基于冗余分析的用电信息采集系统数据压缩方法
2022-05-06郑国权窦健卢继哲郄爽叶方彬胡浩星
郑国权,窦健,卢继哲,郄爽,叶方彬,胡浩星
(1.中国电力科学研究院有限公司, 北京 100192; 2.国网浙江省电力有限公司电力科学研究院, 杭州 310006; 3.重庆大学 微电子与通信工程学院, 重庆 400044)
0 引 言
在智能电网中,用电信息采集系统(以下简称用采系统)对分析用户用电行为以及电网运行状态具有重要意义。用电信息监测最重要的是实现无间断的用电信息采集与远程通信,远程通信指用电信息采集系统中采集终端(下文称终端)与采集主站(下文称主站)之间的数据传输。现阶段实际运行的用采系统的远程通信,多采用GPRS/CDMA、专用230 MHz等无线通信方式进行数据传输[1],高强度的监测意味着采集系统会对下属的终端节点进行全天候的数据采集与监控,用电信息的高频率上报会产生大量的数据积压,从而对无线传输造成严重的通信负荷。
数据压缩技术可对数据量进行有效地压缩,以减少存储空间,提高信息数据传输、存储和处理的效率[2]。目前数据压缩技术已经广泛应用于视频、图像、语音等业务。在电力系统中,各类压缩算法的应用也已经有了先例[3-8]。文献[6]针对电力系统数据周期性的特点,选用合适的小波基将电力数据变换到小波域,然后对高频和低频部分分别进行编码以实现高效压缩。文献[7]针对电力系统故障信号波形在特定时间段内的自相似性,提出了一种基于分形插值的数据压缩与还原算法,有效地提升了故障录波数据的压缩倍数。文献[8]充分利用了电力系统波形数据的周期性、有界性和冗余性特点,在DSP平台上实现了波形数据的高效压缩。然而,上述方法都是针对理论上的单一变量的连续测量数据或者波形数据进行压缩,而在实际用电信息采集与通信过程中,传输的不仅有单一的连续电压值或者电流值,还需加入召测、控制等协议信息以组成封装好的数据报文。因此,研究适合实际应用的用电信息采集系统远程通信报文的压缩方法以降低海量报文数据中存在的冗余信息,最大程度地降低数据传输与存储压力已经成为电力行业的迫切需要。
用采系统分为终端采集系统、远程传输系统和采集主站三大部分,考虑到大量的用电数据通过终端采集上报给主站会对公网的传输造成巨大的压力,因此,文中首先详细分析了数据报文冗余性的产生来源,以此为基础对其进行针对性压缩。由于用采系统远程通信报文通信协议包含控制、互操作等信息,在压缩和恢复的过程中不能对报文结构与内容的完整性产生影响。因此将采用无损压缩方式对报文进行处理。然后,针对数据报文的三种冗余来源:帧间冗余、模式冗余以及编码冗余,分别采用报文预处理、LZ77算法、Huffman算法对数据报文进行压缩,并在此基础上提出了一种组合压缩的方式,实验证明该方法可以最大限度压缩报文长度,提高传输效率。
1 用采系统远程通信报文结构与冗余分析
1.1 用采系统远程通信报文结构
主站与终端进行数据传输需要遵循一定的通信协议,通信协议约定了通信双方在接收报文时的数据格式、编码方法以及传输规则[9]。以图1所示国家电网公司Q/GDW 1376.1-2013协议报文帧结构为例,可见主站与终端的各种交互及上报信息均以帧为基本组成单位,由多个字节严格按照协议规定顺序排列组成。帧中各个域的长度与含义详见文献[10]。

图1 Q/GDW 1376.1-2013协议帧格式Fig.1 Frame format specified in Q/GDW 1376.1-2013 protocol
1.2 用采系统远程通信报文冗余分析
数据能够被压缩的前提条件是数据报文内部与报文之间存在的冗余性。首先,报文必须按规定帧格式通信意味着报文结构间存在一定的相似性(帧间冗余);其次,由于通信协议对于数据的编码方式是固定的,因此报文中重复上报的信息(时间信息)会被编码成许多重复的字符串(模式冗余);最后,每帧数据报文中各个域的值由上报节点当前物理状态直接决定,因此编码之后的报文在信息学上也必然存在着冗余(编码冗余)。
帧间冗余体现在数据报文之间结构的相似性上,由于通信协议严格规定了数据报文各个域的组成方式,因此一段时间之内从某个固定的采集终端上报给主站的所有报文中必然有一些信息(如终端地址信息)是相同的。表1是一个固定的终端节点在一天内发出的所有通信报文的一部分(采用国家电网DL/T 698.45-2017[11]协议)。

表1 终端节点一天之内上报的部分数据报文Tab.1 A portion of datagrams sent in one day by terminal node
Q/GDW 1376.1-2013、DL/T 698.45-2017等通信协议实现了对用户数据的封装,通过加入帧头、帧尾、地址、长度等校验信息可以对数据报文进行有效地差错控制,因此也可以在近距离通信中直接应用于链路层。但当通过远程传输系统来传输时,报文实际上是作为远程传输系统通信协议应用层载荷加载到通信协议栈中,由远程通信协议栈负责可靠传输。因此重复发送地址、帧头、帧尾等校验信息就失去了纠错意义,对于信息存储与传输是冗余的,可以适当减少发送次数。根据DL/T 698.45-2017协议规定,可将每帧报文写成通用的格式: 68+长度校验+控制码+地址+帧头校验码+链路用户数据+校验码+16,由于表2中的报文来自于同一终端节点,因此每帧数据用来表示地址的字节都相同,上述数据中终端地址表示位是从第5个字节开始,内容为05 84 23 00 00 20 15 00,共8个字节,同时,帧头与帧尾标识符对于每帧数据报文都是固有的并且出现的位置固定,因此可以在传输过程中忽略。
模式冗余是指由于节点重复上报与通信协议编码方式固定导致的在报文内部形成的大量重复的字符串[12]。如终端在上报某些电能信息之前总是会将当前的时间一同上报,于是相同的时间标识就会形成一种固定的“模式”在报文中多次出现,具体表现如表2所示。

表2 报文内部重复的时间标识字符串Tab.2 Duplicate time identification string inside the datagram
编码冗余可用信息论中“信息熵”的概念来说明。每条数据的“熵”值越小,代表该数据包含的信息量越少[13-14]。而信息量少,证明可使用更少的二进制位来表示该条报文。具体来说,数据报文由不同字符组成,而不同字符在报文中出现的概率不同,根据信息论中对熵的定义,假设报文中包含某一字符S,对应出现的概率为P,则S的信息熵E定义为:
E=-log2(P)
(1)
式中log2(P)表示以2为底P的对数,单位为bit。由式(1)可以看出,当符号出现的概率越大,熵值E就越小,即当字符S出现的次数越多,S所包含的信息量就越少。下面以具体的数据来说明。表3为一个Q/GDW 1376.1-2013数据报文实例,我们对报文中字符次数、出现概率以及对应的熵值做出了统计,如表4所示。

表3 Q/GDW 1376.1-2013协议数据报文实例Tab.3 An example of Q/GDW 1376.1-2013 protocol datagram

表4 数据报文中字符的次数、概率和熵Tab.4 Number of occurrences of symbols appeared in the datagram and their respective probability and entropy
可见,理论上完整表示该帧报文只需要494个二进制位,而实际上在传输过程中却需要花费87×8=696个二进制位来表示该帧报文,因此从报文的整体内容来看,可以通过降低高频字符的二进制表示位数来对报文进行压缩。
2 用电信息压缩算法及其实现原理
由上面的分析可以看到,帧间冗余、模式冗余以及编码冗余是对用电信息远程通信报文压缩的可行性基础,文中针对这三种冗余分别进行处理,以达到缩短报文长度,减少数据传输量的目的,整体的处理流程如图2所示。
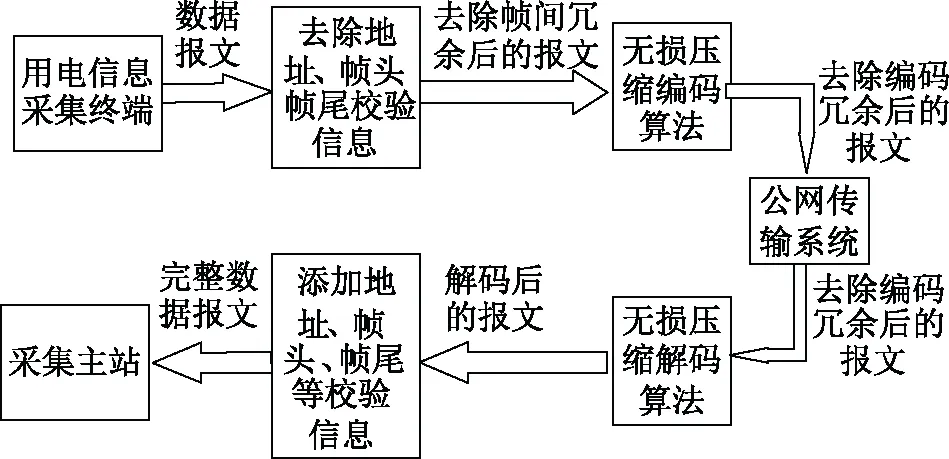
图2 整体处理流程Fig.2 Overall processing flow
2.1 帧间冗余压缩
根据对报文帧间冗余的分析,当报文数据来自于同一个采集终端时,帧头、帧尾标识以及经过通信协议编码后的地址信息都相同。当通过远程传输进行通信时,去除重复信息对于报文的存储与传输没有影响[15]。因此在对报文进一步压缩之前,先进行预处理,去除重复发送的帧头、帧尾以及地址信息,可以消除帧间冗余。由于模式冗余一般出现在报文的链路用户数据区域,预处理操作并不会影响到这个区域的数据,而编码冗余只与报文内部字符出现的频率相关,只要报文内部每个字符出现的频率不符合均匀分布,编码冗余是一定存在的,因此对报文进行预处理操作并不会影响报文的其他冗余性。
2.2 模式冗余压缩
由分析可知,模式冗余表现为报文内部形成的大量重复字符串。LZ77算法对于存在大量重复内容的文件有良好的压缩效率,因此文中将用LZ77算法来消除报文中存在的模式冗余。LZ77编码方法是基于字典的无损压缩算法,它的核心思想是基于数据结构的重复,在编码过程中通过在已经出现的数据中查找重复出现的内容来去除这种冗余,以此实现数据的压缩[16]。
2.2.1 LZ77算法的编码
LZ77算法将数据中重复出现的长字符串用字典索引来表示,这需要一个滑动窗口,它包括两部分:分别为搜索缓冲区以及前向缓冲区。在编码时将文件中的字符读入滑动窗口中的前向缓冲区中,再通过搜索缓冲区。搜索缓冲区中的数据作为建立字典索引的依据,前向缓冲区中的数据与搜索缓冲区中的数据进行比较,查找最长的字符串匹配。编码流程图如图3所示。
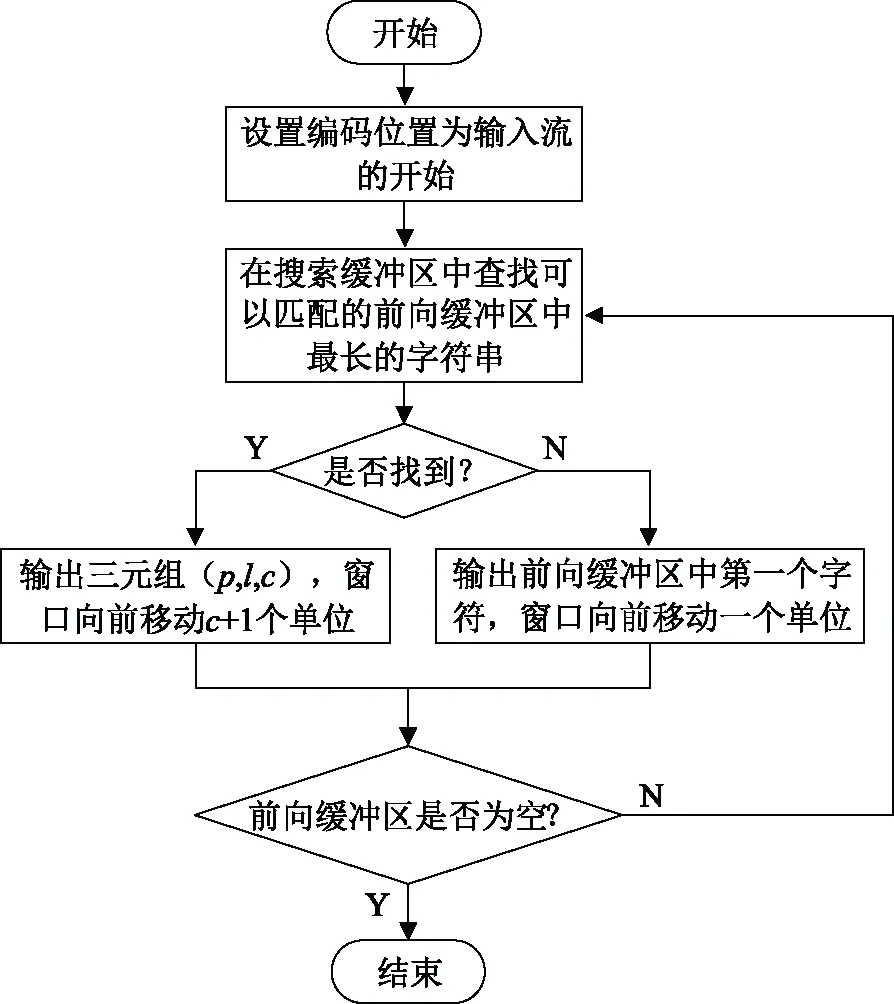
图3 LZ77算法编码流程Fig.3 Encoding flow of LZ77
2.2.2 LZ77算法的解码
LZ77算法的解压缩过程同样需要用到滑动窗口,窗口大小与编码时的搜索缓冲区长度相同,通过解码标记和保持滑动窗口中的符号来更新解压数据。当解码单个字符标记时,将标记解码成字符拷贝到滑动窗口中,解码元组标记时,在滑动窗口中查找相应的偏移量,同时找到指定长度的字符串进行替换。
2.3 编码冗余压缩
由第二节分析可知,只要报文中字符出现频率不符合均匀分布,就会存在编码冗余。而Huffman编码可以根据使用频率最大化节省字符的存储空间,因此我们用Huffman算法来消除报文中存在的编码冗余。Huffman是变长编码方法,以数据中各个字符出现概率的大小为基础对字符赋予不同长度的代码,是一种优化静态编码方法,产生的二叉树具有最小的加权长之和∑WjLj,其中Wj为某个符号出现的频率,Lj为该字符的编码长度。
2.3.1 Huffman算法的编码
Huffman编码最重要的就是构造Huffman树,构建Huffman树的基本步骤如下:
(1)统计各个字符出现的频次及字符总数统计,将频率从小到大排序成{W1,W2,…,Wk,Wm},并构造出森林F={T1,T2,…,Tk,Tm}。其中Ti为左右子树为空,权值为Wi的二叉树;
(2)遍历森林中所有二叉树,找出根节点权值最小的两个二叉树T1,T2合并成为一颗新的二叉树T(T的左子树为T1,右子树为T2),令T的根节点的权值为T1T2的根的权值之和,之后将新生成的二叉树T按根的权值大小顺序加入到森林F中去。同时从F中删除这两棵二叉树;
(3)重复步骤(2),直到森林中只剩下一棵树。
Huffman算法根据构建的Huffman树来对字符进行编码,在Huffman树中,待编码字符必定是叶子节点,编码从根节点开始依次寻找叶子节点,在树有了分叉时,向左的路径记为代码0,向右的记为代码1,直至找到原始的文件的字符,即实现了对该字符的编码。
2.3.2 Huffman算法的解码
Huffman算法解码需要利用Huffman树,因此,在压缩文件时必须要将构建Huffman树的一些必要的统计信息(字符总数,每个字符出现的频率)写入压缩文件中,这样才能完成解压。解压过程是压缩过程的反操作,根据读取的压缩文件的二进制数据流,开始遍历Huffman树,从根节点开始,当读取到0时,取根节点的左子树,读取到1的时候,取根节点的右子树,然后重复上述操作,直到访问到的节点是一个叶子节点,读取该叶子节点表示的字符,即完成一个字符的解码。
3 仿真实验及结果分析
为验证前文的冗余性分析及压缩方法,我们在真实的用电采集系统采集的数据上进行了测试,并进一步探究了LZ77算法中搜索区域长度与前向缓冲区长度对报文压缩比例的影响,分析了各个长度范围内数据报文压缩的最佳参数组合。之后在单种算法压缩的基础上,通过对三种冗余各自的特性与相互关系的分析,提出了一种组合压缩方式来进一步提升压缩效果。
3.1 使用Huffman算法消除编码冗余
本节使用的数据来自国家电网某省公司主站真实采集的符合Q/GDW 1376.1-2013协议专变上行数据报文,共含有10 000条数据报文。我们对所有数据报文的长度做了统计,如图4所示。可见大量数据报文集中在[0,50),[50,100)和[250,300)这三个长度区间。

图4 数据报文长度分布统计表Fig.4 Statistic of datagram length distribution
在得到整体报文长度分布之后,使用Huffman算法对每一个长度范围内的所有数据报文进行压缩并统计平均压缩比例,得到的结果如表5所示。可以看到,Huffman算法对于长度范围处在[450,500)范围内的报文有着最好的压缩效果,而对于长度范围为[0,50)的数据并没有起到压缩效果,原因在于Huffman编码需要在编码的同时写入字符的统计信息,对于长度很短的报文来说,存储字符统计信息所需要的存储空间与原有报文所占用的存储空间基本相同,这在很大程度上会影响Huffman编码的效果。而除了[0,50)长度范围内的短报文,其他所有长度范围内的报文都能被有效压缩。

表5 各长度范围的报文平均压缩比例Tab.5 Compression ratio of datagram in each length range
3.2 使用LZ77算法消除模式冗余
由于LZ77算法的缓冲区长度对于压缩效果有极大影响,因此文中就两个窗口长度对报文压缩比例的影响进行了探究。由于所使用的数据报文最长的长度没有超过500个字节(1000个字符),因此先将搜索缓冲区的长度设定为最长报文长度的一半(500个字符),改变前向缓冲区的长度对每条报文进行压缩,得到各个长度范围内数据报文的平均压缩比例随前向缓冲区长度变化的曲线如图5所示。

图5 前向缓冲区长度对压缩效果的影响Fig.5 Effect of forward buffer length on compression ratio
分别设置10种(10~100,步长为10)不同的前向缓冲区长度进行试验,从实验结果可以明显看出,除了长度范围在[0,50)和[50,100)的数据报文的压缩比例呈现一个整体上升的趋势之外,其他几个长度范围的数据报文的最佳压缩比例对应的前向缓冲区长度均为30个字符。为了验证前两种长度范围的报文在前向缓冲区长度为10个字符时是否已经达到了最佳的压缩比例,对这两种长度范围的报文多增加了5种(2~10步长为2)前向缓冲区的长度并进行实验。长度范围在[0,50)的报文在前项缓冲区长度达到4个字符的时候压缩率最低,长度范围在[50,100)的报文在长度为8的时候压缩率最低。由于LZ77算法的思想是使用三元组来表示源文件中重复出现的字符信息,存储三元组同样需要存储空间,前向缓冲区的长度越长,意味着三元组中用于存储该长度的二进制表示位越多,维护字典的开销也就越大。只有当前向缓冲区长度与文件中前后文能匹配到的最长字符串长度大致相同时,LZ77算法才能达到最佳的效率。
根据上述实验结果,将每个长度范围内报文的前向缓冲区设置为对应的最佳长度,然后分析搜索缓冲区长度对于数据报文压缩比例的影响,得到的实验结果如图6所示。
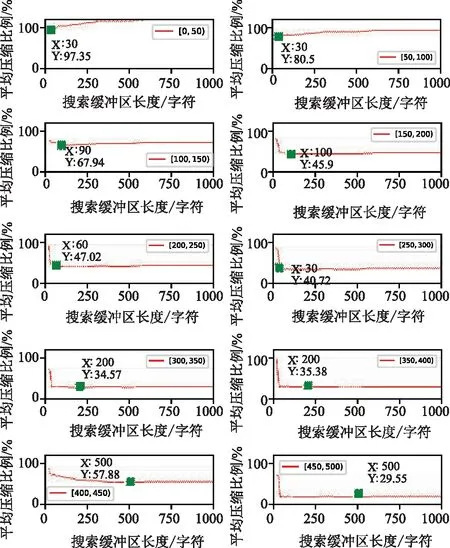
图6 搜索缓冲区长度对压缩效果的影响Fig.6 Effect of search buffer length on compression ratio
分别设置20种(0~100步长为10与100~1000步长为100)搜索缓冲区长度。搜索缓冲区长度代表着在多大的搜索空间中进行查找与匹配,理论上搜索空间长度越大,匹配到重复信息的可能性也越大,压缩效果也越好,但是从实验结果来看,每个长度范围内的数据报文都存在着最佳的搜索缓冲区长度,是因为在增加搜索缓冲区长度的同时也增加了三元组存储的成本,当压缩文件较小或者重复信息出现较为密集时,一味增加搜索缓冲区的长度并不能很好地提升压缩效果,反而会增加三元组的存储消耗。因此如何使用最小的搜索缓冲区长度来达到最高的压缩效率才是问题的关键。从实验结果可以看到,当前向缓冲区长度和搜索缓冲区长度均达到最优时,LZ77算法对于任何一种长度范围的报文都可以达到压缩的效果,各个长度范围的报文使用LZ77算法能达到的最优压缩效果与对应的两个缓冲区长度如表6所示。

表6 LZ77算法对于各个长度范围内的数据报文能达到的最佳效果Tab.6 Optimal effect of LZ77 algorithm which can achieve for the datagrams in each length range
在得到每个长度范围内的报文最佳压缩比例之后,我们将LZ77算法与Huffman算法做了一个比较,结果如图7所示。其中,圆标线表示Huffman算法的压缩结果,星标线代表LZ77算法的压缩结果,可以看到LZ77算法整体优于Huffman编码,而且对于较短的数据报文LZ77算法依旧可以起到压缩效果。但在长度范围为[400,450)范围内,Huffman压缩的效果要优于LZ77,通过进一步分析,该范围内的报文中包含大量的连续字符‘0’,而且连续长度远远超出了设定的前向缓冲区长度30(最长为140个字符),但是报文前后文中并没有像其他报文一样出现明显重复的时间信息,重复信息分布过于集中,这种情况下LZ77算法相当于只对报文中某一块区域起到了压缩效果,对其他区域却起不到压缩效果。而Huffman算法是基于报文内部字符的统计信息进行压缩,并不注重报文的内部结构,因此针对这种情况,Huffman算法有着更好的压缩效果。

图7 Huffman算法与LZ77算法效果对比Fig.7 Effect comparison of Huffman algorithm and LZ77 algorithm
3.3 用电信息采集远程通信报文组合压缩探究
由于数据报文的三种冗余性之间是相互独立的,单种算法无法同时消除所有的冗余,为了进一步提升报文的压缩效果,文中采用组合压缩的方式对报文冗余性进行全面消除。根据分析,报文预处理并不会对另外两种冗余性产生影响,因此将其置于组合压缩中的第一步,考虑到Huffman编码会暂时破坏目标文件的内容与结构,如果先进行Huffman编码会使得报文的模式冗余得不到有效处理,因此在对报文预处理之后先使用LZ77编码再使用Huffman编码来对报文进行组合压缩,组合压缩流程如图8所示。

图8 数据报文组合压缩流程Fig.8 Combinatorial compression process of datagram
实验所用的数据是来自于一个终端节点一天之内上报的所有数据报文,通信协议是DL/T 698.45-2017协议,该数据集中统计了2019年8月5日某终端节点上报的17 641条数据报文,文中对整个数据文件进行压缩处理并将各个阶段的处理结果与压缩结果进行了统计,结果如表7所示。

表7 组合压缩结果Tab.7 Result of combinatorial compression
为了进一步验证组合压缩顺序对压缩结果的影响,交换了LZ77编码与Huffman编码顺序后重新测试,各个阶段的处理结果与压缩结果如表8所示。可以看到交换编码顺序后的压缩结果远远比不上交换之前的结果。

表8 交换编码顺序后组合压缩结果Tab.8 Result of combinatorial compression after exchanging coding order
4 结束语
智能电网需要以大量用户用电数据分析为基础,随着采集终端的泛在化及采集频率的提高,各终端上报的数据量将大大增加,对数据传输与存储造成严重负担。通过压缩算法来降低数据报文的数据量,提高网络传输效率是电力行业一个亟待解决的问题。文中通过对用采系统远程通信报文的分析,从报文的帧间冗余、模式冗余以及编码冗余三个方面讨论了数据报文可以被压缩的现实基础,并有针对性地使用三种方法来消除三种冗余。结果表明,Huffman算法可以有效消除编码冗余,但是其在数据报文较短(<50B)的情况下起不到压缩效果;LZ77算法可以有效地消除模式冗余,当报文中含有大量重复上报的信息时,LZ77算法相较于Huffman算法可以达到更好的压缩效果。文中同时对LZ77算法中两种缓冲区的长度对于报文压缩比例的影响做了相应探究,找到了每个长度范围内报文的最佳压缩参数。由于单种算法无法同时消除报文的三种冗余,因此通过对三种冗余各自的特性及相互之间的关系分析,设计了具有时间顺序的组合式压缩方法,得到了更好的压缩结果。通过对数据报文的压缩可以极大地缩短报文的传输时间,提高传输效率,降低存储资源消耗,在为用电企业降低成本的同时,为智能电网的多种应用提供有力的保障。
