基于改进的RFM模型客户价值分层研究
2022-05-05龙冰婷
龙冰婷
(广州华商学院数据科学学院,广东 广州 511300)
0 引言
电子商务的发展给传统零售行业带来了巨大的冲击,一方面,网购的便捷性改变了人们的消费习惯,更多的人倾向于网上下单送货上门的便利;另一方面,电商平台“大数据营销”策略实施效果显著,通过分析客户用户画像进行精准营销,智能推荐商品,进一步提高销售利润。传统零售行业对于客户的研究更多停留在会员制层面,采取“一刀切”的营销策略,会员拉新和会员流失的问题在电子商务的冲击下尤为突出,这个问题亟待解决。如果零售商能借鉴电商行业的“大数据营销”方式,充分利用客户的数据信息来了解客户的消费特性,针对性地策划营销活动,就能在一定程度上减少老会员流失并且发展更多的新会员,进而为企业获取更高的利润。因此,笔者以某大型超市为例进行相关分析,利用超市客户的消费数据研究其价值,进而对客户进行价值层级划分,最后针对不同类型的客户提出差异化的营销策略,使得超市创利更佳。
对客户价值的研究更多的是基于机器学习的聚类分析,以RFM模型为基础,对客户消费行为数据进行分析,最终对客户进行类别划分。林盛等[1]通过AHP法得到电信行业RFM指标的权重,结合K-means聚类对客户进行分类,但是AHP赋权存在很大的主观性,且对聚类结果没有进行合理性分析;徐翔斌等[2]在传统RFM模型基础上引入了总利润属性作为模型指标对客户进行细分,但是对于模型指标的权重是主观给出的;罗彪等[3]采用ANP确定指标权重,使用K-means聚类进行客户分类,并对每个类别的客户给出相应的营销策略,但是其研究中假设客户的贡献度、重要度、忠诚度和信用度之间相互独立,在实际应用中往往得不到满足;熊兰等[4]对企业的所有产品分类,创建基于RFM的多层级客户价值模型对客户进行分类,但是各类产品的相对权重和RFM模型指标的权重都存在很大的主观性;靖立峥等[5]在RFM模型基础上引进了消费行为特征,通过CH评估指标确定最佳聚类数目,但是将所有指标的权重视为一样;陈方芳等[6]将RFM模型与K-means聚类算法结合,对百货商场客户进行价值研究,对比R、F、M指标在每个类别中的质心值与整体均值,判定不同类别客户的价值,但是没有对客户给百货商场带来的实际利润进行分析,没有验证“价值客户”的实际价值。
针对国内外学者对客户价值研究上存在的4大类问题,本文提出改进的RFM模型。(1)RFM模型指标权重采用熵权法[7]进行客观科学赋权,相比于AHP减少主观因素的影响;(2)RFM模型指标,在原有的F基础上考虑时间累积效应,修改为观察期内年均消费次数;(3)最佳聚类数目,采用手肘法,以误差平方和骤降的点作为最优K值;(4)引入客户利润分析,对于K-means聚类得到的不同类型客户进行创利分析,对比每一类客户给企业带来的价值,观察划分的“价值层级”与真实的“创利等级”是否保持一致,从而验证模型对不同客户进行价值分层结果的合理性。综合考虑RFM模型指标权重和不同类别客户的利润,来说明本文提出的模型的实际应用价值,最终对不同价值客户给出合理的营销策略。
1 模型理论
1.1 RFM模型
对于客户价值的研究[8-10],RFM模型被广泛应用,作为衡量客户价值和客户创利能力的重要工具和手段,其主要原因在于RFM模型简单易懂,与实际应用场景吻合度高[11-14]。
RFM模型最初由Hughes[15]于1994年提出,是衡量客户价值和客户创利能力的重要工具和手段。RFM模型包含3个指标:R(Recency)、F(Frequency)和M(Monetary),R表示客户最后一次消费距观察点的天数,F表示客户在观察期内消费的次数,M表示客户在观察期内消费的总金额。最近消费时间(R)越近、消费的次数(F)越多、消费的金额(M)越高,则相应的客户价值越高。最终通过3个指标的加权和得到相应客户的价值得分,RFM作为定量分析模型,在一定程度上削减了主观因素对客户价值的影响。客户价值得分(score)如式(1)所示:
score=wR×R+wF×F+wM×M
(1)
式中:wR、wF、wM分别表示R、F、M这3个指标的权重。
1.2 K-means聚类
K-means作为聚类中的经典算法,思想简单、计算速度快、计算成本低,从而被广泛应用于实际中。K-Means算法基于给定样本之间的距离大小,来衡量样本间的相似度,样本间距离越小,相似度越高,划分为同一个簇的可能性越大;反之,则越可能被划分到不同的簇中,使得簇内的点尽量紧密地连在一起,而让簇间的距离尽量地大,最终将样本集划分到K个簇中。
1.3 熵权法
在信息论中,“信息熵”是对样本不确定性的一种度量。不确定性越大,熵值越大,则包含的信息量越多;不确定性越小,熵值越小,则包含的信息量就越少。基于熵的特性,可以通过计算熵值来判断一个事件的随机性及无序程度,也可以用熵值来判断某个指标的离散程度,指标的离散程度越大,该指标对综合评价的影响(权重)越大。比如样本在某指标下取值都相等,则该指标对总体评价的影响为0,权值为0。
熵权法基于熵的特性,通过计算不同指标的“信息熵”,来判断该指标的重要程度。它是一种客观赋权法,结果仅由数据本身的离散性所决定,通过数据体现出相应指标的重要程度进而赋予不同的权重,更具有科学性。熵权法计算步骤如下。
1)归一化处理。
将RFM模型的3个指标区分为正向指标和负向指标,F、M两个指标的值越大越好,为正向指标;而指标R值越小越好,为负向指标。由于正向和负向指标的差异性,需要对其分别采用式(2)和(3)进行归一化处理,最终解决各项异质指标值的同质化问题。
正向指标:
(2)
负向指标:
(3)
式中:xij表示第i个样本的第j个指标;i=1,2,...,n;j=1,2,...,m。
2)计算指标的信息熵。
第i个样本在第j项指标下的占比:
(4)
第j项指标的信息熵:
(5)

3)计算指标的权重。
第j项指标的权重:
(6)
2 模型建立与分析
2.1 数据处理
2.1.1 改进的RFM模型指标选取
传统RFM模型中,采用的F(Frequency)是所有时间内客户下单的次数,存在时间累积效应的误差。对于长时间均等消费和偶尔大量消费的客户没有区分度,然而在只考虑该指标的情况下,前者客户黏性更高,价值更高,更值得关注。所以为了在一定程度上消除时间累积效应的误差,对传统RFM模型在指标选取上进行改进,采用下单总次数/客户产生交易的年限,即年均下单次数,作为新的F。改进后的RFM指标与传统的RFM指标含义比较如表1所示。

表1 传统RFM模型与改进的RFM模型指标含义对比
2.1.2 RFM指标计算
基于某大型超市2015—2018年零售交易数据,进行数据清洗后得到有效客户共793名。首先统计观察期内每个客户的R、F、M值,得到3个指标值对应的描述性统计量,结果如表2所示。
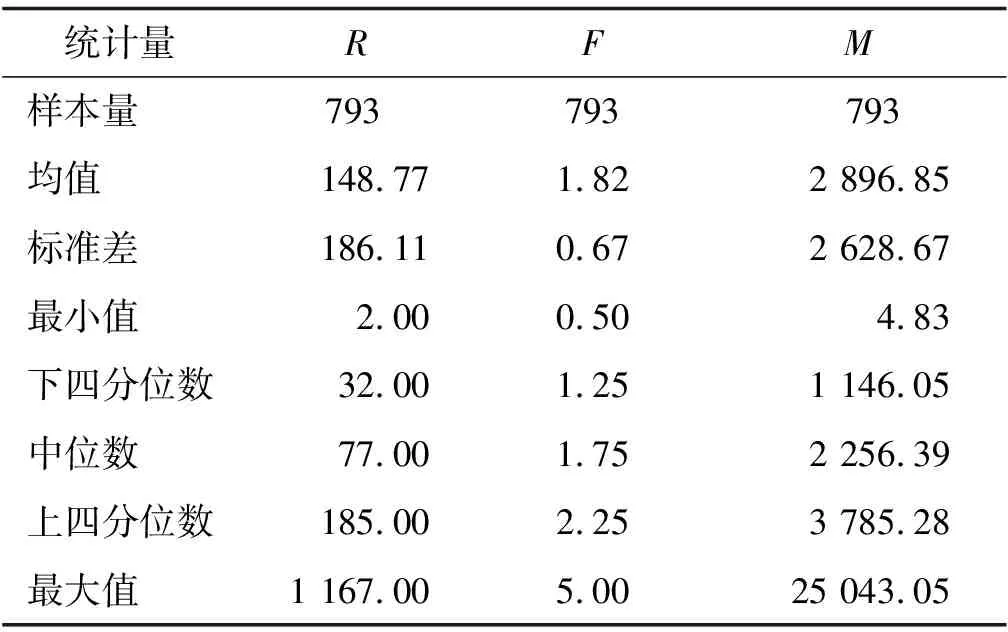
表2 RFM指标原始值的描述性统计量
2.1.3 归一化处理
为了消除RFM模型各指标的计量单位对聚类分析结果产生不合理的影响,不直接采用R、F、M指标的原始数据进行聚类,需要对数据进行归一化处理。对于R、F、M这3个指标,F、M属于正向指标,R属于负向指标,分别采用式(2)和式(3)进行归一化处理,得到的部分数据如表3所示。

表3 归一化处理后RFM模型的部分数据
2.2 熵权法确定模型各指标权重
采用熵权法对归一化后的数据计算R、F、M这3个指标的权重wR、wF、wM,最终得到的结果如表4所示。

表4 RFM模型指标权重
结果显示,M的权重最高,R的权重最低,客户最近一次消费时间距离观察点的天数差异并不显著,而观察期内的消费金额相差较大。
2.3 K-means聚类
2.3.1 RFM模型指标加权处理
传统的K-means聚类分析,默认R、F、M3个指标的权重相同,然而在实际应用中3个指标的权重并非如此。此次研究根据熵权法得到的3个指标的权重结果,进一步赋予3个指标不同的权重进行加权处理,得到K-means聚类分析所需数据分别为RW、FW、MW。
(7)
(8)
(9)
2.3.2 手肘法选择最优K
K-means算法第一步需要确定K的取值,主观选择K值会对聚类效果产生一定的影响,未必是最优的K值,此次研究通过手肘法来确定最优的K值。
手肘法是通过计算每个样本点与其所在簇内质心的误差平方和SSE,来评估样本聚类效果的好坏。随着K值的增加,每个簇内的样本点逐渐减少,簇内的聚合程度也相应提高,SSE随之递减。但是在K增大的过程中,SSE的下降幅度逐渐减弱,某一时刻SSE的下降幅度骤减,然后逐渐趋于平缓。整个过程中,K值与SSE形成的曲线类似于手肘,最优的K值即为手肘位置。由图1结果显示,最优K值为5。
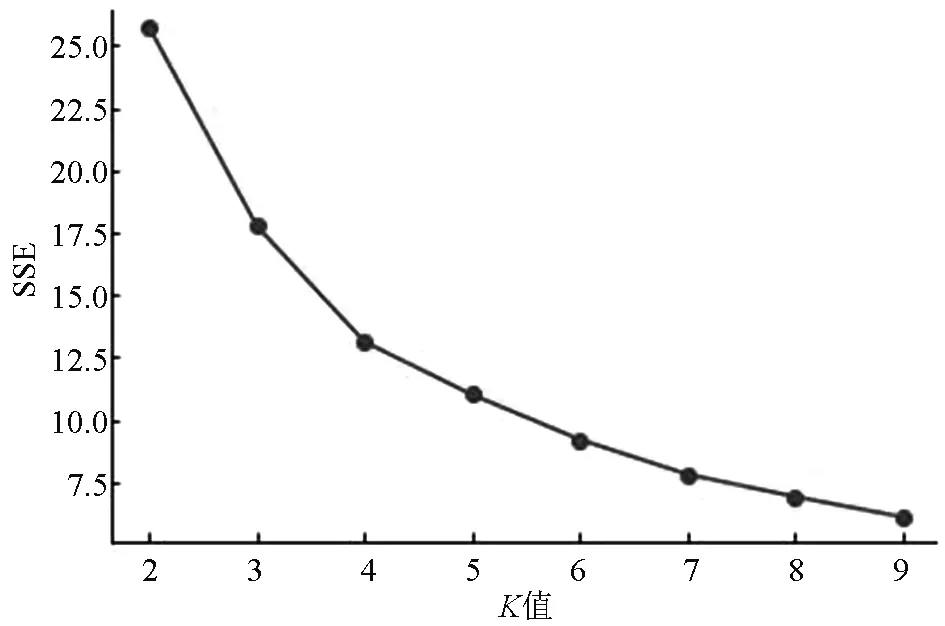
图1 SSE与聚类个数K之间的关系
(10)
式中:Ci是第i个簇;p是Ci中的样本点;mi是Ci的质心。
2.3.3 聚类结果分析
将793名客户划分为5类,每一类的客户数及R、F、M这3个指标的质心结果如表5所示,3个指标聚类中心分布情况如图2所示。
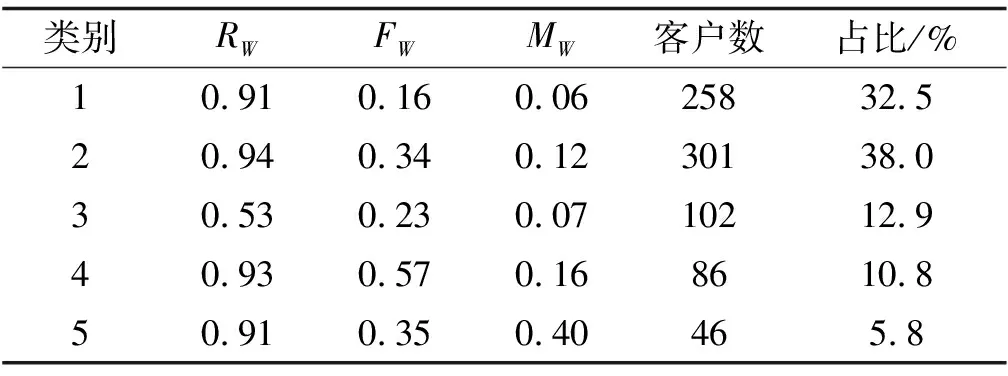
表5 RFM模型聚类结果

图2 RFM模型各指标聚类中心分布
表5和图2显示,聚类结果的5个类别中,类别5整体RW、FW、MW值均较高,最近消费时间近、消费频次和消费金额都很高,绝对的优质客户,视为“重要价值客户”,客户占比最低,只有5.8%;类别4整体RW、FW值较高,MW值次之,最近消费时间较近、消费频次高,消费金额中等,说明这是个黏性度高的忠诚客户群体且很有潜力,必须重点发展,视为“重要发展客户”,客户占比较低,只有10.8%;类别2整体RW值较高,FW、MW值次之,最近消费时间较近,消费金额、消费频次中等,视为“重要保持客户”,这类客户占比最高,达到38.0%;类别3整体RW、FW、MW值处于中等水平,最近消费时间较远、消费频次、消费金额中等,可能是将要流失或者已经要流失的用户,应当基于挽留措施,视为“重要挽留客户”,客户占比为12.9%;类别1整体RW较高,但是FW、MW值较低,最近消费时间较近、消费频次和消费金额较低,属于偶然性消费客户,且消费意向不高,视为“一般客户”,客户占比较高,达到32.5%。
3 不同价值客户创利情况分析
根据RFM模型聚类结果,进一步分析不同层级的客户群体创利情况,不同类型客户创收情况如表6和图3所示。

表6 不同类型客户创利情况

图3 不同类型客户创利情况分布
“重要价值客户”整体人数占比最低,但是却创造了第2的销售额和利润。其盈利客户占比高达86.96%,人均消费金额和人均利润都是最高的,说明该类客户是价值最高的客户,也是超市创利的中坚力量。
对于“重要发展客户”,盈利客户占比、人均消费金额和人均利润同样较高,但相比于重要价值客户,创利明显降低。整体人数较少,但是销售额和利润却处于中上水平,所以该类客户可以采取一定的营销手段刺激其消费,尽可能将其转换为“重要价值客户”。
“重要保持客户”在人数上具有明显的优势,整体销售额和利润占比最高。虽然人均消费金额和人均利润不如前2类客户,但是与重要发展客户相比创利相差不是很显著,该类客户同样是超市创利的主力军。
“重要挽留客户”销售额和利润占比是最低的,其主要原因是客户数占比较低。亏损的客户占比高达25.49%,人均消费金额和人均利润虽然略高于“一般客户”,但显著低于其他3类客户。对于这类客户要时常通过积分换购等优惠方式提醒其消费,防止其流失。
“一般客户”在人数上有一定的优势,但是这类客户消费的偶然性太高,人均利润也不是很高。在营销时可以适当地发放优惠券等,但不要投入过高的成本,不然可能导致投入和产出不成正比。
4 营销策略分析
大数据营销相比于传统营销而言,必然不能对所有客户采取相同的营销策略,针对本文研究得到的结论,主要提出以下营销策略。
策略1对于营销成本投入,重要价值客户>重要发展客户>重要保持客户>重要挽留客户>一般客户,这几类客户的人均利润依次递减,所以对于每类客户的营销成本也依次递减,达到投入与产出成正比的效果。对于价值最大的客户要尽可能地留住,并对有发展潜力的客户进行客户提升活动,使其向上一价值层级转换,对一般客户的投入最少。
策略2对于不同价值客户开展不同的营销活动。
1)重要价值客户,这类客户最近消费时间近、消费频次和消费金额都很高,表明其具备一定的经济实力。应将该类客户设置为特别顾客,为其办理特殊会员卡,比普通会员享有更大的折扣。按时将高门槛优惠券发送至用户的会员手机号,或者是在 微信公众号中选其为特邀顾客,发送一些价格较高的商品优惠信息,进一步刺激其消费。
2)重要发展客户,属于黏性度高、忠诚但是消费金额中等的客户。表明其经济实力一般,但对该超市的商品较为满意,这类顾客主要是提高其购买金额。对于这类客户,首先可为其办理积分会员卡;其次从历史商品购买信息中,找出其购买频率较低或没有购买的商品,为其提供中等额度的消费券,并给予多倍积分,吸引其购买价格较高的商品,从而提高消费。累计的积分可用于换购商品,进一步提高其忠诚度。
3)重要保持客户,这类客户近期有消费,但是消费次数和金额中等,如果是新客则开展新客促销活动,否则就开展消费次数和金额累计优惠活动,刺激其消费更多;对于这类顾客应增加其消费的频次,提高其忠诚度。可先通过发放调查问卷,找出忠诚度不高的原因,是超市的定位还是商品质量等问题。可根据其经常购买的商品为其推送优惠信息,按时发放一些小额的优惠券。
4)重要挽留客户,属于即将要流失或已经流失客户,开展老客户召回活动。给客户发送积分换购、老客户特享优惠等优惠方式提醒其消费,防止其彻底流失。
5)一般客户,这类顾客可能属于偶发性消费,不需要对其花费过多的精力。可在超市门口将每日的优惠信息进行展示,可为其办理一般会员卡,享受折扣优惠。
5 结语
对于大型超市而言,采取传统的营销方案进行利润的提升,效果已然不是很显著。在大数据时代,基于超市的客户消费数据进行相关分析,对客户进行价值分层,针对不同价值客户开展不同的营销活动,将达到事半功倍的效果。对营销效果进行数据跟踪,还能进一步调整相应的营销策略。
本文在传统RFM模型的基础上,改进其指标的选取,得到改进的RFM模型。基于RFM模型理论,通过熵权法对RFM模型指标进行科学客观赋权,最后进行K-means聚类分析,将超市客户划分为不同价值层级的5类:重要价值客户、重要发展客户、重要保持客户、重要挽留客户和一般客户。然后分别对其进行创利分析,进一步验证聚类分析结果,价值层级越高的客户,其创利情况越佳。最后基于本文分析结果给出营销策略。本文倡导基于“大数据”科学分析的结果,对超市客户进行“差异化”营销,达到投入和产出成正比的效果,使得超市创利步步提升。
