基于SSA-BP神经网络模型的风暴潮灾害损失评估
2022-05-05贾丙宏祝文硕王瑞富高松胡莹王怀计
贾丙宏,祝文硕,王瑞富,高松,胡莹,王怀计
(1.山东科技大学测绘与空间信息学院,山东 青岛 266590;2.国家海洋局北海预报中心,山东 青岛 266061)
1 引言
风暴潮作为危害最严重的全球性自然灾害之一,每年带来的风险和损失阻碍了经济的稳定发展[1]。据《中国海洋灾害公报》统计,2020 年我国遭遇的海洋灾害依旧以风暴潮灾害为主,沿海地区共发生14 次(统计范围等级:蓝色及以上),给我国造成8.1 亿元的损失,占各类海洋损失的97%[2]。最严重的2004号“黑格比”台风风暴潮,给浙江省造成了3.55 亿元的经济损失。面对高额的风暴潮损失,防潮减灾是必须的工作,而风暴潮损失评估是防潮减灾工作的前提,如何精确地估算风暴潮灾害的经济损失成为应对海洋灾害的一大科学问题。
国内外学者对风暴潮经济损失的评估方法主要有两类。一类是根据历史灾情资料,建立数学统计模型,对特定区域特定时间段的风暴潮损失进行评估。Huang等[3]利用历史灾情数据,建立了模拟程序来评估美国东南部的飓风预期损失。赵昕等[4]统计了2003—2007 年山东省沿海城市的风暴潮灾害数据,运用投入产出模型对风暴潮造成的损失进行评估。另一类是结合历史灾情资料和社会生产能力,通过建立危险性、脆弱性和指标体系等风险要素进行关联评估[1]。Rao 等[5]利用此方法,选择了研究区住房类型、医院和医疗水平等社会经济参数建立了评估指标体系,对澳大利亚和美国等地风暴潮受灾区的损失进行了评估应用。近年来,风暴潮灾害评估的研究越来越多,投入产出模型和支持向量机等方法被广泛利用。神经网络方法能够通过自主训练学习,建立风险要素指标与灾害损失之间的关系,成为了损失评估的新方向。然而,研究者在选取指标时往往主观性过强,缺少指标属性全面性的考虑,选择的指标并不能客观真实地反应风暴潮灾害的经济损失;同时,神经网络也存在一定的局限性,如收敛速度较慢且易陷入局部极小化等问题。鉴于此,本文提出了基于麻雀搜索算法(Sparrow Search Algorithm,SSA)优化的BP(Back Propaga-tion)神经网络模型,利用模型对风暴潮灾害导致的直接经济损失进行评估,评估结果显示,该方法可以进一步提高风暴潮灾害评估精度。
2 数据与指标选取
2.1 数据来源
浙江省位于我国东部,地处大陆板块过渡地带,海岸线长2 253.7 km,省内地形起伏较大,受东亚季风的影响,在地形与气候的双重影响之下,风暴潮灾害频发[6]。浙江省每年因风暴潮灾害造成的损失高达数亿元,给海洋经济发展造成巨大的伤害。为做好风暴潮防灾减灾工作,本文选取1990—2020 年浙江省记录完整的29 个风暴潮历史灾害资料作为数据集,按时间序列排列,选择时间最近的后4 个作为本文方法的测试集,其余25 个作为训练集。文中风暴潮灾害的数据资料主要来自《中国海洋灾害公报》[7]、《中国风暴潮灾害史料集》[8]、国家减灾中心统计数据以及浙江省统计年鉴[9]。
2.2 指标的选取
本文将风暴潮灾害的直接经济损失作为模型评估的目标因子。直接经济损失包括农业损失(农田和农作物等)、近海养殖损失(海水养殖、船只损毁沉没、池塘、网箱和盐田等)、基础设施损失(海洋工程、防波堤和涵闸等)、个人生命与财产损失(死亡失踪人数、受伤人数、受灾人口和房屋倒塌损毁等)以及其他损失[10]。为建立合理全面的评估指标体系,本文在选取指标时充分考虑到可能引起风暴潮灾害损失的多种要素,从致灾因素、孕灾背景、承灾体脆弱性以及防潮减灾能力4 个维度选取指标,并结合浙江省数字高程模型(Digital Elevation Model,DEM)提取出台风路径的高程、坡度以及坡向等地形数据,共选取出23个指标(见图1)。
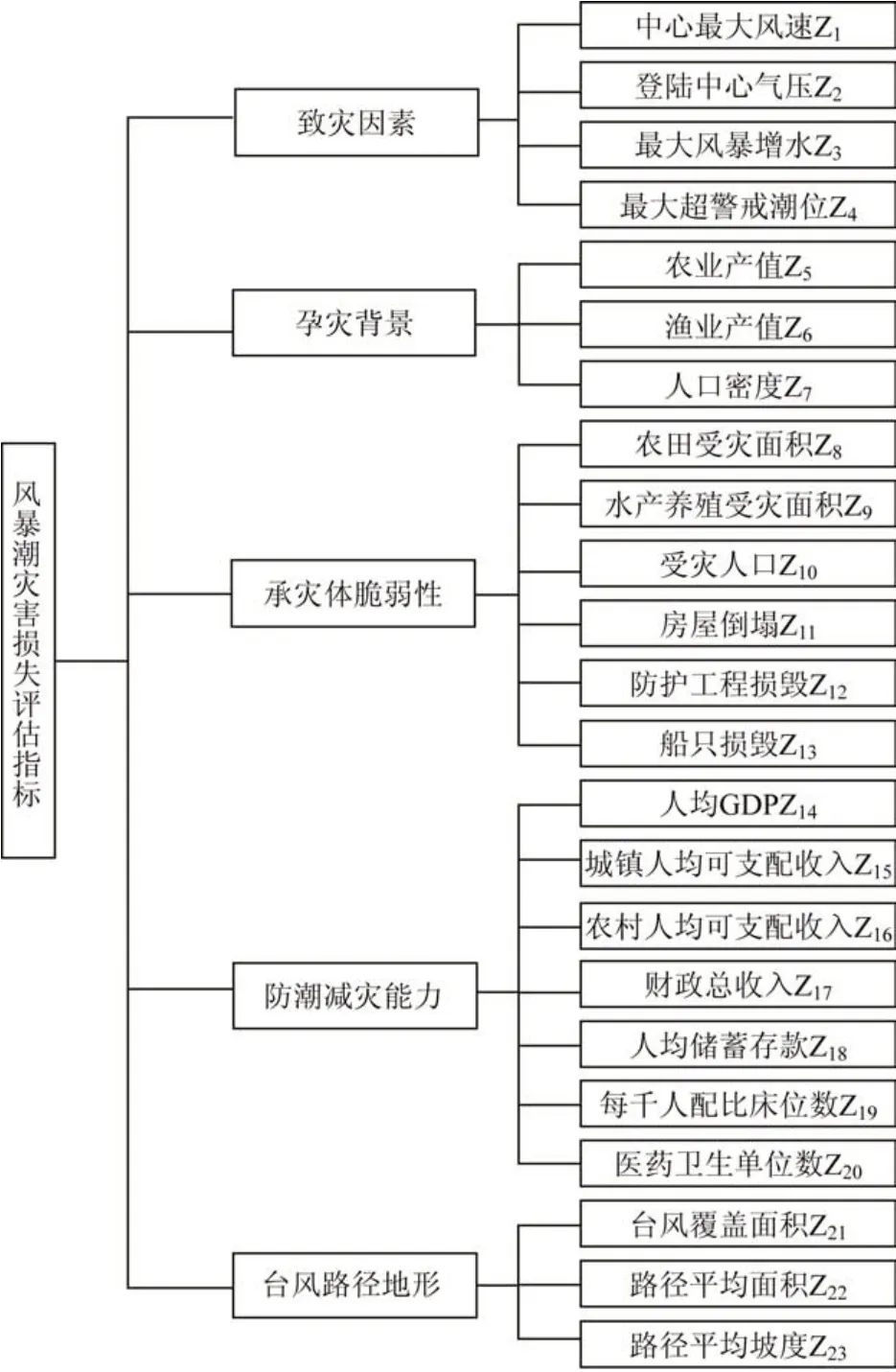
图1 风暴潮灾害损失评估指标体系Fig.1 Indicator system of evaluating storm surge disaster losses
(1)致灾因素。风暴潮是指海平面在受到温带气旋和台风(热带气旋)等因素的影响下出现的水位急剧升高的灾害现象[11]。风暴潮灾害直接表现为增水,其影响因素包括风速、气压、潮位、降水量和持续时间等。因部分致灾数据并不完整,我们选择中心最大风速、登陆中心气压、最大风暴增水和最大超警戒潮位作为风暴潮灾害的致灾因素。
(2)孕灾背景。风暴潮孕灾背景主要是指研究区域的地形地貌、农业渔业分布以及人口密度等指标。鉴于地形地貌变化不大且数值化表示困难,因此未列入统计范畴。我们选取了农业产值、渔业产值以及人口密度作为孕灾背景。
(3)承灾体脆弱性。不同用地类型遭受风暴潮灾害时会表现出不同的损失,这种损失程度被称为承灾体的脆弱性[11],判断一个区域的脆弱程度可以通过承灾体受灾情况进行分析。人员伤亡指标虽然与直接经济损失存在相关性,但由于受自然灾害发生时间等复杂因素的影响,加上统计过程中缺少值较多,本文并未将该指标作为评价因子,而选择受灾人口作为替代评价标准。最终我们选取农田受灾面积、受灾人口、房屋倒塌、水产养殖受灾面积、防护工程损毁以及船只损毁作为参考指标。
(4)防潮减灾能力。防潮减灾能力覆盖面很广,本文在对这一指标进行选取时,从医疗能力、自救能力以及恢复重建能力出发,坚持全面性原则,选取了每千人配比床位数、医药卫生单位数、人均GDP、人均储蓄存款、城镇人均可支配收入、农村人均可支配收入以及财政总收入作为防潮减灾能力指标。
(5)台风路径地形。台风过境时,区域损失的大小与影响面积、高程以及坡度等数据有着密不可分的关系。影响面积越小、高程越大且坡度越大能够更大程度地减少直接经济损失。鉴于前4个维度筛选的指标并未做到与全省的直接经济损失建立统一的联系,本文进一步提取出台风路径的覆盖面积、高程以及坡度数据。步骤如下:①生成DEM 数据。DEM 数据选择的是先进星载热发射和反射辐射仪全球数字高程模型(Advanced Spaceborne Thermal Emission and Reflection Radiometer Global Digital Elevation Model,ASTER GDEM),空间分辨率30 m,数据来源于地理空间数据云(网址:http://www.gscloud.cn/)。②统计台风路径(见图2a)。统计台风样本的过境经纬度坐标,数据来源于中央气象台台风网(网址:http://typhoon.nmc.cn/)。③台风影响范围提取(见图2c)。基于台风中心坐标点生成台风路径,并按影响范围制作缓冲区,影响范围半径依据自然资源部发布的《中国海洋灾害公报》进行设定(见表1)。④空间损失评价指标提取。基于影响范围,统计台风影响区覆盖面积、平均高程以及平均坡度3 个指标数据,作为台风路径的空间损失评价指标。本文对29 个台风过程分别进行空间信息统计,每个过程根据登陆中心最大风速进行影响范围的提取,图2 为199005 号台风路径地形数据提取过程示例。
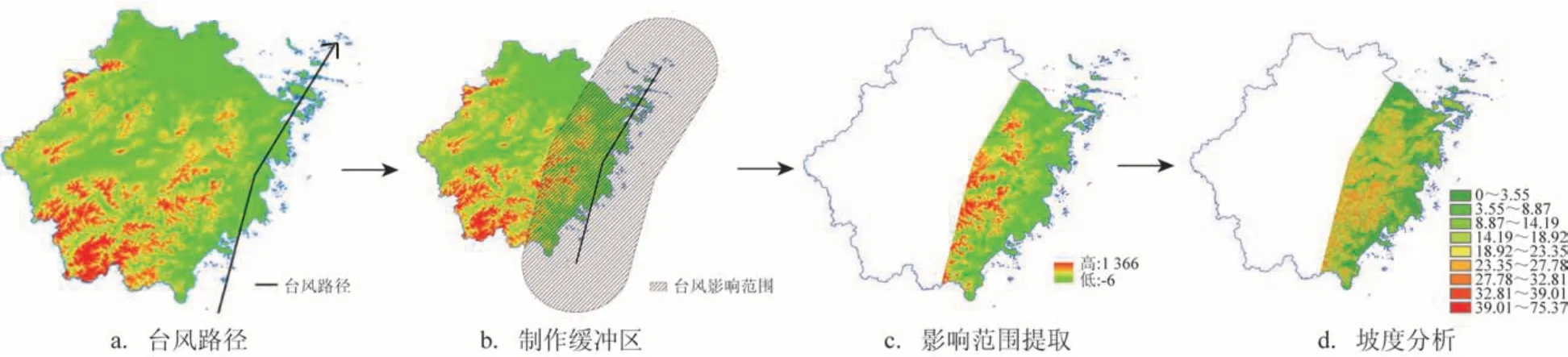
图2 199005号台风路径地形数据提取过程Fig.2 The process of extracting the terrain data of the typhoon(199005)
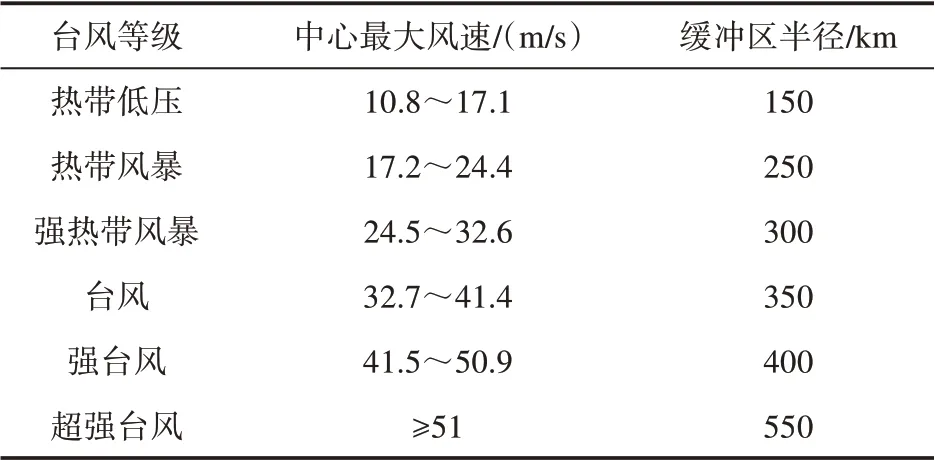
表1 缓冲区半径设定规则Tab.1 Buffer radius setting rules
2.3 指标筛选预处理
在选取指标时,为防止信息丢失我们进行了全关联的覆盖选取,因此出现指标因子较多的情况。不同的指标因子之间的相关性,可能会产生不必要的信息冗余,加大训练的工作量,因此需要对这些指标进行科学的筛选。本文利用灰色关联分析法(Grey Relational Analysis,GRA)对指标进行筛选。GRA 是一种分析系统中各因素之间关联程度的方法,根据系统各因素间发展趋势的近似程度进行关联度大小的量化分析[12]。该方法既可以减少信息冗余,又避免了人为筛选主观性的影响。具体步骤如下:
(1)确定参考序列和比较序列
参考序列基于指标与预测目标的相关程度进行选取。本文选取与直接经济损失相关性最强的农田受灾面积Z8(j)作为参考序列,剩余22 个指标作为比较序列。
(2)指标数据无量纲化
(3)计算灰色关联系数
{Zi(j)}(i=1,2,3,4,5,6,7,9,10,11,···,23)与Z8(j)之间的灰色关联系数为:
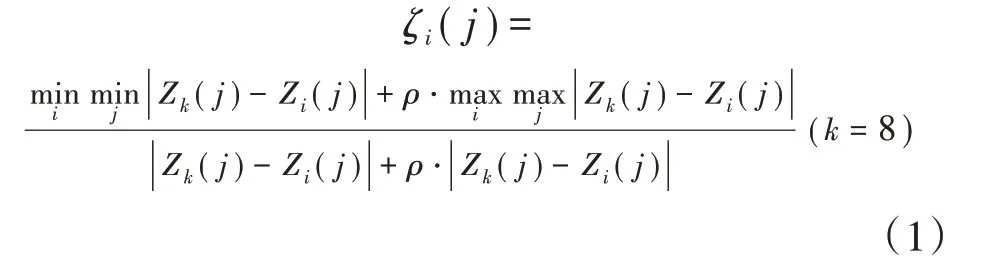
式中,ρ为区分度系数,取值区间为[0,1],本文设定ρ=0.5[13]。
(4)计算关联度
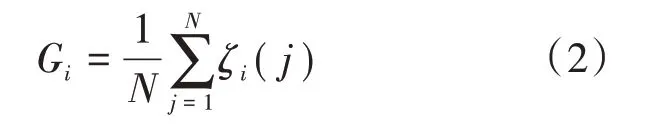
式中,Gi为{Zi(j)}相对Zk(j)的关联度;N为选取的风暴潮灾害样本的个数。计算关联度结果如表2所示。
根据灰色关联分析法得到的关联度结果,值越大说明对结果的影响程度越大,从中筛选出主要影响指标因子,作为输入层进行模型训练。本文将表2 中关联度值小于0.95 的指标剔除,最终选取最大风暴增水、最大超警戒潮位、农业产值、人口密度、农田受灾面积、水产养殖受灾面积、受灾人口、房屋倒塌、防护工程损毁、船只损毁、每千人拥有床位数、路径覆盖面积、平均高程和平均坡度14 个指标作为风暴潮灾害损失评估模型的输入因子,部分展示见表3。
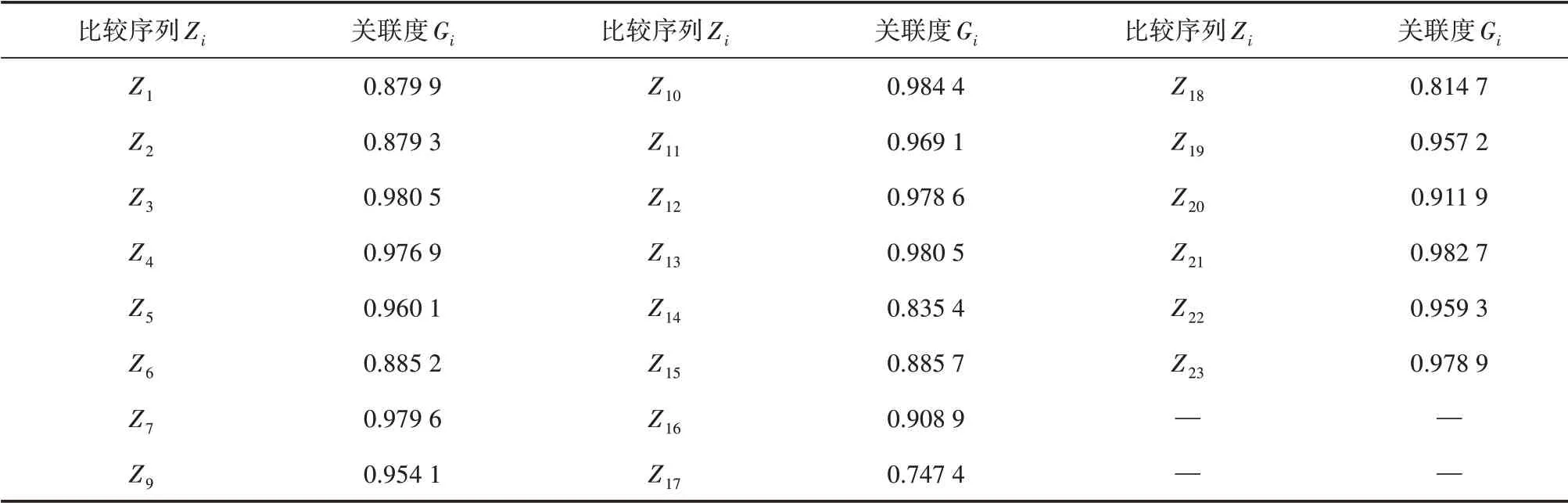
表2 指标关联度结果Tab.2 Result of Metric Relevance

表3 风暴潮指标因子部分展示Tab.3 Partial display of storm surge indicator factors
3 损失评估模型的建立
3.1 BP神经网络原理
BP 神经网络包括信号前向传播和误差后向传播两个过程[14],是预测评估领域中被广泛研究应用的一个模型。模型一般由输入层、隐含层和输出层组成,由网络结点连接各层(见图3)。最主要的参数是各层之间的连接权重,权重是在误差反向传播时进行计算的[15]。BP神经网络经过逐步训练,不断获取输入和输出因子之间的最佳映射关系,调节权值和阈值,直到满足预设的误差精度或训练次数。

图3 BP神经网络结构图Fig.3 BP neural network structure diagram
3.2 麻雀搜索算法的原理
麻雀搜索算法是基于麻雀的群体智慧、觅食行为以及反猎食行为建立的全局群搜索算法。其生物原理为:麻雀群为寻找食物会分为发现者与加入者两类,发现者的职责是标记食物方向,加入者等待接收发现者的食物信号;一旦麻雀觉察到危险,则会立即变化位置。依据这一原理,麻雀可以轻松地获取食物并躲避攻击。具体数学建模步骤参见文献[16]。
3.3 SSA-BP神经网络模型
传统的BP 神经网络在实现从输入到输出的预测领域拥有较强的非线性映射能力,但网络权值在沿着局部改善方向逐步调节时,易陷入局部极小化问题,导致训练结果失真。优化算法的提出为解决网络缺陷提供了可能,SSA 与粒子群(Particle Swarm Optimization,PSO)算法和遗传算法(Genetic Algorithm,GA)相比,在搜索精度、收敛速度和稳定性方面均有优势[16]。本文利用SSA 求解最优权值和阈值参数,赋给设定的BP 神经网络模型,从而构造出SSA-BP 模型,并对损失进行评估。模型构造步骤如下:
(1)定义麻雀种群的初始规模n、最大迭代次数N、发现者的数量占比PD、感应危险的麻雀数量占比SD、安全值ST和预警值R2(随机数产生)。
(2)确定BP 神经网络拓扑结构和SSA 的搜索空间维度dim。定义输入层和隐含层分别为M和N,则结构为M-N- 1,搜索维度dim =M×N+N×1+N+ 1。
(3)确定适应度函数。本文适应度函数定义为训练集均方误差与测试集均方误差的平均值,这样能够兼顾整体的预测精度。函数为:

式中,N为总样本数,N1为训练集数,N2为测试集数,N=N1+N2;ytrain为训练集输出值,ytest为测试集输出值,y为实际值。
(4)计算初始麻雀种群的适应度值进行排序,选出当前最佳值fbest和最劣值fworst。
(5)根据步骤(3)和步骤(4)更新发现者、加入者以及感应危险的麻雀个体位置。
(6)按迭代规则,若当前最优值优于上次迭代结果,则继续进行更新,否则不更新且继续迭代。
(7)迭代终止准则。当适应度值fitness小于模型初设的精度(0.001)或者迭代次数用尽(30代),则终止迭代并输出最佳适应度值及其对应的全局最优位置bestX。
(8)将算法迭代终止时的全局最优位置bestX对BP神经网络进行优化,即获取最优的权值和阈值参数赋予BP 神经网络模型,进而实现网络训练与仿真预测。
综合上述模型构造步骤,SSA-BP 神经网络模型流程如图4所示。
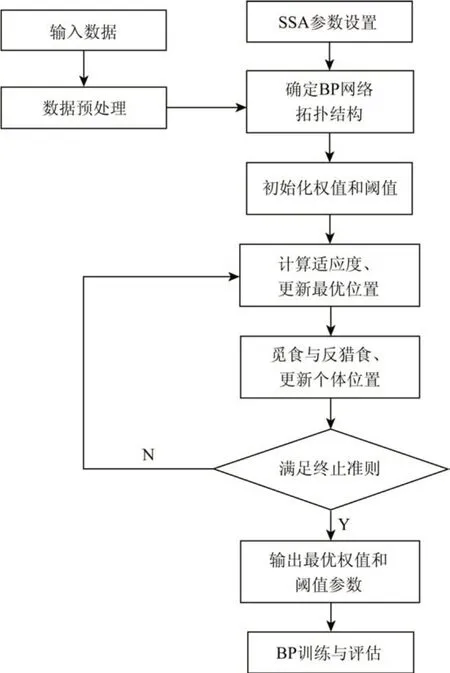
图4 SSA-BP神经网络流程Fig.4 SSA-BP neural network process
4 实验与讨论
本文选取了浙江省记录完整的29 个风暴潮灾害样本,时序前25 个作为训练集,后4 个作为测试集,以MATLAB 2018b为平台进行实验。
本文利用决定系数R2、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)、均方根误差(Root Mean Square Error,RMSE)以及希尔不等系数(Theil IC)4 个统计指标来检验评估模型的性能。公式如下:
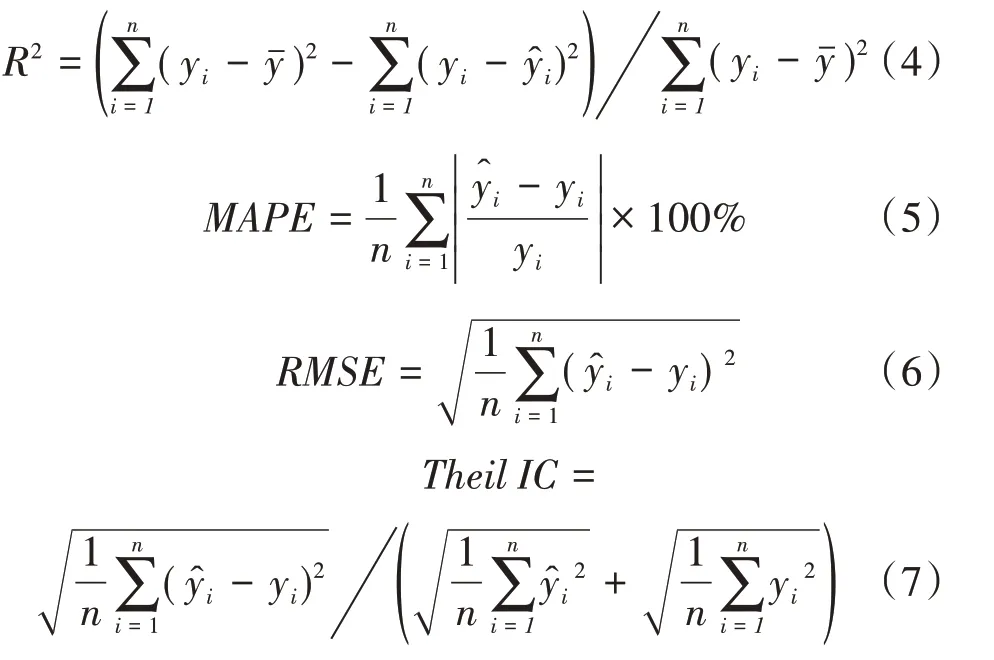
式中,yi为第i个样本的真实值为样本点的真实平均值,为第i个测试样本预测值。
4.1 精度分析
在本文实验中,BP 神经网络的拓扑结构为14-9-1。隐含层节点数先由经验公式求得最优取值范围为[ 4,13 ],然后根据遍历选优原则,选出训练集均方误差最小时对应的最优k值为5。鉴于本文样本数量29 个,输入因子维度14,模型搜索过程不太复杂,因此种群初始规模n设置为30,最大迭代次数N为30,其他设置如下:搜索空间维度dim 为136,发现者的数量占比PD为0.7,感应危险的麻雀数量占比SD为0.2,安全值ST为0.6。
图5 为SSA 的迭代收敛曲线,可以看出迭代次数接近10 次时,就已经收敛到最优值,相较于其他算法收敛速度得到突破性提高,这也为本文将建立的优化模型用于风暴潮评估提供了充分的说服力。
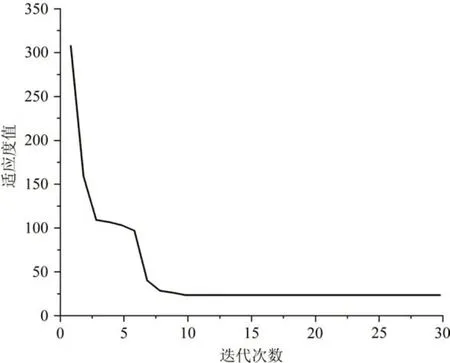
图5 SSA-BP神经网络适应度收敛曲线Fig.5 SSA-BP neural network fitness convergence curve
训练样本模型实验结果见表4,为节省空间保留两位小数。图6为BP神经网络和SSA-BP神经网络模型25 个训练集的拟合结果对比图像,传统BP模型的第15、23 和24 个样本的训练结果出现较大幅度的偏离,计算R2值为0.771;SSA-BP 模型结果与真实值整体趋势相同,R2值为0.916,说明经过SSA 优化后的模型输出值与真实值拟合程度较好且误差更小。虽然仍有个别样本值出现偏离,但由于风暴潮本身就具有不确定性和随机性,因此并不会影响模型的有效性。对比两图可以得出,经过麻雀搜索算法优化的网络模型训练得到的拟合值稳定性有所提高,且更加接近真实结果。
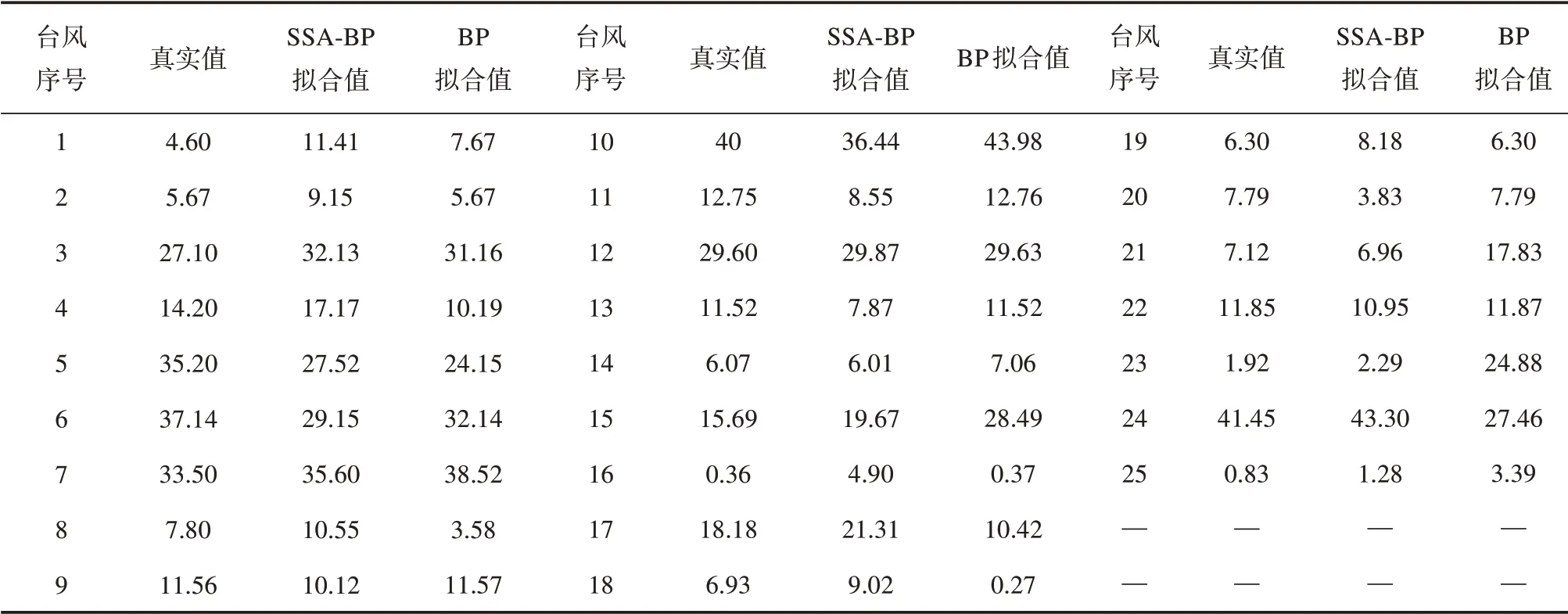
表4 25个训练样本模型拟合结果Tab.4 25 training samples model fitting results
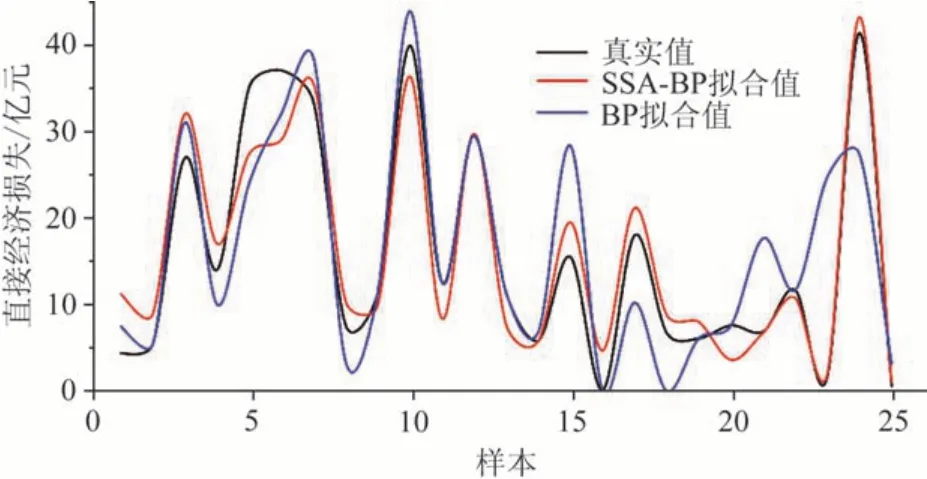
图6 SSA-BP与BP模型训练集拟合结果对比Fig.6 Comparison of fitting results between SSA-BP and BP model training set
为了进一步证明本文提出的SSA-BP 神经网络模型在风暴潮灾害损失评估领域的优势,本文将GA-BP 神经网络模型、PSO-BP 神经网络模型、传统BP神经网络模型与SSA-BP 模型对4个测试样本的拟合值进行了对比,4种模型拟合值的MAPE、RMSE和Theil IC的结果见表5。
由表5 可知,较传统BP 神经网络模型,优化后的模型在预测精度上均有所提高。3 种优化模型中,SSA-BP 神 经 网 络 模 型 的MAPE、RMSE 和Theil IC 值都低于GA-BP 模型和PSO-BP 模型,值越小说明结果越好,因此验证了麻雀搜索算法优化的BP 神经网络模型在风暴潮灾害损失评估领域具有充分的优越性。评价指标因子可以对其造成的直接经济损失进行评估,有效地帮助决策者及时采取适当措施应对风暴潮灾害和灾后救助重建。

表5 不同模型测试集结果对比Tab.5 Comparison of test set results of different models
4.2 鲁棒性分析
为了评估SSA-BP 神经网络模型的鲁棒性,我们将其应用于1990—2020 年福建省32 个风暴潮历史灾害样本数据集,全部样本用于训练拟合实验。由于样本数量与浙江省接近,模型参数上并未做其他调整,样本的拟合结果如图7所示。
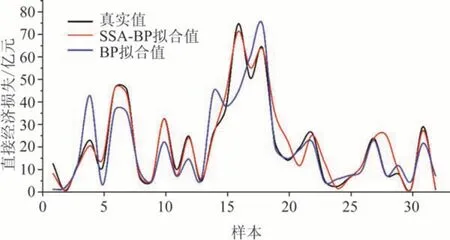
图7 福建省样本训练拟合结果Fig.7 Fujian province sample training fitting results
从图中可以看出,相较于BP 模型,SSA-BP 模型的拟合结果更加接近真实值,稳定性更好,这与浙江省的拟合结果相近,说明该模型的研究区域并不受限于浙江省,只要获取相应区域的评估指标因子即可构建相应模型进行损失评估。因此,SSA-BP模型可用于其他地区的风暴潮灾害评估,具有鲁棒性和推广价值。
5 结论
本文根据风暴潮灾害历史统计数据,从致灾因素、孕灾背景、承灾体脆弱性、防潮减灾能力以及台风路径地形5 个维度建立评估指标体系,利用灰色关联分析法筛选出涵盖信息多、权重高和相关性大的14 个指标。通过本文提出的基于麻雀搜索算法优化的BP 神经网络模型,对29 个风暴潮灾害样本进行了训练预测,并与其他模型进行对比。训练集对比选择了传统BP 模型与SSA-BP 模型,得到的R2值分别为0.771 与0.916;预测集对比选择了传统BP神经模型、GA-BP 模型、PSO-BP 模型和SSA-BP 模型,得到的MAPE 值分别为73.21%、48.85%、46.94%和34.71%,RMSE 分别为15.206 0、8.894 6、11.769 2和5.264 8,Theil IC 分别为0.224 1、0.120 8、0.166 7和0.068 7。结果表明,SSA-BP 神经网络模型的损失评估准确性优于其他算法。我们还对建立的评估模型做了鲁棒性分析,虽然本文以浙江省为研究对象,但只要将模型中的评价因子换成其他省份的数据,本文的模型同样适用于其他省份的风暴潮灾害评估,且精度仍然会有大幅提高。
本文提出的SSA-BP 模型在风暴潮灾害评估中取得了良好的效果,对防潮减灾工作具有一定的现实意义。但本文风暴潮样本数据较少,因此仍需要在样本数据的收集整理方面做一定的工作。从预测角度来讲,对未来将要发生的风暴潮灾害进行预测将是损失评估的新研究方向。
