基于候选中心融合的多观测点I-nice聚类算法
2022-05-07陈鸿杰何玉林黄哲学尹剑飞
陈鸿杰 何玉林 黄哲学 尹剑飞
簇信息是用于理解、归纳和划分数据群体的重要统计信息,是度量数据群体复杂性的一种量化指标.在簇信息中,簇的个数和簇的中心是最核心的元素.例如,在已知两者的情况下,可使用K-means[1]等聚类算法估计数据集上簇的成员关系、离散量化误差等信息.在仅知道簇个数的情况下,可使用谱聚类[2]等聚类算法估计簇的成员关系、数据点图的拉普拉斯矩阵特征值等信息.簇的成员关系信息又可进一步驱动数据处理的下游任务,如监督分类和半监督分类.因此簇的个数和簇的中心点通常是许多聚类算法关键的先验参数,需要提前设定两者或其一的聚类算法,称为有参聚类算法,如K-means和谱聚类等.簇数和初始中心点设定的好坏对于聚类算法的精度和效率都有很大的影响[3].
为了提升聚类算法的自动化能力,必须解决簇的个数和簇的中心点的估计问题,目前也存在一些研究成果[4-8],然而精确估计复杂大规模数据集所含簇个数和簇中心是一项富有挑战性的任务.因为簇的信息是关于数据群体的统计信息,通常能得到的是关于这个数据群体的某些样本数据集,从样本数据集出发,估计关于数据群体的信息存在固有的不确定性和偏置性.另一个原因是,簇的成员关系存在多样性,即用于判定一个数据点是否隶属于某个簇依赖于数据点之间的距离定义,而高维空间的距离定义千差万别,常用的有欧氏距离、闵可夫斯基距离、正态分布距离、积分距离、Wasserstein距离等.
另外,当面对较大复杂数据集时,现有的估计簇的个数和簇的中心点的聚类算法存在如下不足.
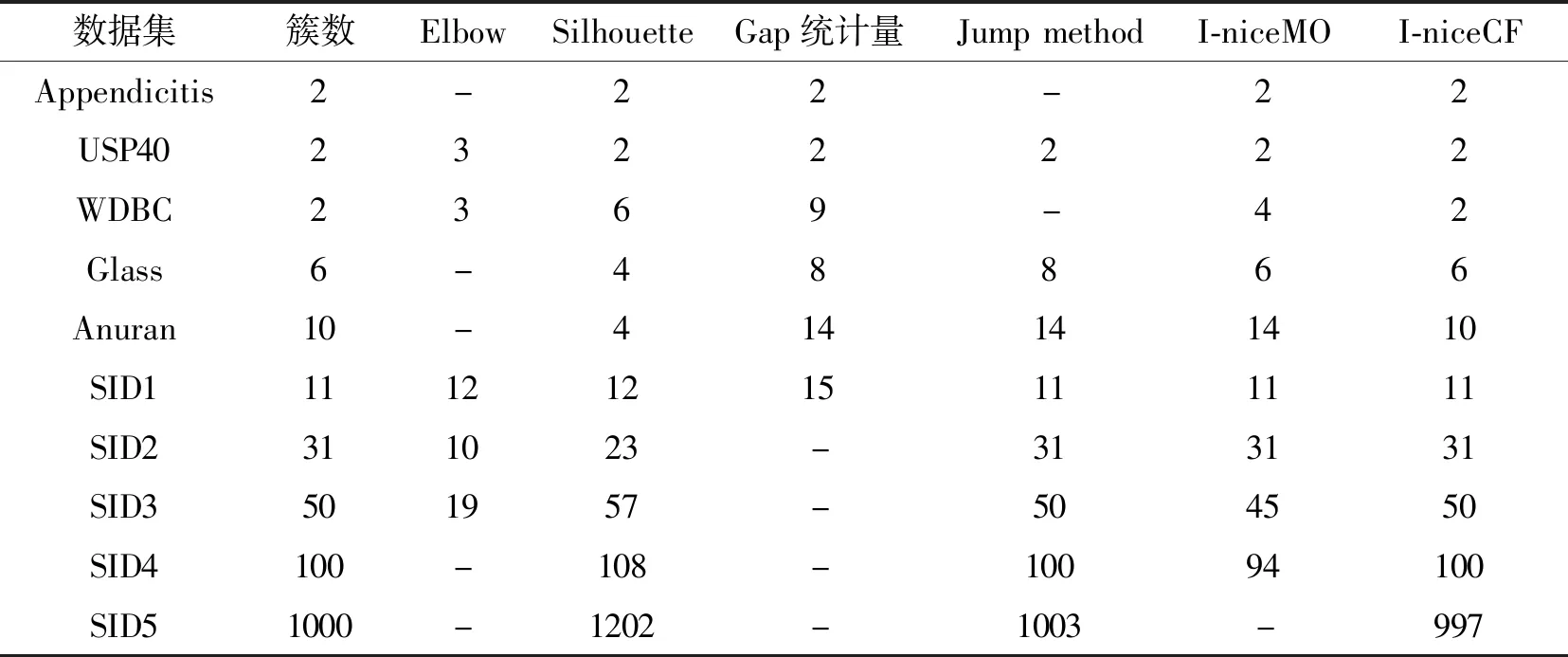
1)准确估计簇个数的能力有限.基于贝叶斯非参的方法[9-10]通过迪利克雷随机过程枚举各个维度的隐藏变量,建立随机过程模型,只能有效识别300多个簇.Elbow[11]被广泛用于估计数据中的簇数,计算簇心和对应簇内对象的平均距离和,观察以簇数为自变量、平均距离和为因变量的曲线,随着簇数增加,平均距离和逐渐降低,其中曲线存在“肘部”,对应簇数值即为结果.缺点在于曲线“肘部”的确定存在模糊性,一些数据集会出现没有“肘部”曲线特征的情况.Silhouette[12]针对数据集中每个对象,计算簇不相似度与对象i到同簇其它对象的平均距离,即对象i到异簇内对象的平均距离.两者的差值即为轮廓系数,平均轮廓系数越小表示聚类效果越优.Silhouette和Elbow均仅可识别10多个簇.
2)估计簇个数和初始中心点的质量较差.现有的无监督的簇个数估计算法,如Silhouette和Elbow,在10个簇内存在至少一位数的偏差.Tibshirani等[13]提出Gap Statistic,简称为Gap统计量,用于确定数据集中的簇数,在簇数K取不同值时,度量其簇内离散值的对数值与相应数学期望的差值Gap,进行簇数的合理选择,差值最大时的K值为最佳的簇数.但Gap统计量容易导致簇数的过高估计[14],在一些情况下差值Gap呈单调递增.另外这种方法无法较好地应用于源自指数分布的数据集[15].Mohajer等[16]在原本的Gap统计量的基础上进行修改,提出Gap*统计量,去除Gap值的对数操作,处理原Gap统计量中簇数过高估计的问题,但在簇间发生重叠的数据集上表现不如Gap统计量,并且在Gap统计量中差值单调递增的数据集上也并不保证在Gap*统计量中得到合理结果,而是得出过小的簇数估计值.Sugar等[15]提出Jump method,度量每个维度上每个观测值与其最近的簇中心之间的平均距离,确定簇数.Jump method在计算上较高效,并且在一系列实验中得到验证,但其畸变曲线容易出现单调情况,导致计算全局最优无法获得一个合理的估计值.通过交叉验证能在一定程度上解决该问题,但需付出昂贵的计算成本.此外,Yang等[17]提出M-means(Mountain Means Clustering Algorithm),在数据集的样本数超过500时,无法正确估计簇的个数.另外,在数据集具有高维特征且簇数较多的情况下,聚类算法往往需要人工介入、设计与观察各种渐进统计数据,如平均Silhouette宽度,才能获得较优的聚类结果.Maitra[3]寻找数据中的大量局部模式,选取分离程度最大的点作为初始中心点,在一系列实验上均取得可观结果.但当数据存在大量坐标(特征数)时,奇异值分解计算过程变难,阻碍在高维数据上的应用.
3)计算复杂度较高,不利于大规模数据应用场景.例如,基于谱聚类的算法[18]需要求解图拉普拉斯矩阵的特征根,计算复杂度为O(N2K),其中,N为样本点数量,K为簇数.狄利克雷过程混合模型[19]采用狄利克雷过程作为聚类参数的先验分布,在较大范围内搜索簇的个数K,并对整个数据集进行多次扫描,估计参数的后验概率,时间复杂度很高,不适用于大规模数据聚类场景[20].此类算法对于大规模数据处理而言是计算不可行的.对于一些基于图神经网络的聚类算法[21],由于需要计算每对数据点之间的距离及断开阈值,计算复杂度也较高,同时算法一般需要监督信息,较适用于半监督场景[22].一些基于密度的聚类算法可直接进行聚类而无需输入簇数或初始中心作为参数[23-24],但往往受较高计算复杂度或空间复杂度限制,难以在大规模或高维数据集上应用.
I-nice(Identifying the Number of Clusters and Initial Cluster Centres)[25]是一种基于观测点投影机制和混合伽马模型数据子集划分的无参聚类算法,可有效估计数据集的簇数和簇中心点并聚类.I-niceSO(I-nice with a Single Observation)和I-niceMO(I-nice with Multiple Observations)分别为I-nice的两种基本模式,I-niceSO基于单观测点投影.I-niceMO基于多观测点投影形成分治聚类框架,得出若干候选中心,集成后得到最终簇数和簇心结果.实验表明I-nice具有比Elbow和Silhouette更优的簇数估计精度,I-niceMO表现最佳.但在面对如下场景时,I-nice的效果与性能明显变差.
1)当数据集的簇之间样本量差异较大时,混合伽马模型无法对不平衡数据集进行较好地拟合,导致数据子集划分质量较差,进而影响候选中心点的选取.
2)当簇数规模较大时,遍历搜索最佳高斯混合模型(Gaussian Mixture Model, GMM)的过程十分耗时.
3)当簇之间的相对距离差异较大时,数据集得出的候选中心之间的距离关系更复杂,无法简单基于候选中心之间的空间距离实现正确集成.
上述场景在实际应用中经常出现,如何使算法能在不同的数据集上保持稳定的聚类效果及性能,是一个非常关键的主题.因此,本文提出基于候选中心融合的多观测点I-nice聚类算法(Multi-obser-vation I-nice Clustering Algorithm Based on Candidate Centers Fusion, I-niceCF),实现在各种数据集上的簇数和中心点的准确估计.首先沿用I-niceMO多观测点投影机制.然后基于GMM构件进行数据子集划分,提出粗细粒度结合的搜索策略,快速划分数据子集.在识别子集候选中心后,采用基于GMM构件归属向量的融合方法,对来自多个子集的簇候选中心进行集成,最终得到数据集的簇数和簇中心点.在合成数据集和真实数据集上进行一系列实验,结果表明I-niceCF能正确估计各类数据集的簇数和簇中心点,聚类效果较优.
1 基于候选中心融合的多观测点I-nice聚类算法
1.1 多观测点投影及数据子集划分
本文沿用I-nice,使用多观测点机制对高维数据集进行投影,得到对应的距离数组.然后使用GMM拟合距离数组,实现数据集的划分.
计算数据集的全部N个样本点到某一观测点的距离,得到对应的距离数组
X=(x1,x2,…,xn),
定义对应GMM为
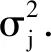
求解GMM参数,其中
Zi=j表示xi属于GMM的第j个构件,θn表示第n次迭代估计的参数.求解参数,得到拟合后的GMM,并对数据集进行划分.
通过单观测点得到的GMM进行数据划分,容易出现不同簇被归为同一子集中的现象.设置多个不同的观测点,分别基于其到数据集全部样本点的距离数组拟合求解,得到多个GMM,每个GMM对数据集进行不同的划分.
1.2 最佳混合模型搜索策略

在I-nice中,设M∈[Mmax-Δ1,Mmax+Δ2],逐个遍历求解得到M取不同值时的多个GMM,选取其中具有最小AICc值的混合模型为最佳模型GMMbest,构件数为Mbest.Mmax是通过核密度估计(Kernel Density Estimation, KDE)拟合距离数组计算密度函数曲线的波峰个数得到,当数据集上簇数较多时,KDE估计的Mmax和最佳模型构件个数Mbest之间的偏差也会较大,Δ1和Δ2需要足够大才能保证Mbest∈[Mmax-Δ1,Mmax+Δ2],从而使遍历搜索过程能得到最佳混合模型.具体而言,遍历搜索最佳模型所需时间与数据集簇数之间存在超线性关系.根据实验,可设
Mmax=(1-α)Mbest,
误差率α为实数区间内定值,对于遍历搜索策略,需
Δ1=Δ2=αMbest

本文提出粗细粒度结合的最佳GMM模型搜索策略,具体见算法1.
算法1粗细粒度结合的最佳GMM搜索策略
输入数据集Y对应观测点p的距离数组X
输出近似最佳混合模型GMMbest
阶段1粗粒度搜索
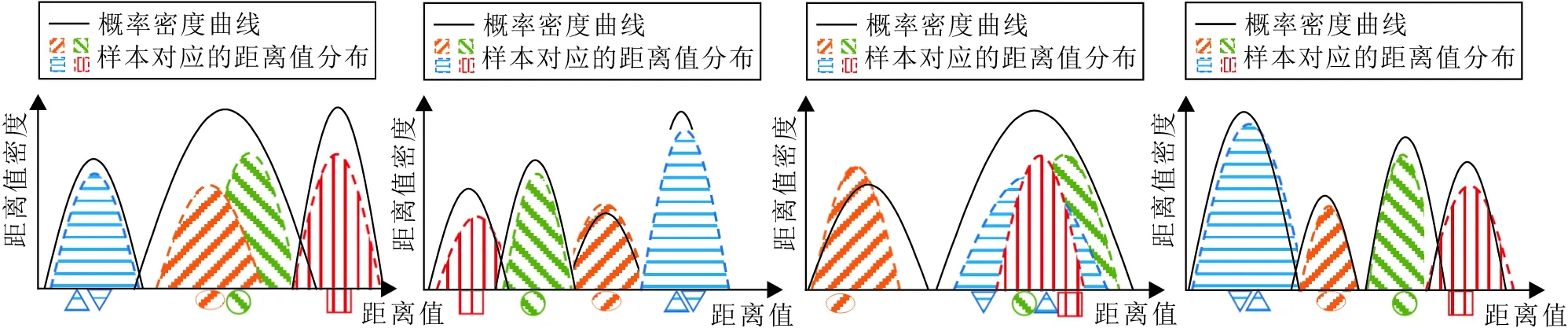
form=1;m 通过EM(Expectation-Maximization)算法求解 GMMm(X); 计算AICcm; ifAICc2-2m≤AICc2-3m& AICc2-2m≤AICc2-1m≤AICcmthen break end for 阶段2细粒度搜索 h=(2-3m-2-1m)/12 form′=2-3m+h;m′<2-1m;m′=m′+hdo 通过EM算法求解GMMm′(X); 计算AICcm′; ifAICc2-2m′≤AICc2-3m′& AICc2-2m′≤AICc2-1m′≤AICcm′then break end for GMMbest=GMM2-2m′ 按两个阶段进行最佳混合模型的搜索,第1个阶段进行粗粒度搜索,GMM构件数以底数为2的幂快速增长,粗粒度搜索的第i步求解GMM的构件数为2i,搜索可确定Mbest的近似区间.第2阶段在近似区间内进行一定步长的细粒度搜索.在2个搜索阶段中,均以AICc的“山谷”趋势作为搜索的结束特征.“山谷”趋势定义为AICc下降一次,然后连续增加两次的阶段,即 AICci≤AICci-1,AICci≤AICci+1≤AICci+2. 粗粒度搜索阶段需进行Mbest次求解,该阶段总复杂度为 细粒度搜索阶段在(2⎣log2Mbest」,2「log2Mbest⎤)区间进行,设搜索步长为区间长度的1/12,则细粒度搜索阶段复杂度为 综上所述,该搜索策略总计算复杂度为O(NMbest),搜索所需时间随簇数呈线性增加趋势,以线性效率高效搜索求解近似最佳混合模型,显著优于I-nice的遍历搜索策略,便于I-niceCF在大规模数据集上的应用. 本文提出基于候选中心融合的多观测点I-nice聚类算法(I-niceCF),准确集成来自多个观测点的候选中心. 经过多观测点投影及最佳GMM进行距离子集划分后,将分别针对各个子集内距离值对应的原始样本点执行聚类任务.每个子集任务内可通过k近邻法确定高密度区域,进一步选取k近邻最大的数据点作为候选中心;或采用密度峰值聚类算法(Density Peak Clustering, DPC)[24]进行聚类,得出高密度点作为候选中心.每个子集均得到若干候选中心,最终需进行集成任务,即集成来自全部观测点对应的最佳GMM的各个构件所得的候选中心. I-nice通过基于候选中心距离度量的方法进行候选中心集成,即通过候选中心之间的空间距离度量候选中心之间的冗余度,距离越小表示冗余度越高,更应将其合并以消除簇心冗余. I-nice的缺点是只考虑候选中心的相对距离,忽略数据集的原始分布情况.在簇间距离较均匀时,已验证是有效的,但当簇间距离差异较大时,容易出现错误合并或漏合并候选中心的情况,使得到的集成结果较差,直接导致整个算法得出错误的簇数和簇中心. 图1为在包含4个簇的数据集上得出的5个候选中心,虚线区域为对应各簇样本点的分布情况,5个填充点为待集成的候选中心,cb1、cb2归属于同个真实簇Gb,3个候选中心co、cg、cr分别归属于3个真实簇Go、Gg、Gr.候选中心cg、cr之间的距离小于候选中心cb1、cb2之间的距离,因此基于候选中心相对距离的集成方式无法同时保证合并cb1、cb2且保留cg、cr.按照I-niceMO,基于候选中心的相对距离进行集成,会出现两种错误.第1种为过度合并,cb1、cb2合并,cg、cr合并,co保留,虽然成功消除真实簇Gb的候选中心冗余,但也错误合并来自不同簇的cg、cr候选中心,最终得出簇数为3的错误结果.第2种为合并不充分,所设候选中心合并的距离阈值过小,图1中5个候选中心全部保留,导致最终得出簇数为5的错误结果. 图1 待集成的候选中心Fig.1 Candidate centers to be integrated I-niceMO这类集成方法仅考虑候选中心之间的相对距离,忽视数据集中各簇整体的分布情况,在簇间距离差异较大时,集成操作容易出现错误,因此有必要提出更合理的候选中心集成方法. 本文提出I-niceCF,可准确度量候选中心之间的冗余度.对于每个候选中心ci,有构件向量Ψi=[ζ1,ζ2,…,ζP],记录其分别在P个观测点的混合模型中对应的构件索引ζ.并结合曼哈顿距离和切比雪夫距离设计闵可夫斯基距离对: (1) 度量不同候选中心构件向量之间的相异度,相异度越小表明冗余度越高.简而言之,DMC的取值越小表明更多观测点将该两个候选中心划分为相同的子集或相邻的子集,这意味着它们在原始高维空间更趋向属于同一个簇. 相对设定的4个观测点,图1的5个候选中心可计算对应的构件向量,过程如图2所示. 每个观测点基于其到数据集所有点的距离数组,可解出对应的混合高斯分布,图2中虚线轮廓的填充区域对应的是图1中各真实簇内样本到观测点的距离数组构成的概率密度分布,各子图横轴下5个候选中心图标的位置对应它们到观测点的距离值.因为对于某特定观测点,存在多个真实簇位于同一距离区间,因此求解的最佳GMM的构件个数常不等于真实簇个数,会存在多个真实簇(对应距离值)包含在求解GMM的单个构件中,也会存在单个真实簇的各部分(对应距离值)分别被包含在GMM的不同构件中. (a)观测点1 (b)观测点2 (c)观测点3 (d)观测点4(a)Observation point 1 (b)Observation point 2 (c)Observation point 3 (d)Observation point 4图2 4个观测点样本距离值分布和混合模型概率密度曲线Fig.2 Distance distribution and probability density curves of GMMs of samples on 4 observation points 图3(b)为基于DMC求解的5个候选中心的相异度矩阵.I-nice错误合并cg和cr,在此处计算得出 DMC(Ψg,Ψr)=〈3,1〉, 而候选中心cb1、cb2的相异度 DMC(Ψb1,Ψb2)=〈0,0〉. 显而易见,2个冗余的候选中心cb1、cb2之间的相异度与其它候选中心之间的相异度差距明显,可容易设定标准以融合相异度小于一定范围的候选中心点对.具体地,设定 其中P为观测点数量.当2个候选中心的相异度DMC同时满足 DMC[0] 则这2个候选中心应进行融合. (a)构件向量 (b)相异度矩阵(a)Component vectors (b)Dissimilarity matrix图3 5个候选中心点的混合模型构件向量及相异度矩阵Fig.3 Mixed model component vectors and dissimilarity matrix of 5 candidate centers 总之,对于全部候选中心计算相异度矩阵,矩阵元素满足上述两个条件,表明对应的两个候选中心存在可融合连接.最终构成以全部候选中心为节点、以可融合连接为边的无向图,计算其连通分量,得出最终的簇数和簇心.基于GMM构件向量的候选中心融合方法步骤详见算法2. 算法2基于GMM构件向量的候选中心融合方法 输入候选中心c1,c2,…,cm,观测点O1,O2,…,OP, 最佳模型GMM1(M1,π1,θ1),…, GMMP(MP,πP,θP) 输出融合中心c′1,c′2,… step 1 对于c1,c2,…,cm,求各自对应的构件向量 其中 step 2 基于式(1)计算相异度矩阵 Φ=[DMC(Ψi,Ψj)]m×m, 1≤i≤m, 1≤j≤m. step 4 计算矩阵 [boolean(φij<〈Tm,Tc〉)]m×m, 并生成对应无向图G. step 5 求解得到连通分量CC1,CC2,… step 6 计算每个连通分量所含候选中心样本点的均值,得到融合后的中心c′1,c′2,… 在全部观测点对应GMM的各个构件的候选中心集成之后,将得到最终的簇数和融合后的候选中心称为初始中心点.将簇数及初始中心点作为先验参数传给K-means算法,得到数据集的聚类结果. I-niceCF流程如图4所示. 图4 I-niceCF流程图Fig.4 Flowchart of I-niceCF 设数据集D的样本数为N,特征数为D′,真实簇数为K,观测点数量为P.按照算法流程分步分析其时间复杂度. 1)计算P个观测点到数据集D的全部样本点距离的时间复杂度为O(PND′). 2)对于P组距离数组,分别进行近似最佳GMM搜索,设Mbest为距离数组对应的最佳GMM构件数量,1.2节中已推导得出搜索过程时间复杂度为O(NMbest),则该步骤总时间复杂度为O(PNMbest). 3)对P个最佳GMM的每个构件包含样本进行候选中心点的选择,具体采用DPC选取密度峰值点作为候选中心点.对于样本为n的数据集,若直接计算距离矩阵,时间复杂度为O(n2),通过R*-Tree[28]可快速计算与邻近点的距离,DPC时间复杂度为O(nlog2n).每个构件平均包含样本数为N/Mbest,则该步骤总时间复杂度为 即 4)候选中心点个数为βK,β∈[1,P],计算全部候选中心点的构件分量的时间复杂度为O(βKP),计算相异度矩阵,得出对应融合无向图的时间复杂度为O(β2K2),求解对应连通分量的时间复杂度为O(βK),则总时间复杂度为O(P2K2). 5)融合后的初始中心点作为输入参数进行K-means聚类,时间复杂度为O(KD′N). I-niceCF所需观测点数量P最多为D′+1,且Mbest∈[1,K].综合上述步骤,I-niceCF的平均时间复杂度为O(Nlog2N),最差时间复杂度为O(N2).相比其它不需输入簇数作为先验参数的传统聚类算法,时间复杂度与DBSCAN(Density Based Spatial Clustering of Applications with Noise)[23]、点排序识别聚类结构的聚类算法[29]、基于分布的大型空间数据库聚类算法[30]相同,具有较优的计算效率.该算法时间复杂度显著优于围绕中心划分的聚类算法[31]的O(N2K3)及谱聚类的O(N2K),差于K-means算法和BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies)[32]等需簇数作为参数的算法的时间复杂度,其中K-means算法时间复杂度为O(tKN),t表示K-means算法的迭代次数,BIRCH的时间复杂度为O(N). 本文实验在真实场景数据集和合成数据集上进行.真实数据集来自加州大学欧文分校机器学习库(http://archive.ics.uci.edu/ml)及开源手写字体库[33],实验前均剔除时间戳字段并进行归一化,具有多标签的数据集只选用单个字段作为标签,Anuran数据集使用Species作为标签字段.合成数据集采用多个高斯分布生成.真实数据集与合成数据集的具体信息分别见表1和表2. 表1 真实数据集信息Table 1 Information of real-world datasets 表2 合成数据集信息Table 2 Information of synthetic datasets 本文选择如下2个指标进行聚类结果的评价:调整兰德系数(Adjusted Rand Index, ARI)[34]和标准化互信息(Normalized Mutual Information, NMI)[35]. ARI计算公式如下: 设C={C1,C2,…,Cr}表示N个样本到r个簇的一个划分,Y={Y1,Y2,…,Ys}表示N个样本到s个类的一个划分.nij=|Ci∩Yj|,表示2个划分中同时位于簇Ci和类Yj的样本个数,ni表示簇Ci的总样本个数,nj表示类Yj的总样本个数.NMI计算公式如下: 其中,C表示簇标签,Y表示类标签,H(·)表示熵,I(Y;C)表示其互信息. ARI和NMI的指标值越大,表示聚类结果越优. 实验主机处理器信息为Intel Core i7-10700 CPU@2.90 GHz×16,内存容量为15.4 GB,操作系统为ubuntu 16.04LTS 64-bit.实验涉及程序均运行于Python 3.5.实验进行时对I-niceMO和I-niceCF共有的参数赋予相同值,若无特别说明,观测点数量均设为5,过滤系数设为(1,0.1).此外两种算法分治环节的各构件(或子集)内的聚类任务均采用DPC. 本节评估I-niceCF的簇数估计效果,与Elbow[11]、Silhouette[12]、Gap统计量[13]、Jump me-thod[15]、I-niceMO[25]进行对比.在5个真实数据集和5个合成数据集上进行实验,结果如表3所示. 由表3可知,I-niceCF簇数估计效果明显优于包括I-niceMO在内的其它算法.当数据集簇数低于10时,Elbow和Silhouette存在约1~2的估计误差.数据集簇数超过10时, Elbow开始失效,估计结果偏差很 表3 各算法在不同数据集上的簇数估计效果对比Table 3 Comparison of cluster number estimation results of different algorithms on different datasets 大或曲线无“肘部”特征,Silhouette估计结果误差也逐渐增大.当数据集簇数达到1 000时,估计误差已达到202,而Gap统计量在数据集簇数超过10时已失效,曲线呈上涨趋势.Jump method在5个簇数较大的合成数据集上的估计效果显著优于Elbow、Silhouette和Gap统计量,但在5个真实数据集上表现不佳.I-niceMO受维度较高和数据集不平衡的困扰,在真实数据集上存在个别误差,在合成数据集上明显优于Elbow和Silhouette,但在簇数达到1 000时,I-niceMO无法在合理时间内得出结果.I-niceCF几乎准确估计全部数据集的簇数,仅在面对具有1 000个簇的SID5数据集时,存在簇数估计偏差为3,I-niceCF估计出997个簇,此时其余算法除Jump method之外均已无法发挥作用,由此验证I-niceCF的簇数估计效果. 本节测试I-niceCF在不同数据集上的表现,验证本文针对I-nice候选中心融合方法的改进对I-niceMO的提升,以及验证I-niceCF在多种场景下的可行性. 考虑数据集的5个因素,分别为数据集的簇数K、单簇样本量CN、数据集的维度D、簇心距离差异程度σncd、数据集平衡度S.其中簇心距离差异程度和数据集平衡度是评估的重点,此处分别定义2个指标如下: σncd计算每个簇的簇心ci与对应最近簇心cnearest(i)的距离di,求得d1,d2,…,dK的标准差为σncd.簇数相同时,σncd越大表示对应数据集的各簇心之间距离差异越大.S表示数据集的平衡程度,计算每个簇包含样本数占数据集样本总数的比例π1,π2,…,πK,计算得出对应的熵,以此度量数据集平衡程度.簇数相同时,S越小表示数据集越不平衡,即不同簇所含样本数差异越大. 图5和图6分别表示σncd和S取不同值时数据集情况. 基于这5个因素,每组分别生成4个合成数据集,5组共20个数据集,详见表4. (a)S=1.0 (b)S=0.65 (c)S=0.44 (d)S=0.19图6 S不同时数据集情况Fig.6 Datasets with different S (a)σncd=2.768 (b)σncd=19.06 (c)σncd=78.03 (d)σncd=142.9图5 σncd不同时数据集的簇中心点图Fig.5 Cluster centers of datasets with different σncd 表4 I-niceMO和I-niceCF在20个合成数据集上的簇数估计结果对比Table 4 Comparison of cluster number estimation results of I-niceMO and I-niceCF on 20 synthetic datasets 因素K生成的4个数据集簇数分别为5,15,25,50,每个数据集内各簇样本数相同,单簇样本数均为100,数据维度(即特征数)均为2.因素CN生成的数据集均为2维5簇,单簇样本从100逐步增至2 000,每个数据集内各簇大小相同.因素D生成的4个数据集维度逐步增加.因素σncd生成的4个数据集对应σncd分别为2.786,19.06,78.03,142.9.因素S生成的4个数据集的平衡度依次减少,分别为2.322,1.914,1.635,1.213. 在20个合成数据集上使用I-niceMO和I-niceCF进行簇数估计,结果如表4所示.由表可知,在5组数据中,单簇样本量CN、维度D的变动对于I-niceMO和I-niceCF性能无影响,10个数据集均能准确估计簇数. 簇数K增加至50时,I-niceMO性能出现一定波动,估计簇数为44,与真实簇数相差为6,I-niceCF估计簇数为51.在σncd影响下,尽管Std3、Std4数据集上真实簇数仅为5,但I-niceMO错误估计簇数为6和9,这是因为σncd(Std3)=78.03,σncd(Std4)=142.9,簇心距离差异较大,导致存在冗余的候选中心未被合并. 图7为I-niceCF对Std1~Std4数据集的候选中心融合情况,I-niceCF准确合并属于同个真实簇的候选中心. (a)Std1 (b)Std2 (c)Std3 (d)Std4图7 I-niceCF在4个数据集上的候选中心融合情况Fig.7 Candidate center fusion for I-niceCF on 4 datasets 如图7(d)所示,I-niceCF在簇间距离差异很大时仍保持候选中心的正确融合,准确估计σncd生成的4个数据集的簇数,验证针对候选中心的融合方法的有效性.在S影响下,I-niceMO伴随着数据集平衡度的减小,性能出现下降,在数据集簇数仅为5时,分别做出簇数为8和11的错误估计,而I-niceCF对于S1~S4数据集均做出正确簇数估计.相比I-niceMO,I-niceCF在全部5个因素的20个数据集上始终保持稳定准确的簇数估计效果,验证I-niceCF在面对多种类型数据集时的稳定性能. 本节通过计算ARI、NMI值,评估I-niceCF的聚类结果,并对比其它聚类算法,包括1)同类型的I-niceMO[25],2)无需簇数作为先验参数的DBSCAN[23]和DPC[24],3)需要预先输入正确簇数作为参数的FCM(FuzzyC-mean)[36-37]和K-means算法[1]. 在实验过程中,I-niceMO和I-niceCF的设置将遵照2.1节实验设置,另外将真实簇数作为先验参数赋予FCM和K-means.K-means算法重复10次实验,每次均随机生成对应数量的初始中心点,取10次结果的ARI和NMI值的平均值作为K-means算法的最终结果.DBSCAN和DPC将以不同参数多次运行,取得最佳结果的一次用于对比,即 具体地,DBSCAN的参数minPts在1至50内多次选择,参数eps在dn至50dn的范围内[38]多次选择,其中dn表示数据集每个样本点到对应的最近样本点的平均距离. 各算法聚类实验的ARI和NMI值如表5和表6所示,表中黑体数字表示最优值.除了在USP40、WDBC数据集上I-niceCF的精度与输入正确簇数的FCM和K-means的精度持平,在其余数据集上I-niceCF精度均优于FCM和K-means.I-niceCF在全部数据集上都得到最高的ARI、NMI值,优于包含I-niceMO在内的其它对比算法,由此验证I-niceCF的有效性. 表5 各算法的聚类结果对比Table 5 Comparison of clustering results by different algorithms 本节考察I-niceCF的参数敏感性,I-niceCF的主要参数为观测点数量P及过滤系数(fkde,fdpc).fkde表示在对各构件所含样本进行高密度点(候选中心)选择前,对构件内样本的过滤比例.具体是通过KDE拟合构件对应的距离数组得到对应的密度值,保留较高密度值对应的距离值,保留比例为fkde.该设置主要是在大规模数据上可通过过滤一定比例的低密度点,减少后续进行高密度点寻找的代价.本文的实验环节均设置fkde=1.0,即全部保留.fdpc的取值则影响使用DPC对每个GMM构件对应样本进行高密度点识别时的截断距离dc,具体为 dc=disasc[ddpc·Len(disasc)], 其中disasc为升序排序的样本点间距离数组.DPC对应于dc取值的鲁棒性已得到说明[39],因此,本文重点考察I-niceCF关于参数观测点数量P的敏感性. 对于D维空间中的2个不同样本点a、b,必有多个观测点o1,o2,…,oD+1,满足 在20个不同数据集(数据集详情见表4)上测试I-niceCF在不同观测点数量时的聚类效果,ARI、NMI值如图8所示.在(a)~(d)子图中,当P=2时,I-niceCF在4个数据集上均未取得正确结果,随着观测点的增加,I-niceCF的聚类性能变优,P=4时已全部正确聚类.(e)~(h)、(q)~(t)子图中的聚类表现类似,都能在P≤5时实现正确聚类.在(i)~(p)子图中,D、σncd生成的8个数据集的ARI、NMI值上涨趋势慢于其余12个数据集,尤其是在(k)~(l)子图中,它们对应的D3、D4数据集的特征数(维度)分别达到50和500,但最终也都在P≤5时实现正确聚类.由图8可知,较少的观测点数量P即可实现在不同数据集上的准确聚类任务,包括高维数据集. (a)K1 (b)K2 (c)K3 本节测试I-niceCF和I-niceMO在不同规模数据集上的运行时间,结果如图9所示. 图9 I-niceCF和I-niceMO在不同规模数据集上的运行时间对比Fig.9 Running time comparison of I-niceCF and I-niceMO on datasets of different scales I-niceCF平均时间复杂度为O(Nlog2N),而I-niceMO的时间复杂度为O(N2),运行时间增长趋势显著快于I-niceCF.此外数据规模大于30 000时,I-niceMO的运行时间和内存占用非常大.I-niceMO的最佳GMM遍历搜索策略不适应于较大规模的数据,计算复杂度与数据集上真实簇数的平方成正比.I-niceCF的粗细粒度结合的搜索策略大幅降低算法的运行时间. 上述为单机情况下算法的效率评估,此外,I-niceCF的计算流程(见图4)使其在当下分布式平台上更容易部署且更高效. 本文提出基于候选中心融合的多观测点聚类算法(I-niceCF),改进I-niceMO的聚类效果.I-niceMO在数据集内簇大小不平衡或簇心距离差异过大时聚类性能出现波动.为了解决这些问题,本文提出粗细粒度结合的混合模型搜索策略,使I-niceCF可快速求解最佳混合高斯模型,并进行子集划分,提升I-niceCF在不平衡数据集上的拟合精度和效率.基于GMM构件向量,提出候选中心融合方法,进行I-nice候选中心之间的相异度度量与集成. 在真实数据集和合成数据集上评估I-niceCF的簇数估计效果,并基于5个因素(簇数、单簇样本量、维度、数据集平衡度和簇心距离差异程度)验证I-niceCF在不同数据集上的合理性,克服I-niceMO的缺点.此外,进行聚类精度对比实验,结果表明I-niceCF的聚类效果较优.I-nice多观测点投影机制适合在分布式环境下工作,结合候选中心融合方法,今后将探究如何将该方式应用于其它聚类算法的分布式部署和集成.1.3 基于GMM构件向量相异度的候选中心融合




1.4 本文算法流程及复杂度分析

2 实验及结果分析
2.1 实验设置


2.2 合理性验证
2.3 可行性验证




2.4 有效性验证

2.5 参数敏感性评估


2.6 算法效率评估

3 结 束 语
