智慧教室课堂教学中学生抬头率检测与分析
2022-04-29孟祥睛贺红赵永健
孟祥睛 贺红 赵永健

关键词:目标检测;YOLOv5;BiFPN;智慧教室;教学评价
1引言
为加快教育现代化和教育强国进程,教育部于2018年制定了《教育信息化2.0行动计划》,计划指出要以人工智能、大数据、物联网等新兴技术为基础,依托各类智能设备及网络,积极开展智慧教育研究和示范。2019年,相关部门印发《中国教育现代化2035》,再次指出要加快教育信息化的脚步,建设智能化的校园,为国内高校探索智慧教育模式提供了方向。智慧校园是数字校园的进一步发展和提升,是教育信息化的更高级形态,智慧教室作为智慧校园的重要组成部分,是建设智慧校园进程中不可或缺的部分。
智慧教室是指在传统教室基础上应用物联网和人工智能技术实现对教室内物品和人员的智能感知与控制、应用大数据技术对课堂活动所产生的的数据进行数据挖掘和数据分析,为教学和教学督导提供便利、有效的帮助。
有关智慧教室的研究,国外相对国内要早一些。20世紀80年代末,RESCIGNO RC首先提出了“Smart Classroom”的概念。这是一种集成了个人计算机、交互式激光磁盘视频程序、闭路电视和局域网等设备或技术的课堂设施。国内史元春等在2001年提出了未来智慧教室的四个特征,即自然用户交互、自动捕获课堂事件和体验、情景感知和主动服务、支持协作工作。他们设计的智慧教室兼具远程教育概念,在当时被称为世界上最先进的教室之一。早期的智慧教室实际上更应该称为多媒体教室,直到2008年“智慧地球”概念的提出,传感器技术、富媒体技术和人工智能技术争先发展,促进了智慧教室项目的发展,研究人员开始尝试将物联网和人工智能中的各类技术与智慧教室相结合。
在人工智能方面,尝试用于处理智慧教室音视频图像数据的有语义识别、人脸识别、目标检测和情绪识别等模型。但是,实验室场景和教室实际应用场景相差较大,有的模型在实验室效果很好但是却不适合用在实际场景。YELINK等在智慧教室项目中加入了情绪识别来检测学生情绪状态。人类的情绪会影响学生的学习认知过程尤其是对注意力影响巨大,在课堂中检测师生情绪状态可以判断其是否在认真参与课堂教学。但是,若要精确识别学生的情绪状态,需要清晰的面部照片和瞳孔照片来展示表情变化,所须条件和环境比较苛刻,难于在学校中广泛实施。LIN J等提出了一种在课堂中进行举手检测的方法来分析教学氛围,通过特征金字塔捕捉细节和语义特征,然后融于R-FCN架构中,取得了85%的平均准确率。董琪琪等改进的SSD算法在进行智慧教室学生状态检测时识别准确率达到了惊人的95.4%,但是从论文中所给出的效果图来看,实验是在8-10人的房间里进行的,且教室内人员较固定、影响因子较小,与实际教室环境相差甚远。
如今,移动智能设备的快速发展,使得手机、平板电脑等智能终端成为人们生活中密不可分的一部分,在大学课堂上越来越多的学生被智能终端吸引从而低头,这种状况对教师教学内容和形式的吸引力是一种负证据。所以,课堂上的抬头率对于教学评价便有了一定的参考价值。为了进一步提高深度学习技术与智慧教育的结合度,在不侵犯学生个人隐私的前提下,本研究将以目标检测的方式,从检测课堂学生抬头率人手,为教学评价新方式提供一定参考。
目标检测至今已有20多年的发展历程,早期的传统目标检测主要是由手工提取特征,不仅实验准确率不高,而且速度还慢,直到2012年卷积神经网络的兴起给目标检测领域注入了新的活力。YOLO( YouOnly Look Once)系列正是基于卷积神经网络的单阶段目标检测算法,自YOLOvl面世以来,历经YOLOv2,YOL0v3等多个版本的改进与优化,一直到现在的YOL0v4与YOL0v5,都是目标检测领域的佼佼者。YOL0v5与YOL0v4相比具有更高的灵活性和更快的速度,且模型方便快速部署。YOL0v5按照模型大小递增分为n,s,m,l,x,其中YOL0v5x模型参数最多,性能最好,但也最耗时间,各模型结构一致,仅在深度和宽度上有变化,模型主体部分均由Backbone,Neck,Head三部分组成。
研究思路是:对智慧教室的各路图像进行比较,从中选出一路能从前方拍到教室所有学生的视频,使用目标检测技术从视频中检测出低头和抬头的学生,统计人数,计算出抬头率。
2材料与方法
在众多目标检测工具中,YOL0v5是较为活跃的一种网络模型,具有超高的灵活性和较低的上手难度。经过速度与准确率之间的比较,本文采用YOL0v5中的YOL0v5s模型进行研究。
2.1课堂学生抬头率检测流程
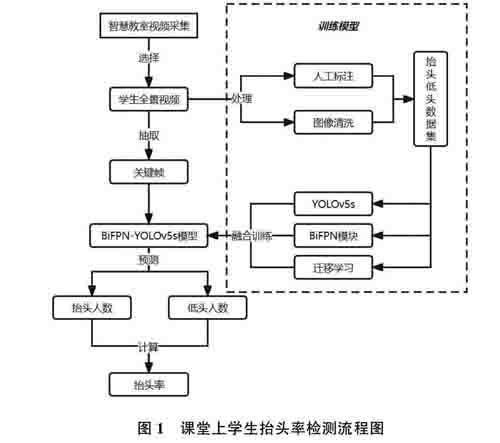
YOL0v5s模型直接用于在智慧教室课堂监测学生抬头率效果不够理想。比如,有学生会把书包放在桌上,书包上端从视频中看去就是一个黑色头顶,容易造成检测误差。经过大量实验,列举了各种造成检测误差的情况,为了提高模型对课堂场景的适用性,提高学生抬头率检测的准确率,团队对YOL0v5s模型进行改进。改进方法是将BiFPN模块融入YOLOv5s模型。研究流程如图1所示。
2.2数据采集与准备
本研究所用实验数据均来源于本校区智慧教室云平台,目前本校已在校区内大多数教室安装了智慧教室所需的硬件设备,该平台具备实时直播、录播回放等视频功能,每间教室设有教师讲台、学生全景、课件屏幕三个机位,部分教室在此基础上额外实现了学生双机位全景。
本文研究的课堂抬头率检测基于学生全景机位(如图2所示)制作数据集,具体方式为:(1)在智慧教室云平台的录播回放分区分别获取春夏秋冬四季课堂上课视频;(2)根据观察,由于时间相隔太近视频帧之间变化极小,因此不必挨个抽取每帧图像,每节课视频选择均匀抽取十帧图像;(3)人工筛选出抽帧不合理的图片,如图片过于模糊、上下课期间等无意义场景图。最终,共采集课堂图片427张,采用Labellmg标注软件进行人工标注后,共计获得标注样本24010个,其中抬头样本10629个、低头样本13381个。
2.3BiFPN简述
在YOLO系列Backbone网络中,将原始输入图像分别通过8倍、16倍和32倍下采样得到三种不同尺寸的特征图,然后采用特征金字塔网络(FeaturePvramid Network,FPN)进行特征融合,从而实现不同大小目标的检测。但是,由于不同的输入特征具有不同的分辨率,带来了各尺度特征信息不一致的问题,LIU S等通过添加路径的方式对其进行了改进,他们提出了一个自顶向下和自底向上的双向融合骨干网络,即路径聚合网络(Path AggregationNetwork,PANet),显著提高了不同尺寸特征融合之后的精确度,但随之而来的问题是成倍增加的计算量。对于只有一条输入边而没有进行特征融合的结点,它并不会对融合不同特征的特征网络产生多少影响,据此TAN M等提出了一种双向特征金字塔网络(Bi-Directional
Feature
Pyramid
Network,
BiFPN),在:PANet基础上删除了只有一条输入边的结点,从原始输入到输出结点添加额外的边,以便在不增加太多成本的境况下融合更多的特征,同时反复应用多次BiFPN实现更高级别的特征融合。
2.4迁移学习
机器学习模型通常是为了解决某类特定任务而设计,从头构建和训练模型需要大量的数据,可能达到百万量级,不仅标注需要大量的人力物力,训练也需要极大地消耗资源。迁移学习是一种用于转移从一个任务获得的成果解决另一个任务的方法,而不是从零开始,有助于提高准确性和减少训练时间。具体到本研究表现为:从COCO数据集的80类目标向抬头、低头两类目标的转换,可大大加快模型训练速度,节省资源占用。
2.5评价指标
本研究采用目标检测常用評价标准,即准确率(Precision,P)、召回率(Recall,R)、平均准确率均值(mean Average Precision,mAP)以及每秒帧数(Frames Per Second,FPS),其中平均准确率均值mAP常与IOU阈值相结合来反应性能,mAP@0.5代表在IOU阈值为0.5时的平均AP,主要提现模型的识别能力:mAP@0.5:0.95代表在IOU阈值从0.5到0.95.步长为0.05时各个mAP的平均值,主要用于提现定位效果以及边界回归能力,比单一的IOU阈值0.5更能说明模型的预测能力:FPS表示每秒检测图像的数目,值越大则说明模型每秒处理的图片越多即速度越快。各指标计算公式如下:
在公式(2)与公式(3)中,TP代表对目标的正确预测样本个数、FP代表对目标的错误预测或不存在目标的错误预测样本个数、FN代表对目标的漏检样本个数。
3实验与结果分析
3.1模型训练过程
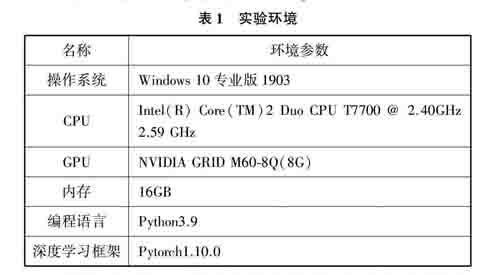
本研究实验环境如表1所列。
训练过程如下:为减少资源消耗、快速得出结果,以YOLOv5官方提供的YOLOv5s权重文件为预训练权重,在此基础上进行迁移学习,设置迭代批量大小为16,总迭代次数为300次,初始学习率为0.01进行模型训练。训练过程中的mAP@ 0.5随训练迭代次数变化如图3所示,mAP@ 0.5:0.95随训练迭代次数变化如图4所示。
3.2模型对比与分析
通过训练过程产生的平均准确率变化(图3)可知,YOLOv5s模型与融合了BiFPN模块的YOLOv5s模型的识别准确率都非常不错,在最高处分别达到了96.21%和96.38%的平均准确率,相较之下,后者优势并不明显。但是从图4来看,融合了BiFPN模块的YOLOv5s模型在mAP@0.5:0.95下相比原版YOLOv5s模型有所提高。根据表2看到,添加了BiFPN模块的YOLOv5s模型之后检测速率略有下降,在本应用场景下差距0.002秒,几乎没有影响,可忽略不计。
为进一步探索BiFPN模块是否起到理论上的作用,在测试集上再次进行对比实验,本次实验采用人工检验的方式检查模型预测结果,使用训练好的模型进行训练时,confidence设置为0.55,IOU阈值设置为0.7,结果如表3所列。可以看到,相较于原版模型,融合BiFPN模块的YOLOv5s模型的错识别率和漏识别率显著降低。从识别的效果图(图5)来看,除了人眼看不到但人脑可以猜测到的人外,BiFPN-YOLOv5模型基本都可以识别正确。
3.3检测结果展示
本研究在模型训练完成后进行了应用测试,测试时会先对输入的视频进行处理。据观察,对于智慧教室产生课堂视频,一节50分钟的课大概有10万帧,因此选择均匀抽帧的方式对其进行处理,这既能确保获取整节课的抬头率变化情况,也能节省系统资源,缩短处理时间。图6为对某节课堂视频使用BiFPN-YOLOv5s模型检测后产生的抬头率变化图,从图6中可以大致得出本节课教师的上课情况,如前半部分学生抬头率较高,说明任课教师讲的内容可能非常吸引学生,课堂中间部分学生抬头率波动比较大,可能是任课教师让学生在记录。
4结束语
本研究基于YOLOv5提出了一种面向教学评价的抬头率检测模型,采用BiFPN结构对网络的精度和泛化能力进行提升,实验结果表明,该模型的平均识别准确率已经达到95.8%,在测试集上经过人工核验后单一精度达到98.4%,每秒可处理50张图片。本文提出的抬头率监测模型具有较强的检测能力和泛化能力,可为学校进行教学评价和学生选课提供客观依据,为智慧教室的数据使用方式提供参考。
