基于海量银行卡的数据挖掘推荐系统研究与应用
2022-04-29田甜蔡雅雅李爽
田甜 蔡雅雅 李爽
关键词:银行卡;数据挖掘;实时推荐
1引言
传统的顾客推荐系统根据用户的过去行为做出推荐,或者应用传统的关联规则模型的APRIORI算法[1],计算出所有的频繁集,根据预设的支持度和置信度,计算出不同的事物间的关联度。但是,这种方法具有相对局限性,截至2019年年末,中国银行卡累计发卡量达85.3亿张,持卡人超过10亿,我国境内受理商户累计2363万户,由此每天产生了海量的交易数据。推荐算法在人类生活中很早就已经得到了应用,如向朋友推荐可能感兴趣的人、可能感兴趣的书籍、可能喜欢吃的食物。而随着互联网昀普及,这种推荐方式逐渐从人们的生活经验中转移到了大型的数据中心和研究中心,使用数学公式和现代化的分析工具进行分析。从最开始的各类热点排行榜[2],到之后的各类网站推出的“猜你喜欢”[3],再到根据用户行为数据分析得到有效数据的各种个性化推荐系统。应用传统的方法在数据集合中挖掘消费行为,不仅效率低下,而且需要大量手工分析,不利于实现系统的实时性和有效性。本文介绍了一种基于海量银行卡的数据挖掘推荐系统,无须借助商业挖掘工具,就能实现实时和非实时推荐。
2数据挖掘简介
2.1确定对象
数据挖掘先要确定目标,然后对现有资源进行评估,再确定问题是否能通过数据挖掘来解决。挖掘的最后结果是不可预测的,但要探索的问题应该有预见性和目标性。一般而言,数据挖掘侧重解决四类问题,即分类、聚类、关联、预测[4]。
2.2分类问题
分类问题属于预测性问题,与预测问题的区别在于其预测结果是类别(如A,B,C三类),而不是一个具体的数值(如100、1000)[5]。在商业应用中,分类问题实践中使用最多,如预测哪些客户会参与某个促销活动,预测哪些客户在未来一段时间是否会停止使用银行卡。解决这一类问题的前提是通过历史数据的收集,明确某些用户的分类结果,确认分类成功的前提是要有明确的样本集。
2.3聚类问题
聚类主要解决的是把一群对象划分成若干个组的问题,其主要特征是需要明确的数据支持,仅根据在数据中发现的描述对象及其关系的信息将数据分组。目标是组内的对象相互之间是相似的,而不同组中的对象是不同的。例如,需要选择的若干个指标项(如渠道、商户类型、交易金额等),对已有的用户群进行划分,特征相似的用户聚为一类,特征不同的用户分属于不同的类。
2.4关联问题
关联问题主要是解决世界上万事万物间千丝万缕的联系的问题。关联分析可从大量数据中发现事物、特征或者数据之间频繁出现的相互依赖关系和关联关系。这些关联并不总是事先知道的,而是通过集中数据的关联分析获得的。例如,一群持卡人去了多种商户类型的商户,哪些同时去的商户类型的概率比较高:去了A商户的同时,接下来去哪些商户的概率比较高。
2.5预测问题
预测主要指的是预测变量的取值为连续数值型的情况。预测的目的是利用过去已有的知识和发生过的事情来更好地了解未来,以及做出合理的期望。例如,预测下一年度的GDP增长率以及银联卡产业下一年度的新增持卡人数等。预测问题的解决更多的是采用统计学的技术,如回归分析和时间序列分析。
2.6实时推荐系统
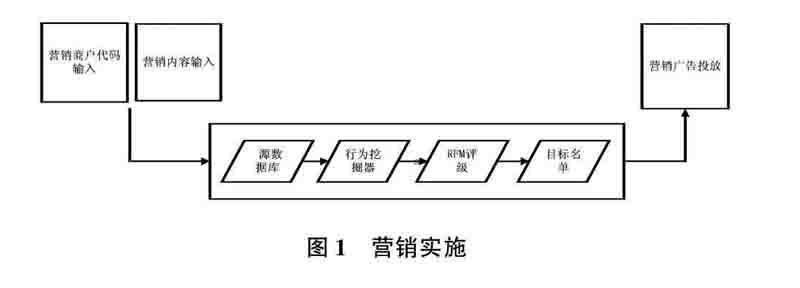
本文介绍的实时推荐系统分为三个部分,即数据ETL流程、行为数据挖掘和营销实施(图1)。
(1)数据ETL流程:数据抽取、转换、加载、集成的實时性。
(2)行为数据挖掘:通过数据挖掘,以产生决策支持的实时性。
(3)营销实施:将决策支持付诸于实施的实时性。
3数据准备
根据不同的业务问题,选取不同的、相关的内部数据和外部数据信息,并从中选择出适用于数据挖掘应用的数据。下文以营销“麻辣风暴”为例,数据的筛选分为两个方面,即数据口径和样品集范围。
3.1数据口径
根据营销的目标导向,旨在发掘商户间的关联信息进行针对性营销,挖掘相关联的商户间的持卡人的线下消费交易行为,所以数据口径确定为:数据的度量口径为交易金额、交易笔数、活动持卡人数等;由于营销的主要渠道是线下到店商户交易,因此消费的渠道为银行银商POS或其他线下消费。
3.2样品集合
3.2.1时间
营销时间的筛选。首先,不同商户间商户类型的关联性会随着刷卡时间的不同出现差异。其次,对于营销的响应度而言,样品时间越长营销响应度越低。因此,确定了营销的投送时间,也就确定了数据的筛选时间。最后,节假日的不同也会影响商户间的关联行为。例如,“火锅类餐饮”商户在冬季消费的关联性与在夏季消费的关联性可能会出现不同。原因一是,样品集合在冬季较多。原因二是,样品集在夏季消费的商户与在冬季消费的商户对比会各有侧重。另外,营销时间的筛选基准为“一个月”,可以根据营销目标的月份进行针对性筛选。例如,在12月对“麻辣风暴”进行营销,数据的样品集可以选择上一年12月的同比数据,或者是同年10月的环比数据。筛选的时间范围可以按照“季度”调整。以季度筛选,可以提高关联性的精确度,但却影响了结果的响应度。筛选的时间范围也可以按照“年度”调整,以“年度”调整一般用于研究报告,周期比较长,运行的时间也较长。
3.2.2卡数量
此项主要针对的是卡样品集的筛选。由于不同商户间商户受理的银行卡张数不同,需要筛选的卡的样品集合也不一样。考虑到样品集合的运行效率和样品集合的准确度,选择以最大10万为准,依次为5万或者1万以下。由此可以综合考虑商户的规模集。
3.2.3地区
针对商户的受理地区的选择,根据商户类型的不同,进行针对筛选。如果是本地餐饮类,可以考虑筛选受理地区为“本地”的关联餐饮商户,如“麻辣风暴”“点都德”“海底捞火锅”。如果是旅游业态为主的商户,如“迪斯尼度假区”“欢乐谷”“世博园”,则需要关注全国各地的关联商户。
4数据清洗及预处理
由研究数据的质量、应用异常值分析模块、进行相关性分析、选择相关因子、排除相关数据、进行数据的清理转换、建立相关的汇总宽表、调整数据结构等模块组成,为进一步的分析做准备,并确定将要进行的挖掘操作的各个字段的类型。
(1)异常值分析模块:应用到所有的挖掘模型,用来确定异常的数据,适用于大多数的模型。
(2)数据审查模块:检查数据的分布情况。
(3)相关性分析模块:适用于因子较多的模型,用来筛选合适的因子经过数据审查的模块。
如果发现具有大量的金额值小于5元的测试数据,就会影响关联的效果。因此,在数据的清洗过程中,还要清除交易金额值小于5元的测试数据。经过数据预处理后,将数据转换成一张分析表,这张分析表是针对关联算法而建立的。
5数据算法流程
关联算法的模型分为两大步骤,即挖掘出关联商户、挖掘出相关人群。
算法的开始确认5个主要参数:I,J,K,L和S。I代表的是样品的时间参数:J代表的是样品的卡张数:K代表的是关联商户的名单:L代表的是目标人群的卡量;S代表的是持卡人RFM评分结果。经过两个流程的梳理,再挖掘出营销关联强商户和营销的目标人群。
算法:Generate_P romotion_List。
输入:商户消费信息库,记作M;个人消费库,记作D;商户类别库,记作L。
输出:营销人群列表L
方法:(1)扫描商户消费信息库M-次,收集目标营销商户C集合的人群列表;(2)扫描个人消费信息库D-次,收集目标C的所有商户消费记录B;(3)调用confidence_ calc来计算关联关系。该执行过程如下,如果B中商户消费中,消费记录则消费N的计数增加l,对N按照置信度计数;(4)扫描商户消费信息库M,筛选关联度紧密用户自定义的商户类别(餐饮、百货、大型仓储式超级市场),选择指定商户筛选出人群列表L;(5)IF M.card_no=L.card_no then收集该卡的交易行为;(6)对个人RFM评分S;(7)根据分值S返回营销列表L。
6结果分析
通过大量数据分析实验,结果表明,川菜的代表“麻辣风暴”人群和粤菜的代表“天天渔港”人群关联商户有明显差异。例如,去过“麻辣风暴”的入群比较喜欢去“欢乐谷”和“科技馆”:去过“天天渔港”的人群比较喜欢去“植物园”和“海洋水族馆”。以下是部分输出结果展示。
如上输出结果所示,比较“麻辣风暴”和“天天渔港”主题挖掘结果:在每家商户中,均有不同的关联度最高的商户。在商户中,有相同的商户地点,也有不同的商户地点。结果显示,在同餐饮商户类别中,不同商户的关联结果是不一致的,证明了结果的差异性和有效性。
7结束语
在“大数据”时代,数据量异常庞大,以不同类型的结构加速数据生产,支持庞大的数据分析规模是一项非常有意义的工作。本文介绍了一种数据挖掘量化的方法和系统,该过程描述了从粗放式营销到活动卡营销,再到区域性营销,最后到精准营销的数据量的变化过程,进一步说明應用该方法不仅增加了营销的准确性,而且增加了营销的有效性。其中,粗放式营销是指对已经发卡的卡片进行大规模营销:活动卡营销是指针对全国活动的卡片进行营销:区域性营销是指针对特定地区的所有卡片进行大面积营销:精准营销是根据挖掘后验证的关联结果进行的针对性营销。系统对大量数据进行分析,并对大数据集合进行了大数据集的查询和推荐实验,通过数据及效果验证,营销的效果更好,成本也得到了有效控制,极大地增加了营销的精准性和有效性。
