基于分层网络与局部约束的高光谱图像分类
2022-04-28闫德勤于佳宁刘德山
张 景,闫德勤,于佳宁,刘德山
(辽宁师范大学 计算机与信息技术学院,辽宁 大连 116029)
0 引 言
高光谱图像(Hyperspectral Image,HSI)是一个三维的数据空间立方体,包括2个空间维和一个光谱维,其中包含了丰富的地理信息量,能够清晰地反映出真实的地表情况。近年来,高光谱图像分类在很多领域都获得了广泛的应用,如精密农业、地质勘探、环境监测、国防科技等方面。目前,人们对高光谱图像分类的研究方法主要分为2种:传统分类方法和深度学习方法。稀疏表示分类算法(Sparse Representation Classification,SRC)是一种传统的分类方法,SRC假设测试样本可以由来自同一类的少量训练样本线性重构,这一特点使得SRC与经典的分类方法,如K近邻(K-Nearest Neighbor,KNN)、支持向量机(Support Vector Machine,SVM)相比更加简洁。稀疏表示分类算法只利用了高光谱图像的光谱信息,忽略了高光谱图像的空间特征。
Chen等人提出了联合稀疏表示方法(Joint Sparse Representation Classification,JSRC),该方法假设局部窗口中的像素可以通过由训练样本构造的字典进行联合稀疏表示。根据表示残差确定每个像素的类别标签,较好地利用了高光谱图像的空谱信息。JSRC存在的问题是当像素周围窗口中包含异类像素时,会对样本的线性表示产生类间影响,Tu等人提出了结合相似度量和联合稀疏表示的分类算法(Correlation Coefficient and Joint Sparse Representation,CCJSR),通过计算训练样本和测试样本的类内相似度,同时减少类间干扰,优化分类的结果。Li等人证明了局部性比稀疏性更加关键,在分类中,局部性具有重要作用。传统的稀疏分类方法使用范数,与字典原子距离远的样本会丢失欧氏距离信息,造成分类不稳定。因此,Cui等人提出了类依赖稀疏表示分类方法(Classdependent Sparse Representation Classifier,cdSRC)用于高光谱图像的分类,有效地结合了KNN分类器,将欧氏距离和重构误差引入到同一个函数中。然而,当有多个类别与测试样本的类别相似时,利用残差和距离之和来确定标签的方法就不适用了。为了解决这一问题,Zhang等人提出了一种局部约束稀疏表示分类方法(Locality-constrained Sparse Representation Classification,LSRC),LSRC没有使用所有的训练集作为字典,而是选择靠近测试样本的样本构成局部字典,消除了远离测试样本的训练样本。
传统分类方法依赖于专业知识和经验来获取光谱空间特征,而深度学习方法通过聚合低级信息自动获取高级抽象表示,避免了复杂的特征提取工程。深度学习主要基于深度神经网络(Deep Neural Network,DNN)实现多个神经网络层(每层由多个节点组成),通过网络能够学习输入输出之间的复杂关系。传统的深度学习方法大多只涉及空谱的噪声滤波,而忽略了光谱的噪声滤波。因此,Zhou等人提出了结合高光谱图像特点的光谱空间网络(Spectral-Spatial Network,SSN)。
以上研究结果表明,在高光谱图像的分类中,基于局部约束的稀疏表示模型尤为重要,充分利用空间信息和光谱信息也必不可少。为取得更优的分类性能,针对LSRC对空谱特征结合运用不充分的问题,本文提出了基于分层网络与局部约束的高光谱图像分类方法(Spectral-spatial Network and Localityconstrained Sparse Representation Classification,SLSRC)。本算法能够充分利用高光谱图像的光谱信息和空间信息,根据训练样本和测试样本之间的欧氏距离信息,构造了一个新的稀疏表示字典。为了证明本算法在高光谱图像分类应用中的性能,选取常见的2个高光谱图像数据集,Indian Pines、Pavia University 数据集,与KNN、SRC、cdSRC、LSRC算法进行综合比较,结果表明本文提出算法在图像分类中表现出较高的分类性能。本文的其余部分安排如下:第1节介绍本文所提出的算法:基于分层网络的局部约束字典分类算法;第2节对实验结果进行展示和分析;第3节对本文进行总结。
1 基于分层网络的局部约束字典分类算法
SLSRC算法由2部分构成,分别为:构建局部约束字典和基于局部约束字典的稀疏表示。第一部分利用分层深度网络完成局部约束字典的构建,第二部分将得到的字典用于稀疏表示,并与相关系数结合进行分类。
1.1 融合深度网络的局部字典构建
本文构建空谱特征学习模型(spectral-spatial feature learning units,SSFL)来获取数据特征。每一个SSFL通过分层形式依次学习光谱特征和空间特征,最终获取高光谱图像的空谱特征。将SSFL叠加在一起,上一个SSFLU的输出作为下一个SSFLU的输入,形成一个多层的深度网络结构、即SSN,该网络能够获得高光谱图像更优的空谱特征。
SSFLU使用线性判别分析(Linear Discriminant Analysis,LDA)处理光谱特征学习的过程,空间特征学习是进行空间滤波,使用多个自适应空间滤波器对LDA的处理结果,获得同一区域图像的不同尺度表示。LDA确保同一类像素具有相似的特性,而不管其在空间中的距离有多远,自适应空间滤波则是保证同一类内的相邻像素具有相似的特征。
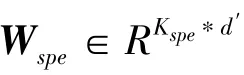
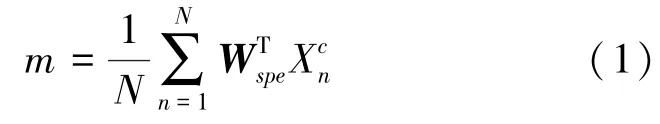
对于第类数据,平均值m为:
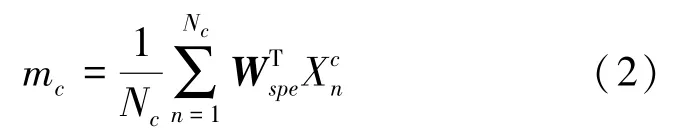
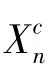
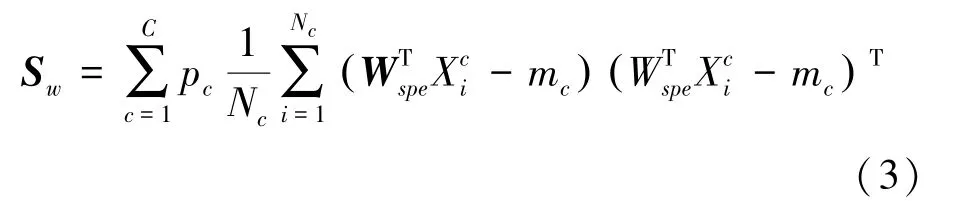
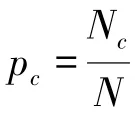
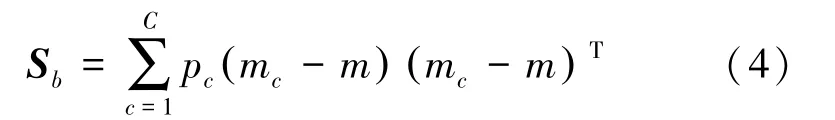
使用一系列滤波器,最大限度地提高类间散射和类内散射的比率:
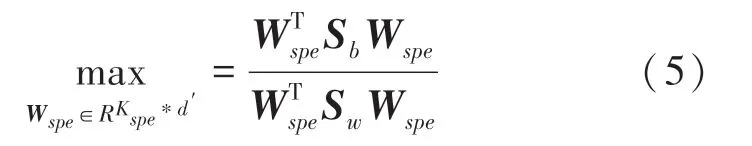
特征向量对应的若干最大特征值,求解:

得出所对应的前K个光谱特征向量,光谱滤波器可以利用滤波器对HSI数据归一化后的每一个像素进行处理形成新的数据集。
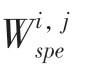
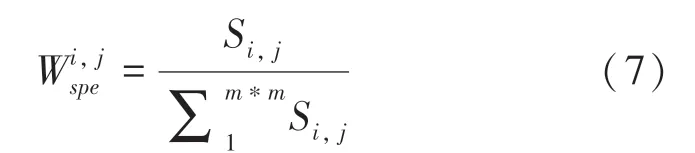
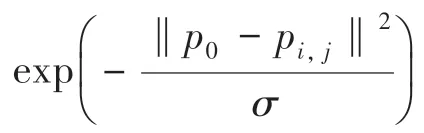
对于得到的新数据集,本文利用KNN算法来构建局部约束字典。K-近邻(KNN)分类器是预测测试样本所属类别的最简单方法,目的是在给定的空间中寻找与测试样本最接近的个训练样本,并将训练样本的类信息分配给测试样本。在本文中,对于未知类别的待测样本[,,…,y]∈R和训练样本[,,…,x]∈R,使用欧氏距离来估计测试样本与训练样本x之间的距离d,如式(8)所示:

由此对d排序,选取最小的个d所对应的训练样本作为测试样本对应的局部约束字典。局部约束字典构建过程如图1所示。

图1 局部约束字典构建过程Fig.1 Construction process of locality-constrained dictionary
1.2 融合分层网络与局部约束字典的稀疏表示
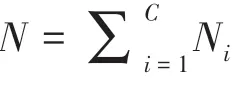
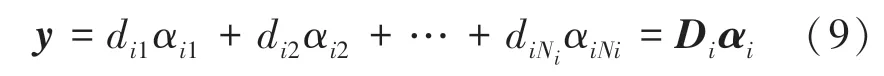
其中,α为稀疏系数,在实际应用中,由于测试样本的未知性,需要用整个字典来表示测试样本,即:

其中,[,,…,α]为子字典对应的稀疏系数,是一个稀疏矩阵,即只有第类训练样样本所对应的系数为非零值,通过计算约束问题得到:
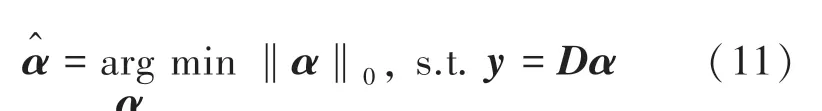
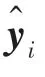

在真实的高光谱数据中,局部区域像素存在同谱异类或同类异谱的形式,这些因素将严重影响联合稀疏表示模型的分类性能。相关参数(Correlation Coefficient,Cor)是一种用于确定2个变量相关性的有效度量标准,文献[18]指出不同像素之间的用于确定像素之间是否属于同一类,同一类中的像素通常彼此具有高相关性,反之亦然。本文为客观地增加分层深度网络特征字典与测试样本之间的关联性,将融合联合稀疏表示与相关参数以平衡同谱异类或同类异谱所带来的分类不稳定性。给定测试样本和第类分层深度网络特征字典=[d,d,…,d]∈R,其中d表示第类第个原子,那么一个字典原子d与一个测试样本之间的相关系数ρ为:
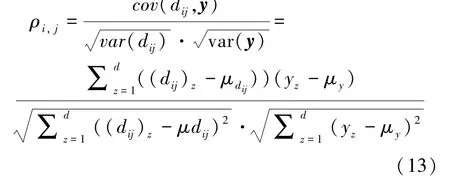
其中,(d)、()表示第类第个字典原子与测试样本之间的方差;μ和μ分别表示字典原子和测试样本的平均值。对所得的所有ρ进行排序,根据文献[18]选取前个相关系数并取得相应的平均值作为当前字典原子和测试样本之间的相关系数Cor。公式如下:
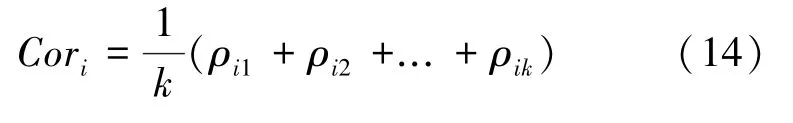
最后,将基于分层深度网络局部字典的稀疏表示与相关系数结合,利用如下公式进行分类:
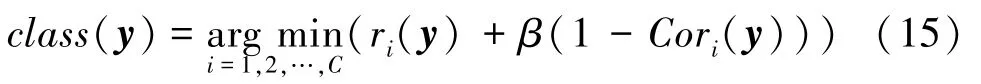
1.3 算法具体流程
给定高光谱数据,高光谱真实地物矩阵,测试样本,测试样本数据标签矩阵,测试样本索引矩阵,空谱网络层数,光谱滤波器,空间滤波次数,自适应加权滤波器AWF窗口矩阵,分层深度网络特征字典,类别数,联合稀疏表示窗口大小,相关参数近邻点个数,正则化参数。基于分层网络与局部约束的高光谱图像分类方法流程具体如下。
高光谱数据,高光谱真实地物矩阵,测试样本,测试样本数据标签矩阵,测试样本索引矩阵,空谱网络层数,光谱滤波器,空间滤波次数,自适应加权滤波器AWF窗口矩阵,分层深度网络特征字典,类别数,联合稀疏表示窗口大小,相关参数近邻点个数,正则化参数。
:、、系数
利用SSN学习空谱特征
1.1 利用LDA提取光谱特征;
1.2 计算出光谱滤波器;
1.3 利用光谱滤波器对高光谱数据进行归一化处理,形成新的数据集;
1.4 利用AWF学习空间特征;
1.5 计算空间特征自适应权重;
1.6 利用空间特征自适应权重对邻近像素进行加权求和;
1.7 多次堆叠形成新的空谱特征数据集。
利用KNN构建分层位置约束字典
2.1 在LDA投影空间中计算测试样本和之间的欧氏距离;
2.2 选取个最近的原子并找到相应的索引;
2.3 根据索引集形成基于局部约束的字典。
利用cdOMP和相关系数进行分类
3.1 对每一个子字典D分别运用OMP算法;
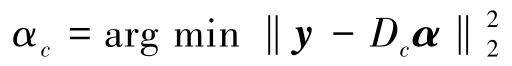
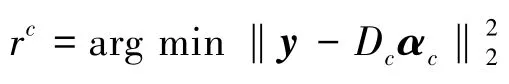
3.4 利用式(13)、式(14)计算每一类的字典原子和测试样本之间的相关系数;
3.5 利用式(15)进行分类。
2 实验结果与分析
为了验证本文算法的有效性,在2个高光谱图像数据集上进行实验,分别为Indian Pines数据集和Pavia University数据集,并选择经典传统算法KNN、SRC、cdSRC和LSRC进行比较。本文使用总体准确率()、平均准确率()和系数()三个评价标准来评价算法的分类性能。这里,表示正确分类的样本数与测试样本总数的比值,是衡量每一类的平均值,是分类测试样本的百分比,就是由纯偶然的预期的协议数修正的,所有精度均通过5次重复实验获得。在2个数据集上随机选择每个类别的10的标记样本进行训练,剩余样本用于测试。
2.1 在Indian Pines数据集上的实验结果
Indian Pines数据集是印第安纳州西北部一个区域的高光谱图像。图像大小为145×145像素,每个像素的空间分辨率为20 m。AVIRIS传感器在0.4~2.5μm的光谱范围内产生220个波段,为降低实验误差通常去除20个吸水带将光谱带的数量降至200。图2中给出了波段17、27和50组成的三波段伪彩色图和真实地面图。由图2可知,该数据集包含16个真实类别,其中大多数为农作物,如玉米、大豆、小麦、燕麦等。在这个实验中,剔除训练样本较少的类选择了12种作物,具体样本划分见表1。

图2 Indian Pines数据集三波段伪彩色图和真实地面图Fig.2 Three band pseudo color map and real ground map of Indian Pines dataset
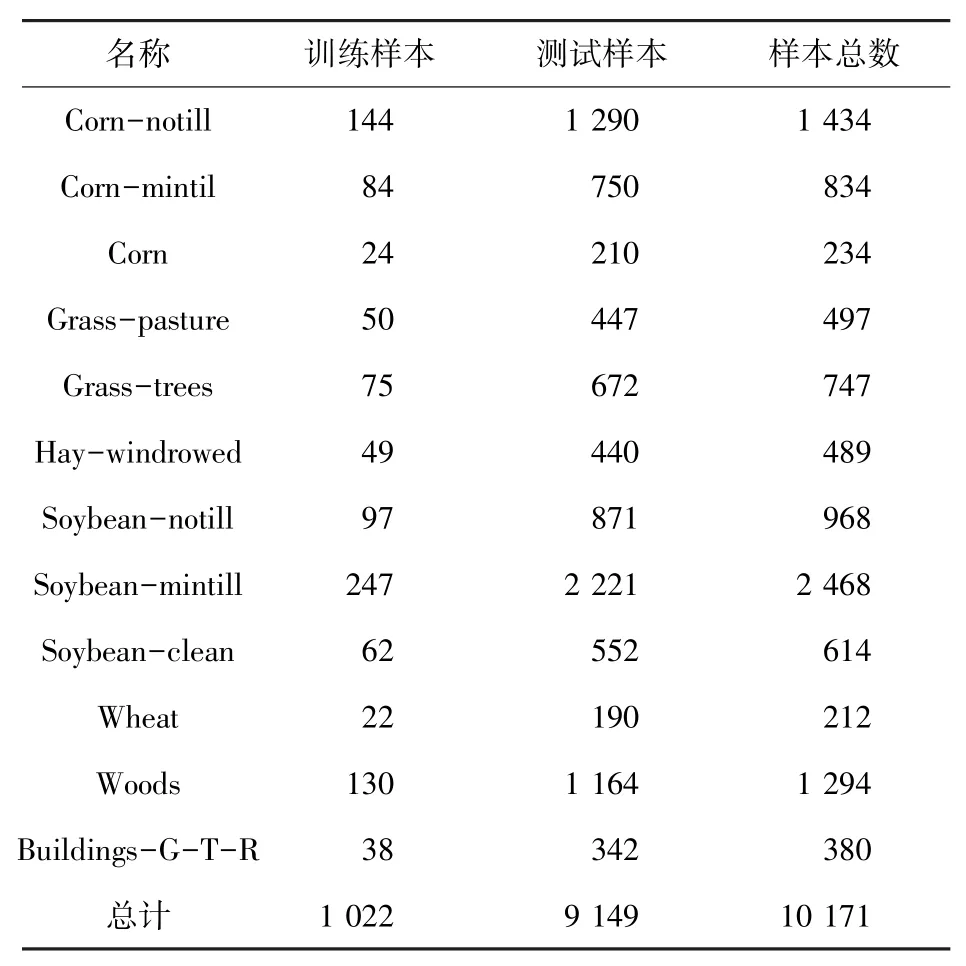
表1 Indian Pines数据集样本信息Tab.1 Indian Pines dataset sample information
表2展示了Indian Pines数据集上不同算法的分类准确率,通过比较KNN、SRC、cdSRC、LSRC与本文提出算法的、和系数可以很清楚地看到,本文算法具有最优的分类效果;相较于传统的KNN算法,总体准确率提高了约29%;相较于相对传统的cdSRC算法,总体准确率提高了大约15%;相较于较新的LSRC算法,总体准确率提高了大约9%。Indian Pines数据集不同方法分类对照结果如图3所示。由图3可以清晰地看出,与对照算法相比,SLSRC算法的分类结果中噪音较少,类间结构清晰。

图3 Indian Pines数据集不同方法分类对照图Fig.3 Comparison of different classification methods of Indian Pines dataset
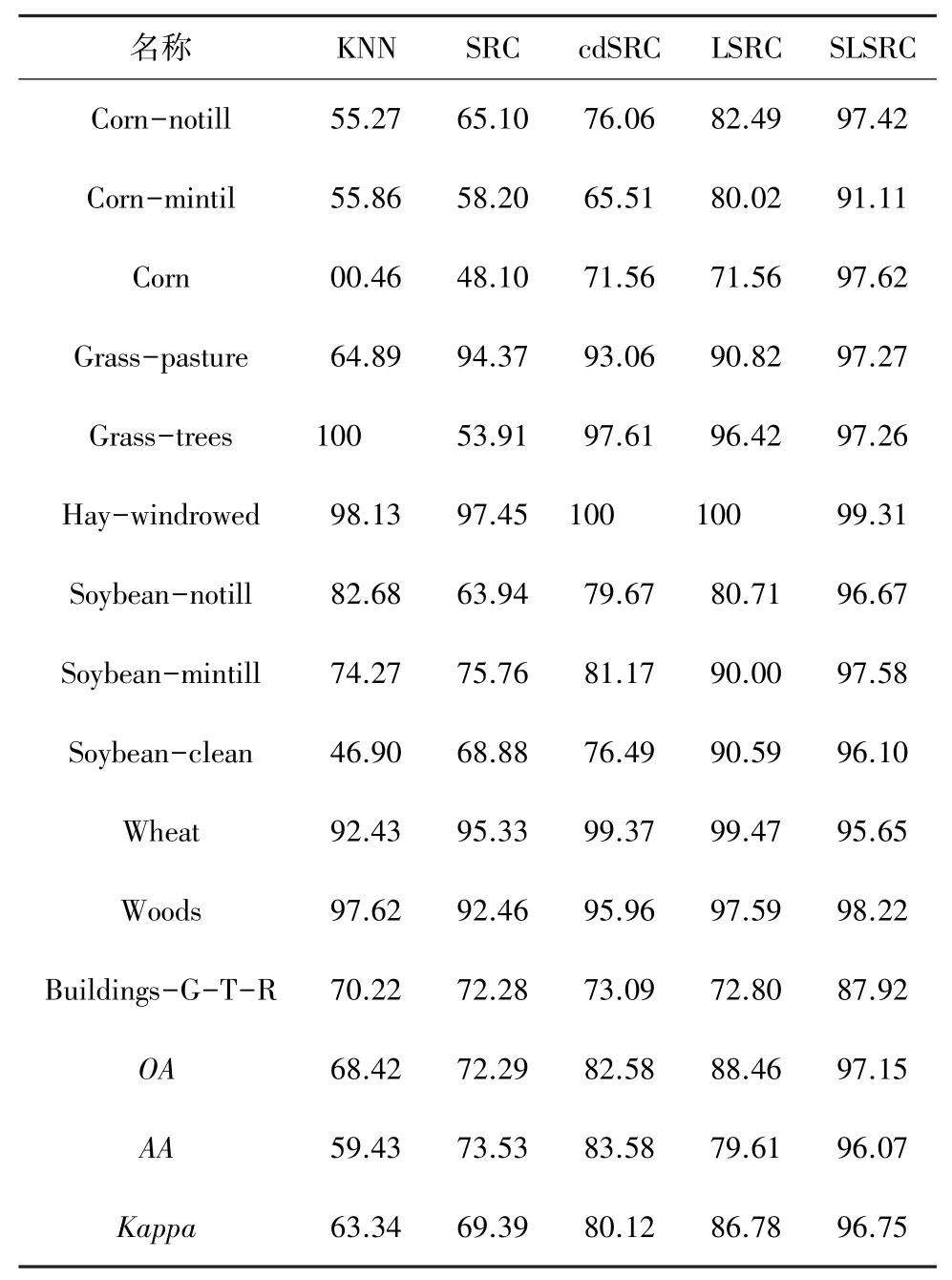
表2 Indian Pines数据集相关算法分类准确率Tab.2 Classification accuracy of Indian Pines dataset correlation algorithm
2.2 在Pavia University数据集上的实验结果
Pavia University数据集是由帕维亚大学通过反射光学系统成像光谱仪ROSIS采集的帕维亚大学的城市图像,各图像大小为610×340像素,每个像素的空间分辨率为1.3 m。ROSIS传感器在0.43至0.86μm的光谱范围内产生115个波段,为降低实验误差通常去除12个最嘈杂的频段将光谱带的数量降至103。图4中给出了Pavia University数据集三波段伪彩色图和真实地面图。由图4可知,该数据集包含9个真实类别,其中大多数基建材料,如沥青、砾石、裸土、彩绘金属板等。在实验中,根据论文通常对9类真实数据选取10%作为训练样本、总计3 921个,其余38 855个数据作为测试样本,具体样本划分见表3。
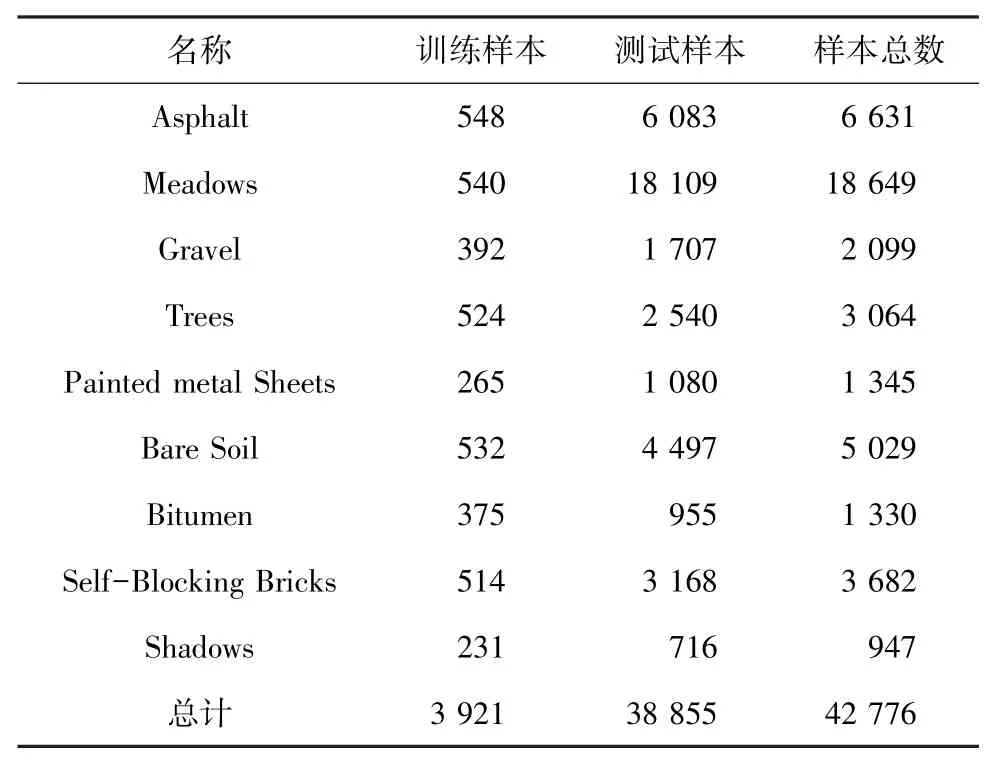
表3 Pavia University数据集样本信息Tab.3 Pavia University dataset sample information

图4 Pavia University数据集三波段伪彩色图和真实地面图Fig.4 Three band pseudo color map and real ground map of Pavia University dataset
表4展示了Pavia University数据集上不同算法的分类准确率,通过比较KNN、SRC、cdSRC、LSRC与本文提出算法、和系数可以很清楚地看到,本文算法具有最优的分类效果,相较于传统的KNN算法,总体准确率提高了约15%;相较于相对传统的cdSRC算法,总体准确率提高了大约13%;相较于较新的LSRC算法,总体准确率提高了大约9%。Pavia University数据集不同方法分类对照结果如图5所示。由图5可以清晰地看出,与对照算法相比,SLSRC算法的分类结果中噪音较少,类间结构清晰。

图5 Pavia University数据集不同方法分类对照图Fig.5 Comparison of different classification methods in Pavia University dataset
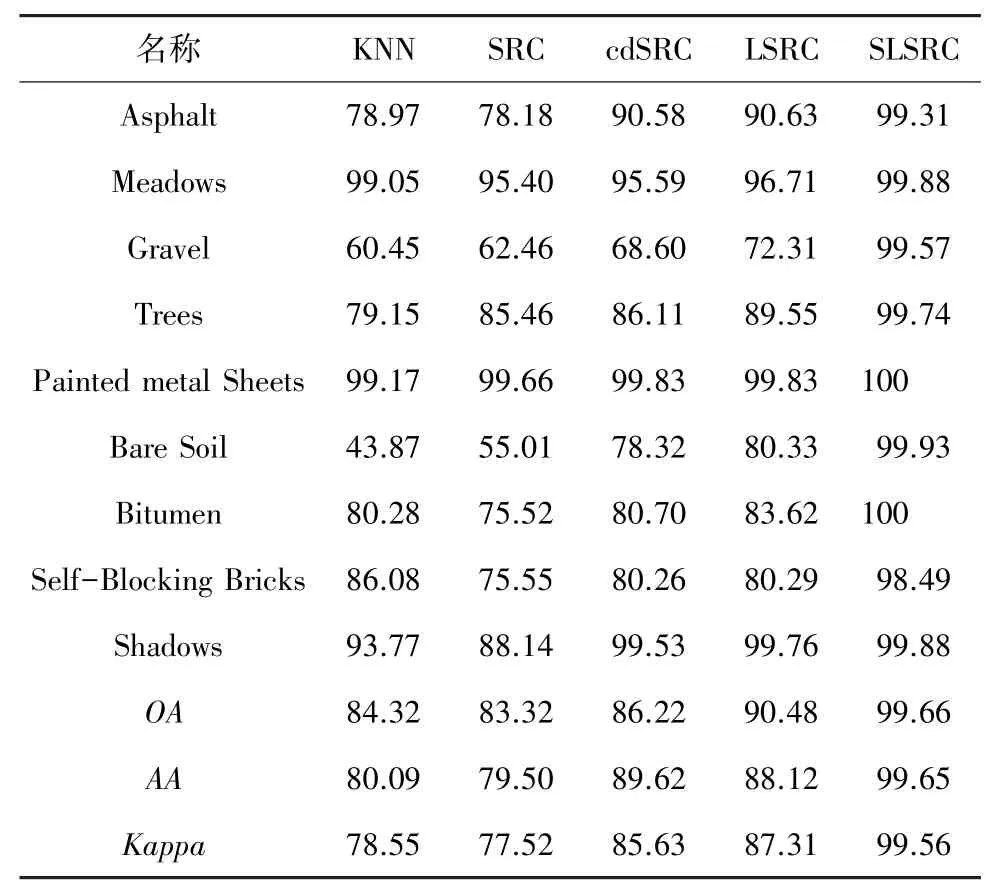
表4 Pavia University数据集相关算法分类准确率Tab.4 Classification accuracy of Pavia University dataset correlation algorithm
2.3 参数分析
在本节中,将分析参数如何影响SLSRC的性能。利用本文提出的SLSRC算法分类时,存在3个参数:稀疏度、近邻点个数和正则化参数影响实验结果。本文依据文献[18],固定和,采取控制变量法调整第三个参数,通过比较的值选取最优的参数。在Indian Pines数据集上,固定20,6,在Pavia University数据集上,固定20,6,分别在2个数据集上选取,如图6所示,给出2个实验的实验结果。
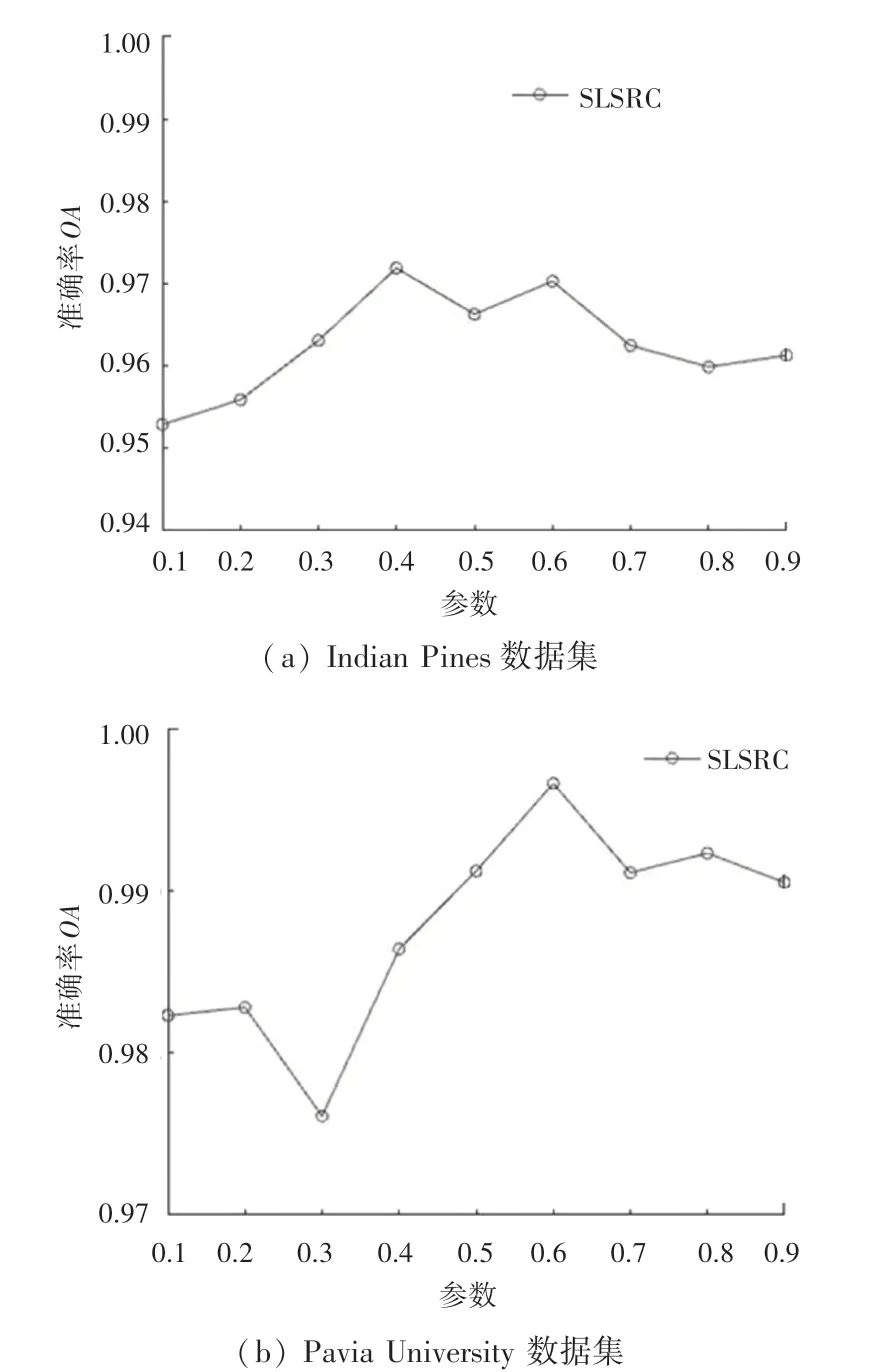
图6 不同参数取值在2个数据集对分类准确率的影响Fig.6 Influence of different parameter values on classification accuracy in two data sets
从图6可以看出,在Indian Pines数据集上当04时,取得最大值,即04时分类结果精度最高;在Pavia University数据集上当06时,取得最大值,即06时本算法的分类精度最高。本算法的性能可以通过改变参数进行调整。
2.4 训练样本选取的影响
为了验证KNN、SRC、cdSRC、LSRC以及本文算法在不同训练样本个数下的分类性能,分别在Indiana Pines和Pavia University两个数据集上进行实验。在Indian Pines和Pavia University数据集上都分别随机选取该类样本数的1%、2%、3%、4%、5%、6%、7%、8%、9%、10%作为训练样本,每类剩下的样本用作测试样本。将实验的总体分类准确度作为评价指标。实验结果如图7所示。
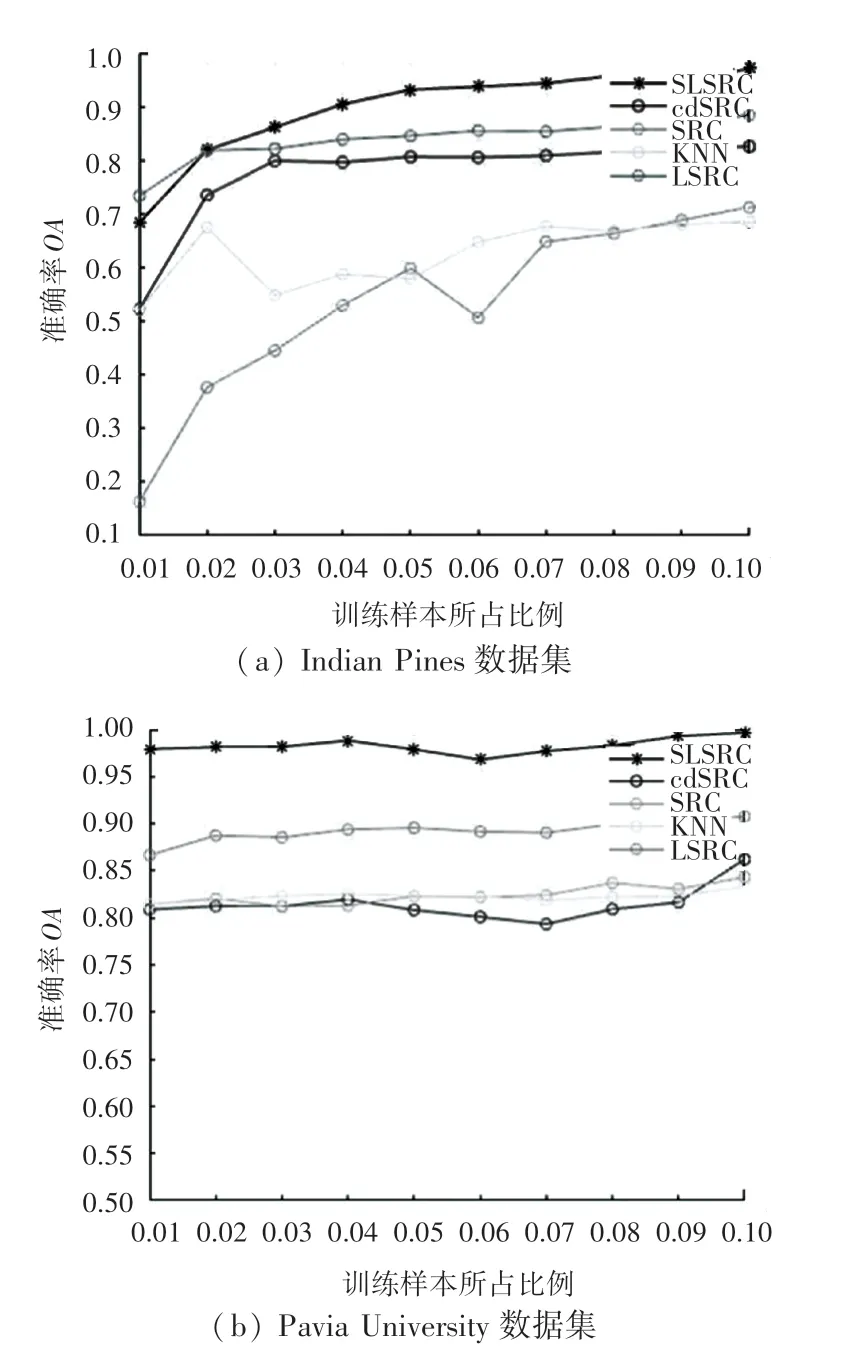
图7 相同训练样本个数下各种算法的分类准确率Fig.7 Classification accuracy of various algorithms under the same number of training samples
根据图7得出,在Indiana Pines和Pavia University两个数据集上选取总样本的1%~10%作为训练样本时,分类的准确率逐渐上升,其中,当训练样本占总样本的10%时准确率最高,故本文选取每类样本的10%作为训练样本,其余样本作为测试样本。由图7可以清晰地看出,从样本的1%~10%本文提出算法的准确率都明显高于经典的SRC算法、KNN算法和较为新颖的LSRC算法,再一次证明了本文算法的有效性。
3 结束语
本文提出了基于分层网络与局部约束的高光谱图像分类方法,首先利用分层深度网络提取高光谱图像的空谱特征信息,得到新数据集,然后计算原子间的欧氏距离,并根据K近邻算法选取前个距离最近的原子得出基于局部约束的字典,最后计算训练样本和测试样本间的相关系数,结合基于局部约束的字典与稀疏表示进行分类。选取2个高光谱数据集实验,由本文提出算法与KNN、SRC、cdSRC、LSRC算法的对比实验表明,本算法具有更优的分类性能。同时,在不同训练样本的选择下进行了分析对比,由此进一步验证了新算法具有更稳定、更好的分类性能。本算法主要论证了空谱信息结合在高光谱图像分类中的重要作用。在进一步的研究中,将针对局部约束字典的构建进行更深入的研究,更好地利用表示学习算法对高光谱图像进行分类。
