融合自注意力机制的生成对抗网络跨视角步态识别
2022-04-24张红颖包雯静
张红颖,包雯静
1.中国民航大学天津市智能信号与图像处理重点实验室,天津 300300;2.中国民航大学电子信息与自动化学院,天津 300300
0 引 言
步态识别是通过人走路的姿势进行身份识别。与人脸、指纹或虹膜等其他生物特征相比,步态的优势在于无需受试者的配合即可进行远距离身份识别(支双双 等,2019)。因此,步态识别在视频监控、刑事侦查和医疗诊断等领域具有广泛的应用前景。然而,步态识别易受衣着、携带物和视角等因素的影响,提取的步态特征呈现很强的类内变化(王科俊 等,2019),其中视角变化从整体上改变步态特征,从而导致跨视角识别性能明显下降。
针对跨视角步态识别问题,提出了许多先进方法,这些方法通常分为基于模型的方法和基于外观的方法两类。其中,基于外观的方法可以更好地处理低分辨图像并且计算成本低,表现出很大优势。Makihara等人(2006)提出以步态能量图(gait energy image,GEI)(Han和Bhanu,2006)为步态模板的视角转换模型(view transformation model,VTM),利用奇异值分解来计算GEI的投影矩阵和视角不变特征。Hu等人(2013)提出视角无关判别投影(view-invariant discriminative projection,ViDP)方法,在无需知道视角情况下使用线性变换将步态模板投影到特征子空间中,但在视角变化大时识别率较低。近年来,深度学习应用于解决步态识别问题已成为主流方向。Wu等人(2017)提出基于卷积神经网络(convolutional neural network,CNN)的方法从任意视角中自动识别具有判别性的步态特征,在跨视角和多状态识别中效果显著。Shiraga等人(2016)提出基于CNN框架的GEINet应用于大型步态数据集,将GEI作为模型输入,其在视角变化范围较小时有较好表现。基于CNN提取视角不变特征进行跨视角步态识别方法表现出卓越的性能,但CNN是一个黑盒模型,缺乏视角变化的可解释性。生成对抗网络(generative adversarial network,GAN)(Goodfellow等,2014)对数据分布建模具有强大性能,在人脸旋转(Tran等,2017)和风格转换(Zhu等,2017)等应用中取得显著效果。目前,基于GAN的方法重构目标视角的身份特征进行步态识别,可提供良好的可视化效果。Yu等人(2017a)提出步态生成对抗网络(gait generative adversarial network,GaitGAN),将不同视角的步态模板标准化为侧面视角的步态模板进行匹配。He等人(2019)提出多任务生成对抗网络(multi-task generative adversarial network,MGAN)用于学习特定视角的步态特征表示。Wang等人(2019)提出双通道生成对抗网络(two-stream generative adversarial network,TS-GAN)进行步态模板的视角转换以学习标准视角的步态特征。尽管目前基于GAN的步态识别方法通过合成图像提供了良好的可视化效果,但这些方法只能进行特定视角的步态转换,误差随视角跨度增大而不断累积,而且在视角转换过程中未能充分利用特征间的全局依赖关系进行建模,生成图像的细节信息仍然不够清晰。而自注意力机制能更好地建立像素点远近距离依赖关系并且在计算效率上表现出良好性能,在图像生成(Zhang等,2018)和图像超分辨率重建(欧阳宁 等,2019)上有较好表现。
为了实现任意视角间的步态模板转换并提升生成图像的质量,本文提出融合自注意力机制的生成对抗网络的跨视角步态识别方法。通过设计带有自注意力机制的生成器和判别器网络,学习更多全局特征的相关性,进而提高生成图像的质量并增强提取特征的区分度,同时在网络结构中引入谱规范化,提高训练过程的稳定性。本文网络框架由生成器G、视角判别器D和身份保持器Φ构成,采用计算简单且有效的步态能量图作为步态模板,从而更好地实现跨视角步态识别。生成网络中使用具有编码器—解码器结构的生成器G以学习不同视角步态模板间的潜在关系,引入像素级损失以生成更准确的目标视角步态模板;在判别网络中使用两个独立判别器D和Φ,在视角转换的同时保留身份信息,并引入视角分类损失和身份保留损失来保持步态结构信息和身份特征,使生成的步态模板更加逼真并具有判别力。
1 本文方法
1.1 网络模型的整体结构


图1 网络模型整体框架Fig.1 The framework of network
在训练网络时,利用对抗损失来约束生成器和判别器,目标函数为

(1)

1.2 生成器网络
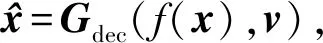

图2 生成器网络Fig.2 Generator
生成器网络结构参数设置如表1所示,对于下采样区Genc,在每个卷积层后均使用批标准化(batch normalization,BN)和ReLU激活函数;对于上采样区Gdec,除了输出层使用Tanh激活函数外,在每个反卷积层后均使用谱规范化(spectral normalization,SN)(Miyato等,2018)、BN和ReLU激活函数。

表1 生成器网络结构参数设置Table 1 The parameter setting of generator
(2)

1.3 判别器网络
本文构建了两个判别器:视角判别器D和身份保持器Φ,从而对真实的步态图像和生成器生成的步态图像进行区分,并在视角转换过程中保持身份特征。
1.3.1 视角判别器


表2 视角判别器网络结构参数设置Table 2 The parameter setting of view classifier

(3)
式中,Dcls(xi)是输入目标视角中真实的步态模板x在视角域的概率分布。优化G时,输入生成的步态模板及相应的视角指示器,目标函数为
(4)
通过最小化该目标函数,生成器G试图合成可以分类到视角指示器v指定视角的步态模板。
1.3.2 身份保持器
传统的GAN模型生成的样本缺乏多样性,生成器会在某种情况下重复生成完全一致的图像,而对于跨视角步态识别任务,在步态模板视角转换过程中保持身份信息是至关重要的。因此,在本文模型中引入身份保持器Φ,缩减目标视角与生成视角的步态模板间差距,进而保持身份信息。身份保持器Φ基于GaitGAN中的身份判别器DA的结构,与视角判别器D类似,引入谱规范化来增加模型的稳定性。如图3所示,身份保持器Φ以(xanc,xpos,xneg)3个图像作为输入,输出xanc相关性标签 。

图3 身份保持器网络Fig.3 Identity preserving discriminator
为了使生成的步态模板更好地保持身份信息,本文引入困难样本三元组Tri-Hard损失(Hermans等,2017)作为身份保留损失来增强生成图像的可判别性。以(xanc,xpos,xneg)3个图像作为输入,最小化如下身份保持损失
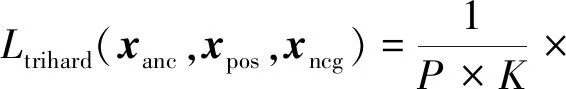
(5)
式中,xanc和xpos是正样本对,它们的身份标签相同,xpos所属的图片集为A;xanc和xneg是负样本对,它们的身份标签不同,xneg所属的图片集为B。困难样本三元组指对于每一个训练batch,随机挑选P个不同身份的行人,每个行人随机选K幅不同的图像,对于训练批次中每一个xanc,选取类内距离最远的样本作为xpos,在训练批次内所有负样本中选取距离最近的作为xneg。d(·,·)表示两个输入元素的欧氏距离,而δ≥0表示三元组损失的边界。在实验中根据经验将δ设为0.2。通过使Tri-Hard损失最小化,d(xanc,xpos)趋于0,而d(xanc,xneg)以一定的边界距离大于d(xanc,xpos)。当损失变为0时,不会向后传播梯度。

1.4 自注意力机制
虽然基于GAN的步态识别方法可实现步态模板的视角转换,但在视角转换过程中未能有效捕获特征间的全局依赖关系,生成图像的细节信息不够清晰,而且会伴随模糊的伪影。这是由于卷积核大小受限,无法在有限的网络层次结构中直接获取图像所有位置特征间的关联关系;而自注意力机制可以更好地处理图像中长范围、多层次的依赖关系,有助于增强步态特征的表达能力,提高步态识别的性能。因此,本文将自注意力机制(Zhang等,2018)引入到生成器和判别器网络中,在生成器的上采样区引入自注意力模块能更好地整合全局和局部的空间信息,提高生成图像的协调性和质量;在判别器引入自注意力模块可以更准确地将真实图像和生成图像进行区分。
如图2所示,自注意力模块将前一层提取的特征图x∈RC×N分别送入两个卷积核为1、输出通道数是C/8的特征空间f(x),g(x)和卷积核为1、输出通道数为C的特征空间h(x),其中f(x)=Wfx,g(x)=Wgx,h(x)=Whx,式中,Wf、Wg、Wh分别为特征空间f(x)、g(x)、h(x)对应的权重矩阵,且Wf∈RC/8×N,Wg∈RC/8×N,Wh∈RC×N。通过对f(x)和g(x)进行张量相乘来计算两个特征空间相似度sij,再使用softmax函数进行归一化,得到第j个区域对第i个位置所占权重的注意力图βj,i,具体为
(6)
随后,将特征图x经过特征空间h(x),再与βj,i构成的注意力权重矩阵相乘,注意力层的输出为
(7)
式中,oi为注意力层的输出,h(xi)为输入信息x与权重矩阵Wh∈RC×N的乘积。
最后,将注意力层的输出与比例系数γ相乘,并添加回输入特征图x,最终输出为
yi=γoi+xi
(8)
式中,γ是初始值为0的比例系数,yi表示最终的输出。输出的注意力特征图会进入下一个网络中继续特征提取与学习的过程。随着网络训练的进行,注意力特征图逐渐为非局部区域分配更多的权重。
2 网络训练
本文采用Goodfellow等人(2014)提出的交替迭代训练的策略,当更新一方的参数时,另一方的参数固定住不更新。网络的训练过程如下:
输入:训练集X。
输出:网络D,G,Φ。
1)判别过程:
(2)视角判别器D网络输出图像真/伪标签并分类到相应的视角域,计算LD;

2)生成过程:
(2)对目标视角以等概率来随机采样目标视角指示器v;

(4)视角判别器D网络输出图像真/伪标签并分类到相应的视角域,计算LD;
(6)反向传递损失至G网络并计算Lpixel;

3)重复步骤1)和2),直至网络收敛。
本文的目标是将步态模板从验证集中的任意视角转换至注册集中的目标视角,同时保留身份信息。为了实现这个目标,联合上述损失函数协同训练,总体目标函数为
(9)
式中,λt,t∈{1,2,3,4}是超参数,用来平衡不同的损失。随着模型训练次数增加,视角判别器区分真/伪和视角分类性能越来越强,身份保持器更准确地保留输入步态图像的身份标签,而生成器更好地生成具有目标视角并保持身份信息的步态图像。整个训练过程得益于4个方面:1)Genc学习输入步态图像的特征表示f(x),将保留更多具有鉴别性的身份信息;2)D中视角分类可引导步态图像的视角转换更加准确;3)视角指示器和身份特征连接向量作为Gdec的输入,可引导生成器生成不同视角的步态图像;4)引入自注意力机制,提高了生成图像的协调性和质量。
3 实验结果及分析
3.1 数据集
3.1.1 公共数据集
CASIA-B(Chinese Academy of Sciences’Institute of Automation gait database——dataset B)步态数据集(Yu等,2006)是广泛用于评估跨视角步态识别效果的公共数据集,包含124人、3种行走状态和11个不同视角(0°,18°,…,180°)。每个人在正常状态下有6个序列(NM #01—06),穿着外套状态下有2个序列(CL#01—02),携带背包状态下有2个序列(BG#01—02),所以,每个人有11×(6+2+2)=110个序列。
OU-MVLP(multi-view large population dataset)步态数据集(Takemura等,2018)是迄今为止世界上最大的跨视角步态数据库,包含10 307人、14个不同视角(0°,15°,…,90°;180°,195°,…,270°)以及每个角度有2个序列(#00—01),步行状态没有变化。官方将数据库分为5 153人的训练集和5 154人的测试集。在测试阶段,序列#01作为注册集,序列#00作为测试集。
3.1.2 帧移式合成GEI数据集
本文方法是基于CNN实现的GAN网络,其性能在一定程度上取决于训练样本的数据规模。考虑到CASIA-B数据量较少,而OU-MVLP数据量大,因此通过对CASIA-B的GEI数据集进行数据增强来评估对步态识别准确率的影响。
本文采用帧移式方法来增加合成GEI的数量,帧移式生成GEI的原理如图4所示。输入步态序列为N帧,根据轮廓的宽高比,得到步态周期为k帧(k≤N),首先将前k帧的步态序列图合成一幅GEI,再以i帧间隔抽取第i帧到第i+k帧的步态序列图合成下一幅GEI,以此类推,直至c×i+k为N,则合成完该序列所有GEI,本文设置i为2。大多学者是将所有周期内的轮廓图合成最终一幅GEI,数据量略显不足。本文利用步态序列的前后循环性和连贯性,将步态序列按照周期帧移方式合成更多GEI。

图4 帧移式生成GEI的原理图Fig.4 Schematic diagram of frame-shift generation of GEI
3.2 评价指标及实验设置
3.2.1 评价指标

(10)
然后根据欧氏距离搜寻注册集中距离最近的步态特征,从而判断是否具有相同身份。
3.2.2 实验设置
实验基于深度学习框架Pytorch在显卡为NVIDA RTX2080Ti×2的Dell工作站上进行训练。本文在CASIA-B数据集的实验设置是将数据集均匀划分为两组,前62人用于训练,后62人用于测试。网络输入和输出的GEI尺寸设置为64 × 64像素,批量大小batch_size设为64。考虑到CASIA-B数据集训练人数较少,使用GEI数据增强进行实验。在OU-MVLP数据集的设置与官方(Takemura等,2018)一致,由于OU-MVLP中GEI数据量远超CASIA-B,故将batch_size设为32。
如第2节所述,本文采用交替训练G、D和Φ网络的方式。由于判别器的学习能力强于生成器,为了保持两者同步,当判别器D和Φ训练5次后,对生成器G更新1次。在训练过程中,所有网络模型的权重通过均值为0、方差为0.02的高斯分布进行随机初始化。采用Adam优化器更新网络参数,β1=0.5,β2=0.999,生成器和判别器网络分别采用0.000 1和0.000 4的初始化学习率进行单独训练。对于CASIA-B数据集,本文训练模型40 K迭代次数,前20 K迭代时学习率保持不变,剩下20 K轮迭代采用step策略,每5 K轮迭代学习率下降为原来的10%,直至衰减为0。对于OU-MVLP数据集,本文训练模型200 K,前150 K迭代时学习率保持不变,剩下50 K轮迭代,每10 K轮迭代学习率变为原来的10%。在本文实验中,凭经验设置式(9)中的权重系数,λ1=λ2=1、λ3=λ4=10。
3.3 实验结果与分析
3.3.1 消融实验
为探究自注意力模块在网络中所处位置对识别性能的影响,本文将自注意力模块添加到生成器的不同位置,并在CASIA-B数据集进行对比实验,如表3所示。可以看出,自注意力模块添加到解码器第2层反卷积之后位置识别效果更好,而位置靠前、靠后或添加到编码器的识别效果均不理想。当添加位置较靠前时,采集到的信息较粗糙,噪声较大;而当对较小的特征图建立依赖关系时,其作用与局部卷积作用相似。因此在特征图较大情况下,自注意力能捕获更多的信息,选择区域的自由度也更大,从而使生成器和判别器能建立更稳定的依赖关系。自注意力模块需在中高层特征图之间使用,所以本文将自注意力机制添加到解码器第2层反卷积后的特征图上。而同时在编码器中加入自注意力模块会导致部分生成的步态模板信息丢失,所以没有单独在解码器中加入自注意力模块的效果好。此外,通过对比生成器中添加自注意力模块与未使用自注意力模块的实验结果,前者识别率较高,进一步验证了自注意力模块的有效性。

表3 自注意力模块处于生成器不同位置对识别率的影响Table 3 The effect of different position of the generator of self-attention module on recognition performance /%
通过上述实验,自注意力模块对步态模板生成具有较好的识别效果,为进一步提高生成图像的判别能力,在身份保持器中融合身份保留损失,为验证其对步态识别效果的影响,在CASIA-B数据集进行消融实验。实验结果如表4所示。

表4 本文不同方案在CASIA-B的识别率对比Table 4 Comparison of recognition performance among different schemes under proposed framework /%
从表4可以看出,在网络模型中没有自注意力模块或身份保留损失的情况下,本文方法仍然比基准方法GaitGAN的识别率高。当引入自注意力模块和身份保留损失训练网络时,在CASIA-B数据集上的识别率有显著提升,平均rank-1准确率提升了15%。实验结果表明,自注意力模块有效解决了目标视角步态模板生成的不完全的问题,提升了生成图像的协调性;身份保留损失使生成的步态模板更好地保持身份信息,增强了生成图像的可判别性。自注意力模块和身份保留损失两者结合有效提高了步态视角转换的效果与质量。
为进一步验证GEI数据增强对步态识别效果的影响,在CASIA-B数据集上进行实验,结果如图5所示。

图5 GEI数据增强在CASIA-B数据集的实验结果Fig.5 Impact of GEI data augmentation evaluated on CASIA-B
从图5可以看出,经过GEI数据增强,达到了最佳识别精度。与GaitGAN方法相比,即使未经数据增强训练的方法也能取得较高的识别率。通过GEI数据增强,既避免了因生成的步态能量图过少导致的识别率不高问题,也避免了不同身份的GEI样本过于接近问题,有助于提高跨视角步态识别率。
3.3.2 与最新方法对比
1)在CASIA-B数据集实验结果。为验证本文方法的有效性,与C3A(complete canonical correlation analysis)(Xing等,2016)、SPAE(stacked progressive auto-encoders)(Yu等,2017b)、GaitGAN(Yu等,2017a)和MGAN(He等,2019)等最新方法进行比较,选择验证集视角为54°、90°、126°进行跨视角步态识别的对比实验。图6显示了排除相同视角的所有注册集视角的跨视角步态识别率。

图6 在Probe NM的3个代表性视角54°、90°和126°下与最新方法比较结果(排除相同视角)Fig.6 Comparison with the state-of-the-art methods under the probe views 54°,90° and 126° excluding identical view((a)54°;(b)90°;(c)126°)

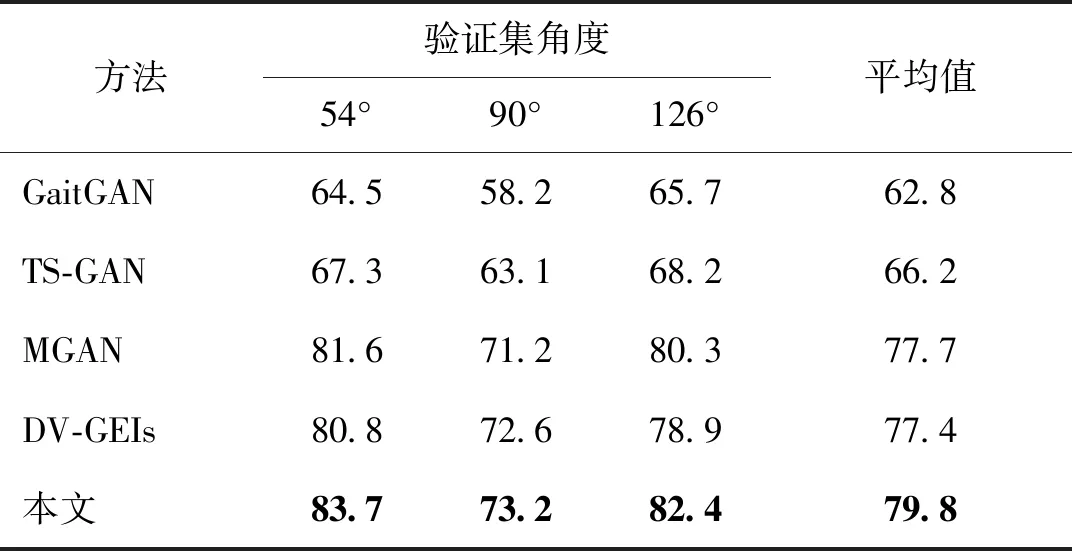
表5 排除相同视角下,在CASIA-B数据集中3种验证集视角的平均识别率比较Table 5 Comparison of average identification rates among three probe views excluding identical view on CASIA-B dataset /%
2)在OU-MVLP数据集实验结果。本文对4个在OU-MVLP数据集实验的方法不多,所以选择与GEINet(Shiraga等,2016)、3in+2diff(Takemura等,典型视角(0°、30°、60°、90°)进行实验,由于近几年2019)和GaitSet(Chao等,2019)等3种方法进行比较,结果如表6所示,所有结果都是在排除相同视角的注册集视角下取平均值得到的识别率。从表6可以看出,GEINet和3in+2diff方法在OU-MVLP这种大规模的跨视角步态识别评估实验中识别性能较差,而本文方法可以达到65.9%的平均识别精度,远高于这两种方法。由于GaitSet采用人体轮廓序列作为输入特征,比GEI包含更多的时空特征信息,所以识别率更高。实验结果表明,与采用GEI步态模板的其他方法相比,本文方法在大规模的跨视角步态数据库中仍具有较好的适用性。

表6 排除相同视角下,在OU-MVLP数据集中4种典型视角的平均识别率比较Table 6 Comparison of average identification rates among four representative probe views on OU-MVLP dataset /%
3.3.3 实验结果定性分析
目前基于GAN的步态识别方法中,MGAN需要事先对视角进行估计才能实现特定视角的步态图像生成,GaitGAN和TS-GAN则是将任意视角的步态模板标准化到侧面视角进行识别,如果要将某一视角的步态模板转换到任意视角,则需构建多个模型,而本文方法建立的统一模型可将步态模板从任意视角转换到目标视角。本文将OU-MVLP数据集中的4个典型视角(0°,30°,60°,90°)合成的步态模板进行可视化,如图7所示。其中,左侧图像为验证集中的输入GEI,上侧图像是注册集中真实的目标GEI,右下4 × 4矩阵中的图像是生成的GEI。由图7可以看出,本文训练的任意视角间步态模板转换模型即使在视角变化较大情况下,生成的步态图像也与真实的目标视角的步态图像高度相似。

图7 输入视角为0°,30°,60°和90°的步态模板合成的可视化结果Fig.7 Visualization of generated gait templates at 0°,30°,60° and 90° with different input views
4 结 论
针对步态识别中的跨视角问题,本文提出融合自注意力机制的生成对抗网络框架,建立可实现任意视角间的步态模板转换模型,由生成器、视角判别器和身份保持器构成,解决了目前生成式方法只能进行特定视角的步态转换并且生成图像的特征信息容易丢失问题,达到了使用统一模型生成任意视角的步态模板的效果,并在视角转换过程中保留步态特征信息,提升了生成图像的质量。
为验证本文方法对跨视角步态识别的有效性,在CASIA-B步态数据库上分别进行对比、消融和增强实验,设计将自注意力模块添加到生成器的不同位置进行对比实验,结果表明在解码器第2层反卷积后加入自注意力模块效果更好;对自注意力模块和身份保留损失进行消融实验,相比于Gait GAN方法,两者结合时的步态识别率有显著提升;采用帧移式方法对CASIA-B数据集进行GEI数据增强实验,进一步提升了识别率。在OU-MVLP大规模的跨视角步态数据库中进行对比实验,与GEINet、3in+2diff两种方法相比,所提方法仍具有较好的适用性,可以达到65.9%的平均识别精度。
本文方法以步态能量图为模型输入,计算简单有效,但在实际场景中,行人检测与分割的好坏会直接影响合成步态能量图的质量;同时在实际应用中,视角变化会与其他协变量(如衣着、携带物)结合。因此,如何建立功能更强大的网络模型来解决复杂场景的步态识别问题,仍是未来步态识别研究的技术难点。
