基于NARX神经网络的千岛湖藻类短期预测模型构建
2022-04-25朱梦圆王裕成朱广伟
李 未,朱梦圆,王裕成,朱广伟
1. 中国科学院南京地理与湖泊研究所,湖泊与环境国家重点实验室,江苏 南京 210008
2. 杭州市生态环境局淳安分局,浙江 杭州 311700
千岛湖又名新安江水库,是长三角最大的战略水源地及杭州市的饮用水源,以水质优异而著称[1-2]. 千岛湖设有4个国控监测断面,其中,街口断面位于安徽省和浙江省交界处,水质考核标准为GB 3838-2002《地表水环境质量标准》河道Ⅱ类;库体内有3个监测断面,分别为小金山、三潭岛和大坝前,水质考核标准均为GB 3838-2002湖库Ⅰ类(除小金山TP浓度≤0.025 mg/L外). 近年来,随着流域经济的发展,千岛湖承接的外源污染负荷增大,加上水文气象过程的影响,库区水质出现不稳定性,局部地区开始出现富营养化和藻类异常增殖现象[3-7]. 尤其是小金山断面,地处自上游狭长河道往开敞型水面过渡的区域,极易受到上游河流断面的影响,导致水质状况无法稳定达标,成为千岛湖面临的水环境保护难题[8-9].
为了快速捕捉水质与藻类变化,自2011年起千岛湖开始在国控监测断面建设集水温、pH、溶解氧浓度、浊度、叶绿素a浓度等参数于一体的剖面高频监测系统. 在获取高频时间序列对水质状况进行实时自动监测的同时,尝试用科学手段挖掘数据特征和规律,在千岛湖沉降通量、热成层和溶解氧分层的稳定性以及藻类垂向分布规律方面取得了新进展[9-13]. 但是,目前通过高频时间序列实现对千岛湖水质水华的短期预测,从而对藻类异常增殖带来的水质风险做出预判的研究较少.
大数据及人工智能技术使得以数据驱动的建模方式对时间序列进行短期预测成为可能[14],尤其是人工神经网络(artificial neural network,ANN)模型,因其具有良好的非线性映射和自学习能力,在非平稳时间序列的高精度预测方面具有独特的优势. BP (back propagation,反向传播)神经网络作为主流网络之一,结构简单、映射能力强,已在医学[15]、大气[16-17]、水文[18]、土壤[19-20]、生物[21]、环境[22-23]等多学科领域广泛应用. 但是,BP神经网络属于静态神经网络,信息流动是由输入层单向流动到输出层,对于历史输入输出缺乏记忆联想,对时间序列时变特性的适应能力不强,从而影响预测精度[24-25].
NARX (nonlinear auto-regressive with exogenous inputs,带有外部输入的非线性自回归)神经网络是动态神经网络的一种,其输入结果是当前外部输入和历史输出结果的非线性函数,可看作是有时延输入的BP神经网络加上输出到输入的延时反馈连接. 由于网络结构中存在时延和反馈,因此其可反映系统的历史状态信息,是一种有记忆功能的神经网络,可以模拟时间序列长期动态特征[26-30]. 近年来,NARX神经网络在环境空气质量[31-32]、水文预报[33]、大坝变形[34]、地表沉降[35]、农作物水分蒸腾[36]、股票择时[37]等预测中均取得了较好的效果. 研究[27,34]表明,NARX神经网络可用于预测时间序列,且通常可以保留信息的时间是常规递归神经网络的2~3倍.
鉴于此,该研究以千岛湖小金山国控监测断面的水质自动监测站叶绿素a (Chla)高频监测数据为研究对象,构建基于NARX神经网络的藻类预测模型,分析该模型在千岛湖Chla浓度时序变化预测的效果,探讨最优预见期,以期为构建以数据驱动的千岛湖水华监测预警系统提供科学依据.
1 材料与方法
1.1 研究点概况与浮标数据
小金山国控监测断面(见图1)距上游浙江省与安徽省交界的街口断面约28.6 km,距下游三潭岛断面约15.0 km,水深约40 m. 布设在小金山国控监测断面的水质自动监测系统为固定浮标站(29°36′38″N、118°56′45″E),浮标悬挂有型号为YSI EXO2的多参数水质仪(Yellow Springs Instrument Co.,美国),可自上而下地同步记录水深(单位为m)和Chla浓度(单位为μg/L). 水深为0.1~10 m时,测量间隔为0.5 m;水深为10~40 m时,测量间隔为2 m. 浮标在2016年每3 h (分 别 为00:00、03:00、06:00、09:00、12:00、15:00、18:00、21:00)记录一次数据,2017年以后每4 h(分别为00:00、04:00、08:00、12:00、16:00、20:00)记录一次数据. 为保持数据的一致性,该研究取用每日00:00与12:00的数据进行分析.

图 1 千岛湖库体及国控监测断面分布Fig.1 Qiandaohu Reservoir and location of state-controlled sections
1.2 数据处理
小金山国控监测断面逐日高频剖面观测数据的监测时间为2016年9月8日-2019年12月2日.从Chla浓度随时间的剖面变化〔见图2(a)〕可见:Chla浓度剖面存在明显的季节性变化特征,冬季、春季水柱垂向差别不明显,呈几乎完全混合的状态;夏季、秋季上层Chla浓度明显高于下层. 随机取夏季某一次监测剖面数据,分析Chla浓度随水深的变化〔见图2(b)〕发现:水深10 m以上,Chla浓度较高且变化较大;水深10 m以下,Chla浓度较低且趋于稳定.因此,对每日00:00和12:00 0~10 m的Chla浓度监测数据运用梯形求和公式,得到随时间变化的Chla浓度在水深10 m以上的沿深平均值,时间间隔为0.5 d.

图 2 小金山国控断面高频监测Chla浓度的剖面变化情况Fig.2 High frequency observed Chla profile at Xiaojinshan Staion
高频监测期间,由于仪器维护或恶劣天气等人为不可抗拒原因,出现了一些时长为半天至十几天的测量间断. 缺测值采用窗口长度为7的移动中位数进行线性填充,即以缺测值位置为中心,向前、向后各移动3个位置,形成长度为7的移动窗口;若没有足够的数据填满窗口,则窗口自动在前或向后继续移动或直至端点处截断. 当窗口被截断时,根据窗口内的数据计算出中位数,替代缺测值.
1.3 NARX神经网络结构及构建
NARX神经网络的拓扑结构分为输入层、隐含层、输出层3个层次以及输出到输入的延时(见图3).神经网络的输出延时保存后,通过外部反馈引入输入层,与输入样本共同学习,按一定的训练标准计算网络的实际输出值与期望输出值的误差,不断进行误差反向传播,从而调整网络各层权重,使误差达到最小,完成学习目的. 隐含层神经元的数目根据经验公式〔见式(1)〕进行确定[32,35].

图 3 NARX神经网络拓扑结构Fig.3 Topology architecture of NARX neural network

式中,h为隐含层神经元数目,n、m分别为输入层、输出层单元数,a为1~10之间的常数.
NARX神经网络训练采用列文伯格-马夸尔特(Levenberg-Marquardt,LM)算法[38-39],计算公式:

式中,ω为权重阈值参数,J为雅克比矩阵,JT为J的转置,μ为学习常数,I为单位矩阵,e为误差向量.
NARX神经网络建模的基本步骤主要包括:①初始化网络,包括网络参数的选择和设定;②训练,训练时应尽量防止网络过度拟合;③仿真,其中如何初始化网络和提高模型泛化能力对神经网络的构建十分关键.
1.4 NARX神经网络藻类预测模型性能评价
为了评价NARX神经网络藻类预测模型的预测性能,采用均方误差(MSE)和相关系数(R)对预测值和实际观测值进行对比分析. 均方误差反映训练输出值与目标值之间的误差,其值越小表示模拟效果越好;相关系数范围在0~1之间,其值越大说明模拟数据和实测数据相关度越高,模型的模拟精度也越高[32,34].
2 结果与讨论
为了探讨NARX神经网络藻类预测模型在千岛湖Chla浓度时序变化的预测情况,分别采用连续3 d的Chla浓度观测值以及连续7 d的Chla浓度观测值作为输入样本,未来0.5~7 d的Chla浓度作为输出,建立输入-输出之间的响应模型共28个.
模型采用3层神经网络,即输入层、隐含层和输出层各1层,其中将利用连续3 d Chla浓度预测未来0.5~7 d Chla浓度的预测模型定义为第1类模型,输入层为6个单元,输入向量Xi=(Ci,Ci+1, …,Ci+5),输出层为1个单元,输出值Yi=Ci+j(j=6,7,…,19);将利用连续7 d Chla浓度预测未来0.5~7 d Chla浓度的预测模型定义为第2类模型,输入层为14个单元,输入向量Xi=(Ci,Ci+1, …,Ci+13),输出层为1个单元,输出值Yi=Ci+j(j=14,15,…,27). 该研究指定隐含层神经元个数为10,延时阶数为3 d. 初始化权值及阈值取[-1, 1]之间的随机数.
经插补后,小金山监测断面2016年9月8日-2019年12月2日的Chla浓度数据共2 361个,按占总样本数量75%、15%和10%的比例,分为训练集、验证集和测试集. 其中,训练集样本在模型训练过程中输入到网络中,神经网络在完成初始化之后,根据输出值与标注值之间的误差不断进行权值和偏置值的调整;验证集样本不直接参与上述训练调整,主要用于测度在训练过程中网络泛化能力的表现,在泛化能力停止改进时停止训练,从而防止神经网络训练中发生过拟合现象,导致泛化能力的下降;测试集样本对训练过程不施加影响,而在训练期间及训练后作为独立于训练的样本数据,对神经网络的性能进行测试、分析及评价.
经过多次试验对比发现,两类模型在训练过程中训练集、测试集和验证集的试验效果均十分理想,相关系数在0.953~0.986之间,均方误差在1.387~4.483之间,模型训练性能较好,可用于预测.
以2019年1-7月数据作为预测数据输入已训练好的28个NARX神经网络进行计算,输出未来0.5~7 d的Chla浓度预测值,并与实际观测值进行比较,从而评价模型预测效果(见表1). 两类模型的预测性能总体比较稳定,相关系数保持在0.8~0.9之间,均方误差在15~30之间. 随着预见期的增加,两类模型的均方误差均呈上升趋势,相关系数呈下降趋势,但趋势平缓,符合神经网络的预测性能,即随着预测时间的增加,预测精度逐渐下降[23,32]. 相比而言,在未来0.5~4 d的预测中,第1类模型的预测精度优于第2类模型,即使用连续3 d的Chla浓度作为输入的预测模型精度较高;而在未来4.5~7 d的预测中,第2类模型的预测精度优于第1类模型.
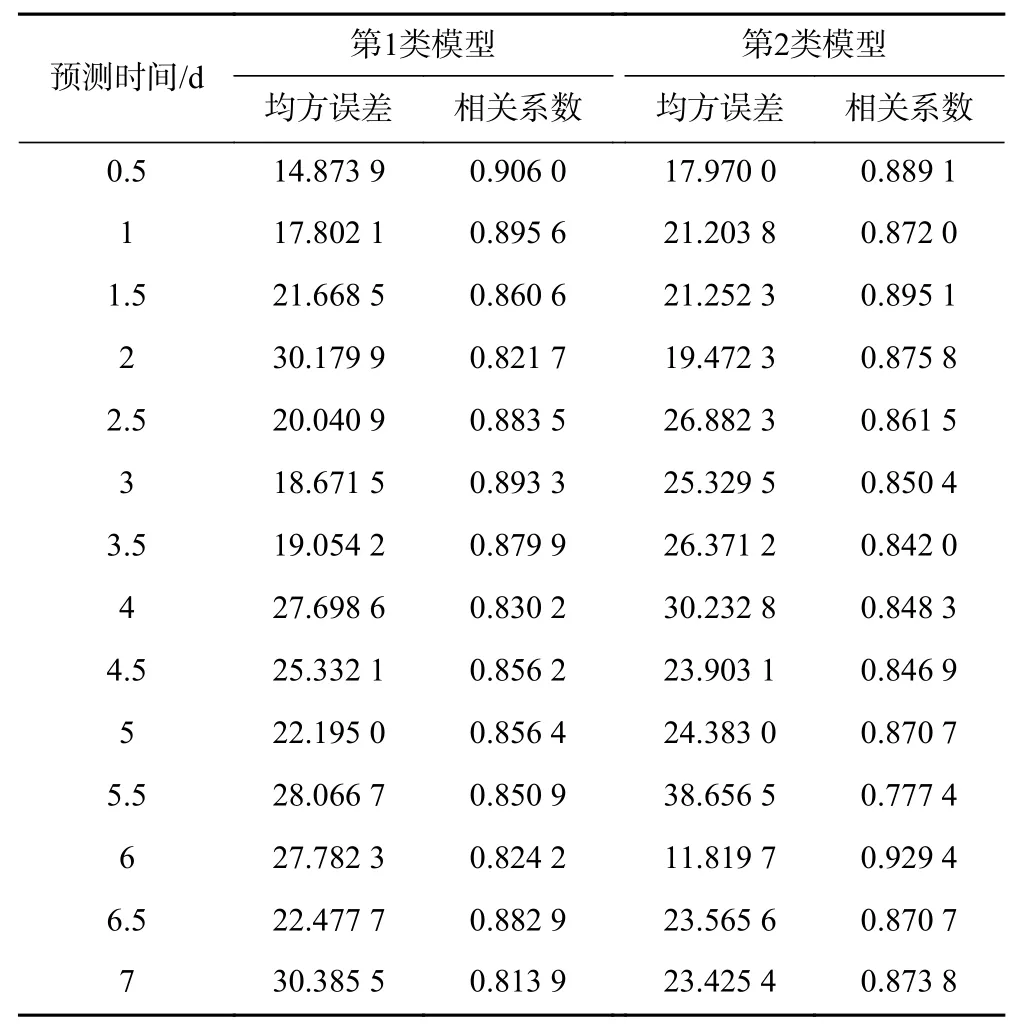
表 1 两类模型预测性能对比Table 1 Prediction performance of two NARX models
图4~6分别为第1类模型和第2类模型对于未来0.5、3和6 d Chla浓度预测值与观测值的对比. 由图4可见,对于未来0.5 d的预测,两类模型预测值与观测值的趋势变化情况基本相似,吻合程度较高,但在第2类模型中存在一些时刻预测值略小于实测值,整体预测程度不如第1类模型. 由图5可见,对于未来3 d的预测,两类模型均存在某些预测值小于实测值的情况,但第1类模型与实测值吻合程度良好,而第2类模型明显存在预测趋势平缓的现象,尤其是没有预测出6月Chla浓度的高值区,7月的Chla浓度存在明显的相位差. 由图6可见,对于未来6 d的预测,第2类模型的预测值与实测值吻合程度高于第1类模型,尤其是对5月后高低值的振荡趋势模拟较好,而第1类模型没有预测出6月以后Chla浓度的高值区.
在已构建的预测千岛湖水体富营养化的BP神经网络模型[22]中,为了预测Chla浓度的周尺度变化,采用了水温、pH、Chla浓度、透明度和总氮5个输入变量,并且随着输入变量减少为1个,模型训练过程中的相关系数降至0.744. 而NARX神经网络藻类预测模型仅用Chla浓度作为输入变量,得到了比BP神经网络高的预测精度,进一步说明NARX神经网络藻类预测模型在时间序列预测中的优势,以及减少输入参数可以降低输入参数带来的模型不确定性[23,40].

图 4 两类模型对未来0.5 d Chla浓度的预测值与观测值对比Fig.4 Performance of two NARX models forecasting the dynamics of Chla in the future 0.5 day

图 5 两类模型对未来3 d Chla浓度的预测值与观测值对比Fig.5 Performance of two NARX models forecasting the dynamics of Chla in the future 3 day

图 6 两类模型对未来6 d Chla浓度的预测值与观测值对比Fig.6 Performance of two NARX models forecasting the dynamics of Chla in the future 6 day
3 结论
a)基于输入样本不同而定义的两类NARX神经网络藻类预测模型预测性能总体比较稳定,预测值与实测值相关系数保持在0.8~0.9之间,均方误差在15~30之间,可以较为准确地预测未来0.5~7 d的Chla浓度值,说明NARX神经网络藻类预测模型对于千岛湖Chla时序变化的预测是可行的.
b)随着预见期的变化,模型性能不尽相同. 建议在实际应用过程中,采取二者相结合的方法,在未来0.5~4 d的预测中,使用连续3 d的Chla浓度作为输入的预测模型;在未来4.5~7 d的预测中,使用连续7 d的Chla浓度作为输入的预测模型.
c)相比于基于机理过程的藻类预测数值模型,基于数据驱动的NARX神经网络藻类预测模型结构简单,运行成本较低,具有较强的实用性和时效性. 如果采用其他点位的监测数据对所构建模型进行训练、测试和验证,同样可以实现对其他点位Chla时序变化的预测,因此又具有较好的可移植性.
d)目前预测获得的时间序列平滑性有待进一步提升,这主要是因为原始时间序列为非平稳序列,不仅包含较平稳的有用信息,还包含影响数据可靠性和预测精度的随机噪声. 在接下来的研究中,将针对时间序列的特性,继续构建基于小波分析的NARX神经网络藻类预测模型,进一步优化模型参数,提高Chla浓度的预测精度.
e)总体来讲,基于NARX神经网络的藻类预测模型是可靠的,可以用于千岛湖重点水域藻类生长的短期预测,为水华的监测预警系统构建提供借鉴与依据.
