基于无人驾驶的多目标联合检测与跟踪方法
2022-05-04吴明瞭郭启翔高宠智胡博伦张路玉
吴明瞭,郭启翔,何 薇,文 进,高宠智,胡博伦,张路玉
(东风汽车股份有限公司商品研发院,湖北 武汉 430000)
1 引言
在深度学习领域中,目标的检测和跟踪是一个十分重要的组成部分。多目标跟踪的任务是将视频中每个目标的轨迹画出来即把同一个目标的bounding box标成同一个ID,按照对多目标跟踪的目标初始化任务划分,可将多目标跟踪按照预处理方式的不同进行划分,一种是基于检测的Detection-Based Tracking(DBT),另一种是基于手工提取方式的Detection-Free Tracking(DFT)。如今比较主流的预处理方式是DBT,DBT按照跟踪过程中处理方式的不同分为离线跟踪和在线跟踪。在线跟踪的示意图如图1所示,离线跟踪示意图如图2所示。

图1 在线跟踪示意图
图2 离线跟踪示意图
2 相关工作
2.1 基于视觉的动态目标检测
本小节的检测网络是基于Faster-RCNN检测网络加以改进得到的,其流程示意如图3所示。输入图片首先经过C-RPN网络,分别经过5个阶段的特征提取之后可以得到不同尺寸分辨率的Feature Map,将不同阶段的特征图相互融合可以得到基于锚点的区域提案和基于车辆的区域提案。

图3 目标检测算法流程
C-RPN网络是针对于车辆的区域提议网络,利用车辆的不同特征对传统的RPN网络加以改进而成。
假设特征单元,黑色虚线是预先埋下的锚框,而蓝色边框是车辆的提案区域,由图4可以看到,锚框和提案区域的中心还存在一定的偏移量Δ(,,,),设锚框的宽和高为和,提案区域边框宽和高为和,其计算公式如公式 (1)所示。
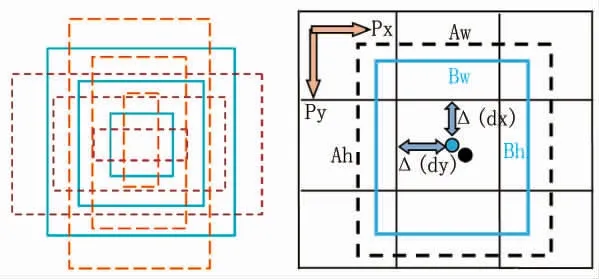
图4 锚框示意图

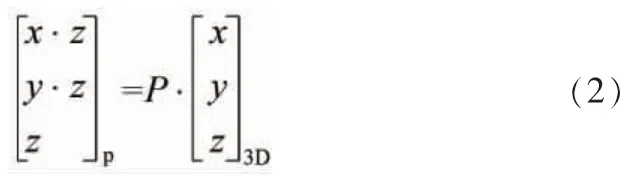
根据公式(2)可以将相机中心三维坐标投影到图像坐标系中,其中为给定已知投影矩阵。
根据候选区域在特征图上裁剪出W×H的256通道的特征图R1,再将这些特征图送入较ROIPooling更精准的ROIAlign网络。
如图5所示,严重影响了检测的品质,所以针对这种情况,采用非极大值抑制算法(Non-maximum suppression,NMS)。NMS算法主要的作用是从很多重叠的搜索区域中,过滤掉多余的搜索框,从而得到最匹配的检索框。

图5 未经非极大值抑制的检测图
2.2 基于卡尔曼滤波的动态目标跟踪
经过多模态融合模块并行处理之后,会得到3种状态的目标,分别为丢失目标、跟踪目标以及出现的新目标。在确定目标状态为丢失后,对卡尔曼跟踪器进行更新,确定是否结束跟踪,如果结束跟踪,则删除卡尔曼滤波器,否则将所有的目标跟踪信息输入到下一帧。其中,多模块融合模块是核心的处理模块,它将从目标检测框架接收到的目标进行目标特征提取并进行三维估计,结合另一个输入端传来的上一帧的多目标跟踪轨迹进行数据关联,根据相似度计算两个对象属于统一目标的概率,从而对检测车辆和跟踪轨迹进行匹配。
DLA网络改进的输入是目标检测框架经过ROIAlign层的池化特征图。
2.3 基于LSTM网络的动态目标跟踪
图6所示为基于LSTM网络的动态目标跟踪框架。本文对马尔可夫决策过程的状态空间进行改进,得到4种状态目标,即新目标、跟踪目标、遮挡目标以及丢失目标。

图6 基于LSTM网络的动态目标跟踪框架
3 实验
3.1 基于视觉的动态目标检测实验结果与分析
评价指标选用常见的目标检测指标平均精度AP(Average Precision)和平均召回率AR(Average Recall),其中AP和AR分别由其他4个指标计算而成,这4个指标分别是TP、TN、FP、TN,其含义如表1所示。

表1 指标含义
AP指的是对所有帧图像中判断为车辆的判断中正确判断的占比的均值,其计算方式如公式(3)所示,而AR指的是对所有帧图像中所有正确判断中判断为车辆的占比的均值,其计算方法如公式(4)所示。

首先对网络的改进部分分别进行实验对比,再对目标检测的性能进行测评,最后针对仿真场景和kitti场景可视化的效果进行分析。如表2所示,改进的RPN实验是基于残差网络的主干架构上进行的,在C-RPN网络中,对原始的RPN网络进行改进,加入多尺度的锚框,使得预设的锚框能够更好匹配检测的车辆目标,从而在召回率上有了较大幅度的提升,同时在精度上获得了小幅的改善。但是由于预设锚框多尺度导致锚框数量的增加,使得系统运行的时间有一定延长。

表2 改进RPN实验对比
在改进RPN的基础上,对NMS进行改进实验,如表3所示。通过数据可以发现,改进后的O-NMS在各项指标上都有小幅的上升,从而证明改进的方式和思路都是正确的。

表3 改进NMS实验对比
将数据集中的场景中的车辆目标按照距离进行分类,分为简单、中等和困难3个级别。表4对不同程度的目标检测进行实验分析。

表4 目标检测实验
从表4中可以观察到,随着检测目标难度的增加,其置信度也越低,从而降低阈值可以获得更加良好的检测结果。而当目标的难度趋于简单时,用较低的阈值则会产生较大的误检情况,会导致精度的降低,所以适当的增加阈值可以提升检测的效果,例如简单模式中的最佳检测效果出现在阈值为0.5。
本小节分别挑选了仿真场景测试结果中的夜晚,雾天、雪天以及强光天气下的4种不同场景进行分析。图7为4种不同场景下对车辆目标的检测情况,每个场景选择了4幅不同时间节点的检测图,由于一个测试序列有400多帧,所以以100为间隔,在测试序列的每100帧中随机选择一副图像作为显示,通过这样的方式保证了场景的随机性和多样性。通过直观的可视化结果来看,在夜景的场景中,由于能见度低,作为前景的车辆和作为背景的夜色具有相似的颜色,所以产生误判和漏检的概率相应更大,如7a检测结果中便把扁长方形的绿植判断为车辆。而在雪景和雾景的场景中由于能见度较夜景大幅提升,所以检测的效果更好,当然也存在一定的误判情形,如7b中的第4幅图将背景中的扁长方形判断为车辆目标。而在7d强光场景下,由于光线很好,能见度高,所以检测的效果比较精确,但是强光场景中存在一些镜面反光的情形,使得检测的性能受一定的影响。

图7 仿真测试场景
图8选择kitti的两个测试场景进行展示,分别是行驶过程和十字路口。在8a的行驶场景中,即使存在较大的自我运动,检测难度上升的情况下,系统依旧能检测出场景中存在的车辆,而在8a中第2幅图中,对于较大尺度畸变的公交车也检测出来。在8b中十字路口,车辆密度增大,而且存在遮挡的情况,如8b的第1幅图所示,都可以很好地检测出目标车辆。故而系统对于多目标,以及车辆之间相互遮挡和车辆尺度畸变都有着良好的鲁棒性。

图8 kitti测试场景
3.2 基于卡尔曼滤波的动态目标跟踪实验结果与分析
对于目标的跟踪来说,主要选用两个指标来对跟踪效果进行评价,一个是多目标跟踪精度MOTP(Multiple Object Tracking Precision),这个指标的内容是体现检测到的目标的三维位置的估计的精准程度。另一个是多目标跟踪准确度MOTA(Multiple Object Tracking Accuracy),它综合了符合人们逻辑的一些对于跟踪的评价,MOTP的计算方式如公式 (5)所示。


公式(6)为MOTA的计算方式,其中公式的第二项是所有负面考虑因素的综合。



从可视化的二维和三维结果来对跟踪的效果进行分析,再对其中的数据指标进行分析。
图9是3种方法跟踪的效果对比。可以看到在图像中,轿车和吉普车在每一帧中都被当成新目标进行处理,被吉普车遮挡的目标在不同两帧中也产生了ID的切换。只有远处相对位置较为稳定的车辆依旧保持着跟踪。
图9b可以看到在右侧的较远处的3辆车可以进行正确跟踪,但是在左侧的轿车和吉普车,畸变较大的情况下,依旧不能正确匹配跟踪,而更为复杂的遮挡情况,就更无法成功跟踪。图9c为卡尔曼三维跟踪+深度排序+遮挡处理的跟踪方式,首先远处的车辆正确跟踪,近处的轿车(橙色)和吉普车(紫色)在畸变较大的情况下也能很好地被跟踪,对于最复杂的遮挡情况,由于加入了遮挡处理,在隔了一帧的情况下依旧保持了跟踪(橘色)。下面通过表5对图9中的3种不同跟踪方式进行总结,给出每种方式在4帧图像中跟踪不同对象成功的概率。

表5 3种跟踪方式对比

图9 不同方式的跟踪效果
通过以上对比可以看到卡尔曼三维跟踪+深度排序+遮挡处理的效果较其他两种要更为鲁棒,接下来分析这种跟踪方式在不同场景下的三维效果,三维跟踪的包围框颜色原理同二维边框。
图10是3种不同仿真场景下的4帧连续图像,这3个不同的场景都位于交叉路口,10a中被红色轿车遮挡的3辆车在红色轿车驶过后ID依旧保持不变,体现了算法对遮挡物体的良好跟踪性能。10b中对深青色轿车的超车过程中,深青色轿车在视角中产生了很大的尺度畸变,但是算法依旧能保持跟踪状态,对尺度畸变有着良好的鲁棒性。10c中的夜晚场景光照条件很差,且场景中的目标数量很多,场景中所有目标的ID在这4帧中都没有切换,体现了算法在暗光环境的适应性以及对多目标跟踪的良好性能。

图10 仿真场景下的三维效果
图11是kitti实景测试集中的连续4帧的测试情况,使用的是卡尔曼三维跟踪+深度排序+遮挡处理的跟踪方法。从可视化的效果可以看出场景中的所有车辆目标均被检测出来且在连续帧中没有出现目标跟踪丢失的情况。橘色框车辆在不断前进的过程中,尺寸在不断变化,算法依旧可以稳定跟踪,体现了算法对跟踪目标尺寸变化的良好适应性。

图11 kitti实景跟踪效果
从表6中可以看出,在原始的跟踪中加入卡尔曼二维跟踪后,MOTA会有15个点的巨大提升且误配率也下降了16个点,这要归功于卡尔曼滤波的强大作用,卡尔曼滤波对跟踪目标的位置进行了预测和更新获得更加精确的位置估计。

表6 不同方法性能评价
而在卡尔曼二维跟踪加入基于深度的排序之后,MOTA获得接近4个点的提升同时误配率下降了3个多点,这是因为基于深度的排序将距离过大的匹配对过滤了,从而减少了误配率,由公式(6)可知误配率的降低必然会提升MOTA。
卡尔曼三维跟踪较二维跟踪在MOTA指标上提升了近7个点,并且误配率也下降了7个点,这得益于加入的深度信息以及车辆的方向信息等,让位置的估计判断更加精准可靠。在卡尔曼三维跟踪加入基于深度的排序之后,有着微小的提升,MOTA上升了0.1个点,这是因为卡尔曼三维跟踪中已经包含了深度的信息,从而基于深度的排序只能略微提升。在卡尔曼三维跟踪加入遮挡处理后,MOTA指标有略微的下降,这是因为遮挡处理在一定程度上会导致误配率的上升,从而导致了MOTA的微幅下降。而从卡尔曼滤波的原理进行考虑的话,它结合历史统计的信息和当前帧的信息去对下一帧物体位置进行估计,对于短时的遮挡勉强可以,但是时间一长,统计特性就跑偏了,从而会导致性能的下降。
3.3 基于LSTM网络的动态目标跟踪实验结果与分析
在引入LSTM网络代替卡尔曼的预测及更新模块后,其结果如图12所示。本组对比选用了雪景和夜景两组场景,每种场景选用卡尔曼三维跟踪+深度排序+遮挡处理和LSTM+深度排序+遮挡处理两种方式。
在图12a中,前两帧的被摩托车遮挡的车辆的边框为紫色,而在后两帧产生了误配,从而变为了粉红色,并且在后续时刻没有恢复跟踪。而在12b中采用LSTM网络之后,被摩托车遮挡的车辆边框始终是蓝色,说明基于LSTM的跟踪方法的对于遮挡车辆的鲁棒性要高于基于卡尔曼滤波器跟踪的方法。在12c中的夜景场景中,两辆边框分别为橘黄色和品红色的车辆在经过遮挡物后,边框颜色切换成了品红色和橘黄色,即产生了误配。在12d中,采用了LSTM网络后,两辆车初始边界框颜色为橘黄色和蓝色,在经过遮挡物后依旧保持了橘黄色和蓝色,说明在夜景的暗光场景下,基于LSTM网络的跟踪算法依旧保持着良好的性能。通过两组不同场景的对比可以发现,在被遮挡时间稍长后,基于卡尔曼的跟踪产生误配的概率便会逐渐增大,这是由于卡尔曼滤波的预测是根据附近两帧的速度和位置进行预测和更新,如果附近两帧的速度位置变化较大,则卡尔曼增益的过大变化会导致对后面预测的偏差增大,从而匹配不成功。

图12 仿真跟踪效果对比
图13和图14为kitti实景测试集的跟踪效果对比,使用了连续4帧的跟踪场景,图13使用了卡尔曼三维跟踪+深度排序+遮挡处理的跟踪方法,图14使用了LSTM+深度排序+遮挡处理的跟踪方法。在图13中,可以看到从第3帧开始,被红色车所遮挡的粉红色跟踪框切换为了深红色的跟踪框,体现了卡尔曼的方法有一定的不足。

图13 卡尔曼kitti测试效果

图14 LSTM kitti测试效果
而在图14中的相同场景下,LSTM的方法则成功解决了上述卡尔曼的方法的不足。
在表7中,可以看到基于卡尔曼三维跟踪和基于LSTM网络的跟踪方法的性能对比。与卡尔曼滤波不同,在加入遮挡处理之后,LSTM的性能没有下降,而是有了0.05个点的提升,这说明LSTM内在的长时间记忆能力发挥了作用,能很好地对遮挡物体进行估计,从而使得遮挡物体的匹配成功率有一定程度的提升。
表8为三维立体框的交并比指标,从这个指标可以间接地看出不同方法预测模型的性能高低。

表7 不同跟踪方法性能评价
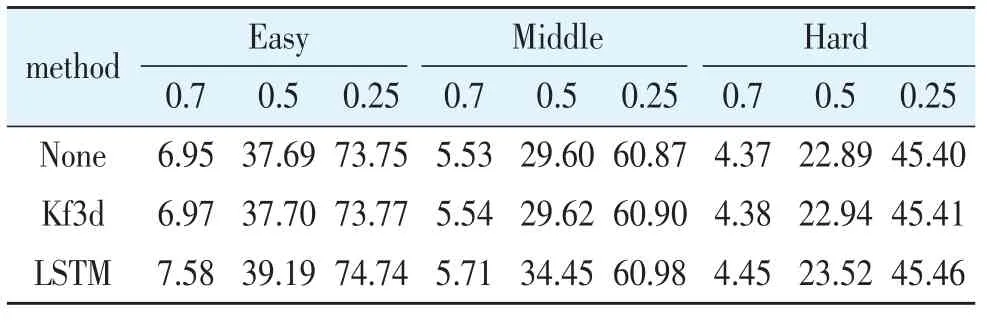
表8 三维立体框交并比
4 结论
本文致力于提高无人驾驶感知模块的检测与跟踪精度来提升无人驾驶的安全性和可靠性,主要的工作总结如下。
1)研究了基于视觉的动态目标检测的方法。本文在原始的Faster R-CNN目标检测框架上进行优化。在C-RPN网络中,通过增加多尺度的锚框来获得基于锚点和基于车辆的候选区域提案,从而提升了检测的精确度。在CRN网络中,通过在全连接层后增加Inception模块,来减小池化所造成的损失,获得精准的车辆回归边框以及三维中心在二维平面的投影。针对传统的NMS算法对遮挡车辆的漏检问题,对其进行优化,提出了O-NMS算法,成功解决遮挡车辆漏检问题,提升了目标检测的精确度。
2)研究了基于卡尔曼滤波的动态目标跟踪的方法。通过提取目标车辆的表观特征以及对车辆进行三维尺寸和三维位置估计,来提升车辆匹配的鲁棒性。对于遮挡的车辆,由于具有近似的深度信息,所以在马尔可夫决策过程的状态空间中加入了遮挡的状态,通过对遮挡车辆的三维运动估计来维持对遮挡车辆的跟踪与匹配。经过改进后的目标跟踪方法在无人驾驶复杂的路况中,对跟踪目标车辆有着稳定良好的表现,且对遮挡车辆的跟踪有了很大的提升。
3)研究了基于LSTM网络的动态目标跟踪的方法。针对基于卡尔曼滤波器的动态目标跟踪方法在处理完全遮挡的车辆目标时依旧存在ID切换问题,在分析后得出卡尔曼滤波器无法支持长时间记忆,所以引进了LSTM网络。用于预测的LSTM网络通过T-1帧的车辆的三维位置及T-5~T-1帧的车辆速度来预测第T帧的车辆位置及速度信息。用于更新的LSTM网络通过预测网络的信息以及当前帧检测的车辆位置信息来对当前帧车辆的位置信息以及速度信息进行更新。通过两个LSTM网络使不同状态的车辆进行有序切换,来获得鲁棒的目标跟踪效果。在实验的效果上来看,该方法有效解决了跟踪车辆完全被遮挡后重现时跟踪ID切换的问题。
通过以上的目标检测与跟踪流程,可以较好地适应无人驾驶的复杂路况和场景,对于跟踪车辆遮挡的问题有着较好的解决效果,故有良好的应用价值。
