基于动态时间跨度与聚类差异指数的用户行为异常检测算法
2022-05-06曾献辉代凯旋
詹 麟 ,曾献辉 ,2,代凯旋
(1.东华大学 信息科学与技术学院,上海 201620;2.数字化纺织服装技术教育部工程研究中心,上海 201620)
0 引言
物联网的迅速发展使其成为了信息化社会的重要一环,其中通过智能家居可以将用户使用的各种设备联系到一起,通过各种连接技术如WiFi[1]、ZigBee[2]、蓝牙[3]将原先机械式、单一化的设备变得具有可控性[4-5]和智能化[6-7],将生活质量提高了一个台阶[8-9]。
通过对智能家居环境下采集的数据进行计算和分析,文献[10]提出了一种从家庭智能电表数据中提取用户行为模式的统一框架,通过集成的频繁模式增长算法和各种机器学习算法的分类来检测用户的异常模式。 文献[11]通过隐马尔科夫模型对智能家居环境下的用户行为进行预测。 文献[12]提出了一种基于用户行为模式的智能家居控制策略,通过对用电量的挖掘与分析,在此基础上设计对应的智能家居系统控制策略。 文献[13]采用关联规则发掘算法对智能家居下的用户行为进行预测,优化了智能家居系统的控制策略。
但现有的研究仍有些许不足,通过各种机器学习对数据进行分类后进行异常检测,可能实时性得不到保障[14],若用户行为发生了概念漂移,则不能及时调整;构建数学模型局限于存在线性关系的数据集,训练集的数据过于关注历史数据,不能对新的行为习惯做出检测,可能存在误判[15];通过关联分析对用户异常行为进行检测[16]比较依赖经验值,在不同的规模下准确率也会受到一定影响。 对于以上缺陷本文提出了一种基于实时数据流的概念漂移检测方法。 首先采集用户家中使用智能家居的能耗和传感器的使用数据,对这些数据进行聚类学习得出用户的正常行为,之后以聚类为标签对加入新的实时数据流进行分类,通过检测聚类的异常性指数得出用户哪些行为发生了改变,对改变后的数据进一步计算,比较LOF 数值[17]得出哪些行为数据导致了概念漂移的发生。 该算法能够对检测用户异常行为的实时性做到保证,耗时非常短,且准确性较高。
1 用户异常行为检测总体框架
在智能家居的环境下,用户所使用设备的状态数据通过传感器进行采集,这些数据的背后隐含了许多用户的行为模式,通过对采集到的数据进行分析可以掌握用户的行为习惯,并对用户的异常行为进行判断。 现有的研究大多数是通过集成模型对流数据进行分类,使其能够适应流数据中出现的概念漂移;运用机器学习以历史数据作为训练集,将训练好的模型去检测实时数据;借助于时间窗口来对数据流进行计算和分析。 本文为了进一步提高实时性以及检测的精度,提出了基于动态时间跨度与聚类差异性指数的用户行为异常检测算法,其总体流程框架如图1 所示。
从图1 可以看出本文提出的异常行为检测模型包含聚类模型和分类模型。 聚类模型主要对传感器收集的离线数据集进行聚类,得到用户正常行为模式。 分类模型主要是以聚类结果作为标签,对数据进行分类。 用户行为在不同的时间段中活动的频繁次数各不相同,针对不同的频繁次数对数据进行不同时间跨度的概念漂移检测,在数据流发生概念漂移后,通过局部离群因子(LOF)来检测用户行为发生异常的时间点。

图1 异常行为检测的总体流程框架
1.1 特征数据选择与处理
在构造合适的分类和聚类模型之前,需要对输入数据进行分析与选择,选取合适的模型输入数据对最后的结果有很大影响。 在智能家居环境下异常数据检测的数据来源主要是传感器采集到的设备状态数据,这些数据主要分为两种:开关型数据、数值型数据。 开关型数据主要表示在某个时间段中智能家居是否在使用,数值型数据主要表示在某个时间段中智能家居的能耗量。
对于输入的数据还需要进行预处理操作。 由于单个数据在模型中没有任何意义,无法体现用户的行为模式,因此需要将不同设备的数据集合并到一起。 以时间为标准对数据进行多对一的合并,将所有设备在这个时间段内的能耗或者使用情况进行整合。 对于缺失的数据可以根据其前后数据的规律性将其补齐。 预处理完后的数据既能够观测到数据的完整性,也能用于后面的用户行为模式聚类。
用户行为必然会随时间而发生改变,因此需要将数据采集的时间作为特征数据并将其划分,比如一天中的不同时间段(早上、中午、晚上),是工作日还是周末,或者一年中的不同月份。 表1 所示就是对一天中不同时间段进行划分的一种方式。

表1 根据不同时间段划分采集时间
1.2 基于密度的用户行为模式聚类
为了对用户行为模式进行挖掘,需要将预处理后的数据运用聚类算法把用户行为特征相似的数据归纳成一类,同时保证类与类之间的数据特性相差尽可能大。 因此聚类可以让用户能耗特征相似的数据归在一起,将其看成一种行为模式。
本文选择基于密度的DBSCAN 聚类算法对用户的历史数据进行聚类。在T 时刻所有设备的状态或者能耗经过预处理构成一组数据,记为 Ext。 将 T1,T2,… ,Tn时 刻 的 数 据 作 为 输 入 数 据 , 记 为 Ext1,Ext2,…,Extn,按照以下DBSCAN 聚类算法对数据进行聚类。

1.3 分类模型的动态更新
每一次概念漂移检测完之后都需要更新分类模型的中心点, 保证之后检测的正确性和实时性。如果没有发生概念漂移则通过式(1)来更新分类模型的中心。 新的中心通过原来中心 Qj和分类到 Qj中 的 n 个 新 数 据 Ext1,Ext2,…,Extn计 算 得 出 。

如果发生概念漂移则需要去除掉LOF 超过一定阈值的数据,剔除异常点后再通过式(1)计算得出新分类的中心。
2 本文算法
2.1 时间跨度动态调整策略
时间跨度是根据需要进行异常检测的时间段精度大小来设定的,所以可以结合实际情况来选择,根据时间规律或者用户活动的频率,将时间分成几个阶段,每个阶段的跨度都不同,如表2所示。

表2 不同时间段对应的时间跨度
例如凌晨用户活动频次低,则选择较大的时间跨度,比如选取4 h,晚上用户的活动相对频繁,选择较小的30 min 作为时间跨度。 如果通过滑动窗口来接收需要处理的数据,在过程中会通过缓存来储存数据,实时性难以得到保证,而本文的时间跨度能够在保证实时性的前提下根据实际情况更加灵活地动态调整。
2.2 用于概念漂移检测的聚类差异性指数
通过聚类算法得出的每个聚类集合都是用户的一个行为模式,随着时间的推移,用户的行为会发生一定变化,与之对应的聚类中心点也可能会发生变化,通过聚类差异性指标来判断是否发生概念漂移。 根据之前聚类得到的集合 Q1,…,Qn,将其中心作为分类的标签,将时间跨度C 中的 n 个新的数据 S1,…,Sn,分别根据式(2)计算欧氏距离 D(Qi,Si),通过比较Si到每个集合的欧氏距离,将Si分类到欧氏距离最小的集合Q 中。

将有新数据归类到的集合,根据原先每个数据Ext1,Ext2,…,Extn在整个集合中的隶属度Lij,使用式(3)计算集合的聚类差异性指数B标准。


隶属度 Lij表示第 j 个数据在第 i 个聚类集合中的重要性。
聚类差异性指数B标准表示数据集中每个数据与聚类中心的差异性,如果数据差异度比较高,则误差 B标准会比较大,如果数据差异度比较低,则聚类差异性指数 B标准会比较小。
根据是否满足式(5)来判断用户是否发生了概念漂移,即数据点的差异性是否超过用户预先指定的阈值。

其中 B新数据是时间参数 C 中 n 个新的数据 S1,…,Sn到其分类集合的差异性;w 则为标准化阈值参数,通过式(6)根据用户该能耗平时所用的最大值和最小值得出,其中j 为数据的列数,作用为允许新数据参数偏移的误差控制。

2.3 基于 LOF 的用户异常行为检测
得出发生概念漂移的集合之后,通过LOF 算法找到对应的异常点,从而知道发生异常行为的具体时间。 根据式(7)可以得出 P 点到 O 点的第 k 可达距。 通过式(8)可计算出点的局部 k 领域距离,之后根据式(9)可计算出点的 LOF 值。 聚类的聚合越密集,k 领域距离就会越短,密度就会越高,反之如果聚类中的点越分散,点的k 领域距离就会越长,密度也会越低。

其中 lofp表示 p 点的异常值,异常值如果越接近 1,则表明p 点与它的邻域点的密度越接近,认为不是导致概念漂移的异常点;当异常值小于1,说明p点为密集点,不可能是异常点;如果异常值大于1,则表明p 的密度小于其邻接点,极有可能是导致概念漂移的异常点。
通过计算得到时间跨度中n 个数据的LOF 值,为了检测其中哪些数据为异常行为,则需要计算出临界值 Lmax。 Lmax的选取对检测异常极其关键,如果Lmax设定太高就难以检测到异常,容易出现漏检,相反如果Lmax设定得太低,则容易发生错检。 根据式(10)可以得出 Lavg,Lavg为 n 个数据的平均值;通过式(11)计算得出的 Lsta表示 n 个数据的标准偏差,反映的是数据的离散程度。 将 Lavg和 Lsta相加就可以得出LOF 的临界值 Lmax,超出临界值 Lmax的数据就认为是用户的异常行为。
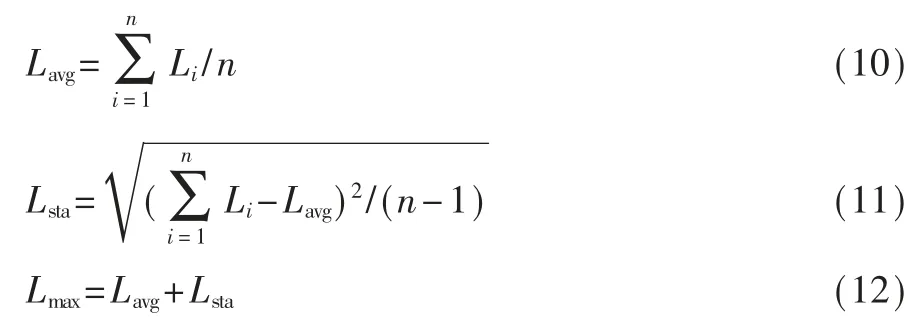
2.4 算法流程
图2 是异常行为检测算法流程图。 在输入数据后,先通过离线数据集得到聚类的结果,将每一个类别作为分类标签对实时数据进行分类,根据动态调整完的时间跨度对数据进行概念漂移检测,通过聚类集合的误差指数来判断是否概念漂移。 如果发生了概念漂移则需要检测导致发生概念漂移的异常点,计算每一个数据的LOF 值是否大于临界值,剔除大于临界值的异常点,通过中心点偏移公式对分类模型的中心点进行更新,若没有发生概念漂移则直接对分类模型进行更新。 之后将新的模型中心作为分类标签再次对新输入的数据进行分类,并且重新计算聚类差异性指数,依次循环往复。

图2 异常行为检测算法流程图
3 实验结果与分析
本文的实验数据来源于实际采集到的智能家居环境下的各类电器设备数据。 整个采集系统有14 个传感器,用于采集14 个设备的状态或能耗数据,每一个传感器设置以1 min 为一个采集周期。实验首先将数据进行预处理,之后通过聚类得到用户的行为模式,再结合时间跨度的大小对新数据流进行分类,通过分类集合的聚类差异性指标判断是否发生了概念漂移,最后通过计算数据点的LOF 异常值检测发生异常行为的时间点,具体过程如下。
3.1 数据处理及行为模式挖掘
在智能家居环境下传感器采集的数据,主要包括存储时间序列和用电能耗或用电信息,比如开关是否打开、设备在短时间内的能耗。 表3 是灯的能耗的一部分采集数据。 通过合并、筛选等方式对采集数据进行预处理,将更加清晰和完整的数据作为输入数据。
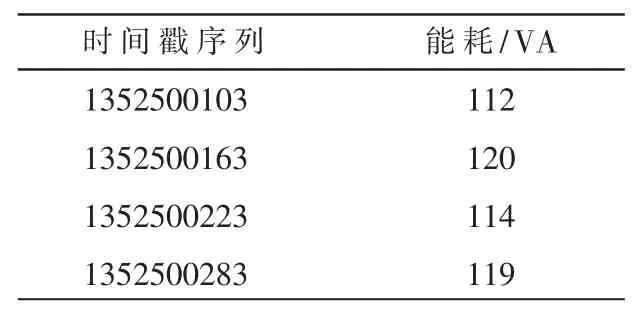
表3 灯的能耗原始数据
由于时间戳序列的形式不方便理解,因此需要把时间戳序列转换为日期和时间的形式。 之后是对数据进行合并,将不同设备的数据集合并到同一个数据表中,以时间为标准对数据进行多合一,将所有的设备在该时间的能耗或者使用情况进行合并,表4 列举了一部分结果。 经过初始的处理后实验输入数据如表5 所示(该表仅列举了部分数据)。
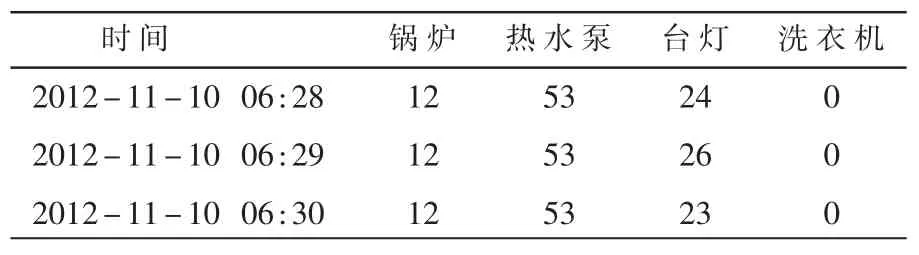
表4 预处理完的数据

表5 实验输入数据
3.2 聚类结果
系统在开始运行之前积累了2 天共2 880 条数据,将这些数据作为离线的聚类版本。 采用基于密度的DBSCAN 聚类算法对其进行初始聚类,得到了9 个类别如表 6 所示,其中数值为电器的能耗,单位为 VA。

表6 聚类结果
实验还与K-Means 聚类和均值漂移聚类的准确性进行比较,结果如表 7 所示。 输入相同的 2 880条数据并对其聚类,可以看到DBSCAN 聚类的正确率达到了98.5%,而K-Means 和均值漂移正确率只有96.3%和98.1%,从而得出本实验使用DBSCAN聚类效果比较好。

表7 聚类算法比较
聚类结果一共分成了9 个类别,每一个类别都代表了用户在某个时间段的一种行为模式。根据聚类结果可以对用户的行为做简单分析,例如表6 中聚类类别2 表示用户在睡觉的时间充电,聚类类别3 表明用户有在晚上同时使用洗衣机和洗碗机的习惯。
3.3 基于聚类差异性指数的概念漂移检测结果
在聚类完成后需要以聚类结果作为标签对实时数据进行分类,之后进行概念漂移的检测。 实时数据为晚上10 点~12 点的时间段,在这个时间段中的时间跨度动态为2 h,对其中的数据进行分类,分类结果如表8 所示,发现有4 个类别有新数据加入。
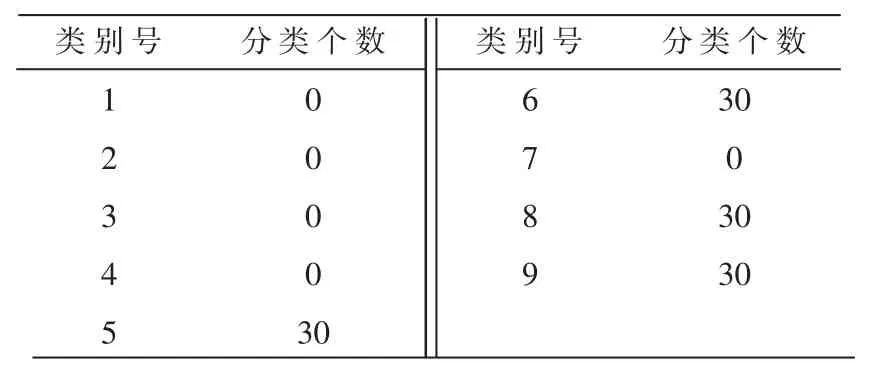
表8 实时数据分类情况
分别计算4 个类别的数据标准误差B标准以及时间跨度中数据归类到该集合的数据的差异度B新数据,计算数据的标准化阈值参数w,通过式(5)判别是否发生了概念漂移。 通过计算得到4 类集合中心发生了偏移,如表 9 所示,可以看到集合类别 6 和集合类别9 发生了概念漂移。

表9 概念漂移检测结果
本文提出的检测算法耗时较短大约0.015 s,并且通过对时间数据的分析,新的输入数据中的确存在用户行为模式的改变,行为发生改变的类别为类别 6 和类别9,检测正确率为 100%。
3.4 通过 LOF 检测异常行为
计算时间跨度中所有数据的LOF 值,为了能够直观体现, 将每个时间段对应的LOF 值绘制出来,并且根据式(12)计算得到 Lmax为 1.5,如图 3 所示。
图3 中圆圈中的点的 LOF 指数大于 1.5,因此认为该点是偏离正常行为的数据,并且根据序号得出异常值属于聚类类别 6 中(序号为 30 ~60 之间)。再根据数据中的序号可以确定用户的异常行为和行为时间点。 通过数据分析得出在聚类类别6 中存在原先关闭的设备处于使用状态,这可能是设备使用后忘记关闭, 与原先的行为相比有了新的用电行为,行为模式发生了变化。

图3 两小时内每一时刻LOF 的趋势
4 结论
本文针对智能家居环境下用户的异常行为提出了一种检测算法。 该算法能够在保证实时性的情况下正确检测出概念漂移,并给出用户行为发生异常的时间点。 通过实验得出该算法能够实时地对用户行为进行检测,耗时非常短,准确性比较高。 本研究为实现智能家居环境下用户行为异常检测提供了新思路,能够有效解决用户独自在家时所产生的安全隐患问题,为居家人士提供有效服务和安全保障。
