基于FPGA 的视频实时目标检测方法研究①
2022-04-30何建彬俞天纬宦若虹
陈 朋 何建彬 陈 诺 俞天纬 宦若虹③
(*浙江工业大学计算机科学与技术学院 杭州 310023)
(**浙江工业大学信息工程学院 杭州 310023)
0 引言
目标检测是一项计算机视觉领域中结合图像分割和图像识别的重要技术。传统目标检测的区域选择策略没有针对性,时间复杂度高,窗口冗余,对于多样性变化的特征没有好的鲁棒性。因此在边缘端设备上实现目标检测,需要实时性更好、计算复杂度更低的目标检测方法。
随着深度学习的发展,目标检测领域取得了很多突破性的研究成果,其检测的精度和速度都有了较好的效果。文献[1-3]提出了区域卷积神经网络(region-based convolutional neural network,R-CNN)和Fast R-CNN 网络,使得神经网络在目标检测上获得了较大的突破。但Fast R-CNN 也暴露出了区域候选的计算瓶颈问题,文献[4]在此基础上提出了Faster R-CNN,引入一个区域候选网络(region proposal networks,RPN),并优化了算法。但是Faster R-CNN 在实时性上仍然有所限制,其在图形处理器(graphics processing unit,GPU)上的帧速率仅有5 fps,因此YOLO[5]提出了one-stage 的概念,此方法将物体分类和物体定位在一个步骤中完成,提高了实时性,但是准确率和漏检率有待提高。SSD[6]综合了Faster R-CNN 和YOLO 的优点,采用多尺度的特征图来得到准确率与实时性更高的网络模型。
另一方面,目前卷积神经网络的实现主要搭建在GPU 上,GPU 能够使卷积神经网络的训练得到很好的加速,但是能耗较大,不易作为边缘端硬件平台,限制了其应用场景。现场可编程门阵列(field programmable gate array,FPGA)是一种可编程、可定制的芯片,具有并行处理的能力,以及高性能、高灵活性等优点[7],可以被运用到CNN 的加速中[8]。Xilinx 公司推出了用于高性能需求的异构平台ZYNQ 系列芯片,配合Cortex 系列的处理器,搭配可编辑逻辑部分,使得芯片架构灵活、运行功耗低、可重构性和可移植性强。同时Xilinx 公司还推出了高层次综合工具Vivado HLS 和Vitis,使得卷积神经网络在FPGA 上的开发周期大大缩短。2015 -2019年的FPGA 会议[9-13]提出的各种加速器和加速器的框架,都表明FPGA 适用于卷积神经网络的移植。文献[14]提出了全栈编译器深度神经网络虚拟机(deep neural network virtual machine,DNNVM),采用启发式子图同构算法枚举所有潜在可获利的融合机会,利用管线和数据布局进行硬件资源优化,并搜索整个计算图的最佳执行策略。文献[15]提出了一种特定于域的FPGA 覆盖处理器(overlay processor unit,OPU),用于加速CNN 网络。文献[16]提出了基于舍入和移位操作量化方案的8 位优化的块浮点算法(block-floating-point,BFP),将能源和硬件效率提高了3 倍。文献[17]提出了一种将原始网络压缩为定点形式的数据量化策略,并设计了可配置的硬件体系架构,使得网络模型在FPGA 上具有较好的效果。
综上所述,本文基于FPGA 对视频实时目标检测算法进行优化实现。本文主要工作如下。
(1) 提出了结合通道注意力机制与深度可分离卷积的神经网络模型(attention-based depthwise seperable single shot multibox detector,AtDS-SSD),减少了计算量,增强了高层特征图的语义信息。
(2) 提出一种基于FPGA 的算法网络量化编译方案,将本文算法移植到FPGA 上,在保证其对目标检测准确率的基础上减少算法的复杂度,降低功耗。
1 系统总体设计
本文系统总体框架如图1 所示,由AtDS-SSD 网络模型的生成、量化、编译以及部署4 个部分构成。
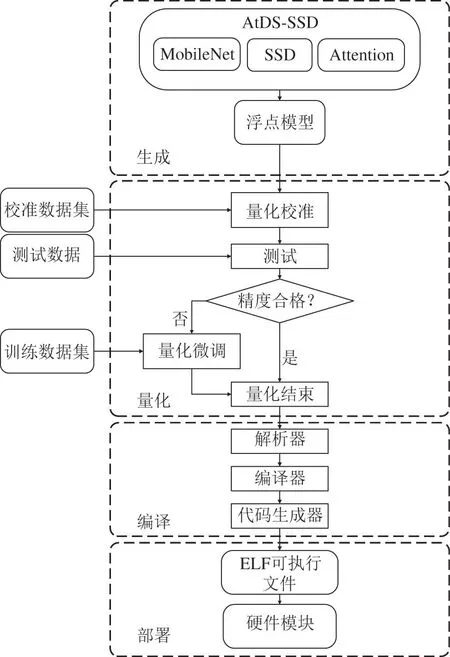
图1 系统总体框架
1.1 AtDS-SSD 神经网络
SSD 采用回归方法获取目标对象的位置,并根据目标对象位置周围的特征进行目标分类,因此需要将特征图分割成若干个相同大小的网格,对每个网格分别进行预测分类,并通过非极大值抑制方法得到最终的检测结果。
标准的SSD 神经网络运行时间较久,不满足实时性需求,并且模型参数计算量较大。为了满足实时性需求,并减少参数计算量,本文使用深度可分离卷积替换原有的常规卷积层,将常规卷积分离成深度卷积和点卷积两部分,使得计算复杂度更适合边缘设备。深度可分离卷积是轻量级神经网络MobileNet 的重要组成部分,所以使用MobileNet 作为主体网络替换原始SSD 网络中的VGG 16。同时本文结合通道注意力机制增强高层语义特征信息,补偿了由于模型参数计算量减少与实时性提升导致的精度下降,具有重要意义。
图2 展示了AtDS-SSD 卷积神经网络的总体结构,包含3 部分:第1 部分为MobileNet 基础网络,通过深度可分离卷积减少基础网络的计算量;第2 部分为通道注意力机制,通过增加很小的计算消耗,提升网络性能;第3 部分为SSD 的类别预测与位置回归。本文对网络结构的优化在保证实时目标检测需求的同时,减少边缘端设备的计算量,有助于将网络模型移植到资源有限、低功耗和低成本的嵌入式应用场景。
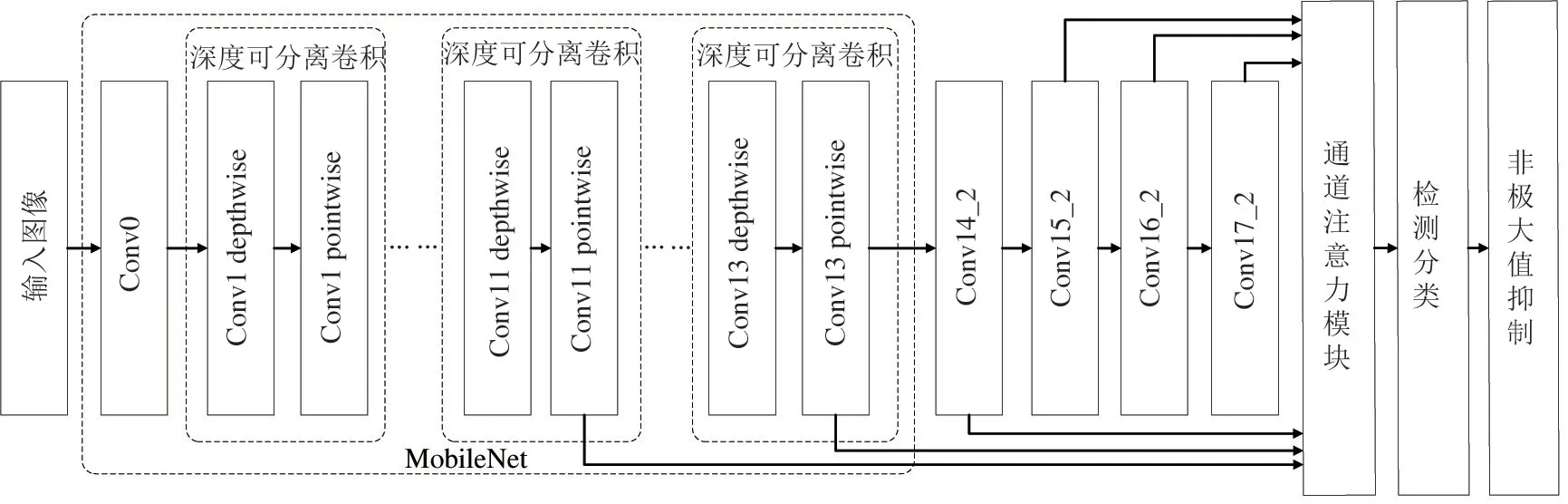
图2 AtDS-SSD 卷积神经网络结构示意
1.1.1 深度可分离卷积
深度可分离卷积是MobileNet 的重要组成部分,将标准卷积核分离成一个逐通道处理的深度卷积核和一个跨通道处理的点卷积核,有效缩小模型参数计算量的同时仍然保持较高的准确率。
标准卷积示意图如图3 所示,其中F为输入,维度为Df × Df,通道为M;将F映射到G作为输出,维度为Dg × Dg,通道为N。以常规卷积的卷积核进行卷积,需要N个卷积核,每个卷积核的维度为Dk × Dk,通道为M,总体计算复杂度为
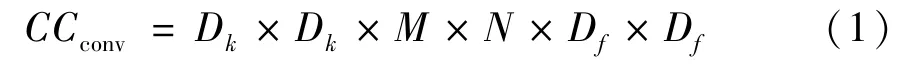
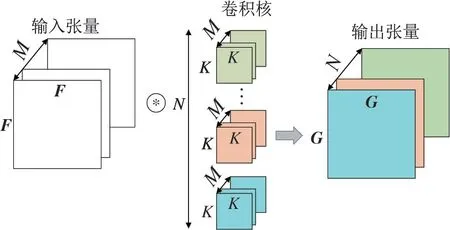
图3 标准卷积
深度可分离卷积示意图如图4 所示,由深度卷积部分与点卷积部分组成。深度卷积部分有M个Dk × Dk ×1 的卷积核,将产生M个输出张量,作为点卷积部分的输入。点卷积部分有N个1×1× M的卷积核,生成N个Dg × Dg的输出张量。该方法总体计算复杂度CCDepth为
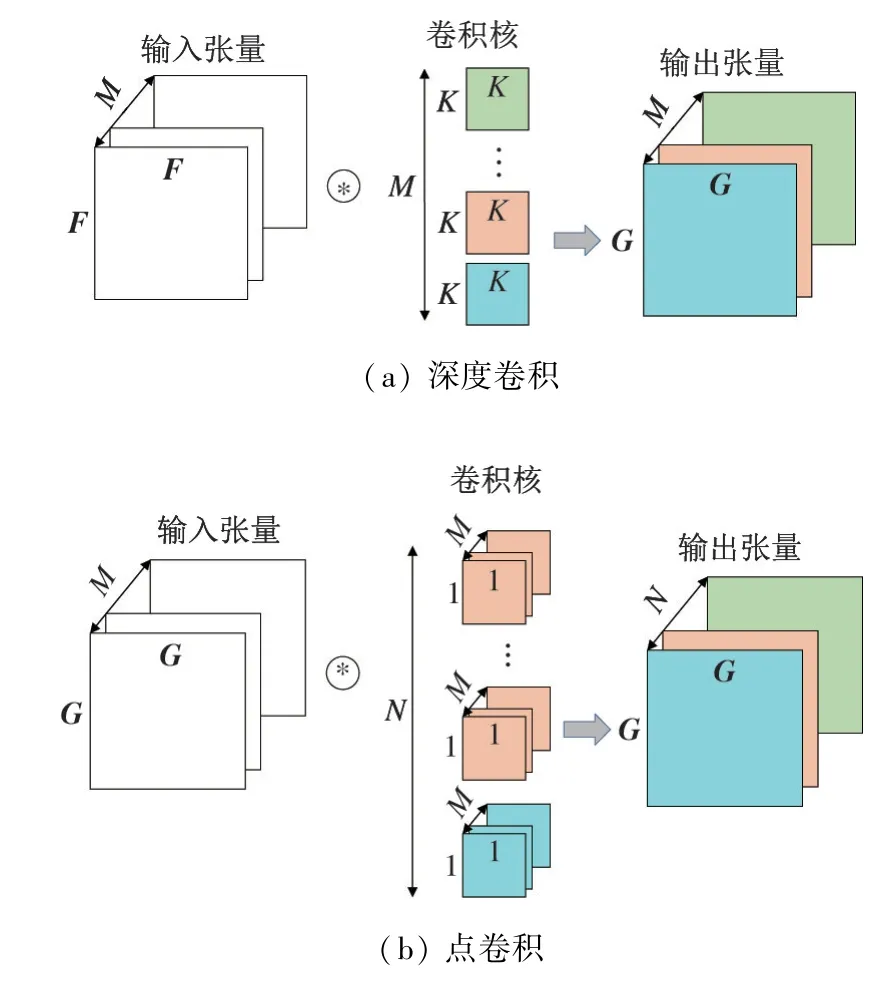
图4 深度可分离卷积
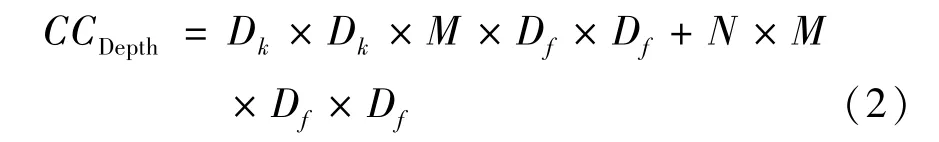
深度可分离卷积计算量CCDepth与常规卷积计算量CCconv的比率为

以AtDS-SSD 中的CONV11 层举例,输出N=1024 通道的特征图,卷积层卷积核的尺寸为3 ×3,则模型的参数计算量仅为标准卷积参数计算量的11.21%,大幅减小了模型参数的计算量。
1.1.2 通道注意力机制
通道注意力机制通过对通道间的依赖关系进行建模,可以自适应调整各通道的特征响应值,仅在牺牲少量计算量的情况下,可以极大地提升网络性能。
注意力机制模块由压缩(squeeze)、激励(excitation)及注意(attention)操作3 部分组成,如图5 所示。
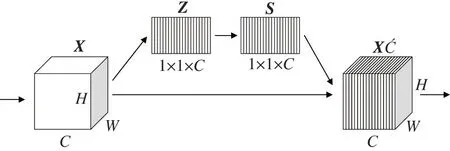
图5 通道注意力机制
Squeeze 操作是对输入X(维度为C×H×W)进行压缩,使用全局平均池化将输入特征图的全局信息压缩为通道描述符,具体的计算公式如式(4)所示。
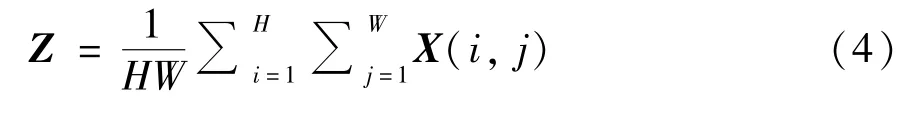
其中,(i,j) 为输入X的坐标,输出Z为C ×1×1的矩阵。
Excitation 操作是对各通道的依赖程度进行建模,本文使用ReLU 非线性激活函数和Sigmoid 激活函数的门限机制来实现。其中为了限制模型的复杂度,增强模型的泛化能力,使用了2 个全连接层去学习,根据输入数据可以调节各个通道特征的权重。具体计算公式如式(5)所示。

其中,W1和W2为通道权重,W1的维度是C′ × C,W2的维度是C × C′,C′=,通过ReLU 激活函数和Sigmoid 函数进行训练学习,最终得到的S的维度为C ×1×1。
Attention 操作为特征加权的过程,将原始的输入X替换为经过注意力模块获得的特征X′,并将其引入到原网络中进行目标检测。通过对各个通道的数据乘上不同的权重,从而增强对关键通道数据的信息。具体计算公式如式(6)所示。

1.2 模型量化
由于嵌入式平台的资源有限,将卷积神经网络移植到嵌入式平台需要进行模型压缩,其中量化模型是一种常用方法。与GPU 及中央处理器(centrol processing unit,CPU)相比较,FPGA 在模型量化上可以更为灵活,故本文采用模型量化的网络压缩方法。
由于卷积神经网络中不同层的数据动态范围通常很大,因此,对所有层进行统一的定点量化可能会导致很大的性能损失。为了解决这个问题,本文对每一层都单独进行定点量化,将32 位浮点型数据转换为8 位整型数据。
量化的方案如图1 中的量化部分所示,将训练好的浮点模型和校准数据集输入到量化校准模块中,获得定点模型。量化结束以后得到的定点模型不一定是最优状态,所以对初步量化好以后的模型进行数据准确性测试。将测试结果与浮点模型进行精度对比,当精度损失较大时,需要进行量化微调;当精度损失较小时,即可得到最终的定点模型。
其中量化校准模块如图6 所示,本文将每层的特征图和网络参数收集到量化校准模块中,对所有参数进行对数取整,得到取整后的数据直方图。根据直方图中连续八位占比最大的区间,可以不同地在每一层中找到最佳零点的位置,随后根据零点位置对所有参数进行移位操作,并进行八位定点量化。在上述步骤中浮点参数过大或过小容易造成八位定点数据溢出,对于过大的数据,保留符号,将其绝对值设置为最大值;对于过小的数据,将其设置为0。本文逐层确定每一层的零点位置,得到最佳量化结果的定点模型,用测试数据集进行测试,根据测试结果可以选择是否进行下一步的量化微调。

图6 量化校准模块
量化微调模块是将量化以后的网络模型转换回浮点格式进行微调,期间需要使用到训练数据集,且中间参数如梯度、权重、激活等浮点数将会重新训练。将重新训练的结果再次量化为定点数据,量化微调后的定点模型再与最初的浮点模型进行精度对比。重复上述步骤,直到量化之后的网络模型的精度损失在可接受范围内。
校准数据集的主要作用是定义模型动态输入的范围,因此本文选取的校准数据集包含了模型输入的所有类别。
1.3 模型编译
模型编译使用的是Xilinx 的Vitis AI 编译工具,该编译工具是编译器系列的统一接口,用于优化DPU 的神经网络计算。每个编译器都将网络模型映射到高度优化的DPU 指令序列中。Vitis AI 编译工具如图1 中的编译模块所示,主要由解析器、优化器和代码生成器3 个部分组成。
解析器将模型中的网络描述符映射到指令中。Vitis 编译工具可以根据不同的FPGA 型号选择相应的指令集。通过指令调度FPGA 上的资源,进行块分区和内存映射。块分区的主要作用是将网络模型和网络参数在片上存储,对每一层的计算都进行分区,充分利用卷积神经网络的数据本地化并减少数据输入输出,实现高效且减少功耗的作用。内存映射主要作用是将外部内存空间分配用于主机和网络加速器之间的通信。块分区和内存映射结束后,FPGA 便可以通过指令集完成网络模型的计算。
优化器优化网络模型,其中包括计算节点的融合(例如将BN 层融合到预卷积中),充分复用FPGA 上的数据,通过固有的并行性进行有效的指令调度或数据的充分利用,可用于处理CNN 的高存储复杂性。
最后通过代码生成器生成可执行文件,该文件包含了网络模型、参数与权重等信息,可将其部署到FPGA 上。
2 实验结果分析
本文完成了以下2 组实验。(1)VGG-SSD、MobileNet-SSD 以及AtDS-SSD 3 种卷积网络模型在GPU 上目标检测的平均精度均值比较以及运行时间比较;(2)AtDS-SSD 网络模型在GPU 与FPGA 上的功能验证以及性能比较。通过上述实验来验证基于FPGA 结合注意力机制与深度可分离卷积的网络模型在边缘端设备进行目标检测的综合优势。
2.1 网络模型训练
本文涉及到的3 种卷积网络模型都由服务器训练生成,硬件平台的处理器为Intel i9-10900X,显卡为NVIDIA RTX 2080Ti,部署TensorFlow 深度学习框架,通过NVIDIA CUDA 运算平台调用显卡进行卷积神经网络学习训练。本文采用PASCAL VOC 2007 和PASCAL VOC 2012 训练数据集进行训练,PASCAL VOC 2007 测试数据集进行测试,该数据集包括20 个类别,即aeroplane、bicycle、bird、boat、bottle、bus、car、cat、chair、cow、diningtable、dog、horse、motorbike、person、pottedplant、sheep、sofa、train、tvmonitor,共22 163 张训练图片和4952 张测试图片。
本文在训练过程中将输入图片的分辨率调整为300 ×300,批尺寸(Batchsize)设置为32。训练完成后对各个网络模型的目标检测准确性和损失值进行对比,各个网络结构训练过程中损失值的变化如图7所示,其中纵坐标为损失值,横坐标为训练的迭代次数,各个网络结构训练过程中准确率的变化如图8所示,其中纵坐标为准确率,横坐标为训练的迭代次数。
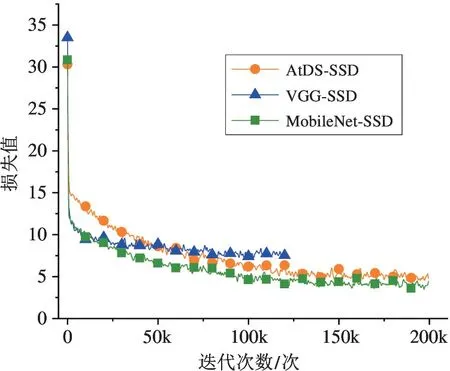
图7 网络的损失值的变化
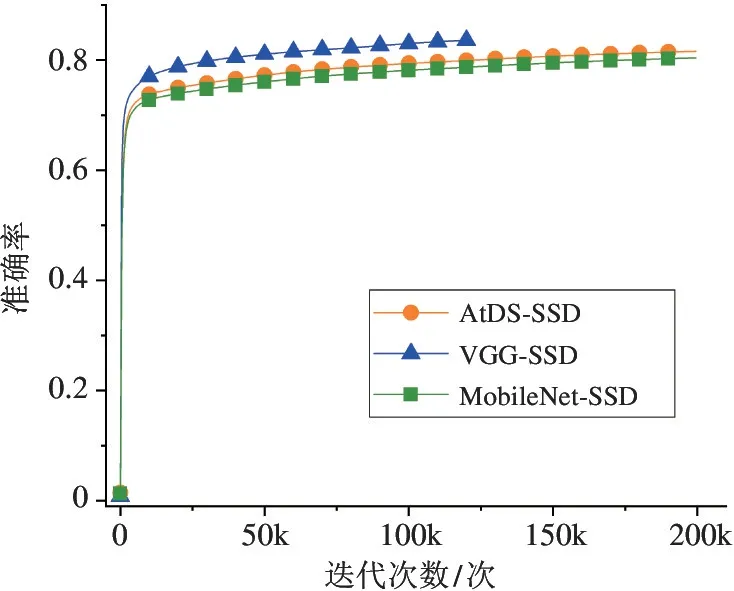
图8 网络的准确率的变化
从图7 中可以看出,loss 值随着训练的迭代次数增加逐渐减少,一直到loss 值几乎不变的时候,表明训练已经达到最优值,可以停止训练。图8 可以看出MobieNet-SSD 与AtDS-SSD 的准确率都低于VGG-SSD 网络,是因为VGG-SSD 进行检测分类的最大特征张量的尺寸是30 ×30,而MobieNet-SSD 与AtDS-SSD 进行检测分类的最大特征张量的尺寸是19 ×19,所以对小目标分类检测更加弱,准确率有所下降,但实时性增强,速率更快。同时AtDS-SSD 相比较于MobileNet-SSD,通过结合通道注意力模块增强了高层特征语义消息,补偿了由于参数计算量的减少带来的精度损失。
2.2 模型目标检测对比
本实验在NVIDIA RTX 2080Ti 上分别使用VGG-SSD 神经网络、轻量级神经网络MobileNet-SSD和结合通道注意力机制和深度可分离卷积的AtDSSSD 神经网络对PASCAL VOC 2007 测试数据集进行目标检测并比较。在目标检测中,通常采用平均精度均值(mean average precision,mAP)指标对精度进行评估,实验结果如表2 所示。从检测结果可以看出,本文提出的AtDS-SSD 网络模型在目标检测的平均精度均值上相较于VGG-SSD 网络降低了11.02%,但是相较于MobieNet-SSD 网络,AtDS-SSD的准确率提升了1.2%。

表2 VOC 测试集中部分目标检测的平均准确率
此外,为检测算法的实时性,本文对比了VGGSSD、MobileNet-SSD 和AtDS-SSD 卷积神经网络的检测速度,具体检测结果如表3 所示。由于VGG-SSD在实时性效果上远低于其他两个网络,因此不适合将其移植到FPGA 上。而结合注意力机制与可分离卷积的AtDS-SSD 卷积神经网络在检测速度上可以满足实时性需求,且在精度上相较于MobileNet-SSD网络略有优化,使其实时性和检测精度达到了更好的平衡,适用于边缘端设备进行目标检测。

表3 VOC 测试集中检测速率对比
2.3 AtDS-SSD 在不同平台的性能比较
本实验对AtDS-SSD 在NVIDIA RTX 2080Ti 和ZCU 102 上的运行结果进行讨论。
首先在不同硬件平台上对AtDS-SSD 神经网络进行功能验证。功能验证主要是将ZCU 102 上计算得到的预测数据与NVIDIA RTX 2080Ti 上计算得到的预测数据进行对比,保证网络模型的输出能达到目标检测的基本功能。
本实验针对单目标检测和多目标检测都进行了功能验证。单目标结果如图9 所示。图9(a)为单目标在NVIDIA RTX 2080Ti 上的检测结果,目标位置检测精准且分类正确,置信度为87.0%;图9(b)为单目标在ZCU 102 上的检测结果,目标位置检测精准且其分类正确,置信度为80.8%,结果与NVIDIA RTX 2080Ti 相差不大。多目标检测如图10所示。图10(a)为多目标在NVIDIA RTX 2080Ti 上的检测结果,目标位置检测精准且其分类正确;图10(b)为多目标在ZCU 102 上的检测结果,目标位置检测精准且其分类正确,但是置信度略低于NVIDIA RTX 2080Ti 的运行结果。上述结果表明,在NVIDIA RTX 2080Ti 与ZCU 102 上运行最后的检测结果产生的偏差不影响最终结果的呈现。

图9 单目标检测结果

图10 多目标检测结果
本实验对AtDS-SSD 神经网络在NVIDIA RTX 2080Ti 和ZCU 102 上的性能和功耗进行测量与对比,其结果如表4 所示。在NVIDIA RTX 2080Ti 上进行目标检测需要的功耗为77 W,而在ZCU 102 上进行测试,功耗为8.56 W,设计功耗低,非常适合用于边缘端设备处理实时目标检测。而且在ZCU 102上使用多线程模式对输入图像进行测试时,帧率达到311.7 fps,高于NVIDIA RTX 2080Ti 平台。
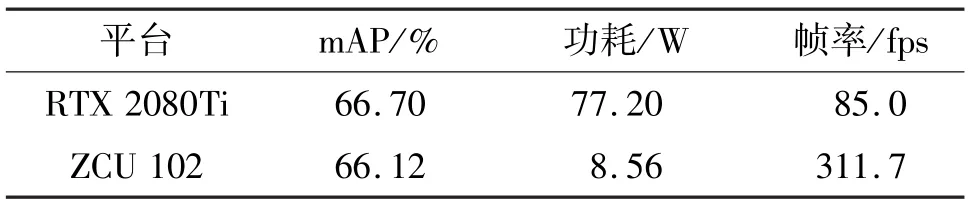
表4 GPU 和FPGA 性能对比
3 结论
本文提出了结合通道注意力机制与深度可分离卷积的AtDS-SSD 网络,减少了计算复杂度,增强了高层特征图的语义信息。提出了一种对基于FPGA的算法网络原始模型进行量化编译方案,将本文算法移植到FPGA 上,相较于现有边缘实时目标检测系统,综合兼顾了目标检测的实时性和准确性,使得2 种参数得到了更好提升,且降低了功耗,提高了计算能效。实验结果表明,本文对视频实时目标检测的优化与实现满足了边缘端设备计算实时性的要求,同时也解决了功耗问题。
