基于深度学习的科技文献摘要结构功能识别研究
2022-04-26陈子洋
毛 进,陈子洋
(1.武汉大学信息资源研究中心,武汉 430072;2.武汉大学信息管理学院,武汉 430072)
1 引言
近年来,随着学术文献数量的急剧增长,掌握一个学科的研究进展和具体文献的知识脉络已变得越来越困难,信息过载成为一大现实问题。学术搜索工具在过去十余年里得到了长足的发展,但是这类工具仍无法实现对学术文本的深度理解。科技文献摘要提炼了研究人员进行科学研究和学术交流的重要信息,是文献内容的梗概性描述。现有文献检索系统主要能够实现摘要内容检索,而不能对摘要中的“方法” “工具” 等部分进行单独的检索,另外现有的研究通常人工提取摘要信息,无法通过自动化手段对摘要的各个功能单元进行识别。摘要功能结构的自动识别可以有效应对上述问题,达到从摘要中更有效挖掘知识的目的,因此对摘要内容中不同功能单元的识别成为学术文献大数据知识挖掘与分析的一项重要内容。
摘要的结构功能是摘要的每个结构部分在学术论文内容层次上的作用,常见的结构功能包括“背景”“目的” “问题” “方法” “工具” “结果” “局限”等[1],且这些结构功能分别有不同的指向性。摘要功能识别即对摘要中的特定信息进行抽取,对其进行结构化的功能划分可以更清晰地更细粒度地展示文献摘要的语义构成和逻辑结构,便于查阅者在较短时间内进行精准检索定位。若将深度学习方法用于该领域进行摘要结构功能特征识别,一方面可做到对非结构化摘要进行自动的结构化,避免人工方式的巨大人力与时间成本;另一方面可用于构建基于单个结构功能而非整段内容的科技文献摘要检索系统。因此,采用深度学习方法对科技文献摘要进行功能识别是有研究必要的。由此,本研究在深度学习模型基础上,利用摘要文本中包含的语义信息,结合上下文特征构建摘要功能识别模型,并对比分析科技文献摘要的结构功能要素特征。
2 国内外研究现状
2.1 文献摘要结构分类框架
目前,关于摘要结构的研究主要围绕结构要素的数量和组合开展。曹雁等[2]以“引言-方法-结果-讨论(Introduction-Methods-Results-Discussions,IMRD)” 四要素结构模式作为分析摘要的对象,且证明每个结构要素都存在一些带有指向性的语料。以GRATEZ[3]为代表的学者总结出具有普遍性的“问题-方法-结果-结论(Problem-Method-Results-Conclusions,PMRC)” 四要素结构模式。SWALES[4]对GRAETZ 研究数据获取的可靠性和科学性提出质疑,认为摘要的结构应与论文的结构一一对应,主张摘要应该由IMRD 四结构要素组成更为合理。然而一些学者发现为保证摘要语义信息的完整性,还应该增加对“背景” 这一结构功能要素,因此TSENG[5]、李涛[6]和周志超[7]等一批学者也都在IMRD 模式的基础上,提出了以“背景-方法-结果-结论(Background-Method-Result-Conclusion,BMRC)”为代表的其他几种四结构要素的变体形式。
在现有的出版规范中,科技期刊论文摘要可分为结构式摘要与非结构式摘要两大类型[8]。相较于非结构式摘要,结构式摘要具有便于进行定位阅读与对所需内容进行自动化抽取的优点[9]。宋东桓等[10]认为结构式摘要和非结构式摘要在书写体例、习惯用语等方面有高度一致性,由此对380 种期刊进行调查,其中188种为采用结构式摘要的期刊、192 种为采用非结构式摘要的期刊,在此基础上提出摘要 “(Background-Objective-Method-Result-Conclusion,BOMRC) 背景-目的-方法-结果-讨论” 结构体系和结构式摘要的识别与规范化标引方法,但因其样本数量有限而具有一定局限性。
2.2 文献结构功能识别方法
目前,关于学术文献的结构功能自动识别已有一定研究。ANTHONY[11]基于朴素贝叶斯算法 (Naive Bayesian,NB),利用少数的摘要数据构建出摘要自动识别模型,TUAROB 等[12]则是采用支持向量机(Support Vector Machine,SVM) 和朴素贝叶斯模型进行对比,对学术文献的章节边界进行划分,实现了学术文献的功能识别。KIM 等[13]通过研究发现条件随机场算法(Conditional Random Field,CRF) 要比朴素贝叶斯算法和SVM 效果更好,精确度一般在90%以上。在摘要的功能识别方法上,除了CRF、SVM 等传统模型的基于浅层机器学习模型应用,近年来关于使用深度学习模型的融合与优化也逐步深入,以卷积神经网络(Convolutional Neural Networks,CNN)、循环神经网络(Recursive Neural Network,RNN) 为代表的深度学习模型,以及在此基础上创新的长短期记忆网络(Long Short-Term Memory,LSTM)、长短期记忆模型和条件随机场混合模型LSTM-CRF、CNN 与条件随机场混合模型CNN-CRF 等模型层出不穷。例如王东波等[14]分别利用LSTM、SVM、LSTM-CRF、CNN-CRF等对3 672 篇情报领域期刊摘要文献进行研究。其另一研究[15]针对CRF、双向长短期记忆模型(Bidirectional LSTM,Bi-LSTM) 和SVM 三种模型的实验,其中CRF 模型表现最佳,其F1值达到92.88%。陆伟和黄永等运用多种模型从基于章节标题[16]、章节内容和标题、段落[17]等层次对学术文本的结构功能进行自动分类识别实验,并取得了令人满意的效果,但其研究并未涉及对于科技文献摘要句功能识别。沈思等[1]基于LSTM-CRF 模型针对科技文献摘要构建了结构功能自动识别模型,但其未能在自动识别任务上尝试应用BERT 等具有更优性能的模型。张智雄等将论文摘要中的研究目的、方法、结果和结论,这些语言单元定义为摘要中的语步,其运用Masked Sentence Model 来解决语步自动识别问题。通过改造BERT 输入层,将摘要中句子的内容特征与上下文特征有效结合,在语步识别实验中取得了较好的效果[18]。上述大部分方法都使用了word2vec 工具来对文本进行预训练,得到的词向量输入神经网络的第一层以减少人工提取特征的成本。但是由于上下文语境、语序对摘要句中词意有重要影响,而如果使用word2vec 对输入的语句进行预训练的话,无论其上下文如何得到的同一个词的词向量都是同一个,由此可以产生相关优化思路。随着研究的不断深入,BERT、ERNIE 等涌现的深度学习模型也被证明在自然语言处理各项任务中取得了不错的成绩。陆伟等[19]将其应用到科技文献文本分类任务中,其实验以计算机领域的学术期刊论文为训练语料,利用BERT 及LSTM 方法构建分类模型,其准确率比传统方法更佳。
选取近年来对文献摘要功能的6 项代表性研究,对其语料语言、功能结构、分类模型等进行了对比,如表1 所示。通过对比可反映出使用模型和结构功能分类的不同将对实验结果造成较大的影响,基于机器学习模型的现有研究结果通常准确率有限,且采用此类方法的研究通常选取的文献较少,在文献数量较大的情况下可能存在局限;而基于深度学习的方法能够适用于数据量较大的情况且通常具有更高的准确性。因此,本文对深度学习方法在该科技文献摘要结构功能识别的应用进行了更加深入的研究。
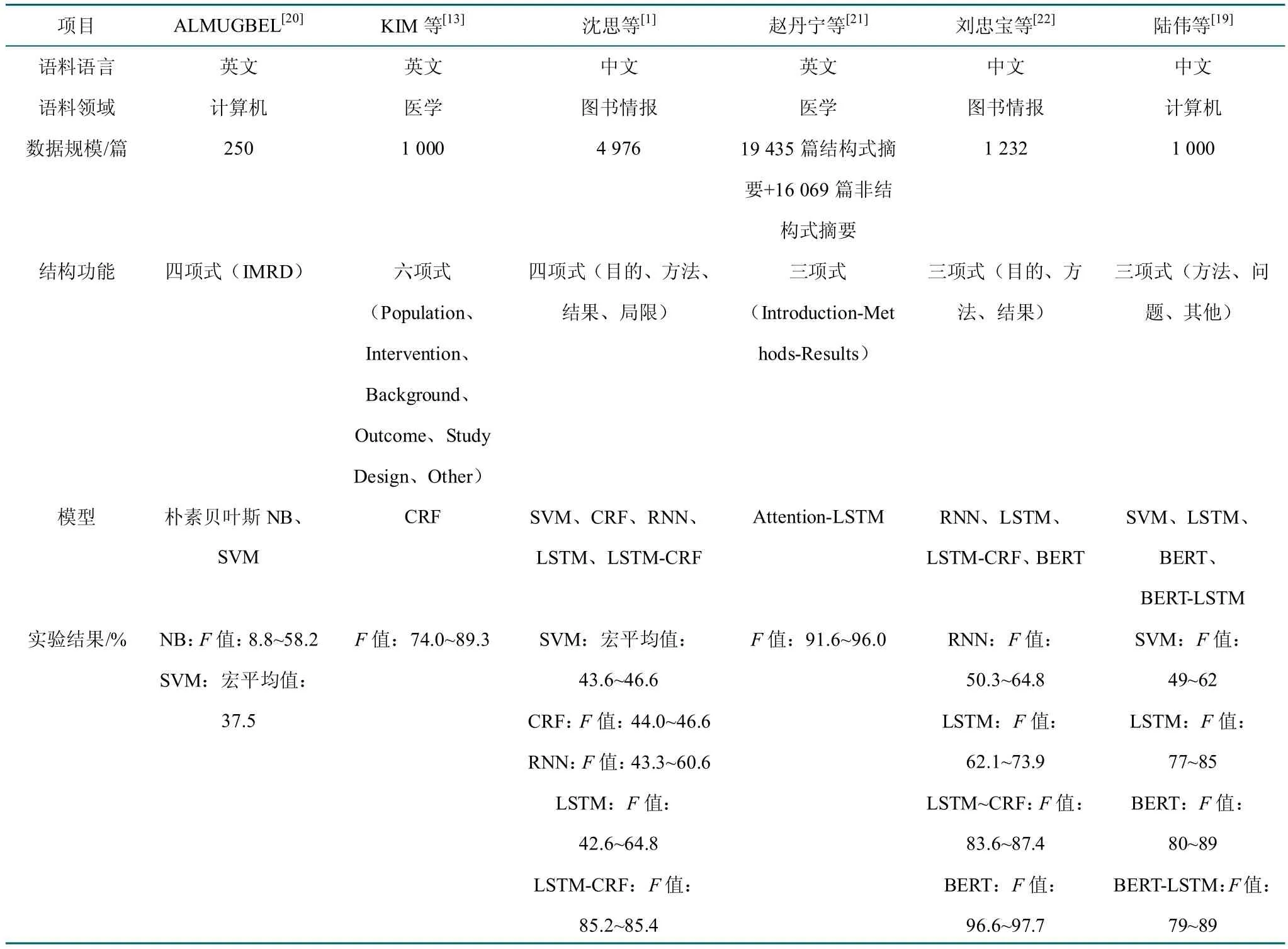
表1 摘要结构功能识别代表性研究对比Table 1 Comparison of representative studies on structural function identification
3 科技文献摘要结构功能分类模型
3.1 科技文献摘要结构功能分类任务定义
科技文献摘要文本往往由多个结构部分组成,每个结构单元在学术论文内容叙述上具有不同的作用。本文将摘要文本中的句子理解为最小的摘要文本单元,而承载某种功能的结构单元可以包含多个句子。现有的结构功能划分要素并不统一,通过分析结构式摘要的期刊文献,从通用型角度出发本文将科技文献摘要的结构功能归纳为“引言-方法-结果-结论(Introduction-Methods-Results-Conclusions,IMRC)” 4 个类型。因此,科技文献摘要结构功能分类任务可以表达为:给定摘要文本中的句子,通过文本分类方法识别其具有的摘要结构功能类型。
3.2 摘要结构功能分类方法
本研究采用基于深度学习的文本分类方法对科技文献摘要句子预测其所属的结构功能类型。该任务本质上是自然语言处理中一项文本分类任务,该分类模型的整体架构如图1 所示,其中输入为摘要文本中的句子内容,并在模型中对输入的文本内容进行特征表示,特征包括词向量和位置特征,最后将这些特征输入多层感知器和softmax 分类器,以输出所预测的句子结构功能类型标签。本研究分别实现并对比BERT 模型、BERT-TextCNN 模 型、BERT-LSTM 模 型 及ERNIE 模型在该任务中的性能。
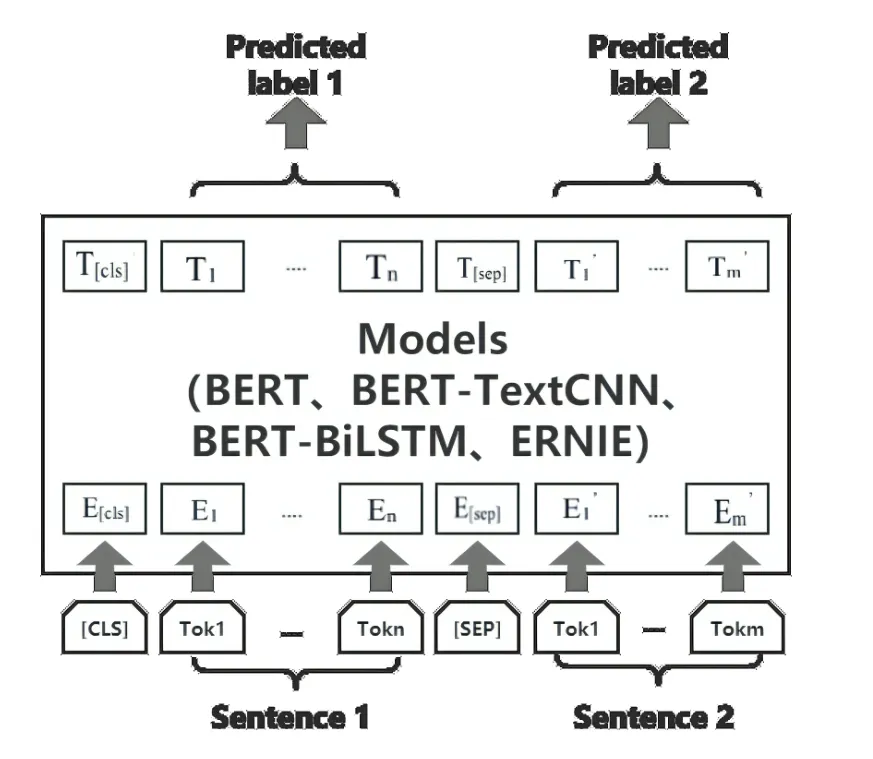
图1 数据输入模型、输出预测标签过程Fig.1 Process of data input model and outputing forecast labels
3.2.1 BERT 模型
BERT 模型基于Transformer[23],借鉴完形填空式的语言模型Masked Language Model (MLM)、Quickthoughts[24]中的Next Sentence Prezdiction(NSP)以及GPT[25]中对于输入层和输出层的改进,其结构如图2所示。
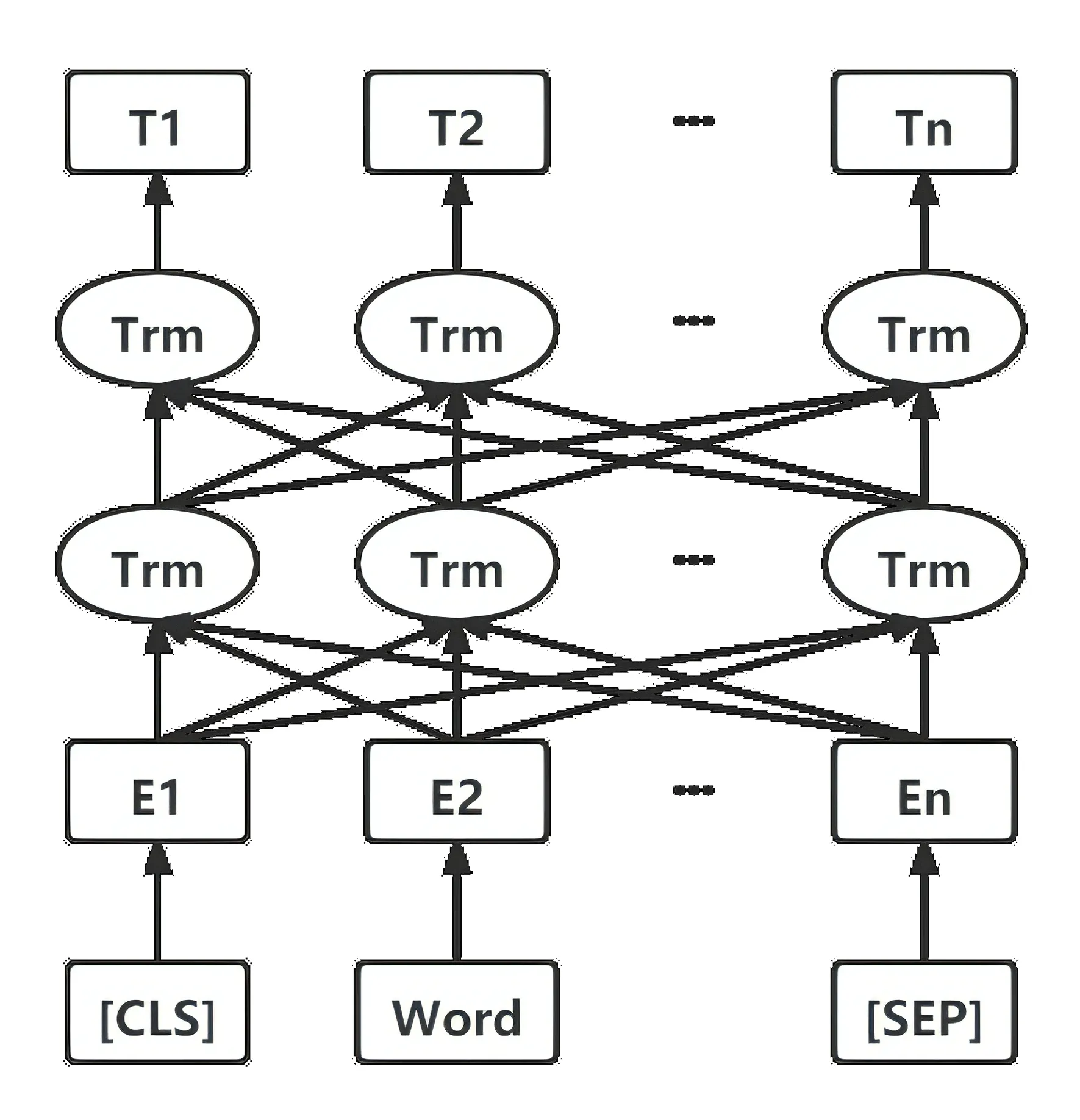
图2 BERT 模型结构图Fig.2 Structure diagram of a BERT model
其核心是一个多层且多方向的Transformer 网络结构,通过这个结构,每个位置的词向量都会融入语句中其他各个位置的词向量信息,因此可以很好地对一词多义现象进行建模,避免标引意图模糊和语义功能不明问题。运用其Encoder 中的Self-attention 机制,计算得到Attention 矩阵,其中每一行代表输入序列中每个字的Attention 向量。
同时,BERT 中使用Masked Language Model 使其提升语境结合能力的同时避免信息泄露情况的发生,利用NSP 任务来判断识别两句文本是否是上下文关系。因此,总体来看BERT 的预训练阶段是一个包括MLM 和NSP 的多任务学习模型.
理论上,对BERT 的输出层加以改进,就已经可以完成文本分类任务。本实验中采用的BERT 模型、BERT-TextCNN 模型、BERT-BiLSTM 模型同样都是先在BERT 层中对摘要文本进行特征向量表示,并进行MLM 和NSP 预训练任务。三者区别主要在于后续步骤中,BERT 模型在上述输入层之后直接接线性函数和输出层完成文本分类任务。
3.2.2 BERT-TextCNN 模型
卷积神经网络(CNN) 设计之初是对大型图片进行处理,YOON[26]在论文中提出了TextCNN 将其应用到文本分类任务。TextCNN 由输入层、卷积层(Convolution)、最大池化层(Max Pooling)、全连接层及输出层构成[27]。其中每个卷积层提取一种特征,经过多个卷积操作得到许多有不同值的Feature Map,而池化层的主要作用在于降低维度,并对每类特征集进行最大池化并传送到全连接层softmax 函数中根据特征进行分类,即把所有特征结合变成全局特征,并最终输出每个类别对应的值,其模型如图3 所示。
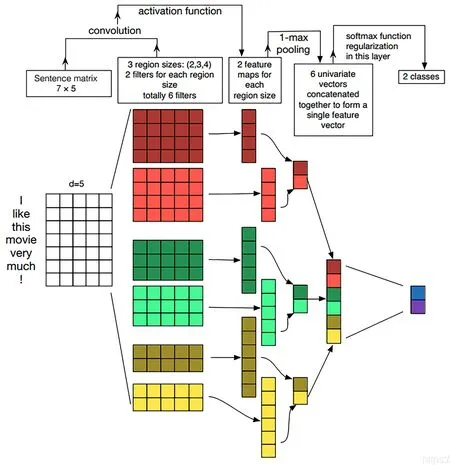
图3 TextCNN 的网络结构[27]Fig.3 Network structure of TextCNN
BERT-TextCNN 模型是在BERT 层获得向量表示后,将得到的特征向量使用TextCNN 分类器取代线性函数进行分类(图4)。采用卷积层提取句子特征并形成注意力矩阵,而后对特征图进行加权池化操作,通过全连接层降维和softmax 函数得到句子分类概率。
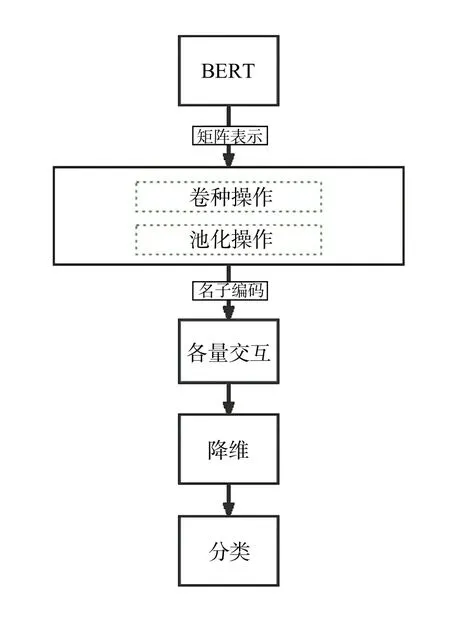
图4 BERT-TextCNN 模型结构图Fig.4 Structure diagram of BERT-TextCNN model
3.2.3 BERT-BiLSTM 模型
长短时记忆神经网络(LSTM) 是一种特殊的循环神经网络(RNN),在RNN 的基础上又加入了记忆单元和门限机制,门限机制通过对状态信息进行储存和修改,实现长距离记忆,解决了长程依赖问题,可以对文本中的长距离信息进行更加有效的利用。其门限机制中包括遗忘门(Forget Gate)、输入门(Input Gate) 和输出门(Output Gate),其中遗忘门让循环神经网络忘记之前记忆单元中不重要的信息,输入门补充最新记忆,输出门决定该时刻的输出。
在实现LSTM 后,再增加一个反向的LSTM,实现双向的LSTM,即BiLSTM。与LSTM 相比,BiLSTM可以获得更完整的信息。BERT-BiLSTM 模型在BERT层后,通过BiLSTM 层整合文本信息和句子的顺序特征,以获取更完整的语义特征,使语义表示更准确,并在BiLSTM 后连接一个全连接层,最后通过softmax层进行分类输出,其结构如图5 所示。
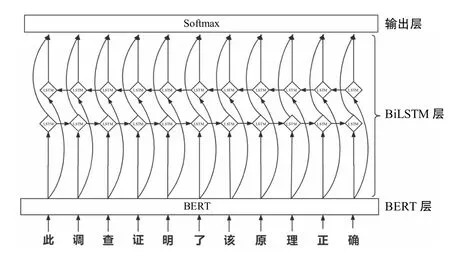
图5 BERT-BiLSTM 模型结构图Fig.5 Structure diagram of BERT-BiLSTM model
3.2.4 ERNIE 模型
通过知识集成的增强表示模型(Enhanced Representation Through Knowledge Integration,ERNIE) 于2019 年被SUN 提出[29],这一模型的提出受到BERT 的Masked LM 训练方式的启发,但相对于BERT 又做出了改进:在Mask LM 训练方式的应用中,BERT 只对字进行Masking,而ERNIE 不仅对字,同时也对实体、短语等进行随机Masking,由此可使模型学习到更多高级的语义。
ERNIE 模型与前3 个模型则主要有如下不同之处。首先,其在预训练中的Masking 分成3 个阶段进行,如图6 所示,第一阶段Basic Level Masking 针对字级别,其中使用的模式与BERT 模型相同。第二阶段Phrase Level Masking 针对短语级别,即随机选择句子中的几个短语,对同一短语中的所有基本单位进行Masking 和预测。第三阶段是Entity Level Masking 针对命名实体级别,实体指人名、机构名、商品名等。虽然ERNIE 模型采用的仍是基于字特征的输入建模,但Mask 的粒度大小有所变化,可能包括字、词、实体等不同粒度的切分,并对切分后的数据进行向量化处理,使得模型在语义、知识等不同层次上学习到相应的关系。
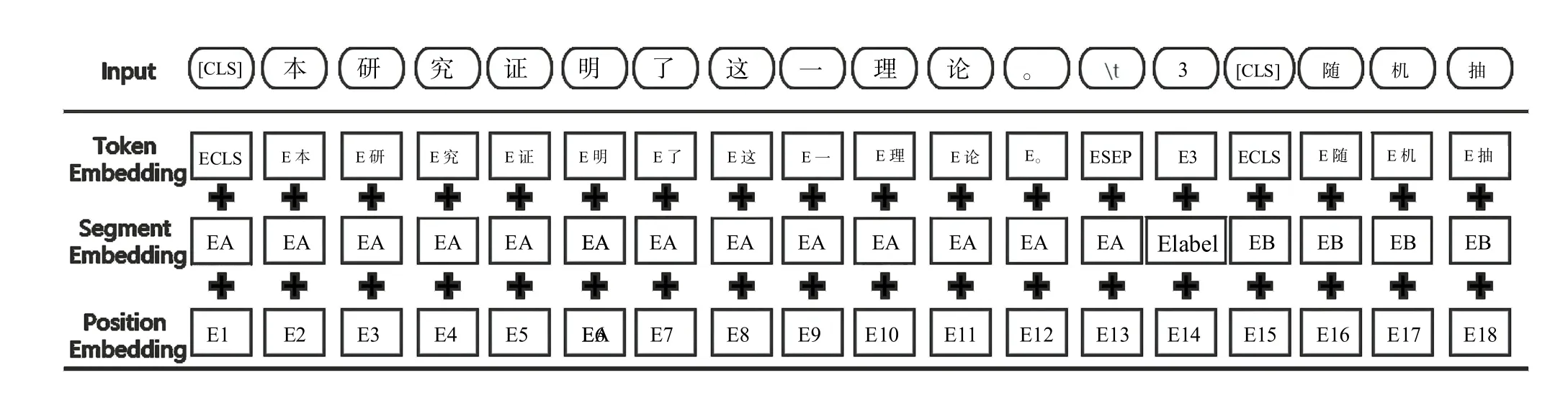
图6 ENRIN 模型的Mask 方式Fig.6 Mask mode of ENRIN model
4 实验与结果分析
本研究整体实验过程如图7 所示,实验流程主要分为4 部分:语料预处理、训练学习、测试数据、对比分析。首先,将获取的科技文献摘要预处理为包含“目的” “方法” “结果” “结论” 4 种结构要素的数据集。第二,在模型构建阶段采用BERT、BERTTextCNN、BERT-BiLSTM、ERNIE 四种分类模型进行训练学习。第三,在测试数据阶段通过这5 组实验得到的预测值与标签进行损失函数的计算并进行效果评价;最终获得优化模型,并探究不同结构功能特征对自动识别效果的差异。
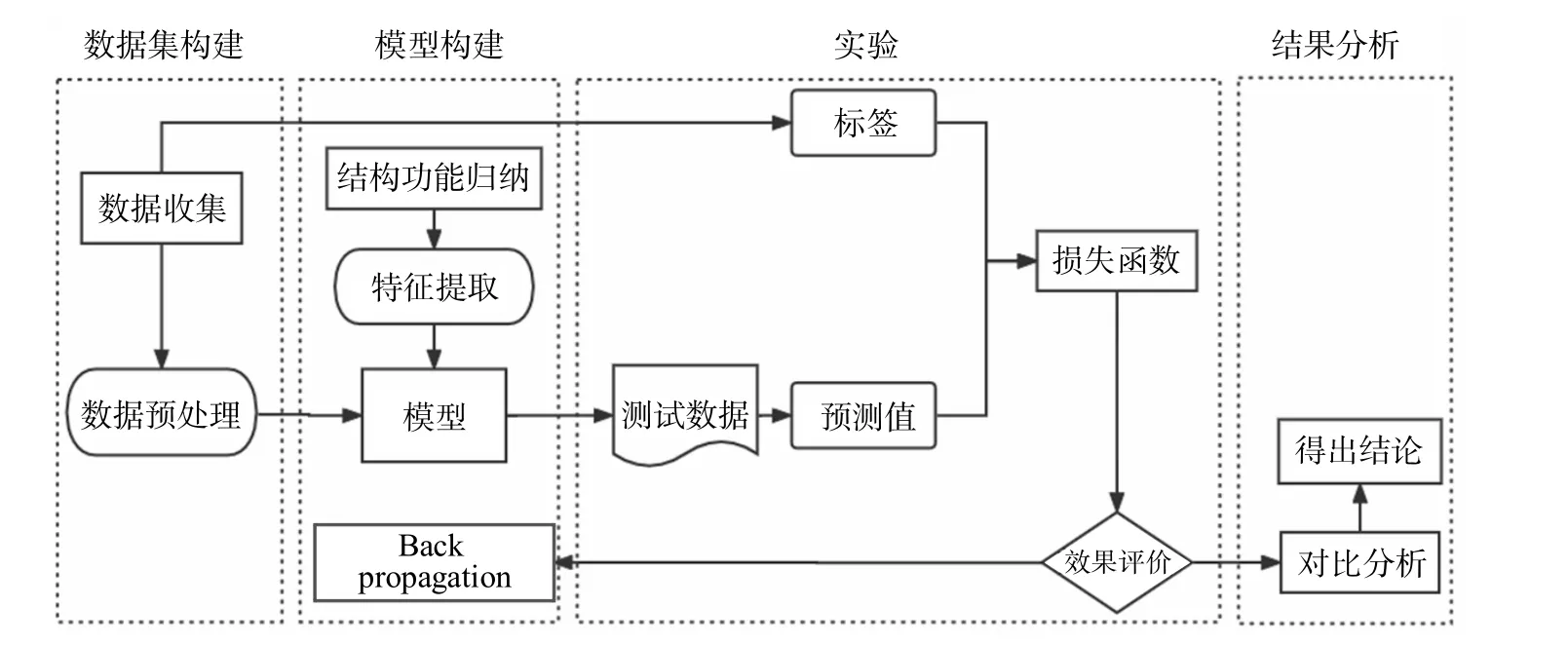
图7 整体实验流程Fig.7 Overall experimental process
4.1 数据集构建
针对本文任务创建新的数据集,要求数据量大且标注要足够准确。为保证准确性一般采用人工标注的方式对摘要中句子所属结构要素进行标注,但为避免人工标注数据的长耗时和低效率,本文希望找到已采用结构式摘要的文献作为数据来源。通过大量对科技文献摘要的前期调研发现,相比于其他领域,生物医学领域科技文献采用结构式摘要的比例较大,据统计在生物医学领域ESI 高被引期刊中提供结构式摘要的期刊占比高达到29.2%[30]。由此在生物医学领域期刊中最终选取采用结构式摘要的两本医学领域期刊JMIR mHealth and uHealth和Journal of Medical Internet Research,并获取Journal of Medical Internet Research1999—2018 年刊载的所有文献和JMIR mHealth and uHealth2013—2018 年刊载的所有文献,除去抓取失败的论文共有3 130 篇。在3 130 篇科技文献摘要中,共含有1 179 343 个词,对其进行逐句划分,得到句子语料共48 107 条,平均句子长度约为25 个词,并将这些句子存在MySQL 数据库中,由此构成实验的原始语料集。
本研究通过对3 130 篇文献的结构式摘要采用的11种结构功能标题进行统计发现,所有标签共出现了48 107 次,平均每个标签出现在285 篇摘要里,其中Results出现的频次最高,接下来依次是Conclustions、Methods、Introduction 和Background。由此,发现Introduction-Methods-Results-Conclusions 四结构化摘要标题组合较为常见。因此将科技文献摘要的结构功能归纳为“引言-方法-结果-结论(IMRC)” 4 个类型可得到验证。依据本文的结构功能分类规则,根据结构化摘要的标题,将相应句子赋予结构功能分类标签。其中,分类标签与结构化摘要标题的对应关系如表2 所示。

表2 摘要结构功能及其标记词汇Table 2 Structural function of summary and its marked vocabulary
为更好地评价实验结果,在实验中选用5 折交叉验证法,因此将原始数据集分为5 份,选取其中4 份作为训练集,1 份作为测试集,以此来作为模型的评价指标。重复进行5 次上述过程,即选取5 组不同的训练集与测试集并分别进行训练和测试。为保证同一篇文章内的所有语料在同一份数据集中,首先将文章分为5 等份,每一份中包含626 篇摘要的全部语料,即分别包含8 998 条、9 449 条、9 612 条、9 357 条、10 691 条语料。将上述的语料集每次选出4 份为训练集、一份为测试集,然后再分别在本文使用的模型上进行实验。
4.2 模型设置
本文实验在NVIDIA GeForce GTX 1080Ti GPU 上进行,GPU 运存11.0GB,使用Pytorch1.7 和Python3.7作为实验环境。在训练超参数设定上,训练次数epoch设为10 次,Hidden_size 表示隐藏层神经元个数设置为768,Pad_size 表示最大序列长度设置为100,Filter_size 表示卷积核尺寸设置为(2,3,4),Num_filter 表示卷积层数量设置为100。Batch_size 表示每一次训练神经网络送入模型的样本数,若Batch_size 过小将使得运行度过慢,数值过大可能会导致内存不够用而降低准确率。考虑到GPU 算力的限制采用每一次训练神经网络送入模型的样本数batch_size 为32,当连续2个周期的预测准确率仍然没有提升时,提前结束预测。
在损失函数设置上,选取分类问题中常用的交叉熵损失函数,其loss 值随预测概率变化如图8 所示。
图8 交叉熵函数的loss 值变化规律Fig.8 Variation law of loss value of cross entropy function
同时,为避免过拟合现象,将Dropout 值设置为0.5,并采用Adam 优化器 (Adaptive Moment Estimation)[31]与Warmup “热身” 策略结合对学习率衰减进行优化,达到传入更新的次数并能返回一个适当的学习率的目的[32]。Learning_rate 随epoch 的变化如图9 所示,在Learning_rate 达到初始化设置的0.000 02 前为预热状态,此阶段学习率线性增长,并在达到该点后开始衰减。
图9 learning_rate 优化曲线Fig.9 Learning-rate optimization curve
4.3 模型评价指标
对于模型对数据集中实体进行预测的结果,当其对实体的类型和该实体所拥有的字符数量都预测正确时判定模型预测正确。采用准确率P、召回率R以及F1值作为模型预测命名实体性能的评价指标,计算公式如下,并引入混淆矩阵进行结果分析。公式中TP为模型预测正确的结构功能个数,TN为模型成功预测出错误的结构功能个数,TP为模型预测错误的结构功能个数,Fn为未识别到的结构功能个数:
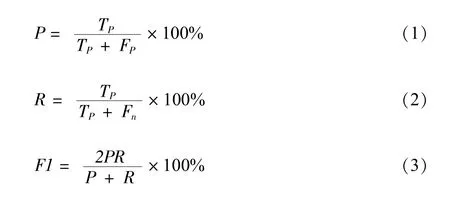
4.4 结果分析
4.4.1 模型性能对比分析
上述各模型在数据集下利用五折交叉检验的性能指标对比如表3 所示,其中每个模型的实验中P、R、F1指标最高数值用加粗进行标识。
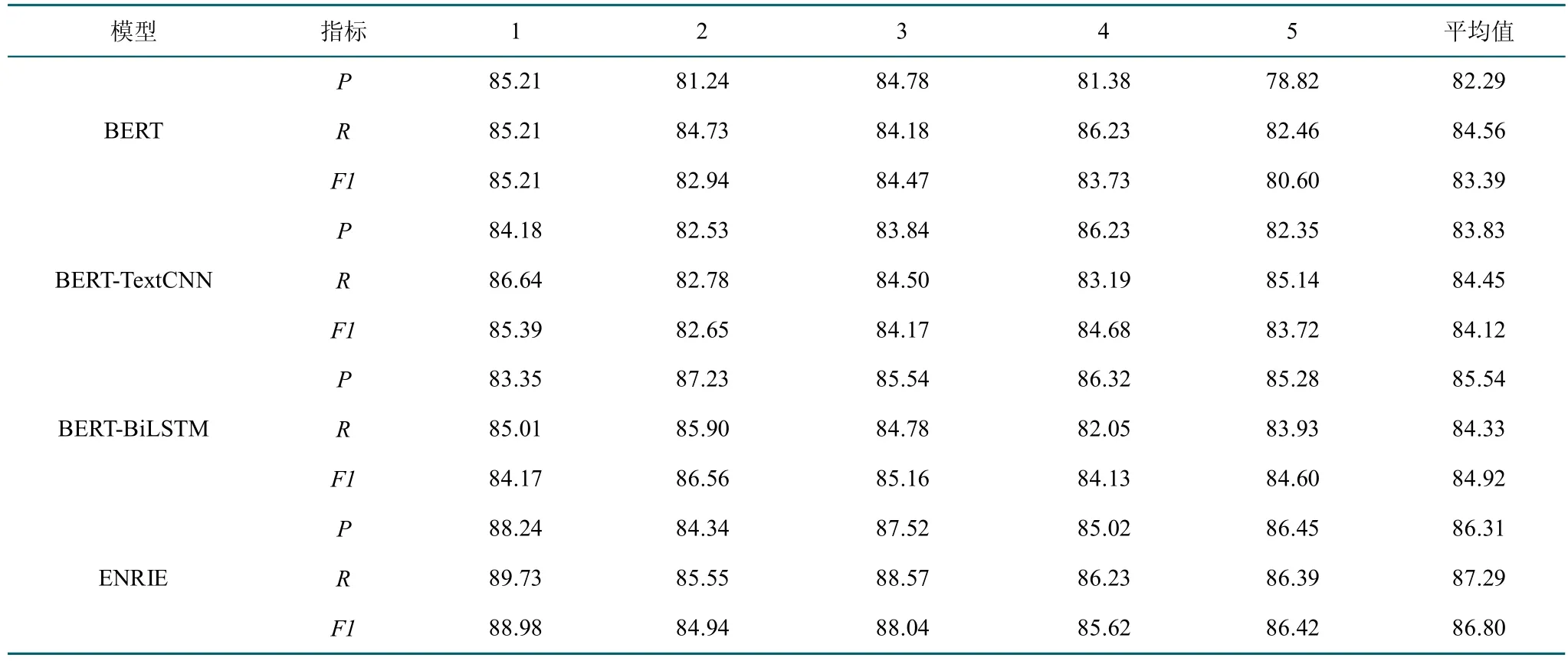
表3 各模型实验结果 单位:%Table 3 Experimental results of each model
通过对比BERT 模型和BERT-TextCNN 模型结果发现将BERT 模型后接TextCNN 层的结果略高于使用BERT 模型后接线性分类函数。在前期进行预实验时,将一篇文章摘要以一结构功能划分而不是以句子为单位划分进行输入时,使用BERT-TextCNN 模型的平均F1值为87.85%,低于使用BERT 模型的平均F1值为91.12%。在正式实验中BERT-TextCNN 模型效果比BERT 模型好,但在预实验中的效果较差的原因主要在于BERTCNN 的句子对特征提取阶段使用的CNN 网络只能提取句子局部特征,且卷积之后的池化操作会进一步损失位置信息,同时池化后会更突出某一种语义而削弱句子各个部分的其他语义。由于一篇文章的一个结构功能中通常含有多个句子,因此其长度远高于分句后,预实验中使用的数据集语料平均含有74 个词,远多于正式实验中使用的平均长度为25 个词的语料。因此BERTCNN 模型对于较长的文本尤其是长难句的处理能力显得较差,因为越长的句子越有可能出现相互依赖的两个或多个词之间间隔很长或是语义有转折的情况,由此便可能带来性能的减弱。由此可以总结出BERT-TextCNN 模型的优点是可以并行计算,缺点是无法捕捉远距离特征且会损失位置信息,其更适合用于处理短文本相关任务。
通过对比BERT 模型和BERT-BiLSTM 模型结果发现BERT-BiLSTM 模型F1的最高值、最低值与平均值均高于没有补充位置信息只使用线性函数的BERT模型,原因主要为BERT 模型在预训练过程中使用的是基于Self-attention 的Transformer 编码单元,即使是有Position Encoding 作为BERT 的一部分输入,训练过程中也还是弱化了位置信息。而在本文对于摘要文本功能识别任务中,获得字词在语句中的位置信息、方向信息会对提升识别结果的准确率有很大帮助。
通过对比ERNIE 模型和上述3 模型发现,结果发现,ERNIE 模型各项数据的平均值都领先于其他模型,平均准确率和召回率均超过了86%,最低F1值为84.94%,最高F1值88.98%,平均F1值达到了86.8%。初步证明了其处理文本分类任务的优越性,由于将外部知识引入到模型中,并通过多任务连续学习机制,因此模型的语义表示能力和自然语言推断任务相较BERT 有一定提升。
4.4.2 不同结构功能的识别效果对比分析
为进一步分析深度学习模型针对每一结构功能的具体性能,选取了4 模型中各自F值最高的情况,并对比了每个摘要结构功能标记具体的识别情况(表4)。

表4 模型最佳识别情况各结构功能情况 单位:%Table 4 Best identification of model and function of each structure
从具体的结构功能特征识别性能的角度来看实验结果,对于引言部分的识别,ERNIE 模型性能最好,BERT-TextCNN 模型较好,BERT 模型与BERT-BiL-STM 模型接近,二者均性能较差。对于方法部分的识别,ERNIE 模型性能最好,BERT-BiLSTM 模型其次,BERT-TextCNN 模型性能最差。对于结果部分的识别,ERNIE 模型性能最好,BERT 模型性能最差,两者的F1值相差3.29%,对于结论部分的识别,ERNIE 模型性能最好,BERT 模型性能最差,两者的F1值相差8.79%。由此可见,ERNIE 模型在各个功能识别上均有较好的表现,其最高F1值“方法” 结构功能识别达到了92.55%。同时,4 类模型中均对“方法” 有较好的功能识别效果,而对“结论” 的识别效果较差,原因主要是“方法” 部分特征较为明显且易于区分,而相对于其他的功能结构“结论” 部分在文献摘要中所占篇幅偏少。除此之外,在“方法” 部分,BERT-TextCNN的性能较差而BERT-BiLSTM 模型较好,且二者有较大的差距,其主要原因在于BiLSTM 模型可以使分类模型更好地结合上下文信息位置信息,而BERTTextCNN 模型捕捉局部信息而模糊位置信息,因此对于平均文本长度更长的“方法” 功能结构识别BERTBiLSTM 模型取得了相对于BERT-TextCNN 模型更好的效果。
在此基础上选取综合识别性能最优的ERNIE 模型为研究对象,通过构建如表5 所示的混淆矩阵,来分析该模型的误识情况。从结果中可以看出,“引言”部分主要被误识为“结论”,“方法” 部分主要被误识为“结果” 和“引言”,“结果” 部分主要被误识为“方法” 和“结论”,“结论” 部分主要被误识为“引言” 和“结果”。总的来看,大部分的误识情况都是将其误识为与其相邻的上下文结构功能,主要原因是紧邻的结构功能句间可能存在过渡句,使其难以分辨属性。唯一的例外是“引言” 和“结论” 这一对结构功能,二者分属摘要的首尾两部、并不相邻,原因主要是这两部分的内容存在较大的相似性,从单句中较难进行准确的识别。

表5 ERNIE 模型混淆矩阵Table 5 Confusion matrix of ERNIE model
5 结论
本文在前期调研的基础上获得了“IMRC” 这一针对科技文献较为普适的结构功能要素归纳框架,以便于理解文献摘要的微观功能结构,同时为实现文献摘要的语义检索提供数据来源。将科技文献摘要特征功能识别任务转换为文本分类问题,以eHealth 领域两本期刊的论文摘要为语料集,在BERT、BERT-BiLSTM、BERT-TextCNN、ERNIE 等深度学习模型上进行应用与对比,并按照五折交叉检验的方式设计实验。实验结果表明ERNIE 模型在科技文献摘要功能识别任务上性能较好,F1值具有在文本分类领域进一步应用拓展的可能性,同时在对比BERT-BiLSTM、BERT-TextCNN 的实验结果后发现,在处理较长文本时BERT-TextCNN的性能较差而BERT-BiLSTM 模型较好,因此在针对不同类型的文本时可选择不同的模型以达到更好的分类效果。在摘要句功能识别任务中词语识别起着决定性作用,但剥离语境的单一词语存在导向不明的问题,可能会导致功能识别的不准确。本文在BERT、ERNIE等深度学习模型基础上,利用摘要文本包含的语义信息,结合上下文特征构建和优化摘要功能识别模型,将对后续类似的短文本结构功能识别任务提供方法指导,有助于基于关键信息语块的知识挖掘应用。
本文实验中选用的是同一个领域内科技文献的结构式摘要,而不同学科领域或语言情境下的科技文献摘要写作可能存在差异性。同时,现有的摘要中非结构式摘要占比更大且可能会更复杂,因此未来将在更大规模、更广领域的数据集上进行工程化应用探索,并尝试构建更精细的知识组织。
