采用蒸馏训练的时空图卷积动作识别融合模型
2022-04-24杨清山穆太江
杨清山,穆太江
清华大学计算机科学与技术系,北京 100084
0 引 言
动作识别有着广泛的应用,包括人机交互、视频理解与检索、场景理解和老人监护等,是计算机视觉一个活跃的研究领域。早期人们主要研究基于RGB数据、深度数据和光流数据等的动作识别,随着深度学习技术对人体姿势和关键点估计准确度的提升,催生了很多工具和设备(Cao等,2017,2021;Fankhauser等,2015),可以方便地估计人体骨架数据,从而吸引了众多的研究者研究基于骨架的动作识别。
骨架(skeleton)是人体结构和姿势的一种简单表示,每一帧骨架数据包含多个关键点(joints),不同时刻的骨架数据组合在一起构成一个骨架序列(skeleton series)即可表示一个动作。骨架数据由于简单、冗余信息少和计算快捷等特点,广泛用于人体动作识别。大多数方法采用与循环神经网络(recurrent neural network,RNN)、卷积神经网络(convolutional neural network,CNN)或者图卷积网络(graph convolutional network,GCN)相关的经典深度学习网络结构构建模型。GCN类的方法可以用邻接矩阵等显式地表示关键点的空间位置关系,并基于空间拓扑关系和时域信息设计模型中数据的更新方式。总体来说,与其他类型的方法相比,GCN类的方法在多个数据集上取得了更好的结果,更适用于基于骨架关键点的动作识别任务。然而,动作识别既要处理关键点空间上的位置信息,还要处理时序上的变化信息,目前很多前沿的GCN类方法的模型结构比较复杂,层数比较深,参数量较大,因此需要研究更加简单轻量化和更加鲁棒的模型。另外,关键点的坐标、角度和相机视野等都是重要的信息,不同形式的输入数据对模型准确率影响较大。在GCN类的方法中,Shi等人(2019a,2020)和Yan等人(2018)使用了用于模拟光流的motion数据以及joints和bone数据等,整体提高了识别准确率,但是单独使用某一种数据时模型的准确率较低。
基于当前方法存在的问题,本文研究如何将数据增强、知识蒸馏、模型融合和分组卷积等与深度学习相关的技术和方法更好地应用于该任务,在降低模型参数量的同时进一步提高模型的识别准确率。具体而言,用分组卷积替换全卷积设计时空卷积模型,降低模型的参数量;为了保证简单模型的准确性,模型训练时使用知识蒸馏的技术,用训练好的教师模型指导学生模型训练;受Shi等人(2019a,b)的启发,采用有向图卷积和自适应图卷积两种图卷积形式构建模型的空间卷积(spatial convolution)模块,使两种结构的子模型得以优势互补,结合仿射变换的数据增强方式,最后训练得到一个多股并联的融合模型。
本文有3个主要贡献:1)使用分组卷积等技术设计了轻量的时序卷积模块,降低了模型参数量。首次将知识蒸馏应用于基于骨架数据的动作识别问题,保证参数量减少后模型的准确性。2)利用仿射变换等数据增强技术增加了新的输入数据形式,为模型增加了额外观察动作的角度,增加了模型的鲁棒性。3)提出了一个多股并联的融合模型,在NTU RGB + D数据集上有更高的识别准确率。
1 相关工作
1.1 基于骨架的动作识别方法
基于骨架的动作识别方法可以分为传统机器学习类的方法和深度学习类的方法。对于传统机器学习类的方法,通常需要手动设计用于动作分类的特征,然后用其他常规的机器学习的方法对动作进行识别和分类。Climent-Pérez等人(2012)使用遗传算法(genetic algorithm)选择对不同动作有贡献的点,然后使用K均值聚类(K-means)方法分类动作;Wang等人(2013)根据身体部位将关键点分为不同的组,然后使用数据挖掘技术在时间和空间域上挖掘位姿信息,并且使用支持向量机对动作进行分类。此类传统的机器学习相关算法需要手动设计分类特征,表达能力较弱,基本无法胜任分类类别多、数据集庞大的分类任务。深度学习类的方法又可以分为RNN类的方法、GCN类的方法和其他CNN类的方法。RNN类的方法中,研究最多的是使用长短期记忆(long short-term memory,LSTM)结构解决该问题,前人设计了包含不同LSTM变体结构的模型,如ST-LSTM(spatio-temporal long short-term network)(Liu等,2016)、Part-aware LSTM(Shahroudy等,2016)等。LSTM结构的模型在处理语音和文本等时序数据类的任务,例如语音识别、文本翻译等任务中表现突出,尽管此处的骨架数据一定程度上也可以看做时间序列的数据,所不同的是,动作识别中,非常依赖骨架数据在空间和时间各个维度的变化,使此类方法难以发挥其处理时间序列数据的优势。其他CNN类的方法,有使用3维卷积的如Two-Stream 3DCNN(Liu等,2017a),或者将骨架数据通过不同方式排列以及设计定制化的卷积核大小,从而满足2维卷积操作的方法,如TCN(temporal convolutional networks)(Kim和Reiter,2017)、Synthesized CNN(Liu等,2017b)等。但因为骨架关键点在人体中是有自然连接关系的,这类方法一个共同的不足就是没有很好地利用骨架数据这种“内在信息”;另外,其他使用3D卷积的方法一个比较明显的劣势就是3D卷积导致模型参数多,计算代价大。而GCN是最近两年在这一问题上使用最多的一类方法。
1.2 图卷积动作识别网络
Yan等人(2018)提出的ST-GCN(spatial temporal graph convolution networks)模型,首次将基于图的卷积网络应用于基于骨架的动作识别这一任务,与其他类型的方法相比,显著地提高了在NTU RGB+D数据集上的准确率,证明了图卷积网络在这一任务上强大的表达和生成能力。自此以后,图卷积成为研究该问题的热门方法,不同结构的图卷积模型相继出现。Shi等人(2019b)提出使用端到端的方式学习一个数据驱动的矩阵,作为表示骨架空间连接关系拓扑结构的邻接矩阵的补充,从而使这种拓扑结构更具弹性。Shi等人(2019a)使用一个无环的有向图表示骨架的拓扑结构,设计了一个有向图卷积网络用于提取和更新关键点(joints)和连接关键点之间的骨(bone)的特征,并根据这些特征进行动作识别。Shi等人(2020)在图卷积网络层中增加了注意力(attention)模块,帮助网络更加注意输入数据中重要的点、帧和特征。Wu等人(2019)在图卷积模型中设计了一个新的残值层和稠密链接块,帮助模型更好地学习时域和空域上的有效信息。这些方法都证明了图卷积在基于骨架的动作识别任务中的有效性。
1.3 知识蒸馏
模型蒸馏训练是“机器教机器”学习范式的一种深度学习模型训练方式。蒸馏知识(Hinton等,2015)的目的是让复杂度低的模型学习复杂模型处理任务的方式,从而将知识由复杂模型转移到简单模型用于解决问题,降低模型的计算量。另一个相关的概念是特权信息(privileged information),Vapnik和Izmailov(2015)介绍了使用特权信息训练的方法,对于“特征—标签”数据,在训练时加上特权信息成为“特征—特权信息—标签”数据用于训练,而用于测试的“特征—标签”数据则并不包含这种特权信息。通过这种方式训练的模型在测试集上能有更高的准确率。综合这些思想,用模型A蒸馏训练模型B的过程为:使用模型A在“特征—标签”数据上训练得到教师模型,然后用教师模型全连接层之前的特征作为特权信息添加到训练数据。最后,“特征—特权信息—标签”数据用于训练模型B,模型B为最终的测试模型。
2 模型构建
模型融合是在深度学习各个领域使用较多的一种策略,其目的是融合一些表达力较弱的分支网络,以构建一个全局优化的整体模型。在基于骨架的动作识别这个问题中,图卷积是有效的一种方法,但不同结构的图卷积模型提取的特征,以及模型做出识别判断时依据的特征信息不一样,融合模型能起到优势互补的作用。
模型的整体示意图如图1所示,模型由有向图卷积子模型(directed graph convolutional sub neural network,DGCNNet)和自适应图卷积子模型(adaptive graph convolutional sub neural network,AGCNNet)两种结构的图卷积子模型组成,其中,DGCNNet和AGCNNet中的空间卷积模块分别采用与有向图神经网络(directed graph neural networks,DGNN)(Shi等,2019a)和自适应图卷积神经网络(adaptive graph convolutional networks for skeleton-based action,AGCN)(Shi等,2019b,2020)相同的图卷积模块,时序卷积模块使用分组卷积设计,子模型的参数量较少。

图1 融合模型示意图Fig.1 The proposed ensemble model
2.1 DGCNNet子模型
DGCNNet是本文提出的融合模型中的一个子模型,包含10层light-DGC(light directed graph convolutional)基础层,结构如图2所示,虚线框表示当前后张量通道(channel)数不匹配的时候使用卷积,其中的空间卷积模块DGC模块采用与DGNN(Shi等,2019a)相同的图卷积结构,用于在空间上更新骨架信息。除此之外,在light-DGC基础层中进行了如下设计:
1)在空间卷积模块之后串联自注意(self-attention)模块。在深度学习神经网络中,自注意机制(Parikh等,2016)是一种用来计算输入数据不同位置特征重要性的机制,每个自注意模块学习一个权重张量,用于表示各位置特征的“重要程度”,已经成功应用于语音识别、文本翻译以及计算机视觉的多种任务中。具体而言,在空间卷积模块之后串联了3个自注意模块,其作用是为特征图在时间、空间和特征3个维度分别学习一个系数向量,用于增强特征图中重要的点、重要的帧和重要的特征通道对模型分类中的影响。
2)为了更好地学习时间上的变化信息,时域维度的卷积核通常较大,使用普通卷积导致模型的参数量较大,因此,用于更新数据时域信息的light-TCN模块中使用参数量较少的分组卷积替换普通的全卷积。light-TCN模块的结构如图3所示,使用一个卷积核为(9,1)的逐通道的2维卷积和一个核为(1,1)的普通2维卷积处理特征图的时域信息,替换卷积核为(9,1)的普通2维卷积。使用该分组卷积策略后,用Ci和Co分别表示输入和输出特征图通道数,在只考虑卷积的情况下,该模块的参数量由Co×Ci×9×1减少为Co×1×1×9+Co×Ci×1×1。
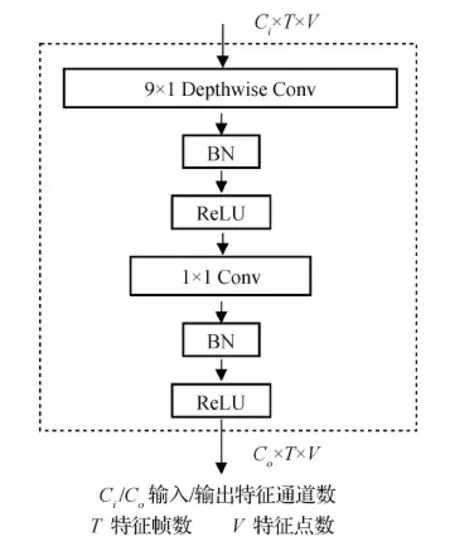
图3 light-TCN模块Fig.3 light-TCN block
2.2 AGCNNet子模型
用邻接矩阵表示人体骨架关键点之间的连接关系,并基于连接关系设置卷积方式,各点的数据由与其相连的点更新,是另外一类使用广泛的图卷积模型。为了能够在模型训练过程中更加关注重要的帧、重要的点和重要的特征,Shi等人(2020)在模型中引入了注意力增强模块。受Shi等人(2019b,2020)工作的启发,用自适应图卷积作为模型的空间卷积模块,构建融合模型AGCNNet。AGCNNet由10层light-AGC基础层构成,light-AGC基础层如图4所示,虚线框表示当前后张量通道数不匹配的时候使用卷积。与Shi等人(2020)的方法相比,light-AGC基础层使用参数更少的light-TCN模块更新特征图的时域信息,因为在Shi等人(2020)的方法中,用来处理时域的卷积模块的卷积核较大,导致模型的参数量大,此处将其替换为light-TCN模块,显著降低了模型的参数量。
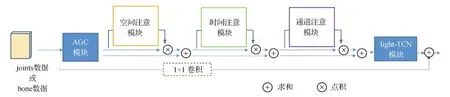
图4 light-AGC层Fig.4 light-AGC layer

2.3 知识蒸馏模型训练

图5 模型蒸馏训练Fig.5 The framework of the distillation training
(1)
式中,crossEntropy()表示计算交叉熵损失,MSE()表示计算均方差损失。
蒸馏训练时,用DGCNNet和AGCNNet模型作为学生模型,用AGCN和DGNN分别作为教师模型蒸馏训练子模型。通过比较学生模型与教师模型的准确率证明使用的蒸馏训练方法的有效性。除了这种教师模型与学生模型结构不同的情况之外,本文也设置了大量的用同一种模型结构,在不同的数据上分别训练教师模型和学生模型的跨数据的蒸馏训练实验,用于证明蒸馏训练的有效性。对AGCN进行跨数据蒸馏训练时,首先使用在joints数据上训练得到的模型作为教师模型,然后用bone数据蒸馏训练学生模型;对DGNN模型做跨数据蒸馏训练时,首先使用骨架数据训练教师网络,然后用仿射变换后的骨架数据蒸馏训练学生网络。
2.4 数据增强
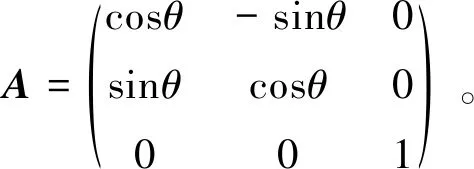
考虑到在NTU RGB+D数据集采集数据时,相机设置的偏移角度为±45°,为了不失一般性以及简化运算,此处设置θ=60°,b=0。
2.5 模型融合

(2)
最终的融合模型如图1所示。
3 实验分析
实验在NTU RGB + D数据集上进行,该数据集有cross-subject和cross-view两种评判标准。通过在两种标准下设置实验,训练和评估本文提出的模型,并与前沿的方法对比,以说明方法的有效性。
3.1 数据集介绍
NTU RGB+D数据集是使用3个微软的Kinect v2相机拍摄的动作识别相关的数据集。整个数据集包含60类动作,超过56 000个动作实例和400万帧数据。每个动作实例包含RGB视频、深度数据、人体关键点数据和红外数据。其中,本文使用的人体关键点数据为:每个人体有25个关键点,每个关键点表示为相机坐标系的3维空间点。NTU RGB + D提供两种训练和评判的标准:CS(cross-subject)和CV(cross-view),前者使用20个志愿者的数据作训练集训练,剩下20个志愿者的数据作测试集评估模型;后者则使用其中两个视角拍摄的数据作训练集训练,剩余一个视角拍摄的数据作测试集评估模型(Shahroudy等,2016)。对于输入数据需要做一些预处理,包括坐标变换使动作主体位于视野中央,将所有动作序列扩展至300帧等,处理过程与Shahroudy等人(2016)和Shi等人(2019a)的方法相同,得到形状为C×T×V的多维joints数据,其中C为坐标维数、T为帧数、V为点数。除此之外,模型还用到了连接关键点的bone数据。bone数据的产生方式与Shi等人(2019a,2020)的方法相同。
3.2 参数设置
模型采用Pytorch深度学习框架实现。对于DGCNNet和AGCNNet子网络,分别使用10层light-DGC基础层和10层light-AGC基础层搭建模型,两支子网络的输出通道数相同,10层的输出通道数分别为(64、64、64、64、128、128、128、256、256、256)。训练数据批大小为32,优化器使用随机梯度下降法(stochastic gradient descent,SGD),学习率初始化为0.1。训练教师网络时,在训练到40和90代后将学习率缩小为1/10,模型总共训练120代。蒸馏训练学生网络时,先后在训练到30和40代后将学习率缩为1/10,模型总共训练60代。训练前10代,反向传播不修改DGCNNet和AGCNNet网络中表示连接关系的矩阵的值,10代以后正常训练。对于蒸馏训练时损失函数中α的取值,通过实验确定,用预训练好并固定权重的AGCN模型作教师模型,以AGCNNet作为学生模型在bone数据上进行训练和测试,不同的α取值及对应的测试准确率如图6所示,根据实验结果,将所有子模型的蒸馏训练的α值都设置为50。

图6 模型准确率与损失函数系数α的关系Fig.6 The relationship between model accuracy and loss function coefficient α
3.3 学生模型与教师模型对比
学生模型使用轻量的时序卷积模块,显著降低了模型参数,同时利用模型蒸馏训练的方法使模型在降低参数量的情况下拥有较高的准确率。对DGCNNet子模型的蒸馏训练,首先在骨架数据joints+bone上训练DGNN,由于原文(Shi等,2019a)未公开源码,此处使用的DGNN网络单层结构如图5中教师网络所示,可能与原文代码有微小差别。然后用其蒸馏训练学生模型DGCNNet。对AGCNNet子模型的蒸馏训练,首先在bone数据上训练教师模型AGCN,然后用教师模型蒸馏训练学生模型AGCNNet。对蒸馏得到的AGCNNet和DGCNNet学生模型与对应的教师模型在参数量、收敛速度和top1准确率3项指标上进行对比,结果如表1所示。从表1可以发现,两种结构的学生模型的参数量都有显著降低(减少约50%),通过蒸馏训练的模型准确率比没有蒸馏训练的高,甚至比参数量大的教师模型的准确率高。这是因为学生模型中使用了轻量的时域卷积模块,降低了模型的参数量,而且训练时通过损失函数增加了来自教师模型的约束,利用模型蒸馏训练的方法保证了学生模型的识别准确率。

表1 学生模型与教师模型对比Table 1 Comparison of student model and teacher model
模型时域卷积模块量化对比如表2所示,g表示分组卷积的分组数。由于DGNN未公开源码,用做教师网络的DGNN模型在具体实现时,时域卷积使用两个核大小为9×1的2维卷积分别处理joints和bone数据。表中展示的是模型最后一层的参数,其他层同理。

表2 模型最后一层时序卷积层参数对比Table 2 Comparison of last temporal convolution layer in student model and teacher model
3.4 数据增强的作用
为了提高融合模型的准确率,本文使用仿射变换数据增强技术,其效果相当于为模型增加了观察动作的视角,增加模型的鲁棒性。实验设置时,分别用仿射变换前后的骨架数据joints + bone作为输入,采用蒸馏训练方法,分别对DGCNNet和AGCNNet进行蒸馏训练。使用不同输入进行训练得到的子模型的结果,以及将各子模型融合得到多股并联的融合模型的结果如表3所示。实验数据表明,利用仿射变换做数据增强能够帮助模型提高准确率,同时进一步证明了本文提出模型的有效性。
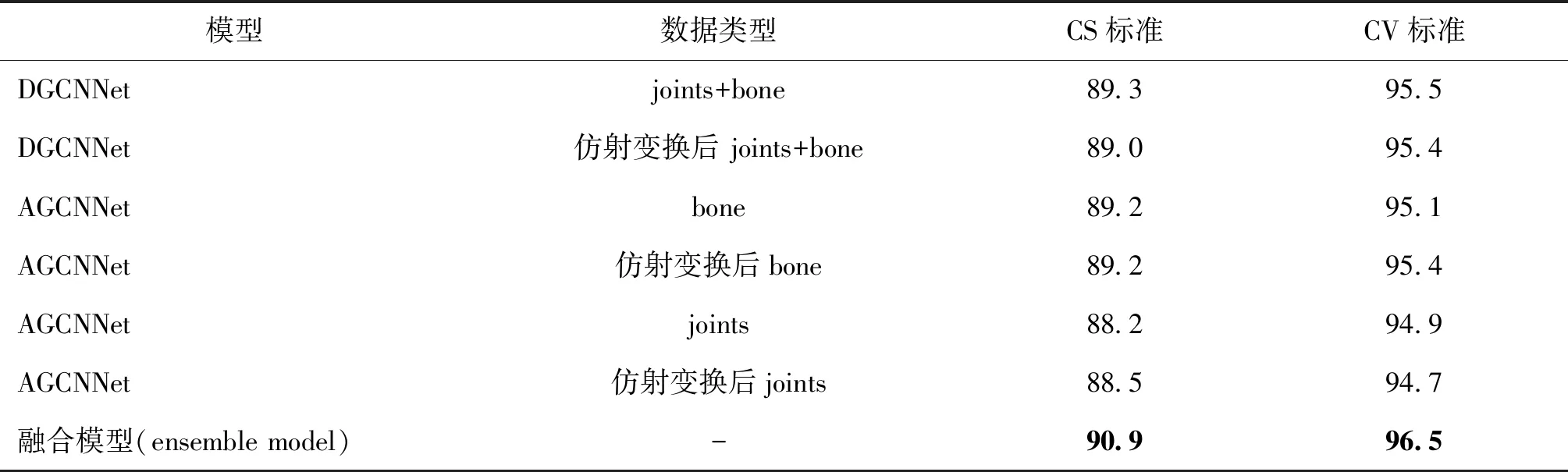
表3 本文模型在不同输入数据上的识别准确率Table 3 The accuracy of our model on different input modalities /%
模型对NTU RGB + D数据集中各个类别的识别准确率如图7所示,有些动作例如falling、standing up、jump up在动作发生过程中,骨架信息在空间和时间维度变化很大,这类动作通过融合不同结构的图卷积网络(AGCNNet和DGCNNet)能够准确识别;而有的动作例如writing、playing with phone等,骨架信息变化不大,对于这类动作,尽管模型融合了不同结构图卷积网络,并使用了数据增强,识别的准确率依然不高,需要更深入的研究。
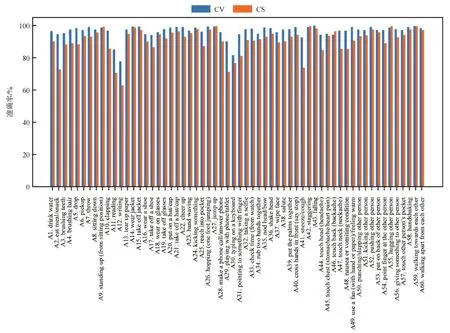
图7 融合模型对NTU RGB+D数据集各类别动作的识别准确率Fig.7 Each class accuracy of the proposed ensemble model on NTU RGB+D dataset
3.5 蒸馏训练的作用
模型蒸馏训练是本文提高模型准确率的一个重要策略,蒸馏训练的损失函数包含均方误差和交叉熵两项,均方误差项的系数通过实验确定,准确率与系数的关系如图6所示,根据实验结果,损失函数中均方误差项的系数取值为50。通过大量的实验,证明了蒸馏训练的有效性,详细数据见表1和表4。表1展示了使用蒸馏训练的学生网络有更少的参数量和更高的准确率,而且蒸馏训练的收敛速度快,训练代数少。表4展示了使用相同结构的模型在不同数据上蒸馏训练的效果,训练结果显示通过蒸馏训练能够提高模型的准确率。另外,蒸馏训练也有一定的局限性,因为在模型训练阶段需要首先训练教师网络,训练时增加了一定的计算代价。
3.6 与其他方法对比
为了验证本文提出的融合模型的性能,与其他前沿方法进行对比。由于训练使用的NTU RGB+D动作识别数据集较大,只有基于深度学习的相关算法表现出了优异性能,因此选择基于深度学习的算法进行对比,这些算法大致可以分为基于RNN的深度学习算法、基于CNN的深度学习算法以及GCN相关的深度学习算法3类,对比结果如表5所示。本文模型在数据集的CS和CV两种评判标准下准确率分别达到了90.9%和96.5%,明显优于基于GCN的基准方法(Yan等,2018)的81.5%和88.3%,与其他优秀的前沿方法相比,同样有比较强的竞争力。另外,与其他方法一样,模型在CS评判标准下的准确度比在CV评判标准下的低,这与两种标准的设置是密切相关的,在CV标准下,测试集和训练集分别是从不同角度同步拍摄的相同动作,而在CS标准下,同一个动作在训练集和测试集由不同的人完成,难以保证一致性,再加上骨架估计模块的误差导致其比CV标准更具挑战性。尽管如此,本文提出的融合模型在CS评判标准下测试集的识别准确率依然达到90.9%,是所有实验方法中的最优结果。

表5 不同方法的准确率对比Table 5 Comparison of accuracy among different methods /%
4 结 论
本文首先采用两种不同结构的图卷积构建的空间卷积模块,结合通道、空间、时间3个维度上的自注意模块,并使用逐通道的分组卷积设计的时序卷积模块构建了多支轻量化的子模型。然后用蒸馏训练的方法从参数量大的教师模型中蒸馏知识,训练这些学生子模型。为了增加模型的鲁棒性,训练和测试时使用了仿射变换等数据增强技术,用于增广输入数据。最终,训练得到了6支更轻量更准确的子模型,并进一步用其融合构建了一支参数量较少且准确性和鲁棒性更好的多股并联融合模型。
在NTU RGB+D数据集上采用两种评判标准对本文提出的融合模型进行了大量实验,实验结果表明,模型的准确率比同样是基于图卷积的基准方法有了很大提高,优于众多现行的基于骨架的动作识别前沿算法。在未来的工作中,拟研究解决骨架信息变化小的动作识别问题。这类动作识别与环境和周边物体有密切关系,需要使用其他数据例如RGB数据结合物体检测和识别等技术构建人物与环境和周边物体的关系图。
致 谢研究过程中模型训练使用的服务器等研究设备得到了“北京市高等学校工程研究中心”和“清华—腾讯互联网创新技术联合实验室”的支持,在此表示感谢。
