基于Spark的近实时增量数据更新方法
2022-04-27朱宏志任楚岚
◆朱宏志 任楚岚
基于Spark的近实时增量数据更新方法
◆朱宏志1,2任楚岚1,2
(1.沈阳化工大学计算机科学与技术学院 辽宁 110142;2.辽宁省化工过程工业智能化技术重点实验室 辽宁 110142)
增量数据更新是各个异构系统之间进行数据共享融合的关键,也是构建增量式数据仓库来进行数据分析的关键。随着大数据技术的发展,传统的增量更新算法已经无法适应时代的潮流。为此,本文基于Spark等成熟的大数据技术提出了一种近实时增量数据更新方法。本文采用OGG+kafka进行增量数据捕获,采用Spark对增量数据进行实时分析,设计Leader-Follower-Replicat模式提高方法可用性,设计Cross-Node模式实现跨节点断点续传。本文在四种应用场景下增量同步100万条数据,实验表明:该方法可适用于多种应用场景,该方法更新效率较高可以在5S内完成数据的同步,可以在4S内完成跨节点的断点续传。
增量更新;ETL;Spark;数据仓库
近年来,随着信息化的大力发展,越来越多的企业已经意识到了数据在决策支持方面的价值,数据驱动也越来越成为一种风潮[1]。这是因为通过数据分析、数据挖掘等手段,能够从数据中获取精准的业务状况和市场趋势[2]。为了创造更多的价值,规避更多的风险,以及更好地优化业务,数据仓库的构建和数据挖掘应用的构建就被提上了日程[3]。ETL是构建数据仓库的重要组成部分之一,它负责将异构数据导入DW中[4]。ETL分为全量抽取更新和增量抽取更新两种方式,全量抽取更新一般在建立DW最初期使用一次[5],除第一次外,数据的后续更新全部依赖于增量抽取。有研究表明,ETL的时间开销占据DW项目的60%-80%[6]。目前,随着时代的发展,实时分析、高可用、高鲁棒是增量数据更新领域的热点。
1 相关研究
传统的ETL增量更新的方式主要有以下五种:时间戳方式、触发器方式、日志方式、表对比方式、CDC方式。
时间戳方式需要源表中存在和时间戳相关的属性列,操作简单,适用于实时性要求不高的场合,但是需要由业务系统维护时间戳,当数据量较大的时候会浪费存储空间等问题。文献[2]改进了传统的时间戳方式,该文通过添加快照表、增加插入和更新两个时间戳字段来解决增量数据抽取操作效率低下、内存浪费的问题。文献[7]将时间戳方法与触发器方法结合,采用区段查询的方式,消除了传统时间戳方式破坏表结构的隐患。文献[8]通过设置时间窗口来控制时间戳的抽取,增强了鲁棒性,降低了系统异常对数据抽取的影响。
触发器方式一般要建立插入、修改、删除三个触发器,该方式优点在于数据抽取的性能高,ETL加载规则简单,不需要修改业务系统表结构,可以实现数据的递增加载。缺点在于对源表有侵入性,会产生严重的性能问题。文献[5]、文献[9]和文献[10]分别提供了在异构数据库和源端数据库中触发器出现异常的解决方案,文献[11]改进了触发器方式,将触发器方式与日志方式结合,为增量更新领域提供了新的思路。
基于表对比的方式会将源数据表中的所有记录同目标表中的所有记录进行比较,然后将识别出来的新增记录以及更新记录抽取出来,其优势在于对源系统无影响,但是这种方式一般情况下抽取性能较差,而且实时性很低。文献[18]优化了全表对比方式,将全表对比方式应用于分布式异构数据的增量抽取。
基于日志更新的方式首先需要建立日志表,然后编写代码去识别增量数据。这种方法的优点是无偏差传输,有回滚机制,有容灾备份的能力,实时性较高。缺点是异构数据库之间接口不统一,日志表维护需要由业务系统完成,浪费系统资源。文献[12]基于元数据提出了一种普适性的用户行为存储方案,解决了异构数据库接口不统一的问题,但是该方案的解耦性不高,映射规则较为麻烦。文献[13]基于ETL工具进行日志方式的增量更新,但是该方法仅适用于Oracle数据库的数据抽取。文献[14]提出一种通用的增量数据抽取模型,但该模型的可靠性不高。
CDC方式是一种新的实时数据集成方法,它识别并捕获数据源发生的变化,并仅将更改的数据传递给操作系统。文献[16]提出了一种近实时更新方法,更新时长在2分钟之内。文献[17]提出使用预聚合方法可以提升增量更新的速度。文献[18]基于时间戳方式和CDC方式提出一种自动增量更新方法。文献[19]总结了CDC方式所使用的架构,并且提出了PULL-CDC架构。文献[20]提出将ETL工具与CDC方式进行组合,该方法的应用场景更广泛、更新效率更高。
随着数据量的爆发式增长,以上算法大多不适用于生产环境。为此,本文提出一种由Oracle Golden Gate+Kafka+Spark组成的近实时增量数据更新方法。
2 基于Spark的近实时增量更新方法
本文提出的近实时增量更新方法的整体架构图如图1所示,主要分为增量数据抽取、增量数据更新两个阶段。

图1 近实时增量更新方法整体架构图
本方法主要完成了以下三方面工作:
(1)在数据捕获层面,捕获时延大大降低,应用场景更广泛。
(2)在数据处理方面,在对增量数据实时分析的同时也可以对增量数据进行数据清洗。
(3)具有高可用性和高鲁棒性。高可用性体现在:本文设计的Leader-Follower-Replicat模式,对集群资源进行调度,可以减少系统的停工时间。高鲁棒性体现在:本文设计的Cross-Node工作模式,可以在较短的时间内实现跨界点的断点续传。
2.1 增量数据抽取阶段
本阶段由OGG+Kafka组成,OGG负责增量数据的捕获和投递,Kafka则负责增量数据的临时存储。其中OGG又分为抽取组和同步组两部分。抽取组负责将不同数据源的增量数据抽取出来,同步组将转换后的数据传输至Kafka集群。
(1)不同数据源下OGG工作模式选择
OGG是一种实现主备数据库之间数据同步复制的软件,能够实现大量数据的实时捕获、路由、转换和交付,主要应用于容灾系统之间的数据同步[21]。OGG可以对多种不同的数据源进行数据捕获和同步。OGG的捕获&应用模式分为集成工作模式和非集成工作模式[22]。只有当源库为Oracle数据库时才可以使用集成工作模式。图2和图3分别为两种工作模式的原理图。
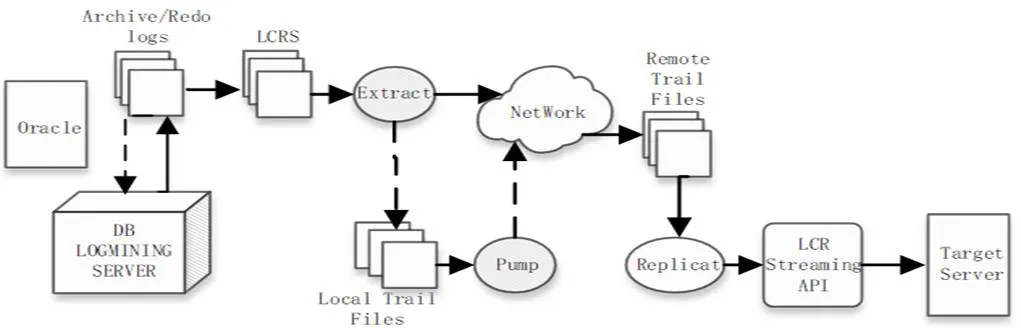
图2 集成模式工作原理图

图3 非集成模式工作原理图
从图2和图3中可以看出,集成模式和非集成模式有共同的工作流程:
①通过Extract组对源节点的日志文件进行增量捕获
②通过Pump组将本地Trail文件传输到目标节点的Replicat组。
③Replicat组通过数据处理接口将增量数据同步到目标库中。
二者的区别就在于是否将传数据转换为逻辑更改记录(Logical Change Record,LCR)。
本文为了统一数据传输标准,定义了通用的数据记录格式:通用更改记录(General Change Log,GCL)。图4列举了GCL中的字段。其中Table字段记录变化数据的源表名,Op_type字段记录该条数据的操作类型(增、删、改)。After Image记录数据的后镜像,Before Image记录数据的前镜像,Current_time记录OGG捕获该变化记录的时间,Primary_key记录主键。

图4 GCL格式图
(2)Leader-Follower-Replicat模式
Leader-Follower-Replicat模式的设计旨在提高系统的可用性。本模式通过调度集群机器来降低宕机产生的停工影响,从而增加了可用性。图5为Leader-follower-Replicat模式原理图,该模式增加了副节点Replicat集群,通过Leader-follower机制对集群进行调度,主节点Replicat组与副节点Replicat集群之间通过leader进行通讯。主节点只需将文件复制给Leader,由Leader负责集群之间的数据同步。

图5 Leader-Follower-Replicat模式原理图
Leader-Follower-Replicat的工作流程如图6所示。从图6可以看出该模式的具体工作流程:在Pump组工作之前,首先需要判断主节点Replicat组是否正常工作,如果正常工作,则立刻传输数据。如果主节点复制进程组出现故障,那么副节点Leader即刻承担主复制组的工作。如果副节点Leader也出现故障,此时完成数据同步的副节点Follower代替新Leader完成数据同步复制工作。

图6 Leader-Follower-Replicat工作流程图
2.2 增量数据更新阶段
增量数据的更新由Kafka+Structed Streaming组成,其中Kafka是特殊数据的临时通道,Structed Streaming负责近实时处理数据,数据的流向有实时更新和实时分析两个分支。Structed Streaming根据用户定义的清洗规则将增量数据进行清洗。清洗后的数据分别提供给分析系统和目标数据库。
图7为Structed Streaming数据处理原理图。从图中可以看出,Structed Streaming对Dataset内的数据进行处理。Dataset的数据来源有两个,第一个源是Dstream,第二个源是目标端数据库。原始Dataset经过User Filter清洗后,一部分被封装为SQL Dataset,另一部分被封装为Processing Dataset,最后流向两个不同分支。

图7 Structed Streaming数据处理原理图
2.3 Cross-Node断点续传工作模式
Cross-Node断点续传工作模式的设计旨在提高系统的可靠性。本模式可以在主复制节点出现问题时,启动其他节点来继续进行增量数据的更新工作。Leader-Follower-Replicat模式为本模式指派更新节点以及相关文件。
Cross-Node断点续传模式的工作模式如图8所示。从图中可以看出Cross-Node断点续传工作模式的原理如下:当CheckNode节点启动时,故障检测脚本check detection script定期运行,该脚本会检查主复制节点的运行情况,如果主复制节点break,那么读取nextnode.txt文件获取nextnode。随后,停止抽取节点的Pump进程,更新Pump配置文件,然后重新启动抽取节点的Pump进程组。最后,更新currentnode.txt以及nextnode.txt文件,为下一次主复制节点宕机做准备。

图8 Cross-Node断点续传工作模式图
3 实验部分
3.1 实验环境配置
本实验的环境搭建在虚拟机环境中。主机配置如下:CPU为AMD Ryzen 7 4800H with Radeon Graphics 2.90 GHz,内存128 GB,操作系统为Windos 10专业工作站版,实验环境网络为百兆光纤,实验环境为7台虚拟机组成的集群,操作系统均为CentOS 7.6,内存设置除Node07为16 GB外,其余虚拟机均为8 GB,所有虚拟机外存配置均为80 GB。
表1为虚拟机的软件环境配置表。从表1中可以得知:Node01、Node02、Node03为Hadoop集群、Spark集群、kafka集群和clickhouse集群。Node04节点和Node05节点作为复制副节点Follower。Node06作为调度节点存在。Node07是DataSource节点,配置了Oracle数据库以及Mysql数据库两个数据库作为数据源。
表1 虚拟机的软件配置表
节点软件配置 Node01Hadoop;Zookeeper;Kafka;Spark;Hive;Mysql;ClickHouse Node02Hadoop,Zookeeper,Kafka,Spark;OGG for big data,ClickHouse Node03Hadoop;Zookeeper;Kafka;Spark;ClickHouse Node04OGG for big data Node05OGG for big data Node06无 Node07Oracle 19c;OGG for Oracle;Mysql;OGG for mysql
3.2 实验结果
在增量数据更新算法中,时间开销一般作为算法好坏的评估标准。本实验中,时间开销T由三部分组成:
第一部分为捕获时长Tcapture,该时长为数据改动时间戳与捕获改动时间戳的差值。
第二部分为传输时长Ttransmit_otk+unit(Ttransmit_kts),该时长为OGG、kafka、Structed Streaming三个组件的通讯时长之和,unit(Ttransmit_kts)为kafka对接Spark的通讯时长与批处理时间窗口长度的比值。
第三部分为数据处理时长,该时长为数据清洗、数据转换、数据更新的时间总开销。
本实验模拟某连锁书店管理系统设计了一个小型的DW,如图9所示。该DW系统有一个事实表,三个维度表。书店事实表记录三个维度表的主键还有一些销售的备注信息。时间维度表记录书籍出售的年份、月份、日期,该时间维度表的设计便于统计年销量、月销量和日销量。书籍维度表简单记录书的名字、书的价格、书的种类三个属性,该书籍维度表的设计便于统计各个分书店不同种类、不同价格、不同系列的书籍销量。地点维度表简单记录了该分店所在城市、所在地区,以及店铺规格,以便于分析店铺所在地点以及店铺规格对于图书销量的影响。

图9 书店DW系统
在本实验中,在四种不同的应用场景下,每张表各同步25万条数据,实验数据共计100万条。四种应用场景如表2所示,实验结果如表3所示。
表2 实验场景配置表
场景序号源库目的库数据量/条batch_time 1OracleHive100万3S 2OracleClickHouse100万3S 3MysqlHive100万3S 4MysqlClickHouse100万3S
表3 实验结果表
场景序号操作类型平均净时长T/ms 1I/D/U4175 2I/D/U3873 3I/D/U4512 4I/D/U4039
表2为实验场景的具体配置,本实验采取两种主流的事务数据库作为源库,采取两种主流的大数据仓库作为目标库,批处理窗口为设置为3 S,增量同步100万条数据。表5为实验的结果表。从表5中可以看出,本方法针对不同数据源和目的源都有着较高的效率,平均时间开销在5S以内。
本文关于跨节点断点续传性能测试的实验步骤如下:
(1)将表2所示的实验场景1作为基础的应用场景,将增量传输的数据量增加为1亿条,启动增量同步进程。
(2)增量同步进程运行10 S时,关闭复制组集群的节点,让增量数据同步进程停止运行。
(3)一分钟后,查看Node04节点和Node05节点的OGG运行日志以及Hive数据库的数据变化情况。
本文根据以上步骤做了多次实验,通过实验得出:本方法跨节点断点续传数据的平均时间开销在3S以内。
4 结语
本文基于数据容灾备份工具OGG、大数据处理框架Spark、分布式消息队列Kafka设计了一个近实时增量数据更新方法。它的优点在于:应用场景广泛,可以支持多种数据源和目标源;实时性强,可实时分析数据、实时清洗数据;可用性高,可以减少停工时间;鲁棒性强,可以在较短时间内实现跨节点的断点续传。但是本实验也有一些不足,当数据规模较大时,Leader-Follower-Replicat工作模式和Cross-node工作模式的磁盘I/O开销会增加,本文的未来研究方向在于如何提高数据更新的速度,如何减小资源开销。
[1]孙琳.利用商业智能技术对多系统的数据整合研究分析[J].中小企业管理与科技(中旬刊),2016(02):236.
[2]Naimi A I,Westreich D J. Big data:A revolution that will transform how we live,work,and think[J]. Computer Science,2014.
[3]袁汉宁,王树良,程永,等. 数据仓库与数据挖掘[M].人民邮电出版社:2015(7):208.
[4]Eckerson W,White C. Evaluating ETL and data integration platforms[J]. Report of The Data Warehousing Institute, 2003,184.
[5]舒琦. ETL过程优化与增量数据抽取的研究[D].湖南大学,2011.
[6]徐俊刚,裴莹.数据ETL研究综述[J].计算机科学,2011,38(04):15-20.
[7]温璐. 基于区段查询的增量数据抽取器的设计与实现[D].河北科技大学,2015.
[8]刘杰,王桂玲,左小将.基于可变时间窗口的增量数据抽取模型[J].计算机科学,2018,45(11):204-209+230.
[9]郭树盛,唐素芳,徐志伟. 一种基于触发器的异构关系型数据库间增量数据迁移方法[P]. 广东省:CN104598531B,2019-05-07.
[10]付铨,梅纲,胡高坤. 一种源端并发导致触发器增量同步异常的处理方法[P]. 湖北省:CN111159208A,2020-05-15.
[11]Wang Y B,Rao X R,He P. Incremental database synchronization update mechanism under heterogeneous environment[J]. Computer Engineering and Design,2011,32(3): 948-951.
[12]杨弈. 分布式环境下元数据驱动增量ETL的设计与实现[D].东南大学,2017.
[13]沈一通. 基于oracle日志挖掘的增量同步方案的设计[J].数码世界,2017(06):156-157.
[14]彭远浩,潘久辉.基于日志分析的增量数据捕获方法研究[J].计算机工程,2015,41(06):56-60+65.
[15]贾艳凯. 多源异构增量数据抽取方法研究与设计[D].哈尔滨工程大学,2013.
[16]谭光玮,武彤.基于CDC机制的数据仓库实时数据更新方法研究[J].计算机科学,2015,42(S1):546-548.
[17]Tank D M,Ganatra A,Kosta Y P,et al. Speeding ETL processing in data warehouses using high-performance joins for Changed Data Capture (CDC)[C]//2010 International Conference on Advances in Recent Technologies in Communication and Computing. IEEE,2010:365-368.
[18]THULASIRAM S,RAMAIAH N. Real Time Data Warehouse Updates Through Extraction-Transformation-Loading Process Using Change Data Capture Method,Cham,F,2020 [C]. Springer International Publishing.
[19]ECCLES M. Pragmatic development of service based real-time change data capture [D]. Aston University,2013.
[20]BISWAS N,SARKAR A,MONDAL K C. Efficient incremental loading in ETL processing for real-time data integration [J]. Innovations in Systems and Software Engineering, 2020,16(1):53-61.
[21]宰旭昕,康凯,许广文. Oracle GoldenGate+DXP技术实现关键业务系统容灾的解决方案 [J]. 通信技术,2020,53(10):2501-9.
[22]GUPTA R. Mastering Oracle GoldenGate [M]. Apress, 2016.
