基于机器学习的非线性局部Lyapunov 向量集合预报订正*
2022-04-27康俊锋冯松江邹倩李艳杰丁瑞强钟权加
康俊锋 冯松江 邹倩 李艳杰 丁瑞强 钟权加†
1) (江西理工大学土木与测绘工程学院,赣州 341000)
2) (中国科学院大气物理研究所,大气科学和地球流体力学数值模拟国家重点实验室,北京 100029)
3) (北京师范大学,地表过程与资源生态国家重点实验室,北京 100875)
4) (中国科学院大学地球科学学院,北京 100049)
基于Lorenz96 模型初步探讨了机器学习算法提高非线性局部Lyapunov 向量(NLLV)集合预报效果的可行性和有效性.结果表明:基于岭回归算法和NLLV 集合预报结果建立的机器学习模型(Ens-ML)能够有效提高整体预报技巧,而且优于集合平均预报(EnsAve)、控制预报(Ctrl)以及基于Ctrl 结果建立的机器学习模型(Ctrl-ML).同时,还发现Ens-ML 的预报技巧改进程度依赖于集合成员的数量,即增加集合成员数有助于提高Ens-ML 模型的整体预报准确率.通过对比个例预报表现得到,随着预报时间延长,Ens-ML,Ctrl-ML和EnsAve 的个例预报误差逐渐小于Ctrl.进一步分析Ens-ML,Ctrl-ML 和EnsAve 预报的吸引子,发现它们的概率分布的值域收缩、峰度增大并向平均值靠拢,尤其Ens-ML 的表现更为明显.
1 引言
近几十年来,得益于计算机硬件的快速发展、数值模式和资料同化技术的研发和应用,数值预报取得了长足的进步,提升了天气预报和气候预测的准确率.然而,大气作为一个具有混沌特性的非线性系统,其预报结果存在一定的不确定性[1].最早,Leith[2]和Epstein[3]提出了集合预报的思想和方法来应对数值预报中的不确定性问题,其基本思路是在初始状态上叠加一组扰动生成初始集合,并分别积分各个初始成员得到一组预报结果的集合.一方面,集合平均的非线性滤波作用可以过滤不可预报的噪音,保留可预报的有用信息;另一方面,根据集合成员的预报结果可获得概率预报.自20 世纪90 年代以来,集合预报在天气预报与气候预测领域得到了广泛的研究和应用,众多研究和业务应用的结果都表明集合预报是减小预报不确定性、提高预报水平的有效途径[4−6].
针对数值预报中的初值不确定性和模式本身的不确定性,前人相应发展了初值扰动和模式物理扰动以及多模式集合预报方法[7].假设在模式完美情况下,初始集合生成的关键是如何产生能够很好描述初始状态不确定性的扰动场.为此,国内外学者相继发展了多种初值集合生成方法,代表性的包括繁殖向量(BV)[8,9]、奇异向量(SV)[10]和集合卡尔曼滤波(EnKF)[11,12]方法.其中,BV 和SV 方法发展较为成熟,它们都是基于误差增长动力学理论发展起来的方法,主要通过抓住增长的扰动结构和演变来反映数值预报误差的不确定性.尽管BV和SV 方法在业务上得到较好的应用,但仍存在一定的不足.例如,SV 方法基于线性误差增长理论,具有线性约束的局限性,不能很好地描述误差非线性增长特征.为此,Duan 和Huo[13]发展了CNOP 方法来表征误差的非线性增长模态.与SV 和CNOP方法相比,BV 方法无需复杂的切线性和伴随模式,计算非常简便和省时.但是BV 扰动是在动力系统中相同的基流演化得到,导致产生的初始扰动结构较为相似,独立性不足[14].考虑BV 方法的优点和不足,最近我国学者提出了非线性局部Lyapunov向量(NLLV)[15,16]集合预报新方法,该方法利用和BV 方法类似的简便的繁殖思想生成扰动,能够很好地抓住非线性动力系统中的增长误差结构,同时又通过正交化弥补BV 方法产生的扰动结构依赖性较强的不足,有助于进一步提升集合初值扰动的产生质量.
近年来,随着大数据科学的发展,越来越多的研究将机器学习算法和人工智能技术应用于挖掘海量的气象数据信息并加以利用,以提高天气预报和气候预测的准确率[17−19].一方面,既有利用单一数值模式的不同气象要素构建预报预测模型,例如,利用机器学习中的随机森林算法构建短时地面风场预报模型,能够有效预报地面1—6 h 风场变化[20];另一方面,也有基于单个数值模式集合预报结果或者多模式的集合预报结果,结合机器学习算法建立集合预报机器学习模型,从而达到提高预报预测准确率的目的.比如,通过机器学习算法对华北气温的多模式集合预报结果进行建模订正,其订正效果明显优于数值模式的单一预报和多模式的集合平均[21].此外,也有学者基于深度学习模型构建了长期气候预测模型,实现了对ENSO 的有效预测[22].
鉴于NLLV 是一种新的集合预报方法,具有一定的理论创新性,同时机器学习方法又在气象领域具有广阔的应用前景.因此,本文将基于简单的Lorenz96 模型开展集合预报试验,然后结合机器学习算法分别利用NLLV 的集合预报和单一控制预报建立机器学习模型,并从整体预报效果、不同个例预报误差大小、吸引子概率分布以及集合成员个数的使用等多个不同角度探讨机器学习算法和NLLV 集合预报相结合的可行性和有效性.
2 数据与方法
2.1 Lorenz96 模型简介与试验设计
Lorenz96 模型具有对初值极端敏感性和非线性的特点,能够作为大气系统的低阶近似,广泛应用于大气可预报性和集合预报研究[15,23],该模型动力方程组可表示为
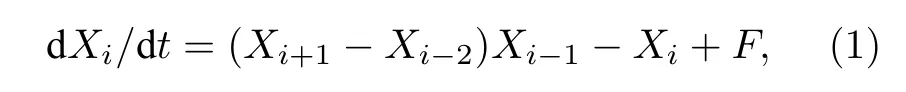
其中,Xi(i=1,2,···,40)为模型状态变量,定常强迫项F=8,数值积分采用四阶龙格-库塔格式,积分步长为0.05 时间单位(tus).在Lorenz96 模型的混沌吸引子上每间隔0.05 tus 选取一个状态作为集合预报试验的初始态,本研究共选取了10000个初始态作为集合预报个例,每个个例的积分步数为41.在Lorenz96 模型中每间隔0.2 tus 大致对应1 d[24].因此,积分41 步共为2.05 tus,大致对应10 d.
2.2 NLLV 方法简介及其产生初始集合扰动的流程
NLLV 是一种生成集合预报初始扰动的新方法[15,16],该方法产生的初始集合成员NLLVs 具有正交性、独立性以及流依赖性等特点.因此,它们既能够描述不同方向的误差增长率,还能够很好地反映误差结构随天气、气候等混沌系统时空演化的特征[25].基于上述优势,NLLV 方法逐渐应用于Lorenz 模型、准地转正压模式、中等复杂程度的ENSO 动力耦合模式(Zebiak-Cane 模式)以及新一代中尺度数值模式(WRF 模式)的集合预报研究,并发现其能够有效地提高预报技巧[15,26,27].NLLV 方法产生扰动制作集合预报的流程如图1所示,当NLLV 繁殖开始时,将一组初始随机扰动添加到分析状态上进行积分,再对积分的结果进行正交化处理并尺度化至初始扰动大小,然后又将其叠加到新的分析状态上,经过多个繁殖循环得到NLLVs.参考Feng 等[15]的研究,当集合成员达到一定数量时,使用更多的成员也只能有限地提高预报技巧,因此本研究使用NLLV 方法共生成6 个集合成员.
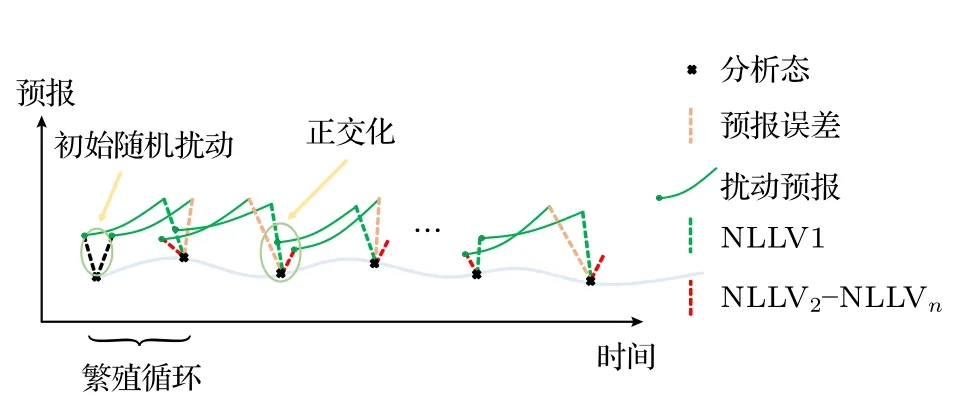
图1 NLLVs 扰动生成示意图[15]Fig.1.Schematic diagram of the generation of NLLVs[15] .
2.3 机器学习方法与其建模流程
岭回归属于多元线性回归方法的一种,其在最小二乘法的基础上改进而来,能够很好地解决多重共线性数据集的回归问题[28,29].考虑到本研究的NLLV 集合预报试验数据集中各预报成员之间呈现强相关性,具有显著的共线性特征(图2),所以将该方法作为构建机器学习模型的算法.在岭回归模型的构建过程中将预报成员作为特征变量xi(i=1,2,3,···,7),其模型框架可表示为
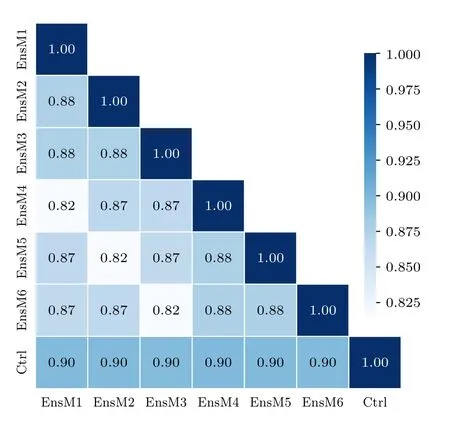
图2 各集合成员间的相关系数矩阵Fig.2.Correlation coefficient matrix of ensemble members.

即
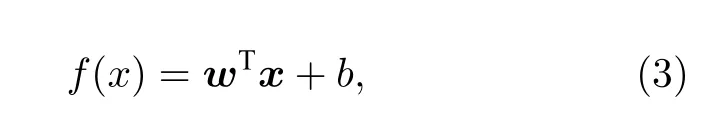
模型的损失函数为
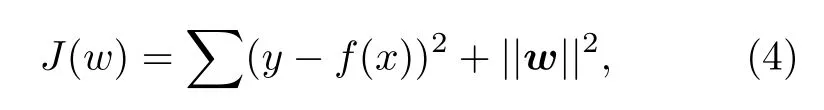
其中wi为特征变量的回归系数,b为偏置,y为真值,λ为正则项系数;w和x分别是wi和xi的矩阵.用梯度下降算法对损失函数求最小解可得w和b,确定岭回归模型.
图3 给出了机器学习的建模流程.首先,对集合成员进行标准化预处理;然后,将集合预报试验的控制预报成员(Control,Ctrl)作为特征变量,真值作为目标变量,建立基于控制预报的机器学习模型(Control machine learning,Ctrl-ML);接着,将集合预报试验的集合成员作为特征变量,真值作为目标变量,建立基于集合成员的机器学习模型(Ensemble machine learning,Ens-ML);上述建模过程还需要分别将两个模型的数据集划分为训练集和测试集,其中训练集占70% (7000 个),测试集占30% (3000 个).接着,分别对上述两个模型进行训练、测试,在训练模型时将其迭代次数参数“max_iter”设置为None,模型将自动寻得最优迭代次数,正则项系数“alpha”为1.0.最后,对模型的测试结果进行评估并输出,评估方法见2.4 节.
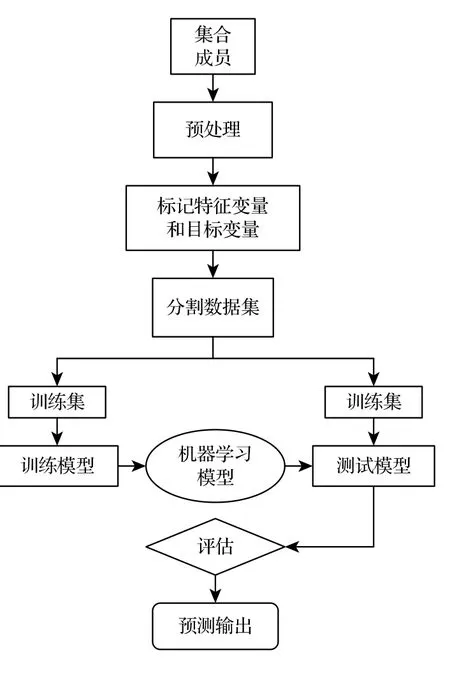
图3 机器学习模型构建流程图Fig.3.Process of machine learning.
2.4 预报试验评估方法
通过对所有集合成员做算术平均,得到集合平均预报(ensemble average,EnsAve).即
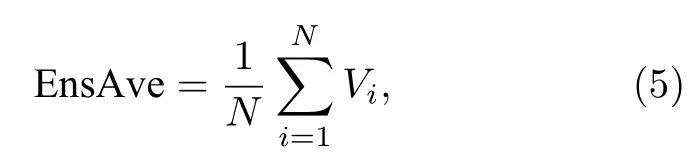
其中,Vi代表集合成员的值,N代表集合成员个数.
此外,为了从不同角度来综合评估不同方法的预报表现,本文主要使用了可决系数(R²)、平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)和型异常相关系数(PAC)等预报评估方法[30,31].
3 结果与分析
3.1 订正结果分析
图4 给出了一组不同预报方法下Lorenz96 模型X变量的预报时间序列,可以发现4 种方法在不同的预报时段各有优劣.在预报初始时刻0—5 tus 时,Ctrl 和EnsAve 的效果优于Ctrl-ML 和Ens-ML;在预报中期20—28 tus,Ctrl 和Ctrl-ML 的预报值最接近真值,Ens-ML 和EnsAve 则略逊;但是在31 tus 时的波峰处,Ctrl 试验的结果却是误差最大的;到后期35—40 tus 时,EnsAve和Ens-ML 的预报结果明显优于Ctrl 和Ctrl-ML.通过R²和MAE 等评价指标从整体表现来看,Ens-ML的R²最大,MAE 和RMSE 最小,表明Ens-ML 的整体预报技巧是最高的,EnsAve 次之,Ctrl 的预报技巧最差(见表1).
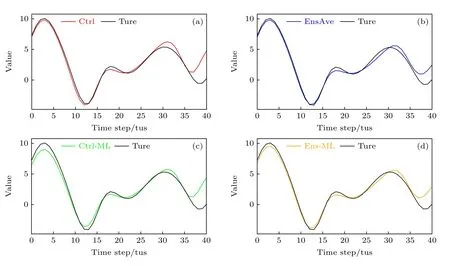
图4 不同预报方法下Lorenz96 模型的X 变量时间序列 (a) Ctrl;(b) EnsAve;(c) Ctrl-ML;(d) Ens-ML(黑线为真值的时间序列)Fig.4.The time series of X variable of Lorenz96 model for different forecast methods:(a) Ctrl;(b) EnsAve;(c) Ctrl-ML;(d) Ens-ML.Black line represents time series of true values.
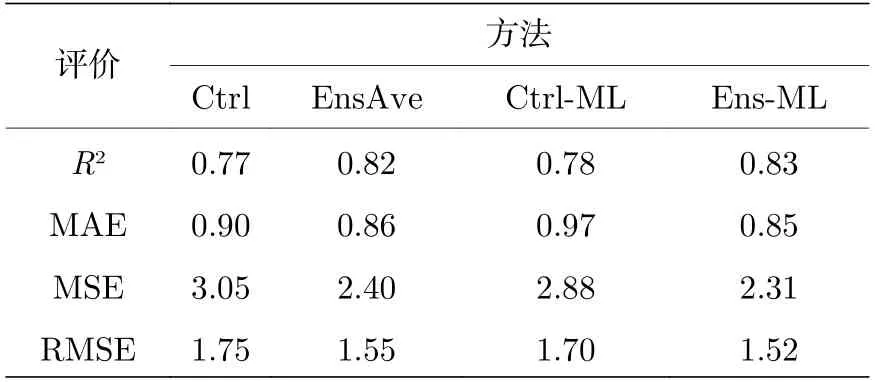
表1 不同预报方法的预报结果比较Table 1.Evaluation of forecast results in different forecasting methods.
如图5(a)所示,由于两个机器学习模型均在预报初期出现过拟合现象,从而导致其平均RMSE大于Ctrl 和EnsAve 预报.然而,随着预报时间的延长,Ctrl-ML 和Ens-ML 的RMSE 逐渐分别小于Ctrl 和EnsAve 的误差,尤其是Ens-ML 表现最好.此外,根据预报序列与真值的PAC 可以发现,Ens-ML 优 于EnsAve,而Ctrl-ML 与Ctrl 的PAC 曲线重合,这可能是在Ctrl-ML 机器学习模型中,只有Ctrl 作为其特征变量,Ctrl-ML 只能学习到Ctrl 的模式信息,导致它们的PAC 与真值的相关性较为一致.但是,Ens-ML 则能综合多个集合成员的信息,使得最后效果优于EnsAve (图5(b)).进一步比较3 种不同方法相对于Ctrl 的改进程度可以发现,虽然两个机器学习模型在预报初期预报误差偏大,提升比例为负(图6),但是,随着时间的演变EnsAve,Ctrl-ML 和Ens-ML 的预报误差逐渐小于Ctrl,改进程度逐渐提高,直到最后Ens-ML 提升比例最高可达3%以上,EnsAve 次之,Ctrl-ML 提升最小.上述结果表明,机器学习对集合预报和控制预报的整体性能是有提高作用的,并且以集合成员为特征建立的机器学习模型明显优于基于单一控制预报试验建立的机器学习模型.
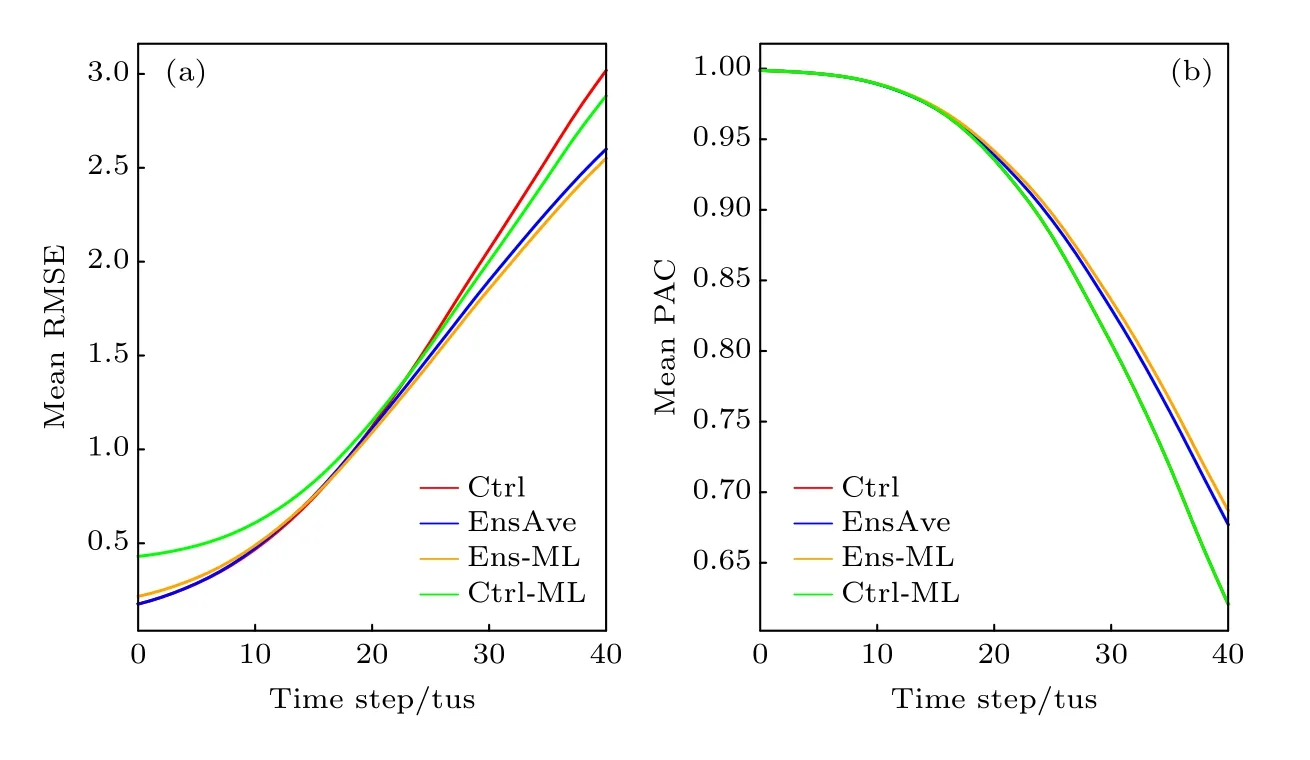
图5 不同预报方法得到的平均RMSE (a)和平均PAC (b)随时间步长的变化Fig.5.The average RMSE (a) and average PAC (b) for different forecast methods.
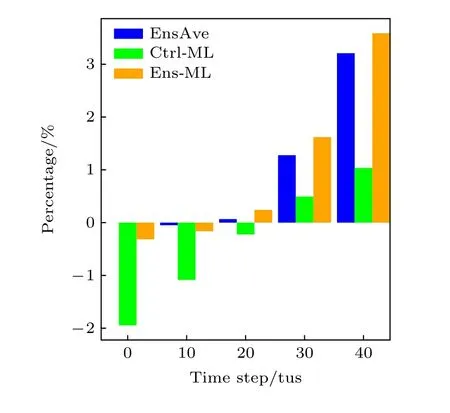
图6 EnsAve,Ens-ML,Ctrl-ML 相对于Ctrl 预报的改进程度Fig.6.The improvement of the EnsAve,Ens-ML and Ctrl-ML compared to Ctrl.
图7 给出了不同预报方法的误差概率分布,可以看出Ens-ML 相比EnsAve 略微提高了误差在[0,2.5]区间的分布概率,降低了在[2.5,4.5]区间的概率,在高误差区间[4.5,6]与EnsAve 基本保持一致.Ctrl-ML 相比Ctrl 则更加明显,显著提高了[1,3]区间的误差概率,降低了[3,6]区间的误差概率.此外,根据图8 可以发现机器学习模型的预报效果与集合成员的数量有重要联系.在Ens-ML 模型中,预报结果与真值的R²随着集合成员的增加而增大.这意味着机器学习依赖NLLV 的集合成员,集合成员的增加能够显著提高模型的预报准确度.这一结果也间接解释了Ctrl-ML 模型预报效果明显不如Ens-ML 的原因.相对于Ctrl试验单一成员,集合成员更能够反映出大气系统的不确定性状态.集合成员的增加能够给机器学习模型提供更多的大气特征信息,从而提高模型的预报精度.综上所述,整体来看机器学习模型提高了误差在低值区的概率,降低了高值区的概率,有助于提升整体预报效果,并且集合成员数量对机器学习模型的效果起着至关重要的影响.
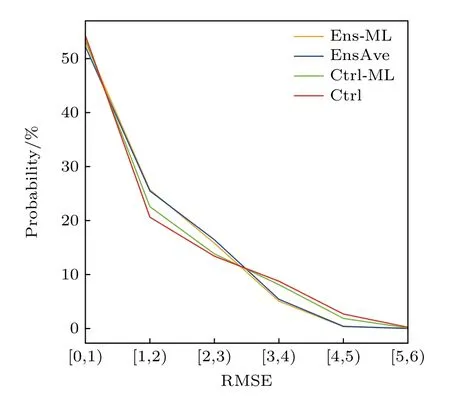
图7 不同预报方法的误差概率分布Fig.7.The probability distribution of forecast errors for different methods.
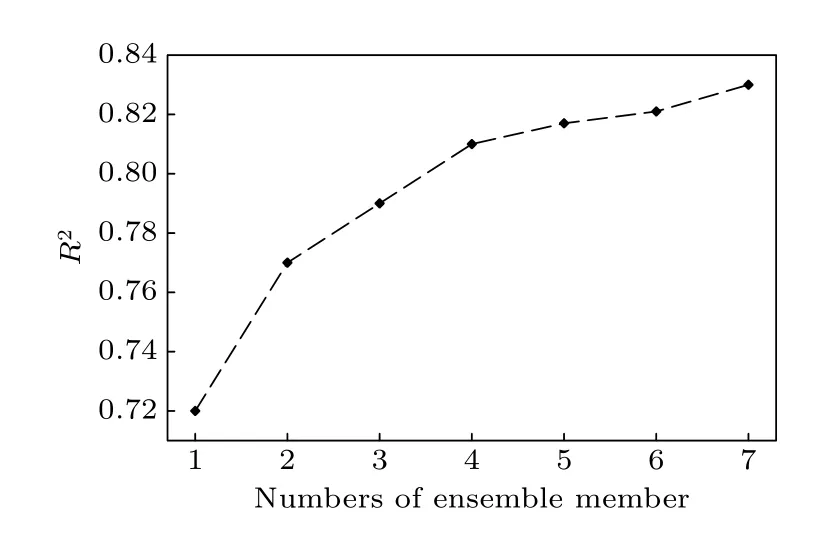
图8 Ens-ML 模型的R² 随集合成员数的变化Fig.8.Changes of the R² with the number of ensemble member used in the Ens-ML model.
3.2 个例表现与吸引子概率分布特征
前人的研究曾指出集合平均预报整体预报技巧优于单一控制预报,但也存在一定比例的个例其单一控制预报优于集合预报[23].下文将进一步比较EnsAve,Ens-ML,Ctrl-ML 模型与Ctrl 单一控制预报在3000 个测试个例中的预报误差大小.
在试验初期0 tus 时,EnsAve 和Ens-ML 的试验个例与Ctrl 的试验个例主要集中在对角线附近,说明初期时这3 种方法的个例误差大小相当(图9(a),(b),(c)).随着预报时间的延长,大多数个例的EnsAve 和Ens-ML 模型误差小于Ctrl,该结果与前人研究一致.除此之外,由于Ctrl-ML 模型的构建过程使用的特征变量只有Ctrl 成员,使得机器学习算法在对其训练过程中只有单一特征信息与真值对应学习,导致与Ctrl 自身个例的对比中整体呈现出线性变化趋势.
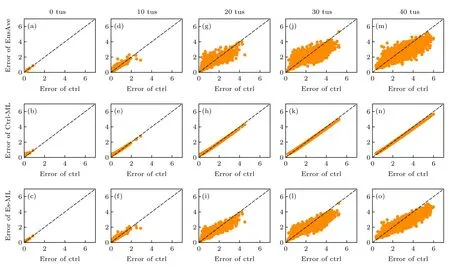
图9 试验个例在不同时刻的EnsAve,Ctrl-ML 和Ens-ML 与Ctrl 的预报误差 (a)—(c) 0 tus;(d)—(f) 10 tus;(g)—(i) 20 tus;(j)—(l) 30 tus;(m)—(o) 40 tusFig.9.Scatterplot of forecast error at different leading times between the EnsAve,Ctrl-ML,Ens-ML and the Ctrl,respectively:(a)–(c) 0 tus;(d)–(f) 10 tus;(g)–(i) 20 tus;(j)–(l) 30 tus;(m)–(o) 40 tus .
Lorenz96 模型中吸引子的概率分布可以揭示系统变量在演化过程中的状态特征,图10 给出了3000 测试个例采用4 种不同预报方法在整个预报周期中Lorenz96 模型的X变量的概率分布.由此可以看出,Ens-ML,Ctrl-ML 的概率分布趋向与真值是一致的,这表明本试验建立的机器学习模型是可靠的,吸引子的系统演化轨迹是基本不变的.随着预报时间的延长,不同时刻Lorenz96 模型X变量的概率分布总体上分布一致,但EnsAve,Ens-ML 和Ctrl-ML 三种方法的概率分布逐渐向中间均值部分收缩,左右分布概率降低,值域变窄,峰度值越来越大,Ctrl 则始终与真值基本保持一致.其中Ens-ML 和EnsAve 的值域收缩最为明显,Ctrl-ML 相较于Ctrl 收缩程度大.这说明机器学习模型在训练学习过程中,有着同集合预报一样偏向平均态的特征且比EnsAve 效果更好,从而提高了预报技巧,但左右极值分布概率的降低意味对极端事件的预报技巧是下降的.
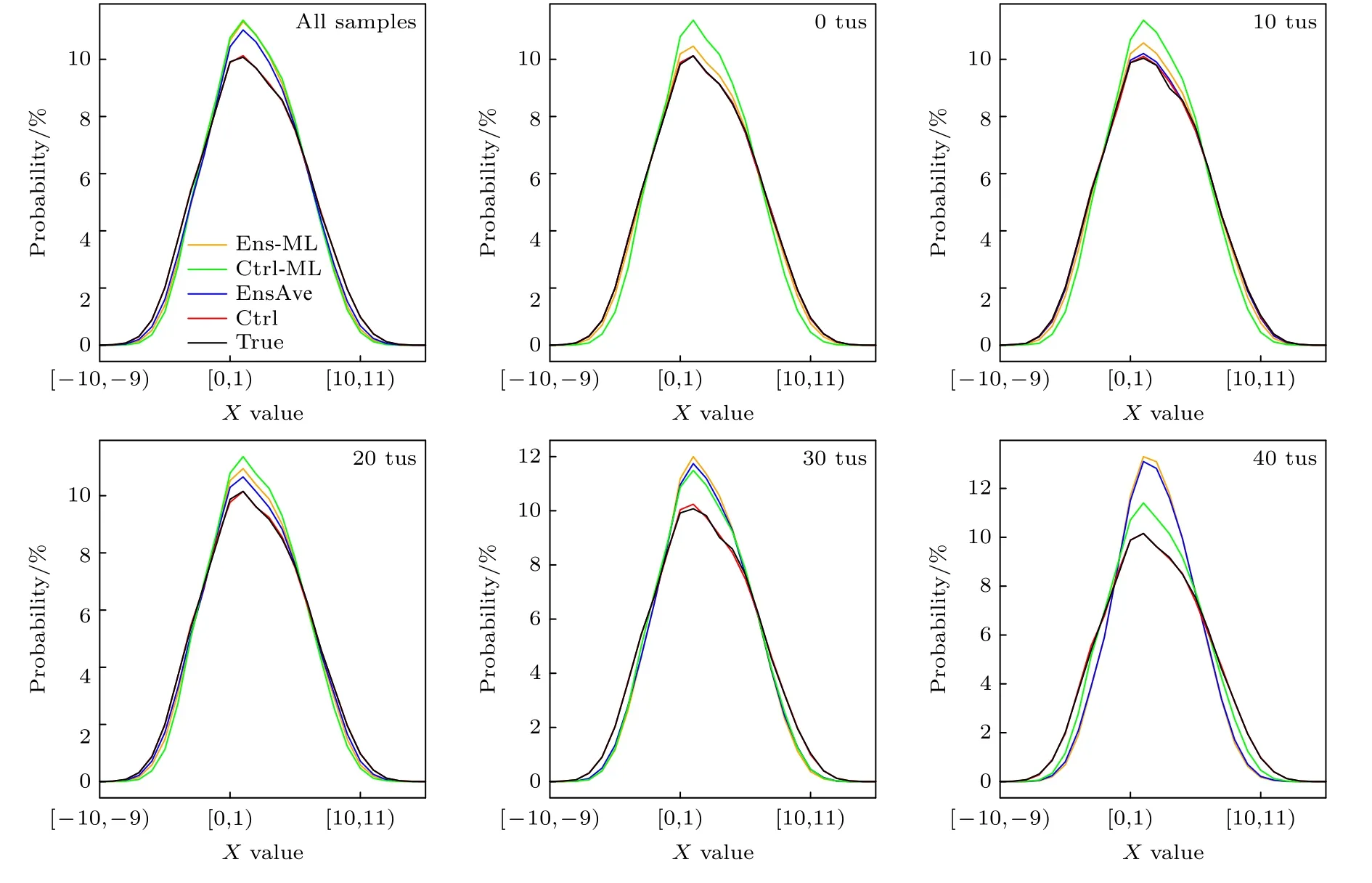
图10 不同预报方法中X 变量状态的概率分布随时间的变化Fig.10.Probability distributions of X variables for different leading times.
图11 给出了4 种方法的预报值与真值的分布对比,也可以看出Ens-ML 和EnsAve 更集中更靠近真值分布,Ctrl-ML 次之,而Ctrl 较前三者分布最为发散,预报技巧最差.可以发现在极值两端,更多Ctrl 预报点偏向极值,而EnsAve 和Ens-ML则明显比Ctrl 要小得多,这说明EnsAve 和Ens-ML与真值的误差更小,比Ctrl 更接近真值.

图11 不同预报方法的结果与真实状态的对比分布Fig.11.Scatterplot of the forecast value.
综上所述,随着预报时间的推移,多数个例的Ctrl 误差逐渐大于EnsAve 和机器学习模型,并且机器学习模型和EnsAve 的吸引子的概率分布出现值域变窄,峰度值增大的特点,总得说来Ens-ML,Ctrl-ML 和EnsAve 的预报技巧均优于Ctrl,其中又以Ens-ML 预报效果最佳.
4 结论
本文基于Lorenz96 模型,借助岭回归算法构建了基于控制预报和NLLV 集合预报的机器学习模型,初步探究了机器学习算法改进NLLV 集合预报效果的可行性,得到的主要结论如下.
1) 机器学习能够有效提高NLLV 集合预报的预报技巧,且其预报改进程度明显依赖于构建机器学习模型的集合成员数,增加集合成员数能够减小预报初期的过拟合现象,提高预报结果与真值之间的相关系数,究其原因可能是较多的集合成员能够提供更多的特征变量信息,使得机器学习训练的模型精度更高.
2) 就试验个例表现而言,随着时间的演变,控制预报误差大于其他3 种方法的个例数增多,在试验中后期尤为明显.从吸引子的概率分布来看,机器学习和集合平均都具有值域收缩、峰度增大并向平均值靠拢的特点,且机器学习比集合平均表现更突出,说明机器学习模型的预报结果优于集合平均和控制预报.
本研究基于Lorenz96 模型利用机器学习算法订正NLLV 集合预报结果,期望进一步改进其预报技巧.研究发现,机器学习模型在中后期对集合预报有较为明显的改进,同时在预报初期有一定的过拟合现象.虽然,增加集合成员数目能够一定程度上解决初期的过拟合现象,但也意味着会增加计算量,需要更多的计算资源.
