2),美国是研究成果最多的国家,发文频数为2 443篇;中介中心性最高的是德国,为0.21,表明德国与其他国家的学术交流、合作较多。英国、德国、中国、澳大利亚、法国等亦拥有不错的研究成果,但与国际间的合作不多。
在全球研究机构合作图谱中(表2、图3),网络节点数为579个,网络密度为0.003 8。美国国家科学研究中心(Centre National DE LA Recherche Scientificas,CSIC)是该领域中发文量最多的研究机构,其与法国国家科学研究中心(Centre national de la recherche scientifique,CNRS)、美国森林服务部(US Forest Serv)及美国国家海洋和大气管理局(National Oceanic and Atmospheric Administration,NOAA)构成了领域里最重要的学术合作圈。此外,由中国科学院(Chinese Acad Sci)、中国科学院大学(University of Chinese Academy of Sciences)及北京林业大学(Beijing Forestry University)组成的学术合作圈也占据重要地位。美国堪萨斯大学(University of Kansas)、英国牛津大学(University of Oxford)、美国地质调查局(US Geol Survey)亦是该领域的主要研究机构。
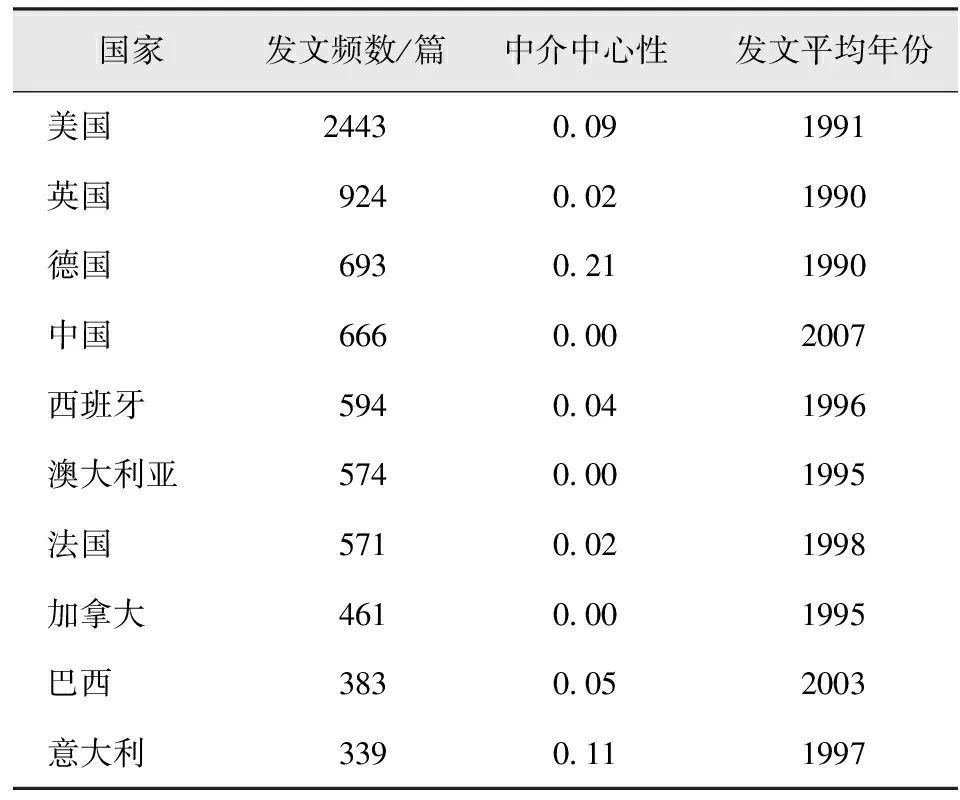
表1 全球发文量前10位国家统计Tab.1 Statistics of the top ten countries in terms of global publication volume
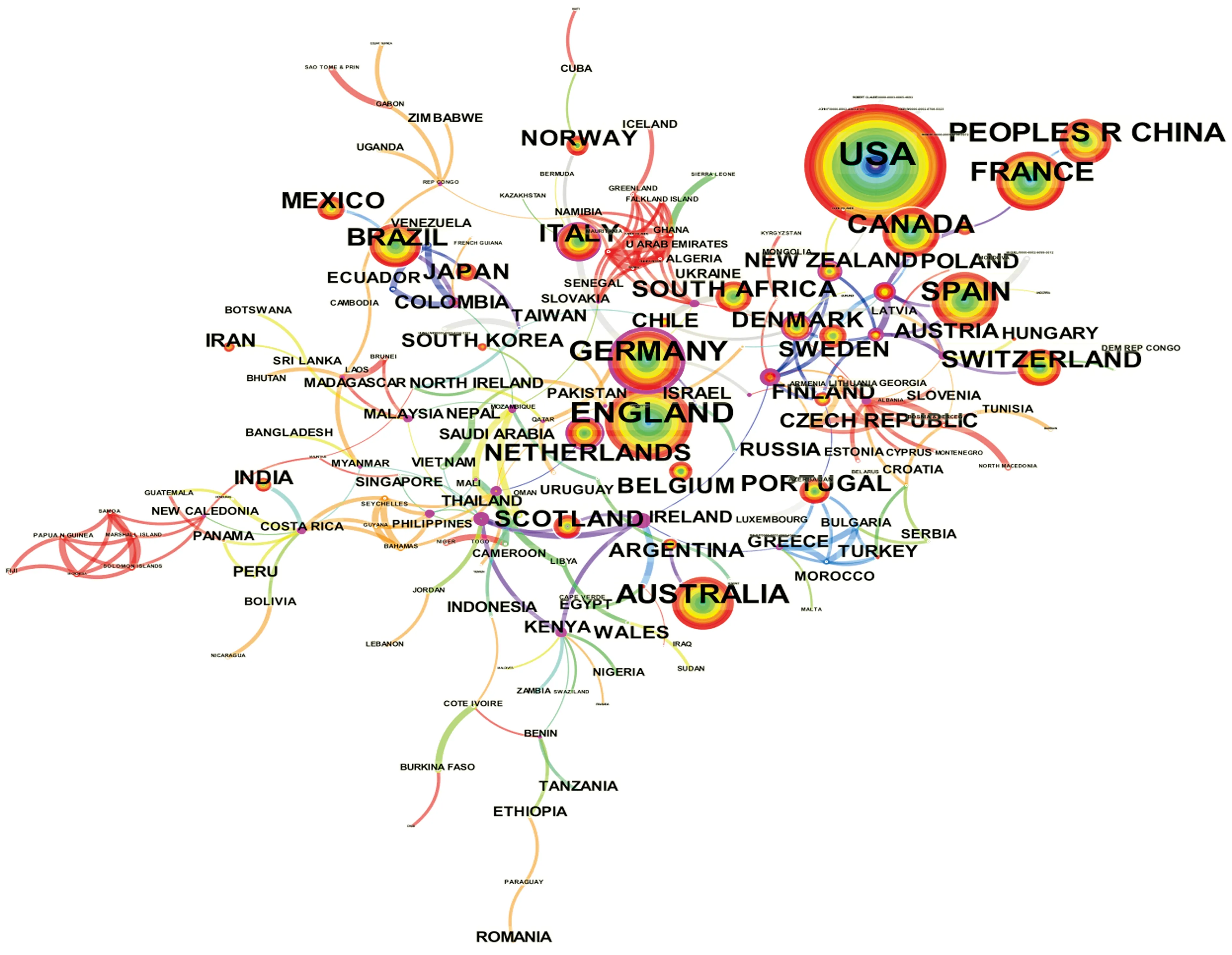
图2 全球发文国家知识合作图谱Fig.2 Knowledge map of countries of publication

表2 国内外发文量前10位研究机构统计Tab.2 Statistics of the top ten institutions in terms of publication volume at home and abroad

图3 全球发文机构知识图谱Fig.3 Knowledge map of global research institutions
2.3 发文作者分析
国外作者合作知识图谱形成了网状分布结构,这表明国外研究学者之间产生了较为密切的学术合作,其中来自堪萨斯大学生物多样性研究所的研究员 Townsend A.Peterson是领域里成果最多的学者,相关文献发文频数为87篇,该作者主要研究方向为引起传染病的寄生虫[51]、病毒[52-53]、病菌[54]等介质的传播范围及路径预测,近年来其对预测模型的优化研究亦展开了较为深入的探讨[55-58]。来自美国国家科学研究中心的学者Wilfried Thuiller是该领域最高被引作者,被引频次为46 180,其主要研究方向为外来生物入侵风险评估,探索导致物种入侵的主要驱动因素[59-60]。
在国内作者合作知识图谱中呈现出大分散、小集中的特点,这表明国内该领域里形成了以万方浩、李明阳、卫海燕、郭彦龙、晋玲等学者为核心的数个作者群,但各团队之间联系强度较差。虽然在1999年就有学者通过CLIMEX模型预测了麦双尾蚜Diuraphisnoxia(Mordvilko)在中国的适生区[27],但直到2002年,北京师范大学的张清芬基于CLIMEX模型,利用气候数据预测了日本金龟子在中国的可能入侵适生区[30],并在随后的第二年发表论文详细阐述CLIMEX模型的运算原理、主要功能、模型特性及实例应用[61],此后,国内相关研究才进入较为系统性的研究流程。卫海燕、郭彦龙、张仪、晋玲、吕利华等是近5年来的高产作者,近期的研究焦点是蜱媒及病原体的适生区预测与适生性分析[44,62-64]、药用植物的生境预测[65-67]、珍稀保护孑遗植物的景观格局破碎度分析[68-69]、基于R语言的预测模型优化研究[70]等(表3,图4,图5)。
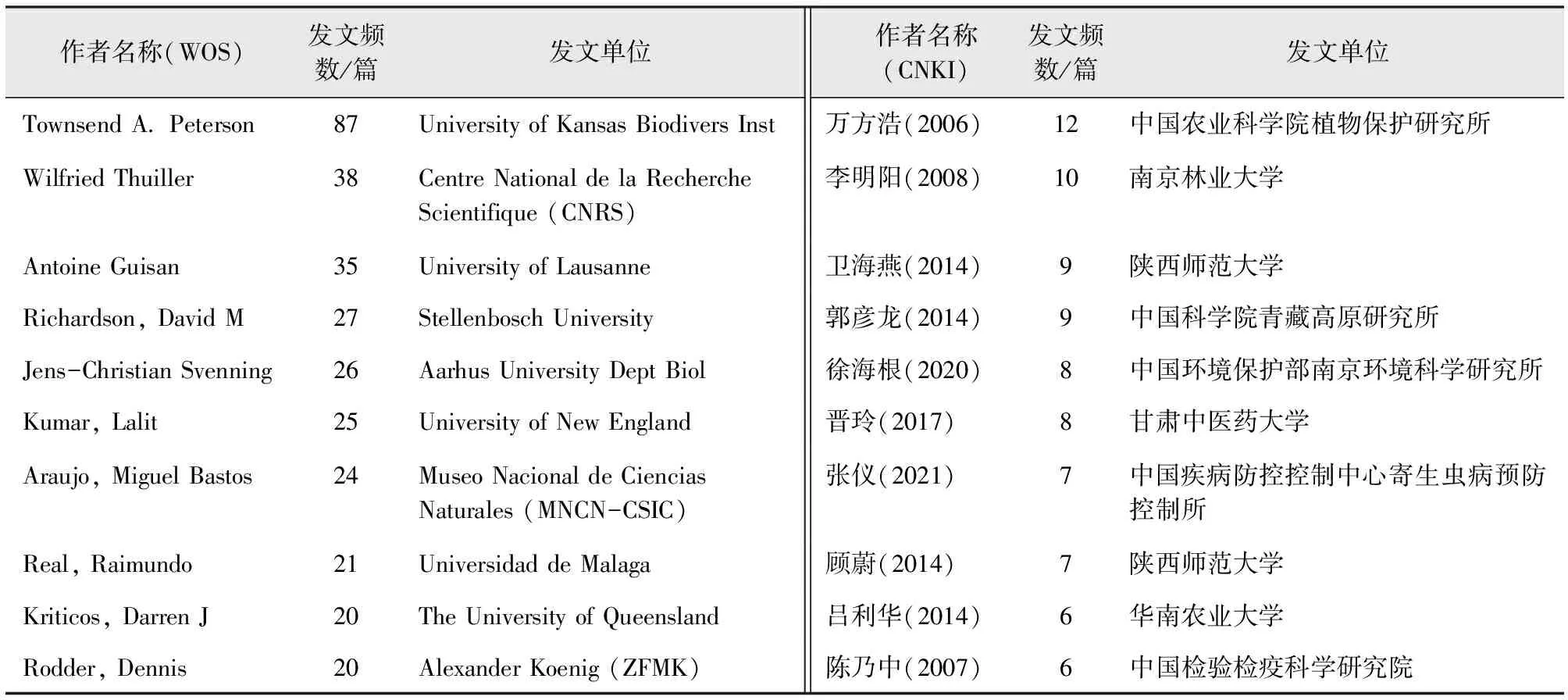
表3 国内外发文量前10位研究作者统计Tab.3 Statistics of the top ten authors in terms of publication volume at home and abroad
2.4 关键词聚类与共现分析
关键词可以揭示文章内容核心观点及主要方向,对关键词进行共现和突现分析,可以更为直观地了解该研究领域的研究热点、研究趋势及知识架构[24]。
国外关键词聚类主要分为#invasive species(入侵物种)、#migration(迁徙)、#phylogeography(系统地理学)、#maxent(最大熵模型)、#risk(风险)、#connectivity(联结度)、#drought(干旱)、#biodiversity(生物多样性)、#evolution(演化)、#climate change(气候变化)、#conservation(对自然环境的保护)、#random forest(随机森林算法)、#population dynamics(种群动态)、#last glacial maximum(末次盛冰期)几大类,聚类Q值(ModularityQ)为0.813 8(>0.3),平均轮廓(mean silhouette)值为0.854(>0.5),表明该聚类图谱结构合理,集群的同质化程度较高(图6)。剔除高度重复的聚类,国内关键词聚类主要分为#潜在生境、#地理信息系统、#ca-markov模型、#组合模型、#maxent、#climex、#人类活动、#遗传算法、#生物入侵、#生态位、#适生区预测、#岛屿生物地理学理论、#3S技术等几大类,聚类Q值(ModularityQ)为0.894 2(>0.3),平均轮廓(mean silhouette)值为0.964 9(>0.5)
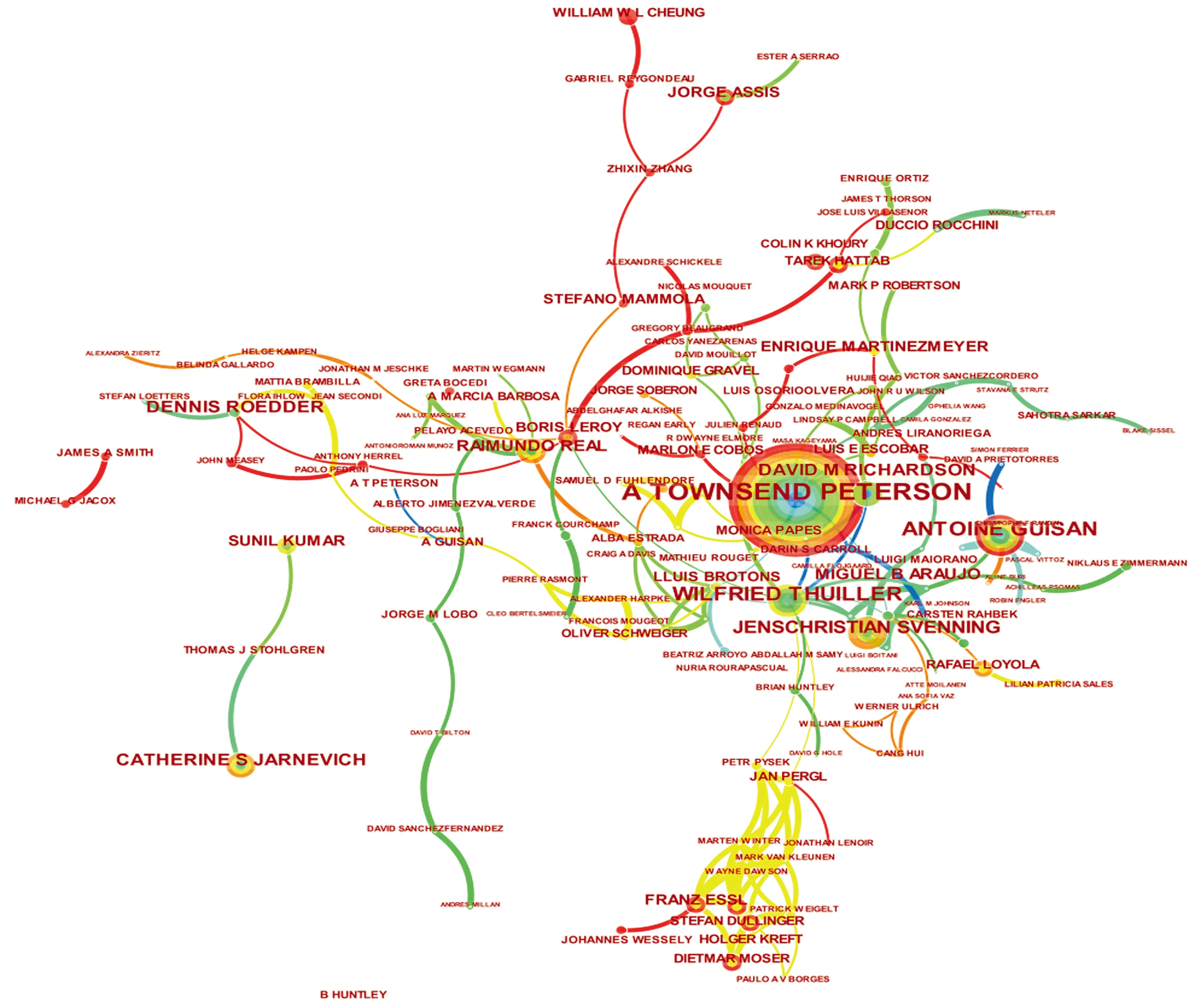
图4 国外发文作者知识图谱Fig.4 Knowledge map of of authors abroad
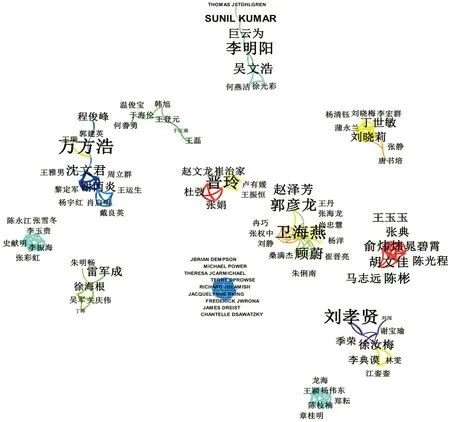
图5 国内发文作者知识图谱Fig.5 Knowledge map of of authors at home
(图7)。通过图谱可以观察到国外物种分布预测每一个聚类所呈现的面积均较大且覆盖面广泛,且多个聚类之间存在相互覆盖,说明各项研究之间存在较深的交流。其中最核心的部分以生物入侵、气候变化、种群动态、Maxent模型等研究为主,说明该类研究出现较早,对研究领域内的其他分支影响较大,属于该领域内的基础类研究;而离中心点较远的如组合模型、biomod、小样本量、人类活动等聚类出现较晚、分支较少,属于领域内较新的课题研究,是近几年的研究热点与趋势(表4)。
在关键词聚类与共现知识图谱(图6,图7)中,出现频次和中介中心性较高的关键词是气候变化、物种分布模型、Maxent最大熵模型、生态位模型、生物多样性、种群动态、生物入侵、演化、生境适宜性。不难发现,物种分布模型一直都是该研究领域的热点课题,无论是初期对于SDMs基础理论研究与模型开发[61],或是后期SDMs的升级优化和多模型联合应用[70],都引起了很多学者的关注和重视。根据目前现有的物种分布模型的运算原理和模型特点,可以将SDMs归纳总结为5类。

图6 国外关键词聚类知识图谱Fig.6 Knowledge map of keywords clustering abroad

图7 国内关键词聚类知识图谱Fig.7 Knowledge map of keywords clustering at home

表4 国内外文献中关键词共现频次排名Tab.4 Ranking of keyword co-occurrence frequency at home and abroad
2.4.1机理模型
该模型的研究基础是建立在了解物种环境变量精确反应的基础上,依赖于对物种生物学和生态学特性的长期观测结果,需要整合物种的生活史、生态位的耐受范围及环境理化动态等数据,从而根据物种的生理生态需求建模[71]。该模型具有明确的生态学意义,因此在物种生境评价研究中得到了广泛应用,然而模型评价准则的建立是根据人为经验而定,对环境因子的适宜性划分具有一定的主观性,这在很大程度上影响了模型的准确性[72-73],且模型所需数据获取难度较大,可实操程度低。
2.4.2统计模型
统计模型的基本原理是数学中的回归分析,在物种变量(分布点数据)与环境变量(如气候、地形)之间建立统计关系,以环境变量为自变量,物种变量为因变量,对物种所处生境进行预测与评价[74]。统计模型主要包含支持广义线性模型GLM、向量机模型SVM、逻辑斯蒂模型 Logistic Model、广义相加模型GAM等。不必同时获取物种“存在”和“不存在”数据是此类模型的优点,但其对物种生态学意义的考虑较少。
2.4.3生态位模型
根据物种实际分布数据及其分布区域对应的生态环境数据,通过某种算法进而得到该物种的生态位特征,将物种的生态位特性投映到特定环境情景中,从而预测物种的分布特征[75]。生态位模型主要包含生态位因子分析模型ENFA、最大熵模型MaxEnt、生物气候模型BIOCLIM、规则遗传算法模型GARP、DOMAIN模型。生态位模型仅需要物种分布点数据与环境数据即可进行模拟,模型操作相对简单,且通常模拟结果较好,因此成为物种分布预测研究中应用最为广泛的模型。
2.4.4模糊数学模型
美国专家查德提出模糊数学的概念,首先采集检测物种相关的有效成分含量值,并收集研究区环境数据,将所有环境因子进行标准化(归一化),之后建立每个环境因子与物种有效成分间的隶属度函数,再根据各环境因子的权重来叠加所有的环境因子,最终得到总的适宜生境评价结果[76-77]。这种方法能够根据物种的有效含量值预测环境因子的相应适宜范围,对物种的有效栽培与利用有着重要意义,此方法比较适用于植物的生境预测,对动物生境预测研究适用度较低。
2.4.5学习型模型
此类模型需要物种的实际分布点数据,以及研究区域的环境数据,并根据经验人为地在不适宜物种生长区域选取“非存在点”(赋值为0),将这3部分数据一同输入模型中,模型将自动学习物种—环境间的关系,并最大限度地逼近这种非线性关系,从而预测研究对象的适生区范围[78]。学习型模型主要包括随机森林RFM、贝叶斯算法模型Bayes、推进式回归树BRT及人工神经网络模型ANN。强大的计算能力与学习能力是此类模型的优点,能够将物种和环境间非线性定量联系清晰呈现,但人为设定“非存在点”数据而使得模型具有一定的主观性。
在现有的众多模型中,Maxent最大熵模型(Maximum Entropy Model)因具有操作简易,样本量对于模拟结果影响较小,且在大多情况下模拟精度高于其他模型的优点,成为物种分布预测研究中应用最广泛的工具之一[79-80]。目前,该模型已被成功应用于珍稀濒危物种如Canacomyricamonticola[81]、Vandabicolor[82]、青钱柳(Cyclocaryapaliurus)[83]、蒙古扁桃(Amygdalusmongolica)[84]等的生境评价与分布预测中。Hernandez等[79]及Deb等[82]的研究均表明当物种出现点很少(<10),即使低至4或5个,Maxent模型仍能以高精度产生有效的预测结果。
3 结论与讨论
3.1 结论
1)发展历程:国内外关于物种分布预测相关研究的发展历程大致相同,可分为初级探索阶段和高速发展阶段。国外相关研究的发展相较于国内萌芽早,发展较为全面,融合学科较多,且机构、学者之间的合作交流较多,形成了以美国国家科学研究中心为核心,法国国家科学研究中心、美国森林服务部及美国国家海洋和大气管理局为重要成员的学术合作圈。Townsend A.Peterson是领域里成果最多的学者,Wilfried Thuiller是该领域最高被引作者,他们的研究成为领域发展的重要基础。国内的相关研究则呈现出大分散、小集中的分布特点,形成了以万方浩、李明阳、卫海燕、郭彦龙、晋玲等学者为核心的数个作者群,但各团队之间联系强度较差,说明各研究团队均处于独立研究状态。卫海燕、郭彦龙、张仪、晋玲、吕利华等是国内近5年来的高产作者,他们的研究方向对领域的发展具有导向作用。从研究机构来看,无论是国内还是国外,该领域相关研究机构主要以高校、研究院所为主,研究机构相对集中,缺乏多样性。
2)研究热点与趋势:在初级探索阶段,对外来生物入侵范围预测的研究是该领域研究开端,此外,探索物种对气候变化的响应、珍稀濒危种群动态预测、Maxent模型的应用等方向亦是初期的研究热点。到了高速发展阶段,初期的研究热点依然热度不减,研究方向还增加了如传染病病原体的适生区预测与适生性分析[44,62-64]、药用植物的生境预测[65-67]、珍稀保护孑遗植物的景观格局破碎度分析[68-69]、物种起源、散布及演替分化规律研究[21]、基于R语言的预测模型优化研究[70]等多项内容,与古生物学、生物地理学、疾病传播学、R语言编程等多个学科交叉融合,应用层面更广、层次更深。
3.2 讨论
国内外物种分布预测研究领域发展历程时间较短,尤其在国内还算较为年轻的学科,缺乏长时间的累积与沉淀导致其可能存在以下不足:
1)研究所需数据获取难度大且准确度不高。物种分布预测研究主要用到两类数据,一类是物种分布有/无数据,另一类是环境变量数据。物种分布数据的主要来源有:野外实地调查数据;各大标本馆馆藏的标本记录;物种数据库,如全球生物多样性信息网站(全球生物多样性信息网络http://www.gbif.org/);文献资料。除野外实地调查数据的可信度与精确度较高外,其他数据来源皆可能存在或多或少的问题,如标本记录与文献记录中的分布数据难以获取准确的经纬度、海拔等信息;物种数据库所记录的分布数据被发现可能存在可信度较低的问题;而野外调查数据虽具有较高的可信度与精确度,但开展野外调查需要花费较高的人力、财力、物力,且无法进行全球或国家层面的大范围普查活动。对于物种分布点样本量的要求目前亦无定论,有学者认为分布点数据越多,预测模型精度越高[85],部分学者对物种分布点样本量对预测模型精度的影响进行了研究,发现50~100的样本量就能获得理想的预测结果[86],Elith等[87]和Wisz等[85]认为30个物种分布点数据也可以得到较为满意的结果,而Hernandez等人[79]及Deb[82]的研究表明,当物种出现点很少(<10),甚至低至4或5个时,仍能够得到有效的模拟结果。
2)物种分布模型众多,选择适用模型存在难点。有学者发现,由于原理和算法的不同,每种模型都有自己的优点和局限性,而且当输入数据发生变化时,模型的表现也是不稳定的[88],如何根据研究物种的特性在众多SDMs中选择适用的模型一直是该领域的研究难点。最近几年,基于R语言的模型优化研究与多模型联合应用是领域的研究热点,Biomod 模型便是应运而生的。2003年Biomod模型在R语言平台发布后引起生物学家们广泛认同和使用[46,89]。目前最新版本是2016年升级的Biomod 2 (3.3-7),其包含了10种常见的SDM算法:分类树分析(classification tree analysis, CTA)、广义线性模型(generalized linear models, GLM)、多元适应回归样条函数(multivariate adaptive regression splines, MARS)、随机森林(random forests, RF)、表面分布区分室模型(one rectilinear envelope similar to BIOCLIM, SRE)、推进式回归树(generalized boosted models, GBM)、柔性判别分析( flexible discriminant analysis, FDA)、最大熵模型(Maximum Entropy, Maxent)以及广义相加模型(generalized additive models, GAM)。使用者可以选择模型提供的5种模型合成方法和10种模型检验方法。此外,还可以自由定制模型组合,调整初始条件、模型类别、模型参数以及边界条件以达到最优预测效果[90]。Biomod组合模型可以有效解决单一模型存在的问题,但其对于使用者的要求较高,使用者需掌握一定的R语言编程基础,且Biomod最终产出的结果是组合模型中各模型结果的平均值,其平均值势必比组合中预测准确值较高的模型要低。因此,从准确度的层面来说,Biomod组合模型并非最优选,针对不同模型的特点加权计算或可得到更好的结果。
3)研究结果难以实证。目前,物种分布预测研究的结果检验通常采取模型精度的评估来实现,AUC值(Area Under the Receiver Operating Characteristic Curve)、TSS真实技巧统计值(True Skill Statistic)、KAPPA系数是3 种常用的评估模型精度的检验指标[13]。AUC值是受试者工作特征曲线(Receiver operating characteristic curve, ROC曲线)下的面积,是一个概率值,其值域范围为0~1,其含义为预测的正例排在负例前面的概率,数值越大则代表模型精度越高[91-92]。KAPPA系数是一种广泛应用于统计学模型的检验指标,主要用于一致性检验和衡量分类精度。Fielding和Bell[93]首次将该系数应用于物种分布模型的研究中,KAPPA 系数的取值范围为-1~1,可解释为模型预测结果和实际分类结果的一致程度。TSS值是由KAPPA系数改良而来的,其值域与KAPPA系数相同,TSS值越接近1,模型精度越高。一般情况下,当取值>0.8时,模型结果较为理想;当取值<0.4时,模型结果较差(Fielding & Bell, 1997; Hipólito et al., 2015)。 TSS和KAPPA值均为阈值依赖的统计量,阈值的选取是否会影响到模型比较结果还有待进一步考证[90]。此外,AUC值、TSS值、KAPPA系数是对模型精度的评估,而非针对研究结果的检验。研究结果检验最直接的方法是实地调查验证,有学者对研究结果进行实地抽样调查,验证研究结果的准确性[94],但此方法的实践存在较高难度。
当前,计算机技术、信息遥感技术、R语言技术已日趋成熟,物种数据库等互联网大数据共享使得物种分布的获取变得简易、方便,上述3个问题或将成为未来该领域研究创新的重要突破口。
尽管Citespace软件具有优良的图谱绘制功能,但其数据运行上限为20 000条文献信息,无法涵盖所有的文献,且如何解读图谱仍然是一项极具主观性的工作,容易出现诸如误读、漏读和选择性解读等问题,这些因素会对结果分析产生影响,未来的研究需要在使用Citespace软件时提高图谱解读的一致性和严谨性[95]。
致谢:广西玉林市农业科学院宁瑶、海南大学林学院谢承智、广西大学林学院马可锦对本文的写作进行了指导与帮助,特此感谢。
