残差密集结构的东巴画渐进式重建
2022-04-24蒋梦洁钱文华徐丹吴昊柳春宇
蒋梦洁,钱文华,徐丹,吴昊,柳春宇
云南大学信息学院,昆明 650504
0 引 言
图像分辨率体现了图像反映物体细节信息的能力,相较于低分辨率(low-resolution,LR)图像,高分辨率(high-resolution,HR)图像通常包含了更丰富的边缘和纹理细节。单图像超分辨率(single image super-resolution,SISR)重建是经典的计算机视觉问题,旨在从一个给定的低分辨率图像中恢复高分辨率图像(周登文 等,2019)。目前,超分辨率重建技术已较广泛应用于人脸图像(王欢 等,2020)、高光谱图像(Fu等,2019)和医学图像(Isaac和Kulkarni,2015)等,且都得到了良好的重建效果。
东巴画是发源于丽江东巴地区的一种具有独特民族风味的绘画,是纳西族东巴文化艺术的重要代表。如图1所示,东巴画具有特殊的绘画手法和鲜艳的绘画色彩,绘画形式以线条为主,同时十分注重色彩的渲染和运用,极具艺术性和研究价值。然而,由于东巴画年代久远,采集设备受历史条件限制,导致现存东巴画数字图像普遍分辨率较低。低质量的东巴画一定程度上限制了针对东巴画的边缘检测、语义分割、数字识别和场景识别等计算机视觉任务的研究。Dai等人(2016)研究证明,提高图像分辨率有助于其他计算机视觉任务的研究。因此,采用超分辨率技术提高东巴画数字图像分辨率显得尤为重要,这不仅有利于东巴画的数字化保护和展示,亦对上述其他计算机视觉任务有促进作用。

图1 东巴画实例Fig.1 Examples of Dongba paintings
早期的超分辨率算法采用基于采样理论的插值技术,例如通过水平方向和垂直方向分别进行插值而获得重建结果的双线性插值(Li和Orchard,2001)。这类方法简单、高效、实时性强,在连续区域和低频信息区域有着较为理想的效果,然而当重建图像中含有大量的边缘、纹理等高频信息区域时,便会出现模糊和锯齿效应,即图像的边缘出现不平滑的棱角。东巴画图像含有繁杂的线条和丰富的纹理等高频信息,采用传统方法重建往往得不到理想的重建效果。
随着深度学习研究和应用的不断深入,针对自然图像的超分辨率重建取得了较大进展。Dong等人(2016a)率先提出利用卷积神经网络实现可见光图像的超分辨率重建,通过学习高、低分辨率图像对之间的映射关系进行重建。为了得到更好的效果,研究者不断增加网络深度,以期得到更好的网络模型。然而,实验结果表明,随着网络深度的不断增加,其损失值不仅没有降低,反而持续增大,并且容易出现网络层之间梯度重复相乘导致梯度指数级增长的梯度爆炸现象,以及梯度趋近于0导致网络无法更新参数的梯度消失现象。为了解决上述问题,专家学者进行了大量研究。Kim等人(2016)将残差网络引入超分辨率,残差网络中的残差连接(He等,2016)能有效避免梯度消失,使网络仅学习高、低分辨率图像之间的高频残差部分,加快网络收敛速度。Tong等人(2017)将密集网络引入超分辨率,密集网络中的密集连接(Huang等,2017)通过通道连接进行特征融合,增强特征复用,进一步减缓了梯度消失。随着研究的深入,人们发现仅以最小均方误差(mean-square error,MSE)为代表的像素损失作为损失函数,虽然能够获得较高的峰值信噪比(peak signal to noise ratio,PSNR),然而重建结果因为缺乏高频细节而导致纹理过于平滑。为了解决重建结果过于平滑问题,Johnson等人(2016)提出利用感知损失取代最小均方误差,Ledig等人(2017)将生成对抗网络(generative adversarial network,GAN)运用到超分辨率重建问题上,在视觉效果和清晰度等方面均有提高。然而,采用基于深度学习的方法对东巴画重建存在以下困难:1)基于深度学习的方法需要大量的高质量样本进行训练,而高质量东巴画样本资源匮乏;2)现有方法大都是针对自然图像的超分辨率重建研究,而东巴画大多以木片、纸牌和墙壁为载体,相对于自然图像而言不存在空间感、距离感、立体感和纵深感,也没有自然光线带来的光影效果;另一方面,东巴画内容丰富,蕴含形象较多,线条粗细有致、疏密相间,色彩较自然图像而言更为鲜艳。东巴画独特的艺术风格使得现有针对自然图像的超分辨率网络模型对东巴画的线条、色块,以及材质的重建效果不理想;3)上述方法都仅在一个阶段进行上采样操作,导致在大尺度因子重建时,东巴画图像的高频细节容易丢失。
综上所述,对含有丰富高频信息的东巴画进行大尺度因子重建时,现有方法不能取得理想结果。为此,本文提出一种针对东巴画的超分辨率网络(Dongba super-resolution network,DBSRN),采用多级子网络级联的方式,在一次大尺度重建的前馈过程中产生多个中间SR(super-resolution)预测。通过多个中间预测值对最后的重建结果进行约束,从而由小到大依次渐进式地重建出不同尺度的东巴画,有效改善了大尺度重建过程中存在的结果模糊、高频细节丢失等问题。在每一级子网络中,分别进行浅层特征提取和以残差密集结构(Zhang等,2018)为核心的深层特征提取,从低分辨率东巴画中提取东巴画的纹理、边缘线条等浅层特征和较为抽象的深层特征进行融合,在较少的东巴画数据集中提取更丰富的东巴画特征用于重建,以保留东巴画线条疏密相间、色块丰富多样的艺术风格。此外,为了提高重建东巴画的视觉效果,本文在DBSRN的基础上引入感知损失和对抗损失进行对抗训练,进一步提升了重建东巴画的清晰度。
1 本文方法
1.1 网络整体结构
DBSRN整体结构如图2所示,整个网络包括L级超分辨率子网络,每级超分辨率子网络上采样因子为2,整个网络上采样因子为2L,前一级超分辨率子网络的输出是后一级超分辨率子网络的输入。由于DBSRN中每一级子网络的结构完全相同,因此在子网络间采用递归结构,各级子网络共享参数。设输入DBSRN的LR东巴画图像为ILR,则经过L级子网络的输出为ISR (×2L)。

图2 DBSRN结构Fig.2 Structure of DBSRN
1.2 子网络结构
基于深度学习的超分辨率方法一般分为特征提取和重建两个阶段。Dong等人(2016b)和Tong等人(2017)都采用大量的卷积层进行特征提取,而重建阶段只有少量的卷积层。因此重建结果取决于特征提取质量,特征提取得越充分,重建效果越好。其次,网络越深,提取到的特征越抽象。采用卷积层的链式叠加会导致前端卷积层提取的浅层特征丢失,仅有较为抽象的特征用于重建。因此,在每一级的超分辨率子网络中分别设计浅层特征提取模块(shallow feature extraction,SFE)和深层特征提取模块(deep feature extraction,DFE)提取不同层次的特征,然后在全局特征融合模块(global feature fusion,GFF)中将提取的特征采用通道连接、恒等映射等方式进行特征融合,避免特征随着网络的加深丢失。最后,将特征图输入上采样模块(upsampling module,UPM)进行重建。DBSRN子网络结构如图3所示。
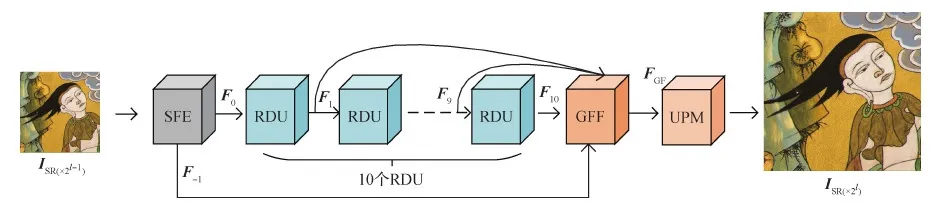
图3 DBSRN子网络结构Fig.3 Structure of DBSRN sub-network
设l为网络级数,ISR(×2l-1)表示第l-1级子网络输出,即第l级子网络输入,ISR(×2l)表示第l-1级子网络重建结果,则每一级超分辨率子网络重建过程如下:
1)浅层特征提取,即
F0=HSFE(ISR(×2l-1))
(1)
2)深层特征提取,即
F10=HDFE(F0)=HRDU,10(…HRDU,d(…(HRDU,1(F0))…)…)
(2)
3)全局特征融合,即
FGF=HGFF(F-1,F1,F2,…,F10)
(3)
4)上采样,即
ISR (×2l)=HUPM(FGF)
(4)
式中,HSFE表示浅层特征提取模块,输出的F0作为深层特征提取模块的输入。HDFE代表深层特征提取模块,包含10个残差密集单元(residual dense unit,RDU),HRDU,d代表第d个残差密集单元。HGFF代表全局特征融合模块,融合后得到FGF作为上采样模块的输入,HUPM代表上采样模块。
1.2.1 浅层特征提取模块
如图4所示,本文将3种不同大小卷积核提取的不同尺度浅层特征进行拼接,用于提取输入东巴画图像的纹理和边缘等底层特征。具体为
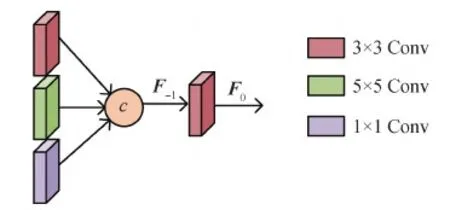
图4 浅层特征提取模块结构Fig.4 Structure of shallow feature extraction module
F-1=c(W1×1[ILR],W3×3[ILR],W5×5[ILR])
(5)
式中,W1×1、W3×3、W5×5分别表示卷积核为1×1、3×3、5×5的卷积层权重,[]表示输入卷积层进行卷积操作,c表示通道维度上的连接。然后将浅层特征F-1进行卷积操作,并作为深层特征提取模块的输入,具体为
F0=W3×3[F-1]
(6)
1.2.2 深层特征提取模块
深层特征提取模块由10个残差密集单元(RDU)组成,用于提取深层的东巴画特征信息。每一个RDU将前一个RDU提取的特征图映射到更高层的特征空间。随着网络结构的加深,获取的特征图越来越抽象。
RDU结合残差连接与密集连接,促进网络各层的信息流通,增强了特征复用。每一个RDU内部结构如图5所示,包含6个3×3卷积层以及一个1×1卷积层,3×3卷积层用于特征提取,1×1卷积层用于降维。Fd-1和Fd分别表示当前RDU的输入和输出,第e(e≤6)个3 × 3卷积层的输出表示为

图5 残差密集单元结构Fig.5 Structure of residual dense unit
Fd,e=σ(Wd,e[c(Fd-1,Fd,1,…,Fd,e-1)])
(7)
式中,Wd,e表示当前RDU中第e个卷积层的权重,σ表示ReLU激活函数。若将输入当前RDU的特征图Fd-1数量表示为g0,增长率表示为g,则c(Fd-1,Fd,1,…,Fd,e-1)表示将数量为g0+(e-1)×g的特征图在通道维度进行连接。
经过6个卷积层的特征提取后,特征图数量为6×g,将其与前一个RDU的输出特征图数量g0进行通道连接,再输入1 × 1的卷积层进行降维,则
Fd′=W1×1[c(Fd-1,Fd,1,…,Fd,6)]
(8)
最后,将Fd-1和Fd′进行元素级相加,得到当前RDU的输出Fd,即
Fd=Fd′+Fd-1
(9)
1.2.3 特征融合模块
不同深度的特征携带不同尺度的感受野信息,随着网络深度的增加,每个RDU提取的特征会逐渐分级,且越来越抽象,这些特征对图像重建提供了重要信息。因此本文将所有RDU提取的特征融合,在通道维度上进行连接,即
FDF=W3×3[W1×1[c(F1,F2,…,F10)]]
(10)
式中,c代表通道连接,F1,F2,…,F10代表10个RDU提取的特征,W1×1代表1×1卷积层权重,用于通道连接后的降维,W3×3代表3×3卷积层权重。同时,为了避免浅层特征丢失,本文将浅层特征提取模块提取的浅层特征F-1与FDF进行恒等映射,进一步将东巴画的浅层特征和深层特征进行融合,融合后输出FGF,即
FGF=FDF+F-1
(11)
1.2.4 上采样模块
上采样模块由亚像素卷积层(Shi等,2016)和两个卷积层组成。Dong等人(2016b)和Tong等人(2017)均采用反卷积对图像进行上采样,但是在反卷积时有大量补零操作,会造成图像细节丢失,因此本文采用亚像素卷积层进行上采样。上采样模块的输入FGF特征通道数为G0,FGF首先输入一个卷积层,将特征通道数变为G0×r×r(r表示上采样因子,此处r=2)。之后输入亚像素卷积层,将每个像素的r2个通道重新排列成一个r×r的区域,G0r2×H×W大小的特征图重新排列为G0×rH×rW,最后用一个卷积层将图像重建为3×rH×rW大小输出。
1.3 损失函数
Dong等人(2016b)和Tong等人(2017)都将MSE为代表的像素损失作为损失函数,在获得较高PSNR的同时,重建结果因为缺乏高频细节而导致纹理过于平滑(Johnson等,2016)。为了让重建的东巴画更加清晰逼真,本文先使用像素损失训练DBSRN,然后在像素损失的基础上分别引入感知损失以及对抗损失联合训练,得到以生成对抗网络为框架的东巴画超分辨率网络(Dongba super-resolution generative adversarial network,DBGAN)。DBGAN网络结构如图6所示。若将像素损失表示为Lpix,感知损失表示为Lper,对抗损失表示为Lgan,则DBGAN损失由感知损失、像素损失和对抗损失组成,即

图6 DBGAN结构图Fig.6 Structure of DBGAN
LG=αLpix+βLgan+Lper
(12)
式中,α和β为损失权重。
1.3.1 像素损失
L1损失和L2损失是常用的像素级损失,但Zhao等人(2017)的研究表明,L2损失会过度惩罚两图较大的差异,破坏了图像中基本的纹理和局部结构,而L1损失较好地保留了纹理结构信息,因此本文用L1损失作为像素损失。对于上采样因子为2L的DBSRN,有L级超分辨率子网络。本文将原高分辨率东巴画下采样L-1次,每次下采样2倍,作为其对应阶段的标签,不同尺度的标签共同指导东巴画的重建。像素损失表示为
(13)

1.3.2 感知损失
由于逐像素优化的方式忽略了图像的全局相似性,本文引入感知损失Lper。感知损失通过最小化重建SR图像与HR图像在语义级别上的差异,提高SR图像与HR图像之间的感知相似性,进而提高SR图像的视觉质量。Lper在预训练好的VGG16 (Visual Geometry Group 16-layer net)激活层上定义,最小化两个激活特征之间距离,具体为
(14)
式中,φi表示VGG16中第i层。φi(ISR(×2l))表示第l级子网络重建的东巴画从VGG16第i层提取的特征,φi(IHR(×2l))表示第l级子网络的标签从VGG16第i层提取的特征。与像素损失相同,总的感知损失为各个子网络感知损失的和。
1.3.3 对抗损失
Wang等人(2018)的研究证明,生成对抗网络应用于超分辨率领域能使生成的图像更加清晰逼真。因此本文以DBSRN作为生成器,在此基础上加入鉴别器进行对抗训练。鉴别器是一个二分类器,结构如图7所示,主要参数配置如表1所示。

表1 鉴别器主要参数配置表Table 1 Main parameters for discriminator

图7 鉴别器结构图Fig.7 Structure of discriminator
生成器重建出与真实高分辨率近似的图像,鉴别器判定该图像是真实高分辨率图像或是由生成器合成的图像,彼此对抗训练引导DBSRN生成更为逼真的高分辨率东巴画。基于Ledig等人(2017)的方法构建对抗损失,具体为
(15)
式中,GθG(ILR)表示DBSRN网络生成的东巴画,DθD(GθG(ILR))表示判断GθG(ILR)为真实高分辨率东巴画的概率。
2 实 验
2.1 数据集
为了使网络模型对东巴画的特征学习更具针对性,本文采用东巴画数据集对网络进行训练。由于现有东巴画图像存在数量少和分辨率低等问题,东巴画图像的采集、处理成为实验的重要环节。本文将拍摄的东巴画图像进行格式转换等预处理后整合成数据集DBH2K。DBH2K包含298幅高清东巴画,每一幅东巴画至少有一个维度的分辨率达到2 K。实验时,将其中278幅用于训练,20幅用于测试,并将测试集命名为set20。同时,对训练集采用随机剪裁方式进行数据增强,剪裁后共获得22 024幅分辨率为480 × 480像素的HR东巴画图像。对于测试集set20,将2 K的高清东巴画进行下采样预处理,作为HR图像,即标签,再对标签下采样不同倍数作为对应网络的LR图像。
2.2 训练情况与评价指标
实验在Windows10,64位操作系统平台上进行,基于GTX2080Ti GPU,使用Pytorch深度学习框架搭建网络模型,batchsize设置为8。在训练DBSRN时,初始学习率设置为2E-4,迭代500 k次,学习率在100 k、200 k、300 k、400 k次迭代时减半。训练DBGAN时,将训练完成的DBSRN作为预训练模型,在此基础上进一步训练。初始学习率设置为1E-4,迭代250 k次,学习率在50 k、100 k、150 k、200 k次迭代时减半。同时,参照Wang等人(2018)的方法,设置α=10-2、β=5×10-3。采用Adam优化器,两个动量参数分别设置为0.9和0.999。
采用PSNR和结构相似度(structural similarity index,SSIM)作为客观评价指标。PSNR计算重建图像与真实高分辨率图像之间的MSE相对于信号最大值平方的对数值,具体为
(16)
式中,n表示每个像素值的比特数,X和Y分别表示重建图像和真实图像。PSNR的数值越大,说明重建图像与真实高分辨率图像越接近。
SSIM也是用于衡量两幅图像相似度的指标,其定义为
(17)

Feng等人(2019)的研究表明,大型超分辨率网络在训练集数据量不足的情况下有过拟合的风险,具体表现为测试集的PSNR值随着迭代次数增加出现先增大后逐渐减小的现象。由于本文东巴画数据集数量较少,而模型结构较复杂,因此训练DBSRN时每迭代5 000次,在测试集set20上进行验证,计算PSNR值,观察PSNR值是否随着迭代次数的增大而减小,出现过拟合现象,PSNR值变化情况如图8所示。可以看出,在测试集上的PSNR值逐渐增大并趋于平稳,未出现先上升后逐渐下降的情况,表明训练过程中未出现过拟合现象。训练DBGAN时,每迭代5 000次对测试集set20输出重建结果,同样在训练过程中未出现清晰度先增加后明显下降的情况。
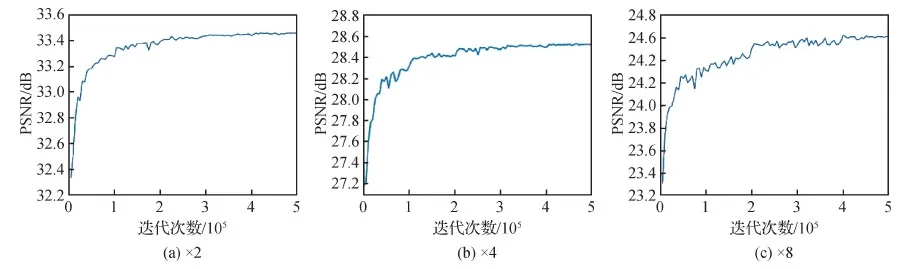
图8 在测试集set20上的PSNR值Fig.8 PSNR values from set20((a)× 2;(b)× 4;(c)× 8)
2.3 对比实验
2.3.1 残差密集单元数量对模型性能的影响
为了验证子网络内部残差密集单元的数量对东巴画重建质量的影响,本文分别用不同数量的残差密集单元构造深层特征提取模块,对比各网络的性能指标。首先使用DBH2K训练由不同数量的残差密集单元组成的DBSRN,然后在东巴画测试集set20上进行测试。表2为上采样因子为2时各网络模型SR与HR图像的PSNR和SSIM,给出了RDU数量对重建质量的影响。

表2 RDU数量对重建质量的影响Table 2 The influence of RDU number on reconstruction quality
从表2可以看出,随着RDU数量逐渐增加,表中数据整体呈上升趋势。因此,针对本文的东巴画数据集,适当增加网络深度可以提升网络性能。此外,表中数据的增速随着RDU数量的增加逐渐减慢,RDU数量为12时比数量为10时指标仅有微小提升,PSNR仅提升0.02 dB。因此综合考虑网络性能与计算资源,对于每一阶段上采样因子为2的超分辨率子网络,本文选用10个RDU作为深层特征提取模块。
2.3.2 损失函数分析
为了验证不同损失函数对重建结果的影响,采用不同的损失函数组合进行对比实验。
表3及图9分别展示了DBSRN、DBSRN+以及DBGAN的客观评价指标和主观视觉质量(上采样因子为4,测试集为set20)。其中,DBSRN仅使用像素损失,DBSRN+加入感知损失,DBGAN加入判别器,融合像素损失、感知损失和对抗损失3个损失的模型。从表3可以看出,由于在像素损失的基础上加入了感知损失和对抗损失,DBSRN+和DBGAN的PSNR与SSIM相比DBSRN均有不同程度的下降。从图9可以看出,DBSRN+和DBGAN的重建结果的清晰度均有不同程度提升,但DBSRN+的结果出现了方格形状的伪影,DBGAN重建结果的线条和色块均与原图最为接近,证明感知损失和对抗训练均提升了视觉效果。

表3 损失函数对比分析Table 3 Comparative analysis of loss function

图9 不同损失函数组合重建结果对比Fig.9 Comparison of reconstruction results of different loss function combinations((a)original image;(b)HR;(c)Bicubic;(d)Lpix;(e)Lpix+Lper;(f)Lpix+Lper+Lgan)
2.4 与其他算法的比较
为了验证本文对东巴画超分辨率重建算法的有效性,与Bicubic(bicubic interpolation)、SRCNN(super-resolution convolutional neural network)(Dong等,2016a)、Srresnet(Ledig等,2017)和IMDN(information multi-distillation network)(Hui等,2019)等超分辨率算法进行比较。首先采用SRCNN、Srresnet和IMDN 3种基于深度学习的方法对东巴画数据集在相同训练设置下训练放大2倍、4倍、8倍的模型,然后用东巴画测试集set20测试,最后将测试结果与DBSRN和DBGAN进行比较。
2.4.1 主观质量评价
图10展示了上采样因子为8的重建结果对比图。可以看出,传统方法双三次插值(Bicubic)的重建结果不理想,手部轮廓和色块均模糊不清。SRCNN重建结果优于双三次插值,对原图中色块的复原结果有了明显改善,但线条上存在大量模糊和错乱情况。Srresnet的重建结果已经能观察到部分较为清晰的线条,手部的色块区域也有了较大程度的还原,但是部分位置(如手指缝隙)依然模糊,同时左下部分的线条发生扭曲变形。IMDN重建结果的指缝部分线条色彩较为鲜明,但左下部分线条仍有扭曲变形的现象。本文提出的DBSRN较好地重建出了原图像中的人物手部线条,对手部色块的颜色和轮廓的还原也更为清晰,然而仅采用像素级损失函数不可避免地导致色块中的像素过度平滑,视觉上复原效果存在一定缺陷。DBGAN的重建结果有效改善了这一情况,尽可能真实地复原了HR图像中色块上的高频信息,复原后的图像在视觉效果上得到了较大提升。

图10 本文算法与其他算法重建结果对比(×8)Fig.10 Comparison of reconstruction results among the proposed algorithm and other algorithms(×8)((a)original image;(b)HR;(c)Bicubic;(d)SRCNN;(e)Srresnet;(f)IMDN;(g)DBSRN(ours);(h)DBGAN(ours))
图11展示了上采样因子为4的重建结果细节对比图。可以看出,Bicubic复原得到的图像线条和色块模糊;SRCNN的重建结果能大致看出画中人物鼻子嘴唇轮廓;Srresnet和IMDN得到的图像效果相近,虽然在一定程度上复原了人脸的线条,然而嘴唇等位置仍然存在细节丢失;DBSRN得到的图像线条与原图几乎一致,却仍然存在像素过度平滑现象;DBGAN的清晰度与还原度得到进一步提升,很好地还原了原图的材质感。从上面分析可以看出,在各尺度下,DBSRN和DBGAN重建结果的视觉效果均优于其他方法,其中DBGAN重建结果的清晰度与原图几乎一致。

图11 本文算法与其他算法重建结果对比(× 4)Fig.11 Comparison of reconstruction results of different algorithms(× 4)((a)original image;(b)HR;(c)Bicubic;(d)SRCNN;(e)Srresnet;(f)IMDN;(g)DBSRN(ours);(h)DBGAN(ours))
2.4.2 客观质量评价
本文在Ycbcr通道的亮度通道上计算PSNR与SSIM,本文算法与其他算法的PSNR和SSIM对比结果如图12和图13所示。可以看出,DBSRN的客观指标PSNR和SSIM在上采样因子为2时分别为33.46 dB和0.911 2,在上采样因子为4时分别为28.54 dB和0.776 2,在上采样因子为8时分别为24.61 dB和0.643 0。
图12和图13还可以看出,DBSRN在测试集set20上的客观指标较Bicubic、SRCNN和Srresnet都有不同程度的提高。PSNR和SSIM较排名第2的Srresnet在上采样因子为2时分别提高了0.10 dB和0.000 8,在上采样因子为4时分别提高了0.18 dB和0.003 2,在上采样因子为8时分别提高了0.23 dB和0.004 4。由于DBGAN以优化感知损失为主,在显著提升重建图像视觉质量的前提下,得到的PSNR和SSIM指标较低。

图12 不同方法的PSNR值对比Fig.12 Comparison of PSNR among different methods

图13 不同方法的SSIM值对比Fig.13 Comparison of SSIM among different methods
2.5 真实环境下的实验
由于本文的低分辨率东巴画均由高分辨率东巴画人为下采样得到,因此对真实环境中的低分辨率东巴画进行实验,并与锐化后的效果进行对比,部分结果如图14所示。图14分别展示了真实低分辨率东巴画LR、DBSRN和DBGAN上采样因子为4的重建结果图以及将LR进行锐化的结果图。由图14可知,DBSRN和DBGAN均有效提高了真实低分辨率东巴画的分辨率和清晰度,而锐化仅通过增加高频分量实现图像清晰度的提升,效果不明显且容易引入噪声,对图像的分辨率没有实质提高。

图14 真实环境下本文算法与其他算法重建结果对比Fig.14 Comparison of reconstruction results among proposed algorithm and other algorithms in real environment((a)original image;(b)LR;(c)DBSRN;(d)DBGAN;(e)sharpening)
2.6 参数量对比分析
本文对比了在上采样因子为4时不同模型的参数量和网络性能,结果如表4所示。可以看出,在得到较高PSNR和SSIM前提下,本文模型参数量较大,达到2.85 M。然而本文模型有极大的灵活性,根据不同应用场景可以对模型进行相应调整。若强调更低的网络空间复杂度,可采用RDU间递归的网络结构,即所有的RDU共享参数,此时参数量为0.46 M,低于Srresnet参数量的1/3,网络性能与Srresnet相比只是略微下降;相比于IMDN,RDU间递归的网络结构参数量更低,且PSNR相比于IMDN提高了0.08 dB;若不采用递归结构,即不共享参数,此时参数量相比子网络间递归的结构增加了一倍,PSNR和SSIM也有微小提升。本文采用子网络间递归的结构,达到了参数量和网络性能的平衡。

表4 参数量和网络性能对比Table 4 The numbers of parameters and network performance comparison
3 结 论
为了有效提升东巴画的分辨率,首先采集东巴画数字图像并整合成数据集用于网络训练,然后针对东巴画内容丰富、线条疏密有致和颜色鲜艳等艺术特点,搭建基于残差密集结构的超分辨率网络对东巴画进行渐进式重建。渐进式的重建方式使各级子网络标签共同指导重建,减少了东巴画高频信息丢失。残差密集结构增强了特征复用,使网络在东巴画数据集较少情况下提取到丰富特征用于重建。最后引入感知损失和对抗损失进行对抗训练,提升了重建东巴画的清晰度。实验结果表明,本文算法应用于图像线条繁杂、纹理细节丰富的东巴画,有良好的重建效果。然而,由于GAN的生成存在随机性,虽然重建图像有更清晰的视觉效果,生成图像会产生原图不存在的纹理和边缘细节。下一步考虑在生成器部分增加约束条件,对GAN的生成进行约束,获得与原图更加接近的高分辨率图像。
