基于多特征信息融合的风电机组整机性能评估
2022-04-29曾天生陈汉斯褚学宁
曾天生,刘 航,陈汉斯,王 峥,褚学宁+
(1.上海交通大学 机械与动力工程学院,上海 200240;2.郑州航空工业管理学院 管理工程学院,河南 郑州 450015)
1 问题的描述
由于长期工作在恶劣的自然环境中,风电机组的性能退化不可避免,其可靠性随着时间的推移逐渐下降[1]。风电机组往往安装在偏远地区,发生故障会导致较长的停机时间,且需要投入大量维修成本。利用传感器采集到的运行数据对风机整体性能进行评估,对于风电机组的状态监测和预防维护具有重要意义。
风电机组的数据采集与监视控制系统(Supervisory Control and Data Acquisition, SCADA)记录了风电机组的运行数据和故障信息,在风机性能评估和状态监测等领域[2]已有广泛的应用。如Sun等[3]使用SCADA数据训练长短时记忆神经网络(Long Short-Term Memory network, LSTM)模型,提出一种风电机组健康状态值的加权评估方法,用于监控风电机组的运行状态;DU等[4]使用自组织映射(Self-Organizing Map, SOM)神经网络将高维的SCADA数据映射到二维平面上,用于检测风电机组的异常状态;丁显等[5]使用随机森林筛选SCADA数据中与转速关联较大的参数,并将其作为输入训练深度神经网络,以误差上下限阈值实现风电机组的故障预警;赵洪山等[6]基于深度自编码网络(Deep Auto Encoder, DAE)分析SCADA数据并提取重构误差,根据其分布的估计计算阈值,最后根据超出阈值的时间预测风电机组的故障;MAZIDI等[7]在SCADA数据上使用神经网络技术检测风电机组的故障,并使用主成分分析定位故障部件;胡姚刚等[8]以SCADA数据中的轴承温度作为退化趋势量,基于Wiener过程建立性能退化模型,并对轴承的剩余寿命进行预测。这些研究为风电机组状态监测和预防维护提供了支持,但对SCADA数据中由于风电机组部件耦合导致的信息冗余、信息冲突等问题考虑不足,可能导致误报警,造成不必要的维护成本。因此,有必要应用信息融合技术来提高性能评估的准确度。
信息融合的目的是对多源数据进行分析、处理和统一,从而得到更加准确的状态估计。该方法广泛应用于传感器网络、机器人技术、图像处理等领域[9]。风电机组SCADA数据是一种典型多源传感器数据,将信息融合技术应用于风电机组的性能评估和状态监测具有重要意义。马越等[10]使用自适应完全集合经验模态分解方法,从风电机组齿轮箱的多个振动传感器数据中提取特征,并使用核主成分分析(Kernel Principle Component Analysis, KPCA)进行融合,对齿轮箱开展了性能衰退分析;SOMAN等[11]使用扩展卡尔曼滤波(Extended Kalman Filtering, EKF)对风电机组的偏航角和弯曲应力数据进行了融合,用于中轴的损伤检测;KIM等[12]提出一种通用的性能指标构建方法,用于融合多传感器的退化信息;蔡忠义等[13]使用贝叶斯统计推断融合实际运行数据和历史寿命数据,实现产品的剩余寿命预测。上述方法主要针对某部件的同源数据进行融合,不适用于风电机组的整机性能评估。
与同源传感器的信息融合不同,本文基于风电机组SCADA数据中异源数据的关联关系,使用深度信念网络(Deep Belief Network, DBN)来建立多健康状态模型,提取性能特征,并基于SOM进行信息融合。最后,对SOM得到的风电机组运行状态转移过程进行分析,提出一种性能指标构建方法来量化风电机组的性能,对风电机组进行性能评估。研究框架可以分为如图1所示的两个阶段。
阶段一:筛选正常运行数据,基于DBN建立健康状态模型以提取性能特征。首先使用Sigmoid函数变换改进局部离群因子算法(Local Outlier Factor, LOF),筛选出正常运行数据。然后,使用Kendall相关系数进行参数选择,建立DBN模型拟合参数间的关联关系,提取模型预测值和实际值的残差作为性能特征。
阶段二:基于SOM融合性能特征,并构建性能指标来评估风电机组性能。使用SOM网络将多维的残差特征映射到竞争层上实现信息融合,使用状态劣化指数加权得到性能指标。最后对性能指标的分布进行拟合以确定报警阈值,作为风电机组运行状态异常的依据。
2 基于LOF-DBN模型的性能特征提取
2.1 改进LOF算法
首先根据文献[14]中对风电机组异常数据的分类和处理方法,分以下3步对数据进行预处理:①使用线性插值处理缺失值;②去除不符合物理意义的数据和弃风数据;③使用z-score公式对原始数据进行标准化。但在进行风电机组性能评估时,需要进一步筛除离群点,获得风电机组正常运行数据。LOF算法是BREUNIG等[15]提出的一种有效的离群点检测算法,其计算步骤如下。
n维空间中点L和点O的欧氏距离为:
将点L邻域内的点到L的距离排序得到(O1,O2,…,Ok),定义到点L的第k距离(即距离点L的k值距离)为dk(L)=d(L,Ok),第k距离内的点的集合称为点L的第k邻域Nk(L)。
以点L及其附近邻域作为研究对象,定义任意一点O到点L的第k可达距离为:
dk(L,O)=max{dk(O),d(L,O)}。
(1)
从式(1)可以看出,点O到点L的第k可达距离即为点O的第k距离和点O,L的实际欧式距离之间的较大值。通过式(2)计算点L的局部可达密度(local reachability density, LRD):
(2)
根据式(3)计算点L的局部离群因子(LOF),若LOF值大于1,说明点L相比领域内的点密度要小,可能为离群点。在实际应用中,需要针对具体数据,设置合适的k值和离群点阈值c,即当LRDk(L)>c时,将L判断为离群点。
(3)
由于风速功率存在非线性关系,风速的轻微变化就可能使功率发生较大的变化,而LOF算法使用欧式距离来度量数据点之间的区别,直接用于处理风电机组数据效果较差。ZHENG等[14]的研究表明,风电机组的功率维度对离群点识别影响更大,需通过对功率加权来改进离群点检测效果,但这种方法比较繁琐,且需要已知理论的风速功率曲线。对风速和功率进行标准化后,其非线性关系可以用式(4)所示的Sigmoid函数近似。因此,基于数据变换的思想,采用Sigmoid函数的反函数将风速和功率的非线性关系近似转化为线性关系,再计算欧式距离来进行离群点检测。
(4)
2.2 基于DBN的健康状态模型
输入风速的高度随机性使得风电机组在正常运行中也可能出现较大的参数波动,而当风电机组发生异常时,传统的参数阈值报警方法可能不准确,且存在滞后性。使用风电机组正常运行数据来建立健康状态模型,基于模型预测值和实际值的残差来分析风电机组的性能能够得到更加准确的结果,且不需要大量故障数据作为支撑。
首先从SCADA数据中选择与风电机组性能相关的参数作为输出,记为{P1,P2,…,Pm,…,PM}。对于其中特定的输出参数Pm,计算剩余参数与Pm的Kendall相关系数,将所有相关系数大于0.3,即中等相关的参数作为Pm的输入,并对相关度过高,即相关系数大于0.95的参数组合进行删减,以降低模型的复杂度,最终得到如图2所示的输入输出组合。

由于风电机组的SCADA数据具有很强的耦合性和随机性,传统回归拟合方法难以很好地拟合参数之间的关系。近年来,深度学习方法因为具有较强的特征学习能力而得到了广泛应用,娄建楼等[16]提出一种改进堆栈降噪自编码器来提取隐藏特征,用于清洗在线监测数据;孔繁辉等[17]使用深度信念网络DBN来预测流量,结果表明DBN能够克服传统反向传播网络的缺陷,预测精度更高。DBN是一种深度网络模型[18],具有很强的数据拟合能力,适用于风电机组参数之间关联关系的拟合,其基本组成单元是受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)。
RBM是由显层v=(vi)p和隐层h=(hi)q组成的概率图模型,ai、aj为显层和隐层神经元的偏置,wij为连接权重,定义RBM的能量函数为:
(5)
则显层神经元和隐层神经元的联合概率分布为:
(6)
(7)
其中:Zθ为归一化因子,θ={v,h,w,a,b}为RBM模型参数。
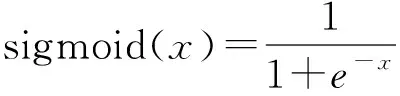
(8)
(9)
DBN的训练过程分为两个阶段:首先对θ进行随机初始化,使用对比散度算法(Contrastive Divergence, CD)[19]进行无监督预训练得到每一层RBM的模型参数;再使用反向传播算法(Back Propagation, BP)对整个网络进行微调,以提高回归预测能力。
根据2.2节中选择的输入输出参数组合,建立m组DBN模型来拟合输出参数与输入参数之间的关系,作为风电机组的健康状态模型。通过式(10)计算输出参数预测值和实际值的残差作为性能特征,用于后续的性能评估。
(10)
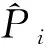
3 基于信息融合的性能评估
3.1 基于SOM的信息融合模型
在多健康状态模型下,多组残差特征的变化趋势可能存在不一致,因此需要进行信息融合。SOM是一种无监督的聚类学习方法,能够将多维特征映射到二维平面,其网络结构包括输入层和竞争层。令竞争层神经元个数为r,定义k组残差特征作为输入,即e=(e1,e2,…,ek)T,则竞争层的第i个神经元与输入层的连接权重为ωi=(ωi1,ωi2,…,ωik),其中i=1,2…,m。
对于任意一个输入e,定义最佳匹配神经元(Best Match Unit, BMU)的权重为ω*,满足:
‖e-ω*‖=min{‖e-ωi‖},i=1,2,…,m。
(11)
得到BMU后,根据式(12)对其权重ω*进行更新,并对BMU领域内所有神经元的权重使用式(13)更新。
e-ω*=min‖e-ωi‖,
(12)
ωi(t+1)=ωi(t)+Gi(t)(e-ωi(t))。
(13)
式中:t为迭代次数;Gi(t)为第i个神经元的邻域函数,一般使用如式(14)所示高斯核函数。
(14)
其中:δ(t)为学习率函数,一般随迭代次数增加而单调减小;σ(t)为宽度函数,同样随迭代次数增加而单调减小。可以看出,离BMU越远的神经元,权重变化越小,且当迭代次数增加时,BMU的邻域也会变小,从而保证算法结果收敛。
使用每一个时刻点的残差特征e=(e1,e2,…,ek)T作为SOM的输入,竞争层的BMU作为输出,从而将残差特征映射到风电机组的运行状态空间S=(S1,S2,…,Sr)T,实现了多组性能特征的信息融合。
3.2 构建性能指标
原始残差特征经过信息融合后得到运行状态序列{r1,r2,…,rN},其中N为原始数据的长度,状态值ri∈S=(S1,S2,…,Sr)T。风电机组正常运行时,残差随机波动,数据点在整个时间序列中分布均匀;运行状态异常时,残差会发生较大偏移,更多数据点转移至异常的状态。因此,本文提出一种使用加权状态劣化指数来构建性能指标的方法,具体步骤如下:

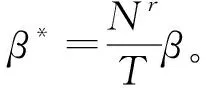
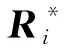
通过对性能指标序列{PI1,PI2,…,PIT}的分布进行拟合,使用上5%分位点作为阈值,性能指标超过阈值时,判定该时间窗内风电机组运行异常。相比于基于相似度的性能指标构建方法,该方法可以得到每一个状态的劣化指数,综合利用了整个时间序列的信息,且不需要设定正常模型的基准。
4 案例分析
原始数据来自EDP(1)https://opendata.edp.com/pages/homepage/。的公开数据集,记录了SCADA系统的43维传感器监测参数,如表1所示。选择采样时间为2016年1月1日~7月18日的数据作为研究对象,数据实例数量为25 494,采样间隔为10 min。根据SCADA系统的记录,该风电机组于2016年07月18日02:10:00齿轮箱发生故障。

表1 SCADA系统传感器参数列表

续表1
4.1 基于LOF-DBN的性能特征提取
首先将预处理后的风速和功率数据标准化,使用改进后的LOF算法筛选出正常运行数据,LOF算法的参数根据历史经验设定离群点比例为5%,由此确定参数设为k=120,c=1.2。如图3所示为离群点的识别情况,可以看出,原始的LOF算法会将部分风速和功率都较低的数据点识别为离群点(如图3中圆圈1),且对于理想风速功率曲线附近的离群点识别效果不好,导致漏识别部分离群点(如图3中圆圈2),改进的LOF算法检测出的离群点的分布更加均匀。
根据风电机组各个部件的重要性和发生故障的频率、使用功率(P),以及控制器温度(CT)、齿轮箱轴承温度(GBT)、齿轮箱温度(GT)、发电机轴承温度(GBT1、GBT2),共6组与风电机组性能较为相关的传感器参数作为输出,使用2.2节中的参数选择方法得到对应的输入参数组合。将原始数据划分为早期数据(60%)和验证数据(40%)。其中早期数据用于训练DBN模型,将其划分为训练集(80%)和测试集(20%),对每一组输入—输出参数组合进行训练,其中DBN的隐层设为4层,RBM的预训练迭代次数设为20,BP迭代次数设为200,学习率设为0.01。测试集的预测结果如表2所示,可以看出6组输出参数预测值与实际值的均方误差都在0.05以下,预测效果较好。

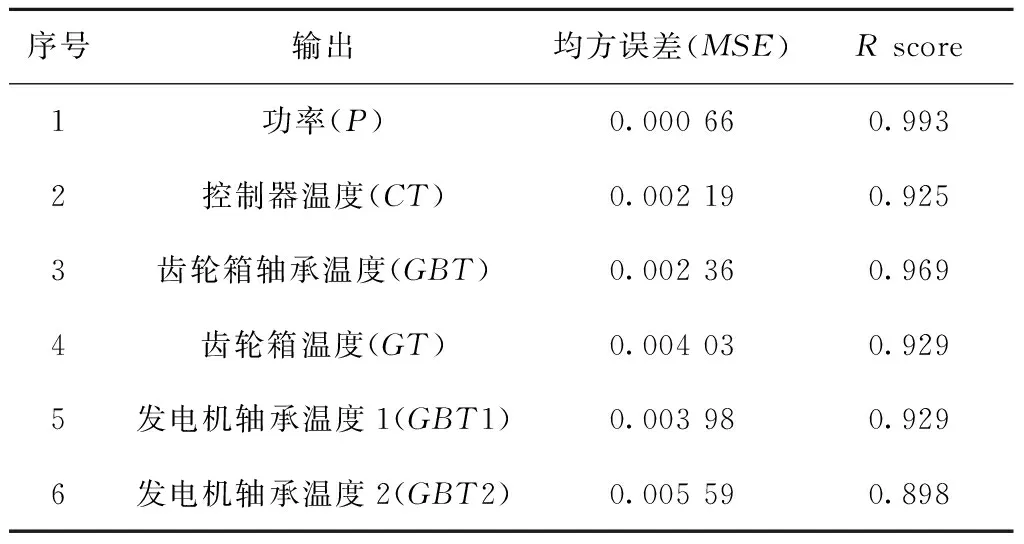
表2 LOF-DBN模型的预测结果
将所有早期数据重新训练后应用于验证数据,并获取6组输出参数的残差(如图4)作为风电机组的性能特征。从图4中纵轴的残差值可以看出P的预测残差较为稳定,而CT的预测残差则有较为明显上升的趋势,6组输入—输出参数的预测残差变化趋势并不一致,说明了信息融合的必要性。

4.2 基于SOM的信息融合与性能评估
SOM的竞争层神经元数量设为36个,将6组性能特征输入SOM,得到每一个时刻点对应的最佳匹配神经元BMU。对每一个BMU内的数据点使用3.2节中的方法计算得到劣化指数,如表3所示。从表中可以看出,大部分数据点对应的BMU的劣化指数较低,而少部分数据点输入SOM得到的BMU的异常指数较高,说明这些时刻风电机组可能处于异常状态。
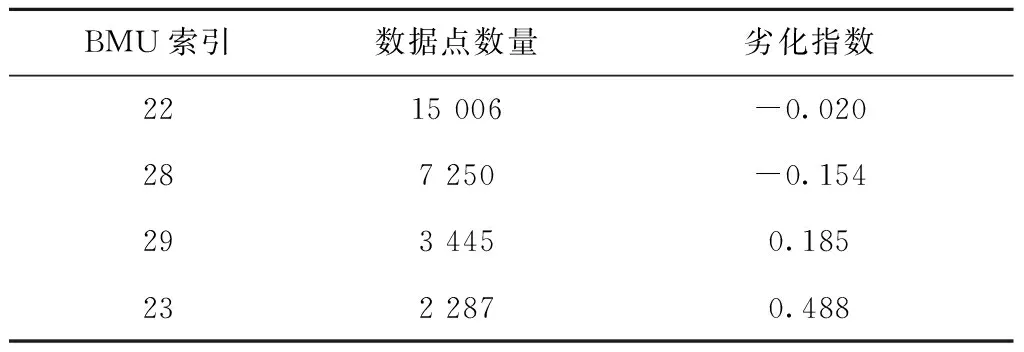
表3 各个状态的劣化指数
以一天为时间窗大小,将每一时间窗的状态分布向量标准化后乘以劣化指数向量,得到性能指标。对性能指标的分布进行拟合,发现其近似服从三参数Gamma分布,其中形状参数μ=3.001,尺度参数σ=0.057 9,阈值参数ν=-0.161。取置信度为5%,计算该分布的上分位点0.254作为报警阈值,根据性能指标的变化及阈值得到性能评估曲线如图5所示。

4.3 结果分析与讨论
从图5所示的性能评估曲线可以看出,风电机组的性能指标随时间逐渐偏离正常值,在第164天时第一次达到报警阈值,在第183天后性能指标多次超出报警阈值,已发生严重偏离。根据风电机组实际运行的故障记录,该风电机组于2016年07月18日02∶10∶00,即第199天时齿轮箱发生故障。这说明所构建的性能指标能较好地反映风电机组的性能,且能够提前16天预测到即将发生的故障。在风电机组的运行过程中,当性能指标超出阈值时应当及时对风电机组进行维护,减少故障时停机时间过长导致的大量维修成本。
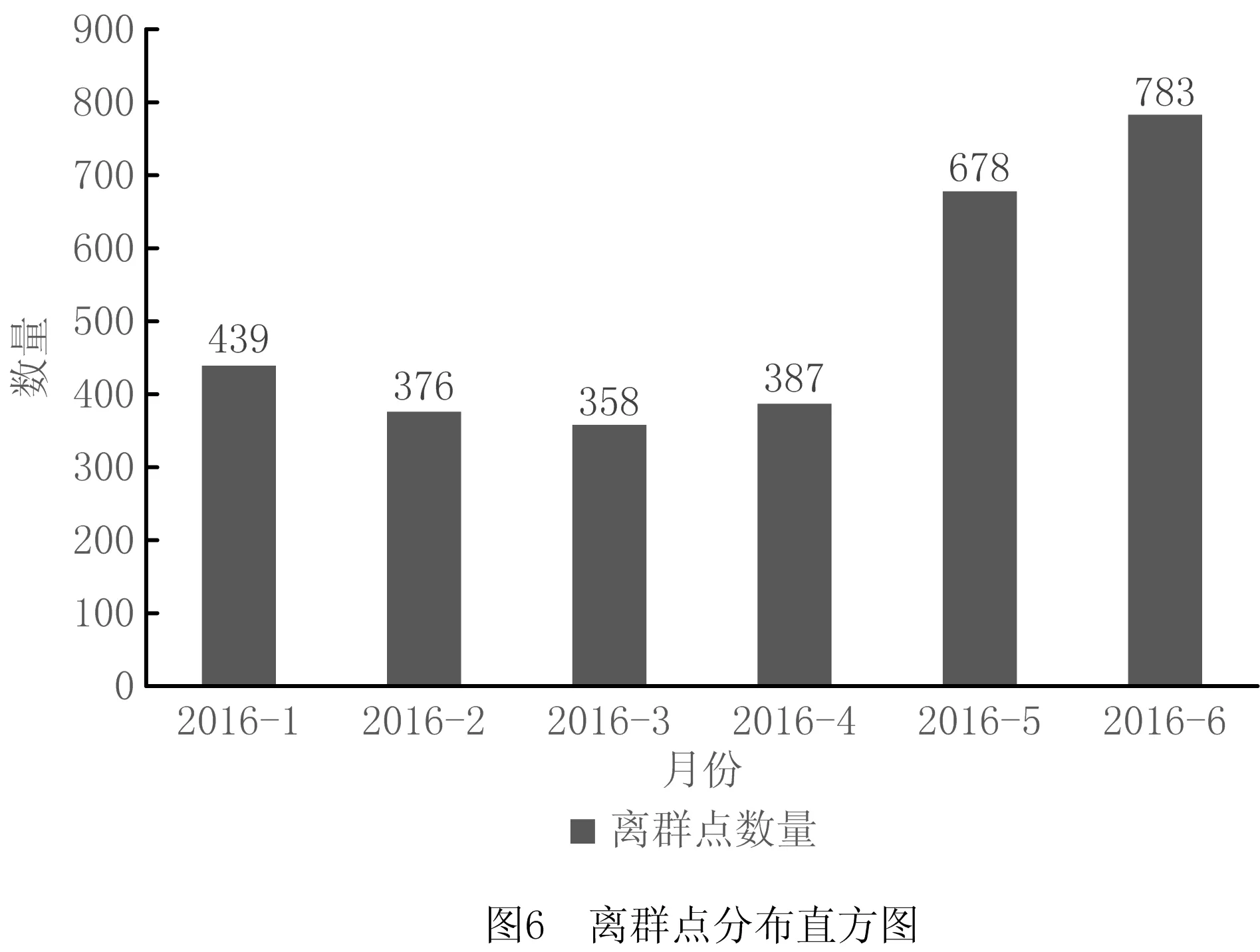
根据图6所示LOF算法筛选出的离群点分布可知,2016年1月~6月离群点数量逐渐增大,这与性能评估曲线得到的结果一致。但离群点的数量并没有发生明显增加,说明只从风速功率数据中的异常点来判断风电机组是否发生故障并不能够提供有效的预警。本文所提方法综合使用了多个与风电机组性能相关的参数来分析风电机组运行过程中的性能变化,能够在运行过程中监测风电机组的运行状态,并有效预知到即将发生的故障。
作为对比,选取该风场中另一台风电机组经过维修后正常运行时的数据输入模型,得到的性能评估曲线如图7所示,与故障时的性能评估曲线对比可以看出,风电机组正常运行时,性能指标虽然有随机波动但未发生明显的偏离,且明显低于预警阈值。因此,所提方法能够有效地识别出风电机组当前运行状态是否发生异常。

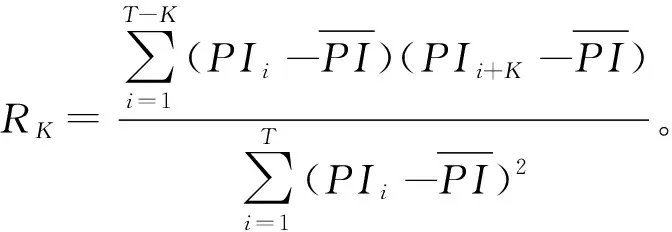
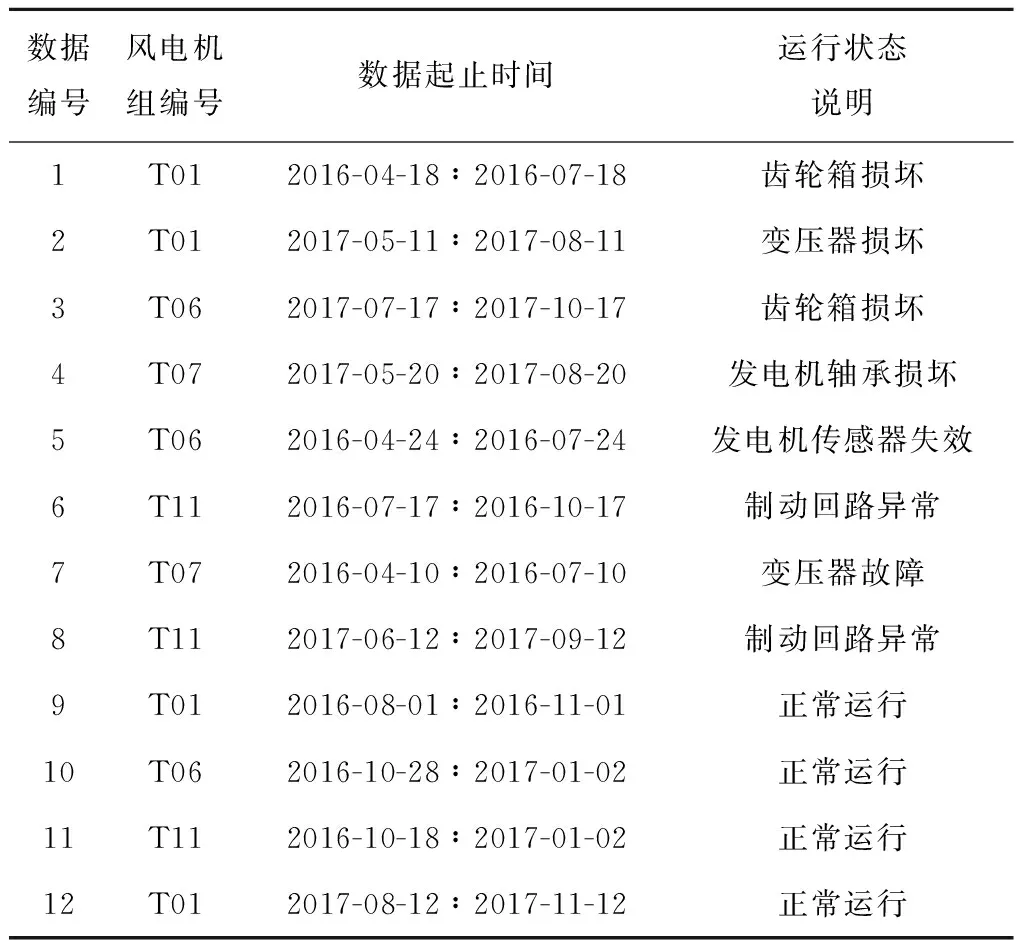
表4 数据集的起止时间和运行状态说明
使用上诉12组数据,对风电机组进行性能评估并计算异常指数,得到的结果如表5所示。
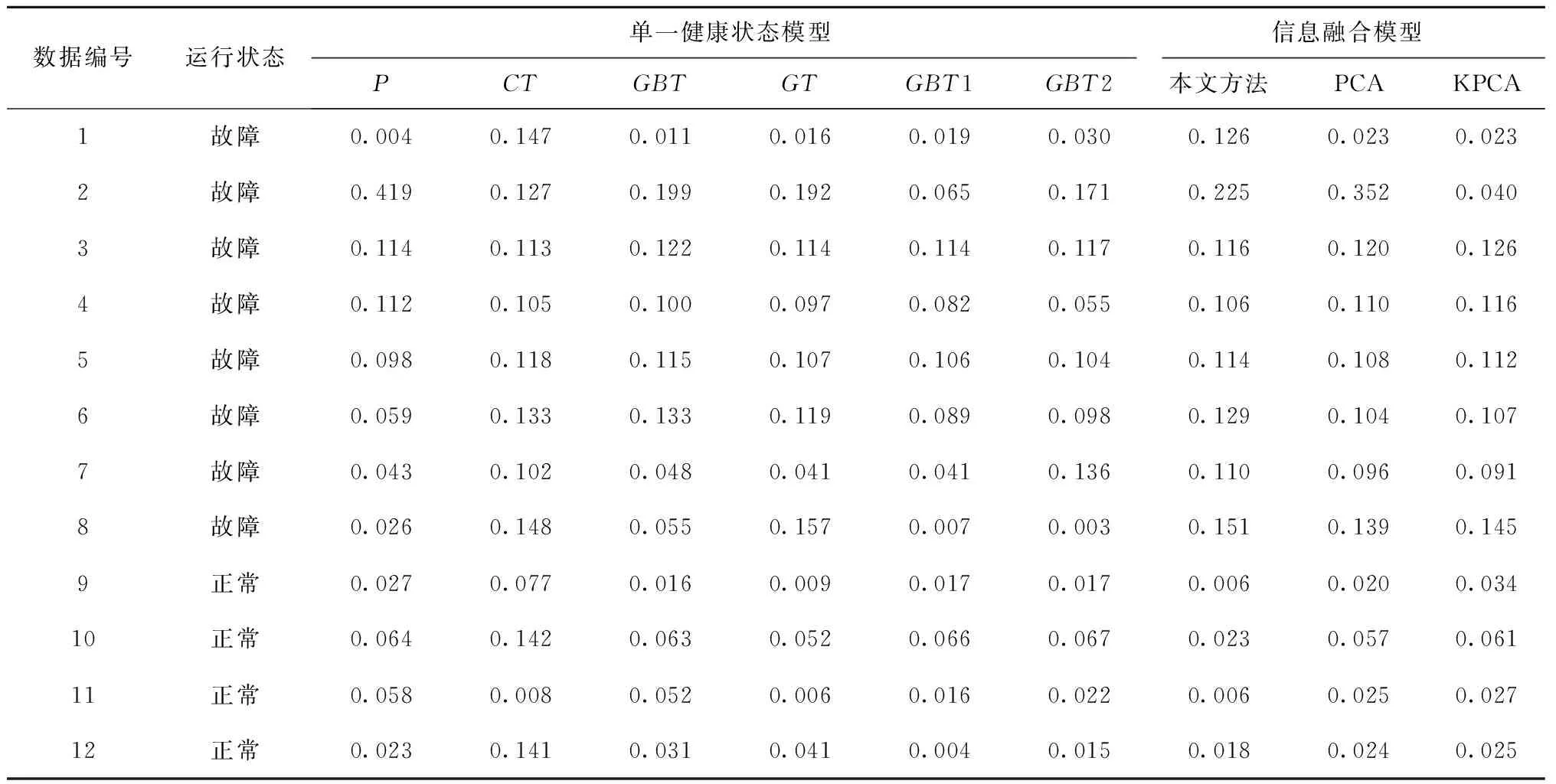
表5 多组数据集的异常指数结果对比
由表5中的结果可以看出,使用单一健康状态模型得到的异常指数存在不一致的结果。例如在数据集1中,CT的异常指数为0.147,明显大于其他指标的异常指数,而P的异常指数仅为0.004,因此难以对风电机组的实际运行状态进行判断。经过信息融合后得到的异常指数为0.126,表明风电机组确实处于异常状态,与实际数据相符。从数据3~数据6的结果可以看出,与PCA、KPCA的结果比较,本文所提方法与PCA,KPCA较为一致。但在数据1和数据2中,PCA和KPCA融合后的结果无法发现风电机组的运行异常,说明本文所提方法具有更好的鲁棒性。从风电机组正常运行的数据(数据9~数据12)可以看出,使用单一健康状态模型时,也可能存在部分输出参数异常指数较高发出报警。例如数据10的CT得到的异常指数为0.142,而综合其他特征融合后的计算结果为0.023,可见当风电机组正常运行时,信息融合能够减少误报警的发生。
因此,从多个数据集的结果来看,本文所提的信息融合方法能够融合单一健康状态模型得到的性能特征,解决不同健康状态模型信息冲突的问题,且能够反映风电机组运行状态的变化,并对每一运行状态的劣化指数进行了确定,得到更加准确的性能评估结果。
5 结束语
本文基于健康状态模型和信息融合,针对风电机组的SCADA系统提出一种状态劣化指数加权计算性能指标的整机性能评估方法。风电机组实际运行的数据表明,单一的健康状态模型可能发生误报警,有必要使用多组性能参数来建立不同健康状态模型,并进行信息融合。从多组运行数据,结果来看,本文提出的性能指标构建方法能够有效地融合SCADA数据,相比于使用单一健康状态模型计算性能指标的方法,性能评估结果更加准确可靠。主要创新点如下:
(1)使用Sigmoid函数变换改进了LOF离群点算法,预先筛选出正常工作下的运行数据用于建立健康状态模型,减少了风电机组运行过程中风速变化、传感器误差等因素对性能评估的影响,提高了性能评估的精度。
(2)针对传统单一健康状态模型不可靠的问题,使用多个健康状态模型来获得更多的性能信息,基于SOM信息融合模型,提出了一种有效的性能指标构建方法,利用该指标能更准确地识别风电机组的运行状态。
风电机组在实际运行过程中,面临复杂多变的工况,如风速、风向、环境温度等。利用工况参数来划分工况并改进健康状态模型,提高模型的准确率是未来的研究方向之一。
