基于G-SMOTE和Biased-SVM的内部威胁用户检测
2022-05-05张晨路
张晨路
(中北大学 大数据学院,山西 太原 030051)
0 引 言
随着信息技术的不断发展,许多公司已经把维护信息安全作为一个长远战略目标. 根据报告显示[1]:仅在 2015年,我国发生的内部威胁安全事件就高达2 097万件,占全年信息安全事件的一半. CERT(Computer Emergency Response Team)内部威胁中心将内部威胁定义为组织的现任或前任员工或合作伙伴利用对组织网络、系统和数据的访问权限进行一系列恶意或无意行为,这些行为包括但不限于窃取知识产权、泄露机密信息、网络或系统破坏[2]. 内部威胁用户对公司造成的损害远超其他攻击事件,因此,内部威胁用户的检测对于公司的信息安全是十分重要的.
当前,机器学习已经广泛用于内部威胁检测,它们能够从大量数据中训练出模型,并将模型用于检测内部人员的异常行为. 文献[3]将用户一周内的所有操作建模为一个序列,并使用隐马尔可夫模型(HMM)进行建模,通过HMM可以得到每周的预测概率,并设置阈值T,如果序列的概率低于阈值,则将其分类为异常; 文献[4]将自组织映射(SOM)方法用于内部威胁检测,SOM还提供了地形图保存的训练数据可视化,内部人员的数据实例集中在SOM地图的较亮区域中,分析人员通过检查映射到较亮区域的数据就能够找出数据中的异常现象并识别可疑行为; 文献[5]对所有特征进行了交叉分组,并利用交叉分组后的特征构建了孤立森林模型,更加充分地利用了数据的特征信息,提升了内部威胁用户检测的效果; 文献[6]将1天划分为4个时间段来提取用户特征,然后使用长短时记忆人工神经网络(LSTM)进行训练,并判断用户的行为是否异常.
以上文献虽然有着较好的总体准确率,但都忽略了数据类别不平衡的问题,威胁用户只占所有用户中的极小一部分,从而导致威胁用户召回率过低. 一般的分类器模型都是基于平衡数据集,而从不平衡数据集上训练出的分类器倾向于多数样本,并不能找出所有少数类样本. 针对类别不平衡问题,文献[7]使用SMOTE-RF算法,通过在少数类样本与其近邻样本之间插入随机生成的新少数类样本重构训练集,并在新的训练集上进行模型训练,从而提高了少数类样本的检测结果; 文献[8]引入专家知识,通过分析真实的攻击数据,得出了3种攻击的子类型,并设计了一个威胁用户数据生成算法,通过输入处理好的正常用户数据即可得到3种不同攻击子类型的威胁用户数据. 然而,文献[7]使用SMOTE-RF算法生成的少数类样本容易被分布边缘化和产生噪声点,影响检测结果; 文献[8]使用专家知识生成内部攻击数据虽然达到了很好的效果,但泛化性差,需要很强的专家知识才能形成内部攻击数据.
综上,针对现有方法存在类别不平衡、生成的样本噪声点过多、泛化性差等问题,本文提出一种将G-SMOTE与Biased-SVM结合的内部威胁用户检测方法,分别从数据和算法层面解决类别不平衡的问题. 算法首先使用G-SMOTE算法生成噪声点较少的威胁用户数据从而保证了数据集的平衡性,再通过 Biased-SVM 算法提高对威胁用户的检测效果.
1 内部威胁用户检测算法
1.1 算法框架
本文所提内部威胁用户检测方法的整体框架如图 1 所示. 首先,对CERT 4.2数据集进行特征提取,将所提取的人物特征按照十折交叉方法分为训练集与测试集; 其次,使用G-SMOTE算法对训练集中的威胁用户的特征进行过采样处理,直到训练集正常用户与威胁用户的特征数量平衡,利用重组后的训练集训练Biased-SVM模型; 再次,使用模型对测试集进行分类且记录结果; 最后,使用网格搜索法遍历完所有参数,从中选取最优参数作为最终模型参数.

图 1 内部威胁用户检测整体框架Fig.1 The overall framework of insider threat user detection
1.2 数据集特征提取
本文使用的数据集为CERT 4.2. CERT数据集是由卡内基梅隆大学与ExactData公司从构建的真实企业环境所采集的,模拟了恶意内部威胁人员对知识产权或安全信息进行窃取、欺诈、破坏等的行为. 该数据集包括了2010年1月至 2011年 5月期间1 000名内部人员的用户活动日志,其中威胁用户只有70个. 本文选择logon,device,file,email,http域的数据,针对用户的不同操作提取特征,这些域的具体操作见表 1.

表 1 CERT数据集内容Tab.1 The contents of CERT dataset
文献[5-6]将时间划分为0:00~6:00,6:00~12:00,12:00~18:00,18:00~24:00等4个时间段,并分别在4个时间段提取特征,但此方法存在某些特征空缺值过多影响分类效果的不足,且没有考虑工作日与休息日的用户行为差别. 本文将时间段分为工作日与休息日,分别对两个时间段按天提取特征. 由于文件内容、邮件内容、上网内容大多都是随机生成的,在特征提取时忽略这些信息. 针对用户的不同操作(登录、登出、邮件操作等)提取两种类型的特征:① 频率特征:统计用户每天执行不同操作的数量,计算在不同时间段的操作数量的平均值、最大值、最小值; ② 时间特征:统计用户每天执行不同操作的时间,计算在不同时间段的操作的开始时间、结束时间以及持续时间的平均值、最大值、最小值,并剔除异常值,对空缺值使用均值法补全,最终提取出1 000条 96维的人物特征数据.
1.3 类别不平衡处理方法
1.3.1 G-SMOTE算法
文献[9]提出的SMOTE算法,通过在少数类样本和其近邻少数类样本中进行线性插值并生成样本,从而达成数据平衡,但SMOTE算法容易生成噪声点、分布边缘化. 文献[10]提出的G-SMOTE算法是SMOTE算法的拓展,其具有以下优点:对每个选定的少数类样本周围定义一个几何区域,在此区域生成的少数类样本不再是简单的线性插值,并且减少了噪声点的生成; 通过不同的策略选择,其近邻样本的类别不再局限于少数类,扩大了生成少数类样本的区域. 以下为G-SMOTE算法的步骤.
输入:训练集train,标签label,近邻选择策略strategy,生成样本的点数N,近邻值k,截断系数truncation,变形系数deformation.
输出:平衡数据集train_res,平衡数据集标签label_res.
步骤1:将训练集train依据标签label分割为多数类样本max和少数类样本min,设置空集S储存生成的少数类样本.
步骤2:选择少数类样本center作为少数类样本中心,根据近邻选择策略strategy,分为以下情况:
i) 若近邻选择策略为少数类,则从少数类样本中心center选择k个最近邻样本,并随机选择一个样本作为surface.
ii) 若近邻选择策略为多数类,则从多数类中心center选择最近邻样本作为surface.
iii) 若近邻选择策略为组合策略,分别按照i)和ii)计算距离d=‖surface-center‖,并选择距离小的样本作为surface.
步骤3:使用正态分布和均匀分布在单位超球体内生成随机点gen,依据截断系数truncation、变形系数deformation对随机点gen进行截断变换和变形变换,将生成的随机点gen平移到中心为center,半径为‖surface-center‖的超球体内并进行伸缩变换生成少数类样本,并将生成的少数类样本并入集合S.
步骤4:重复步骤2、步骤3共N次,将集合S与训练集train合并为平衡数据集train_res,并生成新的标签label_res.
G-SMOTE算法由参数strategy,k, truncation, deformation所控制,strategy分别选择3种最近邻选择策略:少数类、多数类、组合策略;k∈{3,5}; truncation∈{-1.0,-0.75,-0.5,-0.25,0.0,0.25,0.5,0.75,1.0}; deformation∈{0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0}.
G-SMOTE算法是SOMTE算法的一种拓展. 当近邻选择策略选择少数类,变形系数和截断系数为1,近邻选择策略与SMOTE算法相同都为少数类,变形系数使得初始超球体变形为线段,截断系数使得结果截断为一半,此时算法就为SMOTE算法; 当变形系数为1,截断系数不做任何限制,近邻选择策略为多数类策略或者组合策略,此时超球体仍为线段,截断系数可使线段进行截断、扩展或旋转,近邻选择策略有更多的选择,此时算法可以认为是SMOTE的改进算法; 当变形系数小于1,且其余参数无任何限制时,数据生成区域不再为线段,此时算法从严格意义上为G-SMOTE算法.
1.3.2 Biased-SVM算法
SVM算法是基于统计学习理论的分类方法,有着较强的泛化能力. 传统的SVM分类器基于两个假设:数据集内不同种类样本是平衡的; 对于不同种类样本的权重是相同的. 因此,SVM分类器对于不平衡数据集传统的SVM算法分类效果不好,尤其是对少数类样本的识别率很低. Biased-SVM算法通过对正负样本设置不同的惩罚因子中提高对少数类样本的识别率,此时目标函数将变为
s.t.yi(ω·φ(xi)+b)-1+ξi≥0
ξi≥0,i=1,…,l.
(1)
对于惩罚因子的选择,文献[11]使用正、负样本数目的反比分别作为正、负样本的惩罚因子,称为Imbalance Ratio(IR)方法. 本文算法的惩罚因子使用了文献[12]的方法,其考虑了数据集的正、负样本的空间分布,提出一种Average Density(AD)方法,正、负样本的惩罚因子分别选择负样本和正样本的样本数目与平均密度之比. 平均密度的计算过程为
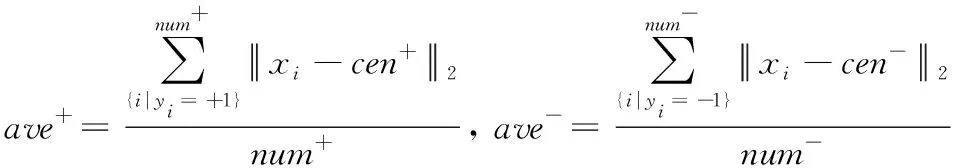
(2)
2 实验分析
2.1 实验配置及评价指标
实验在Windows10操作系统的联想台式机上运行,配置为Intel i7-6700的CPU以及8 GB内存. 使用1.2节所提取的1 000条96维的人物特征数据用于实验. 选择威胁用户作为正类,正常用户作为负类,混淆矩阵如表 2 所示. 表中,ATP表示真正类(True Positive, TP)的用户数量;AFP表示假正类(False Positive, FP)的用户数量;AFN表示假负类(False Negative, FN)的用户数量;ATN表示真负类(True Negative, TN)的用户数量。

表 2 内部威胁人物检测评价指标计算的混淆矩阵Tab.2 Confusion matrix for calculating insider threat user detection evaluation index
内部威胁用户检测的难点在于威胁用户数量很少,这代表即便模型把所有用户认定为正常用户,也会有很高的准确率. 因此,对于内部威胁用户检测不应选择准确率(Accuracy)作为评价指标,本文选择P、R和F1值来评价模型的分类性能,计算过程为

(3)
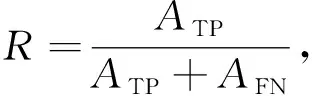
(4)

(5)
式中:P为精确率,反映了模型所预测的威胁用户是否准确;R为召回率,反映了模型是否能够检测出所有威胁用户;F1综合了威胁用户的精确率与召回率,反映了模型对于威胁用户的分类效果. 我们要在尽可能保证精确率的前提下提高召回率,找出更多威胁用户,减少其带来的危害.
2.2 参数选择对比实验
近邻选择策略、近邻值k是网格搜索法找出的最优参数时,分析参数变形系数和截断系数对P、R和F1值的影响,实验结果如图 2 所示.
由图 2 可得,当变形系数为0和截断系数为0.25时,模型的P、R和F1值最高; 随着变形系数与截断系数的绝对值不断增大,实验结果也随之变差. 由于数据集中威胁用户远少于正常用户,所以过采样时会重复选择某些威胁用户作为中心生成样本,当变形系数与截断系数的绝对值逐渐接近1时,G-SMOTE算法与SMOTE算法类似,生成样本的区域逐渐缩小接近线段,生成的威胁用户样本很容易重复或者有噪声; 与之相反,当变形系数与截断系数的绝对值在0附近时,生成样本的几何区域变大,减少了重复点和噪声点的生成,提高了威胁用户的检测效果.
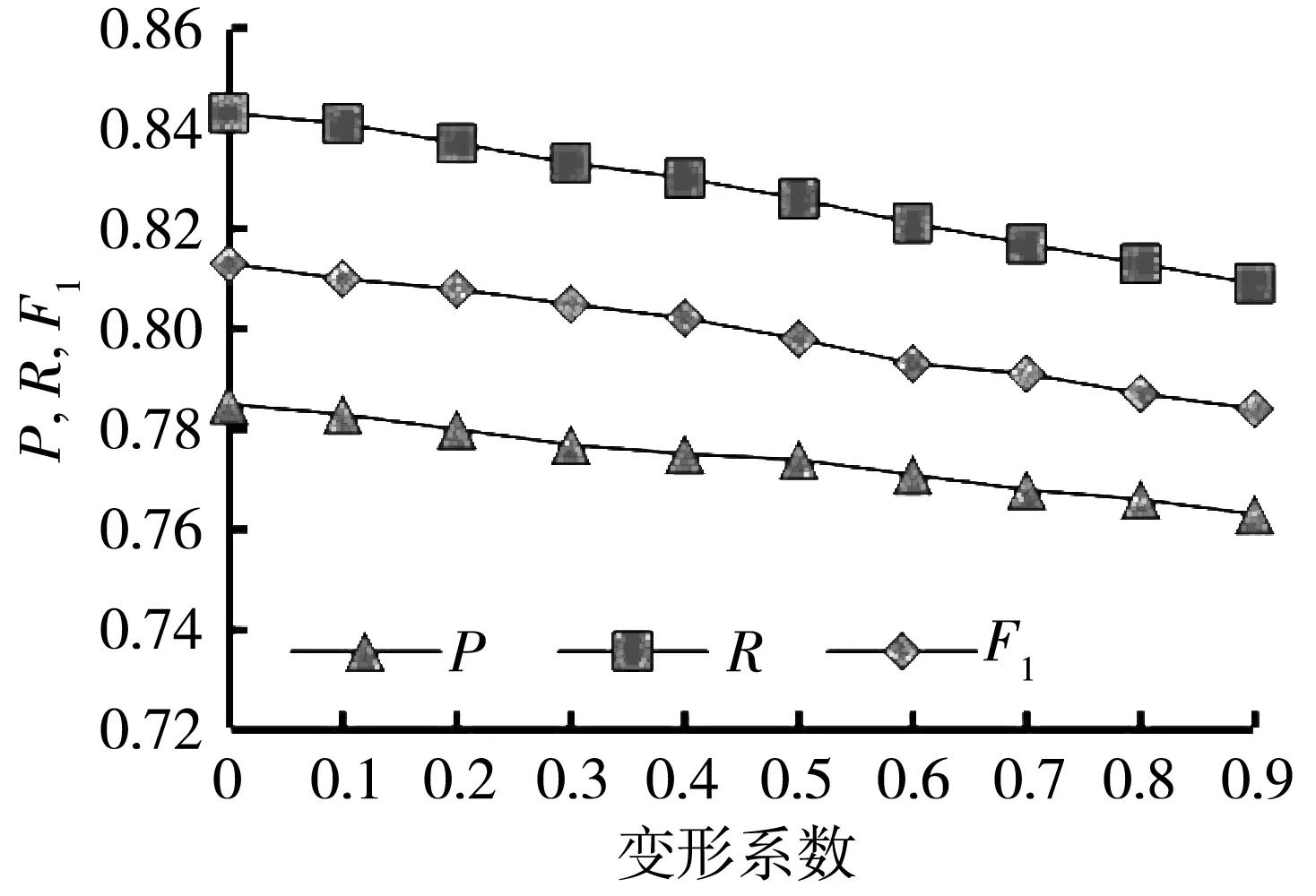
(a) 变形系数deformation参数的选择
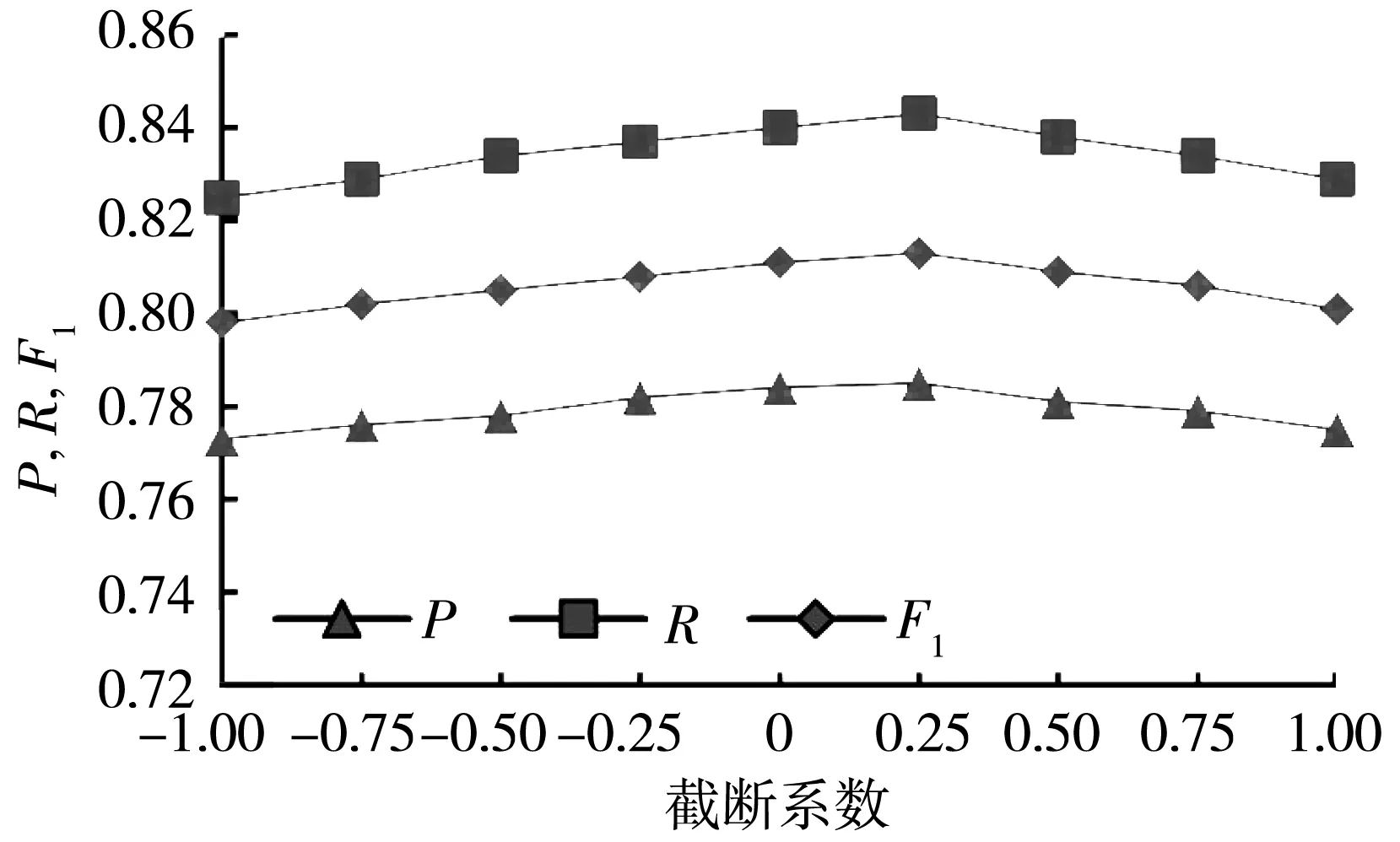
(b) 截断系数truncation参数的选择图 2 参数选择对比实验结果Fig.2 Comparison of different parameters effect
2.3 消融实验
为了验证本文方法对不平衡数据处理的优势,进行消融对比实验. 将本文方法(G-SMOTE+Biased-SVM)的实验结果与以下两种算法相比较:①SMOTE和Biased-SVM相结合的算法; ②G-SMOTE和SVM相结合的算法.

图 3 消融实验结果Fig.3 The results of ablation experiments
如图 3 所示,本文方法与方法①的对比证明了G-SMOTE算法在数据层面处理数据集不平衡问题的优势. 在生成威胁用户时采用G-SMOTE算法有更多的近邻样本选择策略,扩大了生成威胁样本的区域,增加了生成威胁用户样本的多样性,并且引入几何区域生成威胁用户样本,使生成的威胁用户样本的噪声点和重复点更少,因此拥有更高的精确率、召回率和F1值. 本文方法与方法②的对比证明了惩罚因子使用AD方法的有效性. 过采样后样本数目平衡,则此时使用IR方法的Biased-SVM算法与标准SVM相同,但数据集还存在空间分布不平衡的情况; 本文使用的Biased-SVM通过考虑样本数目与空间分布来设置惩罚因子,提高了对于威胁用户的关注度,因此可以找出更多的威胁用户,提高了实验的召回率; 同时由于权重的影响将部分正常用户判别为威胁用户,降低了实验的精确率.
2.4 内部威胁用户检测对比实验
为比较内部威胁用户检测的结果,将本文方法(G-SMOTE+Biased-SVM)的实验结果与SMOTE-RF算法、原始的SVM算法进行对比.
如图 4 所示,本文方法的精确率为78.5%,与其余两种算法的精确率相近; 召回率和F1值分别为84.3%和81.3%,与SMOTE-RF算法相比提高了5.7%和2.1%,与SVM算法相比提高了25.1%和14%. 这是因为SMOTE算法通过在两个威胁用户样本之间线性插值生成的样本,当生成样本较多时,容易产生重复和噪声,影响RF算法的分类效果; SVM算法处理不平衡数据集时具有偏斜性,容易将威胁用户预测为正常用户,不能达到对威胁用户的精确识别; 本文方法过采样时有着更多近邻选择策略以及不再局限于线性插值,因此减少了重复点和噪声点的生成,并且在Biased-SVM算法中提高对于威胁用户的权重,与RF、SVM算法相比能够找出更多的威胁用户. 因此,本文方法的召回率和F1值优于其余两种算法,能够检测出更多的内部威胁用户.

图 4 内部威胁用户检测效果对比实验结果Fig.4 Comparison of insider threat user detection effect
3 结 论
本文提出了一种基于G-SMOTE和Biased-SVM方法的内部威胁用户检测方法. 本方法首先从数据层面使用G-SMOTE算法选择最优参数对训练集的威胁用户进行过采样,改善了SMOTE算法过采样时容易产生噪声点、分布边缘化的问题; 然后从算法层面使用Biased-SVM算法对威胁用户、正常用户设置不同的惩罚因子,提高了对威胁用户的关注度,并且通过消融对比实验验证了两种算法的有效性. 实验结果表明,本文算法在CERT 4.2数据集上,有效地改善了类别不平衡的问题,提升了内部威胁用户检测的召回率和F1值. 但本文方法对过采样威胁用户过采样时,只考虑了不同类别样本数目的平衡性,没有考虑到空间分布的平衡性. 今后的工作应在生成威胁用户样本时考虑空间分布的平衡性问题.
